
データサイエンスと機械学習(第15回):SVM、すべてのトレーダーのツールボックスの必須ツール

内容:
- はじめに
- 超平面とは何か?
- 線形SVM
- デュアルSVM
- ハードマージン
- ソフトマージン
- 線形サポートベクターマシンモデルの訓練
- 線形サポートベクターモデルから予測を得る
- 線形SVMモデルをテストする
- データの収集と正規化
- DualSVMONNXクラスインスタンス|クラスの初期化
- pythonによるデュアルSVMモデルの訓練
- SVCモデルsklearnをONNXに変換して保存する
- 最後に
はじめに
サポートベクターマシン(SVM)は、線形または非線形の分類や回帰タスク、時には異常値検出タスクに使用される強力な教師あり機械学習アルゴリズムです。
ベイズ分類技術やロジスティック回帰が単純な数学的モデルを用いて情報を分類するのとは異なり、SVMはN次元空間でデータを分離する最適な超平面を見つけることを目的とした複雑な数学的学習関数を持っています。
サポートベクターマシンは通常、分類タスクに使われます。

超平面とは何か?
超平面は、異なるクラスのデータ点を分離するために使用される線です。

超平面には次のような性質があります。
次元性:二値分類問題では、超平面は(d-1)次元部分空間であり、ここでdは特徴空間の次元です。例えば、2次元の特徴空間では、超平面は1次元の直線です。
方程式:数学的には、超平面は一次方程式で表すことができます。
![]()
![]() は超平面に直交するベクトルで、その向きを決めます。
は超平面に直交するベクトルで、その向きを決めます。
![]() は特徴ベクトルです。
は特徴ベクトルです。
bは、超平面を原点から遠ざけるスカラーバイアス項です。
分離:超平面は特徴空間を次の2つの半空間に分割します。
![]() が1つのクラスに対応する領域
が1つのクラスに対応する領域
![]() があと1つのクラスに対応する領域
があと1つのクラスに対応する領域
マージン:SVMのゴールは、マージンを最大化する超平面を見つけることであり、これは超平面とどちらかのクラスから最も近いデータ点との距離です。これらの最も近いデータ点を「サポートベクター」と呼びます。 SVMは、分類誤差を最小にしながら最大のマージンを達成する超平面を見つけることを目的としています。
分類最適な超平面が見つかれば、それを使って新しいデータ点を分類することができます。 ![]() を評価することで、データ点が超平面のどちらの側に位置するかを決定し、2つのクラスのいずれかに分類することができます。
を評価することで、データ点が超平面のどちらの側に位置するかを決定し、2つのクラスのいずれかに分類することができます。
超平面の概念は、最大マージン分類器の基礎を形成するため、SVMの重要な要素です。SVMは、クラス間のマージンを最大に保ちながら、データを最もよく分離する超平面を見つけることを目的としており、その結果、モデルの汎化性と未経験データに対する頑健性が向上します。
double CLinearSVM::hyperplane(vector &x) { return x.MatMul(W) - B; }
先に述べたように、bと表記されるバイアス項はスカラー項なので、double変数を宣言しなければなりません。
class CLinearSVM { protected: CMatrixutils matrix_utils; CMetrics metrics; CPreprocessing<vector, matrix> *normalize_x; vector W; //Weights vector double B; //bias term bool is_fitted_already; struct svm_config { uint batch_size; double alpha; double lambda; uint epochs; }; private: svm_config config;
クラス名CLinearSVMは、これが線形サポートベクターマシンであることを説明しています。これにより、線形サポートベクターマシンとデュアルサポートベクターマシンがあるSVMの側面に戻ります。
線形SVM
線形SVMは線形カーネルを採用したSVMの一種で、データ点を分離するために線形決定境界を使用することを意味します。線形SVMでは、特徴空間を直接扱うので、最適化問題はしばしば原始形で表現されます。線形SVMの第一の目標は、データを最もよく分離する線形超平面を見つけることです。
これは、線形分離可能なデータに最適です。
デュアルSVM
デュアルSVMはSVMの別個のタイプではなく、むしろSVM最適化問題の表現です。SVMの双対形式は、元の最適化問題を数学的に再定式化したもので、より効率的な解法を可能にします。ラグランジュ乗数を導入し、原始問題と等価な双対目的関数を最大化します。二重問題を解くことは、分類に重要なサポートベクターを決定することにつながります。
これは線形に分離できないデータに最適です。

また、超平面を使ったSVM分類器の決定には、ハードマージンかソフトマージンのどちらかを使うことができることも知っておく必要があります。
ハードマージン
訓練データが線形分離可能であれば、2つのクラスデータを分離する2つの平行超平面を選択し、その距離をできるだけ大きくすることができます。この2つの超平面に囲まれた領域を「マージン」と呼び、最大マージン超平面はその中間に位置する超平面です。正規化または標準化されたデータセットでは、これらの超平面は次式で記述できます。
![]() (この境界線上またはそれ以上のものは1つのクラス(ラベル1))
(この境界線上またはそれ以上のものは1つのクラス(ラベル1))
および
![]() (この境界線上またはそれ以下のものはあと1つのクラス(ラベル-1))
(この境界線上またはそれ以下のものはあと1つのクラス(ラベル-1))
両者の距離は2/||w||であり、距離を最大にするためには、||w||は最小でなければなりません。データ点がマージン内に入るのを防ぐため、yi(wTXi -b) >= 1という制限を加えます。ここで、yi = ターゲットのi行目、Xi = Xのi行目です。
ソフトマージン
データが線形分離可能でない場合にSVMを拡張するには、ヒンジ損失関数が役に立ちます。
![]()
なお、 ![]() はi番目のターゲット(すなわち、この場合は1または-1)であり、
はi番目のターゲット(すなわち、この場合は1または-1)であり、 ![]() はi番目の出力です。
はi番目の出力です。
データ点がクラス=1であれば、損失は0となり、そうでなければマージンとデータ点間の距離となります。
![]() ここで、λはマージンの大きさとxiがマージンの正しい側にあることのトレードオフです。λが低すぎると、方程式はハードマージンになります。
ここで、λはマージンの大きさとxiがマージンの正しい側にあることのトレードオフです。λが低すぎると、方程式はハードマージンになります。
線形SVMクラスでは、ハードマージンを使用します。これはsign関数(数学表記の実数の符号を返す関数)によって可能になります。次のように表現されます。
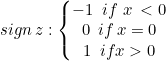
int CLinearSVM::sign(double var) { if (var == 0) return (0); else if (var < 0) return -1; else return 1; }
線形サポートベクターマシンモデルの訓練
サポートベクターマシン(SVM)の学習プロセスでは、マージンを最大化しながらデータを分離する最適な超平面を見つけます。マージンは、超平面とどちらかのクラスから最も近いデータ点との間の距離です。目標は、分類誤差を最小にしながらマージンを最大にする超平面を見つけることです。
重み(w)の更新
a.第1項:損失関数の第1項は、分類誤差を測定するヒンジ損失に相当します。各訓練例に対してiについて,重みに関する損失の導関数を計算します。wに関して損失の導関数を計算します。
-
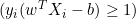 の場合、データ点が正しく分類されてマージンの外にあり、導関数は0となります。
の場合、データ点が正しく分類されてマージンの外にあり、導関数は0となります。 -
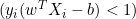 の場合、データ点がマージン内にあるか、誤分類されており、導関数は
の場合、データ点がマージン内にあるか、誤分類されており、導関数は 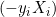 となります。
となります。
b.第2項
第2項は正則化項を表します。これは小さなマージンを奨励し、過学習を防ぐのに役立ちます。この項を重みwに関して微分すると2λwです。ここで、λは正則化パラメータです。
c.第1項と第2項の導関数の組み合わせ
重みwの更新は次のようになります。
![]() の場合は
の場合は ![]() に更新します。
に更新します。 ![]() の場合は
の場合は ![]() に更新します。ここでαは学習率です。
に更新します。ここでαは学習率です。
切片の更新(b)
a.第1項
切片bに対するヒンジ損失の導関数は重みと同様に計算されます。
-
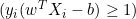 の場合、導関数は0です。
の場合、導関数は0です。 -
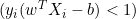 の場合、導関数は
の場合、導関数は 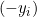 です。
です。
b.第2項
第2項は切片に依存しないので、そのbに対する導関数は0です。切片の更新bは次のように更新されます。
-
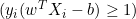 の場合、
の場合、 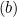 を
を 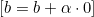 で更新します。
で更新します。 -
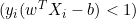 の場合、
の場合、 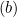 を
を 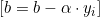 で更新します。
で更新します。
スラック変数(ξ)
スラック変数(ξ)は、いくつかのデータ点がマージンの内側にあることを許容します。これは、誤分類またはマージンの内側にあることを意味します。条件 ![]() は、決定境界が少なくとも
は、決定境界が少なくとも ![]() 単位でデータ点 iから離れていることを表します。
単位でデータ点 iから離れていることを表します。
要約すると、SVMの学習プロセスでは、ヒンジ損失と正則化項に基づいて重みと切片を更新します。目的は、スラック変数によって許容されるマージン内の潜在的な誤分類を考慮しながら、マージンを最大化する最適超平面を見つけることです。このプロセスは、通常、最適化技術を用いて解決され、決定境界を定義するために、訓練プロセス中にサポートベクターが特定されます。
void CLinearSVM::fit(matrix &x, vector &y) { matrix X = x; vector Y = y; ulong rows = X.Rows(), cols = X.Cols(); if (X.Rows() != Y.Size()) { Print("Support vector machine Failed | FATAL | X m_rows not same as yvector size"); return; } W.Resize(cols); B = 0; normalize_x = new CPreprocessing<vector, matrix>(X, NORM_STANDARDIZATION); //Normalizing independent variables //--- if (rows < config.batch_size) { Print("The number of samples/rows in the dataset should be less than the batch size"); return; } matrix temp_x; vector temp_y; matrix w, b; vector preds = {}; vector loss(config.epochs); during_training = true; for (uint epoch=0; epoch<config.epochs; epoch++) { for (uint batch=0; batch<=(uint)MathFloor(rows/config.batch_size); batch+=config.batch_size) { temp_x = matrix_utils.Get(X, batch, (config.batch_size+batch)-1); temp_y = matrix_utils.Get(Y, batch, (config.batch_size+batch)-1); #ifdef DEBUG_MODE: Print("X\n",temp_x,"\ny\n",temp_y); #endif for (uint sample=0; sample<temp_x.Rows(); sample++) { // yixiw-b≥1 if (temp_y[sample] * hyperplane(temp_x.Row(sample)) >= 1) { this.W -= config.alpha * (2 * config.lambda * this.W); // w = w + α* (2λw - yixi) } else { this.W -= config.alpha * (2 * config.lambda * this.W - ( temp_x.Row(sample) * temp_y[sample] )); // w = w + α* (2λw - yixi) this.B -= config.alpha * temp_y[sample]; // b = b - α* (yi) } } } //--- Print the loss at the end of an epoch is_fitted_already = true; preds = this.predict(X); loss[epoch] = preds.Loss(Y, LOSS_BCE); printf("---> epoch [%d/%d] Loss = %f Accuracy = %f",epoch+1,config.epochs,loss[epoch],metrics.confusion_matrix(Y, preds, false)); #ifdef DEBUG_MODE: Print("W\n",W," B = ",B); #endif } during_training = false; return; }
線形サポートベクターモデルから予測を得る
モデルから予測値を得るには、超平面が出力を与えた後、データを符号関数に渡さなければなりません。
int CLinearSVM::predict(vector &x) { if (!is_fitted_already) { Print("Err | The model is not trained, call the fit method to train the model before you can use it"); return 1000; } vector temp_x = x; if (!during_training) normalize_x.Normalization(temp_x); //Normalize a new input data when we are not running the model in training return sign(hyperplane(temp_x)); }
線形SVMモデルをテストする
一般的なプラクティスとして、市場データに対して重要な予測をおこなうためにモデルをデプロイする前にテストすることは良いことです。
#include <MALE5\Support Vector Machine(SVM)\svm.mqh> CLinearSVM *svm; input uint bars = 1000; input uint epochs_ = 1000; input uint batch_size_ = 64; input double alpha__ =0.1; input double lambda_ = 0.01; bool train_once; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- svm = new CLinearSVM(batch_size_, alpha__, epochs_, lambda_); train_once = false; //--- return(INIT_SUCCEEDED); }
データ収集を進めていくので、RSI、BOLLINGERBANDSHIGH、LOW、MIDの4つの独立変数を使用します。
vec_.CopyIndicatorBuffer(rsi_handle, 0, 0, bars); dataset.Col(vec_, 0); vec_.CopyIndicatorBuffer(bb_handle, 0, 0, bars); dataset.Col(vec_, 1); vec_.CopyIndicatorBuffer(bb_handle, 1, 0, bars); dataset.Col(vec_, 2); vec_.CopyIndicatorBuffer(bb_handle, 2, 0, bars); dataset.Col(vec_, 3); open.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_OPEN, 0, bars); close.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_CLOSE, 0, bars); for (ulong i=0; i<vec_.Size(); i++) //preparing the independent variable dataset[i][4] = close[i] > open[i] ? 1 : -1; // if price closed above its opening thats bullish else bearish
データを訓練用サンプルとテスト用サンプルに分けることで、データ収集プロセスを終了します。
matrix_utils.TrainTestSplitMatrices(dataset,train_x,train_y,test_x,test_y,0.7,42); //split the data into training and testing samples
訓練/モデルのフィッティング
svm.fit(train_x, train_y);
出力
0 15:15:42.394 svm test (EURUSD,H1) ---> epoch [1/1000] Loss = 7.539322 Accuracy = 0.489000 IK 0 15:15:42.395 svm test (EURUSD,H1) ---> epoch [2/1000] Loss = 7.499849 Accuracy = 0.491000 EG 0 15:15:42.395 svm test (EURUSD,H1) ---> epoch [3/1000] Loss = 7.499849 Accuracy = 0.494000 .... .... GG 0 15:15:42.537 svm test (EURUSD,H1) ---> epoch [998/1000] Loss = 6.907756 Accuracy = 0.523000 DS 0 15:15:42.537 svm test (EURUSD,H1) ---> epoch [999/1000] Loss = 7.006438 Accuracy = 0.521000 IM 0 15:15:42.537 svm test (EURUSD,H1) ---> epoch [1000/1000] Loss = 6.769601 Accuracy = 0.516000
訓練とテストの両方でモデルの精度を観察します。
vector train_pred = svm.predict(train_x), test_pred = svm.predict(test_x); printf("Train accuracy = %f",metrics.confusion_matrix(train_y, train_pred, true)); printf("Test accuracy = %f ",metrics.confusion_matrix(test_y, test_pred, true));
出力
CH 0 15:15:42.538 svm test (EURUSD,H1) Confusion Matrix IQ 0 15:15:42.538 svm test (EURUSD,H1) [[171,175] HE 0 15:15:42.538 svm test (EURUSD,H1) [164,190]] DQ 0 15:15:42.538 svm test (EURUSD,H1) NO 0 15:15:42.538 svm test (EURUSD,H1) Classification Report JD 0 15:15:42.538 svm test (EURUSD,H1) LO 0 15:15:42.538 svm test (EURUSD,H1) _ Precision Recall Specificity F1 score Support JQ 0 15:15:42.538 svm test (EURUSD,H1) -1.0 0.51 0.49 0.54 0.50 346.0 DH 0 15:15:42.538 svm test (EURUSD,H1) 1.0 0.52 0.54 0.49 0.53 354.0 HL 0 15:15:42.538 svm test (EURUSD,H1) FG 0 15:15:42.538 svm test (EURUSD,H1) Accuracy 0.52 PP 0 15:15:42.538 svm test (EURUSD,H1) Average 0.52 0.52 0.52 0.52 700.0 PS 0 15:15:42.538 svm test (EURUSD,H1) W Avg 0.52 0.52 0.52 0.52 700.0 FK 0 15:15:42.538 svm test (EURUSD,H1) Train accuracy = 0.516000 MS 0 15:15:42.538 svm test (EURUSD,H1) Confusion Matrix LI 0 15:15:42.538 svm test (EURUSD,H1) [[79,74] CM 0 15:15:42.538 svm test (EURUSD,H1) [68,79]] FJ 0 15:15:42.538 svm test (EURUSD,H1) HF 0 15:15:42.538 svm test (EURUSD,H1) Classification Report DM 0 15:15:42.538 svm test (EURUSD,H1) NH 0 15:15:42.538 svm test (EURUSD,H1) _ Precision Recall Specificity F1 score Support NN 0 15:15:42.538 svm test (EURUSD,H1) -1.0 0.54 0.52 0.54 0.53 153.0 PQ 0 15:15:42.538 svm test (EURUSD,H1) 1.0 0.52 0.54 0.52 0.53 147.0 JE 0 15:15:42.538 svm test (EURUSD,H1) GP 0 15:15:42.538 svm test (EURUSD,H1) Accuracy 0.53 RI 0 15:15:42.538 svm test (EURUSD,H1) Average 0.53 0.53 0.53 0.53 300.0 JH 0 15:15:42.538 svm test (EURUSD,H1) W Avg 0.53 0.53 0.53 0.53 300.0 DO 0 15:15:42.538 svm test (EURUSD,H1) Test accuracy = 0.527000
モデルのサンプル外予測の精度は53%で、悪いモデルだと言う人もいますが、私は平均的なモデルだと思います。これには、モデルのバグ、不十分な正規化、収束基準など、さまざまな要因が考えられます。パラメータを調整して、何がより良い結果につながるかを確認してください。ただし、線形モデルにはデータが複雑すぎる可能性もあります。それについては確信があるので、デュアルSVMが役立つかどうかを試してみましょう。
ONXX Python形式で検討するデュアルSVMについては、Python sklearnデュアルSVMモデルのパフォーマンスと精度に近づくためのMQL5コード化モデルを取得できませんでした。そのため、PythonデュアルSVMを検討する価値はあると思います。 現在、MQL5のデュアルSVMライブラリは、この記事で提供されているメインのsvm.mqhファイルと、この記事の最後にリンクされているGitHubで見つけることができます。
PythonでデュアルSVMを開始するには、データを収集し、MQL5を使って正規化する必要があります。svm.mqhファイルの中にCDualSVMONNXという名前で新しいクラスを作成する必要があるかもしれません。このクラスは、Pythonコードから取得したONNXモデルを処理します。
class CDualSVMONNX { private: CPreprocessing<vectorf, matrixf> *normalize_x; CMatrixutils matrix_utils; struct data_struct { ulong rows, cols; } df; public: CDualSVMONNX(void); ~CDualSVMONNX(void); long onnx_handle; void SendDataToONNX(matrixf &data, string csv_name = "DualSVMONNX-data.csv", string csv_header=""); bool LoadONNX(const uchar &onnx_buff[], ENUM_ONNX_FLAGS flags=ONNX_NO_CONVERSION); int Predict(vectorf &inputs); vector Predict(matrixf &inputs); };
クラスは一目でこのようになるでしょう。
データの収集と正規化
モデルが学習するためのデータが必要であり、そのデータをSVMモデルに適したものにするために、データをサニタイズする必要もあります。
void CDualSVMONNX::SendDataToONNX(matrixf &data, string csv_name = "DualSVMONNX-data.csv", string csv_header="") { df.cols = data.Cols(); df.rows = data.Rows(); if (df.cols == 0 || df.rows == 0) { Print(__FUNCTION__," data matrix invalid size "); return; } matrixf split_x; vectorf split_y; matrix_utils.XandYSplitMatrices(data, split_x, split_y); //since we are going to be normalizing the independent variable only we need to split the data into two normalize_x = new CPreprocessing<vectorf,matrixf>(split_x, NORM_MIN_MAX_SCALER); //Normalizing Independent variable only matrixf new_data = split_x; new_data.Resize(data.Rows(), data.Cols()); new_data.Col(split_y, data.Cols()-1); if (csv_header == "") { for (ulong i=0; i<df.cols; i++) csv_header += "COLUMN "+string(i+1) + (i==df.cols-1 ? "" : ","); //do not put delimiter on the last column } //--- Save the Normalization parameters also matrixf params = {}; string sep=","; ushort u_sep; string result[]; u_sep=StringGetCharacter(sep,0); int k=StringSplit(csv_header,u_sep,result); ArrayRemove(result, k-1, 1); //remove the last column header since we do not have normalization parameters for the target variable as it is not normalized normalize_x.min_max_scaler.min.Swap(params); matrix_utils.WriteCsv("min_max_scaler.min.csv",params,result,false,8); normalize_x.min_max_scaler.max.Swap(params); matrix_utils.WriteCsv("min_max_scaler.max.csv",params,result,false,8); //--- matrix_utils.WriteCsv(csv_name, new_data, csv_header, false, 8); //Save dataset to a csv file }
訓練のためのデータ収集は1回に1回おこなう必要があるため、スクリプトの中ほどデータを収集するのに適した場所はありません。
GetDataforONNX.mq5スクリプト内
#include <MALE5\Support Vector Machine(SVM)\svm.mqh> CDualSVMONNX dual_svm; input uint bars = 1000; input uint epochs_ = 1000; input uint batch_size_ = 64; input double alpha__ =0.1; input double lambda_ = 0.01; input int rsi_period = 13; input int bb_period = 20; input double bb_deviation = 2.0; int rsi_handle, bb_handle; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { rsi_handle = iRSI(Symbol(),PERIOD_CURRENT,rsi_period, PRICE_CLOSE); bb_handle = iBands(Symbol(), PERIOD_CURRENT, bb_period,0, bb_deviation, PRICE_CLOSE); //--- matrixf data = GetTrainTestData<float>(); dual_svm.SendDataToONNX(data,"DualSVMONNX-data.csv","rsi,bb-high,bb-low,bb-mid,target"); } //+------------------------------------------------------------------+ //| Getting data for Training and Testing the model | //+------------------------------------------------------------------+ template <typename T> matrix<T> GetTrainTestData() { matrix<T> data(bars, 5); vector<T> v; //Temporary vector for storing Inidcator buffers v.CopyIndicatorBuffer(rsi_handle, 0, 0, bars); data.Col(v, 0); v.CopyIndicatorBuffer(bb_handle, 0, 0, bars); data.Col(v, 1); v.CopyIndicatorBuffer(bb_handle, 1, 0, bars); data.Col(v, 2); v.CopyIndicatorBuffer(bb_handle, 2, 0, bars); data.Col(v, 3); vector open, close; open.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_OPEN, 0, bars); close.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_CLOSE, 0, bars); for (ulong i=0; i<v.Size(); i++) //preparing the independent variable data[i][4] = close[i] > open[i] ? 1 : -1; // if price closed above its opening thats bullish else bearish return data; }
出力
DualSVMONNX-data.csvという名前のcsvファイルがMQL5ディレクトリFilesの下に作成されました。
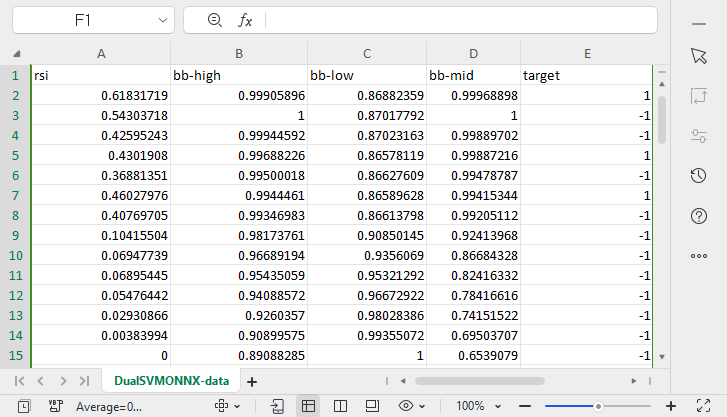
関数SendDataToONNXの最後
正規化のパラメータも保存しました
normalize_x.min_max_scaler.min.Swap(params); matrix_utils.WriteCsv("min_max_scaler.min.csv",params,result,false,8); normalize_x.min_max_scaler.max.Swap(params); matrix_utils.WriteCsv("min_max_scaler.max.csv",params,result,false,8);
これは、モデルから最良の予測を得るために、一度使用した正規化パラメーターを再度使用する必要があるためです。これらを保存すると、データ正規化パラメーター値を追跡するのに役立ちます。CSV ファイルは、次のフォルダーと同じフォルダーにあります。 データセットを保存し、ONNX モデルもそこに保持します。
DualSVMONNXクラスインスタンス|クラスの初期化
class DualSVMONNX: def __init__(self, dataset, c=1.0, kernel='rbf'): data = pd.read_csv(dataset) # reading a csv file np.random.seed(42) self.X = data.drop(columns=['target']).astype(np.float32) # dropping the target column from independent variable self.y = data["target"].astype(int) # storing the target variable in its own vector self.X = self.X.to_numpy() self.y = self.y.to_numpy() # Split the data into training and testing sets self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(self.X, self.y, test_size=0.2, random_state=42) self.onnx_model_name = "DualSVMONNX" #our final onnx model file name for saving purposes really # Create a dual SVM model with a kernel self.svm_model = SVC(kernel=kernel, C=c)
pythonによるデュアルSVMモデルの訓練
def fit(self): self.svm_model.fit(self.X_train, self.y_train) # fitting/training the model y_preds = self.svm_model.predict(self.X_train) print("accuracy = ",accuracy_score(self.y_train, y_preds))
モデルの学習が完了したら、このコードスニペットを実行した後の精度を確認してみましょう。
出力

精度は63%で、この問題を分類するSVMモデルはよくても平均的なものであることがわかりました。しかし、精度が本来のものであるかどうかを証明するために、交差検証を実行させてください。
scores = cross_val_score(self.svm_model, self.X_train, self.y_train, cv=5) mean_cv_accuracy = np.mean(scores) print(f"\nscores {scores} mean_cv_accuracy {mean_cv_accuracy}")
出力

この交差検証の結果は何を意味するのでしょうか。
モデルを異なるパラメータで実行した場合、結果の間に大きなばらつきはありません。これは、モデルが正しい軌道に乗っていることを示しています。得られる平均精度は59.875で、得られた63.3からそれほど遠くありません。
SVCモデルをsklearnからONNXに変換して保存する
def saveONNX(self):
initial_type = [('float_input', FloatTensorType(shape=[None, 4]))] # None means we don't know the rows but we know the columns for sure, Remember !! we have 4 independent variables
onnx_model = convert_sklearn(self.svm_model, initial_types=initial_type) # Convert the scikit-learn model to ONNX format
onnx.save_model(onnx_model, dataset_path + f"\\{self.onnx_model_name}.onnx") #saving the onnx model 出力:NB:モデルはMQL5/Filesディレクトリに保存されています。
以下は、ONNXファイルをMetaEditorで開いたときの様子です。これから説明することに注意を払うことが重要です。

入力セクションを見てください。float_inputは、これがfloat型の入力であることを説明します。その隣にはテンソルがあり、どちらもテンソルであるため、OnnxRun関数に行列またはベクトルを与える必要がある可能性があることを示しています。最後に(?, 4)がありますが、これは入力サイズです。疑問符は行数が不明であることを表しますが、列数は4です。これは残りのセクションに当てはまりますが、出力セクションが示されています。
2つのノードがあります。1つは予測されたラベル(-1または1)を与えるもので、この場合これらはINT64型、またはMQL5では単にINTです。
確率を与えるもう1つのノードはfloat型のテンソルです。行は未知数ですが列は2つあるので、nx2の行列を使用して値を抽出することができます。
出力には2つのノードがあるので、出力を2回抽出することができます。
long outputs_0[] = {1}; if (!OnnxSetOutputShape(onnx_handle, 0, outputs_0)) //giving the onnx handle first node output shape { Print(__FUNCTION__," Failed to set the output shape Err=",GetLastError()); return false; } long outputs_1[] = {1,2}; if (!OnnxSetOutputShape(onnx_handle, 1, outputs_1)) //giving the onnx handle second node output shape { Print(__FUNCTION__," Failed to set the output shape Err=",GetLastError()); return false; }
一方、私たちが持っている1つの入力ノードを抽出することができます。
const long inputs[] = {1,4}; if (!OnnxSetInputShape(onnx_handle, 0, inputs)) //Giving the Onnx handle the input shape { Print(__FUNCTION__," Failed to set the input shape Err=",GetLastError()); return false; }
このONNXコードは、以下に示すLoadONNX関数から抽出したものです。
bool CDualSVMONNX::LoadONNX(const uchar &onnx_buff[], ENUM_ONNX_FLAGS flags=ONNX_NO_CONVERSION) { onnx_handle = OnnxCreateFromBuffer(onnx_buff, flags); //creating onnx handle buffer if (onnx_handle == INVALID_HANDLE) { Print(__FUNCTION__," OnnxCreateFromBuffer Error = ",GetLastError()); return false; } //--- const long inputs[] = {1,4}; if (!OnnxSetInputShape(onnx_handle, 0, inputs)) //Giving the Onnx handle the input shape { Print(__FUNCTION__," Failed to set the input shape Err=",GetLastError()); return false; } long outputs_0[] = {1}; if (!OnnxSetOutputShape(onnx_handle, 0, outputs_0)) //giving the onnx handle first node output shape { Print(__FUNCTION__," Failed to set the output shape Err=",GetLastError()); return false; } long outputs_1[] = {1,2}; if (!OnnxSetOutputShape(onnx_handle, 1, outputs_1)) //giving the onnx handle second node output shape { Print(__FUNCTION__," Failed to set the output shape Err=",GetLastError()); return false; } return true; }
関数をよく見てみると、新しい入力データを標準化し、モデルがすでに慣れ親しんでいる学習済みデータの次元と一致させるために重要な、正規化パラメータの読み込みが欠けていることに気づかれるかもしれません。
CSVファイルからパラメータを読み込めば、ライブ取引中にスムーズに動作します。ただし、この方法は複雑になる可能性があり、ストラテジーテスターにとって必ずしも効果的に機能するとは限りません。少なくとも現時点では、正規化パラメータをEAコードに手動でコピーして、最終的にEA内に正規化パラメータが残るようにしましょう。まず、LoadONNX関数を修正して、MinMaxScalerで大きな役割を果たす入力ベクトルmaxとminを受け取るようにしましょう。
bool CDualSVMONNX::LoadONNX(const uchar &onnx_buff[], ENUM_ONNX_FLAGS flags, vectorf &norm_max, vectorf &norm_min)
紹介した関数の最後には次があります。
normalize_x = new CPreprocessing<vectorf,matrixf>(norm_max, norm_min); //Load min max scaler with parameters
CSVファイルからEAへの正規化パラメータのコピー&ペースト
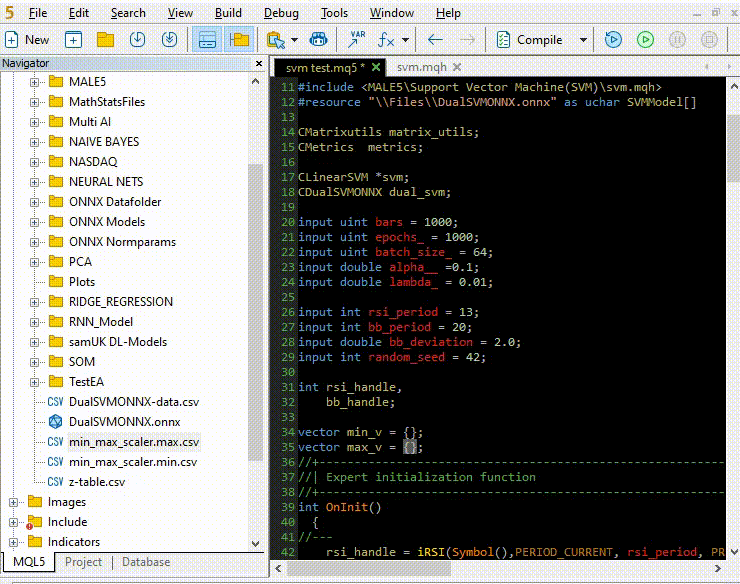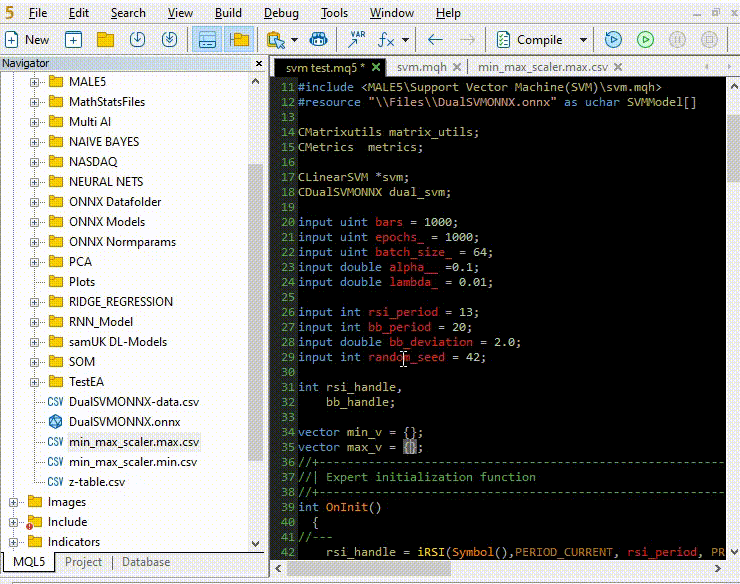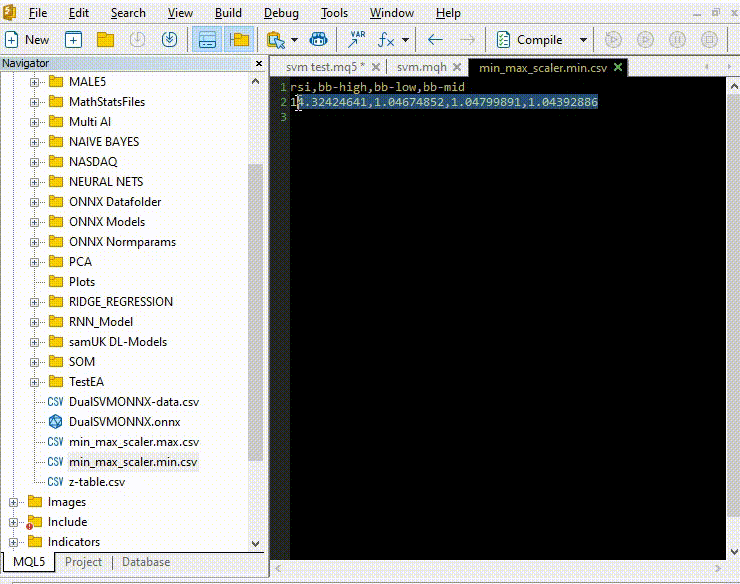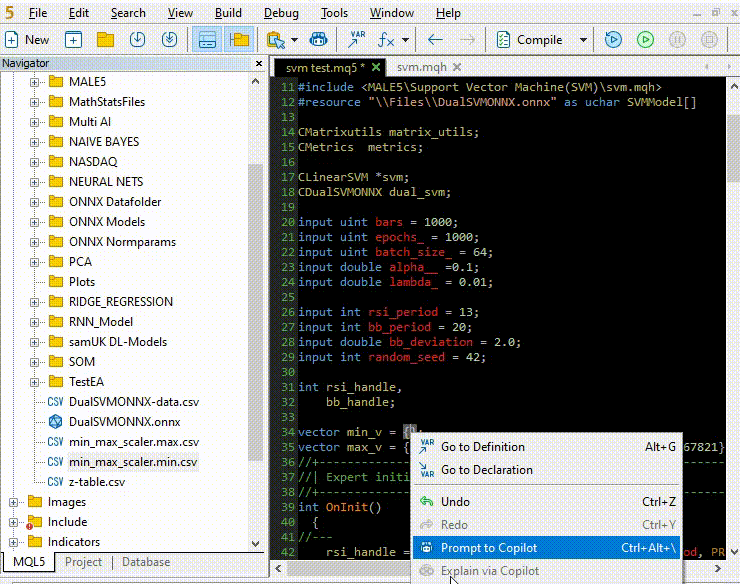
Pythonを使ったときと同じ方法でモデルを訓練し、テストしてみましょう。目的は、どちらの言語でも同じ道を歩んでいることを確認することです。
svmtest.mq5のOnInit関数内
vector min_v = {14.32424641,1.04674852,1.04799891,1.04392886}; vector max_v = {86.28263092,1.07385755,1.07907069,1.07267821}; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- rsi_handle = iRSI(Symbol(),PERIOD_CURRENT, rsi_period, PRICE_CLOSE); bb_handle = iBands(Symbol(), PERIOD_CURRENT, bb_period, 0 , bb_deviation, PRICE_CLOSE); vector y_train, y_test; // float values matrixf datasetf = GetTrainTestData<float>(); matrixf x_trainf, x_testf; vectorf y_trainf, y_testf; //--- matrix_utils.TrainTestSplitMatrices(datasetf,x_trainf,y_trainf,x_testf,y_testf,0.8,42); //split the data into training and testing samples vectorf max_vf = {}, min_vf = {}; //convertin the parameters into float type max_vf.Assign(max_v); min_vf.Assign(min_v); dual_svm.LoadONNX(SVMModel, ONNX_DEFAULT, max_vf, min_vf); y_train.Assign(y_trainf); y_test.Assign(y_testf); vector train_preds = dual_svm.Predict(x_trainf); vector test_preds = dual_svm.Predict(x_testf); Print("\n<<<<< Train Classification Report >>>>\n"); metrics.confusion_matrix(y_train, train_preds); Print("\n<<<<< Test Classification Report >>>>\n"); metrics.confusion_matrix(y_test, test_preds); return(INIT_SUCCEEDED); }出力
RP 0 17:08:53.068 svm test (EURUSD,H1) <<<<< Train Classification Report >>>> HE 0 17:08:53.068 svm test (EURUSD,H1) MR 0 17:08:53.068 svm test (EURUSD,H1) Confusion Matrix IG 0 17:08:53.068 svm test (EURUSD,H1) [[245,148] CO 0 17:08:53.068 svm test (EURUSD,H1) [150,257]] NK 0 17:08:53.068 svm test (EURUSD,H1) DE 0 17:08:53.068 svm test (EURUSD,H1) Classification Report HO 0 17:08:53.068 svm test (EURUSD,H1) FI 0 17:08:53.068 svm test (EURUSD,H1) _ Precision Recall Specificity F1 score Support ON 0 17:08:53.068 svm test (EURUSD,H1) 1.0 0.62 0.62 0.63 0.62 393.0 DP 0 17:08:53.068 svm test (EURUSD,H1) -1.0 0.63 0.63 0.62 0.63 407.0 JG 0 17:08:53.068 svm test (EURUSD,H1) FR 0 17:08:53.068 svm test (EURUSD,H1) Accuracy 0.63 CK 0 17:08:53.068 svm test (EURUSD,H1) Average 0.63 0.63 0.63 0.63 800.0 KI 0 17:08:53.068 svm test (EURUSD,H1) W Avg 0.63 0.63 0.63 0.63 800.0 PP 0 17:08:53.068 svm test (EURUSD,H1) DH 0 17:08:53.068 svm test (EURUSD,H1) <<<<< Test Classification Report >>>> PQ 0 17:08:53.068 svm test (EURUSD,H1) EQ 0 17:08:53.068 svm test (EURUSD,H1) Confusion Matrix HJ 0 17:08:53.068 svm test (EURUSD,H1) [[61,31] MR 0 17:08:53.068 svm test (EURUSD,H1) [40,68]] NH 0 17:08:53.068 svm test (EURUSD,H1) DP 0 17:08:53.068 svm test (EURUSD,H1) Classification Report HL 0 17:08:53.068 svm test (EURUSD,H1) FF 0 17:08:53.068 svm test (EURUSD,H1) _ Precision Recall Specificity F1 score Support GJ 0 17:08:53.068 svm test (EURUSD,H1) -1.0 0.60 0.66 0.63 0.63 92.0 PO 0 17:08:53.068 svm test (EURUSD,H1) 1.0 0.69 0.63 0.66 0.66 108.0 DD 0 17:08:53.068 svm test (EURUSD,H1) JO 0 17:08:53.068 svm test (EURUSD,H1) Accuracy 0.65 LH 0 17:08:53.068 svm test (EURUSD,H1) Average 0.65 0.65 0.65 0.64 200.0 CJ 0 17:08:53.068 svm test (EURUSD,H1) W Avg 0.65 0.65 0.65 0.65 200.0
Pythonスクリプトで得たのと同じ63%の精度を得ました。素晴らしいです。
予測関数の内部はこのようになっています。
int CDualSVMONNX::Predict(vectorf &inputs) { vectorf outputs(1); //label outputs vectorf x_output(2); //probabilities vectorf temp_inputs = inputs; normalize_x.Normalization(temp_inputs); //Normalize the input features if (!OnnxRun(onnx_handle, ONNX_DEFAULT, temp_inputs, outputs, x_output)) { Print("Failed to get predictions from onnx Err=",GetLastError()); return (int)outputs[0]; } return (int)outputs[0]; }
予測値を得るためにONNXファイルを実行し、予測されたラベルを整数で返します。
最後に、ストラテジーテスターでサポートベクターマシンの両モデルをテストできるように、簡単なストラテジーを実装しなければなりませんでした。戦略は単純で、SVMによって予測されたクラスが==1であれば買い取引を開始し、そうでなければ予測されたクラスが==-1であれば売り取引を開始します。
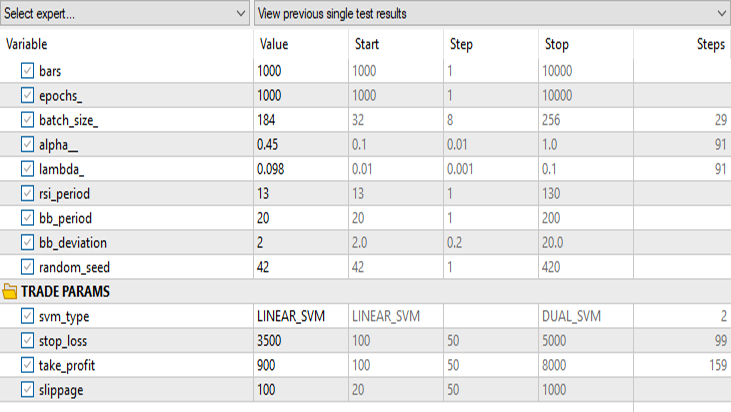
ストラテジーテスターでの結果は次の通りです。
線形サポートベクターマシンの場合
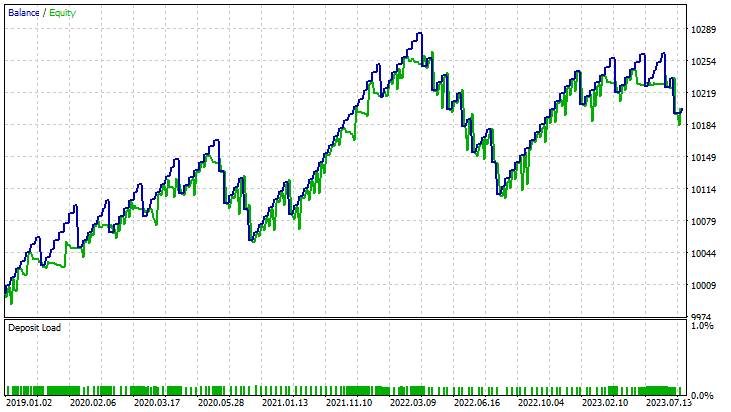
デュアルサポートベクターマシンの場合
svm_type以外の入力は同じにします。
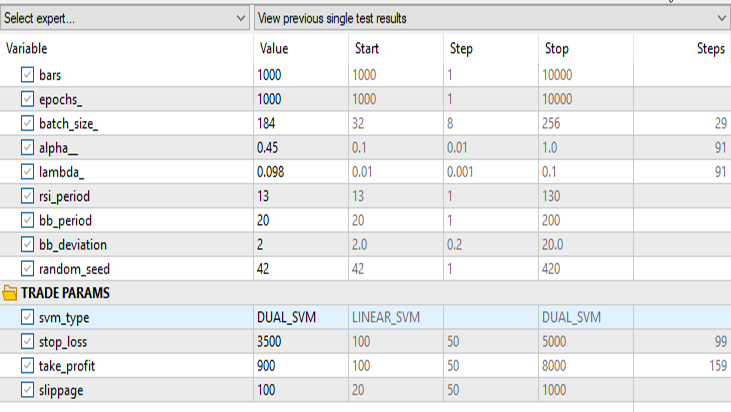
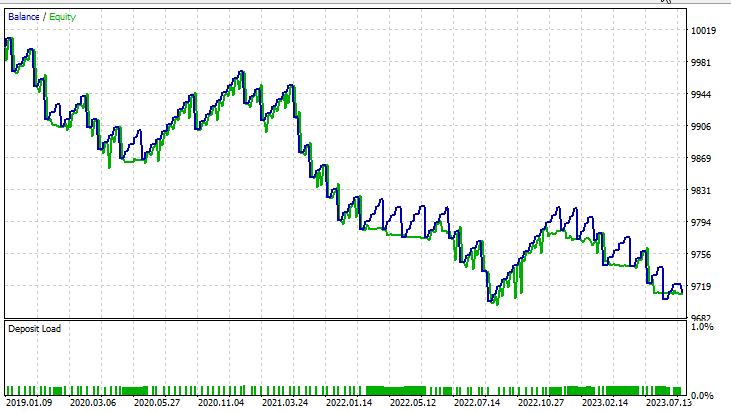
デュアルSVMは、線形SVMで機能した入力ではうまく機能しませんでした。さらに最適化する必要があるかもしれないし、ONNXモデルが収束しなかった理由を探る必要があるかもしれませんが、それはまた別の記事で。
最後に
SVMモデルの利点
- 高次元空間で効果的:SVMは高次元空間において優れた性能を発揮するため、取引指標や市場変数のような多数の特徴を持つ金融データセットに適しています。
- 過学習に強い:SVMは過学習を起こしにくいため、より一般化されたソリューションを提供し、未知の市場状況によりよく適応することができます。
- カーネルの多様性:SVMはさまざまなカーネル関数を通じて汎用性を提供するため、トレーダーはさまざまな戦略を試し、特定の市場パターンにモデルを適応させることができます。
- 非線形シナリオにおける強力なパフォーマンス:SVMは、データ内の非線形関係を捉えることに優れており、複雑な金融市場を扱う際には極めて重要な要素です。
短所
- ノイズに対する感度:SVMはノイズの多いデータに敏感に反応し、その性能に影響を与え、不安定な市場行動の影響を受けやすくなります。
- 計算複雑性:SVMモデルの訓練は、特に大規模なデータセットの場合、計算コストが高くなる可能性があり、特定のリアルタイム取引シナリオにおけるスケーラビリティが制限されます。
- 質の高い特徴量エンジニアリングの必要性:SVMは特徴量エンジニアリングに大きく依存しており、関連する指標を選択し、データを効果的に前処理するためには、領域の専門知識が必要です。
- 平均的なパフォーマンス:これまで見てきたように、SVMモデルはデュアルSVMで63%、線形SVMで59%という平均的な精度を達成しました。これらのモデルは高度な機械学習技術を凌駕するものではありませんが、それでもMQL5トレーダーにとっては合理的な出発点となります。
人気の低下
その歴史的な成功にもかかわらず、SVMの人気は近年低下しています。これは次のような理由によるものです。
- ディープラーニングの出現:ディープラーニング(深層学習)技術、特にニューラルネットワークの台頭は、階層的特徴を自動的に抽出する能力により、SVMのような従来の機械学習アルゴリズムの影を落としています。
- データの利用可能性の向上:膨大な金融データセットの利用可能性が高まるにつれ、大量のデータを得意とするディープラーニングモデルがより魅力的になってきています。
- 計算の進歩:強力なハードウェアと分散コンピューティングリソースが利用可能になったことで、複雑なディープラーニングモデルの学習と導入がより現実的になっています。
結論として、SVMモデルは最先端のソリューションではないかもしれませんが、MQL5の取引環境での使用は正当化されます。その単純さ、頑健さ、適応性から、特にデータや計算資源が限られているトレーダーにとっては、貴重なツールとなります。トレーダーは、SVMをより幅広いツールキットの一部として考えることが不可欠であり、市場の力学が進化するにつれて、より新しい機械学習アプローチでSVMを補完する可能性があります。
ご精読ありがとうございました。
| ファイル | 説明|使用法 |
|---|---|
| dual_svm.py|pythonスクリプト | PythonによるDualSVMの実装があります。 |
| GetDataforONNX.mq5|mql5スクリプト | MQL5/Filesの下にあるcsvファイルにデータを収集、正規化、保存するために使用できます。 |
| 前処理.mqh|mql5インクルードファイル | 入力データの正規化と標準化のためのクラスと関数を含む。 |
| matrix_utils.mqh|mql5インクルードファイル | 行列演算を追加したライブラリ |
| metrics.mqh|mql5インクルードファイル | MLモデルの性能を分析するための追加関数を含むライブラリ |
| svmtest.mq5|EA | 記事にあるすべてのコードをテストするためのエキスパートアドバイザー |
この記事で使用したコードは、私のリポジトリにもある。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/13395
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索