
Simulación de mercado (Parte 22): Iniciando el SQL (V)

Introducción
Hola a todos y sean bienvenidos a un artículo más de la serie sobre cómo construir un sistema de repetición/simulación.
En el artículo anterior Simulación de mercado (Parte 21): Iniciando el SQL (IV), expliqué, de una forma totalmente abstracta, cómo podrías separar una base de datos relacional de una no relacional. Pero, principalmente, y este fue el motivo del artículo anterior, intenté mostrarte cómo tú, aspirante a programador, puedes entender el funcionamiento de una base de datos. Esto, para que pudieras, de hecho, comprender que, aunque pueda parecer adecuado programar algunas cosas, en algunos momentos podemos usar alguna implementación ya existente, a fin de lograr generar el tipo de resultado esperado en una aplicación.
El hecho de que esté usando algo de tiempo para explicar SQL, y no programando en MQL5, se debe justamente a esto. Quiero intentar nivelar un poco las cosas, para que todos puedan entender por qué estaremos usando SQL, cuando podríamos estar creando rutinas y más rutinas para producir algún tipo de implementación.
La implementación, en este caso, es la que nos permitirá desarrollar una forma adecuada y simple para que el sistema de repetición/simulador cuente con un sistema de órdenes. Es decir, necesitamos algún medio para mantener el sistema de órdenes y posiciones, para hacer estudios en el sistema de repetición/simulador. Crear rutinas y más rutinas para hacer esto, a mi juicio, es algo totalmente innecesario, ya que MQL5 nos permite tener cierto soporte de SQL, mediante SQLite. Pero, para quienes están ansiosos por crear siempre código tras código, quiero mostrar una alternativa mejor. Esto se debe a que el tiempo que se gastaría implementando, probando y ajustando las rutinas para conseguir crear algún tipo de base de datos, puede aprovecharse mejor en otras cosas.
De esta manera, en el momento en que empecemos a desarrollar realmente el sistema necesario para que el sistema de repetición/simulador pueda, de hecho, usarse como una alternativa a cuentas demo, a fin de estudiar alguna estrategia, se hará de forma mucho más rápida y sin muchos problemas relacionados con la forma en que las cosas deben funcionar. El motivo de esto es que usaremos SQL para proporcionar el camino necesario para la creación del sistema de órdenes.
Sin embargo, lo que se explicó en el artículo anterior es algo muy abstracto, si dejamos las cosas solo de esa manera y en el terreno de la teoría. Pero, como el tema en cuestión puede ser de interés en otros campos, como, por ejemplo, si deseas crear un Asesor Experto que use una base de datos para aprender a operar, necesitarás, de hecho, poner en práctica lo que se explicó en el artículo anterior. Un detalle importante, y antes de que alguien lo pida: no tengo planes, al menos por el momento, de explicar cómo puedes crear una base de datos para hacer que un Asesor Experto, creado en MQL5, empiece a aprender cómo operar un símbolo determinado.
Explicar este tipo de cosas implicaría explicar muchos otros conceptos y el funcionamiento de una base de datos. Pero, si realmente deseas aprender a hacer esto, te sugiero que profundices bastante en algoritmos de juegos. Esto se debe a que la creación de la base de datos es algo trivial, al igual que la programación del Asesor Experto en MQL5. Pero, para que la base de datos sea, de hecho, útil para que el Asesor Experto aprenda, literalmente, a operar en el mercado, necesitarás saber cómo agregar algunos datos a la base que se creará. Para aprender a crear esos datos, el camino más simple es estudiar algoritmos de juegos.
Sin embargo, existen otros caminos un poco más complicados, como, por ejemplo, el estudio del movimiento de ondas o incluso conceptos de distribución de calor. Pero estas ramas son considerablemente más complicadas, aunque los resultados serán muy parecidos a los de los algoritmos de juegos.
Pero vamos a empezar viendo, en la práctica, lo que se explicó en el artículo anterior. Y, como me gusta separar las cosas en temas, para facilitar la comprensión, vamos al primer tema de este artículo.
Creando una base de datos simple
Aquí no me extenderé mucho. Esto se debe a que esta actividad ya viene siendo explorada desde hace algunos artículos, en los que estamos tratando SQL. Pero, debido a que en el artículo anterior sugerí usar otro programa, para que el trabajo se genere directamente en SQLite, que es la implementación que usaremos mediante MQL5, necesitamos ver algunos pocos detalles, orientados exclusivamente al uso de SQLite.
Muy bien, el primer detalle que veremos es la relación de los tipos de datos en SQLite con los datos que colocaremos en la base de datos. Una de las cosas en SQLite que llaman la atención, cuando el tema son los tipos de datos, es que contiene una cantidad menor de tipos. Pero esto no es una desventaja; al contrario, dependiendo de lo que estés desarrollando, esto es una gran ventaja, además de otra ventaja que SQLite tiene sobre otras implementaciones.
La otra ventaja, que acabo de mencionar, es el hecho de que, en SQLite, los datos son dinámicos y no estáticos, como ocurre en muchas otras implementaciones. Pero espera un momento. ¿Cómo así que los datos en SQLite son dinámicos? ¿Y por qué esto sería una ventaja? Bien, para entender esto, será necesario que veamos una pequeña tabla. Se ve justo debajo:
| Tipo de dato en SQLite | Explicación |
|---|---|
| NULL | Incluye cualquier valor NULL. |
| INTEGER | Enteros con signo, almacenados en 1, 2, 3, 4, 6 u 8 bytes, dependiendo de la magnitud del valor. |
| REAL | Números reales, o valores de punto flotante, almacenados como números de punto flotante de 8 bytes. |
| TEXT | Cadenas de texto almacenadas usando la codificación de la base de datos, que puede ser UTF-8, UTF-16BE o UTF-16LE. |
| BLOB | Cualquier blob de datos, con cada blob almacenado exactamente como se insertó. |
Fíjate que, en esta tabla, tenemos los tipos de SQLite. Ahora, solo por curiosidad, veamos cómo son las cosas en otras implementaciones de SQL. Empezando por MySQL, que tiene la tabla de tipos que se muestra abajo:
| Tipo de dato en MySQL | Explicación |
|---|---|
| TINYINT | Un entero muy pequeño. El rango con signo para este tipo de datos numérico es de -128 a 127, mientras que el rango sin signo es de 0 a 255. |
| SMALLINT | Un pequeño número entero. El rango con signo para este tipo numérico es de -32768 a 32767, mientras que el rango sin signo es de 0 a 65535. |
| MEDIUMINT | Un entero de tamaño medio. El rango con signo para este tipo de datos numérico es de -8388608 a 8388607, mientras que el rango sin signo es de 0 a 16777215. |
| INTEGER | Un número entero de tamaño normal. El rango con signo para este tipo de datos numérico es de -2147483648 a 2147483647, mientras que el rango sin signo es de 0 a 4294967295. |
| BIGINT | Un entero grande. El rango con signo para este tipo de datos numérico es de -9223372036854775808 a 9223372036854775807, mientras que el rango sin signo es de 0 a 18446744073709551615. |
| FLOAT | Un número pequeño de punto flotante (precisión simple). |
| DOUBLE | Un número de punto flotante de tamaño normal (precisión doble). |
| DECIMAL | Un número de punto fijo empaquetado. La longitud de visualización de las entradas para este tipo de datos se define cuando la columna se crea, y cada entrada se ajusta a esa longitud. |
| BOOLEAN | Un booleano es un tipo de dato que solo tiene dos valores posibles, generalmente verdadero o falso. |
| BIT | Un tipo de valor de bit, para el cual puedes especificar el número de bits por valor, de 1 a 64. |
| DATE | Una fecha, representada como YYYY-MM-DD. |
| DATETIME | Un registro de fecha y hora, mostrando la fecha y la hora, mostrado como YYYY-MM-DD HH:MM:SS. |
| TIMESTAMP | Un timestamp, que indica la cantidad de tiempo desde la época de Unix (00:00:00 el 1 de enero de 1970). |
| TIME | Una hora del día, mostrada como HH:MM:SS. |
| YEAR | Un año expresado en un formato de 2 o 4 dígitos, siendo 4 dígitos el estándar. |
| CHAR | Una cadena de longitud fija; las entradas de este tipo se rellenan a la derecha con espacios para cumplir la longitud especificada cuando se almacenan. |
| VARCHAR | Una cadena de longitud variable. |
| BINARY | Similar al tipo char, pero una cadena de bytes binarios de una longitud especificada, en lugar de una cadena de caracteres no binarios. |
| VARBINARY | Similar al tipo varchar, pero una cadena de bytes binarios de longitud variable, en lugar de una cadena de caracteres no binarios. |
| BLOB | Una cadena binaria con longitud máxima de 65535 (2^16 - 1) bytes de datos. |
| TINYBLOB | Una columna blob con longitud máxima de 255 (2^8 - 1) bytes de datos. |
| MEDIUMBLOB | Una columna blob con longitud máxima de 16777215 (2^24 - 1) bytes de datos. |
| LONGBLOB | Una columna blob con longitud máxima de 4294967295 (2^32 - 1) bytes de datos. |
| TEXT | Una cadena con longitud máxima de 65535 (2^16 - 1) caracteres. |
| TINYTEXT | Una columna de texto con longitud máxima de 255 (2^8 - 1) caracteres. |
| MEDIUMTEXT | Una columna de texto con longitud máxima de 16777215 (2^24 - 1) caracteres. |
| LONGTEXT | Una columna de texto con longitud máxima de 4294967295 (2^32 - 1) caracteres. |
| ENUM | Una enumeración, que es un objeto de cadena de caracteres que obtiene un único valor de una lista de valores declarados cuando la tabla se crea. |
| SET | Similar a una enumeración, un objeto de cadena que puede tener cero o más valores, cada uno de los cuales debe elegirse de una lista de valores permitidos, que se especifican cuando la tabla se crea. |
Fíjate que existen muchos más tipos y que debemos elegir adecuadamente el tipo correcto para evitar problemas futuros. Al igual que en PostgreSQL, que tiene su tabla de tipos que se muestra justo debajo.
| Tipo de datos en PostgreSQL | Explicación |
|---|---|
| BIGINT | Un entero con signo de 8 bytes. |
| BIGSERIAL | Un entero de 8 bytes con incremento automático. |
| DOUBLE PRECISION | Un número de punto flotante de precisión doble de 8 bytes. |
| INTEGER | Un entero con signo de 4 bytes. |
| NUMERIC | Un número de precisión seleccionable, recomendado para uso en casos donde la exactitud es crucial, como valores monetarios. |
| REAL | Un número de punto flotante de precisión simple de 4 bytes. |
| SMALLINT | Un entero con signo de 2 bytes. |
| SMALLSERIAL | Un entero de 2 bytes con incremento automático. |
| SERIAL | Un entero de 4 bytes con incremento automático. |
| CHARACTER | Una cadena de caracteres con una longitud fija especificada. |
| VARCHAR | Una cadena de caracteres de longitud variable, pero limitada. |
| TEXT | Una cadena de caracteres de longitud variable e ilimitada. |
| DATE | Una fecha del calendario, que consiste en día, mes y año. |
| INTERVAL | Un intervalo de tiempo. |
| TIME WITHOUT TIME ZONE | Una hora del día, sin incluir la zona horaria. |
| TIME WITH TIME ZONE | Una hora del día, incluyendo la zona horaria. |
| TIMESTAMP WITHOUT TIME ZONE | Una fecha y hora, sin incluir la zona horaria. |
| TIMESTAMP WITH TIME ZONE | Una fecha y hora, incluyendo la zona horaria. |
| BOX | Una caja rectangular en un plano. |
| CIRCLE | Un círculo en un plano. |
| LINE | Una línea infinita en un plano. |
| LSEG | Un segmento de recta en un plano. |
| PATH | Un camino geométrico en un plano. |
| POINT | Un punto geométrico en un plano. |
| POLYGON | Un camino geométrico cerrado en un plano. |
| CIDR | Una dirección de red IPv4 o IPv6. |
| INET | Una dirección de host IPv4 o IPv6. |
| MACADDR | Una dirección Media Access Control (MAC). |
| BIT | Una cadena de bits de longitud fija. |
| BIT VARYING | Una cadena de bits de longitud variable. |
| TSQUERY | Una consulta de búsqueda de texto. |
| TSVECTOR | Un documento de búsqueda de texto. |
| JSON | Datos JSON textuales. |
| JSONB | Datos JSON binarios descompuestos. |
| BOOLEAN | Un booleano lógico, que representa verdadero o falso. |
| BYTEA | Abreviatura de “array de bytes”; este tipo se usa para datos binarios. |
| MONEY | Una cantidad de moneda. |
| PG_LSN | Un número de secuencia de registro de PostgreSQL. |
| TXID_SNAPSHOT | Una instantánea de ID de transacción a nivel de usuario. |
| UUID | Un identificador universalmente exclusivo. |
| XML | Datos XML. |
Fíjate que tenemos todavía más tipos disponibles aquí en PostgreSQL. Quizá estés pensando: Pero todo esto puede volverse, para quien pretenda usar SQL, una pesadilla. Pero no es exactamente así. SQL logra adaptarse a nuestras necesidades. Esto, para que una base de datos pueda usarse en otra aplicación, creada también en SQL. El hecho de que tengamos más o menos tipos hace que elegir el tipo sea más o menos difícil. Esto se debe a que, si eliges el tipo equivocado, cuando necesites cambiarlo, toda la base de datos tendrá que reconstruirse. Aunque es una tarea bastante fácil de realizar, ya que usamos scripts hechos especialmente para esto, puede ser algo bastante trabajoso para quien desea aprender SQL y no sabe por dónde empezar.
Sin embargo, al observar estas tablas, enseguida notas que el hecho de que SQLite use pocos tipos hace que los tipos presentes en él requieran menos trabajo de mantenimiento. Pero esto nos trae otras cuestiones que no vienen al caso. Lo que realmente nos interesa en este momento es el hecho de que, al tener menos tipos, SQLite tiene tipos dinámicos; es decir, crecen conforme la necesidad que la información a almacenar llegue a exigir.
¿Pero cómo se aplica esto en la práctica? Para entenderlo, es necesario que creemos dos bases de datos distintas. Una se creará usando MySQL y la otra, usando SQLite. Ambas usan SQL como lenguaje base. Veamos cómo hacer esto. La animación de abajo muestra cómo se haría este proceso en MySQL.
Fíjate en los tipos utilizados. La animación que se ve a continuación ejecuta prácticamente el mismo procedimiento, solo que en SQLite.
Fíjate en los tipos que están definidos en esta segunda animación. Aunque, en la animación vista en MySQL, el script crea la base de datos, lo mismo no ocurre en SQLite. En este caso, tenemos que tener la base ya creada y abierta en DB Browser. Pero quizá estés pensando: Bien, los tipos son diferentes, entonces un código no funcionaría de forma cruzada. Bien, si estás pensando eso, es porque caíste en paracaídas en este artículo. Mi sugerencia es que leas los artículos anteriores, ya que allí mostré cómo usar el mismo código, tanto en MySQL como en SQLite. Solo que, en ese caso, estábamos usando MetaEditor para ejecutar SQLite.
Pero lo que nos interesa en este punto es el hecho de que, en el código visto en MySQL, definimos, durante la creación de las columnas, el tamaño que tendrían. Ya en el caso de SQLite, tal cosa no se hizo. Este tipo de dinamismo puede hacerse en MySQL. Sin embargo, no es algo que se encuentre comúnmente en implementaciones distintas de SQLite. El motivo es que, muchas veces, el programador de SQL prefiere definir el tipo, o incluso el tamaño de los campos, a fin de optimizar alguna característica de la base de datos. Por esta razón, tenemos un mayor trabajo en lo que respecta al mantenimiento de bases de datos en diferentes implementaciones.
Pero, en este punto, puede surgir una duda. ¿Será que MySQL lograría entender las columnas creadas por SQLite, o viceversa? En cuanto a esto, mi querido lector, no necesitas preocuparte. Pues sí, cualquier implementación de SQL logrará entender el dimensionamiento usado en las columnas. Por esta razón, mostré las tablas de arriba, justamente para facilitar esta comprensión de que existe cierto cruce entre los tipos de datos. Pero, dependiendo de la implementación, el programador puede decidir usar uno u otro tipo específico, a fin de optimizar algún detalle en la base de datos.
Muy bien. Ahora que hicimos las debidas presentaciones, veamos, en la práctica, la cuestión de cómo entran en toda esta historia las claves primarias y foráneas.
Claves primarias y foráneas en la práctica
Puedes ver, en las animaciones de arriba, que estamos creando una base de datos muy simple. Esta tiene como objetivo almacenar el nombre del símbolo, junto con la cotización y la fecha en que se obtuvo la cotización. Sin embargo, en la práctica, difícilmente un programador de bases de datos crearía la base de esta manera. Esto se debe a que podrías querer poner más de un símbolo, o podrías querer añadir información extra en la propia base de datos, como, por ejemplo, el nombre comercial de la empresa cuyo símbolo esté siendo representado en la tabla.
Pero también puede ocurrir que el símbolo cambie de nombre. Aunque es algo bastante raro, a veces ocurre. Tenemos un ejemplo de esto en B3, donde, durante un tiempo, la empresa VIA VAREJO tenía como tick: VVAR3. Por algún motivo, el símbolo cambió el tick a VIIA3. Entonces, piensa en todo el trabajo de tener que cambiar, en cada uno de los registros pasados, el nombre del símbolo de VVAR3 a VIIA3. Pero todo eso podría hacerse muy fácilmente si la base se hubiera construido de otra forma.
Aunque este ejemplo es muy simple, es lo bastante práctico como para que puedas entender otras muchas cosas. Pues mucha gente cree que crear y mantener una base de datos es una tarea sencilla. Pero, cuando va a hacerlo realmente, termina haciendo un montón de tonterías que después dan un trabajazo enorme para resolverse adecuadamente.
Vamos, primero, a ver cómo se hace la solución básica usando SQLite. Para facilitar las cosas y, por consecuencia, la explicación, puedes ver el código de un script SQL justo debajo. Este hará uso de lo que queremos implementar.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY, 06. symbol TEXT 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT, 12. -- symbol TEXT, 13. price NUMERIC, 14. fk_id INTEGER, 15. FOREIGN KEY (fk_id) REFERENCES tb_Symbol (id) 16. );
Código en SQLite
Observa que este código ya contiene algunas cosas que NO son de SQL. En este caso, estamos hablando de la línea uno, donde hacemos uso de una instrucción interna de SQLite. Pero, ¿por qué estoy usando esta instrucción aquí? El motivo es que, en la documentación de SQLite, que dejaré al final de este artículo, en la parte de referencias, se indica que, hasta la versión 3.6.19, SQLite no usa claves foráneas por defecto, siendo necesario que se lo indiquemos. De lo contrario, no las usará. Aunque la versión mencionada es bastante antigua, puede que alguien todavía la esté utilizando por algún motivo. Salvo este hecho, veamos qué está pasando en este script. Recuerda que, para la correcta ejecución del script en SQLite, deberá haber una base de datos abierta en DB Browser.
En la línea tres, estamos creando, si no existe, una tabla llamada tb_Symbols. Dentro de esta tabla, declaramos, en la línea cinco, una identidad única. Ya en la línea seis, definimos el nombre del símbolo. Aquí todavía no estamos limitando más los registros que esta tabla contendrá. El motivo de esto es que aún quiero mostrar cómo llegamos a un modelo mucho más adecuado de construcción de una base de datos. Entonces, aunque el valor de id sea siempre único, podemos tener el mismo símbolo definido en más de un id. Pero esto es supersimple de resolver. Pero, antes de ver cómo lo haremos, primero entendamos cómo funcionan las claves aquí.
Una vez que la tabla tb_Symbols se haya creado, podemos modificar, o mejor dicho, crearemos una nueva tabla. Esta se inicia en la línea nueve, donde decimos que queremos crear la tabla tb_Quotes. Fíjate que la línea 12 es la original, vista en la animación justo arriba. Sin embargo, a diferencia de lo que se ve en la animación, aquí aparece como un comentario. El motivo de esto es que el nombre del símbolo ya no estará en esta tabla. Por este detalle, se añadieron las líneas 14 y 15 al código. Ahora, presta mucha atención a lo que voy a explicar, porque es importante. En la línea 14, definimos un valor que deberá tener el mismo tipo usado en la clave primaria de la tabla tb_Symbols. En algunos casos, el programador que usa SQLite no define el tipo, dejando que el propio programa lo haga. Como quiero mantener cierto estándar en el código, estoy definiendo el tipo.
Esta será nuestra clave foránea dentro de la tabla tb_Quotes. Ahora, el punto realmente importante en este script visto arriba. En la línea 15, decimos cuál es la clave foránea y a qué se referirá esa clave. Fíjate que necesitamos indicar el nombre de la tabla, así como también el nombre de la clave o columna que se usará. Esta clave a la que me refiero tiene como origen la tabla tb_Symbols.
Con esto, creamos un sistema referencial, o relacional, donde tenemos la información de la cotización separada del nombre del símbolo. Sin embargo, esta separación no es realmente real, ya que existe un vínculo entre el registro de la cotización y el nombre del símbolo. Y ese vínculo se da justamente por la creación de la clave primaria y la foránea. Si lograste entender este vínculo, te darás cuenta de que podemos crear una verdadera base de datos, relacionando entre sí diversa información distinta, de tal forma que tendrá algún tipo de enlace que, al mismo tiempo, nos permite agregar más o menos datos a un mismo registro. Todo esto con un costo bajísimo de mantenimiento o modificación de la base de datos original.
Este mismo código visto arriba puede crearse como se muestra abajo, lo que sería algo mucho más cercano a una posible realidad. Aunque todavía no hemos asegurado la cuestión de que el nombre del símbolo se repita en más de una posición en la tabla tb_Symbols.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY, 06. symbol TEXT 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT, 12. price NUMERIC, 13. fk_id INTEGER REFERENCES tb_Symbol (id) 14. );
Código en SQLite
Fíjate que, ahora, hicimos un pequeño cambio. Este está en la línea 13, que tiene el mismo objetivo, es decir, enlazar mediante clave foránea la tabla tb_Quotes con la tabla tb_Symbols. Un detalle: Aunque esté diciendo que estamos enlazando las tablas, lo correcto es decir que estamos enlazando un registro de la tabla tb_Quotes con otro registro de la tabla tb_Symbols. Bien, ahora fíjate en lo siguiente: no importa lo que estemos guardando en cada una de las tablas. Podemos poner más o menos campos, o columnas de datos, en las tablas, y esto no influirá directamente en la búsqueda ni en los resultados que obtendremos en las búsquedas.
Pero, dependiendo de la necesidad, puedes querer agregar alguna información más en una de las tablas. Sin embargo, al hacerlo, cualquier otra tabla vinculada a esta se beneficiará de ese hecho, pero sin que necesariamente tengamos que reescribir toda la base de datos. Tal vez no estés viendo realmente el alcance de esto. Pero, si empiezas a usar SQL, en poco tiempo te darás cuenta de que esto ayuda bastante cuando queremos expandir una base de datos o generar un sistema relacional entre diversa información diferente.
Muy bien, pero ¿cómo podemos resolver el problema de posibles duplicaciones en la base de datos? La forma de hacerlo es muy simple. Durante la creación de la tabla, decimos que una columna no deberá tener ciertos valores o que los valores no podrán duplicarse. Por ejemplo, vamos a modificar el código visto arriba, de modo que no podamos tener un valor nulo en las columnas. Pero también no queremos que el nombre de un símbolo aparezca en más de un registro en la misma columna. Así, el código ya corregido queda como se muestra abajo.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY NOT NULL, 06. symbol TEXT NOT NULL UNIQUE 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT NOT NULL, 12. price NUMERIC NOT NULL, 13. fk_id INTEGER NOT NULL, 14. FOREIGN KEY (fk_id) REFERENCES tb_Symbol (id) 15. );
Código en SQLite
Ahora, si ejecutas este script, notarás que se crearán las dos tablas, como se esperaba y como se vio en la explicación de arriba. Sin embargo, a diferencia de lo que ocurría, ahora ya no tendremos registros duplicados. Si intentas duplicar algún registro, SQL impedirá que eso ocurra. Del mismo modo, ya no tendremos incidencia de valores nulos en nuestra tabla. Fíjate que el código para hacer esto es supersimple y fácil de comprender.
Entendiendo el último script
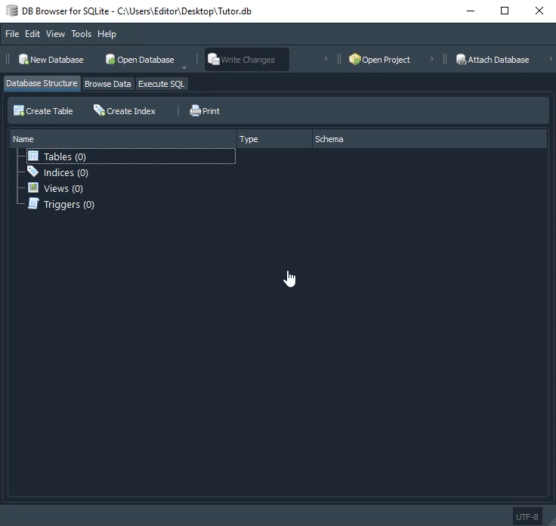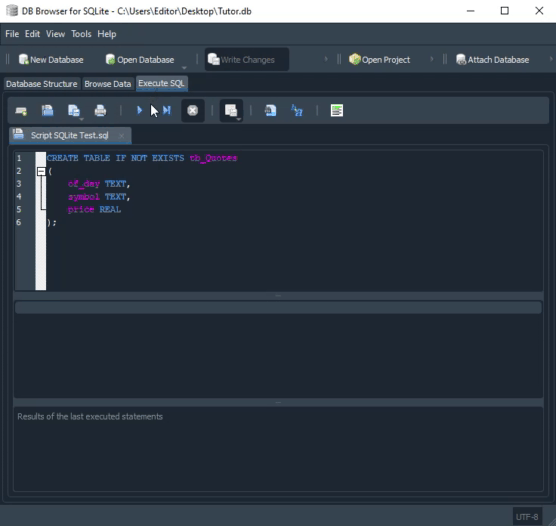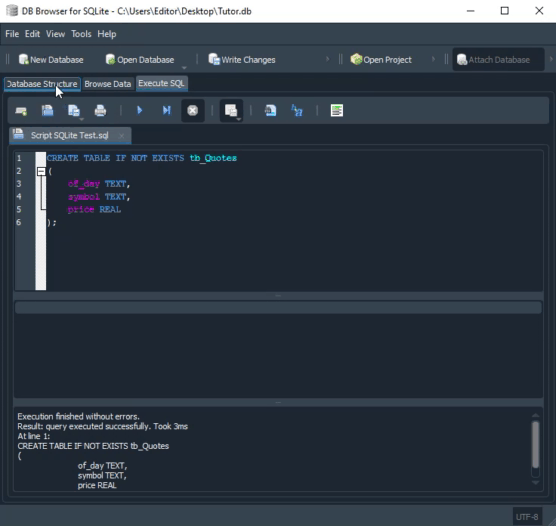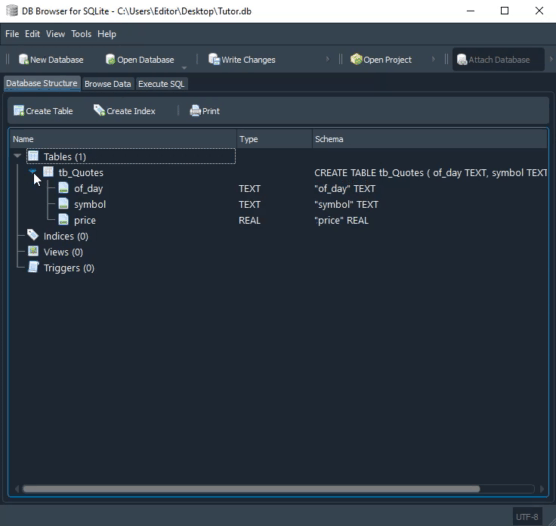
Entender cómo funciona este último script, antes de aventurarnos por nuevos terrenos, no es ni de lejos algo opcional. Es necesario que, de hecho, pruebes y entiendas lo que está pasando aquí. De lo contrario, después estarás completamente perdido. De este modo, después de ejecutar el último código de script en SQL, visto justo arriba, tendrás, en BD Browser, el siguiente resultado, que se ve en la imagen inmediatamente debajo:
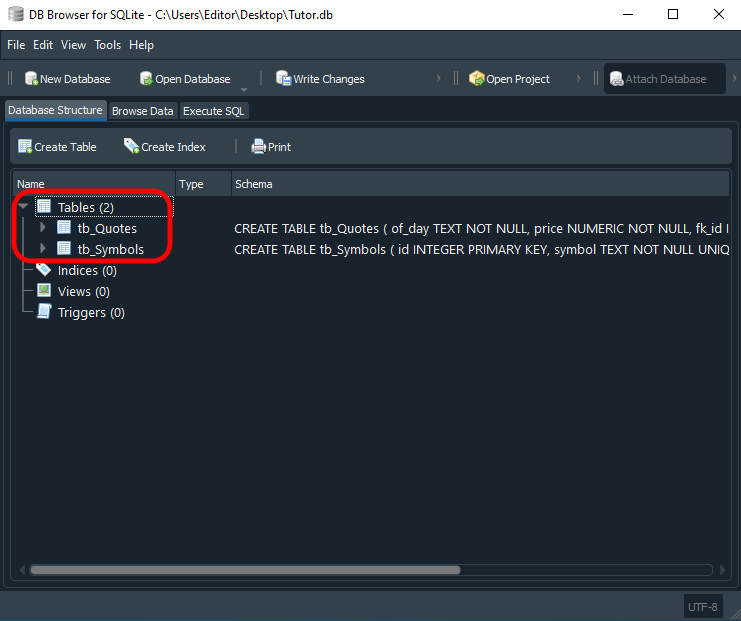
Observa que tenemos las dos tablas mostradas aquí destacadas. Pero, ¿cómo hacemos para utilizarlas de verdad? Parece algo muy complicado y solo posible para grandes gurús de la computación. Para nada. Usar este esquema es más simple que caminar hacia delante. Ya mostré cómo hacemos para agregar información a una tabla mediante un script. Esto en artículos anteriores, hablando sobre SQL. Así que aquí usaremos algo muy parecido a lo que ya se vio.
Para esto, para ver cómo se dan las cosas, vamos a agregar algunos datos solo para ejemplificar la interacción con este tipo de modelado. Y, ya que también mostré el comando básico de selección, también podemos usarlo aquí. Pero primero vamos a agregar algunos registros a nuestra base de datos. Así que vamos a modificar el script visto arriba por otro, ligeramente diferente.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * FROM tb_Quotes;
Script em SQLite
Quizá lo estés mirando y pensando: Caramba, qué código tan complicado. Nunca voy a lograr entender esto. Creo que voy a rendirme y volver a hacer las cosas de otra forma. Pero yo te digo, caro lector: ¿Vas a rendirte ahora? ¿Justo ahora que las cosas empezaron a ponerse más interesantes? Pues este código visto arriba no tiene nada de complicado. Todo, absolutamente todo lo que contiene, ya se explicó en esta fase inicial, donde he dado alguna explicación sobre cómo usar el lenguaje SQL.
Tal vez la única parte que te deje un poco confundido sean las líneas tres y cuatro, donde le estamos diciendo a SQL que, si las tablas tb_Quotes y tb_Symbol existen, deberán ser destruidas. Pero, ¿por qué estamos destruyendo las tablas antes de usarlas? Y la cuestión principal: ¿por qué destruir las tablas? ¿No podríamos simplemente mantenerlas e ir agregando cosas a la base de datos?
Todas estas cuestiones tienen una única respuesta. Necesitamos destruir las tablas por el simple motivo de que, entre las líneas 20 y 29, estaremos añadiendo valores en ellas. Sin embargo, cada vez que ejecutes este mismo script, SQL, en el momento en que vayamos a añadir valores a las tablas, nos informará de un error. El motivo de que se genere ese error es justamente el hecho de que no podremos duplicar algunos campos en la base de datos.
En el momento en que ejecutes este script, tendrás como resultado la siguiente imagen que se ve abajo:
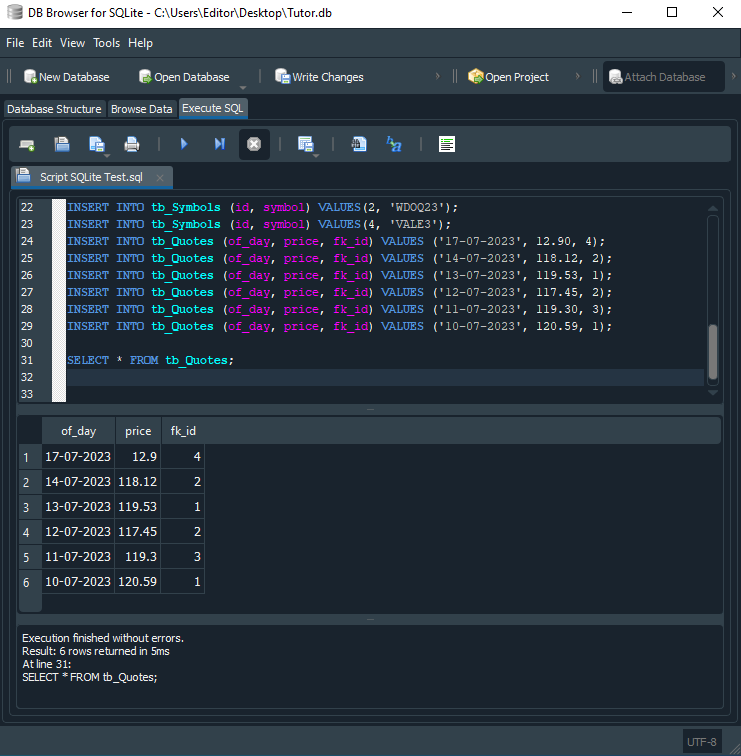
Observa que tenemos exactamente como resultado el contenido presente en la tabla tb_Quotes. Esto se debe a que, en la línea 31, le estamos diciendo a SQL que nos dé esa información. Pero, al mirar esto, puedes desanimarte un poco. Esto se debe a que, si tenemos una base de datos muy extensa, con cotización de diversos símbolos, resulta difícil saber cuál es cuál, ya que no tenemos como retorno el nombre del símbolo ni alguna otra información para entender mejor lo que estamos buscando dentro de la base de datos. Pero pronto veremos cómo mejorar esto, haciendo uso de un pequeño cambio en el código de la línea 31, donde usamos el comando SELECT.
Consideraciones finales
Antes de que tires la toalla y decidas abandonar el estudio sobre cómo usar SQL, déjame recordarte, mi querido lector, que aquí todavía estamos usando solo lo más básico de lo básico. Aún no hemos explorado algunas cosas que es posible hacer en SQL. En cuanto las exploremos, verás que SQL es mucho más práctico de lo que parece. Aunque, muy probablemente, yo termine cambiando la dirección de lo que estamos creando. Esto se debe a que el proceso de creación es dinámico. Voy a mostrar un poco más sobre cómo hacer las cosas en SQL. Esto se debe a que, de hecho, es algo que necesitas entender y conocer. Simplemente pensar que eres más capaz que toda una comunidad de programadores y desarrolladores solo te hará perder tiempo y oportunidades. Ten calma, porque esto se va a volver aún más interesante.
Como dije hace poco, todavía no tengo certeza de que usaré SQLite u otra implementación de SQL. Esto se debe a que el desarrollo de lo que se hará para el sistema de repetición/simulador es algo totalmente dinámico. Aún no decidimos en qué dirección, de hecho, vamos a seguir. Pero, independientemente de cómo se creen y desarrollen las cosas, en los próximos pasos, cuando volvamos a MQL5, con toda seguridad usaremos SQL para ayudarnos en diversas cuestiones. No pretendo, y no vamos a crear, ninguna rutina para producir algo que SQL nos permite hacer y nos ayuda. Pero la forma en que, de hecho, usaremos SQL todavía no se ha definido por completo.
En el próximo artículo, veremos cómo hacer algunas otras cosas en SQL. Esto se debe a que ahora la cosa realmente empieza a tomar más cuerpo, y el rumbo, así como lo que pretendo abordar y explicar, ya está casi en su plenitud. Sin embargo, quiero reforzar el hecho de que estos artículos no tienen como enfoque ser un curso de SQL. Solo quiero mostrar algunos puntos que podrán utilizarse en el futuro, ya que no tiene sentido usar MQL5, o cualquier otro lenguaje, para hacer algo que el propio SQL puede hacer por nosotros. Y no estoy hablando solo de la cuestión de crear y mantener una base de datos. Estoy hablando en términos de programación en sí.
Muchos solo conocen unos pocos comandos de SQL, pero se olvidan o no tienen la debida curiosidad de profundizar en SQL, perdiendo así la oportunidad de usar un verdadero auxiliar, ya que muchas de las rutinas que algunos crean en un lenguaje integrado con SQL podrían hacerse directamente en SQL. Y saber cómo hacer este tipo de cosas te ayudará bastante. Entonces, procura profundizar en el tema. Usa estos artículos solo como un punto de apoyo, pero no los tomes como tu única fuente ni como algo definitivo. Un gran abrazo a todos, y nos vemos en el próximo artículo.
| Archivo | Descripción |
|---|---|
| Experts\Expert Advisor.mq5 | Demuestra la interacción entre Chart Trade y el Asesor Experto (es necesario el Mouse Study para la interacción) |
| Indicators\Chart Trade.mq5 | Crea la ventana para configurar la orden a ser enviada (es necesario el Mouse Study para la interacción) |
| Indicators\Market Replay.mq5 | Crea los controles para la interacción con el servicio de repetición/simulador (es necesario el Mouse Study para la interacción) |
| Indicators\Mouse Study.mq5 | Permite la interacción entre los controles gráficos y el usuario (necesario tanto para operar el sistema de repetición/simulador como en el mercado real) |
| Services\Market Replay.mq5 | Crea y mantiene el servicio de repetición y simulación de mercado (archivo principal de todo el sistema) |
| Code VS C++\Servidor.cpp | Crea y mantiene un socket servidor desarrollado en C++ (versión MiniChat) |
| Code in Python\Server.py | Crea y mantiene un socket en Python para la comunicación entre MetaTrader 5 e Excel |
| Indicators\Mini Chat.mq5 | Permite implementar un minichat mediante un indicador (requiere el uso de un servidor para funcionar) |
| Experts\Mini Chat.mq5 | Permite implementar un minichat mediante un Asesor Experto (requiere el uso de un servidor para funcionar) |
| Scripts\SQLite.mq5 | Demuestra el uso de un script SQL mediante MQL5 |
| Files\Script 01.sql | Demuestra la creación de una tabla simple, con clave foránea |
| Files\Script 02.sql | Demuestra la adición de valores en una tabla |
Referencia
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/12986
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Redes neuronales en el trading: Pronóstico de series temporales con descomposición modal adaptativa (ACEFormer)
Redes neuronales en el trading: Pronóstico de series temporales con descomposición modal adaptativa (ACEFormer)
 Trading de arbitraje en Forex: Sistema comercial matricial para retornar al valor justo con limitación del riesgo
Trading de arbitraje en Forex: Sistema comercial matricial para retornar al valor justo con limitación del riesgo
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso