
Aprendizaje automático y Data Science (Parte 36): Cómo lidiar con mercados financieros sesgados

Contenido
- Introducción
- Deficiencias de la variable objetivo desequilibrada en el aprendizaje automático
- Técnicas para abordar el problema de los conjuntos de datos desequilibrados
- Elegir la métrica de evaluación adecuada
- Un Asesor Experto (EA) para pruebas
- Técnicas de sobremuestreo
- Técnicas de submuestreo
- Métodos híbridos
- Conclusión
Introducción
Los distintos mercados de divisas e instrumentos financieros presentan comportamientos diferentes en distintos momentos. Si bien algunos mercados financieros, como las acciones y los índices, suelen ser alcistas a largo plazo, otros, como los mercados de divisas, suelen mostrar comportamientos bajistas y mucho más. Esta incertidumbre añade complejidad a la hora de intentar predecir el mercado utilizando técnicas de inteligencia artificial (IA) y modelos de aprendizaje automático (ML).

Tomemos un par de mercados financieros (símbolos de negociación) y visualicemos las direcciones del mercado en 1000 barras en el marco temporal diario. Si el precio de cierre de una barra está por encima de su precio de apertura, podemos etiquetarla como una barra alcista (1); de lo contrario, podemos etiquetarla como una barra bajista (0).
import pandas as pd import numpy as np symbols = [ "EURUSD", "USTEC", "XAUUSD", "USDJPY", "BTCUSD", "CA60", "UK100" ] for symbol in symbols: df = pd.read_csv(fr"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\1640F6577B1C4EC659BF41EA9F6C38ED\MQL5\Files\{symbol}.PERIOD_D1.data.csv") df["Candle type"] = (df["Close"] > df["Open"]).astype(int) print(f"{symbol}(unique):",np.unique(df["Candle type"], return_counts=True))
Resultado.
EURUSD(unique): (array([0, 1]), array([496, 504])) USTEC(unique): (array([0, 1]), array([472, 528])) XAUUSD(unique): (array([0, 1]), array([472, 528])) USDJPY(unique): (array([0, 1]), array([408, 592])) BTCUSD(unique): (array([0, 1]), array([478, 522])) CA60(unique): (array([0, 1]), array([470, 530])) UK100(unique): (array([0, 1]), array([463, 537]))
Como se puede observar en el resultado anterior, ninguno de los símbolos de negociación está perfectamente equilibrado, ya que históricamente han aparecido diferentes cantidades de velas alcistas y bajistas.
No hay nada de malo en que el mercado esté sesgado hacia una dirección específica, pero este sesgo en los datos históricos podría causar algunos problemas al entrenar modelos de aprendizaje automático, y aquí te explicamos cómo:
Digamos que queremos entrenar un modelo en USDJPY basado en el conjunto de datos actual que tiene 1000 barras, tenemos 408 velas bajistas (marcadas como 0) que equivalen al 40,8% de todas las señales de trading mientras que tenemos 592 velas alcistas (marcadas como 1) que equivalen al 59,2% de todas las señales de trading.
La presencia de señales alcistas que superan a las señales bajistas suele pasar desapercibida para los modelos de aprendizaje automático, ya que estos tienden a favorecer la clase dominante y, por lo tanto, a realizar predicciones a favor de dicha clase.
Dado que todos los modelos buscan lograr el menor valor de pérdida posible, acompañado del máximo valor de exactitud posible, favorecerán la clase alcista, que se ha producido el 59,2% del 100% de las veces, como una forma sencilla de alcanzar el valor máximo de exactitud.
Esto no es ciencia espacial porque, basándonos solo en esta información simple, si ignoramos todos los predictores y todo lo que está sucediendo en el mercado, usando solo esta información al predecir el USDJPY, podemos decir que todas las barras serán alcistas todo el tiempo, y acertaremos aproximadamente el 59,2% de las veces.No está mal, ¿verdad?¡Equivocado!
Porque al hacerlo estarás asumiendo que lo que sucedió en el pasado está destinado a volver a suceder, algo terriblemente incorrecto y completamente erróneo en este mundo del comercio.
Como puede verse, tener una variable objetivo desequilibrada en los datos de clasificación para el aprendizaje automático plantea un problema; a continuación, se detallan algunas de las deficiencias que esto conlleva.
Deficiencias de las variables objetivo desequilibradas en el aprendizaje automático
- Bajo rendimiento en la clase minoritaria
Como ya he mencionado, el modelo sesga las predicciones hacia la clase mayoritaria porque optimiza la exactitud general. Por ejemplo, en datos de detección de fraudes (con un 99 % de casos no fraudulentos y un 1 % de casos fraudulentos) dado que la mayoría de los casos no son fraudulentos, un modelo podría predecir siempre que no se trata de un fraude y seguir obteniendo una exactitud del 99 %, pero no detectar los casos fraudulentos. - Métricas de evaluación engañosas
El valor de exactitud se vuelve poco fiable; se puede tener un modelo con una exactitud global del 72 % sin saber que una clase se predijo con una precisión del 95 %, mientras que otra solo alcanzó una precisión del 50 %. - Modelos que se sobreajustan a la clase mayoritaria
Los modelos podrían memorizar ruido de la clase mayoritaria y tomar decisiones sesgadas en lugar de aprender patrones generales presentes en los predictores. Por ejemplo, en datos de diagnóstico médico con (95% sanos y 5% enfermos), el modelo puede ignorar por completo los casos enfermos. - Escasa generalización a datos no vistos (del mundo real)
En los datos del mundo real, la distribución cambia con frecuencia y rapidez; si un modelo se entrenó en un entorno sesgado, es probable que falle tarde o temprano, ya que se entrenó sobre un equilibrio poco realista.
Técnicas para abordar el problema de los conjuntos de datos desequilibrados
Ahora que conocemos las deficiencias que conlleva una variable objetivo desequilibrada (sesgada) en un problema de clasificación, analicemos diferentes maneras de abordar este problema.
01: Elección de la métrica de evaluación adecuada
La primera técnica para manejar datos desequilibrados es elegir una métrica de evaluación adecuada, como se dijo en las deficiencias, la exactitud de un clasificador, que es el número total de predicciones correctas dividido por el número total de predicciones, puede ser engañosa en datos desequilibrados.
En un problema de datos desequilibrados, otras métricas, como la precisión, que mide la exactitud de la predicción del clasificador sobre una clase específica, y la exhaustividad, que mide la capacidad del clasificador para identificar una clase, son mucho más útiles que la métrica de exactitud.
Cuando se trabaja con un conjunto de datos desequilibrado, la mayoría de los expertos en aprendizaje automático utilizan la puntuación F1, ya que es la más apropiada.
Es simplemente la media armónica entre la precisión y el recall, representada por la fórmula.

Por lo tanto, si el clasificador predice la clase minoritaria, pero la predicción es errónea y aumenta el número de falsos positivos, la métrica de precisión será baja, al igual que la puntuación F1.
Además, si el clasificador identifica mal la clase minoritaria, aumentarán los falsos negativos, por lo que la exhaustividad y la puntuación F1 serán bajas.
La puntuación F1 solo aumenta si mejora el número y la calidad general de las predicciones.
Para comprender esto en detalle, entrenemos un clasificador RandomForest simple en el instrumento USDJPY sesgado.
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report # Global variables symbol = "USDJPY" timeframe = "PERIOD_D1" lookahead = 1 common_path = r"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\Common\Files" df = pd.read_csv(f"{common_path}\{symbol}.{timeframe}.data.csv") # Target variable df["future_close"] = df["Close"].shift(-lookahead) # future closing price based on lookahead value df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) print("Signals(unique): ",np.unique(df["Signal"], return_counts=True)) X = df.drop(columns=["Signal", "future_close"]) y = df["Signal"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=False) model = RandomForestClassifier(n_estimators=100, max_depth=5, min_samples_split=3, random_state=42) model.fit(X_train, y_train)
Una vez finalizado el entrenamiento, podemos guardar el modelo en formato ONNX para utilizarlo posteriormente en MetaTrader 5.
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType import os def saveModel(model, n_features: int, technique_name: str): initial_type = [("input", FloatTensorType([None, n_features]))] onnx_model = convert_sklearn(model, initial_types=initial_type, target_opset=14) with open(os.path.join(common_path, f"{symbol}.{timeframe}.{technique_name}.onnx"), "wb") as f: f.write(onnx_model.SerializeToString())
saveModel(model=model, n_features=X_train.shape[1], technique_name="no-sampling")
Tuve que utilizar el método del informe de clasificación para analizar diferentes métricas incluidas en Scikit-Learn.
Train Classification report precision recall f1-score support 0 0.98 0.41 0.57 158 1 0.68 1.00 0.81 204 accuracy 0.74 362 macro avg 0.83 0.70 0.69 362 weighted avg 0.81 0.74 0.71 362
Análisis del informe de clasificación del entrenamiento
La exactitud general del entrenamiento del modelo es de 0,74, lo que podría parecer aceptable a primera vista; sin embargo, un análisis más detallado de las métricas por clase revela un desequilibrio significativo en el rendimiento del modelo entre las dos clases, donde la clase 0 tiene una precisión muy alta de 0,98, pero un bajo recall de 0,41, lo que resulta en una modesta puntuación F1 de 0,57.
Esto significa que, si bien el modelo tiene mucha confianza al predecir la clase 0, omite una gran cantidad de muestras reales de la clase 0, lo que indica una baja sensibilidad.
Por otro lado, la Clase 1 muestra un recall de 1,00 y una puntuación F1 de 0,81, pero una precisión relativamente menor de 0,68.
Esto sugiere que el modelo está excesivamente sesgado hacia la predicción de la clase 1, lo que posiblemente conduzca a un elevado número de falsos positivos.
El recall perfecto (1,00) para la clase 1 es una señal de alerta, ya que probablemente indica sobreajuste o un sesgo hacia la clase mayoritaria.
El modelo predice la clase 1 para casi todo y omite muchas muestras reales de la clase 0, lo cual es evidente por el bajo valor de recall de la clase 0, que es de 0,41.
En general, estas métricas no solo muestran un desequilibrio, sino que también plantean dudas sobre la capacidad de generalización del modelo y su equidad entre las distintas clases. Aquí hay algo que claramente no está bien.
Utilicemos técnicas de sobremuestreo para mejorar nuestro modelo y encontrar un equilibrio predictivo.
Un Asesor Experto (EA) para pruebas
Siempre existe una diferencia entre los resultados del análisis de un modelo de aprendizaje automático, como el informe de clasificación anterior, y el resultado real de las operaciones en MetaTrader 5. Dado que guardaremos el modelo en formato ONNX para su uso posterior, podemos crear un robot de trading sencillo que tome un modelo entrenado con cada técnica de remuestreo analizada en este artículo y lo utilice para tomar decisiones de trading en el probador de estrategias con la muestra de entrenamiento.
Los datos utilizados se recopilaron en el archivo llamado Collectdata.mq5, un script que recopila los datos de entrenamiento desde el 01/01/2025 hasta el 01/01/2023. Lo puedes encontrar en los archivos adjuntos de este artículo.
Dentro del Asesor Experto (EA) llamado Test Resampling Techniques.mq5, inicializamos el modelo en formato ONNX y luego lo usamos para hacer predicciones.
#include <Random Forest.mqh> CRandomForestClassifier random_forest; //A class for loading the RFC in ONNX format #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> CTrade m_trade; CPositionInfo m_position; input string symbol_ = "USDJPY"; input int magic_number= 14042025; input int slippage = 100; input ENUM_TIMEFRAMES timeframe_ = PERIOD_D1; input string technique_name = "randomoversampling"; int lookahead = 1; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!random_forest.Init(StringFormat("%s.%s.%s.onnx", symbol_, EnumToString(timeframe_), technique_name), ONNX_COMMON_FOLDER)) //Initializing the RFC in ONNX format from a commmon folder return INIT_FAILED; //--- Setting up the CTrade module m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(symbol_); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- vector x = { iOpen(symbol_, timeframe_, 1), iHigh(symbol_, timeframe_, 1), iLow(symbol_, timeframe_, 1), iClose(symbol_, timeframe_, 1) }; long signal = random_forest.predict_bin(x); //Predicted class double proba = random_forest.predict_proba(x).Max(); //Maximum predicted probability MqlTick ticks; if (!SymbolInfoTick(symbol_, ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(symbol_, SYMBOL_VOLUME_MIN); if (signal == 1) { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, symbol_, ticks.ask,0,0); } if (signal == 0) { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, symbol_, ticks.bid,0,0); } //--- CloseTradeAfterTime((Timeframe2Minutes(timeframe_)*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool PosExists(ENUM_POSITION_TYPE type) { for (int i=PositionsTotal()-1; i>=0; i--) if (m_position.SelectByIndex(i)) if (m_position.Symbol()==symbol_ && m_position.Magic() == magic_number && m_position.PositionType()==type) return (true); return (false); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool ClosePos(ENUM_POSITION_TYPE type) { for (int i=PositionsTotal()-1; i>=0; i--) if (m_position.SelectByIndex(i)) if (m_position.Symbol() == symbol_ && m_position.Magic() == magic_number && m_position.PositionType()==type) { if (m_trade.PositionClose(m_position.Ticket())) return true; } return (false); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CloseTradeAfterTime(int period_seconds) { for (int i = PositionsTotal() - 1; i >= 0; i--) if (m_position.SelectByIndex(i)) if (m_position.Magic() == magic_number) if (TimeCurrent() - m_position.Time() >= period_seconds) m_trade.PositionClose(m_position.Ticket(), slippage); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int Timeframe2Minutes(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return 1; case PERIOD_M2: return 2; case PERIOD_M3: return 3; case PERIOD_M4: return 4; case PERIOD_M5: return 5; case PERIOD_M6: return 6; case PERIOD_M10: return 10; case PERIOD_M12: return 12; case PERIOD_M15: return 15; case PERIOD_M20: return 20; case PERIOD_M30: return 30; case PERIOD_H1: return 60; case PERIOD_H2: return 120; case PERIOD_H3: return 180; case PERIOD_H4: return 240; case PERIOD_H6: return 360; case PERIOD_H8: return 480; case PERIOD_H12: return 720; case PERIOD_D1: return 1440; // 1 day = 1440 minutes case PERIOD_W1: return 10080; // 1 week = 7 * 1440 minutes case PERIOD_MN1: return 43200; // Approx. 1 month = 30 * 1440 minutes default: PrintFormat("Unknown timeframe: %d", tf); return 0; } }
Dado que entrenamos el modelo con la variable objetivo basándonos en un valor de anticipación de 1, debemos cerrar la operación después de que haya transcurrido el número de barras de anticipación en el marco temporal actual. Al hacerlo, nos aseguramos de que se respete el valor de anticipación, ya que mantenemos y cerramos nuestras operaciones de acuerdo con el horizonte predictivo del modelo.
Antes de analizar los resultados de las operaciones con los modelos entrenados con los datos remuestreados, observemos los resultados de las operaciones con un modelo entrenado con los datos de entrenamiento sin remuestrear.
Configuraciones del probador.
Entradas: technique_name = no-sampling.
Resultados de la prueba.
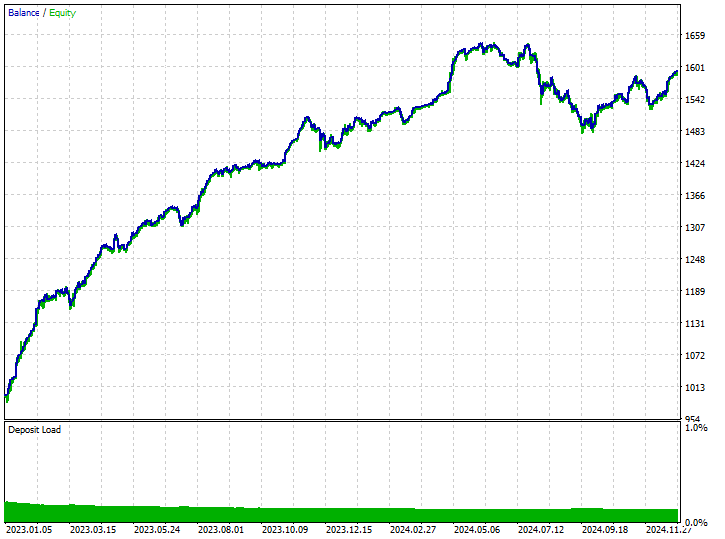
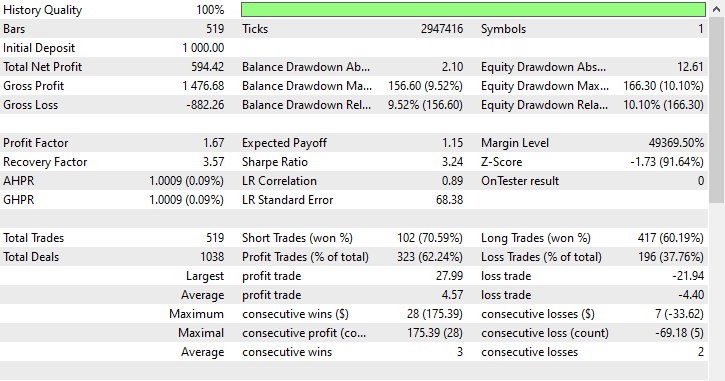
A pesar de que el modelo fue capaz de captar algunas buenas señales y obtener resultados comerciales impresionantes, con operaciones rentables que representaron el 62,24% del total de operaciones realizadas. Si observas las operaciones cortas y largas ganadas, puedes ver que hay una proporción de 1:4 para las operaciones cortas y largas.
De las 519 operaciones realizadas, 102 fueron operaciones cortas, lo que resultó en una tasa de acierto del 70,59%, mientras que 417 de las 519 operaciones realizadas fueron operaciones largas, lo que resultó en una tasa de acierto del 60,19%. Claramente, algo no cuadra aquí, porque si analizamos la dirección de la vela desde el 1 de enero de 2023 hasta el 1 de enero de 2025 basándonos en el valor de anticipación de 1.
print("classes in y: ",np.unique(y, return_counts=True))
Resultado.
classes in y: (array([0, 1]), array([225, 293]))
Podemos ver que 225 fueron movimientos de precios bajistas, mientras que 293 fueron movimientos alcistas. Dado que la mayoría de las velas se movieron en dirección alcista en el USDJPY en este período de 2 años (del 1 de enero de 2023 al 1 de enero de 2025), cualquier modelo trivial que favorezca el movimiento alcista podría obtener ganancias. No es tan difícil.
Ahora podemos entender que la única razón por la que el modelo generó alguna ganancia fue porque favorecía las operaciones de compra cuatro veces más que las de venta.
Dado que el mercado se mostró mayoritariamente alcista durante ese período, pudo generar algunas ganancias.
Procedamos con las técnicas de remuestreo y veamos cómo podemos abordar este sesgo en la toma de decisiones en nuestros modelos.
Técnicas de sobremuestreo
sobremuestreo aleatorio
Esta es una técnica que se utiliza para abordar el desequilibrio de clases en los conjuntos de datos mediante la duplicación de muestras existentes de la clase minoritaria.
Consiste en seleccionar aleatoriamente ejemplos existentes de la clase minoritaria y duplicarlos para aumentar su representación en los datos de entrenamiento, con el objetivo de equilibrar la distribución de clases en conjuntos de datos desequilibrados.
La herramienta más utilizada para esta tarea es imbalanced-learn. A continuación se muestra una forma sencilla de usarlo.
from imblearn.over_sampling import RandomOverSampler print("b4 Target: ",np.unique(y_train, return_counts=True)) rus = RandomOverSampler(random_state=42) X_resampled, y_resampled = rus.fit_resample(X_train, y_train) print("After Target: ",np.unique(y_resampled, return_counts=True))
Resultados.
b4 Target: (array([0, 1]), array([304, 395])) After Target: (array([0, 1]), array([395, 395]))
Podemos ajustar los datos remuestreados al mismo RandomForestClassifier que utilizamos anteriormente y observar la diferencia en los resultados en comparación con los obtenidos sin remuestrear los datos.
model.fit(X_resampled, y_resampled)
Evaluación del modelo.
y_train_pred = model.predict(X_train) print("Train Classification report\n",classification_report(y_train, y_train_pred))
Resultado.
Train Classification report precision recall f1-score support 0 0.82 0.85 0.83 158 1 0.88 0.86 0.87 204 accuracy 0.85 362 macro avg 0.85 0.85 0.85 362 weighted avg 0.85 0.85 0.85 362
Sorprendentemente, estos resultados indican una mejora significativa en todos los indicadores. Las puntuaciones F1 de 0,87 para ambas clases sugieren que el modelo realiza predicciones imparciales y consistentes, lo que apunta a un modelo con una buena generalización y un aprendizaje bien distribuido entre las clases objetivo.
A pesar de su simplicidad y eficacia, el sobremuestreo puede aumentar el riesgo de sobreajuste al crear instancias duplicadas de la clase minoritaria, lo que puede no aportar información nueva al modelo.
Utilizando las mismas configuraciones de prueba, podemos probar el modelo entrenado con estos datos en el probador de estrategias.
Entradas: technique_name = randomoversampling.
Resultados de la prueba.
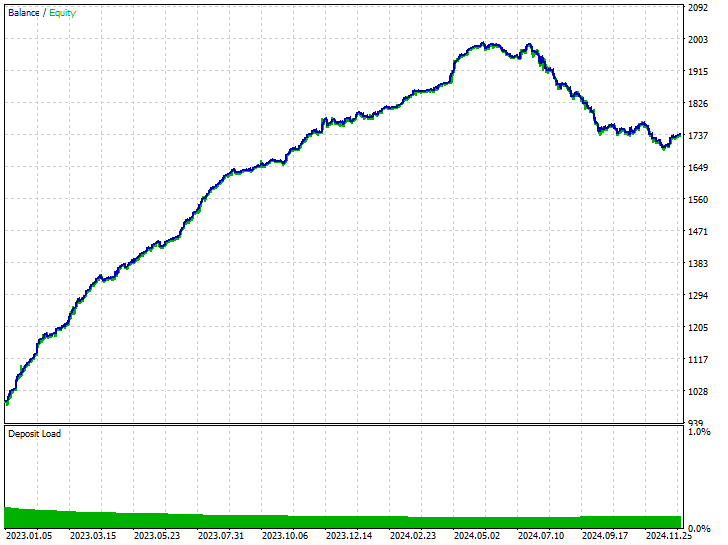
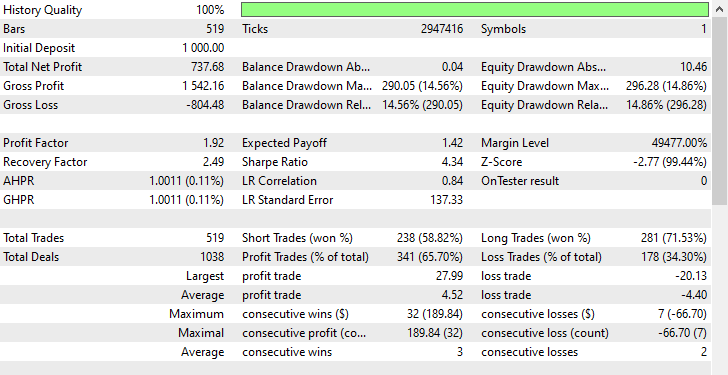
Como pueden ver, hemos logrado mejoras en todos los aspectos de la negociación; este modelo es más robusto que el entrenado con datos sin remuestrear. Ahora el robot abre más posiciones cortas, lo que ha conllevado una reducción significativa de las posiciones largas.
Nuevamente, durante este período de entrenamiento, el mercado mostró 225 y 293 movimientos bajistas y alcistas respectivamente, según cómo definimos la variable objetivo. Este nuevo modelo, entrenado con datos sobremuestreados, parece abrir 238 y 281 operaciones cortas y largas respectivamente. Esto es una buena señal de que el modelo no está sesgado, ya que toma decisiones basándose en los patrones aprendidos más que en cualquier otra cosa.
Técnicas de submuestreo
Existen varias técnicas de submuestreo que podemos utilizar y que están disponibles en distintos módulos de Python. Algunos son:
Submuestreo aleatorio
Esta es una técnica que se utiliza para abordar el desequilibrio de clases en los conjuntos de datos, reduciendo el número de muestras de la clase mayoritaria para equilibrarlo con la clase minoritaria.
Consiste en eliminar muestras de la clase mayoritaria de forma aleatoria o estratégica.
De forma similar a como aplicamos el sobremuestreo, podemos submuestrear la clase principal de la siguiente manera.
from imblearn.under_sampling import RandomUnderSampler print("b4 Target: ",np.unique(y_train, return_counts=True)) rus = RandomUnderSampler(random_state=42) X_resampled, y_resampled = rus.fit_resample(X_train, y_train) print("After Target: ",np.unique(y_resampled, return_counts=True))
Resultado.
b4 Target: (array([0, 1]), array([304, 395])) After Target: (array([0, 1]), array([304, 304]))
El submuestreo aleatorio y otros tipos de submuestreo pueden degradar el rendimiento del modelo al eliminar muestras informativas de la clase mayoritaria, lo que da como resultado un conjunto de entrenamiento menos representativo. Esto podría provocar un ajuste insuficiente del modelo.
Esta técnica mejoró el rendimiento del modelo en los datos de entrenamiento para ambas clases.
Train Classification report precision recall f1-score support 0 0.76 0.90 0.82 158 1 0.91 0.78 0.84 204 accuracy 0.83 362 macro avg 0.83 0.84 0.83 362 weighted avg 0.84 0.83 0.83 362
Utilizando las mismas configuraciones de prueba, podemos probar el modelo entrenado con estos datos en el probador de estrategias.
Entradas: technique_name = randomundersampling.
Resultados de la prueba.
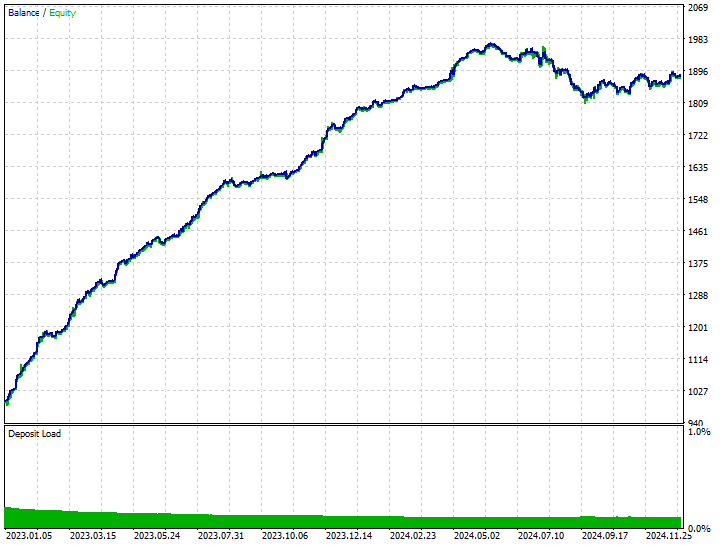
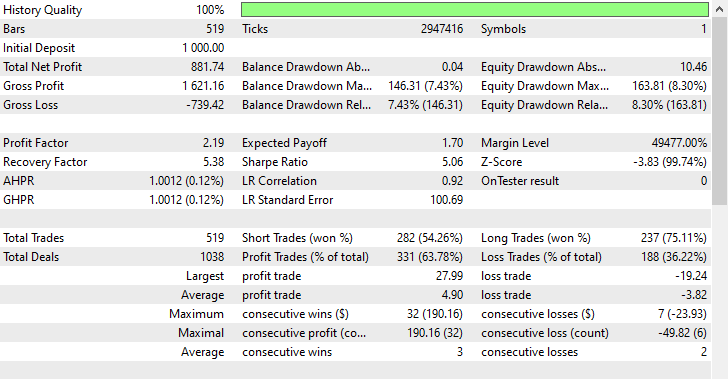
Esta técnica produjo 282 y 237 operaciones cortas y largas respectivamente, a pesar de que este modelo favorecía las operaciones cortas sobre las largas, algo que no se reflejó en el mercado, aun así logró obtener mayores beneficios que el modelo sesgado entrenado con datos sin remuestrear y el modelo sobremuestreado que favorecía los movimientos alcistas.
Estos resultados del modelo nos indican que podemos obtener beneficios del mercado en ambas direcciones, independientemente de lo que haya ocurrido históricamente.
Enlaces de Tomek
Los enlaces de Tomek hacen referencia a un par de instancias de clases diferentes que están muy cerca una de la otra, a menudo consideradas como vecinos más próximos. Aquí se ofrece una explicación sencilla de cómo funciona la técnica de enlaces de Tomek para el submuestreo de datos de aprendizaje automático.
Imaginemos que tenemos dos puntos A y B de clases diferentes, A pertenece a la clase mayoritaria mientras que B pertenece a la clase minoritaria (o viceversa).
Si estos dos puntos (A y B) están cerca uno del otro (son vecinos), entonces se eliminará una observación de la clase mayoritaria (A en este caso).
Esta técnica ayuda a limpiar los límites de decisión y a diferenciar mejor las clases, al tiempo que elimina algunas muestras de la clase mayoritaria.
from imblearn.under_sampling import TomekLinks tl = TomekLinks() X_resampled, y_resampled = tl.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Resultados.
Before --> y (unique): (array([0, 1]), array([304, 395])) After --> y (unique): (array([0, 1]), array([304, 283]))
Esta técnica puede generar resultados predictivos equilibrados e impresionantes a partir del modelo, pero se limita a la clasificación binaria, es menos eficaz con datos muy superpuestos y, al igual que otras técnicas de muestreo, puede provocar la pérdida de datos.
Esta técnica también tuvo un mejor rendimiento con los datos de entrenamiento.
Train Classification report precision recall f1-score support 0 0.69 0.94 0.80 158 1 0.93 0.68 0.78 204 accuracy 0.79 362 macro avg 0.81 0.81 0.79 362 weighted avg 0.83 0.79 0.79 362
Utilizando la misma configuración del probador, podemos probar el modelo entrenado con estos datos en el probador de estrategias.
Entradas: technique_name = tomek-links.
Resultados de la prueba.

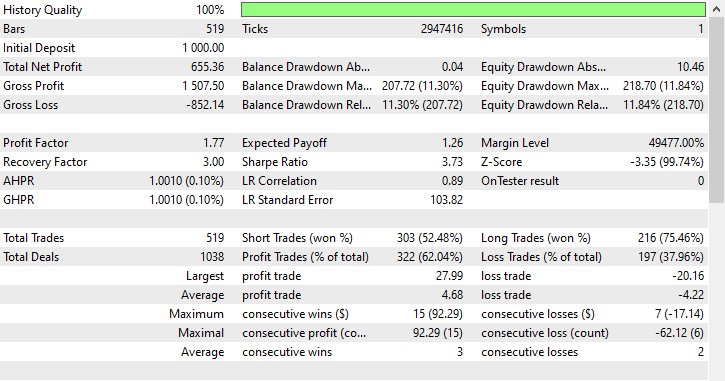
De forma similar a la técnica de submuestreo aleatorio, Tomek Links favoreció las operaciones en corto, ya que abrió 303 operaciones en corto mientras que se abrieron 216 operaciones en largo, y aun así logró obtener ganancias.
Centroides de clúster
Se trata de una técnica de submuestreo en la que la clase mayoritaria se reduce sustituyendo sus muestras por los centroides de los clústeres (normalmente obtenidos mediante el algoritmo de agrupamiento K-means).
Funciona de la siguiente manera.
- El algoritmo de agrupamiento K-means se aplica a la clase mayoritaria.
- Se elige el número K de muestras deseadas.
- La mayoría de las muestras de la clase se reemplazan con k centros de clúster.
- Este resultado se combina con la clase minoritaria para crear un conjunto de datos equilibrado.
from imblearn.under_sampling import ClusterCentroids cc = ClusterCentroids(random_state=42) X_resampled, y_resampled = cc.fit_resample(X, y) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Resultados.
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([225, 225]))
A continuación se muestra el resultado del modelo en los datos de entrenamiento submuestreados utilizando los centroides de los clústeres.
Train Classification report precision recall f1-score support 0 0.64 0.86 0.73 158 1 0.85 0.62 0.72 204 accuracy 0.73 362 macro avg 0.75 0.74 0.73 362 weighted avg 0.76 0.73 0.73 362
Hasta ahora, esta técnica es la que presenta el menor valor de precisión; un valor de 0,73 podría indicar que el modelo está menos sobreajustado que los anteriores, por lo que podría ser el mejor modelo posible hasta el momento. Observemos su exactitud en un entorno de negociación.
Entradas: technique_name = cluster-centroids.
Resultados de la prueba.
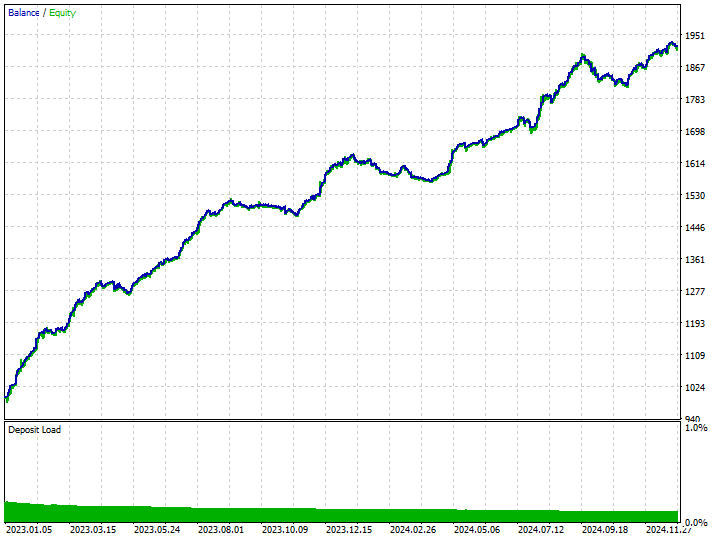
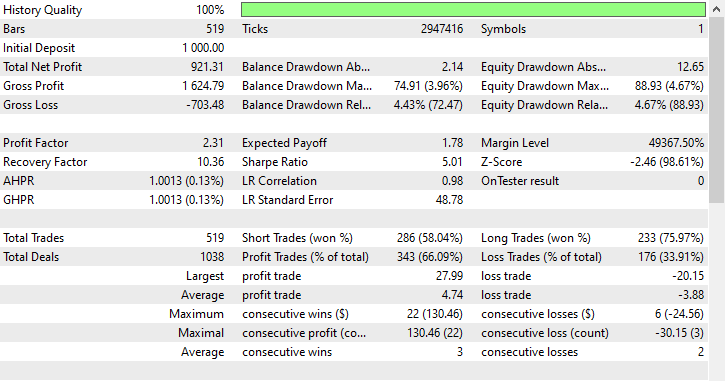
Esta técnica proporcionó el mayor número de operaciones rentables, 343 operaciones de 519, lo que representa una exactitud del 66,09%, ya que sus ganancias casi alcanzaron el depósito inicial. A pesar de que el modelo favorecía las operaciones en corto, fue muy preciso al predecir las señales alcistas, lo que resultó en un impresionante 75,97% de las posiciones largas ganadoras.
Métodos híbridos
Enlaces de SMOTE + Tomek
Primero aplica SMOTE y, a continuación, elimina el ruido con los enlaces Tomek.
from imblearn.combine import SMOTETomek smt = SMOTETomek(random_state=42) X_resampled, y_resampled = smt.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Resultados.
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([159, 159]))
A continuación se muestra el resultado del modelo entrenado con datos de entrenamiento remuestreados mediante esta técnica.
Train Classification report precision recall f1-score support 0 0.74 0.73 0.73 158 1 0.79 0.80 0.80 204 accuracy 0.77 362 macro avg 0.77 0.77 0.77 362 weighted avg 0.77 0.77 0.77 362
A continuación se muestran los resultados de las operaciones.
Entradas: technique_name = smote-tomeklinks.
Resultados de la prueba.
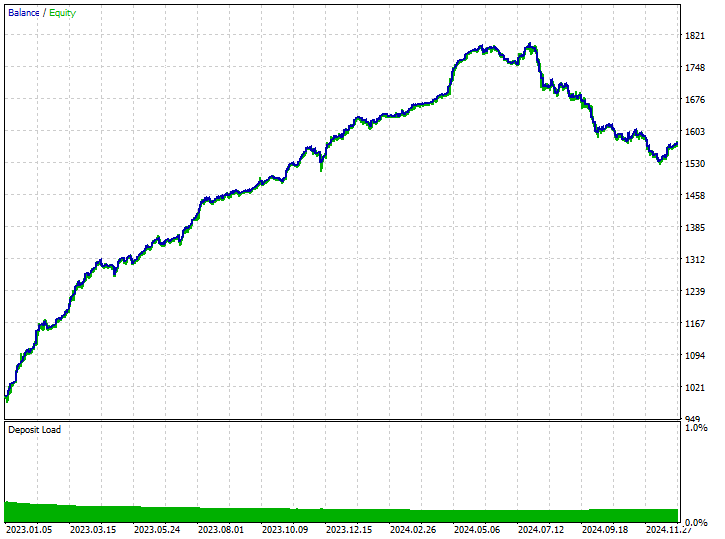
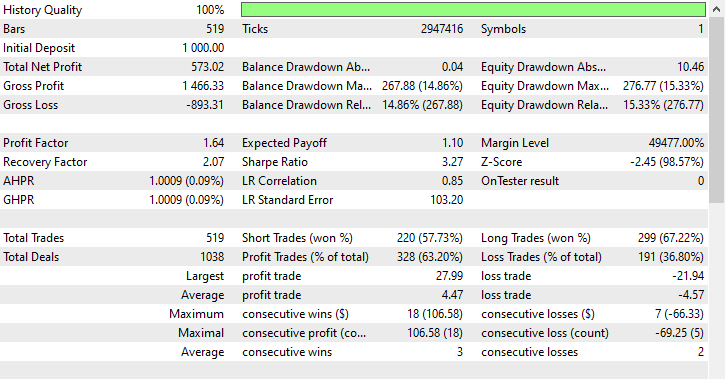
220 y 299 operaciones de compra y venta respectivamente, nada mal.
SMOTE + ENN (Vecinos más cercanos editados)
SMOTE genera muestras sintéticas y, a continuación, ENN elimina las muestras mal clasificadas.
from imblearn.combine import SMOTEENN sme = SMOTEENN(random_state=42) X_resampled, y_resampled = sme.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Esta técnica eliminó una gran cantidad de datos; los datos de entrenamiento se redujeron a un total de 61 muestras.
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([37, 24]))
A continuación se muestra el informe de clasificación de una muestra de entrenamiento.
Train Classification report precision recall f1-score support 0 0.46 0.76 0.58 158 1 0.63 0.32 0.42 204 accuracy 0.51 362 macro avg 0.55 0.54 0.50 362 weighted avg 0.56 0.51 0.49 362
El modelo resultante es deficiente, como era de esperar, ya que fue entrenado con un total de 61 muestras, datos insuficientes para que cualquier modelo aprenda patrones significativos. Analicemos los resultados de las operaciones.
Entradas: technique_name = smote-enn.
Resultados de la prueba.
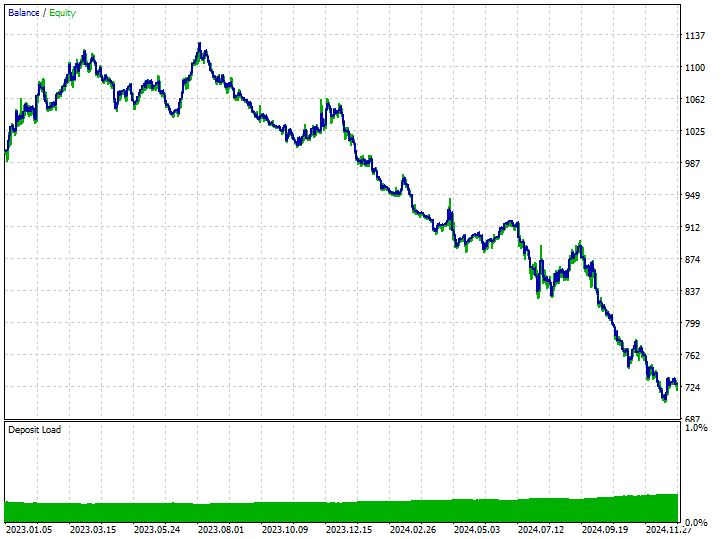
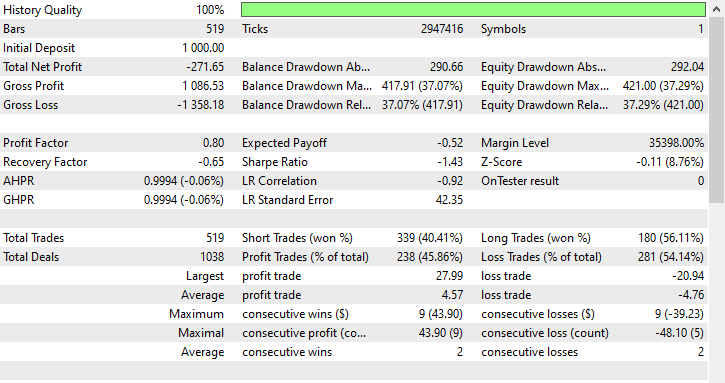
Esta técnica no ayudó en absoluto, incluso empeoró las cosas. Esto generó resultados comerciales sesgados, ya que el robot abrió 180 de 519 operaciones de compra y 339 operaciones de venta.
Esto no significa que la técnica sea mala; simplemente no es la óptima en esta situación.
Conclusión
Vivimos en un mundo imperfecto; no todos los fenómenos que ocurren tienen explicaciones adecuadas o un camino claro. Esto es cierto en el mundo del trading, donde los mercados cambian rápida y frecuentemente, lo que provoca que la mayoría de nuestras estrategias queden obsoletas al instante.
Si bien no podemos controlar lo que sucede en el mercado, lo mejor que podemos hacer es asegurarnos de contar con sistemas y estrategias de negociación sólidos, diseñados para funcionar en condiciones extremas.
Dado que la historia no siempre se repite, es importante asegurarnos de contar con sistemas de negociación imparciales diseñados para funcionar en cualquier mercado, reconociendo los patrones que surgieron previamente, pero sin depender demasiado de ellos para tomar decisiones de negociación. Por muy útiles que puedan ser estas técnicas, hay que tener en cuenta sus inconvenientes y las ventajas e inconvenientes que conlleva el uso de técnicas de remuestreo para los datos de aprendizaje automático. Entre estos inconvenientes se incluyen el riesgo de sobreajuste por sobremuestreo, la posible pérdida de información valiosa por submuestreo y la introducción de ruido o sesgo si el remuestreo no se realiza con cuidado.
Lograr el equilibrio adecuado es clave para construir modelos sólidos que se generalicen bien a condiciones de mercado desconocidas.
Saludos cordiales.
Tabla de archivos adjuntos
| Nombre del archivo | Descripción/Uso |
|---|---|
| Experts\Test Resampling Techniques.mq5 | Un Asesor Experto (EA) para implementar archivos .ONNX en MQL5. |
| Include\pandas.mqh | Biblioteca Pandas similar a Python para la manipulación y el almacenamiento de datos. |
| Scripts\Collectdata.mq5 | Un script para recopilar los datos de entrenamiento. |
| Common\*.onnx | Modelos de aprendizaje automático en formato ONNX. |
| Common\*.csv | Datos de entrenamiento de diferentes instrumentos de aprendizaje automático. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/17736
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Los componentes necesarios son la última versión de todo lo importado dentro del cuaderno, puedes hacer pip install sin preocuparte de los conflictos de versiones. Alternativamente, usted puede seguir el enlace en la tabla de archivos adjuntos, que te lleva a Kaggle.com donde se puede editar y modificar el código.
Identificador no declarado, podría significar que una variable o un objeto no está definido. Inspeccione su código o DM me envíe una captura de pantalla del código.