Discusión sobre el artículo "Trading con algoritmos: La IA y su camino hacia las alturas doradas"
Después de leer el artículo, tuve la idea de jugar con el propio proceso de clustering.
Escribí una variante que realiza la agrupación en una ventana deslizante en lugar de en todo el conjunto de datos. Esto puede mejorar la partición de los clusters, teniendo en cuenta la estructura temporal de BP.
def sliding_window_clustering(dataset, n_clusters: int, window_size=200) -> pd.DataFrame: import numpy as np data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] # Primero creamos los centroides de referencia globales global_kmeans = KMeans(n_clusters=n_clusters).fit(meta_X) global_centroids = global_kmeans.cluster_centers_ clusters = np.zeros(len(data)) # Apply clustering in a sliding window for i in range(0, len(data) - window_size + 1, window_size): window_data = meta_X.iloc[i:i+window_size] # Enseñar KMeans en la ventana actual local_kmeans = KMeans(n_clusters=n_clusters).fit(window_data) local_centroids = local_kmeans.cluster_centers_ # Hacer coincidir los centroides locales con los centroides globales # para garantizar la coherencia de las etiquetas de las agrupaciones centroid_mapping = {} for local_idx in range(n_clusters): # Encuentra el centroide global más cercano a este centroide local distances = np.linalg.norm(local_centroids[local_idx] - global_centroids, axis=1) global_idx = np.argmin(distances) centroid_mapping[local_idx] = global_idx + 1 # +1 para empezar a numerar desde 1 # Obtener las etiquetas de la ventana actual local_labels = local_kmeans.predict(window_data) # Convertir las etiquetas locales en etiquetas globales coherentes for j in range(window_size): if i+j < len(clusters): # Checking for out of bounds clusters[i+j] = centroid_mapping[local_labels[j]] data['clusters'] = clusters return data
Inserte esta función en el código y sustituya clustering por sliding_window_clustering.
Parece que mejora los resultados.
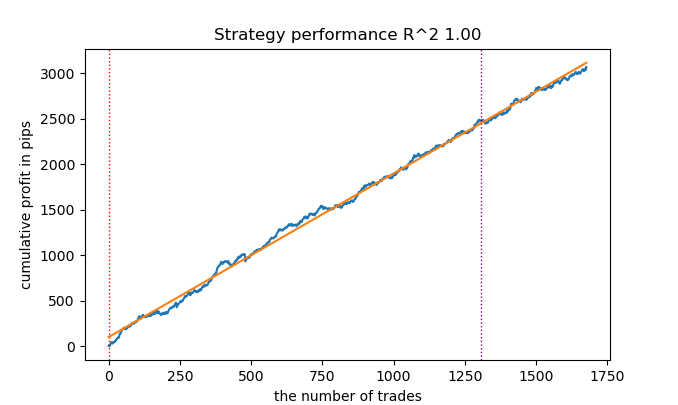
Aún así, a veces es útil escribir artículos.
Gracias por el artículo Dmitrievsky. Parece que el EA cargado y su archivo de inclusión no coinciden entre sí. Se refiere el archivo mpq en la carpeta "tendencia siguiente", pero los archivos de ejemplo estaban en "reversión media".
y la función get_features en el "causal una dirección.py" no son los mismos que lo que aparece en el artículo. Además, el archivo mqh generado por "causal one direction.py" al exportar .onnx no es el mismo que el ofrecido en MQL5_files.zip.
Muy agradecido si puedes hacer las aclaraciones necesarias.
Paul

Gracias por el artículo Dmitrievsky. Parece que el EA cargado y su archivo de inclusión no coinciden entre sí. Se refiere el archivo mpq en la carpeta "tendencia siguiente", pero los archivos de ejemplo estaban en "reversión media".
y la función get_features en el "causal una dirección.py" no son los mismos que lo que aparece en el artículo. Además el fichero mqh generado por "causal one direction.py" al exportar .onnx no es el mismo que el ofrecido en MQL5_files.zip.
Muy agradecido si pueden hacer las aclaraciones necesarias.
Paul
Actualizados los archivos + añadido un nuevo método de agrupación.
Ahora todas las rutas y funciones coinciden.
Así que tienes R2 es un índice modificado, cuya eficiencia se basa en el beneficio en pips. ¿Qué pasa con la reducción y otros indicadores de rendimiento? Si obtenemos un modelo que da más del 90% en el entrenamiento y al menos el 85% en la prueba, entonces su índice dará cifras impresionantes. No importa cuántas veces he ejecutado el probador en MT5, nunca he recibido un beneficio en el historial. El depósito se agota. Esto es a pesar del hecho de que su probador en Python da 0.97-0.98
No entiendo que tiene que ver esto con CV.
Todas estas estrategias tienen bajo poder de prueba, porque se basan sólo en la historia de las cotizaciones no estacionarias. Pero pueden detectar tendencias.- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Trading con algoritmos: La IA y su camino hacia las alturas doradas:
La evolución en la comprensión de las capacidades de los métodos de aprendizaje automático en el trading ha llevado a la creación de diferentes algoritmos que son igual de buenos en la misma tarea, pero fundamentalmente diferentes. En este artículo volveremos a analizar un sistema comercial de tendencia unidireccional utilizando el oro como ejemplo, pero empleando un algoritmo de clusterización.
Al examinar este importante enfoque del análisis y la previsión de series temporales desde distintos ángulos, es posible identificar sus ventajas e inconvenientes en comparación con otras formas de creación de sistemas comerciales basados únicamente en el análisis y la previsión de series temporales financieras. En algunos casos, estos algoritmos resultan bastante eficaces y superan a los enfoques clásicos tanto en velocidad de creación como en la calidad de los sistemas comerciales a la salida.
En este artículo, nos centraremos en el trading unidireccional, en el que el algoritmo solo abrirá operaciones de compra o venta. Utilizaremos los algoritmos CatBoost y K-Means como algoritmos de base. CatBoost es un modelo básico que actúa como clasificador binario para clasificar las transacciones. K-Means, por su parte, se usa para identificar los modos de mercado durante la fase de preprocesamiento.
Autor: dmitrievsky