
Características del Wizard MQL5 que debe conocer (Parte 58): Aprendizaje por refuerzo (DDPG) con patrones de media móvil y oscilador estocástico
Introducción
En nuestro último artículo probamos 10 patrones de señales de nuestros dos indicadores (media móvil y oscilador estocástico). Siete de ellos dieron resultados positivos en una prueba retrospectiva realizada en un periodo de un año. Sin embargo, de ellos, solo dos lo hicieron realizando operaciones tanto en largo como en corto. Esto se debió a que el periodo de prueba fue breve, por lo que se recomienda a los lectores que lo prueben con un historial más amplio antes de seguir adelante.
En este caso, partimos de la premisa de que los tres principales tipos de aprendizaje automático pueden utilizarse conjuntamente, cada uno en su propia «fase». En resumen, estos modos son el aprendizaje supervisado (SL), el aprendizaje por refuerzo (RL) y el aprendizaje por inferencia (IL). En el artículo anterior nos centramos en el SL, donde los patrones combinados de la media móvil y el oscilador estocástico se normalizaron en un vector binario de características. A continuación, estos datos se introdujeron en una red neuronal sencilla que entrenamos con el par EURUSD para el año 2023 y, posteriormente, realizamos pruebas prospectivas para el año 2024.
Dado que nuestro enfoque se basa en la tesis de que el aprendizaje por refuerzo (RL) puede utilizarse para entrenar modelos mientras están en uso, queremos demostrarlo en este artículo utilizando nuestros resultados anteriores y la red de aprendizaje por refuerzo (RL). Planteamos que el aprendizaje por refuerzo (RL) es una forma de retropropagación que, durante su implementación, ajusta cuidadosamente nuestras decisiones de compraventa para que no se basen únicamente en los cambios proyectados en el precio, como ocurría en el modelo SL.
Este "ajuste fino", como hemos visto en artículos anteriores sobre aprendizaje por refuerzo, combina exploración y explotación. De este modo, nuestra red de políticas, mediante la formación recibida en un entorno de mercado real, determinaría qué estados deberían adoptar medidas de compra o venta. Podría haber casos en los que una tendencia alcista no signifique necesariamente una oportunidad de compra, y viceversa. Esto significa que nuestro modelo RL actúa como un filtro adicional a las decisiones tomadas por el modelo SL. Los estados de nuestro modelo SL utilizaban valores continuos unidimensionales, y esto será muy similar al espacio de acciones que utilizaremos.
DDPG
Ya hemos analizado varios algoritmos de aprendizaje por refuerzo diferentes, y en este artículo nos centraremos en el Gradiente de Política Determinista Profunda (Deep Deterministic Policy Gradient, DDPG). Este algoritmo en particular, similar al DQN que analizamos en un artículo anterior, sirve para realizar pronósticos en espacios de acción continuos. Recordemos que la mayoría de los algoritmos que hemos analizado recientemente eran clasificadores, cuyo objetivo era generar distribuciones de probabilidad sobre si la siguiente acción a seguir debía ser comprar, vender o mantener (por ejemplo).
Este no es un clasificador, sino un regresor. Definimos un espacio de acción como un valor de punto flotante en el rango de 0,0 a 1,0. Este enfoque se puede utilizar para calibrar muchas más opciones que simplemente:
- Comprar (cualquier valor por encima de 0,5);
- Vender (cualquier valor por debajo de 0,5);
- o mantener (cualquier valor cercano a 0,5)
Esto podría lograrse introduciendo tipos de órdenes pendientes o incluso ajustando el tamaño de las posiciones. Dejamos estas medidas a criterio del lector, ya que nos ceñiremos a la implementación más básica, donde 0,5 sirve como umbral clave.
En principio, DDPG utiliza redes neuronales para aproximar los valores Q (recompensas por acciones) y optimiza directamente la política (red que elige la siguiente mejor acción cuando se le presentan estados del entorno); en lugar de simplemente estimar los valores Q. A diferencia de DQN, que también se puede utilizar para acciones discretas/de clasificación como izquierda o derecha, DDPG es exclusivamente para espacios de acción continuos. (Piensa, por ejemplo, en los ángulos de dirección o los pares de torsión de los motores al entrenar robots). ¿Cómo funciona?
Principalmente, se utilizan dos redes neuronales.
- Una de ellas es la red de actores, cuyo papel es decidir la mejor acción para un estado ambiental determinado.
- La otra es la red de críticos, cuyo propósito es evaluar la calidad de la acción seleccionada por el actor mediante la estimación de las recompensas potenciales que se pueden obtener al llevar a cabo dicha acción.
Esta estimación también se conoce como valor Q. Además, un aspecto importante dentro de DDPG es el búfer de repetición de la experiencia. Esto almacena experiencias pasadas (un término colectivo para representar estados, acciones, recompensas y estados futuros) en un búfer. Se utilizan muestras aleatorias de este búfer para entrenar las redes y reducir la correlación entre las actualizaciones.
Además de las dos redes mencionadas anteriormente, también participan sus copias equivalentes, a las que se denomina "objetivos". Estas copias independientes de las redes de actores y críticos actualizan sus ponderaciones a un ritmo más lento, y se argumenta que esto ayuda a estabilizar el proceso de entrenamiento al proporcionar objetivos consistentes. Finalmente, en DDPG, la exploración, una característica clave del aprendizaje por refuerzo, se lleva un paso más allá mediante la introducción de un componente de ruido en las acciones a través de algoritmos, el más común de los cuales es el ruido de Ornstein-Uhlenbeck.
La formación DDPG abarca esencialmente 3 cosas. En primer lugar, implica mejorar la red de actores, donde la red de críticos guía a la red de actores a la hora de definir qué acción es buena o mala, de modo que la red de actores ajuste mejor su ponderación a la hora de elegir acciones que maximicen las recompensas. En segundo lugar, se mejora la red de críticos, donde aprende a estimar mejor las recompensas/valores Q utilizando actualizaciones de Bellman, tal como se describe en la ecuación siguiente:

Donde:
-
Q(s,a): El valor Q previsto (estimación del crítico) para tomar la acción "a" en el estado "s".
-
r: Recompensa inmediata recibida después de realizar la acción "a" en el estado "s".
-
γ: Factor de descuento (0≤γ<1), que determina cuánto se valoran las recompensas futuras (más cerca de 0 = enfoque a corto plazo, más cerca de 1 = enfoque a largo plazo).
-
s′: Siguiente estado observado después de realizar la acción "a" en el estado "s".
-
Qtarget(s′,⋅): Estimación de la red Q objetivo del valor Q para el siguiente estado "s′" (utilizado para estabilizar el entrenamiento).
-
Actortarget(s′): Acción recomendada del actor objetivo para el siguiente estado "s′" (política determinista).
Finalmente, existen actualizaciones suaves para el actor-objetivo y el crítico-objetivo, donde las actualizaciones se realizan lentamente para que coincidan con las redes principales de acuerdo con la siguiente ecuación:
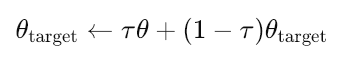
Donde:
- θtarget: Parámetros (pesos) de la red objetivo (ya sea actor o crítico).
- θ: Parámetros de la red principal (en línea) (ya sea actor o crítico).
- τ: Tasa de actualización suave (0≪τ≪1, por ejemplo, 0,001). Controla la lentitud con la que se actualizan las redes de destino.
- Un valor pequeño de τ implica que las redes objetivo cambian muy lentamente (entrenamiento más estable).
- Un valor grande de τ implica que las redes objetivo se actualizan más rápido (son menos estables, pero pueden adaptarse con mayor rapidez).
¿Por qué DDPG? Es popular porque funciona bien en espacios de acción continuos y de alta dimensión, y combina la estabilidad del aprendizaje Q con la flexibilidad de los gradientes de política. Como se muestra en el ejemplo del espacio de acción continuo en robótica anterior, es muy popular en robótica, control basado en la física y otras tareas complejas similares. Esto no significa que no podamos usarlo en series temporales financieras, y eso es lo que exploraremos.
Estamos implementando la mayor parte de nuestro código en Python 3.10 debido a la eficiencia que ofrece al entrenar redes neuronales muy profundas. Pero en este campo uno aprende algo nuevo de vez en cuando. En mi caso, se debe a que Python es capaz de realizar cálculos tan rápidos en el entrenamiento de redes (PyTorch y TensorFlow) gracias al código de anclaje y las clases en C/C++, así como a CUDA. Actualmente, MQL5 es muy similar a C y la implementación de OpenCL cuenta con soporte desde hace algún tiempo. Creo que simplemente falta una biblioteca con la multiplicación básica de matrices (en parte en OpenCL) para obtener un rendimiento similar en MQL5. Esto es algo que quizás valga la pena explorar.
Búfer de reproducción
El búfer de reproducción es un componente muy importante en DDPG y otros algoritmos de aprendizaje por refuerzo fuera de política. Se utiliza principalmente para romper las correlaciones temporales entre muestras consecutivas, permitir la reutilización de la experiencia para que el aprendizaje sea más eficiente, proporcionar un conjunto diverso de transiciones para un entrenamiento estable y almacenar experiencias pasadas (estado, acción, recompensa, siguiente estado, tuplas de finalización) para su uso en el proceso de entrenamiento/actualización de pesos de la red.
Su implementación principal comienza principalmente con su función de inicialización:
def __init__(self, capacity): self.buffer = deque(maxlen=capacity)
Estamos utilizando collections.deque con una capacidad máxima fija y descartando automáticamente las experiencias antiguas cuando se llena mediante un comportamiento FIFO (primero en entrar, primero en salir). Es muy sencillo y consume poca memoria. A continuación, se realiza la operación de inserción, donde el búfer almacena tuplas de transición completas y gestiona tanto las transiciones exitosas como las terminales (mediante el uso del indicador "done"). Proporciona una sobrecarga mínima al agregar nuevas experiencias.
def push(self, state, action, reward, next_state, done): self.buffer.append((state, action, reward, next_state, done))
El mecanismo de muestreo utilizado es un muestreo aleatorio uniforme, lo cual es muy importante para romper correlaciones. Es eficiente porque utiliza el procesamiento por lotes a través de zip(*batch), lo que ayuda a separar los componentes del entorno. Devuelve todos los componentes necesarios para la actualización del aprendizaje Q.
def sample(self, batch_size): batch = random.sample(self.buffer, batch_size) states, actions, rewards, next_states, dones = zip(*batch)
A continuación, en la clase del búfer de reproducción, se realiza la conversión de tensores y el manejo de dispositivos para cada uno de los componentes del entorno. Como ya se ha mostrado anteriormente, estos son estados, acciones, recompensas, estados siguientes y acciones realizadas. La conversión es muy robusta. Admite como entrada tanto matrices NumPy como tensores PyTorch. Esto garantiza que los tensores (que pueden considerarse como matrices con información de gradiente adjunta) se desvinculen de los grafos de cálculo.
Transferimos los datos a la CPU para evitar conflictos entre dispositivos. Realizamos una conversión explícita a tensor de punto flotante (float-32), que es un requisito previo común para las redes neuronales. Este tipo de dato, que es más pequeño que el tipo double que se usa frecuentemente en MQL5, es significativamente más eficiente en términos de cálculo. Finalmente, gracias a PyTorch (a diferencia de TensorFlow), podemos optar por transferir los datos a un dispositivo de computación específico, como una GPU, si está disponible.
states = torch.FloatTensor( np.array([s.detach().cpu().numpy() if torch.is_tensor(s) else s for s in states]) ).to(device)
Nuestra clase de búfer de reproducción funciona bien con DDPG, ya que, en primer lugar, facilita el aprendizaje fuera de política, dado que DDPG requiere un búfer de reproducción para aprender de datos históricos. Los espacios de acción continuos de DDPG se manejan bien con la conversión de tensores de punto flotante. Esto proporciona a DDPG cierta estabilidad mediante un muestreo aleatorio que ayuda a prevenir actualizaciones correlacionadas que podrían desestabilizar el entrenamiento. Además, aporta cierta flexibilidad al poder trabajar con entradas de NumPy y torch, los sistemas comunes de aprendizaje por refuerzo.
Las posibles mejoras incluyen el uso de búferes de reproducción de experiencias priorizadas para gestionar transiciones importantes; el uso de retornos de varios pasos o aprendizaje de n pasos; la separación/clasificación de diferentes tipos de experiencias; y la realización de conversiones de tensores más eficientes que eviten el intermediario NumPy.
En general, nuestra clase de búfer de reproducción es robusta gracias al uso de la comprobación de tipos con torch.is_tensor(), el manejo de dispositivos para garantizar la compatibilidad entre CPU y GPU, y la clara separación de los componentes del entorno. El rendimiento tampoco se ve afectado, ya que la cola inversa ofrece operaciones de inserción y extracción de O(1); utiliza el procesamiento por lotes para minimizar la sobrecarga; e implementa el muestreo aleatorio, que resulta eficiente para búferes de tamaño moderado. Además, es fácil de mantener, dado que el código tiene una implementación clara y concisa; es sencillo de ampliar o modificar; y proporciona una buena consistencia de tipos en la salida.
Las principales limitaciones y consideraciones podrían derivarse del uso de la memoria. Almacenar transiciones completas puede resultar muy costoso para estados de transición elevados. Además, la capacidad fija puede requerir ajustes para diferentes entornos. Otra limitación tiene que ver con la eficiencia del muestreo. El muestreo uniforme no prioriza las experiencias importantes, ya que a todas se les da la misma ponderación. Tampoco se gestionan los límites de los episodios durante el muestreo.
Algunas alternativas posibles para abordar algunos de estos problemas podrían ser el uso de almacenamiento en disco para búferes muy grandes; estados basados en imágenes para almacenar representaciones comprimidas; y la adición de soporte para almacenar información adicional, como probabilidades de registro. Dichos cambios podrían proporcionar una base sólida para DDPG, permitiendo su ampliación en función de las necesidades específicas de cada aplicación, manteniendo al mismo tiempo su funcionalidad principal.
Redes de críticos y actores
Ambas redes siguen una estructura similar de perceptrón multicapa; sin embargo, como cabría esperar en el aprendizaje por refuerzo, cumplen funciones distintas en DDPG. La red crítica, también conocida como función Q, estima el valor de los pares estado-acción (valores Q o recompensas), mientras que la red actor, también conocida como red de políticas, determina la acción óptima para un estado dado.
La inicialización y la estructura de capas de la red crítica adoptan la siguiente forma:
def __init__(self, state_dim, action_dim, hidden_dim): super(Critic, self).__init__() self.fc1 = nn.Linear(state_dim + action_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, 1)
Los puntos clave aquí son que: toma tanto estados como acciones (como hemos visto en algoritmos RL anteriores) como entrada, a diferencia de las funciones de valor en otros métodos; estamos implementando esta red con tres capas totalmente conectadas con neuronas dim ocultas en las dos primeras capas; la capa de salida final produce solo un escalar de valor Q; y la arquitectura está diseñada para estimar Q(s,a) para espacios de acción continuos.
La mecánica del pase hacia adelante es la siguiente:
def forward(self, state, action): x = torch.cat([state, action], dim=1) x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) q_value = self.fc3(x)
Los componentes "críticos" dentro de esta implementación son torch.cat, que es esencial para la estimación del valor de acción de DDPG. Combina vectores de entrada de estado y acción antes del procesamiento. El dimensionamiento dim=1 garantiza una concatenación adecuada para el procesamiento por lotes. Otra parte destacable de nuestro código podrían ser las funciones de activación. La función ReLU se utiliza para las capas ocultas, ya que ayuda a mitigar el problema del gradiente evanescente. No se realiza ninguna activación en la capa final, ya que los valores Q pueden ser cualquier número real.
El flujo de información se produce desde el par estado-acción hasta las capas ocultas y la estimación del valor Q. Representa el núcleo de la función Q-Learning. La red de actores también tiene la siguiente inicialización y estructura:
def __init__(self, state_dim, action_dim, hidden_dim): super(Actor, self).__init__() self.fc1 = nn.Linear(state_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, action_dim) self.tanh = nn.Tanh()
Los aspectos clave que cabe destacar aquí son: solo toma como entrada la dimensión del estado, ya que la política depende del estado. Para nuestros propósitos, sigue una estructura de tres capas similar a la de la red crítica descrita anteriormente, pero con un manejo de salida diferente. El tamaño de la capa final coincide con la dimensionalidad del espacio de acción. La función de activación tanh utilizada para la capa de salida es importante para acciones acotadas. La mecánica del pase hacia adelante se define en la siguiente lista:
def forward(self, state):
x = self.relu(self.fc1(state))
x = self.relu(self.fc2(x))
action = self.tanh(self.fc3(x)) Mucho más simple y directo que la red crítica, donde el procesamiento del estado toma solo el estado como entrada (a diferencia de la red crítica) y luego construye la representación del estado a través de las capas ocultas. La generación de acciones se habilita mediante la activación Tanh, que restringe las salidas al intervalo [-1, 1]. Esto es vital para los espacios de acción continuos de DDPG. Este rango fijo se puede reescalar al rango de acción del entorno, por ejemplo [0, 1], etc. Cabe destacar también que esta política es inherentemente determinista. En lugar de una distribución de probabilidad sobre un conjunto discreto de acciones, como suele ocurrir con los métodos de política estocástica, se obtiene como resultado una acción específica.
Las decisiones de diseño específicas de DDPG para la red crítica guardan cierta relación con otros algoritmos de aprendizaje por refuerzo, y son las siguientes: el manejo conjunto de las entradas, ya que el estado y la acción se concatenan; tener una salida escalar que funciona bien en espacios de acción continuos; y el hecho de que no haya activación preserva todo el rango de estimaciones del valor Q. Para la red de actores, las opciones de diseño de DDPG son salidas limitadas mediante el uso de Tanh, que garantiza que las acciones estén dentro de un rango aprendible; naturaleza determinista, ya que se busca un peso de acción más específico en lugar de una política estocástica; y coincidencia del espacio de acciones, donde el tamaño de la capa final se alinea directamente con las dimensiones de acción del entorno.
Nuestro ejemplo DDPG utiliza un espacio de acción unidimensional. El espacio de estados también es un espacio unidimensional, ya que este fue el resultado de la red de aprendizaje supervisado utilizada en el artículo anterior. Las características arquitectónicas compartidas son las funciones de activación ReLU, que suelen ser una opción común para las capas ocultas en el aprendizaje profundo por refuerzo. Hemos mantenido tamaños ocultos consistentes mediante una dimensionalidad uniforme en todo momento, y también hemos adoptado una estructura MLP adecuada para espacios de estados de baja dimensión.
Las ventajas de implementación de las redes PyTorch no son particularmente destacables, pero sí lo son: robustez en el manejo de dimensiones y especificación clara de las dimensiones de entrada/salida; gestión de la activación donde existe una separación adecuada de las activaciones ocultas/de salida; y soporte para procesamiento por lotes, ya que todas las operaciones (en sus tensores) mantienen una dimensión de lote. Además, algunos factores que mejoran el rendimiento de estas redes son la eficiencia de la función ReLU, ya que esta activación es más rápida en comparación con otros tipos de activación, la simplicidad de la capa lineal (sin convoluciones ni recurrencias) y las operaciones mínimas gracias a los pasos hacia adelante optimizados.
Las posibles mejoras para la red crítica son: la normalización de capas que podría estabilizar el aprendizaje; la arquitectura de duelo donde los valores de estado; y múltiples salidas Q como en TD3 para el aprendizaje Q doble recortado. Para la red de actores, las mejoras podrían ser la inyección de ruido para la exploración (aunque DDPG utiliza ruido externo); la normalización por lotes para ayudar con las diferentes escalas de estado; y la normalización espectral para un entrenamiento más estable.
Para la integración de estos dos elementos en el contexto de DDPG: la función de la red crítica en el entrenamiento es proporcionar estimaciones del valor Q para las actualizaciones de políticas, que luego se utilizan para calcular los objetivos de diferencia temporal para sí misma. Necesita evaluar con precisión sus entradas, los valores de estado-acción, para cuantificar en qué medida se debe ajustar la política (pesos y sesgos de la red de actores). El papel del actor en el entrenamiento consiste en proporcionar acciones tanto para el funcionamiento del entorno como para el cálculo del valor Q, actualizar el ascenso de gradiente en función de los valores Q del crítico y aprender políticas deterministas suaves para el control continuo.
Conclusión
Antes de analizar los informes del probador de estrategias para nuestros siete patrones que pudieron aplicarse prospectivamente a partir del último artículo, debemos examinar la clase «DDPG Agent» y la clase de datos «Environment». Sin embargo, abordaremos esos temas en el próximo artículo, ya que este ya es bastante extenso. Gran parte del material que se trata aquí está escrito en Python, con el objetivo de exportar redes ONNX para integrarlas en MQL5 como recurso.
Python es importante en este momento porque resulta más eficiente en el entrenamiento que el MQL5 sin modificar; sin embargo, podrían existir soluciones alternativas que utilicen OpenCL y que podríamos analizar también en futuros artículos. En el siguiente artículo también se analizará el código adjunto típico que utilizamos en el ensamblaje del asistente a partir de las clases de señal; por lo tanto, este artículo no incluye archivos adjuntos.
| Nombre | Descripción |
|---|---|
| wz_58_ddpg.py | Script para la implementación de DDPG de aprendizaje por refuerzo en Python. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/17668
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso