ニューラルネットワークが簡単に(第56回):核型ノルムを研究の推進力に

はじめに
強化学習は、エージェントが独立して環境を探索するというパラダイムに基づいています。エージェントは環境に影響を与え、それが環境の変化につながります。その見返りとして、エージェントは何らかの報酬を受け取ります。
ここで強化学習の2大問題である環境探索と報酬関数が浮き彫りになります。正しく構成された報酬関数は、エージェントに環境を探索させ、最適な行動戦略を探索させます。
しかし、ほとんどの実用的な問題を解くとき、私たちはまばらな外部報酬に直面します。この障壁を克服するために、いわゆる内部報酬の利用が提案されました。エージェントが新しいスキルを習得することで、将来、外部からの報酬を得るのに役立つ可能性があります。しかし、内的報酬は環境の確率性によってノイズが多くなる可能性があります。ノイズの多い予測値を観測値に直接適用することは、エージェント方策の訓練の効率に悪影響を与える可能性があります。さらに、多くの手法は研究の新規性を測定するためにL2ノルムや分散を用いますが、これは2乗操作によるノイズを増加させます。
この問題を解決するために、論文「Nuclear Norm Maximization Based Curiosity-Driven Learning」は、核型ノルム最大化(NNM)に基づくエージェントの好奇心を刺激する新しいアルゴリズムを提案しています。このような内的報酬は、環境探索の新規性をより正確に評価することができます。同時に、ノイズやスパイクに対する高い耐性を可能にします。
1.核型ノルムとその適用
核型ノルムを含む行列ノルムは、線形代数の解析や計算手法に広く用いられています。核型ノルムは、行列の性質、最適化問題、条件評価など、数学や応用科学の多くの分野で重要な役割を果たしています。
行列の核型ノルムは、行列の「大きさ」を決定する数値特性です。これはシャッテンノルムの特殊な場合で、行列の特異値の和に等しくなります。
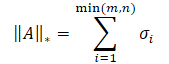
ここでσiはA行列の特異値ベクトルの要素を表します。
核型ノルムの核心は、同じスペクトルノルムを持つ行列の集合に対する階数関数の凸包です。そのため、さまざまな最適化問題を解くことができます。
核型ノルム最大化(Nuclear Norm Maximization (NNM))法の主な考え方は、ノイズや様々なスパイクの影響を緩和しながら、ある状態を訪れた際に行列の核型ノルムを用いて新規性を正確に推定することです。n*mサイズの行列は、環境のn個のコード化された状態からなります。各状態はm次元を持ちます。この行列は、sの現在の状態と、その最も近い(n - 1)の隣接状態を組み合わせたものです。ここでsは、元の高次元観測を低次元の抽象空間に写像することで、抽象的な状態を表します。S行列の各行は符号化された状態を表すので、rank(S)は行列内の多様性を表すのに使うことができます。S行列の階数が高いということは、符号化された状態間の線形距離が大きいことを意味します。本手法の著者は、問題解決に創造的なアプローチをとり、研究の多様性を高めるために行列順位最大化を用いています。これにより、このモデルのエージェントは、多様性の高いさまざまな状態を訪れるようになります。
行列の最大階数を使うには2つのアプローチがあります。損失関数として、あるいは報酬として使うことができます。行列の階数を直接最大化することは、非凸関数でかなり難しい問題です。したがって、損失関数としては使用しません。しかし、行列の階数値は離散的であり、状態の新規性を正確に反映することはできません。したがって、行列の生の階数値を報酬として使ってモデル学習を導くことも非効率的です。
数学的には、行列の階数の計算は通常、その核型ノルムに置き換えられます。したがって、核型ノルムの近似的な最大化によって新規性を維持することができます。階数に比べ、核型ノルムはいくつかの優れた特性を持っています。第一に、核型ノルムが凸であるため、高速で収束性の高い最適化アルゴリズムを開発することができます。第二に、核型ノルムは連続関数であり、これは多くの訓練タスクにとって重要です。
NNMメソッドの著者は、以下の式を使って内部報酬を決定することを提案しています。
![]()
ここで
λは核型ノルムの値の範囲を設定するための重みである;
S‖⋆は状態行列の核型ノルムである;
S‖Fは状態行列のフロベニウスノルムです。
フロベニウスノルムは全行列要素の2乗和の平方根として計算されます。
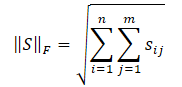
コーシーブニャコフスキー不等式により、以下のように変形することができます。
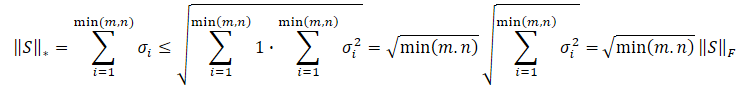
明らかに、値の二乗和の平方根は、常に値そのものの和以下となる。したがって、行列の核型ノルムは常に同じ行列のフロベニウスノルム以上となる。したがって、以下の不等式を導くことができます。
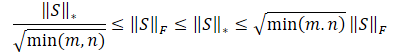
この不等式は、核型ノルムとフロベニウスノルムが互いに制約し合っていることを示しています。核型ノルムが増加すれば、フロベニウスノルムも増加する傾向があります。
さらに、フロベニウスノルムは私たちにとって有用なもうひとつの性質を持っています。その増加は、エントロピーの減少に相当します。その結果、核型ノルムの影響は2つに分けられる:
- バラエティに富んでいる。
- エントロピーが低い。
我々はエージェントに新しい州を訪問することを奨励する必要があり、我々の目標は多様性です。しかし、エントロピーの減少は、状態の凝集の増加を意味します。つまり、州の類似性が高いということです。そのため、私たちは前者の効果を促し、後者の影響を軽減することを目指しています。これをおこなうには、行列の核型ノルムをそのフロベニウスノルムで割る。
上記の不等式をフロベニウスノルムで割ると次のようになる:
![]()
明らかに、このような報酬スケールを直接使用することは、モデルの訓練に悪影響を及ぼす可能性があります。さらに、状態行列の最小次元のルートは、異なる環境や学習済みモデルのアーキテクチャによって異なる可能性があります。したがって、報酬スケールを再正規化することが望ましい。min(m,n)≦max(m,n)であるから、次のようになる:
![]()
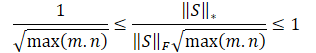
上記の数学的計算により、λ行列の核型ノルムの値の範囲に対する調整係数を次のように自動的に決定することができます。
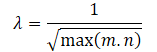
したがって、内部報酬の方程式は次のような形になる:
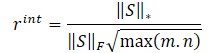
以下は筆者による核型ノルム最大化法の視覚化です。
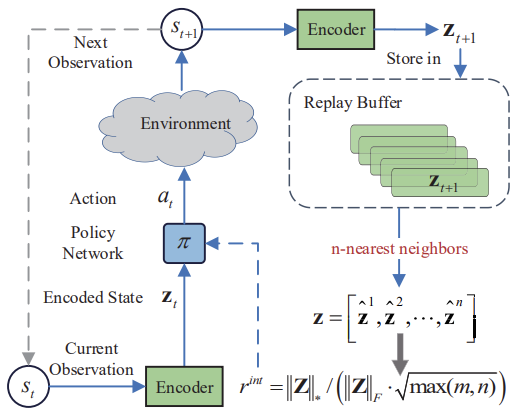
著者の論文で示されたテスト結果は、以前にレビューされた内発的好奇心モジュールや不一致による自己監視型探索など、他の環境調査アルゴリズムに対する提案手法の優位性を示しています。さらに、この方法は、元のデータにノイズを加えた場合により良い結果を示すことも注目に値します。この記事の実用的な部分に移り、私たちの問題を解決するためのこの方法の能力を評価しましょう。
2.MQL5を使用した実装
核型ノルム最大化メソッドの実装を始める前に、その主な革新点である新しい内部報酬方程式を強調しておきましょう。したがって、このアプローチは、これまで考えられてきた強化学習アルゴリズムのほとんどを補完するものとして実装することができます。
また、このアルゴリズムは、エンコーダを使って環境状態をある種の圧縮表現に変換していることにも注目すべきです。k近傍法のアルゴリズムも、環境状態の圧縮表現の行列を形成するために適用されます。
私見では、最も簡単な解決策は、提案されている内部報酬をRE3アルゴリズムに導入することだと思われます。また、エンコーダを使って環境状態を圧縮表現に変換します。この目的のために、RE3のランダム畳み込みエンコーダを使用します。これにより、エンコーダの訓練コストを削減することができます。
さらにRE3は、内部報酬の形成にk近傍法環境条件を適用します。しかし、この報酬の形は異なります。
私たちの行動の方向性ははっきりしているので、作業を始めます。まず、「...\Experts\RE3\」ディレクトリのすべてのファイルを「...\Experts\NNM\」にコピーします。覚えていらっしゃるかもしれませんが、4つのファイルが含まれています。
- Trajectory.mqh:一般的な定数、構造体、メソッドのライブラリ
- Research.mq5:環境と対話し、訓練サンプルを収集するためのEA
- Study.mq5:モデルを直接訓練するためのEA
- Test.mq5:訓練済みモデルをテストするためのEA
分解された報酬も使用します。報酬ベクトルの構造体は以下のようになります。
//+------------------------------------------------------------------+ //| Rewards structure | //| 0 - Delta Balance | //| 1 - Delta Equity ( "-" Drawdown / "+" Profit) | //| 2 - Penalty for no open positions | //| 3 - NNM | //+------------------------------------------------------------------+
「...\NNM\Trajectory.mqh」ファイルでは、環境状態の圧縮表現とモデルの内部全結合層のサイズを増やします。
#define EmbeddingSize 16 #define LatentCount 512
このファイルには、使用するモデルのアーキテクチャを記述するためのCreateDescriptionsメソッドも含まれています。ここでは3つのニューラルネットワークモデルを使用します。Actor、Critic、エンコーダです。エンコーダには、ランダム畳み込みエンコーダを使用します。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; }
メソッド本体では、1つのCLayerDescriptionニューラル層を記述するオブジェクトへのポインタを格納するローカル変数を作成し、必要に応じて、使用するモデルのアーキテクチャソリューションを記述する動的配列を初期化します。
まず、Actorアーキテクチャの説明を作成します。このアーキテクチャは、ソースデータの事前処理と意思決定の2つのブロックから構成されます。
分析対象商品の値動きに関する過去のデータと指標の読み取り値を、初期データ予備処理ブロックの入力に送信します。ご覧のように、指標によってパラメータの範囲は異なります。これはモデルの訓練効率に悪影響を及ぼします。そこで、CNeuronBatchNormOCLバッチ正規化層を使用して、受信データを正規化します。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
正規化されたデータを2つの畳み込み層に通し、個々の指標パターンを探索します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; int prev_wout=descr.window_out = HistoryBars/2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
得られたデータは、全結合層によって処理されます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
最初のデータ前処理ブロック操作のこの段階で、分析対象商品の過去のデータのある種の潜在的表現を受け取ることが期待されます。これは、ポジションを建てたり保有したりする方向を決定するには十分かもしれませんが、資金管理機能を実装するには十分ではありません。口座ステータスに関する情報でデータを補足してみましょう。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
この後、全結合層の意思決定ブロックが続き、変分オートエンコーダの潜在表現の確率的層で終わります。前回と同様、Actorの確率的方策を実行するために、モデルの出力にこのタイプの層を使用します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Actorアーキテクチャーについては十分に説明しました。同時に、確率的方策を実施するモデルを構築し、このような意思決定に核型ノルム最大化法を用いる可能性を強調しました。さらに、Actorは連続行動空間で働きます。しかし、これはNNM法の使用範囲を制限するものではありません。
次のステップは、Criticのアーキテクチャの説明を作成することです。ここでは、すでに実績のある技術を使用し、データの前処理ブロックを除外します。初期データとして、商品の過去のデータとActorの内部ニューラル層からの口座の状態の潜在的表現を使用します。同時に、環境状態の内部表現とActorが生成する行動テンソルを組み合わせます。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; }
得られたデータはCriticの全結合層で処理されます。予測値のベクトルは、報酬関数の分解の文脈で生成されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
すでに2つのモデルのアーキテクチャを説明しました。次に、エンコーダアーキテクチャーを作成する必要があります。ここで理論的な部分に戻り、NNM法が遷移St+1後の環境状態の比較を提供することに注目します。明らかに、この方法はオンライン訓練用に開発されたものですが、これについてはもう少し後で話しましょう。モデルのアーキテクチャを形成する段階で、エンコーダが分析対象商品の過去のデータと口座ステータスの読み取り値を処理することを理解することが重要です。十分な大きさのソースデータ層を作成しましょう。
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
データ正規化層も2つのデータテンソルの和も使わないことに注意してください。このモデルを訓練する予定がないためです。これは環境の多次元表現を、あるランダムな圧縮空間に変換するためだけに使われるもので、その中で状態間の距離を測定しますが、ここでは全結合層を使用し、データを比較可能な形で表示できるようにします。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 1024; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!convolution.Add(descr)) { delete descr; return false; }
次に、データの次元を減らすための畳み込み層のブロックが来ます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = 1024 / 16; descr.window = 16; descr.step = 16; prev_wout = descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 8; descr.window = 8; descr.step = 8; prev_wout = descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
最後に、全結合層を使って、与えられたサイズのデータの次元を減らします。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- return true; }
エンコーダの入力と出力に全結合層を使用することで、ソースデータの次元や圧縮表現の埋め込みに縛られることなく、畳み込み層のアーキテクチャをカスタマイズすることができます。
これで、モデルアーキテクチャに関する研究は終わりです。未来の状態の説明に戻りましょう。オンライン訓練の場合、この問題で苦労することはないでしょう。ただし、オンライン訓練には欠点もあります。経験再生バッファを使用する際、分析対象商品と指標の値動きの過去のデータに疑問はありません。Actorの行動が彼らに与える影響は、無視できるほど小さくなります。口座状況は別問題で、ポジションの方向と量に直接依存します。現状分析の結果に基づいてActorが生成する行動のベクトルによって、口座の状態を予測しなければなりません。この機能をForecastAccount関数で実装します。
メソッドのパラメータに次を渡します。
- prev_account:現在の口座状態(エージェントの行動の前)の説明の配列
- actions:Actorの行動のベクトル
- prof_1l:ロングポジションの1ロットあたりの利益
- time_label:予測されたバーのタイムスタンプ
パラメータの種類がかなり豊富であることがお分かりいただけるでしょう。これはデータソースに関連しています。現在の口座の状態と予測バーのタイムスタンプを経験再生バッファから取得します。データはfloat型の動的配列に格納されます。
Actorの行動は、モデルのダイレクトパスの結果からベクトルの形で得られます。
vector<float> ForecastAccount(float &prev_account[], vector<float> &actions, double prof_1l, float time_label ) { vector<float> account; double min_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); double step_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); double stops = MathMax(SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL), 1) * Point(); double margin_buy,margin_sell; if(!OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_ASK),margin_buy) || !OrderCalcMargin(ORDER_TYPE_SELL,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_BID),margin_sell)) return vector<float>::Zeros(prev_account.Size());
関数の本体で少し準備をします。商品の最小ロットとポジションボリュームの変更ステップを決定します。現在のストップレベルと取引ごとの証拠金サイズをリクエストします。なお、分析対象商品を特定するための追加パラメータは導入していません。プログラムが起動したチャートの商品を使用します。したがって、モデルを訓練する際には、訓練サンプルから初期データを収集するための手段や、モデル訓練プログラムが添付されているチャートを遵守することが非常に重要です。
次に、Actorの行動ベクトルを調整し、体積差によって一方向のみの取引を選択します。環境との相互作用のために、EAでも同様の操作をおこないます。モデル訓練プロセスのすべてのプログラムにおいて、統一されたルールを遵守することは、望ましい結果を得るために非常に重要です。
また、ポジションを建てるのに十分な資金が口座にあるかどうかもすぐに確認します。
account.Assign(prev_account); //--- if(actions[0] >= actions[3]) { actions[0] -= actions[3]; actions[3] = 0; if(actions[0]*margin_buy >= MathMin(account[0],account[1])) actions[0] = 0; } else { actions[3] -= actions[0]; actions[0] = 0; if(actions[3]*margin_sell >= MathMin(account[0],account[1])) actions[3] = 0; }
口座の状態は、調整された行動のベクトルに基づいて予測されます。まず、ロングポジションを確認します。ポジションを決済する必要がある場合は、累積利益を口座残高に振り替えます。そして、ポジションの数量と累積利益をリセットします。
ポジションを保有する場合、ポジションの一部決済や追加決済の必要性を確認します。ポジションの一部を決済する場合、決済した部分と残った部分に比例して累積利益を分割します。決済したポジションの取り分は、累積利益から口座残高に振り替えられます。
必要に応じて、ポジションの数量を調整し、保有ポジションの数量に比例して累積損益額を変更します。
//--- buy control if(actions[0] < min_lot || (actions[1] * MaxTP * Point()) <= stops || (actions[2] * MaxSL * Point()) <= stops) { account[0] += account[4]; account[2] = 0; account[4] = 0; } else { double buy_lot = min_lot + MathRound((double)(actions[0] - min_lot) / step_lot) * step_lot; if(account[2] > buy_lot) { float koef = (float)buy_lot / account[2]; account[0] += account[4] * (1 - koef); account[4] *= koef; } account[2] = (float)buy_lot; account[4] += float(buy_lot * prof_1l); }
ショートポジションについても同様の操作を繰り返します。
//--- sell control if(actions[3] < min_lot || (actions[4] * MaxTP * Point()) <= stops || (actions[5] * MaxSL * Point()) <= stops) { account[0] += account[5]; account[3] = 0; account[5] = 0; } else { double sell_lot = min_lot + MathRound((double)(actions[3] - min_lot) / step_lot) * step_lot; if(account[3] > sell_lot) { float koef = float(sell_lot / account[3]); account[0] += account[5] * (1 - koef); account[5] *= koef; } account[3] = float(sell_lot); account[5] -= float(sell_lot * prof_1l); }
次に、双方向の累積損益の総量と口座純資産を調整します。
account[6] = account[4] + account[5]; account[1] = account[0] + account[6];
得られた予測値をもとに、モデルにデータを提供する形式で口座の状態を表すベクトルを用意します。操作の結果は、呼び出し元のプログラムに返されます。
vector<float> result = vector<float>::Zeros(AccountDescr); result[0] = (account[0] - prev_account[0]) / prev_account[0]; result[1] = account[1] / prev_account[0]; result[2] = (account[1] - prev_account[1]) / prev_account[1]; result[3] = account[2]; result[4] = account[3]; result[5] = account[4] / prev_account[0]; result[6] = account[5] / prev_account[0]; result[7] = account[6] / prev_account[0]; double x = (double)time_label / (double)(D'2024.01.01' - D'2023.01.01'); result[8] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_MN1); result[9] = (float)MathCos(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_W1); result[10] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_D1); result[11] = (float)MathSin(2.0 * M_PI * x); //--- return result return result; }
準備作業はすべて終わりました。環境と相互作用するためのプログラムと訓練モデルのアップデートに移りましょう。NNMメソッドは内部の報酬関数に変更を加えることを思い出してください。この機能は環境との相互作用には影響しません。そのため、「...\NNM\Research.mq5」EAと「...\NNM\Test.mq5」EAに変更はありません。コードを以下に添付します。アルゴリズム自体は以前の記事で説明しました。
ここでは、モデル学習用EA「...\NNM\Study.mq5」に注目してみましょう。まず言っておかなければならないのは、NNMメソッドは主にオンライン訓練用に開発されたということです。これは、その後の状態の比較によって示されます。もちろん、かなり長い時間、予測状態を生成することができますが、状態間比較データベース内にない場合、訓練全体に悪影響を及ぼす可能性があります。それがない場合、モデルは状態を新しいものと認識し、訓練中に以前訪問したことに気づかず、繰り返し訪問するよう促します。
理論的には、この問題を解決するには2つの選択肢があります。
- 例のデータベースに予測状態を追加する
- 訓練サイクルの反復を減らす
どちらのアプローチにも欠点があります。例のデータベースに予測状態を追加する際、信頼性の低い不完全なデータで埋めてしまいます。もちろん、先験的な知識といくつかの仮定に基づいて数学的な計算をおこないましたが、それでも、その中に一定の誤りがあることを認めています。さらに、モデルを訓練するために、これらの行動に対する実際の報酬値を持っていません。そのため、訓練データの収集とモデルの訓練の実行回数が増えるという点で、手作業が増えるものの、2番目の方法を選択しました。
訓練ループの反復回数を減らします。
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 10000; input float Tau = 0.001f;
訓練では、1つのActor、2つのCriticsとそのターゲットモデル、そしてランダム畳み込みエンコーダを使用します。すべてのCriticモデルは同じアーキテクチャを持つが、訓練中に形成されるパラメータは異なります。
CNet Actor; CNet Critic1; CNet Critic2; CNet TargetCritic1; CNet TargetCritic2; CNet Convolution;
1つのActorと2つのCriticを訓練します。対応するCriticのパラメータから対象となるCriticモデルをTauパラメータでソフト的に更新します。エンコーダは訓練されていません。
OnInitEAの初期化メソッドでは、事前に収集した初期データを読み込みます。事前に訓練されたモデルを読み込めない場合は、与えられたアーキテクチャに従って新しいモデルを初期化します。このプロセスは変わっていないので、添付ファイルでご確認ください。直接Trainモデルの訓練方法に移ります。
この方法では、まず経験再生バッファに保存されている軌跡の数を決定し、その中の状態の総数を数えます。
状態の埋め込みと対応する外部報酬を記録するための行列を用意します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards);
次に、入れ子になったループのシステムを調整します。ループ本体では、経験再生バッファからすべての状態のエンコードを調整します。得られたデータは、状態とそれに対応する報酬の埋め込み行列を埋めるために使用されます。新しい状態への個々の遷移の報酬は、通過の終わりまで蓄積された値を考慮せずに保存されることに注意してください。このように、基本的な考え方は似ていますが、時間的に離れている状態を比較可能な形にしたいと思います。
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); next.Assign(Buffer[tr].States[st + 1].rewards); rewards.Row(temp - next * DiscFactor,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { rewards.Resize(state,NRewards); state_embedding.Reshape(state,state_embedding.Cols()); total_states = state; }
状態の埋め込みを準備したら、そのままモデルの訓練サイクルの配置に進みます。通常通り、サイクルの反復回数は外部パラメータによって設定され、ユーザー終了イベントの確認が追加されます。
ループ本体では、経験再生バッファからランダムに軌道とその軌道上の個別の状態を選択します。
vector<float> rewards1, rewards2; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; } vector<float> reward, target_reward = vector<float>::Zeros(NRewards); reward.Assign(Buffer[tr].States[i].rewards);
報酬を記録するためのベクトルを準備します。
次に、次の状態の説明を用意します。なお、ターゲットモデルの必要性に関係なく用意します。結局のところ、NNMメソッドを使用して内部報酬を生成するためには、どのような場合でもそれが必要です。
//--- Target TargetState.AssignArray(Buffer[tr].States[i + 1].state);
逆に、その後の口座状態の記述ベクトルや対象モデルのダイレクトパスは、必要な場合にのみおこなわれます。
if(iter >= StartTargetIter) { float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(TargetState), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; for(ulong r = 0; r < target_reward.Size(); r++) target_reward -= Buffer[tr].States[i + 1].rewards[r]; target_reward *= DiscFactor; }
次に、Criticを訓練します。このブロックでは、まず現在の環境状態に合わせたデータを準備します。
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
次に、Actorのフォワードパスを実行します。
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
ここで注意しなければならないのは、Criticを訓練するために、Actorが環境と相互作用したときの実際の行動と、実際に得られた報酬を使用することです。しかし、Criticアーキテクチャから除外されたソースデータの前処理ユニットを使用するために、Actorのフォワードパスを実行しました。
経験再生バッファからActorの行動バッファを準備し、両方のCriticのダイレクトパスを実行します。
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
フォワードパスの後、リバースパスを実行し、モデルパラメータを更新する必要があります。覚えていらっしゃるかもしれませんが、ここでは報酬関数を分解して使用します。勾配の最適化にはCAGrad法を使用します。目標は同じでも、各Criticの誤差勾配は明らかに異なります。モデルを順次更新していきます。まず、誤差勾配を修正し、Critic1のリバースパスを実行します。
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(reward + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
そして、Critic2の操作を繰り返します。もちろん、すべての段階で操作をコントロールしています。
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(reward + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Criticモデルは、特定の環境状態におけるActorの行動を正しく評価するように訓練されます。Criticのモデル運用の結果、正しい予測報酬を受け取ることを期待しています。これは氷山の一角にすぎませんが、水中の部分もあります。訓練中、CriticはQ関数を近似し、Actorの行動と報酬の間に一定の関係を構築します。
私たちの目標は、外部からの報酬を最大化することです。しかし、Criticの訓練の質に直接依存するわけではありません。逆に、報酬はActorの行動によって達成されます。Actorの行動を調整するために、近似Q関数を使用します。Actorの行動に対するCriticの評価と受け取った報酬の間の誤差勾配は、Actorの行動の調整方向を示します。過大評価の可能性は減り、過小評価の可能性は増えます。
Actorを訓練するために、移動予測誤差の平均値が最小となるCriticを使用します。これにより、Actorの行動をより正確に評価できる可能性があります。
CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
Actorのダイレクトパスはすでに実施済みです。選択された行動を評価するためには、選択されたCriticのダイレクトパスを実行する必要があります。その前に、目標報酬値のベクトルを用意しましょう。この仕事は些細なことではありません。環境からの外的報酬を予測し、それを内発的報酬で補うことで、Actorの探究心を刺激する必要があります。
奇妙に思われるかもしれませんが、まずはNNM法を用いて内部報酬を決定します。すでに述べたように、内部報酬を決定するためには、その後の状態のコード化された表現を得る必要があります。その後の状態過去のデータは、すでにTargetStateバッファに追加されています。先に説明したForecastAccount関数を使用して、予想口座ステータスを取得します。
Actor.getResults(rewards1); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,rewards1, prof_1l,Buffer[tr].States[i + 1].account[7]); TargetState.AddArray(forecast);
2つのテンソルを連結し、Actorとエンコーダの行動を評価する2つのCriticモデルのダイレクトパスをおこない、予測された状態の圧縮表現を得ます。
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Convolution.feedForward(GetPointer(TargetState))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
次に、報酬ベクトルの形成に移ります。target_rewardベクトルには、Actorの行動に対するCriticの評価と、環境と相互作用したときに実際に受け取った累積報酬との乖離が含まれていることを思い出してください。基本的に、このベクトルは方策変更が全体的な結果に与える影響を表しています。
ベクトル間の距離を調整したk近傍法による実際の報酬を、Actorの現在の行動に対する目標外部報酬として使用します。ここでは、行動に対する報酬は対応する隣人との距離に反比例すると仮定します。
kの隣人の選択と内部報酬の形成はKNNReward関数でおこなわれます。後で少し説明します。
しかし、ここでもう一点に注意を払う必要があります。コード化された状態の報酬行列には、累積のない最後の遷移についてのみ、外部報酬を保存しました。従って、同等のゴールを得るためには、経験再生バッファから、現在のパスが完了する前に受け取った累積報酬をtarget_rewardに加える必要があります。
next.Assign(Buffer[tr].States[i + 1].rewards); target_reward+=next; Convolution.getResults(rewards1); target_reward=KNNReward(7,rewards1,state_embedding,rewards) + next * DiscFactor; if(forecast[3] == 0.0f && forecast[4] == 0.0f) target_reward[2] -= (Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance) / DiscFactor; critic.getResults(reward); reward += CAGrad(target_reward - reward);
Conflict-Averse勾配降下法を用いて、目標報酬値とCriticの評価値との乖離を調整し、その結果の値をCriticの予測値に加えます。こうして、報酬分解を考慮して調整された目標値のベクトルが得られます。それを使って、Actorのパラメータを更新していきます。まず、Criticの訓練モードを無効にし、調整した目標にパラメータを合わせないようにします。
Result.AssignArray(reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
Actorパラメータの更新に成功したら、Criticモデルを訓練モードに戻し、両方のCriticのターゲットモデルを更新します。
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau);
これでモデル訓練サイクルの反復が完了しました。ここでしなければならないのは、実行された操作をユーザーに知らせることです。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
訓練ループのすべての反復が成功したら、チャートのコメントエリアを消去します。モデルの訓練結果をログに送信し、EAの終了を開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
ここで、モデル学習アルゴリズムの動作を完全に理解するために、KNNReward報酬生成関数を見てみましょう。この関数には、核型ノルム最大化法の主な機能が含まれています。
この関数のパラメータには、分析された隣人の数、分析された状態の埋め込み、状態の埋め込み行列、および対応する報酬が、経験再生バッファから受け取られます。
vector<float> KNNReward(ulong k, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards ) { if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return vector<float>::Zeros(0); }
メソッド本体では、現在の状態と経験再生バッファからの状態の埋め込み次元を確認します。現在の実装では、この確認は冗長に見えるかもしれません。結局のところ、このEAでは1つのエンコーダを使ってすべての埋め込みを受信します。しかし、RE3メソッドの元記事で推奨されているように、環境とのインタラクション中に状態埋め込みを生成し、それを経験再生バッファに保存することにした場合には、非常に便利です。
次に、いくつかの定数をローカル変数として定義することで、少し準備作業をします。必要であれば、隣人の数も経験再生バッファの状態数まで減らします。そのような必要性の可能性は極めて低くなりますが、この機能はコードをより汎用的にし、実行時のエラーから守ってくれます。
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); k = MathMin(k,states); ulong rew_size = rewards.Cols(); matrix<float> temp = matrix<float>::Zeros(states,size);
次のステップは、分析された状態のベクトルと、経験再生バッファ内の状態との間の距離を決定することです。得られた値はdistanceベクトルに保存されます。
for(ulong i = 0; i < size; i++) temp.Col(MathPow(state_embedding.Col(i) - embedding[i],2.0f),i); vector<float> distance = MathSqrt(temp.Sum(1));
次に、kの最も近い隣人を決定しなければなりません。これらのパラメータをk_embeding行列とk_rewards行列に保存します。k_embeding行列の行を1つ増やしていることに注意。その中に分析された状態の埋め込みを書きます。
探しているベクトルの数に応じて、ループでデータを行列に転送します。ループ本体では、ArgMinベクトル演算を使って、距離ベクトルの最小値の位置を決定します。これが、最も近い隣人となります。そのデータを行列の対応する行に移し、距離ベクトルでは、この位置に可能な限り最大の定数を設定します。このように、データをコピーした後、最小距離を最大値に変更しました。次のループの繰り返しで、ArgMin演算は次の隣人の位置を提供します。
なお、報酬ベクトルを転送する際には、状態ベクトル間の距離の逆数でその値を調整します。
matrix<float> k_rewards = matrix<float>::Zeros(k,rew_size); matrix<float> k_embeding = matrix<float>::Zeros(k + 1,size); for(ulong i = 0; i < k; i++) { ulong pos = distance.ArgMin(); k_rewards.Row(rewards.Row(pos) * (1 - MathLog(distance[pos] + 1)),i); k_embeding.Row(state_embedding.Row(pos),i); distance[pos] = FLT_MAX; } k_embeding.Row(embedding,k);
このアルゴリズムには多くの利点があります。
- 反復回数が経験再生バッファのサイズに依存しないため、大規模なデータベースを使用する場合に便利
- データを並び替える必要がないため、多くのリソースを必要とすることが多い
- 各隣人のデータをコピーするのは一度だけで、他のデータはコピーしない
必要なすべての近傍のデータを転送した後、現在の状態をk_embedding行列の最後の行に追加します。
次に、k_embeding行列の核型ノルムを決定するために行列の特異値を求め、NNM法を実行する必要があります。そのために、SVD行列演算を使用します。
matrix<float> U,V; vector<float> S; k_embeding.SVD(U,V,S);
行列の特異値はSベクトルに格納されます。核型ノルムを決定するためには、その値を要約するだけでよくなります。しかしその前に、選択された報酬のk_rewards行列の列による平均値のベクトルとして、外部報酬のベクトルを生成します。
NNM法を用いた内部報酬を、状態埋め込み行列の核型ノルムとそのフロベニウスノルムの比として定義し、核型ノルムのスケーリングファクターで調整します。結果の値を報酬ベクトルの対応する要素に書き込み、報酬ベクトルを呼び出し元のプログラムに返す。
vector<float> result = k_rewards.Mean(0); result[rew_size - 1] = S.Sum() / (MathSqrt(MathPow(k_embeding,2.0f).Sum() * MathMax(k + 1,size))); //--- return (result); }
これで、MQL5を用いた核型ノルム最大化法の実装に関する研究は終わりです。記事で使用したすべてのプログラムの完全なコードは、添付ファイルでご覧いただけます。
3.検証
核型ノルム最大化法をRE3アルゴリズムに統合するために、かなり多くの作業をおこないました。検証する時間です。いつものように、モデルは2023年の1月~5月のEURUSDH1で訓練され、テストされています。すべての指標のパラメータがデフォルトで使用されます。
訓練EA「...\NNM\Study.mq5」を作成する際に、メソッドの特徴や経験再生バッファに生成された状態がないことは既に述べました。そこで、訓練サイクルの反復回数を減らすことにしました。もちろん、これは訓練全体に影響を及ぼす。
全体的な再生バッファを減らすことはしませんでしたが、同時に、モデルパラメータの更新を1万回繰り返すために、1.3Mの状態のデータベースを用意する必要はありません。もちろん、データベースが大きければ、モデルのチューニングもしやすくなります。しかし、1回の更新反復で100以上の状態がある場合、それらをすべて処理することはできません。そのため、経験再生バッファを徐々に埋めていきます。最初の反復では、訓練データ収集EAを50パスだけ起動します。これですでに、指定された過去の期間でモデルを訓練するための約12万の状態を得ることができます。
モデル訓練の最初の反復の後、さらに50パスで例のデータベースを補足します。こうして、訓練された方策の枠組みの中で、Actorの行動に対応する新しい状態で経験再生バッファを徐々に満たしていきます。
このアプローチは、EA立ち上げに関わる手作業を大幅に増やしますが、そのおかげで、例のデータベースを比較的最新の状態に保つことができます。生成された内部報酬は、Actorを新しい環境状態の探索に向かわせます。
モデルを訓練しながら、訓練サンプルで利益を生み出し、獲得した知識をその後の環境状態に対して汎化できるモデルを得ることに成功しました。例えば、ストラテジーテスターでは、訓練済みのモデルは、訓練サンプルの後、1ヶ月以内に1%の利益を生み出すことができました。テスト期間中、このモデルは133回の取引をおこない、そのうちの42%は利益で決済されました。取引ごとの最大利益は、最大損失取引のほぼ2倍です。取引ごとの平均利益は平均損失より40%高くなります。この結果、プロフィットファクターは1.02となりました。


結論
本稿では、核型ノルム最大化に基づく強化学習における探索を促す新しいアプローチを紹介しました。この方法により、過去の情報を考慮し、ノイズや排気ガスに対する高い耐性を確保しながら、環境研究の新規性を効果的に評価することができます。
実用的な部分では、核型ノルム最大化法をRE3アルゴリズムに統合しました。モデルを訓練し、MetaTrader 5ストラテジーテスターでテストしました。テスト結果に基づき、純粋なRE3法を用いてモデルを訓練した結果に比べ、提案メソッドはActorの挙動を大幅に多様化させたと言えます。ただし、結局はもっと混沌とした取引になってしまいました。これは、報酬関数に追加的な影響比率を導入することで、探査と搾取のバランスを調整する必要性を示しているのかもしれません。
リンク
- Nuclear Norm Maximization Based Curiosity-Driven Learning
- ニューラルネットワークが簡単に(第53回):報酬の分解
- ニューラルネットワークが簡単に(第54回):ランダムエンコーダを使った効率的な研究(RE3)
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述構造 |
| 5 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 6 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13242
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索