
Aprendizaje automático y Data Science (Parte 40): Uso de retrocesos de Fibonacci en datos de aprendizaje automático

Contenido
- El origen de los números de Fibonacci
- Comprender los niveles de retroceso de Fibonacci desde el punto de vista del trading
- Creación de una variable objetivo mediante los retrocesos de Fibonacci
- Entrenamiento de un modelo clasificador con una variable objetivo basada en Fibonacci
- Entrenamiento de un modelo de regresión con una variable objetivo basada en Fibonacci
- Prueba de modelos de aprendizaje automático basados en Fibonacci en el Probador de estrategias
- Reflexiones finales
El origen de los números de Fibonacci
Los números de Fibonacci se remontan al matemático medieval Leonardo de Pisa, también conocido como Fibonacci.
En su libro titulado «Liber Abaci», publicado en 1202, Fibonacci presentó la sucesión numérica que hoy se conoce como la sucesión de Fibonacci. La sucesión comienza con 0 y 1, y cada número subsiguiente en la serie es la suma de los dos números anteriores.
Esta sucesión es poderosa, ya que aparece en muchos fenómenos naturales, incluidos los patrones de crecimiento de las plantas y los animales.
En biología, aunque no sea perfecta, la espiral logarítmica que se observa en las conchas de algunos animales e insectos se aproxima a los números de Fibonacci.
El patrón de crecimiento similar al de Fibonacci también se puede observar en la población de conejos y en los árboles genealógicos de las abejas.
Los números de Fibonacci también pueden observarse en la composición del ADN de algunos mamíferos y seres humanos.

Estas cifras son universales, ya que se han observado prácticamente en todas partes. A continuación, se presentan algunos de los términos comunes que encontrará al trabajar con números de Fibonacci.
Sucesión de Fibonacci
En matemáticas, una sucesión de Fibonacci es una sucesión en la que cada elemento es la suma de los dos elementos que lo preceden. Los números que forman parte de una sucesión de Fibonacci se conocen como números de Fibonacci.

La sucesión de Fibonacci se puede expresar mediante la siguiente ecuación.
![]()
Donde n es mayor que 1 (n > 1).
La proporción áurea
Este es un concepto matemático que describe la relación entre dos cantidades, donde la razón entre la cantidad menor y la mayor es la misma que la razón entre la mayor y la suma de ambas.
La proporción áurea es aproximadamente igual a 1,6180339887 y se representa con la letra griega phi (φ).
La proporción áurea, representada por φ, es el valor al que tiende la razón entre términos consecutivos de la sucesión de Fibonacci.
Cuando se divide el número mayor por el menor, el resultado es un valor cercano a Phi. Cuanto más se avanza en la sucesión de Fibonacci, más se acercan las respuestas al número Phi. Pero el resultado nunca será exactamente igual a Phi. Esto se debe a que Phi no se puede expresar como una fracción. ¡Es irracional!

Este número se ha observado en diversas estructuras naturales y artificiales, y se considera un principio universal de belleza y armonía.
Comprensión de los niveles de retroceso de Fibonacci desde el punto de vista del trading
Los niveles de retroceso de Fibonacci son líneas horizontales que indican los posibles niveles de soporte y resistencia en los que el precio podría invertir su tendencia; se calculan utilizando los principios de los números de Fibonacci que hemos comentado anteriormente.
Se trata de una herramienta habitual que los operadores utilizan en MetaTrader 5 con diversos fines, como definir niveles de stop loss y take profit y detectar líneas de soporte y resistencia que sirven para identificar los puntos en los que es más probable que los precios cambien de tendencia.
En MetaTrader 5, se encuentra en la pestaña «Insertar» > «Objetos» > «Herramientas de Fibonacci».

A continuación se muestra la herramienta de retrocesos de Fibonacci aplicada al par EURUSD en el gráfico de 1 hora.

Aunque la herramienta de retrocesos de Fibonacci parece fiable a la hora de proporcionar niveles útiles para detectar cambios de tendencia en el mercado y definir niveles de stop loss y take profit, analicemos la eficacia de los niveles de Fibonacci en el ámbito del aprendizaje automático y la inteligencia artificial (IA), la proporción áurea (61,8 o 0,618), para ser más concretos.
Exploremos diversas formas de crear niveles de Fibonacci matemáticamente y utilicémoslos para crear una variable objetivo que los modelos de aprendizaje automático puedan usar para comprender y predecir la dirección del mercado.
Creación de una variable objetivo mediante retrocesos de Fibonacci
Para entrenar un modelo que comprenda las relaciones en nuestros datos mediante el aprendizaje automático supervisado, necesitamos una variable objetivo bien definida. Dado que un nivel de Fibonacci es simplemente un número que representa un determinado nivel de precio, podemos recopilar el precio de mercado en el nivel de Fibonacci que necesitamos y usarlo como variable objetivo para un problema de regresión.
Para un problema de clasificación, creamos las etiquetas de clase basándonos en los movimientos del mercado según las líneas de Fibonacci. Es decir, si el mercado avanza ciertas barras, superando el nivel de Fibonacci calculado en una tendencia alcista, podemos considerar que es una señal alcista (indicada por 1), y de lo contrario, si el mercado se mueve a la baja superando el nivel de Fibonacci que establecimos, podemos considerar que es una señal bajista (indicada por 0). Podemos asignar cualquier otro caso a la categoría sin señal (indicada por -1).
Para un problema de clasificación
Importaciones.
import pandas as pd import numpy as np
Funciones.
def create_fib_clftargetvar(price: pd.Series, lookback_window: int=10, lookahead_window: int=10, fib_level: float=0.618): """ Creates a target variable based on Fibonacci breakthroughs in price data. Parameters: - price: pd.Series of price data (close, open, high, or low) - lookback_window: int - number of past periods to calculate high/low - lookahead_window: int - number of future periods to assess breakout - fib_level: float - Fibonacci retracement level (e.g. 0.618) Returns: - pd.Series: with values 1 => Bullish fib level reached 0 => Bearish fib level reached -1 => False breakthrough or no fib hit """ high = price.rolling(lookback_window).max() low = price.rolling(lookback_window).min() fib_level_value = high - (high - low) * fib_level # calculate the Fibonacci level in market price price_ahead = price.shift(-lookahead_window) # future price values target_var = [] for i in range(len(price)): if np.isnan(price_ahead.iloc[i]) or np.isnan(fib_level_value.iloc[i]) or np.isnan(price.iloc[i]): target_var.append(np.nan) continue # let's detect bull and bearish movement afterwards if price_ahead.iloc[i] > price.iloc[i]: # The market went bullish if price_ahead.iloc[i] >= fib_level_value.iloc[i]: target_var.append(1) # bullish Fibonacci target reached else: target_var.append(-1) # false breakthrough else: # The market went bearish if price_ahead.iloc[i] <= fib_level_value.iloc[i]: target_var.append(0) # bearish Fibonacci target reached else: target_var.append(-1) # false breakthrough return target_var
El nivel de Fibonacci del mercado se calcula utilizando la siguiente fórmula.
fib_level_value = high - (high - low) * fib_level
Dado que se trata de un problema de clasificación en el que queremos predecir la reacción del mercado basándonos en el nivel de Fibonacci anterior, debemos anticiparnos al futuro y detectar una tendencia. Posteriormente, comprobamos si el precio futuro, basado en la ventana de previsión, cruzó por encima del nivel de Fibonacci (para una tendencia alcista) o por debajo (para una tendencia bajista) para generar señales de compra o venta, respectivamente. Se asignará una señal neutral cuando el precio no alcance el nivel de Fibonacci en ninguna de las dos direcciones.
Vamos a crear la variable objetivo con esta función y añadir el resultado al DataFrame.
df["Fib signals"] = create_fib_clftargetvar(price=df["Close"], lookback_window=10, lookahead_window=5, fib_level=0.618) df.dropna(inplace=True) # drop nan(s) caused by the shifting operation df
Resultado.
| Open | High | Low | Close | Fib signals | |
|---|---|---|---|---|---|
| 9 | 1.3492 | 1.3495 | 1.3361 | 1.3362 | 0.0 |
| 10 | 1.3364 | 1.3405 | 1.3350 | 1.3371 | 0.0 |
| 11 | 1.3370 | 1.3376 | 1.3277 | 1.3300 | 0.0 |
| 12 | 1.3302 | 1.3313 | 1.3248 | 1.3279 | -1.0 |
| 13 | 1.3279 | 1.3293 | 1.3260 | 1.3266 | 0.0 |
En el caso de un problema de regresión
def create_fib_regtargetvar(price: pd.Series, lookback_window: int=10, fib_level: float=0.618): """ This function helps us in calculating the target variable based on fibonacci breakthroughs given a price price: Can be close, open, high, low """ high = price.rolling(lookback_window).max() low = price.rolling(lookback_window).min() return high - (high - low) * fib_level
Para un problema de regresión, no necesitamos desplazar los valores para obtener información futura porque en el trading manual, el nivel de Fibonacci calculado en la ventana anterior (lookback_window) es el que usamos para comparar si los precios futuros lo han cruzado por encima o por debajo.
Nuestro objetivo es entrenar el modelo regresor para que pueda predecir el siguiente valor del nivel de Fibonacci basándose en la ventana de retrospectiva (lookback_window).
df["Fibonacci Level"] = create_fib_regtargetvar(price=df["Close"], lookback_window=10, fib_level=0.618) df.dropna(inplace=True) df.head(5)
A continuación se muestra el Dataframe resultante después de haberle añadido la columna del nivel de Fibonacci.
| Open | High | Low | Close | Fibonacci Level | |
|---|---|---|---|---|---|
| 9 | 1.3492 | 1.3495 | 1.3361 | 1.3362 | 1.343840 |
| 10 | 1.3364 | 1.3405 | 1.3350 | 1.3371 | 1.342923 |
| 11 | 1.3370 | 1.3376 | 1.3277 | 1.3300 | 1.339015 |
| 12 | 1.3302 | 1.3313 | 1.3248 | 1.3279 | 1.337717 |
| 13 | 1.3279 | 1.3293 | 1.3260 | 1.3266 | 1.335195 |
Entrenamiento de un modelo clasificador con una variable objetivo basada en Fibonacci
Empezando por la variable de clasificación denominada «Fib signals», vamos a entrenar con estos datos un modelo sencillo RandomForestClassifier.
Importaciones.
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.utils.class_weight import compute_class_weight from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler
División entre datos de entrenamiento y de prueba.
X = df.drop(columns=[ "Fib signals" ]) y = df["Fib signals"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=False)
El modelo.
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train) weight_dict = dict(zip(np.unique(y_train), class_weights)) model = RandomForestClassifier(n_estimators=100, min_samples_split=2, max_depth=10, class_weight=weight_dict, random_state=42 ) clf_pipeline = Pipeline(steps=[ ("scaler", RobustScaler()), ("rfc", model) ]) clf_pipeline.fit(X_train, y_train)
El modelo Random Forest, al estar basado en árboles de decisión, no necesita necesariamente escalado; aun así, como los valores Open, High, Low y Close (OHLC) son variables continuas y pueden introducir valores atípicos con el paso del tiempo, RobustScaler puede ayudar a atenuar ese problema en los datos.
Finalmente, podemos probar este modelo clasificador tanto en las muestras de entrenamiento como en las de prueba.
y_train_pred = clf_pipeline.predict(X_train) print("Train Classification report\n",classification_report(y_train, y_train_pred)) y_test_pred = clf_pipeline.predict(X_test) print("Test Classification report\n",classification_report(y_test, y_test_pred))
Resultado.
Train Classification report precision recall f1-score support -1.0 0.53 0.55 0.54 4403 0.0 0.59 0.64 0.61 7122 1.0 0.67 0.60 0.64 8294 accuracy 0.61 19819 macro avg 0.60 0.60 0.60 19819 weighted avg 0.61 0.61 0.61 19819 Test Classification report precision recall f1-score support -1.0 0.22 0.22 0.22 1810 0.0 0.38 0.60 0.46 3181 1.0 0.42 0.20 0.27 3504 accuracy 0.35 8495 macro avg 0.34 0.34 0.32 8495 weighted avg 0.36 0.35 0.33 8495
El resultado parece impresionante en la muestra de entrenamiento, pero terrible en la muestra de prueba. Esto indica que el modelo no puede comprender los patrones presentes en una muestra distinta a aquella con la que fue entrenado.
Esto podría deberse a varios factores, como la falta de características que ayuden a capturar patrones significativos presentes en el mercado (las características OHLC por sí solas podrían ser insuficientes), o tal vez la forma rudimentaria de detectar una tendencia basada en la siguiente barra de lookahead_window utilizada al crear la variable objetivo sea mala, lo que provoca que el modelo no detecte barras intermedias en las que el precio podría haber cruzado el nivel de Fibonacci.
Dado que este proceso tenía como objetivo entrenar un modelo para predecir si el precio futuro cruzará el nivel de Fibonacci, este resultado del informe de clasificación podría ser engañoso, ya que no tiene por qué ser perfecto. Por ahora, seguiremos adelante con ello, mientras analizamos el resultado con los datos de prueba en el entorno real de negociación.
Guardemos este modelo entrenado en formato ONNX para su uso externo en el lenguaje de programación MQL5.
import skl2onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
# Define the initial type of the model’s input initial_type = [('input', FloatTensorType([None, X_train.shape[1]]))] # Convert the pipeline to ONNX onnx_model = convert_sklearn(clf_pipeline, initial_types=initial_type, target_opset=13) # Save the ONNX model to a file with open(f"{symbol}.{timeframe}.Fibonnacitarg-RFC.onnx", "wb") as f: f.write(onnx_model.SerializeToString())
Entrenamiento de un modelo de regresión con una variable objetivo basada en Fibonacci
Se pueden seguir los mismos principios al entrenar un modelo de regresión; en este caso, solo difieren el tipo de modelo y la variable de respuesta.
Importaciones.
from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import r2_score
División entre datos de entrenamiento y de prueba.
X = df.drop(columns=[ "Fibonacci Level" ]) y = df["Fibonacci Level"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=False)
El modelo de regresión Random Forest.
model = RandomForestRegressor(n_estimators=100, min_samples_split=2, max_depth=10, random_state=42 ) reg_pipeline = Pipeline(steps=[ ("scaler", RobustScaler()), ("rfr", model) ]) reg_pipeline.fit(X_train, y_train)
Finalmente, podemos probar el modelo de regresión tanto en las muestras de entrenamiento como en las de prueba.
y_train_pred = reg_pipeline.predict(X_train) print("Train accuracy score:",r2_score(y_train, y_train_pred)) y_test_pred = reg_pipeline.predict(X_test) print("Test accuracy score:",r2_score(y_test, y_test_pred))
Resultado.
Train accuracy score: 0.9990321734526452 Test accuracy score: 0.9565827587164671
No podemos extraer demasiadas conclusiones solo a partir de este valor del coeficiente de determinación R2 en un modelo de regresión, aunque un 0,9565 en la muestra de prueba puede considerarse aceptable.
Guardemos este modelo entrenado en formato ONNX para su uso externo en el lenguaje de programación MQL5.
# Define the initial type of the model’s input initial_type = [('input', FloatTensorType([None, X_train.shape[1]]))] # Convert the pipeline to ONNX onnx_model = convert_sklearn(reg_pipeline, initial_types=initial_type, target_opset=13) # Save the ONNX model to a file with open(f"{symbol}.{timeframe}.Fibonnacitarg-RFR.onnx", "wb") as f: f.write(onnx_model.SerializeToString())
Ahora, pongamos a prueba la capacidad predictiva de estos dos modelos en un entorno comercial real.
Prueba de modelos de aprendizaje automático basados en Fibonacci en el Probador de estrategias
Comenzamos agregando modelos de bosques aleatorios en formato ONNX como recursos a nuestro Asesor Experto (EA).
#resource "\\Files\\EURUSD.PERIOD_H4.Fibonnacitarg-RFC.onnx" as uchar rfc_onnx[] #resource "\\Files\\EURUSD.PERIOD_H4.Fibonnacitarg-RFR.onnx" as uchar rfr_onnx[]
A continuación, importamos una biblioteca que nos ayuda a cargar tanto el clasificador de bosque aleatorio como un modelo de regresión en formato ONNX.
#include <Random Forest.mqh>
CRandomForestClassifier rfc;
CRandomForestRegressor rfr; Necesitamos los mismos valores de ventana de anticipación y de retroceso que los que aplicamos en los datos de entrenamiento. Estos valores resultan útiles para determinar cuánto tiempo mantener las posiciones y cuándo cerrarlas.
input group "Models configs"; input target_var_type fib_target = CLASSIFIER; //Model type input int lookahead_window = 5; input int lookback_window = 10;
La variable de entrada fib_target nos ayudará a seleccionar el tipo de modelo a utilizar.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setting the symbol and timeframe if (!MQLInfoInteger(MQL_TESTER) && !MQLInfoInteger(MQL_DEBUG)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe_)) { printf("%s failed to set symbol %s and timeframe %s",__FUNCTION__,symbol_,EnumToString(timeframe_)); return INIT_FAILED; } //--- m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(Symbol()); //--- switch(fib_target) { case REGRESSOR: if (!rfr.Init(rfr_onnx)) { printf("%s failed to initialize the random forest regressor",__FUNCTION__); return INIT_FAILED; } break; case CLASSIFIER: if (!rfc.Init(rfc_onnx)) { printf("%s failed to initialize the random forest classifier",__FUNCTION__); return INIT_FAILED; } break; } //--- return(INIT_SUCCEEDED); }
Dentro de la función OnTick, obtenemos señales del modelo después de pasar los valores OHLC tal como se utilizaron en los datos de entrenamiento.
Esas señales se utilizan posteriormente para abrir operaciones de compra y venta.
void OnTick() { //--- Getting signals from the model if (!isNewBar()) return; vector x = { iOpen(Symbol(), Period(), 1), iHigh(Symbol(), Period(), 1), iLow(Symbol(), Period(), 1), iClose(Symbol(), Period(), 1) }; long signal = 0; switch(fib_target) { case REGRESSOR: { double pred_fib = rfr.predict(x); signal = pred_fib>iClose(Symbol(), Period(), 0)?1:0; //If the predicted fibonacci is greater than the current close price, thats bullish otherwise thats bearish signal } break; case CLASSIFIER: signal = rfc.predict(x).cls; break; } //--- Trading based on the signals received from the model MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); if (signal == 1) { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask); } if (signal == 0) { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid); } //--- Closing trades switch(fib_target) { case CLASSIFIER: CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead_window)*60); //Close the trade after a certain lookahead and according the the trained timeframe break; case REGRESSOR: CloseTradeAfterTime((Timeframe2Minutes(Period())*lookback_window)*60); //Close the trade after a certain lookahead and according the the trained timeframe break; } }
El cierre de las operaciones depende del tipo de modelo seleccionado y de los valores de lookahead_window y lookback_window.
Cuando el modelo seleccionado sea un clasificador, las operaciones se cerrarán una vez que hayan transcurrido en el marco temporal actual un número de barras igual a lookahead_window.
Cuando el modelo seleccionado sea un regresor, las operaciones se cerrarán una vez que hayan transcurrido en el marco temporal actual un número de barras igual a lookback_window.
Esto se debe a la forma en que hemos creado las variables de destino dentro del script de Python.
Por último, podemos probar estos dos modelos en el Probador de estrategias.
Dado que los datos de entrenamiento se recopilaron entre el 1 de enero de 2005 y el 1 de enero de 2023, probemos los resultados del modelo para el periodo comprendido entre el 1 de enero de 2023 y el 31 de diciembre de 2023 (datos fuera de la muestra).
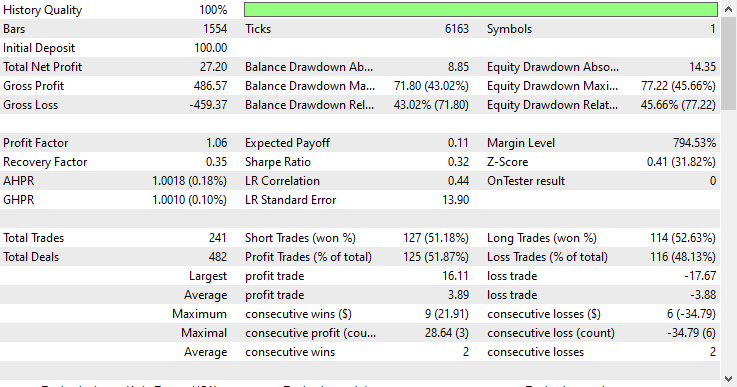
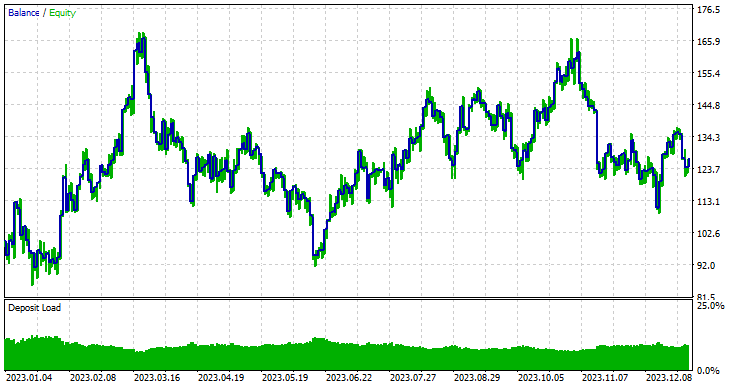
Tipo de modelo: Clasificador
Tipo de modelo: Regresor
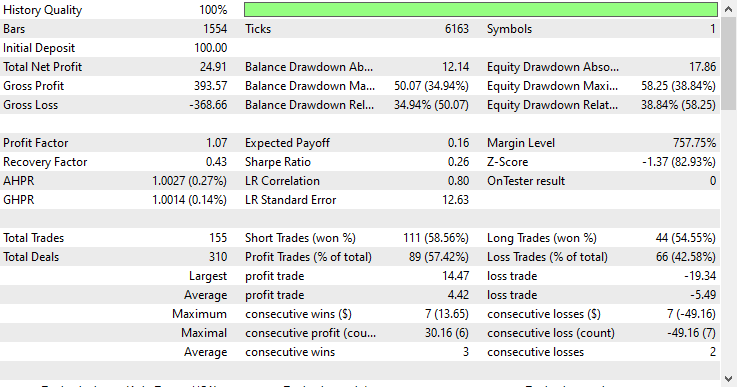
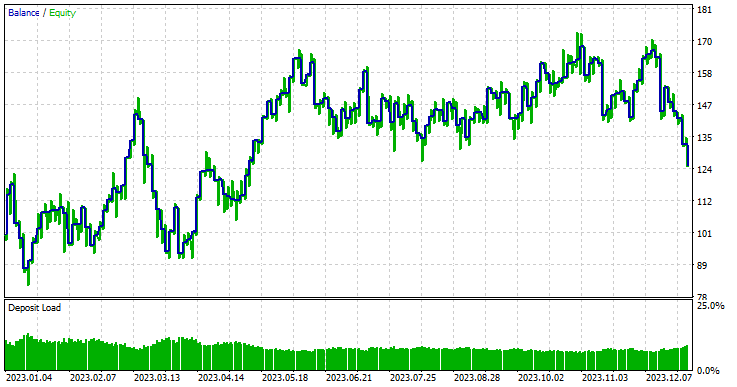
El modelo de regresión obtuvo unos resultados excepcionales, teniendo en cuenta que se trata de datos fuera de la muestra, con una tasa de acierto del 57,42 %.
Para simplificar las cosas y que el modelo de regresión resultara útil, dentro del robot de trading convertí el resultado continuo proporcionado por un modelo de regresión de bosque aleatorio en una solución binaria.
signal = pred_fib>iClose(Symbol(), Period(), 0)?1:0; //If the predicted Fibonacci is greater than the current close price, that's bullish otherwise that's bearish signal
Esto cambia por completo la forma en que interpretamos el nivel de Fibonacci previsto porque, a diferencia de lo que solemos hacer en el trading manual, solemos abrir una operación al final de la tendencia una vez recibida una señal de confirmación. Después, fijamos niveles objetivo en algún nivel de Fibonacci, normalmente el 61,8 %.
Al utilizar este enfoque, asumimos que nuestros modelos de aprendizaje automático ya han comprendido este patrón durante un período de tiempo determinado, tanto retrospectivo como prospectivo, utilizado en los datos de entrenamiento, por lo que simplemente abrimos algunas operaciones y las mantenemos de acuerdo con el número de barras especificado.
La clave aquí son los valores de las ventanas de anticipación y retrospectiva, sobre todo porque, cuando utilizamos la herramienta de Fibonacci en el trading manual, no tenemos en cuenta el número de barras que se deben utilizar para sus cálculos (valores mínimos y máximos); por lo general, colocamos la herramienta donde nos parece más adecuado.
Si bien la herramienta funciona bien en las operaciones manuales, nos engaña haciéndonos creer que la tenemos en el lugar correcto, cuando en realidad solo la estamos colocando donde queremos sin tener en mente reglas claras.
Estos dos valores (ventanas de anticipación y de retroceso) son los que debemos optimizar si queremos explorar la efectividad de los niveles de Fibonacci en la creación de la variable objetivo y para su uso en el aprendizaje automático en general.
Reflexiones finales
Los retrocesos y niveles de Fibonacci son técnicas poderosas para crear la variable objetivo para el aprendizaje automático, como lo ilustra el informe del probador de estrategias anterior producido por el modelo de regresión. Incluso con tan pocos predictores como los valores de Apertura, Máximo, Mínimo y Cierre, que no ofrecen muchos patrones, los modelos podrían detectar algunos patrones valiosos y obtener buenos resultados en comparación con las conjeturas aleatorias, basándose en la información aprendida de los niveles de Fibonacci.
Independientemente de cómo se analicen los resultados, en mi opinión son impresionantes.
Tal como está planteada, esta idea no está lo suficientemente pulida; necesitamos añadir más características a nuestros datos, como lecturas de indicadores y confirmaciones de estrategias de negociación, para ayudar a nuestro modelo basado en Fibonacci a capturar patrones complejos que se producen en el mercado. Además, no dude en explorar otros niveles de Fibonacci.
Cuando esta idea se perfeccione aún más, considero que resultará muy eficaz en los mercados de valores e índices, donde se producen retrocesos con regularidad en algunas tendencias alcistas a largo plazo, así como en marcos temporales de mayor alcance, como el diario, en el que los datos son «menos ruidosos».
Tabla de archivos adjuntos
| Nombre y ruta del archivo | Descripción y uso |
|---|---|
| Experts\Fibonacci AI based.mq5 | El principal asesor experto para la prueba de modelos de aprendizaje automático. |
| Include\Random Forest.mqh | Contiene clases para cargar y desplegar el clasificador y el regresor de bosque aleatorio presentes en formato .ONNX. |
| Files\*.onnx | Modelos de aprendizaje automático en formato ONNX. |
| Files\*.csv | Archivos CSV que contienen conjuntos de datos que se utilizarán para entrenar modelos de aprendizaje automático. |
| Python\fibbonanci-in-ml.ipynb | Script de Python para procesar los datos y entrenar los modelos de bosque aleatorio. |
Fuentes y referencias
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/18078
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso