Aprendizaje automático y Data Science (Parte 39): Noticias + Inteligencia artificial, ¿apostarías por ella?

Contenido
- Introducción
- Recopilando las noticias
- Preparación de datos de noticias para el entrenamiento de modelos de IA
- Entrenamiento de un modelo de IA con datos de noticias
- Noticias + Robot de trading con IA
- Conclusión
Introducción
Probablemente ya lo haya oído: los mercados financieros y de divisas se ven impulsados y afectados por las noticias, especialmente por publicaciones importantes como las «Non-Farm Payrolls» (NFP). Esta afirmación es cierta, ya que las noticias describen acontecimientos que suceden en el mundo real.
Las noticias financieras suelen incluir informes económicos, anuncios corporativos, acontecimientos geopolíticos y comunicaciones de los bancos centrales. Con frecuencia, cuando se producen estas noticias (unos instantes antes o después), se genera volatilidad y oportunidades de trading en activos y símbolos relacionados.
Dado que las noticias describen lo que sucede en el mundo en una región o país específico y los resultados previstos, son uno de los mejores predictores de los mercados financieros. Por ejemplo, en el par EUR/USD, un aumento del IPC, reflejado en las noticias sobre el IPC subyacente para el euro, podría generar una subida del euro, ya que suele aumentar las expectativas de una política monetaria más restrictiva (subidas de tipos de interés), y también podría provocar una caída del dólar estadounidense.
A diferencia de noticias como los anuncios corporativos y los informes económicos, que pueden tener un impacto en cualquier dirección en los mercados, algunas noticias, como los desastres naturales, tienden a impactar negativamente y a perturbar principalmente los mercados de divisas y las acciones.
Para convertirnos en operadores exitosos, no debemos depender demasiado del aspecto técnico del mercado, sino que también debemos estar atentos a las noticias, ya que son uno de los principales impulsores de los mercados financieros.

Dicho esto, sabemos que las noticias son uno de los factores más importantes, si no el más importante, que influyen en los mercados. En este artículo, utilizaremos la información de noticias que ofrece MetaTrader 5 para los modelos de IA y veremos si esta poderosa combinación es realmente efectiva en el trading algorítmico.
Recopilación de noticias
Este es el primer proceso que debemos realizar en nuestro proyecto.
Recopilar las noticias puede ser un proceso complejo y delicado; hay varios aspectos que debemos considerar cuidadosamente, entre ellos, el plazo para la recopilación de datos, el instrumento (símbolo) y el manejo de la presencia de variables vacías o que no son números (NaN).
A continuación se muestra la estructura de datos que contiene las variables que utilizaremos para almacenar la información noticiosa que vamos a recopilar.
struct news_data_struct { datetime time[]; //News release time string name[]; //Name of the news ENUM_CALENDAR_EVENT_SECTOR sector[]; //The sector a news is related to ENUM_CALENDAR_EVENT_IMPORTANCE importance[]; //Event importance double actual[]; //actual value double forecast[]; //forecast value double previous[]; //previous value }
Esta estructura representa algunos de los atributos de noticias proporcionados por MqlCalendarEvent y MqlCalendarValue.
A continuación se muestra cómo recopilamos las noticias iterando a través de varias barras en el historial para obtenerlas.
//--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price infromation from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } }
Si bien este código nos proporciona las noticias que queremos, también necesitamos recopilar los valores de Apertura, Máximo, Mínimo y Cierre (OHLC) en el momento de la publicación de la noticia. Estos valores serán útiles para el análisis y a la hora de definir la variable objetivo para el aprendizaje automático supervisado.
También necesitamos la funcionalidad para guardar esta información en un archivo CSV para su uso externo.
A continuación se muestra la función completa para recopilar las noticias.
void SaveNews(string csv_name) { //--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price infromation from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } uint size = rates.Size(); news_data.Resize(size-1); //--- FileDelete(csv_name); //Delete an existing csv file of a given name int csv_handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI,",",CP_UTF8); //csv handle if(csv_handle == INVALID_HANDLE) { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return; //stop the process } FileSeek(csv_handle,0,SEEK_SET); //go to file begining FileWrite(csv_handle,"Time,Open,High,Low,Close,Name,Sector,Importance,Actual,Forecast,Previous"); //write csv header MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { news_data.time[i] = rates[i].time; news_data.open[i] = rates[i].open; news_data.high[i] = rates[i].high; news_data.low[i] = rates[i].low; news_data.close[i] = rates[i].close; int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } } FileWrite(csv_handle,StringFormat("%s,%f,%f,%f,%f,%s,%s,%s,%f,%f,%f", (string)news_data.time[i], news_data.open[i], news_data.high[i], news_data.low[i], news_data.close[i], news_data.name[i], EnumToString(news_data.sector[i]), EnumToString(news_data.importance[i]), news_data.actual[i], news_data.forecast[i], news_data.previous[i] )); } //--- FileClose(csv_handle); }
El proceso de guardar la información en un archivo CSV se realiza fuera del bucle para que también se conserven las barras en las que no hubo noticias. Esto es importante porque necesitamos esos intervalos sin noticias para evaluar el impacto de las noticias antes y después de que se hayan producido.
He fijado la fecha de inicio en el 1 de enero de 2023 y la fecha de finalización en el 31 de diciembre de 2023, lo que equivale a un año completo de noticias y otros datos de trading.
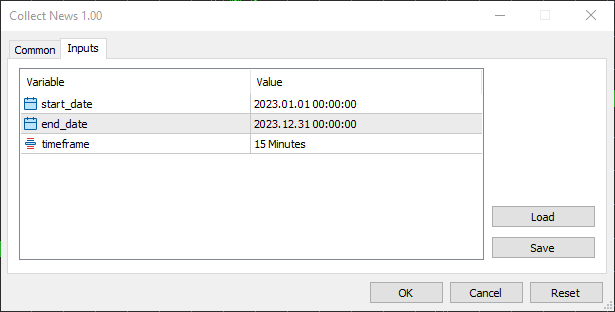
Elegí el intervalo de 15 minutos porque es el que veo que utilizan la mayoría de los operadores a la hora de crear filtros de noticias y de aplicar estrategias basadas en las noticias en general. Se trata de un equilibrio óptimo entre captar las reacciones significativas de los precios tras las noticias y filtrar el ruido del mercado que puede observarse en intervalos de tiempo inferiores a los 15 minutos.
Preparación de datos de noticias para el entrenamiento de modelos de IA
Dentro de un script de Python (Jupyter Notebook), comenzamos importando el archivo CSV que contiene los datos de las noticias.
df = pd.read_csv("/kaggle/input/nfp-forexdata/EURUSD.PERIOD_M15.News.csv") df.head(5)
Resultados.
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06976 | 1.06933 | 1.06935 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 1 | 2023.01.02 01:15:00 | 1.06934 | 1.06947 | 1.06927 | 1.06938 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 2 | 2023.01.02 01:30:00 | 1.06939 | 1.06943 | 1.06939 | 1.06942 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 3 | 2023.01.02 01:45:00 | 1.06943 | 1.06983 | 1.06942 | 1.06983 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 4 | 2023.01.02 02:00:00 | 1.06984 | 1.06989 | 1.06984 | 1.06989 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
Dado que los datos de noticias siempre están asociados con valores NaN en los valores reales, anteriores y previstos. Debemos comprobar expresamente si se ha colado algún valor NaN en el archivo CSV, a pesar de que el script MQL5 «Collect News» cuenta con comprobaciones para garantizar que no se inserten valores NaN en el archivo.
df.info()
Resultados.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 24848 entries, 0 to 24847 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Time 24848 non-null object 1 Open 24848 non-null float64 2 High 24848 non-null float64 3 Low 24848 non-null float64 4 Close 24848 non-null float64 5 Name 24848 non-null object 6 Sector 24848 non-null object 7 Importance 24848 non-null object 8 Actual 24848 non-null float64 9 Forecast 24848 non-null float64 10 Previous 24848 non-null float64 dtypes: float64(7), object(4) memory usage: 2.1+ MB
Definición de la variable de destino
En el aprendizaje automático supervisado, necesitamos una variable objetivo que el modelo pueda utilizar para establecer las relaciones entre las variables predictoras y dicha variable objetivo.
Sabemos que, una vez publicadas las noticias, los mercados tienden a reaccionar rápidamente en cualquier dirección según las acciones y reacciones de los operadores. Sin embargo, el desafío radica en determinar durante cuánto tiempo podemos considerar que lo que está sucediendo en el mercado se debe realmente a las noticias publicadas recientemente.
Quienes evitan operar en los mercados tras la publicación de noticias suelen abstenerse de operar durante 15 a 30 minutos después de la publicación, creyendo que después de ese tiempo el impacto causado por la noticia ha disminuido.
Dado que tras la publicación de noticias los mercados experimentan una enorme volatilidad y picos inesperados que generan mucho ruido, vamos a crear la variable objetivo para 15 barras por delante (aproximadamente 4 horas por delante).
lookahead = 15 clean_df = df.copy() clean_df["Future Close"] = df["Close"].shift(-lookahead) clean_df.dropna(inplace=True) # drop nan caused by shifting operation clean_df["Signal"] = (clean_df["Future Close"] > clean_df["Close"]).astype(int) # if the future close > current close = bullish movement otherwise bearish movement clean_df
Eliminar filas sin noticias en los datos
Una vez creada la variable de destino, podemos eliminar todas las filas en las que no se publicaron noticias, ya que queremos alimentar nuestro modelo únicamente con las filas que contienen noticias.
Filtramos todas las filas que contienen el valor (null) en la columna «Name» (una columna destinada a los nombres de las noticias).
clean_df = clean_df[clean_df['Name'] != '(null)'] clean_df
Codificación de cadenas en el dataframe
Dado que muchos modelos de aprendizaje automático no admiten cadenas de texto, tenemos que codificar los valores de cadena como números enteros.
Las cadenas de texto se pueden encontrar en las columnas: Name, Sector e Importance.
from sklearn.preprocessing import LabelEncoder
categorical_cols = ['Name', 'Sector', 'Importance'] label_encoders = {} encoded_df = clean_df.copy() for col in categorical_cols: le = LabelEncoder() encoded_df[col] = le.fit_transform(clean_df[col]) # Save classes to binary file (.bin) with open(f"{col}_classes.bin", 'wb') as f: np.save(f, le.classes_, allow_pickle=True) label_encoders[col] = le encoded_df.head(5)
Como alternativa, puede integrar el LabelEncoder en un Pipeline para facilitar su uso.
Es fundamental guardar las clases detectadas por el objeto codificador de etiquetas para cada columna codificada, ya que necesitaremos esa misma información a la hora de codificar noticias en nuestros programas finales creados con el lenguaje MQL5.
Esto se debe principalmente a que queremos mantener la coherencia con nuestros patrones de codificación, así como permanecer alerta y generar errores cuando el codificador se encuentre con noticias con las que no haya sido entrenado, ya que es inevitable que surjan noticias inesperadas en el mundo.
Resultados.
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | Future Close | Signal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06976 | 1.06933 | 1.06935 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06880 | 0 |
| 1 | 2023.01.02 01:15:00 | 1.06934 | 1.06947 | 1.06927 | 1.06938 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06888 | 0 |
| 2 | 2023.01.02 01:30:00 | 1.06939 | 1.06943 | 1.06939 | 1.06942 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06891 | 0 |
| 3 | 2023.01.02 01:45:00 | 1.06943 | 1.06983 | 1.06942 | 1.06983 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06892 | 0 |
| 4 | 2023.01.02 02:00:00 | 1.06984 | 1.06989 | 1.06984 | 1.06989 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06897 | 0 |
Ahora dividamos los datos en conjuntos X e Y, y a continuación dividamos estos dos conjuntos en muestras de entrenamiento y de prueba.
X = encoded_df.drop(columns=[ "Time", "Open", "High", "Low", "Close", "Future Close", "Signal" ]) y = encoded_df["Signal"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state = 42, shuffle=True)
Observe que hemos eliminado todas las columnas, excepto las que contienen información sobre las noticias.
Entrenamiento de un modelo de IA con datos de noticias
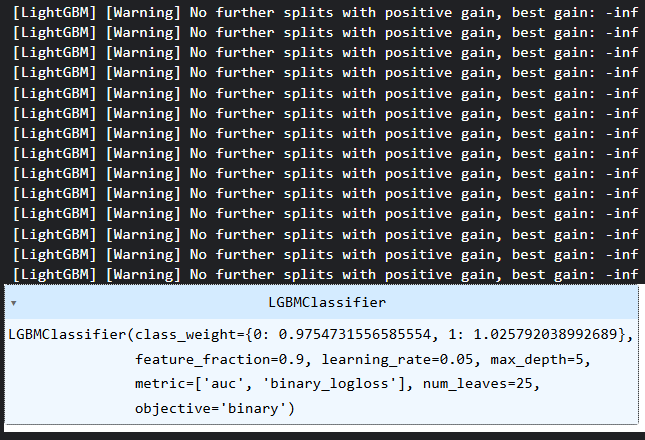
Decidí entrenar un modelo Light Gradient Boosting Machine (LightGBM) porque es sencillo, rápido y preciso. Por no mencionar que se trata de un modelo basado en árboles de decisión que funciona bien con datos categóricos como los que tenemos actualmente.
params = {
'boosting_type': 'gbdt', # Gradient Boosting Decision Tree
'objective': 'binary', # For binary classification (use 'regression' for regression tasks)
'metric': ['auc','binary_logloss'], # Evaluation metric
'num_leaves': 25, # Number of leaves in one tree
'n_estimators' : 100, # number of trees
'max_depth': 5,
'learning_rate': 0.05, # Learning rate
'feature_fraction': 0.9 # Fraction of features to be used for each boosting round
}
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train)
weight_dict = dict(zip(np.unique(y_train), class_weights))
model = lgb.LGBMClassifier(**params, class_weight=weight_dict)
# Fit the model to the training data
model.fit(X_train, y_train) Los pesos de clase se introdujeron como medida para contrarrestar el sesgo en las decisiones de los modelos.
Resultados.
A continuación se muestra el informe de clasificación de las predicciones realizadas por el modelo sobre la muestra de prueba.
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 Classification Report precision recall f1-score support 0 0.59 0.52 0.55 1116 1 0.55 0.61 0.58 1049 accuracy 0.56 2165 macro avg 0.57 0.57 0.56 2165 weighted avg 0.57 0.56 0.56 2165
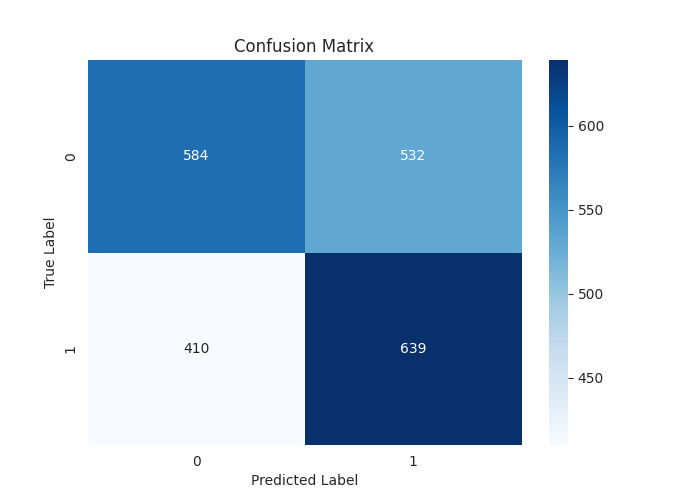
Una impresionante exactitud global de 0,56 sobre 1,0 en los datos de prueba. Esto es algo que no se consigue fácilmente al entrenar modelos de aprendizaje automático utilizando los «datos técnicos».
En este momento, el modelo que acabamos de crear es una caja negra; no sabemos cómo influyen las noticias en las decisiones finales que toma el modelo. Veamos qué nos revela el modelo sobre sus características.
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_train) Resultados.
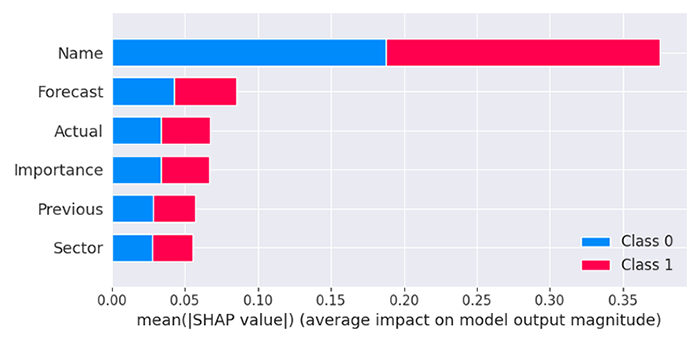
El modelo concluye que la columna "Nombre" es la que tiene mayor impacto de todas las columnas, lo que significa que algunas noticias con nombres específicos influyen significativamente en la reacción del mercado en comparación con otros predictores.
Los valores pronosticados son los segundos valores más importantes para nuestro modelo, seguidos de Real, Importancia, Anterior y Sector de la noticia.
Esto todavía no aclara mucho, hay muchas maneras de determinar el impacto que cada valor único dentro de una característica tiene en el modelo usando SHAP, por ejemplo, evaluando la primera fila en los datos.
i=0 shap.force_plot(explainer.expected_value[1], shap_values[1][i], X_train.iloc[i], matplotlib=True)
Resultados.
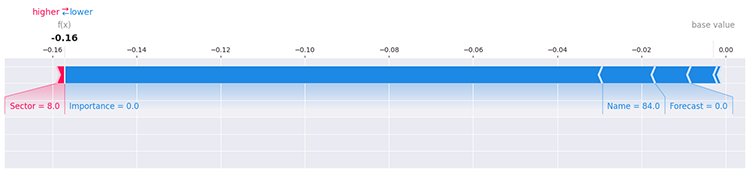
Para obtener más información y detalles sobre cómo explorar el modelo, consulte la documentación de SHAP.
Por último, debemos guardar este modelo en formato ONNX para su uso externo.
# Registering ONNX converter update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) # Final conversion model_onnx = convert_sklearn( model, "lightgbm_model", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 14, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.EURUSD.news.M15.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Noticias + Robot de trading con IA (EA)
Para que este robot de trading funcione, necesitamos un par de dependencias y archivos.
#define NEWS_CSV "EURUSD.PERIOD_M15.News.csv" //For simulating news on the strategy tester, making testing possible //--- Encoded classes for the columns stored in a binary file #define SECTOR_CLASSES "Sector_classes.bin" #define NAME_CLASSES "Name_classes.bin" #define IMPORTANCE_CLASSES "Importance_classes.bin" #define LIGHTGBM_MODEL "lightgbm.EURUSD.news.M15.onnx" //AI model //--- Tester files #property tester_file NEWS_CSV #property tester_file SECTOR_CLASSES #property tester_file NAME_CLASSES #property tester_file IMPORTANCE_CLASSES #property tester_file LIGHTGBM_MODEL
Tenemos que habilitar el uso de estos archivos en el probador de estrategias porque es cuando más los necesitamos.
//--- Dependencies #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> #include <pandas.mqh> //https://www.mql5.com/en/articles/17030 #include <Lightgbm.mqh> //For importing LightGBM model CLightGBMClassifier lgbm; CTrade m_trade; CPositionInfo m_position;
Necesitamos la misma estructura de noticias que la que utilizamos dentro de Collect News.mq5 (un script que usamos para recopilar datos de noticias).
MqlRates rates[]; struct news_data_struct { datetime time; double open; double high; double low; double close; int name; int sector; int importance; double actual; double forecast; double previous; } news_data;
Dado que en MQL5 disponemos de un LabelEncoder similar al que utilizamos para transformar las características de tipo cadena en Python, podemos cargar su clase y asignarla a tres variables para cada columna (Name, Sector e Importance).
CLabelEncoder le_name, le_sector, le_importance;
La función Init debe ser prácticamente perfecta; el robot solo debe poder inicializarse cuando todos los archivos se hayan importado, cargado y asignado correctamente a sus respectivas matrices y objetos.
CDataFrame news_df; //Pandas like Dataframe object from pandas.mqh //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Initializing LightGBM model if (!lgbm.Init(LIGHTGBM_MODEL, ONNX_DEFAULT)) { printf("%s failed to initialize ONNX model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Assign the classes read from Binary files to the label encoders class objects if (!read_bin(le_name.m_classes, NAME_CLASSES)) { printf("%s Failed to read name classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } if (!read_bin(le_sector.m_classes, SECTOR_CLASSES)) { printf("%s Failed to read sector classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } if (!read_bin(le_importance.m_classes, IMPORTANCE_CLASSES)) { printf("%s Failed to read importance classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Setting the symbol and timeframe if (!MQLInfoInteger(MQL_TESTER) && !MQLInfoInteger(MQL_DEBUG)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe)) { printf("%s failed to set symbol %s and timeframe %s",__FUNCTION__,symbol_,EnumToString(timeframe)); return INIT_FAILED; } //--- Loading news from a csv file for testing the EA in the strategy tester if (MQLInfoInteger(MQL_TESTER)) { if (!news_df.from_csv(NEWS_CSV,",", false, "Time", "Name,Sector,Importance" )) { printf("%s failed to read news from a file %s, Error = %d",__FUNCTION__,NEWS_CSV,GetLastError()); return INIT_FAILED; } } //--- Configuring the CTrade class m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(Symbol()); return(INIT_SUCCEEDED); }
La función denominada from_csv que ofrece CDataFrame codifica automáticamente los valores de fecha y hora y las columnas de cadenas de caracteres cuando se le indica.
bool CDataFrame::from_csv(string file_name,string delimiter=",",bool is_common=false, string datetime_columns="",string encode_columns="", bool verbosity=false)
Esto simplifica el trabajo con los datos resultantes almacenados en un objeto `news_df`, ya que no será necesario codificar manualmente las columnas extraídas del archivo CSV.
La columna Time se convertirá a segundos (tipo de datos «double») en lugar de a fecha y hora (tipo de datos «datetime»).
Puede consultar los datos recibidos de la siguiente manera.
news_df.head();
Resultados.
QE 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | Index | Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | MI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 0 | 1672621200.00000000 | 1.06967000 | 1.06976000 | 1.06933000 | 1.06935000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 1 | 1672622100.00000000 | 1.06934000 | 1.06947000 | 1.06927000 | 1.06938000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | RI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 2 | 1672623000.00000000 | 1.06939000 | 1.06943000 | 1.06939000 | 1.06942000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 3 | 1672623900.00000000 | 1.06943000 | 1.06983000 | 1.06942000 | 1.06983000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 4 | 1672624800.00000000 | 1.06984000 | 1.06989000 | 1.06984000 | 1.06989000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 |
Es dentro de la función getNews donde se realizan la mayoría de los cálculos.
vector getNews() { //--- vector v = vector::Zeros(6); ResetLastError(); if (CopyRates(Symbol(), timeframe, 0, 1, rates)<=0) { printf("%s failed to get price infromation. Error = %d",__FUNCTION__,GetLastError()); return vector::Zeros(0); } news_data.time = rates[0].time; news_data.open = rates[0].open; news_data.high = rates[0].high; news_data.low = rates[0].low; news_data.close = rates[0].close; //--- if (MQLInfoInteger(MQL_TESTER)) //If we are on the strategy tester, read the news from a dataframe object { if ((ulong)n_idx>=news_df["Time"].Size()) TesterStop(); //End the strategy tester as there are no enough news to read datetime news_time = (datetime)news_df["Time"][n_idx]; //Convert time from seconds back into datetime datetime current_time = TimeCurrent(); if (news_time >= (current_time - PeriodSeconds(timeframe)) && (news_time <= (current_time + PeriodSeconds(timeframe)))) //We ensure if the incremented news time is very close to the current time { n_idx++; //Move on to the next news if weve passed the previous one } else return vector::Zeros(0); if (n_idx>=(int)news_df["Name"].Size() || n_idx >= (int)news_df.m_values.Rows()) TesterStop(); //End the strategy tester as there are no enough news to read news_data.name = (int)news_df["Name"][n_idx]; news_data.sector = (int)news_df["Sector"][n_idx]; news_data.importance = (int)news_df["Importance"][n_idx]; news_data.actual = !MathIsValidNumber(news_df["Actual"][n_idx]) ? 0 : news_df["Actual"][n_idx]; news_data.forecast = !MathIsValidNumber(news_df["Forecast"][n_idx]) ? 0 : news_df["Forecast"][n_idx]; news_data.previous = !MathIsValidNumber(news_df["Previous"][n_idx]) ? 0 : news_df["Previous"][n_idx]; if (news_data.name==0.0) //(null) return vector::Zeros(0); } else { int all_news = CalendarValueHistory(calendar_values, rates[0].time, rates[0].time+PeriodSeconds(timeframe), NULL, NULL); //we obtain all the news with their calendar_values https://www.mql5.com/en/docs/calendar/calendarvaluehistory if (all_news<=0) return vector::Zeros(0); for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(calendar_values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { //--- Important | Encode news names into integers using the same encoder applied on the training data news_data.name = le_name.transform((string)event.name); news_data.sector = le_sector.transform((string)event.sector); news_data.importance = le_importance.transform((string)event.importance); news_data.actual = !MathIsValidNumber(calendar_values[n].GetActualValue()) ? 0 : calendar_values[n].GetActualValue(); news_data.forecast = !MathIsValidNumber(calendar_values[n].GetForecastValue()) ? 0 : calendar_values[n].GetForecastValue(); news_data.previous = !MathIsValidNumber(calendar_values[n].GetPreviousValue()) ? 0 : calendar_values[n].GetPreviousValue(); } } if (news_data.name==0.0) //(null) return vector::Zeros(0); } v[0] = news_data.name; v[1] = news_data.sector; v[2] = news_data.importance; v[3] = news_data.actual; v[4] = news_data.forecast; v[5] = news_data.previous; return v; }
Cuando esta función detecta que el EA se encuentra en el simulador de estrategias, lee las noticias almacenadas en el objeto Dataframe en lugar de obtenerlas directamente del mercado, algo que no es posible en el entorno del simulador.
Observe cómo las cadenas recibidas de las noticias se convirtieron en números enteros utilizando codificadores que incorporaban las clases utilizadas en los datos de entrenamiento dentro de la función OnInit.
Dado que contamos con un par de comprobaciones dentro de la función getNews para garantizar que la función devuelva un vector vacío cuando se produzca un error o cuando no se hayan recibido noticias en ese momento. Dentro de la función OnTick, comprobamos que el vector recibido no esté vacío. Si no es así, seguimos adelante con una estrategia de negociación sencilla.
void OnTick() { //--- vector x = getNews(); if (x.Size()==0) //No present news at the moment return; long signal = lgbm.predict(x).cls; //--- MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); //--- if (signal == 1) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask,0,0); } if (signal == 0) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid,0,0); } CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe }
Si el modelo predice que, según las noticias recibidas, el mercado tendrá una tendencia alcista (señal = 1), abrimos una operación de compra, y si el modelo predice que el mercado bajará (señal = 0), abrimos una operación de venta.
Una operación se cerrará una vez que haya transcurrido el número de barras igual al valor de anticipación en el marco temporal actual. El valor de anticipación debe ser el mismo que el utilizado al crear una variable objetivo en un script de Python. Esto garantiza que mantengamos posiciones de acuerdo con el horizonte predictivo del modelo entrenado.
Finalmente, probemos este robot de trading en el mismo período en el que fue entrenado dentro del probador de estrategias.
- Símbolo: EURUSD
- Periodo: PERIODO_M15
- Modelado: Sólo precios de apertura
Resultados del Probador de estrategias.
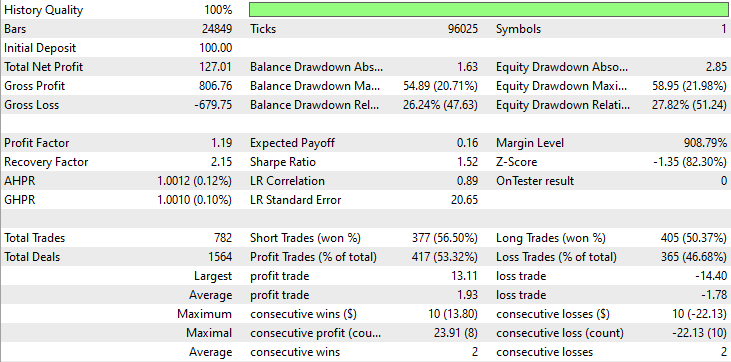
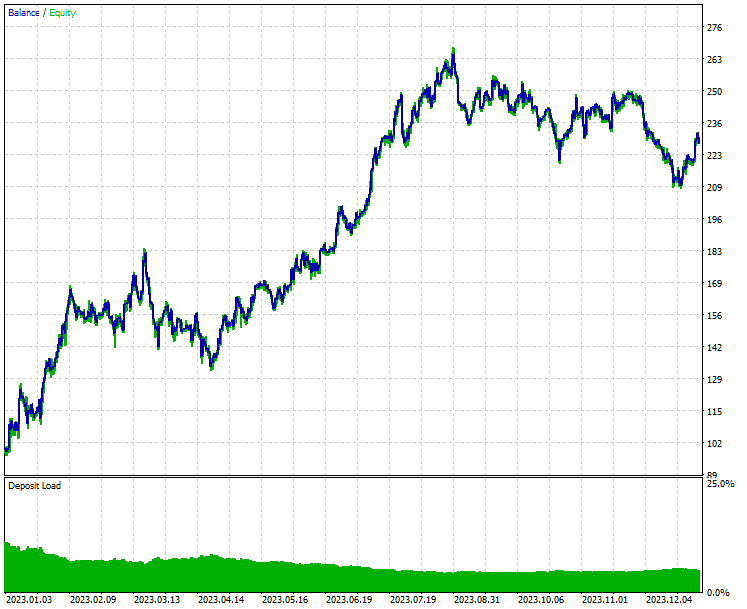
Conclusión
Como puede verse en los resultados del probador de estrategias, la combinación de noticias y un modelo de aprendizaje automático eficaz (LightGBM) produjo resultados predictivos y de trading impresionantes durante el año con el que se entrenó.
Si bien las noticias son uno de los indicadores más fiables de los mercados de divisas y de valores, operar durante la publicación de noticias o poco después es muy arriesgado debido a la volatilidad inesperada que se produce en el mercado durante ese período. Debe tener esto en cuenta siempre que quiera confiar su dinero, ganado con tanto esfuerzo, a un robot de trading basado en noticias.
Se puede decir que este proyecto tiene margen de mejora, así que no dudes en ajustar algunos parámetros y perfeccionar esta idea. Por favor, déjenos su opinión en la sección de comentarios.
Atentamente.
Manténgase al tanto y colabore en el desarrollo de algoritmos de aprendizaje automático para el lenguaje MQL5 en este repositorio de GitHub.
Tabla de archivos adjuntos
| Nombre y ruta del archivo | Descripción y uso |
|---|---|
Files\AI+NFP.mq5 | El principal asesor experto para la implementación de modelos de IA y noticias con fines comerciales y de prueba. |
Files\Collect News.mq5 | Un script para recopilar noticias de MetaTrader 5 y exportarlas a un archivo CSV. |
Include\Lightgbm.mqh | Una biblioteca para cargar y desplegar el modelo LightGBM en formato ONNX. |
Include\pandas.mqh | Una biblioteca que contiene un DataFrame similar a Pandas para el almacenamiento y la manipulación de datos. |
Files\* | Los archivos ONNX, CSV y binarios utilizados en este artículo se encuentran en esta carpeta. |
Python\nfp-ai.ipynb | Notebook Jupyter de Python en el que se puede encontrar todo el código Python para el entrenamiento, la limpieza de datos, etc. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/17986
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso