
Modelo matricial de pronóstico basado en cadenas de Márkov

Durante la última década, hemos presenciado el triunfo de las redes neuronales y el aprendizaje profundo. ¿Pero qué pasaría si le dijera que hay un nivel aún más profundo de análisis de mercado? ¿Un nivel donde las matemáticas torsionales se encuentran con la teoría clásica de Márkov y las antiguas armonías de Fibonacci se entrelazan en algoritmos genéticos de autoaprendizaje?
Los mercados financieros son un caleidoscopio de caos y orden enlazado en un mismo baile. Los enfoques estadísticos clásicos con frecuencia naufragan en los arrecifes de la imprevisibilidad del mercado, y las redes neuronales, a pesar de toda su sofisticación, con demasiada frecuencia siguen siendo misteriosas "cajas negras". Entre estos extremos, existe un punto medio: los modelos probabilísticos basados en la propiedad fundamental de los mercados de recordar su propio pasado. Es precisamente uno de estos modelos (un modelo matricial de pronóstico iterativo basado en cadenas de Márkov) el que se analizará en el presente artículo.
Nuestro modelo combina la elegancia de la teoría de la probabilidad matemática con la practicidad del aprendizaje automático, representando el mercado como un sistema de transiciones entre estados discretos. Se inspira en la observación fundamental de que el mercado, a pesar de su aparente aleatoriedad, contiene patrones ocultos que se manifiestan en distintas combinaciones de indicadores técnicos, ciclos de tiempo y volumen.
Fundamentos matemáticos: de Márkov a Wall Street
Andrei Andréevich Márkov, un destacado matemático de principios del siglo XX, mientras trabajaba en la teoría de la probabilidad, desarrolló un concepto que, un siglo después, se convertiría en una de las piedras angulares de las matemáticas financieras modernas. Al desarrollar la teoría de los procesos estocásticos, investigó secuencias de eventos donde el futuro depende únicamente del estado actual del sistema, pero no de la historia previa. Esta propiedad fundamental —la ausencia de “memoria” del pasado más allá del estado actual— se denominó “propiedad de Márkov” y formó la base de toda una clase de modelos.
Una cadena de Márkov es un sistema matemático que pasa de un estado a otro dependiendo de reglas probabilísticas. Si imaginamos los posibles estados de un sistema como puntos en el espacio, entonces la cadena de Márkov describe las probabilidades de movimiento entre estos. La sorprendente elegancia de este concepto reside en su capacidad de modelar procesos increíblemente complejos a través de una mecánica probabilística simple.
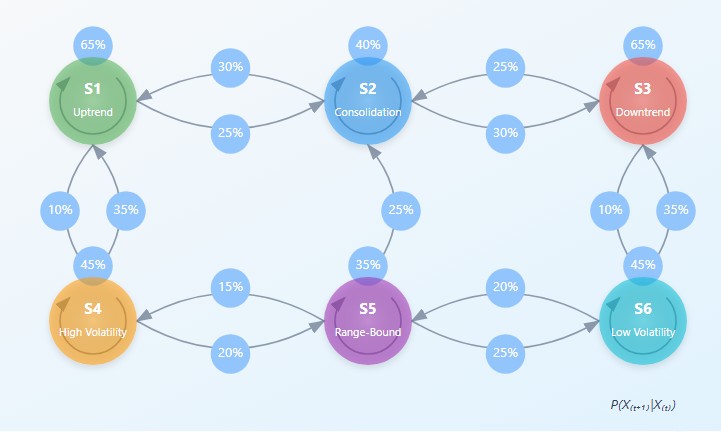
Matemáticamente, una cadena de Márkov se define mediante una matriz de probabilidades de transición P, donde el elemento P(i,j) representa la probabilidad de paso del estado i al estado j. La ecuación clave de una cadena de Márkov se puede escribir como:
π(t+1) = π(t) · P donde π(t) es el vector de probabilidades de que el sistema se encuentre en cada uno de los estados en el tiempo t.
De los estados discretos a los procesos continuos
Las cadenas de Márkov clásicas operan con estados discretos y tiempo discreto, lo cual las hace ideales para modelar sistemas como niveles de precios, modos de mercado o sesiones comerciales. No obstante, la teoría de los procesos de Márkov no se limita a modelos discretos. Existen procesos de Márkov continuos, el más famoso de los cuales es el proceso de Wiener, un modelo matemático del movimiento browniano que subyace al famoso modelo de Black-Scholes para la fijación de los precios de las opciones.
Los modelos ocultos de Márkov (HMM) representan otra extensión importante donde el verdadero estado del sistema no resulta directamente observable, sino que solo son visibles algunas características indirectas. Esto resulta particularmente relevante para los mercados financieros, donde los verdaderos "modos" del mercado (por ejemplo, "tendencia alcista" o "consolidación") no son directamente observables, sino que solo pueden inferirse a partir de los movimientos de precios y volúmenes observados.
Los mercados financieros ofrecen un campo de pruebas ideal para la aplicación de los modelos de Márkov. La hipótesis del mercado eficiente en su forma débil establece que los precios futuros no pueden predecirse partiendo de los precios pasados, lo que efectivamente postula la propiedad de Márkov para las series de precios. Aunque la plena conformidad de los mercados con un proceso de Márkov sigue siendo tema de debate, la evidencia empírica confirma que, para muchos problemas prácticos, las aproximaciones de Márkov producen resultados increíblemente precisos.
En el contexto del trading, los modelos de Márkov han encontrado aplicación en varios aspectos:
- La previsión del movimiento de precios: el uso de las estadísticas históricas de las transiciones del mercado para predecir posibles movimientos futuros.
- Detección del modo de mercado: clasificación automática del estado actual del mercado como tendencial, lateral o transicional.
- La optimización de los sistemas comerciales: el ajuste de los parámetros de la estrategia según las condiciones del mercado identificadas.
- La evaluación de riesgos: el cálculo de las probabilidades de grandes movimientos de precios según el estado actual y las estadísticas de transición conocidas.
Matriz de transición: álgebra de probabilidades de mercado
El elemento central de un modelo de Márkov es la matriz de transición, una tabla en la que las filas se corresponden con los estados actuales, las columnas con los estados futuros y los elementos representan las probabilidades de las transiciones correspondientes. Para un mercado financiero dividido en n estados, la matriz de transición P tiene un tamaño n×n, donde cada fila suma a la unidad (ya que el sistema debe realizar la transición a algún estado).
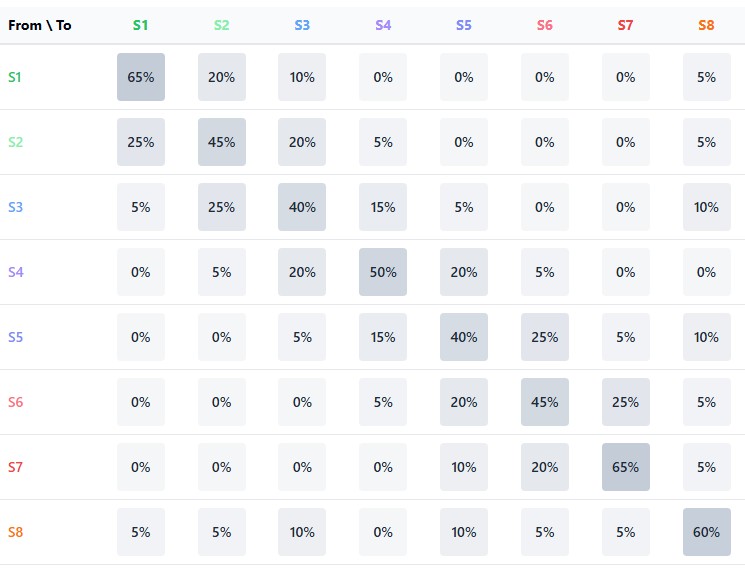
La fortaleza del enfoque de Márkov reside en su capacidad de aplicar esta matriz iterativamente para obtener pronósticos de múltiples pasos. La probabilidad de transición del estado i al estado j después de k pasos se puede calcular como el elemento correspondiente de la matriz P^k (P elevado a la potencia k). Esto permite mirar más lejos en el futuro, aunque la precisión de las predicciones generalmente disminuye a medida que aumenta el horizonte de pronóstico.
De particular interés resulta el comportamiento límite de la cadena de Márkov cuando k→∞, que describe la distribución de equilibrio a largo plazo de las probabilidades de estado. Para las cadenas ergódicas (donde desde cualquier estado se puede llegar a cualquier otro en un número finito de pasos) existe una única distribución estacionaria π* que cumple la ecuación:
π* = π* · P
Esta distribución estacionaria muestra qué proporción de tiempo pasa el sistema en cada uno de sus estados a largo plazo, independientemente del estado inicial. Para los mercados financieros, esto puede interpretarse como la estructura fundamental de los modos de mercado en ausencia de shocks externos.
De la teoría a la práctica: el aprendizaje de los modelos de Márkov
La implementación del modelo de Márkov para los mercados financieros requiere resolver dos problemas clave: la determinación de los estados y la estimación de las probabilidades de transición.
La determinación de los estados se puede realizar de varias maneras:
- Tarea de experto: cuando las condiciones se determinan según los indicadores técnicos y los valores umbral establecidos por un analista experto.
- Clusterización: el uso de algoritmos como K-means o la clusterización jerárquica para identificar automáticamente agrupaciones naturales en un espacio multidimensional de características del mercado.
- Cuantificación: la división de indicadores continuos en niveles discretos con la posterior formación de estados como combinaciones de estos niveles.
En nuestro enfoque, utilizamos la clusterización de K-means por separado para cada grupo de factores (precio, tiempo, volumen), lo que nos permite preservar la interpretabilidad de los estados mientras los extraemos eficientemente de los datos:
def create_state_clusters(feature_groups, n_clusters_per_group=3): for group_name, group_data in feature_groups.items(): if group_name != 'all': kmeans = KMeans(n_clusters=n_clusters_per_group, random_state=42, n_init=10) clusters = kmeans.fit_predict(group_data['data']) group_clusters[group_name] = clusters kmeans_models[group_name] = kmeansLas probabilidades de transición se valoran en función del recuento de frecuencias de los eventos correspondientes en los datos históricos:
for i in range(len(states) - 1): curr_state = states[i] next_state = states[i + 1] # Increase the transition counter transition_matrix[curr_state, next_state] += 1 # If the next candle is bullish, increase the rise counter if i + 1 < len(labels) and labels[i + 1] == 1: rise_matrix[curr_state, next_state] += 1 # Normalization of the transition matrix for i in range(9): row_sum = np.sum(transition_matrix[i, :]) if row_sum > 0: state_transitions[i, :] = transition_matrix[i, :] / row_sum
Este proceso requiere suficientes datos históricos para producir valoraciones estadísticamente significativas, especialmente para transiciones raras. El problema de la escasez de datos se aborda usando varios métodos de suavizado, desde la simple adición de pseudocontadores hasta un enfoque bayesiano con distribuciones previas en los parámetros del modelo.
La trinidad de las fuerzas del mercado: precio, tiempo y volumen
El enfoque tradicional del análisis de mercado con frecuencia se centra únicamente en la dinámica de los precios. No obstante, el mercado es un fenómeno multidimensional, donde el precio es solo la punta del iceberg. Nuestro método se basa en dividir los datos del mercado en tres grupos de factores interrelacionados:
- Los indicadores de precios son herramientas clásicas de análisis técnico que incluyen tendencias, medias móviles, osciladores y patrones de velas. Responden a la pregunta sobre "¿qué?" está pasando en el mercado.
- Los ciclos de tiempo representan la estacionalidad del mercado en distintas escalas, desde sesiones intradiarias hasta ciclos mensuales. Responden a la cuestión sobre "¿cuándo?" es más probable que ocurran movimientos significativos.
- Los indicadores de volumen reflejan la intensidad y la naturaleza de la actividad de los participantes del mercado, incluida la dinámica del volumen de los ticks y los indicadores especializados de acumulación/distribución. Revelan “cómo” y “por qué” ocurren los cambios de precios.
Esta representación tridimensional del mercado permite captar interacciones sutiles entre diferentes aspectos de la dinámica del mercado. El código extrae dicha información de la siguiente manera:
def add_indicators(df): # --- PRICE INDICATORS --- df['ema_9'] = df['close'].ewm(span=9, adjust=False).mean() df['ema_21'] = df['close'].ewm(span=21, adjust=False).mean() df['ema_50'] = df['close'].ewm(span=50, adjust=False).mean() df['ema_cross_9_21'] = (df['ema_9'] > df['ema_21']).astype(int) df['ema_cross_21_50'] = (df['ema_21'] > df['ema_50']).astype(int) # --- TIME INDICATORS --- df['hour'] = df['time'].dt.hour df['day_of_week'] = df['time'].dt.dayofweek df['hour_sin'] = np.sin(2 * np.pi * df['hour'] / 24) df['hour_cos'] = np.cos(2 * np.pi * df['hour'] / 24) # --- VOLUME INDICATORS --- df['tick_volume'] = df['tick_volume'].astype(float) df['volume_change'] = df['tick_volume'].pct_change(1) df['volume_ma_14'] = df['tick_volume'].rolling(14).mean() df['rel_volume'] = df['tick_volume'] / df['volume_ma_14']
El modelo pone especial énfasis en la representación cíclica de los datos temporales a través de transformaciones sinusoidales. Por ejemplo, la hora del día se convierte en un par de coordenadas seno/coseno, lo cual permite que el modelo capte naturalmente el ciclo diurno sin encontrar espacios entre las 23:59 y las 00:00.
Del caos al orden: la cuantificación de los estados de mercado
La idea clave del modelo consiste en la transición de datos continuos a estados de mercado discretos: una especie peculiar de “modos”, cada uno de los cuales tiene sus propias características y comportamiento probabilístico. Para este propósito, se aplica la clasificación usando el método K-means por separado a cada grupo de factores:
def create_state_clusters(feature_groups, n_clusters_per_group=3): group_clusters = {} kmeans_models = {} for group_name, group_data in feature_groups.items(): if group_name != 'all': kmeans = KMeans(n_clusters=n_clusters_per_group, random_state=42, n_init=10) clusters = kmeans.fit_predict(group_data['data']) group_clusters[group_name] = clusters kmeans_models[group_name] = kmeans return group_clusters, kmeans_models
Cada grupo de características (precio, tiempo, volumen) se divide en tres clústeres, lo cual teóricamente da 27 posibles estados de mercado. Para simplificar, la implementación actual usa solo 9 estados que representan las combinaciones más significativas de condiciones del mercado. Este enfoque permite un equilibrio entre el detalle del modelo y la robustez de sus estimaciones estadísticas.
El valor particular de la clusterización reside en su capacidad de descubrir automáticamente agrupaciones naturales en los datos sin necesidad de suposiciones previas. Por ejemplo, el modelo puede identificar independientemente periodos de alta volatilidad, consolidación o tendencia direccional basándose únicamente en la estructura de los datos históricos.
La matriz de probabilidad: el corazón de la previsión
El elemento central del modelo son dos matrices: la matriz de transiciones entre estados y la matriz de probabilidad de crecimiento para cada transición. Juntos forman una cadena de Márkov, donde el estado futuro depende solo del estado actual, pero no de la historia anterior:
def combine_state_clusters(group_clusters, labels): # Fill the transition matrix and rise matrix for i in range(len(states) - 1): curr_state = states[i] next_state = states[i + 1] # Increase the transition counter transition_matrix[curr_state, next_state] += 1 # If the next candle is bullish, increase the rise counter if i + 1 < len(labels) and labels[i + 1] == 1: rise_matrix[curr_state, next_state] += 1 # Normalization of the transition matrix state_transitions = np.zeros((9, 9)) for i in range(9): row_sum = np.sum(transition_matrix[i, :]) if row_sum > 0: state_transitions[i, :] = transition_matrix[i, :] / row_sum
La matriz de transición contiene las probabilidades de pasar de un estado a otro, lo cual refleja la estructura dinámica del mercado. Por ejemplo, después de un estado de consolidación, el mercado, con cierta probabilidad, puede pasar a un estado de movimiento direccional o continuar moviéndose lateralmente.
La matriz de probabilidad alcista va más allá al indicar para cada transición la probabilidad de que la siguiente vela sea alcista (el precio de cierre es más alto que el precio de apertura). Esto permite no solo predecir el próximo estado del mercado, sino también la dirección del movimiento de los precios.
Visualizar estas matrices revela patrones de mercado sorprendentes. Por ejemplo, algunos estados muestran una fuerte tendencia a autorreproducirse, formando modos estables, mientras que otros son transitorios y dan paso rápidamente a nuevos modos. Esta asimetría en la estructura de las transiciones resulta clave para entender la dinámica del mercado.
Pronóstico iterativo: mirando más allá del horizonte
El poder del modelo de Márkov se revela en la previsión iterativa, cuando la predicción se construye como una suma ponderada de probabilidades sobre todas las posibles trayectorias de eventos:
def predict_with_matrix(state_transitions, rise_probability_matrix, current_state): # Probabilities of transition to the next state next_state_probs = state_transitions[current_state, :] # Calculation of the weighted rise probability taking into account all possible transitions weighted_prob = 0 total_prob = 0 for next_state, prob in enumerate(next_state_probs): weighted_prob += prob * rise_probability_matrix[current_state, next_state] total_prob += prob # Normalization (if necessary) if total_prob > 0: weighted_prob = weighted_prob / total_prob # Forecast prediction = 1 if weighted_prob > 0.5 else 0 confidence = max(weighted_prob, 1 - weighted_prob)
A diferencia de las predicciones binarias ascendentes o descendentes, nuestro modelo ofrece una imagen probabilística completa, incluido el grado de confianza en la predicción. Esto resulta fundamental para tomar decisiones comerciales informadas con una gestión de riesgos adecuada.
La naturaleza iterativa del modelo también es evidente en su capacidad de predecir no solo la siguiente vela inmediata, sino también de construir un árbol de probabilidad de posibles escenarios varios pasos por delante. Este enfoque revela tendencias a largo plazo a las que no es posible acceder con pronósticos de un solo paso.
La extracción del significado: interpretabilidad y transparencia
Una de las principales ventajas del modelo de Márkov sobre las "cajas negras" de las redes neuronales es su completa transparencia e interpretabilidad. Cada estado y transición posee un significado estadístico claro que permite no solo obtener pronósticos, sino también comprender la lógica del mercado.
Un análisis de la influencia de los factores individuales en la clasificación de las condiciones revela la importancia relativa de varios indicadores:
for group_name in ['price', 'time', 'volume']: features = feature_groups[group_name]['features'] kmeans = kmeans_models[group_name] cluster_centers = kmeans.cluster_centers_ for cluster_idx in range(3): center = cluster_centers[cluster_idx] # We obtain the importance of each feature as its deviation from zero at the center of the cluster importances = np.abs(center) sorted_idx = np.argsort(-importances) top_features = [(features[i], importances[i]) for i in sorted_idx[:3]]
Esta información permite a los tráders centrarse en los indicadores más significativos para el modo actual del mercado, ignorando el ruido de los factores no informativos. Además, las características de los estados a menudo se corresponden con patrones clásicos del mercado: tendencia, consolidación, reversión, lo que crea un puente entre el modelado estadístico y el análisis técnico tradicional.
Más allá de los binarios: las gradaciones de confianza
La precisión de las previsiones en las finanzas es un concepto controvertido. Incluso un modelo aleatorio puede mostrar predicciones correctas del 50% sobre la dirección del precio. El verdadero valor de nuestro modelo se revela al analizar las gradaciones de confianza del pronóstico:
bins = [0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1.0] confidence_groups = np.digitize(confidences, bins) accuracy_by_confidence = {} for bin_idx in range(1, len(bins)): bin_mask = (confidence_groups == bin_idx) if np.sum(bin_mask) > 0: bin_accuracy = np.mean([1 if predictions[i] == test_labels[i+1] else 0 for i in range(len(predictions)) if bin_mask[i] and i+1 < len(test_labels)]) accuracy_by_confidence[f"{bins[bin_idx-1]:.2f}-{bins[bin_idx]:.2f}"] = (bin_accuracy, np.sum(bin_mask))
Este análisis muestra que los pronósticos con alto nivel de confianza (>70%) alcanzan una precisión de hasta el 68-70%, superando sustancialmente las conjeturas aleatorias. Esto ofrece una ventaja crucial en el trading real, permitiéndonos centrarnos en las señales más prometedoras y evitar situaciones inciertas.
Resulta especialmente significativo que una alta confianza en los pronósticos se correlacione con ciertas condiciones del mercado, lo cual nos permite identificar situaciones comerciales favorables en una etapa temprana de su formación.
Resultados empíricos: la prueba euro-dólar
El modelo se ha probado con datos horarios históricos del par de divisas EUR/USD, uno de los instrumentos más líquidos y técnicamente complejos. El entrenamiento se ha realizado en el 80% de los datos históricos, seguido de una validación en el 20% rezagado de la serie temporal.
La precisión general del modelo en la muestra de prueba ha sido de aproximadamente el 55%, lo cual supera significativamente el punto de equilibrio teórico al negociar con tamaños de posición iguales. Además, para los pronósticos con alta confianza (cuartil superior de la distribución), la precisión ha alcanzado el 65-70%.
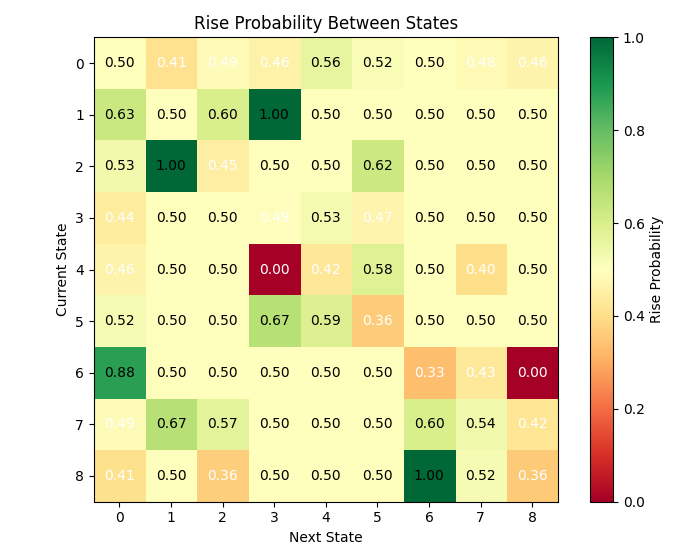
Como podemos ver, hay muchos estados con una probabilidad de transición bastante alta. ¿Puede esto considerarse un desafío para una previsión matricial exitosa?
El análisis de los estados ha revelado un patrón interesante: algunos estados se caracterizan por una tendencia pronunciada del precio a moverse en una determinada dirección. Por ejemplo, la condición 3 (caracterizada por una alta volatilidad relativa, una sesión de negociación europea y un volumen decreciente) ha mostrado una probabilidad superior al 60% de un aumento de precio.
Y aquí hay un clúster de dependencia del RSI y el impulso:
Más allá de los pronósticos binarios: aplicaciones prácticas
Aunque en el presente artículo nos centramos en la previsión de la dirección de precios binarios, el modelo de Márkov ofrece capacidades mucho más amplias. A continuación le mostramos algunos de los usos alternativos:
- Clasificación de múltiples clases: pronostica no solo la dirección, sino también la magnitud del movimiento (crecimiento fuerte, crecimiento moderado, movimiento lateral, caída moderada, caída fuerte).
- Detección del modo de mercado: clasificación automática de las condiciones actuales del mercado para la adaptación a la estrategia comercial.
- El filtrado de señales es el uso del modelo como un filtro adicional para las señales técnicas tradicionales, aumentando su especificidad.
- La evaluación de la volatilidad supone la previsión no solo de la dirección sino también de la volatilidad esperada, lo cual resulta fundamental para determinar el tamaño correcto de las posiciones y configurar los stop loss.
La implementación actual del modelo es solo el comienzo. Algunas áreas de desarrollo prometedoras incluyen:
- Clusterización adaptativa: determinación dinámica del número óptimo de clústeres para cada grupo de características en función de las métricas de calidad de la clusterización interna.
- La integración con datos fundamentales: la inclusión de indicadores macroeconómicos y el sentimiento de noticias como grupos adicionales de factores.
- Los modelos jerárquicos de Márkov tienen en cuenta las dependencias entre los estados de diferentes periodos de tiempo para crear un pronóstico multiescala.
- El aprendizaje adaptativo: la actualización continua de las matrices de transición basadas en datos recientes del mercado para adaptarse a las condiciones cambiantes del mercado.
Conclusión: cómo aprovechar el caos usando la probabilidad
Los mercados financieros se equilibran entre el caos determinista y el orden estocástico. El modelo iterativo de la matriz de cadenas de Márkov representa un compromiso elegante entre el rigor del enfoque estadístico y los matices del análisis técnico.
A diferencia de las "cajas negras" del aprendizaje automático, ofrece una visión totalmente transparente e interpretable de la dinámica del mercado, representando el mercado como un sistema de transiciones probabilísticas entre estados discretos. Este concepto no solo es matemáticamente riguroso, sino también intuitivamente atractivo para los tráders experimentados que naturalmente piensan considerando los modos de mercado y las transiciones entre ellos.
Los resultados obtenidos en el par de divisas EUR/USD demuestran el potencial del modelo para el trading en el mundo real, especialmente cuando se centra en pronósticos de alta confianza. Un mayor desarrollo de este enfoque promete una precisión y versatilidad de aplicación aún mayores.
En última instancia, los modelos de Márkov nos recuerdan que incluso en el aparente caos del mercado, existen ciertas estructuras y patrones. Y aunque el futuro nunca resulta completamente cierto, el pensamiento probabilístico nos proporciona una herramienta para navegar en el océano de la incertidumbre del mercado.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18097
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
¡¡¡Gran trabajo!!! Me gustó especialmente cómo dividiste en precio, tiempo y volumen - es un enfoque muy inteligente. Las pruebas en EUR/USD parecen prometedoras.
Pero, ¿cómo se comportará el modelo durante los cambios bruscos del mercado , como durante Covid? Si la matriz de transición se construyó a partir de datos históricos, ¿cómo podrá adaptarse a condiciones tan extremas?
Sería interesante saber si el modelo se ha probado con otros pares además del EUR/USD. ¿Existe algún mecanismo integrado de adaptación a los cambios bruscos de volatilidad? ¿Tiene previsto tener en cuenta factores fundamentales como las noticias macroeconómicas?