
Aprendizaje automático y Data Science (Parte 35): NumPy en MQL5, el arte de crear algoritmos complejos con menos código

Contenido
- Introducción
- ¿Por qué NumPy?
- Inicialización de vectores y matrices
- Funciones matemáticas
- Funciones estadísticas
- Generadores de números aleatorios
- - Distribución uniforme
- - Distribución normal
- - Distribución exponencial
- - Distribución binomial
- - Distribución de Poisson
- - Reproducción aleatoria
- - Elección aleatoria
- Transformación rápida de Fourier (Fast Fourier Transform, FFT)
- - Transformadas rápidas de Fourier estandarizadas
- Álgebra lineal
- Polinomios (series de potencias)
- Métodos NumPy de uso común
- Codificación de modelos de ML desde cero
- Conclusión
"Cree que puedes y ya estarás a medio camino."
— Theodore Roosevelt.
Introducción
Ningún lenguaje de programación es totalmente autosuficiente para todas las tareas posibles que se nos ocurran crear mediante código. Todos los lenguajes de programación dependen de herramientas bien diseñadas, como bibliotecas, marcos y módulos, que ayudan a abordar determinados problemas y convertir algunas ideas en realidad.
MQL5 no es una excepción. Diseñado principalmente para el comercio algorítmico, su funcionalidad inicial se limitaba en gran medida a las operaciones comerciales. A diferencia de su predecesor, MQL4, considerado un lenguaje más débil, MQL5 es mucho más potente y capaz. Sin embargo, construir un robot comercial completamente funcional requiere más que simplemente llamar funciones para realizar operaciones de compra y venta.
Para navegar por las complejidades de los mercados financieros, los operadores a menudo implementan operaciones matemáticas sofisticadas que incluyen aprendizaje automático e inteligencia artificial (IA). Esto ha creado una creciente demanda de bases de código optimizadas y marcos especializados que puedan gestionar cálculos complejos de manera eficiente.

¿Por qué NumPy?
Cuando se trata de realizar cálculos complejos en MQL5, disponemos de numerosas bibliotecas de gran calidad proporcionadas por MetaQuotes, como las que se encuentran en Fuzzy, Stat y la potente Alglib (que se encuentra en MetaEditor, en MQL5\Include\Math).
Estas bibliotecas tienen muchas funciones adecuadas para programar asesores expertos complejos con un mínimo esfuerzo; sin embargo, la mayoría de las funciones de estas bibliotecas no son tan flexibles debido al uso excesivo de matrices y punteros de objetos, por no mencionar que algunas requieren conocimientos matemáticos para poder utilizarlas correctamente.
Desde la introducción de matrices y vectores, el lenguaje MQL5 se ha vuelto más versátil y flexible en lo que respecta al almacenamiento de datos y los cálculos. Estas matrices, que tienen la forma de objetos, van acompañadas de numerosas funciones matemáticas integradas que antes requerían implementaciones manuales.
Debido a la flexibilidad de las matrices y los vectores, podemos ampliarlos a algo más grande, creando una colección de diversas funciones matemáticas similares a las presentes en NumPy (Numerical Python, una biblioteca de Python que ofrece una colección de funciones matemáticas de alto nivel, incluyendo soporte para matrices multidimensionales, matrices enmascaradas y matrices).
Es justo decir que la mayoría de las funciones que ofrecen las matrices y los vectores en MQL5 se inspiraron en NumPy, como se puede ver en la documentación, ya que la sintaxis es muy similar.
MQL5 | Python |
|---|---|
vector::Zeros(3); vector::Full(10); | numpy.zeros(3) numpy.full(10) |
Según la documentación, esta sintaxis similar se introdujo para «facilitar la traducción de algoritmos y códigos de Python a MQL5 con el mínimo esfuerzo». Muchas tareas de procesamiento de datos, ecuaciones matemáticas, redes neuronales y tareas de aprendizaje automático pueden resolverse utilizando métodos y bibliotecas de Python ya preparados.
Esto es cierto, pero las funciones que proporcionan las matrices y los vectores no son suficientes. Todavía nos faltan muchas funciones cruciales que a menudo necesitamos para traducir estos algoritmos y códigos de Python a MQL5. En este artículo, implementaremos algunas de las funciones y métodos más útiles de NumPy en MQL5 utilizando una sintaxis muy similar para facilitar la traducción de algoritmos del lenguaje de programación Python.
Para mantener una sintaxis similar a la de Python, implementaremos los nombres de las funciones en minúsculas. Comenzaremos con métodos para inicializar vectores y matrices.
Inicialización de vectores y matrices
Para trabajar con vectores y matrices, necesitamos disponer de métodos para inicializarlos rellenándolos con algunos valores. A continuación se muestran algunas de las funciones para la tarea.
Método | Descripción |
|---|---|
template <typename T> vector CNumpy::full(uint size, T fill_value) { return vector::Full(size, fill_value); } template <typename T> matrix CNumpy::full(uint rows, uint cols, T fill_value) { return matrix::Full(rows, cols, fill_value); } | Construya un nuevo vector/matriz de tamaño/filas y columnas determinadas, rellena con un valor. |
vector CNumpy::ones(uint size) { return vector::Ones(size); } matrix CNumpy::ones(uint rows, uint cols) { return matrix::Ones(rows, cols); } | Construya un nuevo vector de un tamaño dado/matriz de filas y columnas dadas, rellena con unos. |
vector CNumpy::zeros(uint size) { return vector::Zeros(size); } matrix CNumpy::zeros(uint rows, uint cols) { return matrix::Zeros(rows, cols); } | Construya un vector de un tamaño dado/matriz de filas y columnas dadas, rellenas con ceros. |
matrix CNumpy::eye(const uint rows, const uint cols, const int ndiag=0) { return matrix::Eye(rows, cols, ndiag); } | Construya una matriz con unos en la diagonal y ceros en el resto. |
matrix CNumpy::identity(uint rows) { return matrix::Identity(rows, rows); } | Construya una matriz cuadrada con unos en la diagonal principal. |
A pesar de su simplicidad, estos métodos son cruciales para crear matrices y vectores de marcadores de posición que a menudo se utilizan en transformaciones, relleno y aumentos.
Ejemplo de uso:
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Initialization // Vectors One-dimensional Print("numpy.full: ",np.full(10, 2)); Print("numpy.ones: ",np.ones(10)); Print("numpy.zeros: ",np.zeros(10)); // Matrices Two-Dimensional Print("numpy.full:\n",np.full(3,3, 2)); Print("numpy.ones:\n",np.ones(3,3)); Print("numpy.zeros:\n",np.zeros(3,3)); Print("numpy.eye:\n",np.eye(3,3)); Print("numpy.identity:\n",np.identity(3)); }
Funciones matemáticas
Este es un tema amplio ya que hay muchas funciones matemáticas para implementar y describir tanto para vectores como para matrices, y analizaremos solo algunas de ellas. Empezando con constantes matemáticas.
Constantes
Las constantes matemáticas son tan útiles como las funciones.
Constante | Descripción |
|---|---|
numpy.e | Constante de Euler, base de los logaritmos naturales, constante de Napier. |
numpy.euler_gamma | Se define como la diferencia límite entre la serie armónica y el logaritmo natural. |
np.inf | Representación de punto flotante IEEE 754 del infinito (positivo). |
np.nan |
|
| np.pi | Aproximadamente igual a 3,14159, es decir la relación entre la circunferencia de un círculo y su diámetro. |
Ejemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Mathematical functions Print("numpy.e: ",np.e); Print("numpy.euler_gamma: ",np.euler_gamma); Print("numpy.inf: ",np.inf); Print("numpy.nan: ",np.nan); Print("numpy.pi: ",np.pi); }
Funciones
A continuación se muestran algunas de las funciones presentes en la clase CNumpy.
| Método | Descripción |
|---|---|
vector CNumpy::add(const vector&a, const vector&b) { return a+b; }; matrix CNumpy::add(const matrix&a, const matrix&b) { return a+b; }; | Suma dos vectores/matrices. |
vector CNumpy::subtract(const vector&a, const vector&b) { return a-b; }; matrix CNumpy::subtract(const matrix&a, const matrix&b) { return a-b; }; | Resta dos vectores/matrices. |
vector CNumpy::multiply(const vector&a, const vector&b) { return a*b; }; matrix CNumpy::multiply(const matrix&a, const matrix&b) { return a*b; }; | Multiplica dos vectores/matrices. |
vector CNumpy::divide(const vector&a, const vector&b) { return a/b; }; matrix CNumpy::divide(const matrix&a, const matrix&b) { return a/b; }; | Divide dos vectores/matrices |
vector CNumpy::power(const vector&a, double n) { return MathPow(a, n); }; matrix CNumpy::power(const matrix&a, double n) { return MathPow(a, n); }; | Eleva todos los elementos de la matriz/vector a a la potencia n. |
vector CNumpy::sqrt(const vector&a) { return MathSqrt(a); }; matrix CNumpy::sqrt(const matrix&a) { return MathSqrt(a); }; | Calcula la raíz cuadrada de cada elemento del vector/matriz a. |
Ejemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Mathematical functions vector a = {1,2,3,4,5}; vector b = {1,2,3,4,5}; Print("np.add: ",np.add(a, b)); Print("np.subtract: ",np.subtract(a, b)); Print("np.multiply: ",np.multiply(a, b)); Print("np.divide: ",np.divide(a, b)); Print("np.power: ",np.power(a, 2)); Print("np.sqrt: ",np.sqrt(a)); Print("np.log: ",np.log(a)); Print("np.log1p: ",np.log1p(a)); }
Funciones estadísticas
Estas también pueden clasificarse como funciones matemáticas, pero a diferencia de las operaciones matemáticas básicas, estas funciones ayudan a proporcionar métricas analíticas a partir de los datos dados. En el aprendizaje automático, se utilizan principalmente en ingeniería de características y normalización.
La siguiente tabla representa algunas de las funciones implementadas en la clase MQL5-Numpy.
Método | Descripciones |
|---|---|
double sum(const vector& v) { return v.Sum(); } double sum(const matrix& m) { return m.Sum(); }; vector sum(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Sum(axis); }; | Calcula la suma de los elementos del vector/matriz, lo que también se puede realizar para el eje (ejes) dado. |
double mean(const vector& v) { return v.Mean(); } double mean(const matrix& m) { return m.Mean(); }; vector mean(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Mean(axis); }; |
|
double var(const vector& v) { return v.Var(); } double var(const matrix& m) { return m.Var(); }; vector var(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Var(axis); }; |
|
double std(const vector& v) { return v.Std(); } double std(const matrix& m) { return m.Std(); }; vector std(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Std(axis); }; |
|
double median(const vector& v) { return v.Median(); } double median(const matrix& m) { return m.Median(); }; vector median(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Median(axis); }; | Calcula la mediana de los elementos del vector/matriz. |
double percentile(const vector &v, int value) { return v.Percentile(value); } double percentile(const matrix &m, int value) { return m.Percentile(value); } vector percentile(const matrix &m, int value, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Percentile(value, axis); } | Estas funciones calculan el percentil especificado de valores de elementos de un vector/matriz o de elementos a lo largo del eje especificado. |
double quantile(const vector &v, int quantile_) { return v.Quantile(quantile_); } double quantile(const matrix &m, int quantile_) { return m.Quantile(quantile_); } vector quantile(const matrix &m, int quantile_, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Quantile(quantile_, axis); } | Calculan el cuartil especificado de valores de elementos de matriz/vector o de elementos a lo largo del eje especificado. |
vector cumsum(const vector& v) { return v.CumSum(); }; vector cumsum(const matrix& m) { return m.CumSum(); }; matrix cumsum(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.CumSum(axis); }; | Estas funciones calculan la suma acumulada de los elementos de la matriz/vector, incluidos aquellos a lo largo del eje dado. |
vector cumprod(const vector& v) { return v.CumProd(); } vector cumprod(const matrix& m) { return m.CumProd(); }; matrix cumprod(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.CumProd(axis); }; | Devuelven el producto acumulativo de los elementos de la matriz/vector, incluidos aquellos a lo largo del eje dado. |
double average(const vector &v, const vector &weights) { return v.Average(weights); } double average(const matrix &m, const matrix &weights) { return m.Average(weights); } vector average(const matrix &m, const matrix &weights, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Average(weights, axis); } |
|
ulong argmax(const vector& v) { return v.ArgMax(); } ulong argmax(const matrix& m) { return m.ArgMax(); } vector argmax(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.ArgMax(axis); }; | Devuelven el índice del valor máximo. |
ulong argmin(const vector& v) { return v.ArgMin(); } ulong argmin(const matrix& m) { return m.ArgMin(); } vector argmin(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.ArgMin(axis); }; | Devuelven el índice del valor mínimo. |
double min(const vector& v) { return v.Min(); } double min(const matrix& m) { return m.Min(); } vector min(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Min(axis); }; | Devuelven el valor mínimo en un vector/matriz, incluidos aquellos a lo largo del eje especificado. |
double max(const vector& v) { return v.Max(); } double max(const matrix& m) { return m.Max(); } vector max(const matrix& m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Max(axis); }; | Devuelven el valor máximo en un vector/matriz, incluidos aquellos a lo largo del eje especificado. |
double prod(const vector &v, double initial=1.0) { return v.Prod(initial); } double prod(const matrix &m, double initial) { return m.Prod(initial); } vector prod(const matrix &m, double initial, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Prod(axis, initial); } | Devuelven el producto de los elementos de la matriz/vector, lo que también se puede realizar para el eje dado. |
double ptp(const vector &v) { return v.Ptp(); } double ptp(const matrix &m) { return m.Ptp(); } vector ptp(const matrix &m, ENUM_MATRIX_AXIS axis=AXIS_VERT) { return m.Ptp(axis); } | Devuelven el rango de valores de una matriz/vector o del eje de la matriz dada, equivalente a Max() - Min(). Ptp – Peak to peak (De pico a pico). |
Estas funciones se basan en las funciones estadísticas integradas para vectores y matrices, como puede verse en la documentación. Lo único que hice fue crear una sintaxis similar a NumPy y envolver estas funciones.
A continuación se muestra un ejemplo de cómo utilizar estas funciones.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Statistical functions vector z = {1,2,3,4,5}; Print("np.sum: ", np.sum(z)); Print("np.mean: ", np.mean(z)); Print("np.var: ", np.var(z)); Print("np.std: ", np.std(z)); Print("np.median: ", np.median(z)); Print("np.percentile: ", np.percentile(z, 75)); Print("np.quantile: ", np.quantile(z, 75)); Print("np.argmax: ", np.argmax(z)); Print("np.argmin: ", np.argmin(z)); Print("np.max: ", np.max(z)); Print("np.min: ", np.min(z)); Print("np.cumsum: ", np.cumsum(z)); Print("np.cumprod: ", np.cumprod(z)); Print("np.prod: ", np.prod(z)); vector weights = {0.2,0.1,0.5,0.2,0.01}; Print("np.average: ", np.average(z, weights)); Print("np.ptp: ", np.ptp(z)); }
Generadores de números aleatorios
NumPy tiene muchos submódulos útiles, uno de ellos es el submódulo aleatorio.
El submódulo numpy.random proporciona varias funciones de generación de números aleatorios basadas en el generador de números aleatorios PCG64 (a partir de NumPy 1.17+). La mayoría de estos métodos se basan en principios matemáticos de la teoría de la probabilidad y las distribuciones estadísticas.
En el aprendizaje automático, a menudo generamos números aleatorios para muchos casos de uso; generamos números aleatorios como pesos iniciales para redes neuronales y muchos modelos que utilizan métodos iterativos basados en el descenso de gradientes para el entrenamiento, a veces incluso generamos características aleatorias que siguen una distribución estadística para obtener datos de prueba de muestra para nuestros modelos.
Es muy importante que los números aleatorios que generamos sigan una distribución estadística, algo que no podemos lograr utilizando las funciones de generación de números aleatorios nativas/integradas en MQL5.
En primer lugar, así es como se puede establecer la semilla aleatoria para el submódulo CNumpy.random.
np.random.seed(42); Distribución uniforme #
Generamos números aleatorios a partir de una distribución uniforme entre unos valores mínimos y máximos.
Fórmula:
Donde Rtoma un valor aleatorio en el intervalo [0, 1].
template <typename T> vector uniform(T low, T high, uint size=1) { vector res = vector::Zeros(size); for (uint i=0; i<size; i++) res[i] = low + (high - low) * (rand() / double(RAND_MAX)); // Normalize rand() return res; }
Uso.
Dentro del archivo Numpy.mqh, se creó una estructura independiente con el nombre CRandom, que luego se invoca dentro de la clase CNumpy. Esto nos permite invocar una estructura dentro de una clase, lo que nos proporciona una sintaxis similar a la de Python.
class CNumpy { protected: public: CNumpy(void); ~CNumpy(void); CRandom random; }
Print("np.random.uniform: ",np.random.uniform(1,10,10));
Resultados.
2025.03.16 15:03:15.102 Numpy np.random.uniform: [8.906552323984496,9.274605548265022,7.828760643330179,9.355082857753228,2.218420972319712,5.772331919309061,3.76067384868923,6.096438489944151,1.93908505508591,8.107272560808131]
Podemos visualizar los resultados para ver si los datos están distribuidos uniformemente.
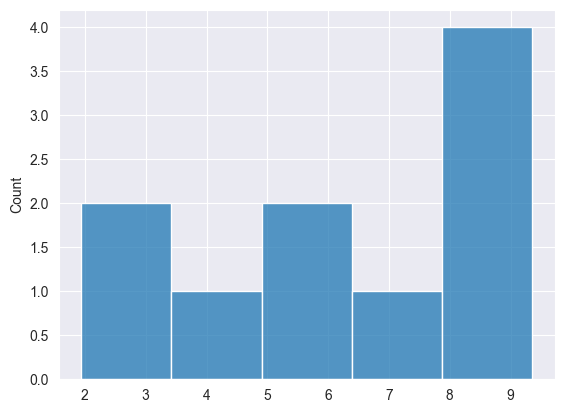
Distribución normal #
Este método se utiliza en muchos modelos de aprendizaje automático, como la inicialización de los pesos de las redes neuronales.
Podemos implementarlo utilizando el método de Box-Muller.
Fórmula:
Donde:
![]() son números aleatorios de [0, 1]
son números aleatorios de [0, 1]
vector normal(uint size, double mean=0, double std=1) { vector results = {}; // Declare the results vector // We generate two random values in each iteration of the loop uint n = size / 2 + size % 2; // If the size is odd, we need one extra iteration // Loop to generate pairs of normal numbers for (uint i = 0; i < n; i++) { // Generate two random uniform variables double u1 = MathRand() / 32768.0; // Uniform [0,1] -> (MathRand() generates values from 0 to 32767) double u2 = MathRand() / 32768.0; // Uniform [0,1] // Apply the Box-Muller transform to get two normal variables double z1 = MathSqrt(-2 * MathLog(u1)) * MathCos(2 * M_PI * u2); double z2 = MathSqrt(-2 * MathLog(u1)) * MathSin(2 * M_PI * u2); // Scale to the desired mean and standard deviation, and add them to the results results = push_back(results, mean + std * z1); if ((uint)results.Size() < size) // Only add z2 if the size is not reached yet results = push_back(results, mean + std * z2); } // Return only the exact size of the results (if it's odd, we cut off one value) results.Resize(size); return results; }
Uso.
Print("np.random.normal: ",np.random.normal(10,0,1));
Resultados.
2025.03.16 15:33:08.791 Numpy test (US Tech 100,H1) np.random.normal: [-1.550635379340936,0.963285267506685,0.4587699653416977,-0.4813064556591148,-0.6919587880027229,1.649030932484221,-2.433415738330552,2.598464400400878,-0.2363726420659525,-0.1131299501178828]
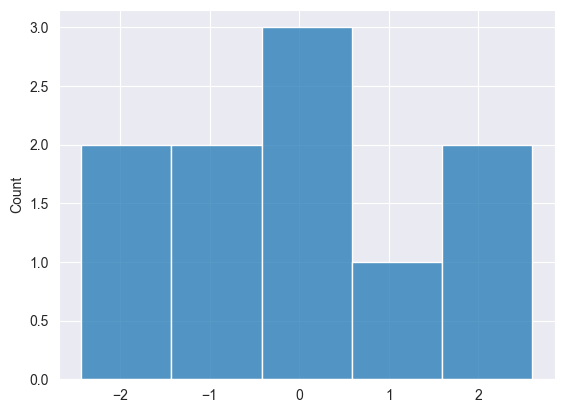
Distribución exponencial #
La distribución exponencial es una distribución de probabilidad que describe el tiempo entre eventos en un proceso de Poisson, en el que los eventos se producen de forma continua e independiente a una tasa media constante.
Dado por la fórmula:
Para generar números aleatorios distribuidos exponencialmente, utilizamos el método de muestreo por transformada inversa. La fórmula es:
Donde:
-
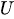 es un número aleatorio uniforme entre 0 y 1.
es un número aleatorio uniforme entre 0 y 1. -
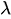 es el parámetro de tasa.
es el parámetro de tasa.
vector exponential(uint size, double lmbda=1.0) { vector res = vector::Zeros(size); for (uint i=0; i<size; i++) res[i] = -log((rand()/RAND_MAX)) / lmbda; return res; }
Uso.
Print("np.random.exponential: ",np.random.exponential(10));
Resultados.
2025.03.16 15:57:36.124 Numpy test (US Tech 100,H1) np.random.exponential: [0.4850272647406031,0.7617651806321184,1.09800210467871,2.658253432915927,0.5814831387699247,0.9920104404467721,0.7427922283035616,0.09323707153463576,0.2963563234048633,1.790326127008611]
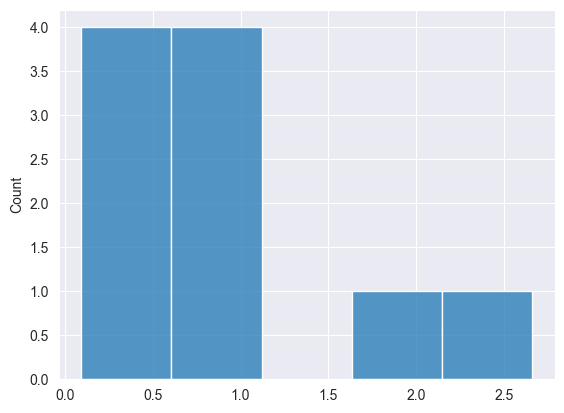
Distribución binomial #
Se trata de una distribución de probabilidad discreta que modela el número de éxitos en un número fijo de ensayos independientes, cada uno con la misma probabilidad de éxito.
Dado por la fórmula.
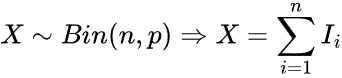
Podemos implementarlo de la siguiente manera.
// Function to generate a single Bernoulli(p) trial int bernoulli(double p) { return (double)rand() / RAND_MAX < p ? 1 : 0; }
// Function to generate Binomial(n, p) samples vector binomial(uint size, uint n, double p) { vector res = vector::Zeros(size); for (uint i = 0; i < size; i++) { int count = 0; for (uint j = 0; j < n; j++) count += bernoulli(p); // Sum of Bernoulli trials res[i] = count; } return res; }
Uso.
Print("np.random.binomial: ",np.random.binomial(10, 5, 0.5));
Resultados.
2025.03.16 19:35:20.346 Numpy test (US Tech 100,H1) np.random.binomial: [2,1,2,3,2,1,1,4,0,3]
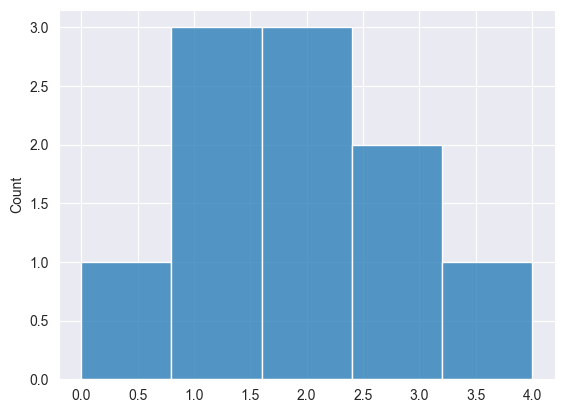
Distribución de Poisson #
Se trata de una distribución de probabilidad que expresa la probabilidad de que se produzca un número determinado de eventos en un intervalo fijo de tiempo o espacio, dado que estos eventos ocurren a una tasa media constante e independientemente del tiempo transcurrido desde el último evento.
Fórmula.
Donde:
-
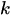 es el número de ocurrencias (0, 1, 2...)
es el número de ocurrencias (0, 1, 2...) -
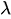 (lambda) es la tasa media de ocurrencias.
(lambda) es la tasa media de ocurrencias. - e es el número de Euler.
int poisson(double lambda) { double L = exp(-lambda); double p = 1.0; int k = 0; while (p > L) { k++; p *= MathRand() / 32767.0; // Normalize MathRand() to (0,1) } return k - 1; // Since we increment k before checking the condition }
// We generate a vector of Poisson-distributed values vector poisson(double lambda, int size) { vector result = vector::Zeros(size); for (int i = 0; i < size; i++) result[i] = poisson(lambda); return result; }
Uso.
Print("np.random.poisson: ",np.random.poisson(4, 10));
Resultados.
2025.03.16 18:39:56.058 Numpy test (US Tech 100,H1) np.random.poisson: [6,6,5,1,3,1,1,3,6,7]
Reproducción aleatoria #
Cuando intentamos entrenar modelos de aprendizaje automático para que comprendan los patrones de los datos, a menudo barajamos las muestras para ayudar a los modelos a comprender los patrones presentes en los datos y no la disposición de los mismos.
La función de reproducción aleatoria resulta muy útil en este tipo de situaciones.
Ejemplo de uso.
vector data = {1,2,3,4,5,6,7,8,9,10}; np.random.shuffle(data); Print("Shuffled: ",data);
Resultados.
2025.03.16 18:55:36.763 Numpy test (US Tech 100,H1) Shuffled: [6,4,9,2,3,10,1,7,8,5]
Elección aleatoria #
De forma similar a la reproducción aleatoria, esta función toma muestras aleatorias de la dimensión 1 dada, pero con la opción de mezclar con o sin reemplazo.
template<typename T> vector<T> choice(const vector<T> &v, uint size, bool replace=false)
Con reemplazo.
Los valores no serán únicos, los mismos elementos pueden repetirse en el vector/matriz aleatorio resultante.
vector data = {1,2,3,4,5,6,7,8,9,10}; Print("np.random.choice replace=True: ",np.random.choice(data, (uint)data.Size(), true));
Resultados.
2025.03.16 19:11:53.520 Numpy test (US Tech 100,H1) np.random.choice replace=True: [5,3,9,2,1,3,4,7,8,3]
Sin reemplazo.
El vector mezclado resultante tendrá elementos únicos, igual que en el vector original, solo que su orden habrá cambiado.
Print("np.random.choice replace=False: ",np.random.choice(data, (uint)data.Size(), false));
Resultados.
2025.03.16 19:11:53.520 Numpy test (US Tech 100,H1) np.random.choice replace=False: [8,4,3,10,5,7,1,9,6,2]
Todas las funciones en un solo lugar.
Ejemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Random numbers generating np.random.seed(42); Print("---------------------------------------:"); Print("np.random.uniform: ",np.random.uniform(1,10,10)); Print("np.random.normal: ",np.random.normal(10,0,1)); Print("np.random.exponential: ",np.random.exponential(10)); Print("np.random.binomial: ",np.random.binomial(10, 5, 0.5)); Print("np.random.poisson: ",np.random.poisson(4, 10)); vector data = {1,2,3,4,5,6,7,8,9,10}; //np.random.shuffle(data); //Print("Shuffled: ",data); Print("np.random.choice replace=True: ",np.random.choice(data, (uint)data.Size(), true)); Print("np.random.choice replace=False: ",np.random.choice(data, (uint)data.Size(), false)); }
Transformación rápida de Fourier (Fast Fourier Transform, FFT) #
Una transformada rápida de Fourier (FFT) es un algoritmo que calcula la transformada discreta de Fourier (DFT) de una secuencia, o su inversa (IDFT). Una transformada de Fourier convierte una señal de su dominio original (a menudo tiempo o espacio) a una representación en el dominio de la frecuencia y viceversa. El DFT se obtiene descomponiendo una secuencia de valores en componentes de diferentes frecuencias. Leer más.
Esta operación es útil en muchos campos, tales como:
- En el procesamiento de señales y audio, se utiliza para convertir ondas sonoras del dominio del tiempo en espectros de frecuencia. En la codificación de los formatos de audio y el filtrado del ruido.
- También se utiliza en la compresión de imágenes y en el reconocimiento de patrones a partir de imágenes.
- Los científicos de datos a menudo utilizan FFT para extraer características de datos de series temporales.
El submódulo numpy.fft es el responsable de gestionar la FFT.
En nuestro CNumpy, tal y como está actualmente, solo he implementado las funciones unidimensionales FFT estándar.
Antes de explorar los métodos «FFT estándar» implementados en la clase, veamos la función para generar frecuencias DFT.
Frecuencia FFT
Al realizar una FFT sobre una señal o datos, el resultado se obtiene en el dominio de la frecuencia. Para interpretarlo, necesitamos saber a qué frecuencia corresponde cada elemento de la FFT. Aquí es donde entra en juego este método.
Esta función devuelve las frecuencias de muestreo de la transformada discreta de Fourier (DFT) asociadas a una FFT de un tamaño determinado. Ayuda a determinar las frecuencias correspondientes para cada coeficiente FFT.
vector fft_freq(int n, double d)
Ejemplo de uso.
2025.03.17 11:11:10.165 Numpy test (US Tech 100,H1) np.fft.fftfreq: [0,0.1,0.2,0.3,0.4,-0.5,-0.4,-0.3,-0.2,-0.1]
Transformadas rápidas de Fourier estandarizadas #
FFT
Esta función calcula la FFT de una señal de entrada, convirtiéndola del dominio del tiempo al dominio de la frecuencia. Es un algoritmo eficiente para calcular la transformada discreta de Fourier (DFT).
vector<complex> fft(const vector &x)
Esta función se basa en CFastFourierTransform::FFTR1D, una función proporcionada por ALGLIB. Consulte ALGLIB para obtener más información.
Ejemplo de uso.
vector signal = {0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}; Print("np.fft.fft: ",np.fft.fft(signal));
Resultado.
2025.03.17 11:28:16.739 Numpy test (US Tech 100,H1) np.fft.fft: [(4.5,0),(-0.4999999999999999,1.538841768587627),(-0.4999999999999999,0.6881909602355869),(-0.5000000000000002,0.3632712640026804),(-0.5000000000000002,0.1624598481164532),(-0.5,-3.061616997868383E-16),(-0.5000000000000002,-0.1624598481164532),(-0.5000000000000002,-0.3632712640026804),(-0.4999999999999999,-0.6881909602355869),(-0.4999999999999999,-1.538841768587627)]
FFT inversa
Esta función calcula la transformada rápida de Fourier inversa (IFFT), que convierte los datos del dominio de frecuencia de nuevo al dominio del tiempo. Básicamente, anula el efecto del método anterior np.fft.fft.
vector ifft(const vectorc &fft_values)
Ejemplo de uso.
vector signal = {0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}; vectorc fft_res = np.fft.fft(signal); //perform fft Print("np.fft.fft: ",fft_res); //fft results Print("np.fft.ifft: ",np.fft.ifft(fft_res)); //Original signal
Resultados.
2025.03.17 11:45:04.537 Numpy test np.fft.fft: [(4.5,0),(-0.4999999999999999,1.538841768587627),(-0.4999999999999999,0.6881909602355869),(-0.5000000000000002,0.3632712640026804),(-0.5000000000000002,0.1624598481164532),(-0.5,-3.061616997868383E-16),(-0.5000000000000002,-0.1624598481164532),(-0.5000000000000002,-0.3632712640026804),(-0.4999999999999999,-0.6881909602355869),(-0.4999999999999999,-1.538841768587627)] 2025.03.17 11:45:04.537 Numpy test np.fft.ifft: [-4.440892098500626e-17,0.09999999999999991,0.1999999999999999,0.2999999999999999,0.4,0.5,0.6,0.7,0.8000000000000002,0.9]
Álgebra lineal #
El álgebra lineal es una rama de las matemáticas que se ocupa de vectores, matrices y transformaciones lineales. Es fundamental para muchos campos, como la física, la ingeniería, la ciencia de datos, etc.
NumPy proporciona el módulo np.linalg, un submódulo dedicado a las funciones de álgebra lineal. Ofrece casi todas las funciones para álgebra lineal, como resolver sistemas lineales, calcular valores y vectores propios, y mucho más.
A continuación se muestran algunas de las funciones de álgebra lineal implementadas en la clase CNumpy.
Método | Descripción |
|---|---|
matrix inv(const matrix &m) { return m.Inv(); } | Calcula la inversa multiplicativa de una matriz cuadrada invertible mediante el método de Jordan-Gauss. |
double det(const matrix &m) { return m.Det(); } | Calcula el determinante de una matriz cuadrada invertible. |
matrix kron(const matrix &a, const matrix &b) { return a.Kron(b); } matrix kron(const vector &a, const vector &b) { return a.Kron(b); } matrix kron(const vector &a, const matrix &b) { return a.Kron(b); } matrix kron(const matrix &a, const vector &b) { return a.Kron(b); } | Calculan el producto de Kronecker de dos matrices, una matriz y un vector, un vector y una matriz o dos vectores. |
struct eigen_results_struct { vector eigenvalues; matrix eigenvectors; }; eigen_results_struct eig(const matrix &m) { eigen_results_struct res; if (!m.Eig(res.eigenvectors, res.eigenvalues)) printf("%s failed to calculate eigen vectors and values, error = %d",__FUNCTION__,GetLastError()); return res; } | Esta función calcula los valores propios y los vectores propios de una matriz cuadrada. |
double norm(const matrix &m, ENUM_MATRIX_NORM norm) { return m.Norm(norm); } double norm(const vector &v, ENUM_VECTOR_NORM norm) { return v.Norm(norm); } | Devuelve la norma de la matriz o del vector. Más información. |
svd_results_struct svd(const matrix &m) { svd_results_struct res; if (!m.SVD(res.U, res.V, res.singular_vectors)) printf("%s failed to calculate the SVD"); return res; } | Calcula la descomposición en valores singulares (Singular Value Decomposition, SVD). |
vector solve(const matrix &a, const vector &b) { return a.Solve(b); } | Resuelve una ecuación matricial lineal o un sistema de ecuaciones algebraicas lineales. |
vector lstsq(const matrix &a, const vector &b) { return a.LstSq(b); } | Calcula la solución de mínimos cuadrados de ecuaciones algebraicas lineales (para matrices no cuadradas o degeneradas). |
ulong matrix_rank(const matrix &m) { return m.Rank(); } | Esta función calcula el rango de una matriz, que es el número de filas o columnas linealmente independientes en la matriz. Es un concepto clave para comprender el espacio de soluciones de un sistema de ecuaciones lineales. |
matrix cholesky(const matrix &m) { vector values = eig(m).eigenvalues; for (ulong i=0; i<values.Size(); i++) { if (values[i]<=0) { printf("%s Failed Matrix is not positive definite",__FUNCTION__); return matrix::Zeros(0,0); } } matrix L; if (!m.Cholesky(L)) printf("%s Failed, Error = %d",__FUNCTION__, GetLastError()); return L; } | La descomposición de Cholesky se utiliza para factorizar una matriz definida positiva en el producto de una matriz triangular inferior y su transpuesta. |
matrix matrix_power(const matrix &m, uint exponent) { return m.Power(exponent); } | Calcula la matriz elevada a una potencia entera específica. Más formalmente, calcula |
Ejemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Linear algebra matrix m = {{1,1,10}, {1,0.5,1}, {1.5,1,0.78}}; Print("np.linalg.inv:\n",np.linalg.inv(m)); Print("np.linalg.det: ",np.linalg.det(m)); Print("np.linalg.det: ",np.linalg.kron(m, m)); Print("np.linalg.eigenvalues:",np.linalg.eig(m).eigenvalues," eigenvectors: ",np.linalg.eig(m).eigenvectors); Print("np.linalg.norm: ",np.linalg.norm(m, MATRIX_NORM_P2)); Print("np.linalg.svd u:\n",np.linalg.svd(m).U, "\nv:\n",np.linalg.svd(m).V); matrix a = {{1,1,10}, {1,0.5,1}, {1.5,1,0.78}}; vector b = {1,2,3}; Print("np.linalg.solve ",np.linalg.solve(a, b)); Print("np.linalg.lstsq: ", np.linalg.lstsq(a, b)); Print("np.linalg.matrix_rank: ", np.linalg.matrix_rank(a)); Print("cholesky: ", np.linalg.cholesky(a)); Print("matrix_power:\n", np.linalg.matrix_power(a, 2)); }
Polinomios (series de potencias) #
El submódulo numpy.polynomial proporciona un conjunto de potentes herramientas para crear, evaluar, diferenciar, integrar y manipular polinomios. Es más estable numéricamente que usar numpy.poly1d para operaciones polinómicas.
Hay diferentes tipos de polinomios en la biblioteca NumPy del lenguaje de programación Python, pero en nuestra clase CNumpy-MQL5, actualmente he implementado una base de potencia estándar (Polinomio).
class CPolynomial: protected CNumpy { protected: vector m_coeff; matrix vector21DMatrix(const vector &v) { matrix res = matrix::Zeros(v.Size(), 1); for (ulong r=0; r<v.Size(); r++) res[r][0] = v[r]; return res; } public: CPolynomial(void); CPolynomial(vector &coefficients); //for loading pre-trained model ~CPolynomial(void); vector fit(const vector &x, const vector &y, int degree); }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CPolynomial::CPolynomial(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CPolynomial::~CPolynomial(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CPolynomial::CPolynomial(vector &coefficients): m_coeff(coefficients) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CPolynomial::fit(const vector &x, const vector &y, int degree) { //Constructing the vandermonde matrix matrix X = vander(x, degree+1, true); matrix temp1 = X.Transpose().MatMul(X); matrix temp2 = X.Transpose().MatMul(vector21DMatrix(y)); matrix coef_m = linalg.inv(temp1).MatMul(temp2); return (this.m_coeff = flatten(coef_m)); }
Ejemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Polynomial vector X = {0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}; vector y = MathPow(X, 3) + 0.2 * np.random.randn(10); // Cubic function with noise CPolynomial poly; Print("coef: ", poly.fit(X, y, 3)); }
Resultados.
2025.03.17 14:01:43.026 Numpy test (US Tech 100,H1) coef: [-0.1905916844269999,2.3719065699851,-5.625684489899982,4.749058310806731]
Además, existen funciones auxiliares para facilitar la manipulación de polinomios, ubicadas en la clase principal CNumpy. Estas funciones incluyen:
Función | Descripción |
|---|---|
vector polyadd(const vector &p, const vector &q); | Suma dos polinomios alineándolos según su grado (longitud de los coeficientes). Si un polinomio es más corto, se rellena con ceros antes de realizar la suma. |
vector polysub(const vector &p, const vector &q); | Resta dos polinomios. |
vector polymul(const vector &p, const vector &q); | Multiplica dos polinomios utilizando la propiedad distributiva, cada término de p se multiplica por cada término de q y los resultados se suman. |
vector polyder(const vector &p, int m=1); | Calcula las derivadas del polinomio p, la derivada se calcula aplicando la regla estándar para derivadas. Cada término |
vector polyint(const vector &p, int m=1, double k=0.0) | Calcula la integral de la polinomio p, la integral de cada término |
double polyval(const vector &p, double x); | Evalúa el polinomio en un valor específico x sumando los términos del polinomio, donde cada término se calcula como |
struct polydiv_struct { vector quotient, remainder; }; polydiv_struct polydiv(const vector &p, const vector &q); | Esta función divide dos polinomios y devuelve el cociente y el resto. |
Ejemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Polynomial utils vector p = {1,-3, 2}; vector q = {2,-4, 1}; Print("polyadd: ",np.polyadd(p, q)); Print("polysub: ",np.polysub(p, q)); Print("polymul: ",np.polymul(p, q)); Print("polyder:", np.polyder(p)); Print("polyint:", np.polyint(p)); // Integral of polynomial Print("plyval x=2: ", np.polyval(p, 2)); // Evaluate polynomial at x = 2 Print("polydiv:", np.polydiv(p, q).quotient," ",np.polydiv(p, q).remainder); }
Otros métodos NumPy de uso común
Es difícil clasificar todos los métodos de NumPy, a continuación se muestran algunas de las funciones más útiles de la clase que aún no hemos comentado.
Método | Descripción |
|---|---|
vector CNumpy::arange(uint stop) vector CNumpy::arange(int start, int stop, int step) | La primera función crea un vector con un rango de valores en un intervalo especificado. La segunda variante hace lo mismo pero considera el paso para incrementar los valores. Estas dos funciones son útiles para generar un vector de algún número en orden ascendente. |
vector CNumpy::flatten(const matrix &m) vector CNumpy::ravel(const matrix &m) { return flatten(m); }; | Transforman una matriz 2D en un vector 1D. A menudo terminamos con una matriz de quizás una fila y una columna que necesitamos convertir en un vector para facilitar su uso. |
matrix CNumpy::reshape(const vector &v,uint rows,uint cols) | Reforma un vector 1D en una matriz de filas y columnas (cols). |
matrix CNumpy::reshape(const matrix &m,uint rows,uint cols) | Reforma una matriz 2D en una nueva forma (filas y columnas). |
matrix CNumpy::expand_dims(const vector &v, uint axis) | Añade un nuevo eje al vector 1D, convirtiéndolo efectivamente en una matriz. |
vector CNumpy::clip(const vector &v,double min,double max) | Recorta los valores de un vector para que estén dentro de un rango especificado (entre mín. y máx.), lo que resulta útil para reducir valores extremos y mantener el vector dentro del rango deseado. |
vector CNumpy::argsort(const vector<T> &v) | Devuelve índices que ordenarían una matriz. |
vector CNumpy::sort(const vector<T> &v) | Ordena una matriz en orden ascendente. |
vector CNumpy::concat(const vector &v1, const vector &v2); vector CNumpy::concat(const vector &v1, const vector &v2, const vector &v3); | Concatena más de un vector en un vector masivo. |
matrix CNumpy::concat(const matrix &m1, const matrix &m2, ENUM_MATRIX_AXIS axis = AXIS_VERT) | Cuando axis=0 concatena la matriz a lo largo de las filas (apila las matrices m1 con m2 horizontalmente). Cuando axis=1 concatena la matriz a lo largo de las columnas (apila las matrices m1 con m2 verticalmente). |
matrix CNumpy::concat(const matrix &m, const vector &v, ENUM_MATRIX_AXIS axis = AXIS_VERT) | Si axis = 0, añade el vector como una nueva fila (solo si su tamaño coincide con el número de columnas de la matriz). Si axis = 1, añade el vector como una nueva columna (solo si su tamaño coincide con el número de filas de la matriz). |
matrix CNumpy::dot(const matrix& a, const matrix& b); double CNumpy::dot(const vector& a, const vector& b); matrix CNumpy::dot(const matrix& a, const vector& b); | Calculan el producto escalar (también conocido como producto interno) de dos matrices, vectores o una matriz y un vector. |
vector CNumpy::linspace(int start,int stop,uint num,bool endpoint=true) | Crea una matriz de números espaciados uniformemente en un rango especificado (inicio, fin). num = Número de muestras que se van a generar. endpoint (predeterminado=true), se incluye la parada; si se establece en false, se excluye la parada. |
struct unique_struct { vector unique, count; }; unique_struct CNumpy::unique(const vector &v) | Devuelve los elementos únicos (unique) de un vector y el número de veces que aparecen (count). |
Ejemplo de uso.
#include <MALE5\Numpy\Numpy.mqh> CNumpy np; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Common methods vector v = {1,2,3,4,5,6,7,8,9,10}; Print("------------------------------------"); Print("np.arange: ",np.arange(10)); Print("np.arange: ",np.arange(1, 10, 2)); matrix m = { {1,2,3,4,5}, {6,7,8,9,10} }; Print("np.flatten: ",np.flatten(m)); Print("np.ravel: ",np.ravel(m)); Print("np.reshape: ",np.reshape(v, 5, 2)); Print("np.reshape: ",np.reshape(m, 2, 3)); Print("np.expnad_dims: ",np.expand_dims(v, 1)); Print("np.clip: ", np.clip(v, 3, 8)); //--- Sorting Print("np.argsort: ",np.argsort(v)); Print("np.sort: ",np.sort(v)); //--- Others matrix z = { {1,2,3}, {4,5,6}, {7,8,9}, }; Print("np.concatenate: ",np.concat(v, v)); Print("np.concatenate:\n",np.concat(z, z, AXIS_HORZ)); vector y = {1,1,1}; Print("np.concatenate:\n",np.concat(z, y, AXIS_VERT)); Print("np.dot: ",np.dot(v, v)); Print("np.dot:\n",np.dot(z, z)); Print("np.linspace: ",np.linspace(1, 10, 10, true)); Print("np.unique: ",np.unique(v).unique, " count: ",np.unique(v).count); }
Resultados.
NJ 0 16:34:01.702 Numpy test (US Tech 100,H1) ------------------------------------ PL 0 16:34:01.703 Numpy test (US Tech 100,H1) np.arange: [0,1,2,3,4,5,6,7,8,9] LG 0 16:34:01.703 Numpy test (US Tech 100,H1) np.arange: [1,3,5,7,9] QR 0 16:34:01.703 Numpy test (US Tech 100,H1) np.flatten: [1,2,3,4,5,6,7,8,9,10] QO 0 16:34:01.703 Numpy test (US Tech 100,H1) np.ravel: [1,2,3,4,5,6,7,8,9,10] EF 0 16:34:01.703 Numpy test (US Tech 100,H1) np.reshape: [[1,2] NL 0 16:34:01.703 Numpy test (US Tech 100,H1) [3,4] NK 0 16:34:01.703 Numpy test (US Tech 100,H1) [5,6] NQ 0 16:34:01.703 Numpy test (US Tech 100,H1) [7,8] HF 0 16:34:01.703 Numpy test (US Tech 100,H1) [9,10]] HD 0 16:34:01.703 Numpy test (US Tech 100,H1) np.reshape: [[1,2,3] QD 0 16:34:01.703 Numpy test (US Tech 100,H1) [4,5,6]] OH 0 16:34:01.703 Numpy test (US Tech 100,H1) np.expnad_dims: [[1,2,3,4,5,6,7,8,9,10]] PK 0 16:34:01.703 Numpy test (US Tech 100,H1) np.clip: [3,3,3,4,5,6,7,8,8,8] FM 0 16:34:01.703 Numpy test (US Tech 100,H1) np.argsort: [0,1,2,3,4,5,6,7,8,9] KD 0 16:34:01.703 Numpy test (US Tech 100,H1) np.sort: [1,2,3,4,5,6,7,8,9,10] FQ 0 16:34:01.703 Numpy test (US Tech 100,H1) np.concatenate: [1,2,3,4,5,6,7,8,9,10,1,2,3,4,5,6,7,8,9,10] FS 0 16:34:01.703 Numpy test (US Tech 100,H1) np.concatenate: PK 0 16:34:01.703 Numpy test (US Tech 100,H1) [[1,2,3] DM 0 16:34:01.703 Numpy test (US Tech 100,H1) [4,5,6] CJ 0 16:34:01.703 Numpy test (US Tech 100,H1) [7,8,9] IS 0 16:34:01.703 Numpy test (US Tech 100,H1) [1,2,3] DH 0 16:34:01.703 Numpy test (US Tech 100,H1) [4,5,6] PL 0 16:34:01.703 Numpy test (US Tech 100,H1) [7,8,9]] FQ 0 16:34:01.703 Numpy test (US Tech 100,H1) np.concatenate: CH 0 16:34:01.703 Numpy test (US Tech 100,H1) [[1,2,3,1] KN 0 16:34:01.703 Numpy test (US Tech 100,H1) [4,5,6,1] KH 0 16:34:01.703 Numpy test (US Tech 100,H1) [7,8,9,1]] JR 0 16:34:01.703 Numpy test (US Tech 100,H1) np.dot: 385.0 PK 0 16:34:01.703 Numpy test (US Tech 100,H1) np.dot: JN 0 16:34:01.703 Numpy test (US Tech 100,H1) [[30,36,42] OH 0 16:34:01.703 Numpy test (US Tech 100,H1) [66,81,96] RN 0 16:34:01.703 Numpy test (US Tech 100,H1) [102,126,150]] RI 0 16:34:01.703 Numpy test (US Tech 100,H1) np.linspace: [1,2,3,4,5,6,7,8,9,10] MQ 0 16:34:01.703 Numpy test (US Tech 100,H1) np.unique: [1,2,3,4,5,6,7,8,9,10] count: [1,1,1,1,1,1,1,1,1,1]
Codificación de modelos de aprendizaje automático desde cero utilizando MQL5-NumPy
Como expliqué anteriormente, la biblioteca NumPy es la columna vertebral de muchos modelos de aprendizaje automático que se implementan en el lenguaje de programación Python, debido a la presencia de una gran cantidad de métodos que ayudan con matrices, matrices, matemáticas básicas e incluso álgebra lineal. Ahora que tenemos un cierre similar en MQL5, intentemos utilizarlo para implementar un modelo sencillo de aprendizaje automático desde cero.
Utilizando un modelo de regresión lineal como ejemplo.
Encontré este código en Internet, es un modelo de regresión lineal que utiliza el descenso de gradiente en su función de entrenamiento.
import numpy as np from sklearn.metrics import mean_squared_error, r2_score class LinearRegression: def __init__(self, learning_rate=0.01, epochs=1000): self.learning_rate = learning_rate self.epochs = epochs self.weights = None self.bias = None def fit(self, X, y): """ Train the Linear Regression model using Gradient Descent. X: Input features (numpy array of shape [n_samples, n_features]) y: Target values (numpy array of shape [n_samples,]) """ n_samples, n_features = X.shape self.weights = np.zeros(n_features) self.bias = 0 for _ in range(self.epochs): y_pred = np.dot(X, self.weights) + self.bias # Predictions # Compute Gradients dw = (1 / n_samples) * np.dot(X.T, (y_pred - y)) db = (1 / n_samples) * np.sum(y_pred - y) # Update Parameters self.weights -= self.learning_rate * dw self.bias -= self.learning_rate * db def predict(self, X): """ Predict output for the given input X. """ return np.dot(X, self.weights) + self.bias # Example Usage if __name__ == "__main__": # Sample Data (X: Input features, y: Target values) X = np.array([[1], [2], [3], [4], [5]]) # Feature y = np.array([2, 4, 6, 8, 10]) # Target (y = 2x) # Create and Train Model model = LinearRegression(learning_rate=0.01, epochs=1000) model.fit(X, y) # Predictions y_pred = model.predict(X) # Evaluate Model print("Predictions:", y_pred) print("MSE:", mean_squared_error(y, y_pred)) print("R² Score:", r2_score(y, y_pred))
Salida de la celda.
Predictions: [2.06850809 4.04226297 6.01601785 7.98977273 9.96352761] MSE: 0.0016341843485627612 R² Score: 0.9997957269564297
Preste atención a la función de ajuste, tenemos un par de métodos NumPy en la función de entrenamiento. Como también tenemos estas mismas funciones en CNumpy, hagamos la misma implementación en MQL5.
#include <MALE5\Numpy\Numpy.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- // Sample Data (X: Input features, y: Target values) matrix X = {{1}, {2}, {3}, {4}, {5}}; vector y = {2, 4, 6, 8, 10}; // Create and Train Model CLinearRegression model(0.01, 1000); model.fit(X, y); // Predictions vector y_pred = model.predict(X); // Evaluate Model Print("Predictions: ", y_pred); Print("MSE: ", y_pred.RegressionMetric(y, REGRESSION_MSE)); Print("R² Score: ", y_pred.RegressionMetric(y_pred, REGRESSION_R2)); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CLinearRegression { protected: CNumpy np; double m_learning_rate; uint m_epochs; vector weights; double bias; public: CLinearRegression(double learning_rate=0.01, uint epochs=1000); ~CLinearRegression(void); void fit(const matrix &x, const vector &y); vector predict(const matrix &X); }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CLinearRegression::CLinearRegression(double learning_rate=0.01, uint epochs=1000): m_learning_rate(learning_rate), m_epochs(epochs) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CLinearRegression::~CLinearRegression(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CLinearRegression::fit(const matrix &x, const vector &y) { ulong n_samples = x.Rows(), n_features = x.Cols(); this.weights = np.zeros((uint)n_features); this.bias = 0.0; //--- for (uint i=0; i<m_epochs; i++) { matrix temp = np.dot(x, this.weights); vector y_pred = np.flatten(temp) + bias; // Compute Gradients temp = np.dot(x.Transpose(), (y_pred - y)); vector dw = (1.0 / (double)n_samples) * np.flatten(temp); double db = (1.0 / (double)n_samples) * np.sum(y_pred - y); // Update Parameters this.weights -= this.m_learning_rate * dw; this.bias -= this.m_learning_rate * db; } } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CLinearRegression::predict(const matrix &X) { matrix temp = np.dot(X, this.weights); return np.flatten(temp) + this.bias; }
Resultados.
RD 0 18:15:22.911 Linear regression from scratch (US Tech 100,H1) Predictions: [2.068508094061713,4.042262972785917,6.01601785151012,7.989772730234324,9.963527608958529] KH 0 18:15:22.911 Linear regression from scratch (US Tech 100,H1) MSE: 0.0016341843485627612 RQ 0 18:15:22.911 Linear regression from scratch (US Tech 100,H1) R² Score: 1.0
Genial, obtuvimos los mismos resultados de este modelo que los que obtuvimos en el código Python.
¿Y ahora qué?
Tienes una potente biblioteca y una colección de métodos valiosos que se han utilizado para construir innumerables algoritmos estadísticos y de aprendizaje automático en el lenguaje de programación Python, nada te impide codificar sofisticados robots comerciales equipados con cálculos complejos como los que a menudo ves en Python.
Tal como está actualmente, la biblioteca aún carece de la mayoría de las funciones, ya que me llevaría meses escribir todo, así que siéntete libre de agregar una propia; las funciones presentes en el interior son las que uso a menudo o que deseo usar mientras trabajo con algoritmos ML en MQL5.
La sintaxis de Python en MQL5 a veces puede resultar confusa, así que no dudes en modificar los nombres de las funciones según lo que sea adecuado para ti.
Paz.
Tabla de archivos adjuntos
| Nombre del archivo | Descripción |
|---|---|
| Include\Numpy.mqh | Clon de NumPy MQL5. Todos los métodos de NumPy para MQL5 se pueden encontrar en este archivo. |
| Scripts\Linear regression from scratch.mq5 | Script donde se implementa el ejemplo de regresión lineal utilizando CNumpy. |
| Scripts\Numpy test.mq5 | Script que llama a todos los métodos de Numpy.mqh para fines de prueba. Es un entorno de pruebas para todos los métodos descritos en este artículo. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/17469
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso