
Aprendizaje automático y Data Science (Parte 38): Aprendizaje por transferencia de IA en los mercados de divisas

Contenido
- ¿Qué es el aprendizaje por transferencia?
- ¿Cómo funciona?
- Ventajas del aprendizaje por transferencia
- Un modelo básico sencillo
- El problema con las variables continuas
- Aprendizaje por transferencia
- Aprendizaje por transferencia en un robot de trading
- Reflexiones finales
¿Qué es el aprendizaje por transferencia?
El aprendizaje por transferencia es una técnica de aprendizaje automático en la que un modelo entrenado para una tarea se reutiliza como base para una segunda tarea.
En el aprendizaje por transferencia, en lugar de entrenar un modelo de aprendizaje automático desde cero, transferimos el conocimiento aprendido por un modelo preentrenado y lo ajustamos para una nueva tarea específica. Esta técnica resulta bastante útil cuando:
- No disponemos de muchos datos etiquetados para una tarea en particular.
- Entrenar un modelo desde cero llevaría demasiado tiempo o requeriría demasiada potencia computacional.
- La tarea en cuestión guarda similitudes con aquella para la que se entrenó el modelo original.
Aquí tenemos un ejemplo real de cómo los expertos en IA utilizan el aprendizaje por transferencia:
Supongamos que estás creando un clasificador de imágenes para distinguir entre gatos y perros, pero solo tienes 1.000 imágenes. Entrenar una CNN profunda desde cero resultaría complicado; en su lugar, puedes usar un modelo como ResNet50 o VGG16 que ya esté entrenado en ImageNet (que cuenta con millones de imágenes repartidas en 1000 clases), utilizar sus capas convolucionales como extractores de características, añadir sus capas de clasificación personalizadas y ajustarlo en su conjunto de datos más pequeño de gatos y perros.
Este proceso permite reutilizar el conocimiento del modelo, lo que nos facilita el trabajo como desarrolladores, ya que no queremos reinventar la rueda cada vez; en lugar de entrenar un modelo desde cero, podemos basarnos en modelos existentes diseñados para una tarea muy similar.
Se dice que la mayoría de las personas que saben patinar o practican patinaje con regularidad también suelen desenvolverse bien en el esquí, y viceversa, a pesar de no haber recibido un entrenamiento intensivo en cada disciplina. Esto se debe simplemente a que estos dos deportes presentan algunas similitudes.
Esto también es válido para los mercados financieros, donde, a pesar de contar con diferentes instrumentos (símbolos) que representan distintos activos económicos o mercados financieros, todos los mercados se comportan de manera similar la mayor parte del tiempo, ya que todos ellos se ven impulsados y afectados por la oferta y la demanda.

Si se analiza el mercado con detenimiento desde un punto de vista técnico, se observa que todos los mercados tienden a subir y bajar, que se muestran patrones de velas japonesas similares en todos ellos, que los indicadores presentan patrones similares en diferentes instrumentos, y mucho más. Esta es la razón principal por la que a menudo aprendemos una estrategia de análisis técnico para operar con un instrumento y aplicamos el conocimiento adquirido a todos los mercados, independientemente de las diferencias en la magnitud de los precios que ofrece cada instrumento.
En el aprendizaje automático, los modelos a menudo no comprenden que estos mercados son comparables. En este artículo, vamos a analizar cómo aprovechar el aprendizaje por transferencia para ayudar a los modelos a comprender patrones en diversos instrumentos financieros y entrenarlos de forma más eficaz, cuáles son las ventajas y desventajas de esta técnica y qué aspectos conviene tener en cuenta para aplicar el aprendizaje por transferencia de forma eficaz.
¿Cómo funciona el aprendizaje por transferencia?
El aprendizaje por transferencia es una forma inteligente de reutilizar lo que un modelo ya ha aprendido de una tarea y aplicarlo a una tarea diferente pero relacionada. Ahorra tiempo y, a menudo, mejora el rendimiento.
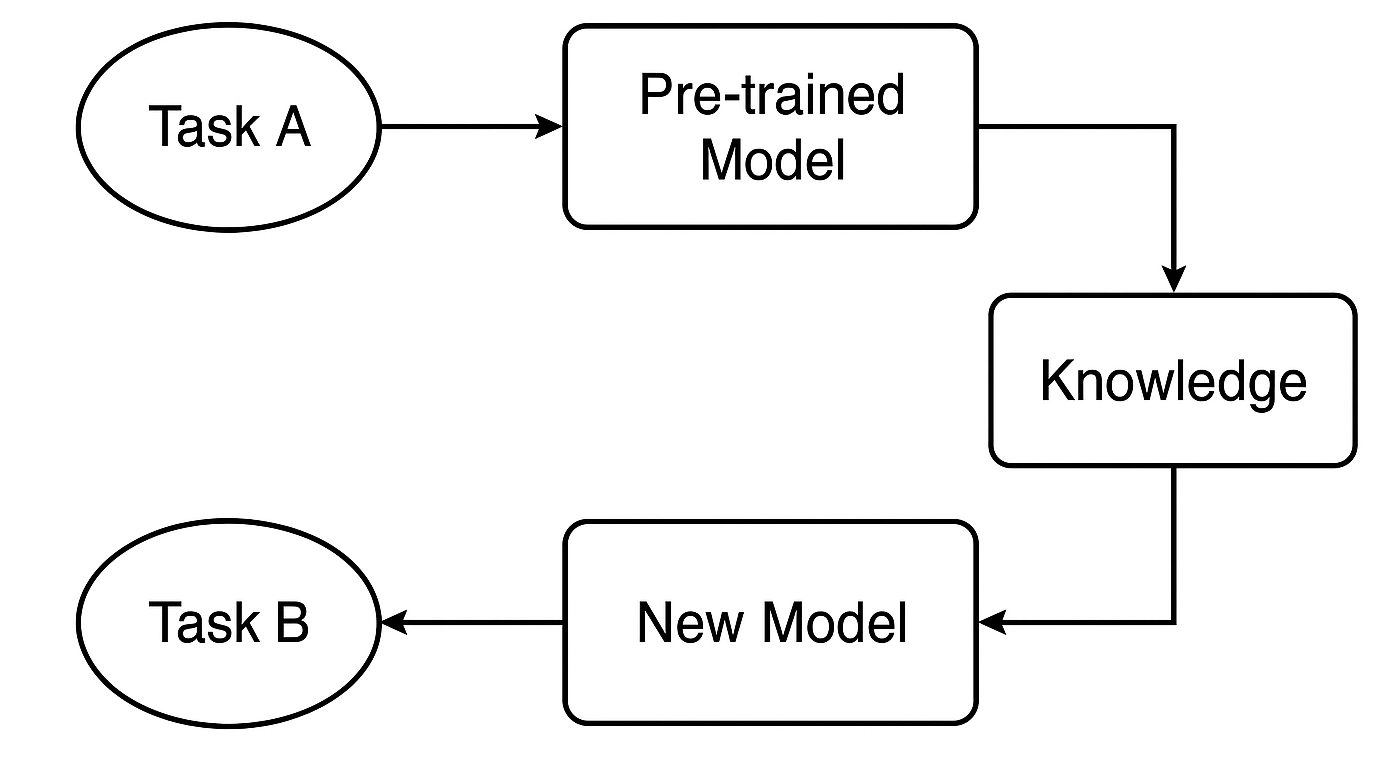
¿Qué es un modelo preentrenado?
Comenzamos con un modelo que ya ha sido entrenado con un gran conjunto de datos para la Tarea A. Este modelo ha aprendido a reconocer patrones y características generales que son útiles para tareas similares.
En el trading, por ejemplo, podría tratarse de un modelo entrenado con una estrategia o símbolo específico, que ya comprende los comportamientos comunes del mercado que también aparecen en otros instrumentos de divisas.
¿Cómo se transfiere el conocimiento?
Si utilizamos una red neuronal como una CNN o una RNN, podemos tomar las primeras capas —las que capturan características generales— y reutilizarlas. Estas capas actúan como una base, detectando patrones generales que resultan útiles tanto para las tareas originales como para las nuevas.
Ajustes para la nueva tarea
A continuación, ajustamos el modelo para la Tarea B —quizás otro instrumento o estrategia— modificando ciertas capas o parámetros para que funcione correctamente con los nuevos datos. Este paso adapta el modelo a la nueva situación.
¿Por qué utilizar el aprendizaje por transferencia?
1. Entrenamiento más rápido
En lugar de empezar desde cero, reutilizamos las características aprendidas. Esto reduce significativamente el tiempo de entrenamiento, especialmente en el aprendizaje profundo, donde ahorrar horas o incluso días de cálculo puede marcar una gran diferencia.
2. A menudo mejora la precisión
Los modelos que utilizan aprendizaje por transferencia tienden a rendir mejor, especialmente cuando los datos etiquetados son limitados. El modelo preentrenado ya sabe detectar señales importantes, como configuraciones de mercado o indicadores, lo que le ayuda a tomar decisiones más inteligentes en la nueva tarea.
3. Funciona incluso con conjuntos de datos pequeños o ruidosos.
Seamos realistas: obtener buenos datos históricos o de ticks en MetaTrader 5 para algunos símbolos es difícil. Algunos instrumentos simplemente no tienen suficientes datos. Pero al utilizar un modelo entrenado con un conjunto de datos más completo, podemos evitar el sobreajuste y aun así construir un modelo sólido, incluso con datos limitados.
4. Conocimiento reutilizable en diferentes instrumentos
Los mercados suelen comportarse de forma similar a nivel técnico. Así, en lugar de entrenar un nuevo modelo para cada símbolo, podemos compartir y reutilizar el conocimiento entre diferentes instrumentos, lo que ahorra tiempo y mejora la coherencia.
Un modelo base sencillo
Vamos a entrenar un clasificador simple de bosque aleatorio (Random Forest) para obtener un punto de partida (un modelo base). Para simplificar, podemos usar los valores OHLC (Apertura, Máximo, Mínimo y Cierre).
Comenzamos recopilando valores OHLC de varios instrumentos de divisas principales y secundarios, incluyendo también algunos metales.
#include <pandas.mqh> //https://www.mql5.com/en/articles/17030 input datetime start_date = D'2005.01.01'; input datetime end_date = D'2023.01.01'; input string symbols = "EURUSD|GBPUSD|AUDUSD|USDCAD|USDJPY|USDCHF|NZDUSD|EURNZD|AUDNZD|GBPNZD|NZDCHF|NZDJPY|NZDCAD|XAUUSD|XAUJPY|XAUEUR|XAUGBP"; input ENUM_TIMEFRAMES timeframe = PERIOD_D1; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string SymbolsArr[]; ushort sep = StringGetCharacter("|",0); if (StringSplit(symbols, sep, SymbolsArr)<0) { printf("%s failed to split the symbols, Error %d",__FUNCTION__,GetLastError()); return; } //--- vector open, high, low, close; for (uint i=0; i<SymbolsArr.Size(); i++) { string symbol = SymbolsArr[i]; if (!SymbolSelect(symbol, true)) { printf("%s failed to select symbol %s, Error = %d",__FUNCTION__,symbol,GetLastError()); continue; } //--- open.CopyRates(symbol, timeframe, COPY_RATES_OPEN, start_date, end_date); high.CopyRates(symbol, timeframe, COPY_RATES_HIGH, start_date, end_date); low.CopyRates(symbol, timeframe, COPY_RATES_LOW, start_date, end_date); close.CopyRates(symbol, timeframe, COPY_RATES_CLOSE, start_date, end_date); CDataFrame df; df.insert("Open", open); df.insert("High", high); df.insert("Low", low); df.insert("Close", close); df.to_csv(StringFormat("Fxdata.%s.%s.csv",symbol,EnumToString(timeframe)), true); } }
Tras recopilar los datos, podemos acceder a los archivos CSV directamente desde un script de Python.
def getXandY(symbol: str, timeframe: str, lookahead: int) -> tuple: df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{symbol}.{timeframe}.csv") # Target variable df["future_close"] = df["Close"].shift(-lookahead) df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) # Splitting data into X and y X = df.drop(columns=[ "future_close", "Signal" ]) y = df["Signal"] return (X, y)
Tras leer el archivo CSV, la función getXandY prepara la variable objetivo basándose en una lógica sencilla: si el precio de cierre de la siguiente barra es superior al precio de cierre actual, se trata de una señal alcista, y lo contrario cuando el precio de cierre de la siguiente barra es inferior al precio de cierre actual.
Creemos una función para entrenar un modelo a partir de datos X e y y que devuelva un modelo entrenado en un pipeline de Scikit-learn.
def trainSymbol(X_train: pd.DataFrame, y_train: pd.DataFrame) -> Pipeline: # Training a model classifier = RandomForestClassifier(n_estimators=100, min_samples_split=3, max_depth = 5) pipeline = Pipeline([ ("scaler", RobustScaler()), ("classifier", classifier) ]) pipeline.fit(X_train, y_train) return pipeline
Sería útil contar con una función para evaluar este modelo con diferentes instrumentos.
def evalSymbol(model: Pipeline, X: pd.DataFrame , y: pd.Series) -> int: # evaluating the model preds = model.predict(X) acc = accuracy_score(y, preds) return acc
Entrenemos nuestro modelo base con el par EURUSD y luego evaluemos su rendimiento con el resto de los símbolos que hemos recopilado.
symbols = ["EURUSD","GBPUSD","AUDUSD","USDCAD","USDJPY","USDCHF","NZDUSD","EURNZD","AUDNZD","GBPNZD","NZDCHF","NZDJPY","NZDCAD","XAUUSD","XAUJPY","XAUEUR","XAUGBP"] # training on EURUSD lookahead = 1 X, y = getXandY(symbol=symbols[0], timeframe="PERIOD_H4", lookahead=lookahead) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, shuffle=True) model = trainSymbol(X_train, y_train) # Evaluating on the rest of symbols trained_symbol = symbols[0] print(f"Trained on {trained_symbol}") for symbol in symbols: X, y = getXandY(symbol=symbol, timeframe="PERIOD_H4", lookahead=1) acc = evalSymbol(model, X, y) print(f"--> {symbol} | acc: {acc}")
Resultados.
Trained on EURUSD --> EURUSD | acc: 0.5478518727715607 --> GBPUSD | acc: 0.5009182736455464 --> AUDUSD | acc: 0.5026133634694165 --> USDCAD | acc: 0.4973701860284514 --> USDJPY | acc: 0.49477401129943505 --> USDCHF | acc: 0.5078731817539895 --> NZDUSD | acc: 0.4976826463824518 --> EURNZD | acc: 0.5071507150715071 --> AUDNZD | acc: 0.5005597760895641 --> GBPNZD | acc: 0.503459397596629 --> NZDCHF | acc: 0.4990389436737423 --> NZDJPY | acc: 0.4908841561794127 --> NZDCAD | acc: 0.5023507681974645 --> XAUUSD | acc: 0.48674396277970605 --> XAUJPY | acc: 0.4816082121471343 --> XAUEUR | acc: 0.4925268155442237 --> XAUGBP | acc: 0.49455864570737607
El modelo tuvo una precisión de 0,54 en el símbolo con el que fue entrenado, y la precisión en el resto osciló entre 0,48 y 0,50. Podría pensarse que este resultado no se desvía mucho del obtenido en el símbolo de entrenamiento, por lo que esto significa que el modelo funciona bien en símbolos con los que no fue entrenado, por decir lo menos; sin embargo, este es un resultado terrible.
Sencillamente porque una tasa de éxito de 0,5 sobre 1 (50% sobre 100%) es como lanzar una moneda al aire, tu probabilidad de ganar es de 0,5 sobre 1.
Aunque el modelo base parece hacer algunas predicciones sobre otros instrumentos con los que no fue entrenado, tenemos un gran problema causado por las variables continuas: esos valores OHLC.
El problema de las variables continuas
Dado que queremos que nuestro modelo base sea robusto y universal, capaz de detectar patrones y operar con diversos símbolos, las variables continuas, como los precios de apertura, máximo, mínimo y cierre, no son adecuadas para esta tarea porque no ofrecen ningún patrón más allá de una representación de cómo se movieron los precios en el pasado.
Sin mencionar que cada instrumento tiene un precio de una magnitud muy diferente al de los demás. Por ejemplo, los precios de cierre de hoy son los siguientes:
| SÍMBOLO | PRECIO DE CIERRE DIARIO |
|---|---|
| USDJPY | 142.17 |
| EURUSD | 1.13839 |
| XAUUSD | 3305.02 |
Esto significa que un modelo entrenado con un instrumento podría no ser capaz de generalizar bien a otros debido a las diferencias de precio entre ellos.
Además de no contener patrones fáciles de aprender, los modelos entrenados con variables continuas requieren reentrenamiento frecuente, porque los mercados alcanzan nuevos niveles cada día. Eso obliga a actualizarlos con información reciente de forma regular, lo que aumenta el coste computacional, algo que el aprendizaje por transferencia pretende mitigar.
Solo las variables estacionarias son capaces de ayudar a los modelos de aprendizaje automático a captar la esencia y adquirir relevancia en distintos mercados, simplemente porque su media, varianza y autocorrelación no varían con el tiempo (se mantienen constantes). Esto se puede observar en diferentes instrumentos.
Si queremos aprovechar el aprendizaje por transferencia, todas las características, como los indicadores y los patrones extraídos del mercado, que utilizamos en nuestras variables independientes deben ser constantes o estacionarias.
Por ejemplo, si se toman lecturas del indicador RSI en cualquier instrumento, los valores seguirán estando entre 0 y 100, lo cual es crucial para detectar patrones.
Ingeniería de características
Existen numerosas técnicas que podemos emplear para obtener variables estacionarias, pero por ahora, podemos utilizar algunas técnicas para elaborar nuestros datos, como calcular el cambio porcentual en el precio de cierre, diferenciar cada valor OHLC y utilizar algunos indicadores estacionarios.
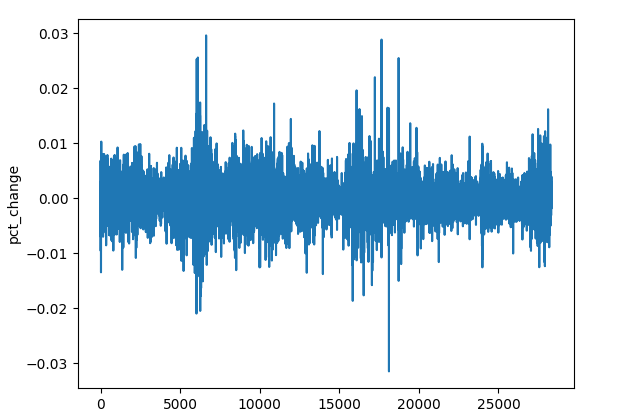
(a): Variación porcentual del precio de cierre
res_df["pct_change"] = df["Close"].pct_change()
A pesar de las diferencias de magnitud de precio entre los distintos símbolos, los valores de variación porcentual mantienen una escala comparable, lo que los convierte en una buena característica universal para la detección de patrones.
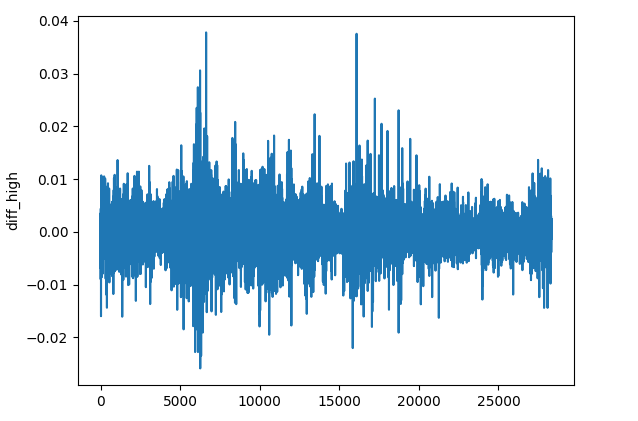
(b): Diferenciar cada valor OHLC
res_df["diff_open"] = df["Open"].diff() res_df["diff_high"] = df["High"].diff() res_df["diff_low"] = df["Low"].diff() res_df["diff_close"] = df["Close"].diff()
El método diff() calcula la diferencia entre el elemento actual y el anterior (por defecto). Esta función nos permite detectar cómo cambia el precio en cada barra en comparación con la anterior en cada instrumento.
(c): Indicadores estacionarios
Podemos añadir algunos indicadores de impulso y osciladores que produzcan valores estacionarios.
Indicador | Rango de valores |
|---|---|
# Relative Strength Index (RSI) res_df['rsi'] = ta.momentum.RSIIndicator(df["Close"], window=14).rsi() | De 0 a 100. |
# Stochastic Oscillator (Stoch) res_df['stoch_k'] = ta.momentum.StochasticOscillator(df['High'], df['Low'], df['Close'], window=14).stoch() | De 0 a 100. |
# Moving Average Convergence Divergence (MACD) res_df['macd'] = ta.trend.MACD(df["Close"]).macd() | Valores pequeños, tanto positivos como negativos, generalmente entre -0,1 y +0,1. |
# Commodity Channel Index (CCI) res_df['cci'] = ta.trend.CCIIndicator(df['High'], df['Low'], df['Close'], window=20).cci() | Normalmente de -300 a +300. |
# Rate of Change (ROC) res_df['roc'] = ta.momentum.ROCIndicator(df["Close"], window=12).roc() | Ilimitado, puede ser negativo o positivo. |
# Ultimate Oscillator (UO) res_df['uo'] = ta.momentum.UltimateOscillator(df['High'], df['Low'], df['Close'], window1=7, window2=14, window3=28).ultimate_oscillator() | De 0 a 100. |
# Williams %R res_df['williams_r'] = ta.momentum.WilliamsRIndicator(df['High'], df['Low'], df['Close']).williams_r() | De -100 a 0. |
# Average True Range (ATR) res_df['atr'] = ta.volatility.AverageTrueRange(df['High'], df['Low'], df['Close'], window=14).average_true_range() | Valores positivos pequeños no acotados. |
# Awesome Oscillator (AO) res_df['ao'] = ta.momentum.AwesomeOscillatorIndicator(df['High'], df['Low']).awesome_oscillator() | Valores pequeños sin límite, normalmente de -0,1 a +0,1. |
# Average Directional Index (ADX) res_df['adx'] = ta.trend.ADXIndicator(df['High'], df['Low'], df['Close'], window=14).adx() | De 0 a 100. |
# True Strength Index (TSI) res_df['tsi'] = ta.momentum.TSIIndicator(df['Close'], window_slow=25, window_fast=13).tsi() | Normalmente de -100 a +100. |
Estas son solo algunas variables estacionarias; puedes añadir otras que consideres adecuadas.
Todos estos métodos y operaciones se pueden encapsular en una función independiente.
def getStationaryVars(df: pd.DataFrame) -> pd.DataFrame: res_df = pd.DataFrame() res_df["pct_change"] = df["Close"].pct_change() res_df["diff_open"] = df["Open"].diff() res_df["diff_high"] = df["High"].diff() res_df["diff_low"] = df["Low"].diff() res_df["diff_close"] = df["Close"].diff() # Relative Strength Index (RSI) res_df['rsi'] = ta.momentum.RSIIndicator(df["Close"], window=14).rsi() # Stochastic Oscillator (Stoch) res_df['stoch_k'] = ta.momentum.StochasticOscillator(df['High'], df['Low'], df['Close'], window=14).stoch() # Moving Average Convergence Divergence (MACD) res_df['macd'] = ta.trend.MACD(df["Close"]).macd() # Commodity Channel Index (CCI) res_df['cci'] = ta.trend.CCIIndicator(df['High'], df['Low'], df['Close'], window=20).cci() # .... See the code in the notebook in the attachments and above # .... # .... # True Strength Index (TSI) res_df['tsi'] = ta.momentum.TSIIndicator(df['Close'], window_slow=25, window_fast=13).tsi() return res_df
Ahora vamos a crear un modelo base que se utilizará para transferir conocimientos de un instrumento a otro.
Aprendizaje por transferencia
El aprendizaje por transferencia se suele aplicar a modelos profundos, principalmente a redes neuronales convolucionales (CNN). Dado que las CNN destacan en la detección de patrones, esta capacidad les permite identificar patrones similares que, a su vez, pueden transferirse a diferentes aspectos dentro del mismo ámbito.
Encapsulemos un modelo de red neuronal convolucional (CNN) en una función denominada trainCNN.
import tensorflow as tf from tensorflow.keras import layers, models, Model from tensorflow.keras.callbacks import EarlyStopping
def trainCNN(train_set: tuple, val_set: tuple, learning_rate: float=1e-3, epochs: int=100, batch_size: int=32): X_train, y_train = train_set X_val, y_val = val_set input_shape = X_train.shape[1:] num_classes = len(np.unique(y_train)) model = models.Sequential([ layers.Input(shape=input_shape), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.GlobalAveragePooling1D(), layers.Dense(32, activation='tanh'), layers.Dense(num_classes, activation='softmax') ]) # Compile with Adam optimizer model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='categorical_crossentropy', metrics=['accuracy'] ) # Early stopping callback early_stop = EarlyStopping( monitor='val_loss', # Watch validation loss patience=10, # Stop if no improvement restore_best_weights=True ) # Train the model model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=epochs, batch_size=batch_size, callbacks=[early_stop], verbose=1 ) # Save trained weights model.save_weights('cnn_pretrained.weights.h5') return model
Este modelo secuencial cuenta con dos capas convolucionales unidimensionales que pueden ayudarnos a extraer las características de la secuencia de entrada.
Se introduce la capa de agrupación global para reducir las secuencias, de modo que puedan introducirse en una capa densa (capa FNN) con una función de activación tanh.
La última capa utiliza una función de activación softmax para obtener las probabilidades previstas para cada clase.
Guardamos los pesos del modelo tal como están, ya que representan los patrones aprendidos a partir de los datos; estos pesos pueden transferirse a otro modelo.
Utilizando el par EURUSD en un marco temporal de 4 horas, podemos recopilar los valores OHLC del marco de datos original.
lookahead = 1 trained_symbol = symbols[0] timeframe = "PERIOD_H4" df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{trained_symbol}.{timeframe}.csv") stationary_df = getStationaryVars(df) stationary_df["Close"] = df["Close"] # add the close price for crafting the target variable X, y = getXandY(df=stationary_df, lookahead=lookahead)
Una vez más, la función getXandY crea una variable de destino utilizando los valores de «Close» y basándose en el valor de anticipación proporcionado (1 en este caso).
def getXandY(df: pd.DataFrame, lookahead: int) -> tuple: # Target variable df["future_close"] = df["Close"].shift(-lookahead) df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) # if next bar closed above the current one, thats a bullish signal otherwise bearish # Splitting data into X and y X = df.drop(columns=[ "Close", "future_close", "Signal" ]) y = df["Signal"] return (X, y)
Debemos dividir los datos en conjuntos de entrenamiento y de validación (prueba) y, a continuación, normalizar el resultado utilizando un escalador de nuestra elección; en este caso, el escalador robusto (Robust Scaler).
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=42) # Scalling the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)
Dado que las redes neuronales convolucionales (CNN) requieren datos de entrada tridimensionales, podemos procesar estos datos para que se ajusten a una ventana específica, con el fin de detectar patrones temporales en ese horizonte concreto.
def create_sequences(X, Y, time_step): if len(X) != len(Y): raise ValueError("X and y must have the same length") X = np.array(X) Y = np.array(Y) Xs, Ys = [], [] for i in range(X.shape[0] - time_step): Xs.append(X[i:(i + time_step), :]) # Include all features with slicing Ys.append(Y[i + time_step]) return np.array(Xs), np.array(Ys)
# Prepare data within a window window = 10 X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, window) X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, window)
La codificación «one-hot» es fundamental para la variable de destino en cualquier problema de clasificación en el que intervengan redes neuronales, ya que les ayuda a distinguir las clases.
# One-hot encode the labels for multi-class classification
y_train_encoded = to_categorical(y_train_seq, num_classes=num_classes)
y_test_encoded = to_categorical(y_test_seq, num_classes=num_classes)
Finalmente, podemos entrenar un modelo base.
base_model = trainCNN(train_set=(X_train_seq, y_train_encoded), val_set=(X_test_seq, y_test_encoded), learning_rate = 0.01, epochs = 1000, batch_size =32) print("Test acc: ", base_model.evaluate(X_test_seq, y_test_encoded)[1])
Resultados.
Epoch 1/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 4s 4ms/step - accuracy: 0.4994 - loss: 0.6990 - val_accuracy: 0.5023 - val_loss: 0.6938 Epoch 2/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4976 - loss: 0.6939 - val_accuracy: 0.5023 - val_loss: 0.6936 Epoch 3/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4977 - loss: 0.6940 - val_accuracy: 0.5023 - val_loss: 0.6938 Epoch 4/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5034 - loss: 0.6937 - val_accuracy: 0.4977 - val_loss: 0.6962 ... ... Epoch 16/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5039 - loss: 0.6934 - val_accuracy: 0.5023 - val_loss: 0.6932 Epoch 17/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4988 - loss: 0.6940 - val_accuracy: 0.4977 - val_loss: 0.6937 Epoch 18/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5013 - loss: 0.6943 - val_accuracy: 0.5023 - val_loss: 0.6931 266/266 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.5037 - loss: 0.6931 Test acc: 0.5022971034049988
¡Genial! Acabamos de entrenar un modelo base para el par EURUSD y hemos logrado una precisión general de 0,502.
Ahora, usemos este modelo para transferir y compartir conocimientos sobre otros modelos entrenados con diferentes instrumentos y veamos qué tal funciona.
for symbol in symbols: if symbol == trained_symbol: # skip transfer learning on the trained symbol continue print(f"Symbol: {symbol}") df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{symbol}.{timeframe}.csv") stationary_df = getStationaryVars(df) stationary_df["Close"] = df["Close"] # we add the close price for crafting the target variable X, y = getXandY(df=stationary_df, lookahead=lookahead) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=42) # Scalling the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # Prepare data within a window window = 10 X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, window) X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, window) # One-hot encode the labels for multi-class classification y_train_encoded = to_categorical(y_train_seq, num_classes=num_classes) y_test_encoded = to_categorical(y_test_seq, num_classes=num_classes) # Freeze all layers except the last one for layer in base_model.layers[:-1]: layer.trainable = False # Create new model using the base model's architecture model = models.clone_model(base_model) model.set_weights(base_model.get_weights()) # Recompile with lower learning rate model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy']) early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = model.fit(X_train_seq, y_train_encoded, validation_data=(X_test_seq, y_test_encoded), epochs=1000, # More epochs for fine-tuning batch_size=32, callbacks=[early_stop], verbose=1) print("Test acc:", model.evaluate(X_test_seq, y_test_encoded)[1])
Los mismos procesos se repiten para dividir los datos, crear datos secuenciales y codificar la variable objetivo. Las operaciones se especifican únicamente para cada símbolo.
Para transferir el conocimiento del modelo base, construimos otro modelo basado en el primero; lo crucial aquí es congelar algunas de las capas de la CNN.
Congelamos todas las capas de un modelo CNN excepto la última porque queremos que nuestro modelo conserve los patrones aprendidos a partir de los datos base. Al congelar algunas de las capas, evitamos que se destruyan características útiles al volver a entrenar este modelo con nuevos datos.
Dejamos la capa final sin congelar porque queremos que los pesos de la capa final se recalibren a nuevos límites de decisión para cada símbolo, así que, básicamente, proporcionamos al modelo nuevas distribuciones en la variable objetivo y dejamos que determine las relaciones entre los patrones aprendidos del modelo base y lo que hay en la variable objetivo en estos nuevos datos.
También clonamos la arquitectura del modelo base en el modelo actual y asignamos sus pesos al nuevo modelo. Recuerda que guardamos los pesos en la función trainCNN. Puedes cargar los pesos desde un archivo cuando importas el modelo desde algún lugar o cargar los pesos del modelo directamente desde el objeto del modelo si el modelo base está en el mismo script o archivo de Python, tal como se indicó anteriormente.
Finalmente, compilamos el modelo utilizando datos de mercado de un instrumento distinto al empleado para entrenar el modelo base; también se pueden modificar otros parámetros.
A continuación se muestra la precisión alcanzada con diferentes símbolos de divisas.
| SÍMBOLO | GBPUSD | AUDUSD | USDCAD | USDJPY | USDCHF | NZDUSD | EURNZD | AUDNZD | GBPNZD | NZDCHF | NZDJPY | NZDCAD | XAUUSD | XAUJPY | XAUEUR | XAUGBP |
| PRECISIÓN | 0.505 | 0.506 | 0.501 | 0.516 | 0.506 | 0.497 | 0.505 | 0.502 | 0.504 | 0.505 | 0.51 | 0.505 | 0.506 | 0.514 | 0.507 | 0.504 |
Este resultado no nos aporta mucha información, así que vamos a incorporar el informe de clasificación para analizarlo en detalle.
preds = base_model.predict(X_test_seq) pred_indices = preds.argmax(axis=1) pred_class_labels = [classes_in_y[i] for i in pred_indices] print("Classification report\n", classification_report(pred_class_labels, y_test_seq))
El informe de clasificación del modelo base.
Classification report precision recall f1-score support 0 1.00 0.50 0.66 8477 1 0.00 0.00 0.00 0 accuracy 0.50 8477 macro avg 0.50 0.25 0.33 8477 weighted avg 1.00 0.50 0.66 8477
Este resultado indica un resultado muy pobre. El modelo generó un informe de clasificación con un sesgo considerable.
Esto indica que nuestro modelo presenta un sesgo que podría deberse al propio modelo o a los datos.
Hay varias formas de abordar este sesgo, tal y como comentamos en este artículo anterior, pero, por ahora, hagamos lo siguiente:
(a): Añadamos ponderaciones de clase para corregir el desequilibrio entre clases, si existe en nuestros datos.
from sklearn.utils.class_weight import compute_class_weight
def trainCNN: #.... #.... y_train_integers = np.argmax(y_train, axis=1) # return to non-one hot encoded class_weights = compute_class_weight('balanced', classes=np.unique(y_train_integers), y=y_train_integers) class_weight_dict = {i: weight for i, weight in enumerate(class_weights)} # Train the model model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=epochs, batch_size=batch_size, callbacks=[early_stop], class_weight=class_weight_dict, verbose=1 )
(b): Añadamos otra capa convolucional y aumentemos el número de neuronas en la capa densa para facilitar la detección de patrones complejos.
def trainCNN: # ... # ... model = models.Sequential([ layers.Input(shape=input_shape), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(32, kernel_size=3, activation='relu', padding='same'), layers.GlobalAveragePooling1D(), layers.Dense(128, activation='relu'), layers.Dense(num_classes, activation='softmax') ])
(c): Dado que se trata de un problema de clasificación binaria, nuestra variable de destino solo tiene dos clases. 0 para las señales de venta y 1 para las señales de compra; cambiemos la función de pérdida a «binary_crossentropy» y la métrica de evaluación a «binary_accuracy».
# Compile with Adam optimizer model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='binary_crossentropy', metrics=['binary_accuracy'] )
Cuando se volvió a entrenar el modelo de la CNN, los valores mejoraron considerablemente.
.... .... 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5257 - loss: 0.6920 - val_binary_accuracy: 0.5043 - val_loss: 0.6933 Epoch 7/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5259 - loss: 0.6918 - val_binary_accuracy: 0.5027 - val_loss: 0.6934 Epoch 8/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5283 - loss: 0.6915 - val_binary_accuracy: 0.5042 - val_loss: 0.6936 Epoch 9/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5284 - loss: 0.6912 - val_binary_accuracy: 0.5028 - val_loss: 0.6937 Epoch 10/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5315 - loss: 0.6909 - val_binary_accuracy: 0.5036 - val_loss: 0.6938 Epoch 11/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5295 - loss: 0.6907 - val_binary_accuracy: 0.5042 - val_loss: 0.6940 Epoch 12/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5298 - loss: 0.6904 - val_binary_accuracy: 0.5074 - val_loss: 0.6941 619/619 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5101 - loss: 0.6926 265/265 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - binary_accuracy: 0.5018 - loss: 0.6933 Train acc: 0.5114434361457825 Test acc: 0.5050135850906372 265/265 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step Classification report precision recall f1-score support 0 0.58 0.50 0.54 4870 1 0.43 0.51 0.47 3607 accuracy 0.51 8477 macro avg 0.51 0.51 0.50 8477 weighted avg 0.52 0.51 0.51 8477
No existía ninguna razón específica para la modificación de los parámetros. Quería demostrar que, al igual que con cualquier otro modelo basado en redes neuronales, la optimización y el ajuste de parámetros son cruciales.
El resultado actual puede que no sea la solución óptima, ya que hay mucho que podemos debatir sobre las CNN y las redes neuronales en general.
Por ahora, continuemos con los parámetros actuales, pero siéntase libre de ajustar estos valores para obtener un modelo que se adapte a sus necesidades.
Ahora que contamos con un modelo base que no presenta tantos sesgos, podemos utilizarlo para transferir sus conocimientos a otros instrumentos y guardar todos estos modelos en formato ONNX, con el fin de observar los resultados que ofrece el aprendizaje por transferencia en un entorno de negociación real.
Aprendizaje por transferencia en un robot de trading (EA)
Para probar el aprendizaje por transferencia en un entorno de trading en MetaTrader 5, primero debemos guardar los modelos en formato ONNX y, a continuación, cargarlos utilizando el lenguaje de programación MQL5.
Importaciones.
import onnxmltools import tf2onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Funciones.
def saveCNN(model, window: int, features: int, filename: str): model.output_names = ["output"] # Specifying the input signature for the model spec = (tf.TensorSpec((None, window, features), tf.float16, name="input"),) # Convert the Keras model to ONNX format onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=14) # Save the ONNX model to a file with open(filename, "wb") as f: f.write(onnx_model.SerializeToString())
Dado que los modelos de Keras no cuentan con una canalización compatible como la que solemos usar para integrar todas las técnicas de preprocesamiento junto con el modelo de Scikit-learn, lo que facilita guardar el modelo y todos sus pasos en un único archivo ONNX, tenemos que guardar un modelo de Keras y un escalador utilizado por separado como archivos ONNX independientes.
def saveScaler(scaler, features: int, filename: str): # Convert to ONNX format initial_type = [("input", FloatTensorType([None, features]))] onnx_model = convert_sklearn(scaler, initial_types=initial_type, target_opset=14) with open(filename, "wb") as f: f.write(onnx_model.SerializeToString())
Ahora podemos llamar a estas funciones al guardar el modelo base y los anteriores.
Guardando el modelo base.
# .... # .... base_model = trainCNN(train_set=(X_train_seq, y_train_encoded), val_set=(X_test_seq, y_test_encoded), learning_rate = 0.01, epochs = 1000, batch_size =32) saveCNN(model=base_model, window=window, features=X_train_seq.shape[2], filename=f"{trained_symbol}.basemodel.{timeframe}.onnx") saveScaler(scaler=scaler, features=X_train.shape[1], filename=f"{trained_symbol}.{timeframe}.scaler.onnx")
Guardar modelos entrenados mediante aprendizaje por transferencia.
for symbol in symbols: # ... # ... history = model.fit(X_train_seq, y_train_encoded, validation_data=(X_test_seq, y_test_encoded), epochs=1000, # More epochs for fine-tuning batch_size=32, callbacks=[early_stop], verbose=1) saveCNN(model=model, window=window, features=X_train_seq.shape[2], filename=f"basesymbol={trained_symbol}.symbol={symbol}.model.{timeframe}.onnx") saveScaler(scaler=scaler, features=X_train.shape[1], filename=f"{symbol}.{timeframe}.scaler.onnx")
Tras guardar los archivos en la carpeta común, podemos cargarlos dentro de un Asesor Experto (EA) utilizando un sistema de nombres similar.
#include <ta.mqh> //similar to ta in Python --> https://www.mql5.com/en/articles/16931 #include <pandas.mqh> //similar to Pandas in Python --> https://www.mql5.com/en/articles/17030 #include <CNN.mqh> //For loading Convolutional Neural networks in ONNX format --> https://www.mql5.com/en/articles/15259 #include <preprocessing.mqh> //For loading the scaler transformer #include <Trade\Trade.mqh> //The trading module #include <Trade\PositionInfo.mqh> //Position handling module CCNNClassifier cnn; RobustScaler scaler; CTrade m_trade; CPositionInfo m_position; input string base_symbol = "EURUSD"; input string symbol_ = "USDJPY"; input ENUM_TIMEFRAMES timeframe = PERIOD_H4; input uint window_ = 10; input uint lookahead = 1; input uint magic_number = 28042025; input uint slippage = 100; long classes_in_y_[] = {0, 1}; int OldNumBars = -1; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!MQLInfoInteger(MQL_TESTER)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe)) { printf("%s Failed to set symbol_ = %s and timeframe = %s, Error = %d",__FUNCTION__,symbol_,EnumToString(timeframe), GetLastError()); return INIT_FAILED; } //--- string filename = StringFormat("basesymbol=%s.symbol=%s.model.%s.onnx",base_symbol, symbol_, EnumToString(timeframe)); if (!cnn.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s failed to load a CNN model in ONNX format from the common folder '%s', Error = %d",__FUNCTION__,filename,GetLastError()); return INIT_FAILED; } //--- filename = StringFormat("%s.%s.scaler.onnx", symbol_, EnumToString(timeframe)); if (!scaler.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s failed to load a scaler in ONNX format from the common folder '%s', Error = %d",__FUNCTION__,filename,GetLastError()); return INIT_FAILED; } }
Dado que en MQL5 disponemos del equivalente al módulo TA (Technical Analysis) de Python, del que hablamos en este artículo. Podemos llamar a las funciones del indicador y asignar el resultado a un marco de datos similar a Pandas en Python.
CDataFrame getStationaryVars(uint start = 1, uint bars = 50) { CDataFrame df; //Dataframe object vector open, high, low, close; open.CopyRates(Symbol(), Period(), COPY_RATES_OPEN, start, bars); high.CopyRates(Symbol(), Period(), COPY_RATES_HIGH, start, bars); low.CopyRates(Symbol(), Period(), COPY_RATES_LOW, start, bars); close.CopyRates(Symbol(), Period(), COPY_RATES_CLOSE, start, bars); vector pct_change = df.pct_change(close); vector diff_open = df.diff(open); vector diff_high = df.diff(high); vector diff_low = df.diff(low); vector diff_close = df.diff(close); df.insert("pct_change", pct_change); df.insert("diff_open", open); df.insert("diff_high", high); df.insert("diff_low", low); df.insert("diff_close", close); // Relative Strength Index (RSI) vector rsi = CMomentumIndicators::RSIIndicator(close); df.insert("rsi", rsi); // Stochastic Oscillator (Stoch) vector stock_k = CMomentumIndicators::StochasticOscillator(close,high,low).stoch; df.insert("stock_k", stock_k); // Moving Average Convergence Divergence (MACD) vector macd = COscillatorIndicators::MACDIndicator(close).main; df.insert("macd", macd); // Commodity Channel Index (CCI) vector cci = COscillatorIndicators::CCIIndicator(high,low,close); df.insert("cci", cci); // Rate of Change (ROC) vector roc = CMomentumIndicators::ROCIndicator(close); df.insert("roc", roc); // Ultimate Oscillator (UO) vector uo = CMomentumIndicators::UltimateOscillator(high,low,close); df.insert("uo", uo); // Williams %R vector williams_r = CMomentumIndicators::WilliamsR(high,low,close); df.insert("williams_r", williams_r); // Average True Range (ATR) vector atr = COscillatorIndicators::ATRIndicator(high,low,close); df.insert("atr", atr); // Awesome Oscillator (AO) vector ao = CMomentumIndicators::AwesomeOscillator(high,low); df.insert("ao", ao); // Average Directional Index (ADX) vector adx = COscillatorIndicators::ADXIndicator(high,low,close).adx; df.insert("adx", adx); // True Strength Index (TSI) vector tsi = CMomentumIndicators::TSIIndicator(close); df.insert("tsi", tsi); if (MQLInfoInteger(MQL_DEBUG)) df.head(); df = df.dropna(); //Drop not-a-number variables return df; //return the last rows = window from a dataframe which is the recent information fromthe market }
En cada barra, recopilamos 50 barras hacia atrás en el tiempo para los cálculos del indicador comenzando en la barra cerrada más recientemente en el índice de 1.
La razón principal para usar 50 barras es dar suficiente espacio para los cálculos de los indicadores, que suelen ir acompañados de valores NaN (Not a Number), los cuales queremos evitar.
El indicador Awesome Oscillator es el que mira más al pasado con un valor de window2 de 34, esto significa que 50-34 = 16 es la cantidad de datos elegibles que quedan para nuestro modelo.
Al ejecutar esta función en modo de depuración, obtendrá una visión general de los datos en la pestaña Expertos de MetaTrader 5.
MD 0 18:17:26.145 Transfer Learning EA (USDJPY,H4) | Index | pct_change | diff_open | diff_high | diff_low | diff_close | rsi | stock_k | macd | cci | roc | uo | williams_r | atr | ao | adx | tsi | FF 0 18:17:26.145 Transfer Learning EA (USDJPY,H4) | 0 | nan | 142.67000000 | 143.08800000 | 142.49100000 | 142.68300000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | JO 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 1 | -0.25300842 | 142.68400000 | 142.84900000 | 142.28700000 | 142.32200000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | IR 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 2 | 0.09977375 | 142.32300000 | 142.63500000 | 141.89900000 | 142.46400000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | HF 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 3 | -0.00070193 | 142.46400000 | 142.71900000 | 142.34400000 | 142.46300000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | GJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 4 | -0.04702976 | 142.37400000 | 142.47200000 | 142.18600000 | 142.39600000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | IJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | ... | NR 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 45 | -0.22551954 | 142.33800000 | 142.38800000 | 141.98200000 | 142.01700000 | 28.79606321 | 1.70731707 | 0.20202343 | -149.46898289 | -0.42629273 | 28.03714657 | -48.58934169 | 0.58185714 | 0.84359706 | 29.65580624 | 8.31951160 | NJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 46 | 0.16054416 | 141.97800000 | 142.31600000 | 141.96400000 | 142.24500000 | 35.49705652 | 13.58800774 | 0.12993025 | -131.96513868 | -0.57316604 | 34.81743660 | -43.09139137 | 0.56978571 | 0.51217941 | 28.18573720 | 4.78996901 | HQ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 47 | 0.19543745 | 142.24500000 | 142.58100000 | 142.12400000 | 142.52300000 | 43.03880625 | 27.03094778 | 0.09414295 | -86.63856716 | -0.76174826 | 43.61239023 | -36.38775018 | 0.57742857 | 0.21773529 | 26.19967843 | 3.09202782 | FH 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 48 | 0.04771160 | 142.52300000 | 142.61500000 | 142.29800000 | 142.59100000 | 44.85843867 | 30.31914894 | 0.07045611 | -66.64608781 | -0.57732936 | 49.55462139 | -34.74801061 | 0.56007143 | -0.01222353 | 24.37916904 | 2.01861384 | MQ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 49 | -0.19776844 | 142.59100000 | 142.75800000 | 142.25100000 | 142.30900000 | 38.91058297 | 16.68278530 | 0.02859940 | -70.14493704 | -0.77257229 | 41.99481159 | -41.54810707 | 0.52700000 | -0.13378529 | 23.02215655 | 0.05188403 |
Dentro de la función OnTick, lo primero que hacemos es obtener estas variables estacionarias, seguido de la operación de segmentación que tiene como objetivo garantizar que los datos o el número de barras recibidas estén dentro de la ventana requerida que utilizamos al entrenar un modelo CNN.
void OnTick() { //--- if (!isNewBar()) return; CDataFrame x_df = getStationaryVars(); //--- Check if the number of rows received after indicator calculation is >= window size if ((uint)x_df.shape()[0]<window_) { printf("%s Fatal, Data received is less than the desired window=%u. Check your indicators or increase the number of bars in the function getSationaryVars()",__FUNCTION__,window_); DebugBreak(); return; } ulong rows = (ulong)x_df.shape()[0]; ulong cols = (ulong)x_df.shape()[1]; //printf("Before scaled shape = (%I64u, %I64u)",rows, cols); matrix x = x_df.iloc((rows-window_), rows-1, 0, cols-1).m_values; }
Ahora que tenemos una matriz segmentada con 10 filas similares al valor de la ventana y 16 características que usamos durante el entrenamiento, podemos pasar estos datos al RobustScaler cargado antes de pasarlos al modelo CNN para las predicciones finales.
matrix x_scaled = scaler.transform(x); //Transform the data, very important long signal = cnn.predict(x_scaled, classes_in_y_).cls; //Predicted class
Finalmente, utilizando la señal obtenida del modelo, podemos crear una estrategia de trading sencilla: cuando la señal recibida del modelo sea igual a 1 (señal alcista), abrimos una operación de compra, y cuando la señal recibida sea igual a 0 (señal bajista), abrimos una operación de venta.
Cada operación se cerrará una vez que haya transcurrido el número de barras similares al valor de anticipación en el marco temporal actual.
//--- Trading functionality MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); if (signal == 1) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask,0,0); } if (signal == 0) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid,0,0); } CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe
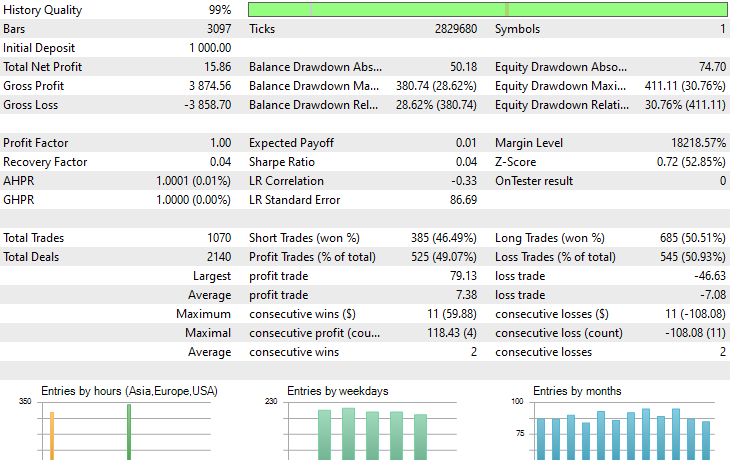
Eso es todo, vamos a ejecutar este robot de negociación en varios instrumentos que utilizamos durante este proceso de aprendizaje por transferencia y a observar su resultado predictivo desde el 1 de enero de 2023 hasta el 1 de enero de 2025.
Marco temporal: PERIOD_H4. Modelado: OHLC de 1 minuto.
Símbolo: XAUEUR
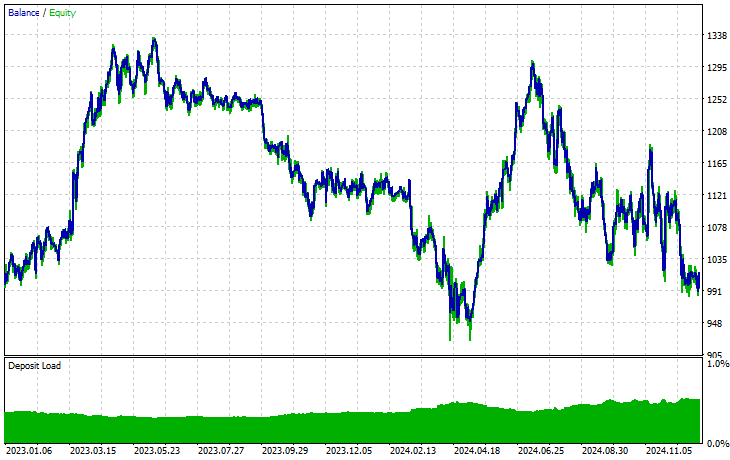
Símbolo: XAUUSD
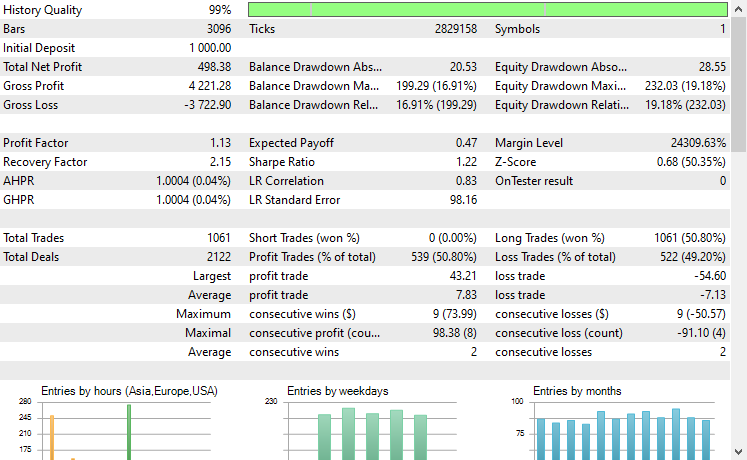
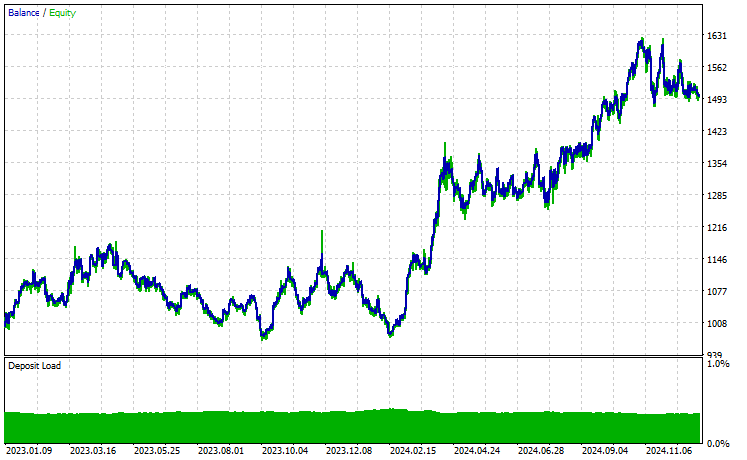
De los 17 instrumentos utilizados en este proceso de aprendizaje por transferencia sobre un modelo base entrenado con EURUSD, solo 2 arrojaron resultados prometedores. El resto ofreció resultados muy pobres.
Esto podría significar dos cosas: una es que los patrones observados en el EURUSD tienen una fuerte relación o similitudes con los que se muestran en el XAUUSD y el XAUEUR. Tiene sentido, ya que ambos instrumentos tienen EUR y USD, que conforman el símbolo base EURUSD.
En segundo lugar, esto también podría significar que tenemos modelos CNN subóptimos, ya que no hemos optimizado nuestros modelos para encontrar la mejor combinación de la arquitectura y los parámetros del modelo, sin mencionar que ni siquiera hemos probado diferentes símbolos base y observado los resultados en otros.
Podríamos haber explorado un par de enfoques más, pero eso queda fuera del alcance de este artículo. Te lo dejo a ti.
Reflexiones finales
Estamos en la edad de oro de la Inteligencia Artificial y el aprendizaje automático. Esta tecnología avanza a un ritmo mayor del previsto, todo gracias al código abierto. Ahora se pueden crear modelos magníficos a partir de los existentes con tan solo unas líneas de código; a esto lo llamamos simplemente aprendizaje por transferencia.
Si bien tenemos estos enormes modelos de código abierto en visión por computadora y tareas relacionadas con imágenes como ResNet50, MobileNet, etc. Aunque esto ha permitido a los desarrolladores situarse a la vanguardia y obtener soluciones de IA significativas, el ámbito financiero aún no se ha explorado en lo que respecta al código abierto.
El objetivo de este artículo era mostrar el potencial del aprendizaje por transferencia y cómo podría aplicarse en este ámbito, como punto de partida para ayudarles a construir modelos complejos que nos permitan comprender los mercados financieros aprovechando los patrones comunes disponibles en diversos instrumentos.
Buena suerte.
Tabla de archivos adjuntos
Nombre del archivo | Descripción/Uso |
|---|---|
| Expert\Transfer Learning EA.mq5 | El principal asesor experto para probar modelos de aprendizaje por transferencia en un entorno de negociación. |
| Include\CNN.mqh | Una biblioteca para cargar y desplegar modelos CNN en archivos .onnx en MQL5. |
Include\pandas.mqh | Biblioteca Pandas similar a Python para la manipulación y el almacenamiento de datos. |
Include\preprocessing.mqh | Contiene clases para técnicas de carga y escalado de transformadores de datos presentes en formato .onnx. |
Include\ta.mqh | Una biblioteca con un enfoque plug-and-play para trabajar con indicadores en MQL5. |
Scripts\CollectData.mqh | Un script para recopilar y guardar en archivos CSV datos OHLC de varios instrumentos. |
| Python\forex-transfer-learning.ipynb | Un script de Python (Jupyter Notebook) para ejecutar todo el código Python descrito en este artículo. |
Common\Files\*scaler.onnx | Escaladores de preprocesamiento de datos guardados en archivos con formato ONNX. |
Common\Files\*.onnx | Modelos CNN guardados en archivos con formato ONNX. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/17886
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso