
深層強化学習を用いたIlanエキスパートアドバイザーの強化

はじめに
アルゴリズム取引の世界では、一部の戦略は金融市場という絶えず変化する天空の中で永遠の星のように輝き、取引の歴史に消えない足跡を残します。その代表格がIlanです。Ilanは、2010年代に、シンプルながらも潜在的に有効な低ボラティリティ環境におけるグリッド型ナンピン(平均化)戦略として、トレーダーの注目と口座を魅了した伝説的なエキスパートアドバイザー(EA)でした。
しかし、時代は止まりません。量子コンピューティング、ニューラルネットワーク、機械学習の時代において、昔の戦略は根本的な再考を迫られます。もし、古典的なIlanグリッド平均化の仕組みを、先進的な人工知能アルゴリズムと組み合わせたらどうなるでしょうか。もし、ハードコーディングされたルールの代わりに、システム自身が学習し続け、常に改善できるとしたら?
本記事では、取引モデルに関する従来の考え方に挑戦し、古典的Ilanを深層強化学習(Q学習)と動的Qテーブルで蘇らせるという野心的な試みをおこないます。単なる既存コードの改修ではなく、自己学習し、市場変化に適応し、リアルタイムで取引戦略を最適化できる知的モデルの構築を目指します。
私たちの旅は、数学的厳密性と計算上の洗練性が交錯するアルゴリズム取引の迷宮を通り抜け、古典的なマーチンゲール手法が革新的な機械学習アプローチによって新たな命を吹き込まれる過程を描きます。経験豊富なアルゴリズムトレーダー、取引アーキテクチャの開発者、あるいはフィンテック愛好家にとっても、本記事は自動取引の未来に対するユニークな視点を提供します。
シートベルトを締めてください。伝統と革新が融合し、過去が未来へ進化するIlan 3.0 AIの創造という刺激的な旅が、ここで始まります。
古典的Ilanを内部から理解する
人工知能の世界に踏み込む前に、なぜIlanが2010年代にこれほど人気のあるEAだったのかを理解する必要があります。その動作の核心は、ポジションの平均化の考え方にあります。価格が保有ポジションに逆行した場合、EAは損失を決済するのではなく、新しい注文を追加して平均取得価格を改善しました。
以下は、このロジックを簡略化して示したコードスニペットです。
// Simplified averaging logic in the original Ilan if(positionCount == 0) { // Opening first position on signal if(OpenSignal()) { OpenPosition(ORDER_TYPE_BUY, StartLot); } } else { // Calculating level for averaging double averagePrice = CalculateAveragePrice(); double gridLevel = averagePrice - GridSize * Point(); // If price has reached grid level, add position if(Bid <= gridLevel) { double newLot = StartLot * MathPow(LotMultiplier, positionCount); OpenPosition(ORDER_TYPE_BUY, newLot); } // Checking for closing of all TP positions if(Bid >= averagePrice + TakeProfit * Point()) { CloseAllPositions(); } }
マーチンゲールの魔法:なぜトレーダーはIlanに夢中になったのか
Ilanの人気は、いくつかの要因で説明できます。まず第一に、その動作は初心者のトレーダーにも直感的に理解できるものでした。レンジ相場では、システムはほぼ魔法のような結果を示しました。価格のわずかな変動でさえ利益の源に変わったのです。ポジションの平均化により、最初は含み損だった取引を「救う」ことができ、トレーダーにはこのアーキテクチャが無敵であるかのような感覚を与えました。
もう1つの魅力は、最小限のパラメータで戦略をカスタマイズできる機能です。
// Key parameters of Ilan Expert Advisor input double StartLot = 0.01; // Initial lot size input double LotMultiplier = 1.5; // Lot multiplier for each new position input int GridSize = 30; // Grid size in points input int TakeProfit = 40; // Profit for closing all positions input int MaxPositions = 10; // Maximum number of positions to open
この設定のシンプルさが、「コントロール」の錯覚を生み出しました。トレーダーはパラメータの組み合わせを試行することで、履歴データに基づき印象的な成果を得ることができたのです。
進化の試み:Ilan 2.0で何が変わったのか
Ilan 2.0では、開発者は一部の問題を解決しようと試みました。市場ボラティリティに基づくグリッド間隔の動的計算、複数通貨ペアでの運用および相関分析、ポジション開始用の追加フィルタや過剰損失を防ぐ保護メカニズムなどが導入されました。
// Dynamic calculation of grid step in Ilan 2.0 double CalculateGridStep(string symbol) { double atr = iATR(symbol, PERIOD_CURRENT, ATR_Period, 0); return atr * ATR_Multiplier; } // Protective mechanism to limit losses bool EquityProtection() { double currentEquity = AccountInfoDouble(ACCOUNT_EQUITY); double maxAllowedDrawdown = AccountInfoDouble(ACCOUNT_BALANCE) * MaxDrawdownPercent / 100.0; if(AccountInfoDouble(ACCOUNT_BALANCE) - currentEquity > maxAllowedDrawdown) { CloseAllPositions(); return true; } return false; }
これらの改善により、システムはより堅牢になりましたが、根本的な課題である適応性の欠如は解決されませんでした。Ilan 2.0は依然として静的なルールに基づいており、自身の経験から学習したり、市場の変化に適応したりすることはできなかったのです。
なぜトレーダーはIlanを使い続けたのか
明らかな欠点があるにもかかわらず、多くのトレーダーはIlanやその改良版を使い続けました。その背景には、いくつかの心理的要因があります。損失を出した人は通常口を閉ざし、成功例だけが積極的に公表されました。トレーダーは成功した期間に注目し、警告サインを無視してしまいます。パラメータの微調整で全ての問題が解決できるように見えたのです。さらに、マーチンゲール戦略はギャンブルと同じ心理的トリガーを刺激しました。
公平を期すために言うと、特定の市場条件、特に低ボラティリティかつレンジ相場の期間においては、EAは実際に長期間にわたって印象的な成果を示すことがありました。しかし問題は、市場条件が必然的に変化することであり、EAがこれらの変化に適応できなかったことにあります。
なぜIlanが必然的に破綻し、証拠金を失ったのか
Ilanの本当の問題は、長期的に見ると明らかになります。レンジ相場では完璧に機能していた戦略も、長期トレンドの動きには致命的に脆弱であることが分かります。典型的な破綻シナリオを考えてみましょう。
まず、最初の買いポジションが建てられます。その後、市場が安定した下落トレンドを開始すると、EAはポジションを追加し、ロットサイズを指数的に増加させます。数段階の平均化を経ると、ポジションサイズは非常に大きくなり、わずかな価格変動でもマージンコールに至ります。
数学的には、この問題は次のように表現できます。マーチンゲール戦略で倍率が1.5、初期ロットが0.01の場合、10回目の連続ポジションは約0.57ロットとなり、初期ロットの57倍になります。すべての保有ポジションの合計は約1.1ロットとなり、$1,000口座でレバレッジ1:100の場合、利用可能証拠金のほぼ全てを消費することになります。
// Calculation of total size of martingale positions double totalVolume = 0; double currentLot = StartLot; for(int i = 0; i < MaxPositions; i++) { totalVolume += currentLot; currentLot *= LotMultiplier; } // At StartLot = 0.01 and LotMultiplier = 1.5 after 10 positions // totalVolume will be about 1.1 lots!
この戦略の根本的な問題は、平均化戦略をいつ中止すべきかを判断するメカニズムが欠如していたことです。Ilanは、いつ止めるべきか分からず、勝ち戻しを期待してさらに賭け続けるギャンブラーのようなものでした。
なぜIlanにAIが必要なのか
Ilanの強みと弱みを分析すると、最大の問題は学習や適応ができないことであることが明らかになります。EAは、過去の結果が成功であれ失敗であれ、同じルールに従い続けます。
ここで人工知能の出番です。もし、Ilanの基本的な仕組みを維持しつつ、自分の行動結果を分析し、戦略を調整する機能を加えたらどうなるでしょうか。もし、ハードコーディングされたルールの代わりに、蓄積された経験に基づいてモデル自身が最適なパラメータやエントリーポイントを見つけられるとしたら?
この発想こそが、Ilan 3.0 AIプロジェクトの核心です。ここでは、長年実績のある平均化戦略と先進的な機械学習手法を統合します。次のセクションでは、Q学習技術がどのようにこのコンセプトを実現するのかを解説します。
Q学習はIlan EAをどのように改善するか
従来のIlanモデルから、学習可能なインテリジェントシステムへの移行には、EAのアーキテクチャを根本的に変更する必要があります。ここで、Q学習アルゴリズムがIlan 3.0 AIの核心となります。強化学習の分野で最も重要な技術のひとつです。
Q学習の基本:行動価値に基づく学習
Q学習は、「Q値関数(Quality関数)」に由来します。これは特定の状態における行動の価値を決定する関数です。私たちの実装では、Qテーブルというデータ構造を用いて、各「状態-行動ペア」のスコアを格納します。
// Structure for Q-table struct QEntry { string state; // Discretized state of market int action; // Action (0-nothing, 1-buy, 2-sell) double value; // Q-value }; // Global array for Q-table QEntry QTable[]; int QTableSize = 0;Q学習の重要な特徴は、システムが自身の経験から学習できることです。各行動の後に、アルゴリズムは報酬(利益)またはペナルティ(損失)を受け取り、特定の市場状況におけるその行動の価値評価を調整します。
// Updating Q-value using Bellman formula void UpdateQValue(string stateStr, int action, double reward, string nextStateStr, bool done) { double currentQ = GetQValue(stateStr, action); double nextMaxQ = 0; if(!done) { // Find maximum Q for following state nextMaxQ = GetMaxQValue(nextStateStr); } // Updating Q-value double newQ = currentQ + LearningRate * (reward + DiscountFactor * nextMaxQ - currentQ); // Saving updated value SetQValue(stateStr, action, newQ); }
この式はベルマン方程式として知られ、私たちのアプローチの基盤です。LearningRateは学習速度を決定し、DiscountFactorは将来の報酬が現在の報酬に対してどれだけ重要かを示します。
新しい解の探索と経験の活用のバランス
強化学習における重要な課題のひとつは、新しい戦略を探索することと、既に分かっている最適解を活用することのバランスです。この問題を解決するために、ε-greedy戦略を使用します。
// Choosing action with balance between exploration and exploiting int SelectAction(string stateStr) { // With epsilon probability choose random action (research) if(MathRand() / (double)32767 < currentEpsilon) { return MathRand() % ActionCount; } // Otherwise, choose action with maximum Q-value (exploiting) int bestAction = 0; double maxQ = GetQValue(stateStr, 0); for(int a = 1; a < ActionCount; a++) { double q = GetQValue(stateStr, a); if(q > maxQ) { maxQ = q; bestAction = a; } } return bestAction; }currentEpsilonパラメータはランダムに行動を選ぶ確率を決定します。時間が経つにつれて、この値は減少し、システムは積み上げた知識の活用を優先するようになります。
// Reducing epsilon for a gradual transition from exploration to exploiting if(currentEpsilon > MinExplorationRate) currentEpsilon *= ExplorationDecay;
デジタルな感覚器官:アルゴリズムが市場をどのように「認識」するか
アルゴリズムを効果的に学習させるには、市場を「見る」必要があります。つまり、現在の状況を形式化した状態ベクトルとして認識することです。Ilan 3.0 AIでは、テクニカル指標、保有ポジションの情報、その他の市場データを含む包括的な状態ベクトルを使用します。
// Getting current market state for Q-learning void GetCurrentState(string symbol, double &state[]) { ArrayResize(state, StateDimension); // Technical indicators double rsi = iRSI(symbol, PERIOD_CURRENT, RSI_Period, PRICE_CLOSE, 0); double cci = iCCI(symbol, PERIOD_CURRENT, CCI_Period, PRICE_TYPICAL, 0); double macd = iMACD(symbol, PERIOD_CURRENT, 12, 26, 9, PRICE_CLOSE, MODE_MAIN, 0); // Normalization of indicators double normalized_rsi = rsi / 100.0; double normalized_cci = (cci + 500) / 1000.0; // Metrics of positions int positions = (symbol == "EURUSD") ? euroUsdPositions : audUsdPositions; double normalized_positions = (double)positions / MaxTrades; // Calculating price difference double point = SymbolInfoDouble(symbol, SYMBOL_POINT); double currentBid = SymbolInfoDouble(symbol, SYMBOL_BID); double avgPrice = CalculateAveragePrice(symbol); double price_diff = (currentBid - avgPrice) / (100 * point); // Filling in state vector state[0] = normalized_rsi; state[1] = normalized_cci; state[2] = normalized_positions; state[3] = price_diff; state[4] = macd / (100 * point); state[5] = AccountInfoDouble(ACCOUNT_EQUITY) / AccountInfoDouble(ACCOUNT_BALANCE); }Qテーブルを扱うためには、連続的な状態値を離散化する必要があります。つまり、有限個の選択肢を持つ文字列表現に変換します。
// Converting state to string for Q-table string StateToString(double &state[]) { string stateStr = ""; for(int i = 0; i < ArraySize(state); i++) { // Rounding to 2 decimal places for discretization double discretized = MathRound(state[i] * 100) / 100.0; stateStr += DoubleToString(discretized, 2); if(i < ArraySize(state) - 1) stateStr += ","; } return stateStr; }
この離散化プロセスにより、システムは蓄積された経験を、完全に同一ではないが類似した市場状況にも応用できるようになります。
インセンティブシステム:AIの世界における「飴と鞭」報酬の定義は、効果的な強化学習システムを構築する上でおそらく最も重要な要素です。Ilan 3.0 AIでは、アルゴリズムの学習を正しい方向に導く多層的なインセンティブシステムを開発しています。
報酬の経済学:アルゴリズムをどのように動機づけるか
利益の出たポジションを決済する際、モデルは利益額に比例した正の報酬を受け取ります。
// Reward at closing profitable positions if(shouldClose) { if(ClosePositions(symbol, magic)) { if(isTraining) { double reward = profit; // Reward is equal to profit UpdateQValue(stateStr, action, reward, stateStr, true); // Learning statistics episodeCount++; totalReward += reward; Print(“Episode ", episodeCount, " completed with reward: ", reward, ". Average reward: ", totalReward / episodeCount); } } }損失の出たポジションを平均化する場合、システムには小さなペナルティが与えられます。これは、最適なエントリーポイントを探し、平均化が必要な状況を避けるよう促すためです。
// Penalty at averaging positions if(OpenPosition(symbol, ORDER_TYPE_BUY, CalculateLot(positionsCount, symbol), StopLoss, TakeProfit, magic)) { if(isTraining) { double reward = -1; // Small penalty for averaging UpdateQValue(stateStr, action, reward, stateStr, false); } }
最初のポジションを建てた時に即時報酬がないことにより、システムは短期的な行動ではなく、長期的な成果に集中するようになります。
モデルのファインチューニング
Q学習システムのパフォーマンスは主要パラメータの正しい設定に大きく依存します。Ilan 3.0 AIでは、学習のあらゆる側面を微調整できる機能を提供しています。
// Reinforcement learning parameters input double LearningRate = 0.01; // Learning rate input double DiscountFactor = 0.95; // Discount factor input double ExplorationRate = 0.3; // Initial probability of exploration input double ExplorationDecay = 0.995; // Exploration reduction factor input double MinExplorationRate = 0.01;// Minimal probability of exploration
LearningRateはQ値の更新速度を決定します。高い値は急速な学習を可能にしますが、不安定になる場合があります。低い値は安定した学習を保証しますが、学習速度は遅くなります。
DiscountFactorは将来の報酬の重要度を決定します。1に近い値は、システムが短期的利益よりも長期的な利益の最大化を重視することを意味します。
探索パラメータ(ExplorationRate、ExplorationDecay、MinExplorationRate)は、新しい戦略の探索と既知の最適解の活用のバランスを制御します。時間が経つにつれて探索確率は減少し、システムは蓄積された経験に依存する度合いが高まります。
理論から実践へ:実装
Ilan 3.0 AIを実装するには、Q学習の仕組みを従来のEAロジックと統合する必要があります。重要なコンポーネントは取引管理関数であり、Q学習を用いて意思決定をおこないます。// Trade management function using Q-learning void ManagePairWithDQN(string symbol, int &positionsCount, CArrayDouble &trades, int magic, datetime &firstTradeTime) { // Getting current market data double currentBid = SymbolInfoDouble(symbol, SYMBOL_BID); double currentAsk = SymbolInfoDouble(symbol, SYMBOL_ASK); double point = SymbolInfoDouble(symbol, SYMBOL_POINT); // Forming current state double state[]; GetCurrentState(symbol, state); string stateStr = StateToString(state); // Selecting action using Q-table int action = SelectAction(stateStr); // Converting action into trading operation bool shouldTrade = (action > 0); ENUM_ORDER_TYPE orderType = (action == 1) ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; // Logic of opening and managing positions if(shouldTrade) { // Logic of opening first position or averaging // ... } // Checking need to close positions double profit = CalculatePositionsPnL(symbol, magic); if(profit > 0 && positionsCount > 0) { // Logic of closing profitable positions // ... } }
システムによる経験の保存
蓄積された経験を保持するために、セッション間でQテーブルの保存および読み込みをおこなう仕組みを実装しています。
// Saving Q-table to file bool SaveQTable(string filename) { int handle = FileOpen(filename, FILE_WRITE|FILE_BIN); if(handle == INVALID_HANDLE) { Print("Error when opening file for writing Q-table: ", GetLastError()); return false; } // Writing table size FileWriteInteger(handle, QTableSize); // Writing values for(int i = 0; i < QTableSize; i++) { FileWriteString(handle, QTable[i].state); FileWriteInteger(handle, QTable[i].action); FileWriteDouble(handle, QTable[i].value); } FileClose(handle); return true; } // Downloading Q-table from file bool LoadQTable(string filename) { if(!FileIsExist(filename)) { Print("Q-table file does not exist: ", filename); return false; } int handle = FileOpen(filename, FILE_READ|FILE_BIN); if(handle == INVALID_HANDLE) { Print("Error when opening file to read Q-table: ", GetLastError()); return false; } // Reading table size int size = FileReadInteger(handle); // Allocating memory for table if(size > ArraySize(QTable)) { ArrayResize(QTable, size); } // Reading values for(int i = 0; i < size; i++) { QTable[i].state = FileReadString(handle); QTable[i].action = FileReadInteger(handle); QTable[i].value = FileReadDouble(handle); QTableSize++; } FileClose(handle); return true; }
次に、このEAのテストについて考察します。テストは15分足チャートでのOHLCモデリングを使用し、AUDUSDとEURUSDペアで2020年から2025年までおこなわれました(メインペアはEURUSDですが、EAはAUDUSDも同時に処理します)。
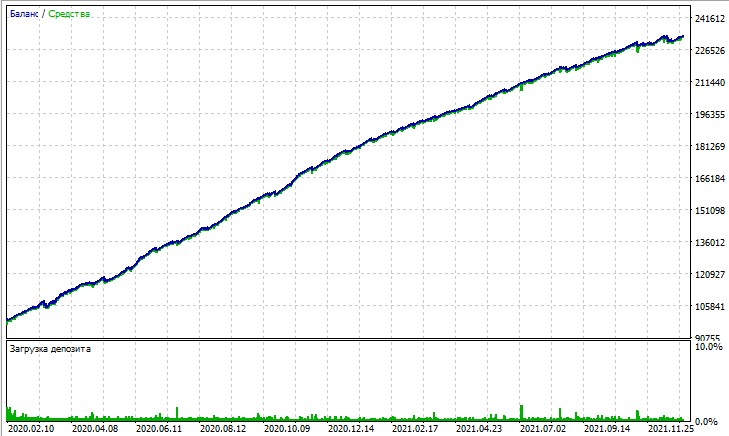
しかし、「全ティック」テストでは、マーチンゲールによる大きなドローダウンが容赦なく浮き彫りになります。ペナルティを設定していても、モデルが連続平均化取引に陥ることがあります。今後のバージョンでは、DQNによるリスク管理でドローダウンを抑制することも検討しています。
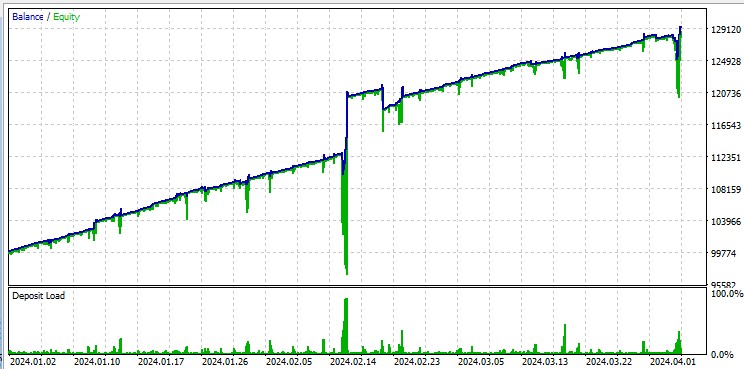
また、このロボットは非常に大きなロットで取引する点にも注意が必要です。これは、売買高(ターンオーバー)に応じたブローカーからのリベート獲得には有効です
アルゴリズム改善の方向性
Ilan 3.0 AIは大きな進化を遂げましたが、知能型取引システムの進化の第一歩に過ぎません。今後の発展が期待される分野は以下の通りです。
- 経験の一般化をより高めるために、Qテーブルを本格的なニューラルネットワークに置き換える
- 深層強化学習(DQN、DDPG、PPO)アルゴリズムの実装
- 新しい市場環境への迅速な適応のためのメタ学習技術の活用
- ニュースやファンダメンタルデータ分析との統合
結論
Ilan 3.0 AIの実装は、アルゴリズム取引へのアプローチにおける根本的な変化を示しています。私たちは、固定ルールに基づく静的なシステムから、学習し進化できる適応型アルゴリズムへと移行しています。
従来のIlan戦略と最新の機械学習手法の統合により、取引システムの開発に新たな地平が開かれます。無限のパラメータ調整に頼るのではなく、システム自体が最適戦略を独自に見つけ、変化する市場環境に適応できるようになります。
アルゴリズム取引の未来は、長年の実績ある取引戦略と革新的な人工知能技術を融合させたハイブリッド手法にあります。Ilan 3.0 AIは従来のEAの単なる改良版ではなく、市場とともに学習し、適応し、進化できる知能型取引システムの新しいクラスです。
私たちは今、決められたルールに従うだけでなく、絶えず進化し、変化する金融市場の中で最適戦略を見つけるモデルの時代の門前に立っているのです。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17455
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ざっと読んだが、一見したところ、この記事はスーパーだ!
イラノに鍛えられるには、どのシンボルが良くて、どのシンボルが悪いのか、いろいろなシンボルを見てテストする必要がある!
マーティンは多くを負っている。
開発という観点で先進的な製品を手に入れるのは興味深い。
こんにちは、
CalculateAveragePrice(symbol) のコードはどこにありますか?
また、2つ以上のポジション間の平均価格のSLとTPを事前に計算する方法を教えてください。
ありがとうございます。