
Simulación de mercado (Parte 21): Iniciando SQL (IV)

Introducción
Hola a todos y sean bienvenidos a un artículo más de la serie sobre cómo construir un sistema de repetición/simulación.
En el artículo anterior, Simulación de mercado (Parte 20): Iniciando SQL (III), expliqué un poco sobre el comando SELECT. Pero, para que realmente podamos usar SQL de una forma un poco más adecuada, o mejor dicho, para que podamos aprovechar aquello que hace que usar SQL sea una alternativa mejor que tener que programar una aplicación que haría el mismo trabajo, es decir, mantener y permitirnos manipular bases de datos, necesitamos ver otro concepto. Este otro concepto es lo que marca toda la diferencia cuando el tema es bases de datos. Estoy hablando de las claves, que pueden ser primarias o foráneas.
Pero, aunque MetaEditor nos permite hacer las cosas usando SQLite, si tú estás empezando y deseas aprender de forma más consistente a trabajar con SQL, será necesario usar una herramienta un poco más elaborada. Detalle: no estoy diciendo que MetaEditor no sea funcional. Pero, para entender algunas cosas, MetaEditor no se ajusta, y esto se debe a que su propósito es otro, es decir, editar y compilar códigos escritos en MQL5. El hecho de que nos brinde alguna ayuda para usar SQLite no es suficiente para lo que realmente necesitamos, cuando el tema es aprendizaje.
Entonces, para este caso específico, me tomaré la libertad de sugerir otra herramienta. Esto se debe a que está orientada, de hecho, a trabajar con SQLite. Aunque, usando MySQL o cualquier otra plataforma para trabajar con SQL, en la práctica tendríamos el mismo tipo de resultado. Esto porque, en los artículos anteriores, creo haber dejado bastante claro que no importa el sistema que vayas a usar para acceder a SQL. Todos podrán hacer lo mismo, siempre y cuando, claro, utilices solo y exclusivamente la sintaxis de SQL, sin hacer uso de algo presente únicamente en esa variación específica de SQL.
La herramienta que propongo es DB Browser. Es de código abierto, está escrita en C++ y puede descargarse gratuitamente desde GitHub. Al final de este artículo, dejaré la referencia de dónde puedes acceder al instalador de la herramienta. Una de las ventajas de DB Browser es que facilitará mucho la comprensión de varias cosas, ya que existen traducciones a otros idiomas, lo que, para muchos que no dominan el inglés, ayudará bastante.
Otro detalle es que, a diferencia de MetaEditor, donde no puedes editar, guardar y usar un script de SQL, en DB Browser podrás hacerlo. Este tipo de cosa ayuda bastante al inicio del aprendizaje. Pero quien ya tiene conocimientos en SQL y lo usa solo para consultar una base de datos, usar una u otra herramienta no hará diferencia. Entonces, queda a tu criterio qué herramienta utilizar.
En la imagen de abajo, muestro la interfaz de DB Browser. Claro que, en esta imagen, removí algunas opciones, ya que no son necesarias para lo que exploraremos.
Pero, antes de que empecemos a ver el tema de las claves primarias y las claves foráneas, quiero explicar algo sobre lo cual tal vez tengas alguna duda, sobre todo si buscas profundizar en el tema de SQL.
¿Por qué el cambio de estrategia?
Tal vez te sientas un poco incómodo e incluso frustrado si intentas usar SQL en cualquier implementación. Hay algunos administradores que, cuando van a contratar a un analista de bases de datos, muchas veces exigen que sepa trabajar con una implementación determinada. Por ejemplo: puedes estudiar SQL Server y no conseguir un puesto de trabajo porque, en el lugar, se usa MySQL. O puedes ver a alguien diciendo que Oracle es mejor que otras implementaciones de SQL. En los artículos anteriores, intenté mostrar que las personas que piensan así, en realidad, no saben nada sobre bases de datos. Solo imaginan que algo es mejor o peor. No tienen la debida noción de cómo realmente funciona la cosa en los pormenores y se quedan ahí queriendo juzgar algo que, de hecho, no entienden.
Si vas a usar una base de datos o una implementación que haga uso de un servidor, tendrás una forma de acceder a la base de datos. La forma más común de hacer esto es mediante sockets. Antes de hablar sobre SQL, expliqué, en algunos artículos, cómo haces para trabajar con sockets. Si bien allí la idea era, además de explicar el funcionamiento de los sockets, también mostrar cómo hacer para que Excel se comunicara con MetaTrader 5, de forma bidireccional. Es decir, tanto Excel como MetaTrader 5 podrían enviar datos el uno al otro. No te quedarías limitado a usar un RTD o DDE para transferir datos, porque, en ese caso, solo Excel recibiría los datos. Pero, sabiendo usar sockets, podemos hacer mucho más.
Ese mismo conocimiento que se mostró allí puede usarse para que MQL5, o un ejecutable corriendo en MetaTrader 5, pueda trabajar con SQL a fin de acceder a una base de datos. Todo lo que necesitarás saber es cómo trabajar con los comandos de SQL y también cómo enviar y recibir información vía socket. El resto es historia, ya que las bases de datos basadas en servidores son mucho más prácticas cuando el tema es el flujo de información. Para dejarlo más claro, es lo siguiente: una base de datos alojada en un servidor SQL será mucho más extensible que una base de datos alojada en un archivo.
Pero, cuando usamos SQLite, la premisa es alojar la base de datos en un archivo. No es que quedes limitado a eso. Sí es posible usar un servidor SQLite. Pero, normalmente, usamos archivos cuando se emplea SQLite. Esto nos trae algunas limitaciones y molestias. Algunas de estas limitaciones son aceptables, ya que, muchas veces, la base de datos será usada solo por una aplicación específica. En otros casos, estas limitaciones nos obligarán a cambiar de estrategia y nos forzarán a usar un servidor de SQL.
Pero, como el propósito aquí es ser didáctico y, sobre todo, mostrarte que no necesitamos programar ciertas cosas y debemos usar herramientas ya existentes cuando esto sea posible, tales limitaciones que aparecen cuando la base de datos está contenida en un archivo no serán, de hecho, un problema. Pero ten esto en mente: un servidor de SQL siempre será superior, en varios puntos, a una implementación que utiliza un archivo para mantener la base de datos.
Explicado este punto, a partir de este momento dejaremos MySQL un poco de lado. Aunque me gusta bastante, necesitamos enfocarnos primero en lo que realmente es necesario. Tal vez, en el futuro, en otro artículo, llegue a explicar cómo puedes usar sockets para programar una base de datos. Pero, por ahora, veamos otra cosa y, para que el tema no se mezcle con este, vayamos a un nuevo tema.
¿Por qué existen claves primarias y claves foráneas?
Para explicar esto, que es algo bastante complicado de entender, al menos para quien no entiende de bases de datos, primero es necesario explicar otra cosa, que también es bastante complicada de entender para quien no conoce nada de programación. Es decir, un asunto está ligado al otro. Pero veamos si consigo explicarte, querido lector, que muy probablemente no sabes o no tienes los conceptos correctos sobre bases de datos, por qué existen claves primarias y foráneas. Sin embargo, si no sabes nada sobre programación, te aconsejo estudiar al menos lo básico de algún lenguaje de programación, para entender algunos de los conceptos que usaré en esta explicación.
El motivo de que existan claves primarias y foráneas, y observa que siempre las estoy poniendo juntas, es el mismo que separa las bases de datos relacionales de las bases de datos no relacionales. Uy, ahora esto complica las cosas, ya que mucha gente piensa que solo existe un único tipo de base de datos. Es decir, gran parte, cuando oye hablar de base de datos, de inmediato piensa que existe una relación entre clave y valor. Pero no es exactamente así. El problema es el mal uso de algunos conceptos. El concepto clave - valor no está, de ninguna manera, diciendo que una base de datos sea o no del tipo relacional. En realidad, el concepto clave - valor se extiende un poco más allá de lo que rige algunas ideas. Para poder entender esto, olvidemos, por unos instantes, el tema de las bases de datos y pensemos cómo eran las cosas antes de que surgiera el término base de datos.
La forma más simple de aplicar el concepto clave - valor es usando un array. Si tú sabes lo que es un array, sabes que cada índice, o posición del array, puede contener un valor o registro. Muy bien. Entonces, usando un índice, que sería el equivalente a una clave, podrás obtener el registro de esa posición, que sería el equivalente al valor. Sabiendo esto, puedes modificar, borrar o hacer cualquier cosa con esos datos. Esto es lo más básico de todo.
Si colocas este mismo array, que está en memoria, dentro de un archivo, podrás crear un formato para poder recrear fácilmente el array original, esto cuando vuelvas a leer el archivo a la memoria. Y, nuevamente, esto es lo más básico de todo. En este punto, podrías pensar lo siguiente: bueno, yo, como programador, puedo crear toda una serie de rutinas y procedimientos para modificar, buscar, organizar, borrar, entre otras cosas, cualquier registro en el array. Observa que, en este punto, tú mismo, sin darte cuenta, acabas de crear una base de datos. Esto se debe a que estás usando exactamente las mismas cosas que haría una base de datos.
Entonces, para acceder a cualquier registro o valor dentro de lo que ahora es una base de datos, cargarías el archivo en el array en memoria, harías los procedimientos necesarios y, justo después, guardarías el array de vuelta en el archivo. Este tipo de cosa es algo que se practica y se explica mucho cuando comenzamos a aprender programación. Sin embargo, hasta donde sé, nadie trata este tipo de cosa como si fuera una base de datos. ¿El motivo? Bueno, quién sabe. Pero la verdad es que tú, incluso sin darte cuenta, habrás creado una base de datos personal y particular.
Pero este tipo de solución, muchas veces, no es escalable. Es decir, no logras transferir fácilmente información entre aplicaciones diferentes. Y es en este punto donde el concepto de base de datos empieza a tener sentido, ya que tú puedes, usando algo que otros también usarán, en este caso SQL, escribir una base de datos que puede ser usada por diversas aplicaciones. Por eso, desde el inicio, dije que, aunque se puedan hacer las cosas, a veces es mejor usar lo que ya existe.
Sin embargo, toda esta explicación todavía no respondió a la pregunta que abre el tema. Pero calma, mi querido lector, ya llegaremos allí. Pero como ahora ya tienes una idea bien básica de lo que sería una base de datos, podemos pasar al siguiente punto. Es decir, ¿cuál es la diferencia entre una base de datos relacional y una no relacional, y por qué existe esa diferencia? Bueno, aunque esta sea una pregunta simple, la respuesta no es tan simple. Algunas personas, por tener más o menos experiencia, enseguida dirán: una base de datos relacional usa SQL, mientras que una que no es relacional no usa SQL. Yo hasta quisiera que la respuesta fuera así de simple. Pero no lo es. La diferencia entre una base relacional y una no relacional está en la forma en que el conjunto clave - valor se coloca en la base de datos.
Virgen María, si antes ya estaba complicado, ahora sí que se fastidió del todo. ¿Pero cómo es eso? ¿Cómo puede estar la diferencia en la forma en que el conjunto clave - valor se coloca en la base? A primera vista, no tiene ningún sentido. De hecho, al primer momento, no tiene ningún sentido, pero, conforme vayas experimentando y trabajando con bases de datos, en algún momento te darás cuenta de esto. Pero, para que puedas al menos comprender lo que estoy diciendo, aunque esto te parezca una locura, voy a intentar explicar este punto, a pesar de que es algo realmente complicado de explicar.
Una de las principales características de una base de datos relacional es su integridad, o mejor dicho, es la capacidad de la base de mantenerse íntegra, incluso cuando intentamos hacer que pierda esa característica. Tú puedes pensar que toda base de datos es íntegra. Pero hay casos en los que esta integridad no es la prioridad. Y, cuando esto ocurre, tenemos algo que no es deseable cuando la base de datos necesita ser íntegra. Tenemos la duplicación de conjuntos clave - valor. Pero espera un momento. Esta duplicación no debería, de hecho, ocurrir, porque cada índice, que sería una clave, estaría ligado a un registro, que sería un valor. De hecho, tienes razón si pensaste así. Sin embargo, si pensaste eso, es porque todavía estás pensando en el tema del array. Ahora, la cosa se puso un poco más complicada. En el caso del array, cada posición representa un valor. Entonces, no hay forma de que tengas una posición que represente dos valores diferentes. Esto, de hecho, es correcto.
¿Pero y si, en lugar del índice, o posición, se usara otra cosa, como, por ejemplo, un valor o una string que representaría ahora el índice o la clave, en este caso? Ahora la cosa empieza a tener un aspecto bastante familiar. Para entender esto, pensemos en algo que ha sido bastante común en los días actuales: programar en Python. ¿Y por qué voy a usar Python en la explicación? El motivo es que, en Python, tenemos un concepto que encaja perfectamente con lo que necesito para explicar esto de base relacional y no relacional. Además, Python también puede usar arrays. Entonces, la explicación quedará mucho más coherente.
En Python, existe algo llamado diccionario. Un diccionario sería, a grandes rasgos, un tipo de array donde cada índice tendría un campo que sería la clave y otro campo que sería el valor. Es decir, ya no es el índice en el array el que indicaría cuál es el valor al que la clave estaría ligada. Puedes colocar la clave en cualquier índice y, aun así, al buscar por la clave, encontrarías el valor correspondiente. Esta analogía es perfecta, ya que ahora podemos tener claves iguales que representan valores diferentes, así como también podemos tener valores iguales representados por claves diferentes. En este punto, la base de datos que sería creada por el diccionario en Python sería una base de datos no relacional. Así de simple. Al igual que esto se hizo en Python, podrías usar SQL para hacer lo mismo. Es decir, crearías una columna que contendría los valores que serían usados como claves.
En otra columna, pondrías una correspondencia de cada clave a un valor de registro. Sin las debidas medidas de protección, la base de datos, incluso escrita en SQL, se convertiría en una base de datos no relacional. ¿Vieron que, aunque parezca algo simple, entender un poco sobre diversas cosas diferentes puede ayudarnos a comprender mejor algunos conceptos? Pero todo lo que se vio hasta este punto es solo para explicar cómo podemos ver una base de datos. Y cómo podrías sentirte tentado a programar una serie de rutinas y procedimientos, solo para hacer lo que SQL puede hacer. ¿O crees que no podrías crear un diccionario de Python usando, para eso, SQL?
En este punto, surge un detalle que tal vez sea interesante mencionar, antes de explicar las bases de datos relacionales. Mucha gente, principalmente entusiastas con poca práctica en programación, se ha imaginado mil y una formas de crear un sistema de inteligencia artificial usando, para eso, Python. Muy bien, no estoy aquí para criticar ni para decir que estas personas estén equivocadas. Sin embargo, piensa solo en lo siguiente: tales sistemas de inteligencia artificial hacen, en su esencia, uso de una base de datos. Sea no relacional, como la que acabamos de ver, o relacional, que veremos dentro de poco. Mi pregunta es: ¿por qué se crean esas bases de datos en Python, si podrías hacer lo mismo usando SQL?
Entonces, a pesar de toda la euforia en torno a esos GPTs, haciendo que mucha gente pase a estudiar Python, intentando crear algo parecido, o que, como mínimo, atienda alguna necesidad específica, lo mismo podría hacerse usando SQL. El gran detalle es: ¿cuánto esfuerzo necesitarías poner para hacer algo en uno u otro lenguaje? Cuando, en el pasado, hice una serie de artículos hablando sobre cómo crear un Asesor Experto que operara de forma automática, algunos me cuestionaron por qué había hecho eso. Pero, personalmente, no veo, de hecho, ninguna gran dificultad en hacer algo de ese nivel, porque eso es algo súper simple de construir.
En cambio, un Asesor Experto que usara una base de datos, mantenida y escrita en SQL, para aprender a operar en el mercado, eso sí es algo que merece respeto. Pues, aunque sea algo igualmente simple de construir, es algo que involucra bastante conocimiento y dedicación, sobre todo para lograr que el Asesor Experto pueda aprender y crear la base de datos de la forma correcta. Muy probablemente, ya debe existir algo así: un robot que, usando MetaTrader 5 junto con SQL, opere igual que un ser humano, con toda una subjetividad en la toma de decisiones, si debe o no operar, si debe comprar o vender, si una señal es mejor que otra. En fin, este tipo de cosa puede nacer si estudias las cosas correctas.
Muy bien, ahora podemos ver qué sería una base de datos relacional. Pues, si tú tienes algún conocimiento en programación, debes haber entendido cómo puede surgir una base de datos no relacional. Sin embargo, sin entender esta primera, no lograrás entender la del tipo relacional. Nuevamente, el hecho de usar o no SQL no hace la menor diferencia. Lo que marca la diferencia es cómo se está creando la base.
Para entender el tipo relacional, necesitamos retroceder un poco en el tiempo. En realidad, necesitamos volver a un artículo anterior, donde expliqué cómo haces para modificar y eliminar un registro de la base de datos. Bastará con que leas los artículos anteriores para encontrar el punto del que estoy hablando. Allí mostré, de forma bastante clara, que necesitas algo para encontrar un determinado registro. Sin usar ese algo, que es una clave, no encontrarías la posición correcta. Pero, ¿qué hace que esta clave usada en una base de datos relacional sea diferente de la misma clave usada en una base no relacional? Una de las diferencias es el hecho de que, en la base no relacional, esa misma clave no será única. Pero no solo esto. Pero, por ahora, piensa solo en este punto.
Esa clave no se repetirá cuando usamos una base de datos relacional. Para eso, normalmente, la definimos como una clave primaria. Pero el hecho de que sea primaria no se debe a que no se repetirá. Tú puedes decirle a SQL que, en una columna, los valores no podrán repetirse. Y, aun así, eso no convierte esos datos, o registros pertenecientes a esa columna específica, en un conjunto de claves primarias.
Lo que hace que una columna tenga, o sea, de claves primarias es el hecho de que existan las claves foráneas. Esto sí es lo que determina y garantiza que una base de datos sea o no del tipo relacional. Esto porque, ahora, tendremos una relación entre una clave presente en una tabla y otra clave presente en otra tabla. Este tipo de cosa se usa mucho para generar un tipo de base de datos donde tú podrás, o deseas, que todos los registros sean únicos. Pero, principalmente, que, de alguna forma, todos tengan algún tipo de relación entre sí, creando algo que sería como un esquema de grafo muy similar al que se muestra en la imagen de abajo.
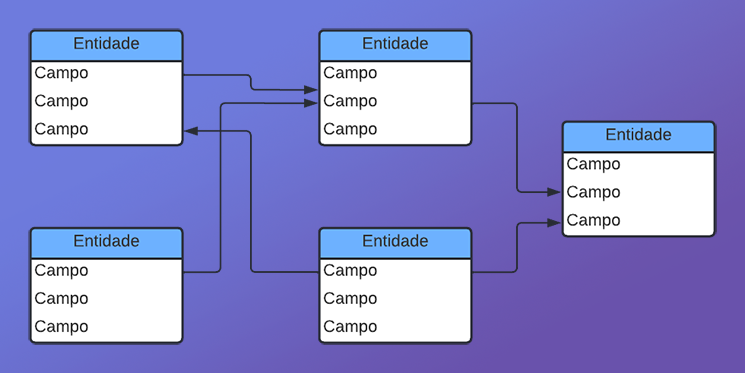
Tal vez, solo observando esta imagen, esto de clave primaria y clave foránea no parezca tener mucho sentido. Pero piensa, por un momento, si crearas una base de datos sobre tu vida particular. Esta base no necesitaría clave primaria ni foránea. Sin embargo, si tú, en esa misma base de datos, empezaras a agregar tus contactos personales, ya sean de redes sociales o personas cercanas, cada uno de estos contactos tendría una clave que sería primaria. Pero existirán puntos en los que habrá cosas en común entre todos estos registros. Si tú, al intentar mantener esta misma base de datos, duplicaras estos puntos en común, al momento de hacer alguna consulta cruzada, el proceso sería mucho más lento y trabajoso.
Sin embargo, si esos mismos puntos en común se colocaran en una tabla específica, podrías, usando otra clave, que en este caso es una clave foránea, cruzar la información con mucha más facilidad, agilizando, así, tanto la consulta como cualquier cambio que, eventualmente, necesite hacerse en la base de datos. Y así es como surge una base de datos relacional. Es decir, una información encontrada en un lugar se enlazará a otra información colocada en otro lugar.
Consideraciones finales
Sé que el contenido de este artículo puede sonar muy abstracto y ser difícil de entender y comprender. Sin embargo, quiero resaltar el hecho de que las bases de datos, tal como se definen y se usan en la actualidad, no surgieron de un momento a otro. Se construyeron e implementaron poco a poco, a lo largo de los años. Muchos de ustedes, queridos lectores, pueden tener un nivel de experiencia muy superior al mío en lo que respecta a trabajar con bases de datos y, así, por esta razón, tener una visión diferente de la mía.
Pero, como era necesario definir y desarrollar alguna forma de explicar el motivo por el cual las bases de datos se crean como se crean, explicar por qué SQL tiene el formato que tiene y, sobre todo, por qué surgieron las claves primarias y las claves foráneas, fue necesario dejar las cosas un poco abstractas. Nuevamente, el tema, al abordarse solo mediante una explicación, puede parecer muy abstracto y sin una justificación válida.
Pero, como tengo interés en mostrar lo básico sobre el tema, para que tú, querido lector, puedas llegar a hacer ciertos tipos de cosas, sin necesidad de profundizar demasiado en SQL, necesitamos entender este concepto, que es el de las claves primarias y las claves foráneas, y cómo, de hecho, funcionan. Esto porque entender, de manera adecuada, tal concepto hará una gran diferencia al momento de crear una base de datos, aunque sea solo para consulta y aprendizaje.
Si vamos a empezar a usar algo, debemos hacerlo de la manera correcta. Aprender las cosas de forma que en realidad no las entendamos no nos ayuda a desarrollarnos como profesionales. Pues, como dejé claro, o intenté dejar, a lo largo de este artículo, no es el hecho de que tú estés o no usando SQL lo que hará que un archivo o un grupo de archivos sea, de hecho, una base de datos relacional. Tú puedes simplemente crear tu conjunto de procedimientos, instrucciones y rutinas para crear una base de datos, no solo para manipular una ya existente, sino para literalmente crear una. Y, si no comprendes algunos de los conceptos involucrados, terminarás creando un sistema que, con el tiempo, se volverá insostenible.
Sé esto porque, durante mucho tiempo, ignoré el uso de SQL o de implementaciones ya existentes. Yo siempre insistía en crear mis propias soluciones y, aunque funcionaran, después de un tiempo, era necesario hacer algo que ya existía en SQL. Y todo ese trabajo y tiempo podrían haberse aprovechado mejor si simplemente hubiera empezado a usar una solución ya existente.
Entonces, en el próximo artículo veremos, de una forma más práctica, cómo estas claves se usan, de hecho, en una base de datos. Tal vez así un concepto que, en este momento, es abstracto se vuelva más plausible y mejor entendido.
| Archivo | Descripción |
|---|---|
| Experts\Expert Advisor.mq5 | Demuestra la interacción entre Chart Trade y el Asesor Experto (es necesario el Mouse Study para la interacción) |
| Indicators\Chart Trade.mq5 | Crea la ventana para configurar la orden que se enviará (es necesario el Mouse Study para la interacción) |
| Indicators\Market Replay.mq5 | Crea los controles para la interacción con el servicio de reproducción/simulador (es necesario el Mouse Study para la interacción) |
| Indicators\Mouse Study.mq5 | Permite la interacción entre los controles gráficos y el usuario (necesario tanto para operar el sistema de repetición como en el mercado real) |
| Services\Market Replay.mq5 | Crea y mantiene el servicio de reproducción y simulación de mercado (archivo principal de todo el sistema) |
| Code VS C++\Servidor.cpp | Crea y mantiene un socket servidor desarrollado en C++ (versión Mini Chat) |
| Code in Python\Server.py | Crea y mantiene un socket en Python para la comunicación entre MetaTrader 5 y Excel |
| Indicators\Mini Chat.mq5 | Permite implementar un minichat mediante un indicador (requiere el uso de un servidor para funcionar) |
| Experts\Mini Chat.mq5 | Permite implementar un minichat mediante un Asesor Experto (requiere el uso de un servidor para funcionar) |
| Scripts\SQLite.mq5 | Demuestra el uso de un script SQL mediante MQL5 |
| Files\Script 01.sql | Demuestra la creación de una tabla simple, con clave foránea |
| Files\Script 02.sql | Demuestra la adición de valores en una tabla |
Referencia
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/12985
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.


- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso