
データサイエンスとML(第36回):偏った金融市場への対処

内容
- はじめに
- 機械学習における不均衡なターゲット変数の欠点
- 不均衡なデータセットの問題に対処する技術
- 適切な評価指標の選択
- テスト用エキスパートアドバイザー(EA)
- オーバーサンプリング手法
- アンダーサンプリング手法
- ハイブリッド手法
- 結論
はじめに
為替市場やその他の金融商品は、時期によってさまざまな動きを見せます。たとえば、株式や株価指数などの一部の金融市場は長期的には上昇傾向(ブル相場)を示すことが多い一方で、為替市場のように下降傾向(ベア相場)やさらに複雑な挙動を示す市場もあります。こうした不確実性は、人工知能(AI)技術や機械学習(ML)モデルを用いて市場を予測しようとする際に、予測の難しさをさらに高める要因となります。

いくつかの金融市場(取引銘柄)を取り上げ、日足で直近1000本のローソク足の方向性を可視化してみましょう。もしローソク足の終値が始値より高ければ、その足は強気(ブル)と判断して「1」とラベル付けし、そうでなければ弱気(ベア)として「0」とラベル付けします。
import pandas as pd import numpy as np symbols = [ "EURUSD", "USTEC", "XAUUSD", "USDJPY", "BTCUSD", "CA60", "UK100" ] for symbol in symbols: df = pd.read_csv(fr"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\1640F6577B1C4EC659BF41EA9F6C38ED\MQL5\Files\{symbol}.PERIOD_D1.data.csv") df["Candle type"] = (df["Close"] > df["Open"]).astype(int) print(f"{symbol}(unique):",np.unique(df["Candle type"], return_counts=True))
結果
EURUSD(unique): (array([0, 1]), array([496, 504])) USTEC(unique): (array([0, 1]), array([472, 528])) XAUUSD(unique): (array([0, 1]), array([472, 528])) USDJPY(unique): (array([0, 1]), array([408, 592])) BTCUSD(unique): (array([0, 1]), array([478, 522])) CA60(unique): (array([0, 1]), array([470, 530])) UK100(unique): (array([0, 1]), array([463, 537]))
上の結果からも分かるように、どの取引銘柄も完全にバランスが取れているわけではなく、過去のデータを見ると強気のローソク足と弱気のローソク足の数に偏りがあります。
市場が特定の方向に偏ること自体は問題ではありませんが、このような偏った履歴データを使って機械学習モデルを訓練する場合、いくつかの問題が生じます。具体的には以下のようになります。
たとえば、現在のデータセットに基づいてUSDJPYでモデルを訓練しようとするとしましょう。このデータセットには1000本のローソク足が含まれており、そのうち408本(40.8%)が弱気(ラベル0)、592本(59.2%)が強気(ラベル1)です。
このように、強気のシグナルが弱気のシグナルよりも多く存在する場合、機械学習モデルはしばしばこの不均衡を無視し、より優勢なクラスに偏った予測をおこなう傾向があります。
これは、モデルができるだけ損失を小さくし、精度(Accuracy)を最大化しようとするためであり、その結果、59.2%の確率で出現している強気クラスに偏った予測をおこなってしまうのです。
これは決して難しい話ではありません。この単純な情報だけを使って、市場の動向や指標を一切考慮せず、「USDJPYのすべてのバーは常に強気になる」と予測した場合、約59.2%の確率で正解してしまうのです。悪くないと思うかもしれませんが、 それは誤りです。
なぜなら、これは過去に起きたことは将来も同じように起きると仮定していることになります。これは、取引の世界ではそれは極めて危険で、完全に間違った考え方です。
このように、分類問題においてターゲット変数が不均衡であることは、機械学習において重大な課題を引き起こします。以下では、この不均衡によって生じる主な問題点について紹介します。
機械学習におけるターゲット変数の不均衡による問題点
- 少数クラスの予測性能が低下する
先ほど述べたように、モデルは全体の精度を最適化しようとするため、多数派クラスに偏った予測をおこなう傾向があります。たとえば、詐欺検出のデータにおいて「99%が非詐欺、1%が詐欺」のような場合、ほとんどの人が詐欺をしないため、モデルは常に「非詐欺」と予測しても99%の精度を達成できます。しかし、このようなモデルは本来の目的である詐欺の検出に失敗してしまいます。 - 誤解を招く評価指標
精度は信頼できない指標になることがあります。たとえば、モデル全体で72%の精度があるように見えても、あるクラスでは95%、別のクラスでは50%しか正解できていない可能性があります。 - 多数派クラスへのモデルの過剰適合
モデルが多数派クラスのノイズを記憶してしまい、特徴量に含まれる本質的なパターンを学習できなくなることがあります。たとえば、医療診断のデータにおいて「95%が健康、5%が疾患あり」のような場合、モデルは疾患の予測を完全に無視する可能性があります。 - 未知の(実世界の)データに対する汎化性能が低い
現実のデータ分布は常に変化します。もしモデルが偏ったデータセットで訓練されている場合、実際の運用環境では高い確率で性能が崩れ、信頼性が低下します。これは、訓練時に現実的ではないバランスで学習されているためです。
不均衡なデータセットへの対処法
分類問題においてターゲット変数が不均衡(偏っている)である場合に発生する問題について理解したところで、次はこの問題に対処するためのさまざまな手法を見ていきましょう。
01:適切な評価指標の選定
不均衡データを扱ううえでの最初のステップは、適切な評価指標を選ぶことです。先ほどの問題点でも述べたように、分類器の精度、つまり「正しく予測した件数 ÷ 総予測件数」は、不均衡なデータセットにおいては誤解を招くことがあります。
不均衡なデータ問題では、分類器があるクラスをどれだけ正確に予測できているかを示す適合率(precision)や、あるクラスをどれだけ正しく検出できたかを示す再現率(recall)などの指標の方が、精度よりもはるかに有用です。
不均衡なデータセットを扱う際、ほとんどの機械学習の専門家はF1スコアを使用します。
F1スコアは適合率(precision)と再現率(recall)の調和平均であり、以下の数式で表されます。

もし分類器が少数クラスを予測したとしても、その予測が誤っており偽陽性が増えると、適合率(precision)は低くなり、それに伴いF1スコアも低下します。
また、分類器が少数クラスを正しく識別できない場合、偽陰性が増加するため、再現率(recall)とF1スコアも低くなります。
F1スコアが向上するのは、予測件数や全体の予測品質が改善された場合のみです。
この点を詳しく理解するために、偏ったUSDJPYのデータを用いて、シンプルなランダムフォレスト分類器を訓練してみましょう。
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report # Global variables symbol = "USDJPY" timeframe = "PERIOD_D1" lookahead = 1 common_path = r"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\Common\Files" df = pd.read_csv(f"{common_path}\{symbol}.{timeframe}.data.csv") # Target variable df["future_close"] = df["Close"].shift(-lookahead) # future closing price based on lookahead value df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) print("Signals(unique): ",np.unique(df["Signal"], return_counts=True)) X = df.drop(columns=["Signal", "future_close"]) y = df["Signal"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=False) model = RandomForestClassifier(n_estimators=100, max_depth=5, min_samples_split=3, random_state=42) model.fit(X_train, y_train)
訓練が完了したら、モデルをONNX形式で保存し、後でMetaTrader 5で使用できるようにします。
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType import os def saveModel(model, n_features: int, technique_name: str): initial_type = [("input", FloatTensorType([None, n_features]))] onnx_model = convert_sklearn(model, initial_types=initial_type, target_opset=14) with open(os.path.join(common_path, f"{symbol}.{timeframe}.{technique_name}.onnx"), "wb") as f: f.write(onnx_model.SerializeToString())
saveModel(model=model, n_features=X_train.shape[1], technique_name="no-sampling")
Scikit-Learnに含まれるclassification_reportメソッドを使って、さまざまな評価指標を確認しました。
Train Classification report precision recall f1-score support 0 0.98 0.41 0.57 158 1 0.68 1.00 0.81 204 accuracy 0.74 362 macro avg 0.83 0.70 0.69 362 weighted avg 0.81 0.74 0.71 362
Train Classification reportの分析
モデルの全体的な訓練精度は0.74で、一見するとまずまずのように見えます。しかし、クラスごとの指標を詳しく見ると、モデルの性能に大きな偏りがあることがわかります。クラス0は非常に高い適合率0.98を示す一方で、再現率が0.41と低く、その結果F1スコアは0.57と控えめな値になっています。
これは、モデルがクラス0と予測するときには非常に自信を持っているものの、実際のクラス0のサンプルを多く見逃してしまっている、つまり感度が低いことを示しています。
一方、クラス1は再現率が1.00と完璧で、F1スコアも0.81と高いですが、適合率は0.68とやや低めです。
これは、モデルがクラス1を過剰に予測していることを示唆しており、多くの偽陽性を生んでいる可能性があります。
クラス1の再現率が1.00というのは非常に注意が必要で、過学習や多数派クラスへの偏りを示している可能性があります。
モデルはほぼすべてをクラス1と予測しており、多数のクラス0のサンプルを見逃していることが、クラス0の低い再現率である0.41からも明らかです。
これらの指標は、不均衡があるだけでなく、モデルの汎化能力やクラス間の公平性にも問題があることを示しています。明らかに何かがおかしい状況です。
そこで、オーバーサンプリング手法を用いてモデルを改善し、よりバランスの取れた予測を目指しましょう。
テスト用エキスパートアドバイザー(EA)
上記の分類レポートのような機械学習モデル分析結果と、MetaTrader 5からの実際の取引結果の間には常に違いがあります。今後の活用に備えてモデルをONNX形式で保存するために、この記事で紹介した各リサンプリング手法で訓練されたモデルを取得し、それを用いてストラテジーテスター上で取引判断をおこなうシンプルな自動売買ロボットを作成することができます。
使用されたデータは、Collectdata.mq5というファイル内で収集されました。このスクリプトは、2025年1月1日から遡って、2023年1月1日までの訓練データを取得します。このスクリプトは、この記事の添付ファイルから入手できます。
Test Resampling Techniques.mq5という名前のEA内で、モデルをONNX形式で初期化し、それを使用して予測をおこないます。
#include <Random Forest.mqh> CRandomForestClassifier random_forest; //A class for loading the RFC in ONNX format #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> CTrade m_trade; CPositionInfo m_position; input string symbol_ = "USDJPY"; input int magic_number= 14042025; input int slippage = 100; input ENUM_TIMEFRAMES timeframe_ = PERIOD_D1; input string technique_name = "randomoversampling"; int lookahead = 1; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!random_forest.Init(StringFormat("%s.%s.%s.onnx", symbol_, EnumToString(timeframe_), technique_name), ONNX_COMMON_FOLDER)) //Initializing the RFC in ONNX format from a commmon folder return INIT_FAILED; //--- Setting up the CTrade module m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(symbol_); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- vector x = { iOpen(symbol_, timeframe_, 1), iHigh(symbol_, timeframe_, 1), iLow(symbol_, timeframe_, 1), iClose(symbol_, timeframe_, 1) }; long signal = random_forest.predict_bin(x); //Predicted class double proba = random_forest.predict_proba(x).Max(); //Maximum predicted probability MqlTick ticks; if (!SymbolInfoTick(symbol_, ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(symbol_, SYMBOL_VOLUME_MIN); if (signal == 1) { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, symbol_, ticks.ask,0,0); } if (signal == 0) { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, symbol_, ticks.bid,0,0); } //--- CloseTradeAfterTime((Timeframe2Minutes(timeframe_)*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool PosExists(ENUM_POSITION_TYPE type) { for (int i=PositionsTotal()-1; i>=0; i--) if (m_position.SelectByIndex(i)) if (m_position.Symbol()==symbol_ && m_position.Magic() == magic_number && m_position.PositionType()==type) return (true); return (false); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool ClosePos(ENUM_POSITION_TYPE type) { for (int i=PositionsTotal()-1; i>=0; i--) if (m_position.SelectByIndex(i)) if (m_position.Symbol() == symbol_ && m_position.Magic() == magic_number && m_position.PositionType()==type) { if (m_trade.PositionClose(m_position.Ticket())) return true; } return (false); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CloseTradeAfterTime(int period_seconds) { for (int i = PositionsTotal() - 1; i >= 0; i--) if (m_position.SelectByIndex(i)) if (m_position.Magic() == magic_number) if (TimeCurrent() - m_position.Time() >= period_seconds) m_trade.PositionClose(m_position.Ticket(), slippage); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int Timeframe2Minutes(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return 1; case PERIOD_M2: return 2; case PERIOD_M3: return 3; case PERIOD_M4: return 4; case PERIOD_M5: return 5; case PERIOD_M6: return 6; case PERIOD_M10: return 10; case PERIOD_M12: return 12; case PERIOD_M15: return 15; case PERIOD_M20: return 20; case PERIOD_M30: return 30; case PERIOD_H1: return 60; case PERIOD_H2: return 120; case PERIOD_H3: return 180; case PERIOD_H4: return 240; case PERIOD_H6: return 360; case PERIOD_H8: return 480; case PERIOD_H12: return 720; case PERIOD_D1: return 1440; // 1 day = 1440 minutes case PERIOD_W1: return 10080; // 1 week = 7 * 1440 minutes case PERIOD_MN1: return 43200; // Approx. 1 month = 30 * 1440 minutes default: PrintFormat("Unknown timeframe: %d", tf); return 0; } }
先読み値1に基づいてターゲット変数でモデルを訓練したため、現在の時間枠で先読みバー数が経過した後に取引を終了する必要があります。そうすることで、モデルの予測期間に従って取引を保持および終了する際に、先読み値が尊重されることが効果的に保証されます。
リサンプリングされたデータで訓練されたモデルの取引結果を見る前に、リサンプリングされていない訓練データ(生データ)で訓練されたモデルの取引結果を観察してみましょう。
テスターの構成
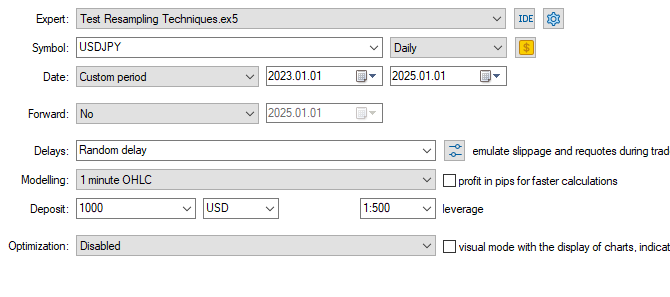
入力:technique_name = no-sampling
テスターの結果
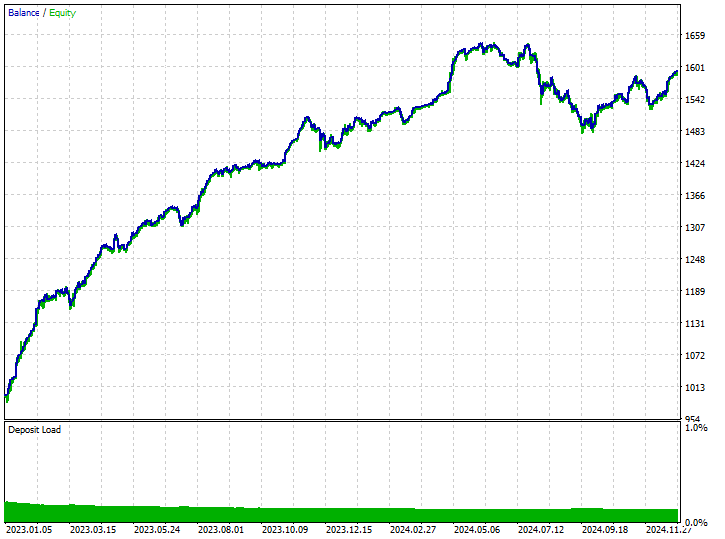
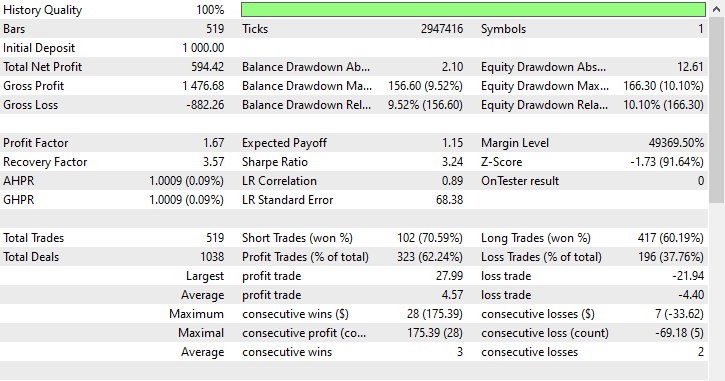
モデルはいくつかの良好なシグナルを拾い上げ、印象的な取引結果を出すことができ、全体的な収益性の高い取引はすべての取引の62.24%に達しました。ショート取引とロング取引の勝利数を見ると、比率が1:4であることがわかります。
おこなわれた519回の取引のうち102回はショートで、勝率は70.59%でした。一方、417回はロングで、勝率の精度は60.19%でした。2023年1月1日から2025年1月1日までのローソク足の方向を先読み値1に基づいて分析すると、明らかに何かがおかしいことがわかります。
print("classes in y: ",np.unique(y, return_counts=True))
結果
classes in y: (array([0, 1]), array([225, 293]))
225が弱気の価格変動で、293が強気の価格変動であったことがわかります。この2年間(2023年1月1日から2025年1月1日)にUSDJPYではほとんどのローソク足が強気方向に動いたため、強気の動きを支持するどんなひどいモデルでも利益を上げる可能性があります。そんなに難しいことではありません。
これで、モデルが利益を生み出した唯一の理由は、ショート取引よりもロング取引を4倍優先したためだということが分かります。
その期間中、市場は概ね強気だったため、ある程度の利益を上げることができました。
リサンプリング手法に進み、モデル内でこの偏った意思決定にどのように対処できるかを見てみましょう。
オーバーサンプリング手法
ランダムオーバーサンプリング
これは、データセット内のクラス不均衡に対処するための手法で、少数クラスのサンプルを人工的に増やすことで対応します。
具体的には、既存の少数クラスのデータをランダムに選び、それらを複製して学習データ内での存在比率を高めます。これにより、データセット内のクラス分布をバランス良く整えることが目的です。
このタスクで最も一般的に使用されるツールはimbalanced-learnです。以下にその基本的な使用方法を示します。
from imblearn.over_sampling import RandomOverSampler print("b4 Target: ",np.unique(y_train, return_counts=True)) rus = RandomOverSampler(random_state=42) X_resampled, y_resampled = rus.fit_resample(X_train, y_train) print("After Target: ",np.unique(y_resampled, return_counts=True))
出力
b4 Target: (array([0, 1]), array([304, 395])) After Target: (array([0, 1]), array([395, 395]))
リサンプリング後のデータを、先ほど使用したのと同じhttps://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.htmltitleRandomForestClassifier に再度適用し、リサンプリングをおこなわなかった場合と比べて結果にどのような違いがあるかを確認してみましょう。
model.fit(X_resampled, y_resampled)
モデルの評価
y_train_pred = model.predict(X_train) print("Train Classification report\n",classification_report(y_train, y_train_pred))
結果
Train Classification report precision recall f1-score support 0 0.82 0.85 0.83 158 1 0.88 0.86 0.87 204 accuracy 0.85 362 macro avg 0.85 0.85 0.85 362 weighted avg 0.85 0.85 0.85 362
素晴らしいことに、これらの結果はすべての評価指標において大きな改善が見られることを示しています。両クラスのF1スコアが0.87であることから、モデルが偏りなく一貫した予測をおこなっていることがわかります。これは、ターゲットクラス全体に対してモデルが健全な汎化能力を持ち、バランス良く学習できていることを示しています。
ただし、オーバーサンプリングはそのシンプルさと有効性にもかかわらず、少数クラスのデータを重複して生成することで過学習のリスクを高める可能性があります。これは、モデルに新たな情報を提供するとは限りません。
同じテスター構成を使用して、このデータで訓練されたモデルをストラテジーテスターで検証することができます。
入力:Technique_name = randomoversampling
テスターの結果
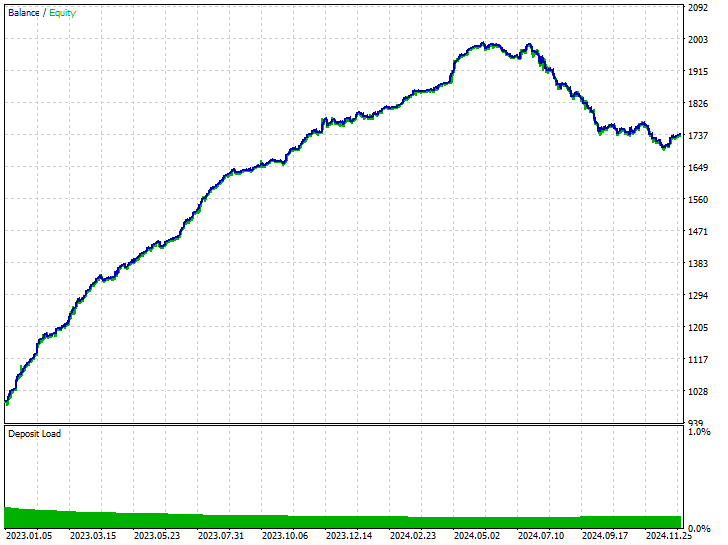
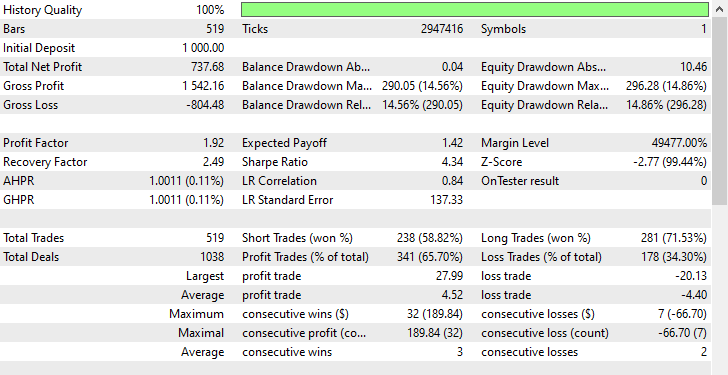
ご覧のとおり、すべてのトレード面で改善が見られ、このモデルは生のデータで訓練されたものよりもはるかに堅牢です。今回のモデルではショートポジションのエントリーが増え、それに伴ってロングポジションの数が大きく減少しました。
今回の訓練期間中、市場はターゲット変数の定義に従って、下落(ベア)方向に225回、上昇(ブル)方向に293回動いたとされます。一方で、このオーバーサンプリングによって訓練された新しいモデルは、238回のショート取引と281回のロング取引を実行しており、これはモデルが偏りなく、学習したパターンに基づいて意思決定をおこなっていることを示す良い兆候です。
アンダーサンプリング手法
Pythonのさまざまなモジュールには、アンダーサンプリングに利用できる手法がいくつか用意されています。いくつか例を挙げます。
ランダムアンダーサンプリング
これは、データセットのクラス不均衡に対処するための手法で、多数派クラスのサンプル数を減らすことで、少数派クラスとのバランスを取ります。
具体的には、多数派クラスからサンプルをランダムまたは戦略的に削除することで実現します。
オーバーサンプリングと同様に、このアンダーサンプリングも以下のような手順で適用することができます。
from imblearn.under_sampling import RandomUnderSampler print("b4 Target: ",np.unique(y_train, return_counts=True)) rus = RandomUnderSampler(random_state=42) X_resampled, y_resampled = rus.fit_resample(X_train, y_train) print("After Target: ",np.unique(y_resampled, return_counts=True))
結果
b4 Target: (array([0, 1]), array([304, 395])) After Target: (array([0, 1]), array([304, 304]))
ランダムアンダーサンプリングやその他のアンダーサンプリング手法は、多数派クラスの有益なサンプルを削除してしまうことで、訓練データの代表性を損ない、結果としてモデルの性能を低下させる可能性があります。このような場合、モデルが十分に学習できず、過小適合を引き起こすおそれがあります。
それでも、この手法は訓練データ上でのモデルのパフォーマンスを両クラスにおいて改善する結果となりました。
Train Classification report precision recall f1-score support 0 0.76 0.90 0.82 158 1 0.91 0.78 0.84 204 accuracy 0.83 362 macro avg 0.83 0.84 0.83 362 weighted avg 0.84 0.83 0.83 362
同じテスター構成を使用して、このデータで訓練されたモデルをストラテジーテスターで検証することができます。
入力:technique_name = randomundersampling
テスターの結果
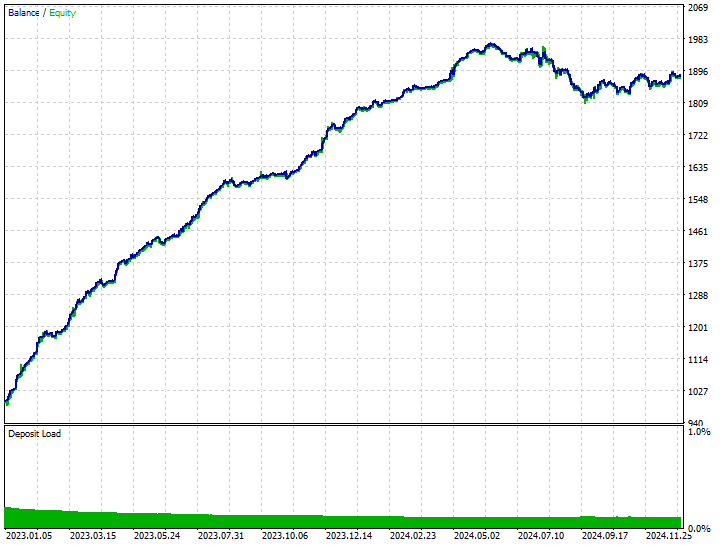
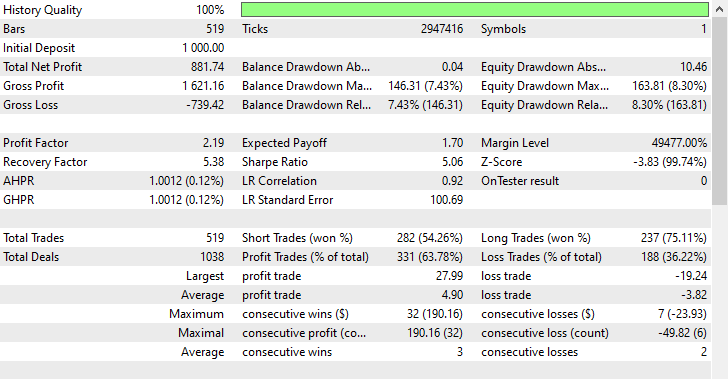
この手法によって、ショート取引が282回、ロング取引が237回実行されました。今回のモデルはロング取引よりもショート取引を好む傾向を示していますが、これは市場の実際の動きとは一致していませんでした。それでも、このモデルは、生のデータで訓練された偏りのあるモデルや、強気相場に偏った予測をしていたオーバーサンプリングモデルよりも高い利益を上げることができました。
このような結果からわかるのは、市場の過去の動きに関係なく、どちらの方向(上昇・下降)でも利益を上げることが可能であるということです。
トメックリンク
トメックリンクとは、異なるクラスに属しながらも非常に近い距離にあるインスタンス(データ点)のペアのことを指します。しばしば、互いに最も近い近傍同士になります。以下は、このトメックリンク手法が、アンダーサンプリングの文脈でどのように機能するかを簡単に説明したものです。
仮に、異なるクラスに属する2つの点AとBがあったとします。Aは多数派クラス、Bは少数派クラスに属しているとします(またはその逆でも構いません)。
もしこの2つの点AとBが非常に近い距離にある(つまり互いに近傍である)場合、多数派クラスに属する点(この場合はA)が削除されます。
この手法は、決定境界をきれいにし、クラス同士の境界をより明確にするのに役立ちます。また、同時に多数派クラスからいくつかのサンプルを削除することにもなります。
from imblearn.under_sampling import TomekLinks tl = TomekLinks() X_resampled, y_resampled = tl.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
出力
Before --> y (unique): (array([0, 1]), array([304, 395])) After --> y (unique): (array([0, 1]), array([304, 283]))
この手法は、モデルにおいて非常にバランスの取れた予測結果をもたらす可能性がありますが、二値分類に限定されるという制約があり、クラス間の重なりが大きいデータでは効果が薄くなることがあります。また、他のサンプリング手法と同様に、データの損失を招く可能性もあります。
それでも、この手法は訓練データ上でより良いパフォーマンスを示しました。
Train Classification report precision recall f1-score support 0 0.69 0.94 0.80 158 1 0.93 0.68 0.78 204 accuracy 0.79 362 macro avg 0.81 0.81 0.79 362 weighted avg 0.83 0.79 0.79 362
同じテスター構成を使用して、このデータで訓練されたモデルをストラテジーテスターで検証することができます。
入力:technique_name = tomek-links
テスターの結果

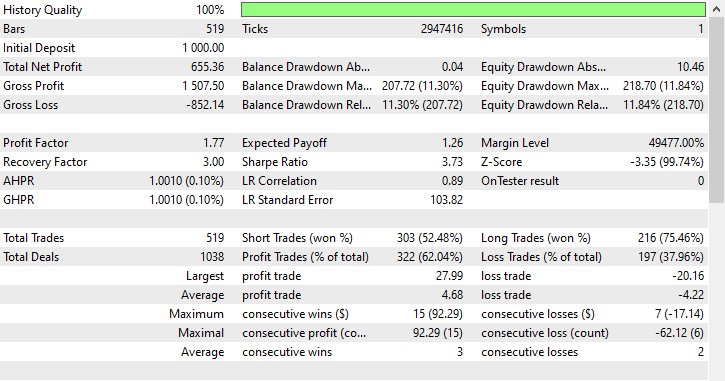
ランダムアンダーサンプリングと同様に、トメックリンクもショート取引を優先する傾向があり、303回のショート取引に対して216回のロング取引を実行しました。それでも利益を出すことができました。
クラスタ重心法
これはアンダーサンプリングの手法の一つで、多数派クラスのサンプルをクラスタの重心(通常はK-meansクラスタリングによって得られる)で置き換えることで多数派クラスのサイズを削減します。
動作は以下のとおりです。
- 多数派クラスに対してK平均クラスタリングを適用する。
- 望ましいサンプル数であるKを選択する。
- 多数派クラスのほとんどのサンプルを、K個のクラスタ中心点で置き換える。
- その結果と少数派クラスのサンプルを組み合わせて、バランスの取れたデータセットを作成する。
from imblearn.under_sampling import ClusterCentroids cc = ClusterCentroids(random_state=42) X_resampled, y_resampled = cc.fit_resample(X, y) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
出力
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([225, 225]))
以下は、クラスタ重心法によってアンダーサンプリングされたデータで訓練したモデルの結果です。
Train Classification report precision recall f1-score support 0 0.64 0.86 0.73 158 1 0.85 0.62 0.72 204 accuracy 0.73 362 macro avg 0.75 0.74 0.73 362 weighted avg 0.76 0.73 0.73 362
これまでのところ、この手法は最も低い精度値を示しています。0.73という値は、これまでのモデルよりも過学習が抑えられている可能性を示しており、その意味では現時点で最も優れたモデルである可能性もあります。
入力:Technique_name = cluster-centroids
テスターの結果
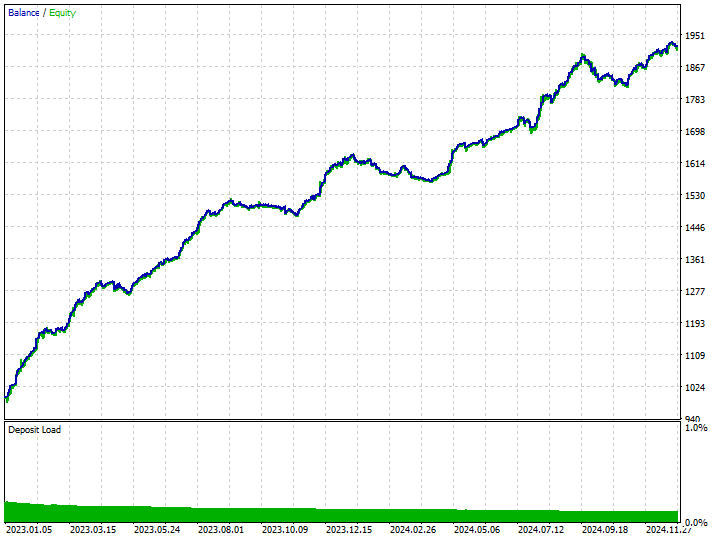
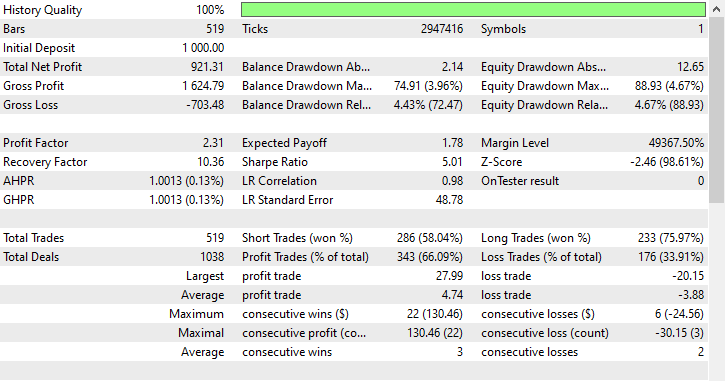
この手法は、519回のトレード中343回が利益となり、66.09%の精度を記録しました。利益は初期預金にほぼ達するほどで、非常に好成績でした。モデルはショート取引をやや多く好む傾向が見られましたが、強気(ロング)シグナルの予測精度が非常に高く、勝率75.97%という圧倒的なパフォーマンスを示しました。
ハイブリッド方式
SMOTE + トメックリンク
最初にSMOTEを適用し、次にトメックリンクでノイズを除去します。
from imblearn.combine import SMOTETomek smt = SMOTETomek(random_state=42) X_resampled, y_resampled = smt.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
出力
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([159, 159]))
以下は、この手法でリサンプリングされた訓練データを用いて学習させたモデルの結果です。
Train Classification report precision recall f1-score support 0 0.74 0.73 0.73 158 1 0.79 0.80 0.80 204 accuracy 0.77 362 macro avg 0.77 0.77 0.77 362 weighted avg 0.77 0.77 0.77 362
以下は取引結果です。
Inputs:technique_name = smote-tomeklinks
テスターの結果
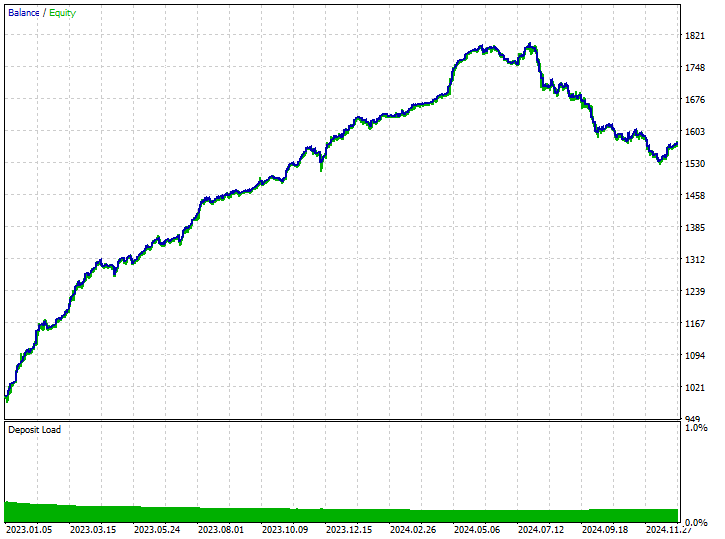
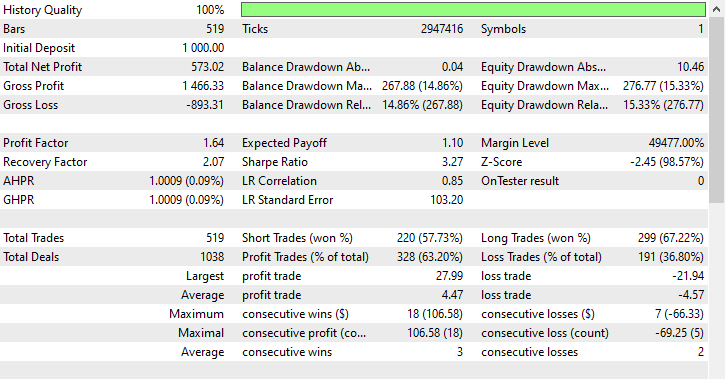
ショート取引が220回、ロング取引が299回で、なかなか悪くない結果です。
SMOTE + ENN (Edited Nearest Neighbors)
SMOTEは合成サンプルを生成し、その後にENNが誤分類されたサンプルを除去します。
from imblearn.combine import SMOTEENN sme = SMOTEENN(random_state=42) X_resampled, y_resampled = sme.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
この手法では大量のデータが削除され、訓練データはわずか61サンプルにまで減少しました。
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([37, 24]))
以下は、訓練サンプルに対する分類レポートです。
Train Classification report precision recall f1-score support 0 0.46 0.76 0.58 158 1 0.63 0.32 0.42 204 accuracy 0.51 362 macro avg 0.55 0.54 0.50 362 weighted avg 0.56 0.51 0.49 362
結果として得られたモデルは予想どおり良くない出来栄えとなりました。なぜなら、わずか61サンプルで訓練されたため、どのようなモデルであっても有意義なパターンを学習するには不十分だからです。取引の結果を観察してみましょう。
入力:Technique_name = smote-enn
テスターの結果
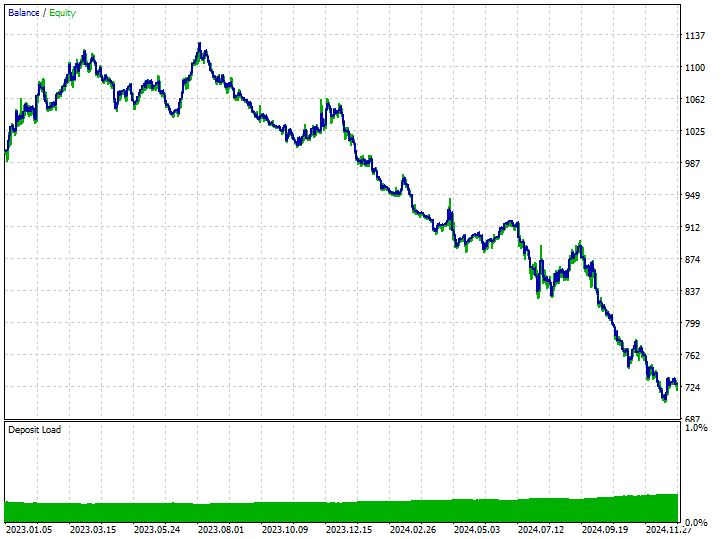
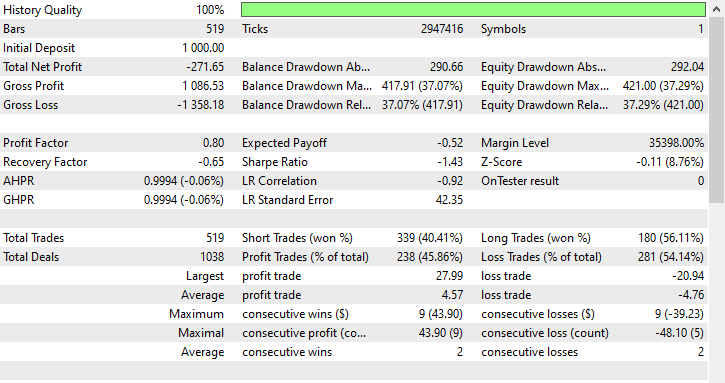
この手法はまったく効果がなく、むしろ状況を悪化させてしまいました。ロボットは519回のトレードのうち、180回が買い(ロング)で、339回が売り(ショート)を開くという偏ったトレード結果をもたらしました。
とはいえ、この手法が悪いというわけではなく、単に今回の状況には最適ではなかったということです。
結論
私たちは完璧な世界に生きているわけではありません。起こる現象すべてに明確な説明や確かな道筋があるわけではなく、これは市場が急速かつ頻繁に変動し、多くの戦略が瞬時に陳腐化してしまう取引の世界でも同様です。
市場の動きをコントロールすることはできませんが、私たちにできる最善のことは、極端な状況下でも機能する堅牢な取引システムや戦略を設計することです。
歴史が必ずしも繰り返されるわけではない以上、過去の市場で現れたパターンを認識しつつも、それに過度に依存しない偏りのない取引システムを構築することが極めて重要です。リサンプリング技術は非常に有用ですが、その活用には欠点やトレードオフへの配慮が欠かせません。たとえば、オーバーサンプリングによる過学習のリスク、アンダーサンプリングによる貴重な情報の損失、そしてリサンプリングを慎重におこなわなかった場合に発生するノイズやバイアスなどです。
適切なバランスを取ることこそが、未知の市場環境にも柔軟に対応できる堅牢なモデルを構築する鍵となるのです。
ご一読、誠にありがとうございました。
添付ファイルの表
| ファイル名 | 説明/用途 |
|---|---|
| Experts\Test Resampling Techniques.mq5 | MQL5で.ONNXファイルをデプロイするためのEA |
| Include\pandas.mqh | データ操作と保存のためのPython風Pandasライブラリ |
| Scripts\Collectdata.mq5 | 訓練データを収集するためのスクリプト |
| Common\*.onnx | ONNX形式の機械学習モデル |
| Common\*.csv | さまざまな商品からの訓練データと機械学習の使用 |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/17736
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 MQL5でのカスタム市場レジーム検出システムの構築(第2回):エキスパートアドバイザー
MQL5でのカスタム市場レジーム検出システムの構築(第2回):エキスパートアドバイザー
 MQL5でのカスタム市場レジーム検出システムの構築(第1回):インジケーター
MQL5でのカスタム市場レジーム検出システムの構築(第1回):インジケーター
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
必要なコンポーネントは、ノートブックにインポートされているすべての最新バージョンなので、バージョンの競合を気にせずにpip installを行うことができます。また、添付ファイルのリンクからKaggle.comに移動し、そこでコードを編集・修正することもできます。
未宣言の識別子は、変数やオブジェクトが定義されていないことを意味します。コードを確認するか、DMでコードのスクリーンショットを送ってください。