
Verwendung von Deep Reinforcement Learning zur Verbesserung des Ilan Expert Advisor

Einführung
In der Welt des algorithmischen Handels gibt es einige Strategien, die wie ewige Sterne am sich ständig verändernden Firmament der Finanzmärkte unauslöschliche Spuren in der Geschichte des Handels hinterlassen. Dazu gehört auch Ilan, ein einst legendärer Grid Expert Advisor, der in den 2010er Jahren mit seiner trügerischen Einfachheit und seiner potenziellen Effektivität in Zeiten niedriger Volatilität die Köpfe und Konten von Händlern in seinen Bann zog.
Doch die Zeit bleibt nicht stehen. Im Zeitalter von Quantencomputern, neuronalen Netzen und maschinellem Lernen müssen die Strategien von gestern grundlegend überdacht werden. Was wäre, wenn wir die klassische Mechanik der Ilan-Gitter-Mittelwertbildung mit fortschrittlichen Algorithmen der künstlichen Intelligenz kombinieren? Was wäre, wenn wir anstelle von fest kodierten Regeln das System sich selbst anpassen und ständig verbessern ließen?
In diesem Artikel stellen wir etablierte Ideen über Handelsmodelle in Frage und unternehmen einen ehrgeizigen Versuch, den klassischen Ilan wiederzubeleben, indem wir ihn mit Deep Reinforcement Learning (Q-Learning) und einer dynamischen Q-Tabelle ausstatten. Wir ändern nicht einfach nur bestehenden Code, sondern schaffen ein grundlegend neues, intelligentes Modell, das in der Lage ist, aus unseren eigenen Erfahrungen zu lernen, sich an Marktveränderungen anzupassen und Handelslösungen in Echtzeit zu optimieren.
Unsere Reise führt Sie durch die Labyrinthe des algorithmischen Handels, wo mathematische Strenge auf rechnerische Eleganz trifft und klassische Martingale-Techniken dank innovativer Ansätze des maschinellen Lernens zu neuem Leben erwachen. Ob Sie nun ein erfahrener algorithmischer Händler, ein Entwickler von Handelsarchitekturen oder einfach nur ein Enthusiast der Finanztechnologie sind, dieser Artikel bietet eine einzigartige Perspektive auf die Zukunft des automatisierten Handels.
Schnallen Sie sich an - wir begeben uns auf eine aufregende Reise, um Ilan 3.0 KI zu schaffen, wo Tradition auf Innovation trifft und sich die Vergangenheit in die Zukunft entwickelt.
Den Klassiker Ilan von innen studieren
Bevor man in die Welt der künstlichen Intelligenz eintaucht, muss man verstehen, was Ilan in den 2010er Jahren zu einem so beliebten Expert Advisor machte. Der Schlüsselgedanke seiner Arbeit war das Konzept der Mittelwertbildung von Positionen. Wenn sich der Kurs gegen die offene Position bewegte, schloss der Expert Advisor den Verlust nicht, sondern fügte neue Aufträge hinzu und verbesserte so den durchschnittlichen Einstiegskurs.
Hier ist ein vereinfachter Codeausschnitt, der diese Logik veranschaulicht:
// Simplified averaging logic in the original Ilan if(positionCount == 0) { // Opening first position on signal if(OpenSignal()) { OpenPosition(ORDER_TYPE_BUY, StartLot); } } else { // Calculating level for averaging double averagePrice = CalculateAveragePrice(); double gridLevel = averagePrice - GridSize * Point(); // If price has reached grid level, add position if(Bid <= gridLevel) { double newLot = StartLot * MathPow(LotMultiplier, positionCount); OpenPosition(ORDER_TYPE_BUY, newLot); } // Checking for closing of all TP positions if(Bid >= averagePrice + TakeProfit * Point()) { CloseAllPositions(); } }
Die Magie des Martingals: Warum sich Händler in Ilan verliebt haben
Die Popularität von Ilan lässt sich durch mehrere Faktoren erklären. Zunächst einmal war seine Arbeit selbst für unerfahrene Händler intuitiv. In einem seitwärts tendierenden Markt zeigte das System fast magische Ergebnisse - jede Kursschwankung wurde zu einer Quelle des Gewinns. Die Durchschnittsbildung von Positionen ermöglichte es, Handelsgeschäfte zu „retten“, die zunächst mit Verlust abgeschlossen wurden, und vermittelte dem Händler das Gefühl der Unbesiegbarkeit der Architektur.
Ein weiterer attraktiver Faktor war die Möglichkeit, die Strategie mit einer minimalen Anzahl von Parametern anzupassen:
// Key parameters of Ilan Expert Advisor input double StartLot = 0.01; // Initial lot size input double LotMultiplier = 1.5; // Lot multiplier for each new position input int GridSize = 30; // Grid size in points input int TakeProfit = 40; // Profit for closing all positions input int MaxPositions = 10; // Maximum number of positions to open
Diese Einfachheit der Einrichtung vermittelte den Eindruck von Kontrolle. Der Händler konnte mit verschiedenen Parameterkombinationen experimentieren und auf der Grundlage historischer Daten beeindruckende Ergebnisse erzielen.
Versuche der Evolution: Was hat sich in Ilan 2.0 geändert?
In Ilan 2.0 haben die Entwickler versucht, einige dieser Probleme zu lösen. Die dynamische Berechnung des Rasterschritts auf der Grundlage der Marktvolatilität, die Arbeit mit mehreren Währungspaaren und die Analyse ihrer Korrelation, zusätzliche Filter für die Eröffnung von Positionen und Schutzmechanismen gegen übermäßige Verluste wurden hinzugefügt.
// Dynamic calculation of grid step in Ilan 2.0 double CalculateGridStep(string symbol) { double atr = iATR(symbol, PERIOD_CURRENT, ATR_Period, 0); return atr * ATR_Multiplier; } // Protective mechanism to limit losses bool EquityProtection() { double currentEquity = AccountInfoDouble(ACCOUNT_EQUITY); double maxAllowedDrawdown = AccountInfoDouble(ACCOUNT_BALANCE) * MaxDrawdownPercent / 100.0; if(AccountInfoDouble(ACCOUNT_BALANCE) - currentEquity > maxAllowedDrawdown) { CloseAllPositions(); return true; } return false; }
Diese Verbesserungen machten das System zwar widerstandsfähiger, lösten aber nicht das grundlegende Problem der mangelnden Anpassungsfähigkeit. Ilan 2.0 basierte immer noch auf statischen Regeln und konnte nicht aus seinen Erfahrungen lernen oder sich an veränderte Marktbedingungen anpassen.
Warum nutzten die Händler weiterhin Ilan
Trotz der offensichtlichen Nachteile nutzten viele Händler weiterhin Ilan und seine Modifikationen. Dies ist auf eine Reihe von psychologischen Faktoren zurückzuführen. Diejenigen, die pleite gingen, schwiegen in der Regel, während erfolgreiche Geschichten aktiv veröffentlicht wurden. Die Händler bemerkten erfolgreiche Phasen und ignorierten die Warnzeichen. Es schien, dass die Feinabstimmung der Parameter alle Probleme lösen könnte. Darüber hinaus aktiviert die Martingale-Strategie die gleichen psychologischen Auslöser wie das Glücksspiel.
Fairerweise ist anzumerken, dass der EA unter bestimmten Marktbedingungen - insbesondere in Zeiten geringer Volatilität und Seitwärtsbewegungen - tatsächlich lange Zeit beeindruckende Ergebnisse erzielen konnte. Das Problem war, dass sich die Marktbedingungen unweigerlich änderten und der Expertenberater sich nicht an diese Veränderungen anpasste.
Warum Ilan unweigerlich zusammenbrach und die Einlage verlor
Das eigentliche Problem von Ilan wurde erst im Laufe der Zeit deutlich. Die Strategie, die in einem Seitwärtsmarkt perfekt funktionierte, erwies sich bei länger anhaltenden Trendbewegungen als katastrophal anfällig. Betrachten Sie ein typisches Crash-Szenario.
Zunächst wird die erste Kaufposition eröffnet. Dann beginnt der Markt eine stetige Abwärtsbewegung. Der EA fügt Positionen hinzu, indem er die Losgrößen exponentiell erhöht. Nach mehreren Stufen der Mittelwertbildung wird die Positionsgröße so groß, dass selbst eine kleine weitere Bewegung zu einem Margin Call führt.
Mathematisch lässt sich dieses Problem wie folgt ausdrücken: Bei einer Martingale-Strategie mit einem Multiplikationsfaktor von 1,5 und einer anfänglichen Losgröße von 0,01 wird die zehnte aufeinanderfolgende Position eine Größe von etwa 0,57 Lots haben, was 57 Mal größer ist als die erste. Die Gesamtgröße aller offenen Positionen wird etwa 1,1 Losgrößen betragen, was bei einem Konto von 1.000 $ und einem Hebel von 1:100 bedeutet, dass fast die gesamte verfügbare Marge verwendet wird.
// Calculation of total size of martingale positions double totalVolume = 0; double currentLot = StartLot; for(int i = 0; i < MaxPositions; i++) { totalVolume += currentLot; currentLot *= LotMultiplier; } // At StartLot = 0.01 and LotMultiplier = 1.5 after 10 positions // totalVolume will be about 1.1 lots!
Das Hauptproblem war das Fehlen eines Mechanismus, mit dem bestimmt werden konnte, wann die Mittelwertbildung eingestellt werden sollte. Ilan war wie ein Glücksspieler, der nicht weiß, wann er aufhören soll und immer mehr setzt, in der Hoffnung, wieder zu gewinnen.
Warum Ilan KI braucht
Analysiert man die Stärken und Schwächen von Ilan, so wird deutlich, dass sein Hauptproblem die Unfähigkeit zu lernen und sich anzupassen ist. Der Expert Advisor folgt denselben Regeln, unabhängig davon, wie erfolgreich oder desaströs seine vorherigen Aktionen waren.
Hier kommt die künstliche Intelligenz ins Spiel. Wie wäre es, wenn wir den grundlegenden Mechanismus des Ilan-Betriebs beibehalten, ihn aber um eine Funktion zur Analyse der Ergebnisse seiner Aktionen und zur Anpassung der Strategie ergänzen? Was wäre, wenn wir das Modell anstelle von fest kodierten Regeln selbständig optimale Parameter und Einstiegspunkte auf der Grundlage der gesammelten Erfahrungen finden ließen?
Diese Idee steht im Mittelpunkt unseres KI-Projekts Ilan 3.0, bei dem wir eine bewährte Mittelwertbildungsstrategie mit fortschrittlichen Methoden des maschinellen Lernens kombinieren. Im nächsten Abschnitt wird untersucht, wie die Q-Learning-Technologie dieses Konzept in die Tat umsetzen kann.
Wie Q-Learning Ilan Expert Advisor verbessern wird
Der Übergang vom klassischen Ilan-Modell zu einem intelligenten, lernfähigen System erfordert eine grundlegende Änderung der Architektur des EAs. Der Q-Learning-Algorithmus wird zum Herzstück von Ilan 3.0 KI. Sie ist eine der wichtigsten Technologien im Bereich des verstärkten Lernens.
Die Grundlagen des Q-Learnings auf der Grundlage Ihrer Handlungen
Das Q-Learning hat seinen Namen von der „Qualitätsfunktion“, die den Wert einer Handlung unter einer bestimmten Bedingung bestimmt. In unserer Implementierung verwenden wir eine Q-Tabelle, eine Datenstruktur, die Bewertungen für jedes Paar „Zustand-Aktion“ speichert:
// Structure for Q-table struct QEntry { string state; // Discretized state of market int action; // Action (0-nothing, 1-buy, 2-sell) double value; // Q-value }; // Global array for Q-table QEntry QTable[]; int QTableSize = 0;Ein wesentliches Merkmal des Q-Learnings ist die Fähigkeit des Systems, aus seinen eigenen Erfahrungen zu lernen. Nach jeder Aktion erhält der Algorithmus eine Belohnung (bei Gewinn) oder eine Strafe (bei Verlust) und passt seine Einschätzung des Wertes dieser Aktion in einer bestimmten Marktsituation an:
// Updating Q-value using Bellman formula void UpdateQValue(string stateStr, int action, double reward, string nextStateStr, bool done) { double currentQ = GetQValue(stateStr, action); double nextMaxQ = 0; if(!done) { // Find maximum Q for following state nextMaxQ = GetMaxQValue(nextStateStr); } // Updating Q-value double newQ = currentQ + LearningRate * (reward + DiscountFactor * nextMaxQ - currentQ); // Saving updated value SetQValue(stateStr, action, newQ); }
Diese Formel, die so genannte Bellman-Gleichung, ist der Eckpfeiler unseres Ansatzes. Der Parameter LearningRate legt die Lernrate fest, und DiscountFactor bestimmt die Bedeutung zukünftiger Belohnungen im Vergleich zu aktuellen.
Ein Gleichgewicht zwischen der Suche nach neuen Lösungen und der Nutzung von Erfahrungen
Eine der größten Herausforderungen beim Reinforcement Learning ist die Notwendigkeit, ein Gleichgewicht zwischen der Erforschung neuer Strategien und der Nutzung bereits bekannter optimaler Lösungen zu finden. Um dieses Problem zu lösen, verwenden wir die Strategie ε-greedy:
// Choosing action with balance between exploration and exploiting int SelectAction(string stateStr) { // With epsilon probability choose random action (research) if(MathRand() / (double)32767 < currentEpsilon) { return MathRand() % ActionCount; } // Otherwise, choose action with maximum Q-value (exploiting) int bestAction = 0; double maxQ = GetQValue(stateStr, 0); for(int a = 1; a < ActionCount; a++) { double q = GetQValue(stateStr, a); if(q > maxQ) { maxQ = q; bestAction = a; } } return bestAction; }Der Parameter currentEpsilon bestimmt die Wahrscheinlichkeit einer zufälligen Wahl der Aktion. Mit der Zeit nimmt sein Wert ab, sodass das System von der aktiven Forschung zur bevorzugten Nutzung des angesammelten Wissens übergehen kann:
// Reducing epsilon for a gradual transition from exploration to exploiting if(currentEpsilon > MinExplorationRate) currentEpsilon *= ExplorationDecay;
Digitales Sinnesorgan: Wie der Algorithmus den Markt wahrnimmt
Um einen Algorithmus effektiv zu trainieren, muss er den Markt „sehen“, d.h. eine formalisierte Vorstellung von der aktuellen Situation haben. In Ilan 3.0 KI verwenden wir einen umfassenden Zustandsvektor, der technische Indikatoren, Metriken zu offenen Positionen und andere Marktdaten enthält:
// Getting current market state for Q-learning void GetCurrentState(string symbol, double &state[]) { ArrayResize(state, StateDimension); // Technical indicators double rsi = iRSI(symbol, PERIOD_CURRENT, RSI_Period, PRICE_CLOSE, 0); double cci = iCCI(symbol, PERIOD_CURRENT, CCI_Period, PRICE_TYPICAL, 0); double macd = iMACD(symbol, PERIOD_CURRENT, 12, 26, 9, PRICE_CLOSE, MODE_MAIN, 0); // Normalization of indicators double normalized_rsi = rsi / 100.0; double normalized_cci = (cci + 500) / 1000.0; // Metrics of positions int positions = (symbol == "EURUSD") ? euroUsdPositions : audUsdPositions; double normalized_positions = (double)positions / MaxTrades; // Calculating price difference double point = SymbolInfoDouble(symbol, SYMBOL_POINT); double currentBid = SymbolInfoDouble(symbol, SYMBOL_BID); double avgPrice = CalculateAveragePrice(symbol); double price_diff = (currentBid - avgPrice) / (100 * point); // Filling in state vector state[0] = normalized_rsi; state[1] = normalized_cci; state[2] = normalized_positions; state[3] = price_diff; state[4] = macd / (100 * point); state[5] = AccountInfoDouble(ACCOUNT_EQUITY) / AccountInfoDouble(ACCOUNT_BALANCE); }Um mit der Q-Tabelle arbeiten zu können, müssen kontinuierliche Zustandswerte diskretisiert werden, d. h. in eine Zeichenkettendarstellung mit einer endlichen Anzahl von Optionen umgewandelt werden:
// Converting state to string for Q-table string StateToString(double &state[]) { string stateStr = ""; for(int i = 0; i < ArraySize(state); i++) { // Rounding to 2 decimal places for discretization double discretized = MathRound(state[i] * 100) / 100.0; stateStr += DoubleToString(discretized, 2); if(i < ArraySize(state) - 1) stateStr += ","; } return stateStr; }
Dieser Diskretisierungsprozess ermöglicht es dem System, Erfahrungen zu verallgemeinern, indem es sie auf ähnliche, aber nicht identische Marktsituationen anwendet.
Anreizsystem: Zuckerbrot und Peitsche in der KI-WeltDie richtige Definition eines Belohnungsansatzes ist wahrscheinlich der kritischste Aspekt beim Aufbau eines effektiven Verstärkungslernsystems. In Ilan 3.0 KI haben wir ein mehrstufiges Anreizsystem entwickelt, das die Algorithmenentwicklung in die richtige Richtung lenkt.
Wirtschaftliche Aspekte von Auszeichnungen: Wie man den Algorithmus motiviert
Wenn Positionen mit Gewinn geschlossen werden, erhält das Modell eine positive Belohnung, die proportional zur Höhe des Gewinns ist:
// Reward at closing profitable positions if(shouldClose) { if(ClosePositions(symbol, magic)) { if(isTraining) { double reward = profit; // Reward is equal to profit UpdateQValue(stateStr, action, reward, stateStr, true); // Learning statistics episodeCount++; totalReward += reward; Print(“Episode ", episodeCount, " completed with reward: ", reward, ". Average reward: ", totalReward / episodeCount); } } }Bei der Durchschnittsbildung von Verlustpositionen erhält das System eine kleine Strafe, die es dazu anregt, nach optimalen Einstiegspunkten zu suchen und Situationen zu vermeiden, die eine Durchschnittsbildung erfordern:
// Penalty at averaging positions if(OpenPosition(symbol, ORDER_TYPE_BUY, CalculateLot(positionsCount, symbol), StopLoss, TakeProfit, magic)) { if(isTraining) { double reward = -1; // Small penalty for averaging UpdateQValue(stateStr, action, reward, stateStr, false); } }
Das Fehlen einer unmittelbaren Belohnung bei der Eröffnung der ersten Position zwingt das System, sich auf langfristige Ergebnisse und nicht auf kurzfristige Aktionen zu konzentrieren.
Feinabstimmung des Modells
Die Wirksamkeit des Q-Learning-Systems hängt stark von der korrekten Einstellung seiner Schlüsselparameter ab. In Ilan 3.0 KI bieten wir eine Funktion zur Feinabstimmung aller Aspekte des Lernens:
// Reinforcement learning parameters input double LearningRate = 0.01; // Learning rate input double DiscountFactor = 0.95; // Discount factor input double ExplorationRate = 0.3; // Initial probability of exploration input double ExplorationDecay = 0.995; // Exploration reduction factor input double MinExplorationRate = 0.01;// Minimal probability of exploration
LearningRate bestimmt die Aktualisierungsrate der Q-Werte. Hohe Werte führen zu schnellem Lernen, können aber auch zu Instabilität führen. Niedrige Werte sorgen für stabiles, aber langsames Lernen.
DiscountFactor bestimmt die Bedeutung zukünftiger Belohnungen. Werte, die näher bei 1 liegen, zwingen das Modell dazu, eine langfristige Gewinnmaximierung anzustreben, was manchmal zu Lasten des unmittelbaren Gewinns geht.
Die Forschungsparameter steuern das Gleichgewicht zwischen der Suche nach neuen Strategien und der Ausnutzung bekannter optimaler Lösungen. Im Laufe der Zeit sinkt die Wahrscheinlichkeit von Nachforschungen, sodass sich das System mehr und mehr auf gesammelte Erfahrungen stützen kann.
Von der Theorie zur Praxis: Umsetzung
Die Implementierung von Ilan 3.0 KI erfordert die Integration von Q-Learning-Mechanismen in die traditionelle Logik eines Trading Expert Advisors. Die Schlüsselkomponente ist die Handelsmanagementfunktion, die Q-Learning zur Entscheidungsfindung einsetzt:// Trade management function using Q-learning void ManagePairWithDQN(string symbol, int &positionsCount, CArrayDouble &trades, int magic, datetime &firstTradeTime) { // Getting current market data double currentBid = SymbolInfoDouble(symbol, SYMBOL_BID); double currentAsk = SymbolInfoDouble(symbol, SYMBOL_ASK); double point = SymbolInfoDouble(symbol, SYMBOL_POINT); // Forming current state double state[]; GetCurrentState(symbol, state); string stateStr = StateToString(state); // Selecting action using Q-table int action = SelectAction(stateStr); // Converting action into trading operation bool shouldTrade = (action > 0); ENUM_ORDER_TYPE orderType = (action == 1) ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; // Logic of opening and managing positions if(shouldTrade) { // Logic of opening first position or averaging // ... } // Checking need to close positions double profit = CalculatePositionsPnL(symbol, magic); if(profit > 0 && positionsCount > 0) { // Logic of closing profitable positions // ... } }
Erfahrung mit dem System speichern
Um die gesammelten Erfahrungen zu speichern, haben wir einen Mechanismus zum Speichern und Laden der Q-Tabelle zwischen den Sitzungen eingeführt:
// Saving Q-table to file bool SaveQTable(string filename) { int handle = FileOpen(filename, FILE_WRITE|FILE_BIN); if(handle == INVALID_HANDLE) { Print("Error when opening file for writing Q-table: ", GetLastError()); return false; } // Writing table size FileWriteInteger(handle, QTableSize); // Writing values for(int i = 0; i < QTableSize; i++) { FileWriteString(handle, QTable[i].state); FileWriteInteger(handle, QTable[i].action); FileWriteDouble(handle, QTable[i].value); } FileClose(handle); return true; } // Downloading Q-table from file bool LoadQTable(string filename) { if(!FileIsExist(filename)) { Print("Q-table file does not exist: ", filename); return false; } int handle = FileOpen(filename, FILE_READ|FILE_BIN); if(handle == INVALID_HANDLE) { Print("Error when opening file to read Q-table: ", GetLastError()); return false; } // Reading table size int size = FileReadInteger(handle); // Allocating memory for table if(size > ArraySize(QTable)) { ArrayResize(QTable, size); } // Reading values for(int i = 0; i < size; i++) { QTable[i].state = FileReadString(handle); QTable[i].action = FileReadInteger(handle); QTable[i].value = FileReadDouble(handle); QTableSize++; } FileClose(handle); return true; }
Schauen wir uns den Test dieses Expertenberaters an. Der Test wurde mithilfe der OHLC-Modellierung auf einem 15-Minuten-Chart für die Paare AUDUSD und EURUSD für 2020-2025 durchgeführt (das Hauptsymbol ist EURUSD, aber der Expert Advisor lädt auch AUDUSD).
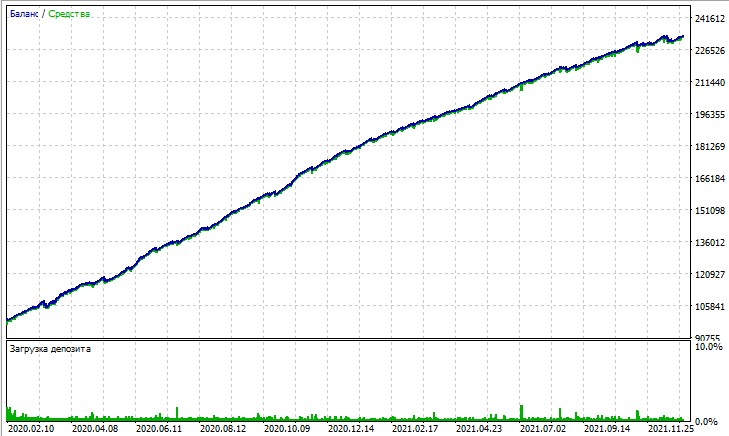
Aber der Test mit „allen Ticks“ hebt gnadenlos die großen Drawdowns hervor, die durch das Martingale auftreten. Trotz der Strafen fällt das Modell manchmal in eine Reihe von Durchschnittsgeschäften. Vielleicht werden wir in zukünftigen Versionen die Drawdowns mit Hilfe des DQN-Risikomanagements entfernen:
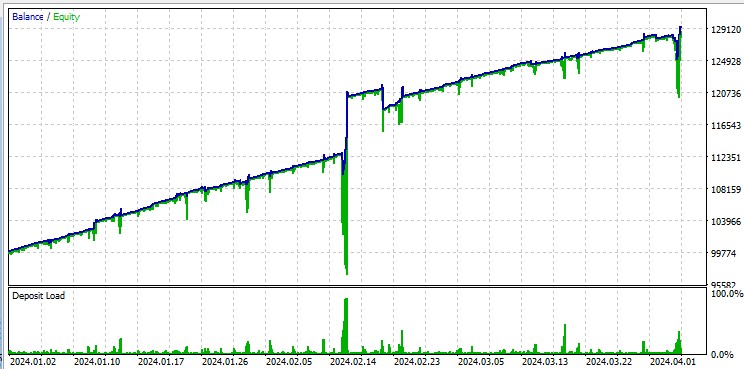
Es sollte auch beachtet werden, dass der Roboter mit großen Losgrößen handelt, was nützlich ist, um vom Broker einen Rabatte pro Umsatz zu erhalten.
Möglichkeiten zur Verbesserung des Algorithmus
Trotz erheblicher Verbesserungen stellt Ilan 3.0 KI nur den ersten Schritt in der Entwicklung intelligenter Handelssysteme dar. Zu den vielversprechenden Bereichen für die weitere Entwicklung gehören:
- Das Ersetzen der Q-Tabelle durch ein vollwertiges neuronales Netz für eine bessere Verallgemeinerung von Erfahrungen.
- Die Implementierung von Deep Reinforcement Learning (DQN, DDPG, PPO) Algorithmen.
- Der Einsatz von Meta-Learning-Techniken zur schnellen Anpassung an neue Marktbedingungen.
- Die Integration mit Architekturen zur Analyse von Nachrichten und Fundamentaldaten.
Schlussfolgerung
Die Implementierung von Ilan 3.0 KI zeigt einen grundlegenden Wandel im Ansatz des algorithmischen Handels. Wir bewegen uns von statischen, auf festen Regeln basierenden Systemen zu adaptiven Algorithmen, die lernfähig sind und sich weiterentwickeln.
Die Integration der klassischen Ilan-Strategie mit modernen Methoden des maschinellen Lernens eröffnet neue Horizonte in der Entwicklung von Handelssystemen. Anstelle einer endlosen Parameteroptimierung implementieren wir Systeme, die in der Lage sind, selbstständig optimale Strategien zu finden und sich an veränderte Marktbedingungen anzupassen.
Die Zukunft des algorithmischen Handels liegt in hybriden Ansätzen, die bewährte Handelsstrategien mit innovativen Techniken der künstlichen Intelligenz kombinieren. Ilan 3.0 KI ist nicht nur eine verbesserte Version des klassischen Expert Advisors, sondern eine grundlegend neue Klasse von intelligenten Handelssystemen, die in der Lage sind, gemeinsam mit dem Markt zu lernen, sich anzupassen und weiterzuentwickeln.
Wir stehen an der Schwelle zu einer neuen Ära des algorithmischen Handels - einer Ära von Modellen, die nicht nur festen Regeln folgen, sondern sich ständig weiterentwickeln und optimale Strategien in der sich ständig verändernden Welt der Finanzmärkte finden.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17455
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich habe es kurz gelesen - auf den ersten Blick ist der Artikel super!
es ist notwendig, auf verschiedene Symbole zu achten und zu testen - welche sind besser und welche sind schlechter, um von ilano trainiert zu werden!
Martin hat eine Menge zu verdanken.
Es wird interessant sein, ein fortschrittliches Produkt mit einer Entwicklungsperspektive zu erhalten.
Hallo Yevgeniy,
wo ist der Code von CalculateAveragePrice(symbol) ?
und auch, wie kann ich SL und TP eines Durchschnittspreises zwischen 2 oder mehr Positionen vorberechnen?
Vielen Dank, Sabino.