
Simulación de mercado (Parte 20): Iniciando el SQL (III)

Introducción
Hola a todos y sean bienvenidos a un artículo más de la serie sobre cómo construir un sistema de repetición/simulación.
En este artículo, empezaremos a tratar un tema que, al mismo tiempo, es espinoso. Pero, si tú logras entender lo que veremos a partir de aquí, podrás avanzar mucho en tu carrera. No será un tema sencillo. Aun así, intentaré presentarlo de la forma más simple posible para que se entienda y se asimile.
Preparando el escenario
En el artículo anterior, Simulación de mercado (Parte 19): Iniciando el SQL (II), expliqué cómo tú puedes, usando scripts, agregar, modificar e incluso eliminar registros en una base de datos. Sin embargo, para avanzar en la explicación, necesitamos una base de datos con un mínimo de elementos. Así tú podrás entender realmente lo que se explicará.
Aunque podemos trabajar con una base de datos de unas 10 entradas, esto se entiende mejor cuando usamos un archivo con más de 15 mil registros. Es decir, si tú intentaras crear eso manualmente, sería una tarea enorme. Sin embargo, es difícil encontrar una base de datos, incluso con fines didácticos, disponible para descargar. Pero no hace falta: podemos usar MetaTrader 5 para generarla. Puede que no sea perfecta, pero al menos tendrá muchos registros, y eso es lo que realmente necesitamos.
Para entender cómo haremos esto, es decir, usar MetaTrader 5 para producir una base de datos y así estudiar el siguiente tema, tenemos que retroceder un poco en el tiempo.
Hay personas, e incluso organizaciones pequeñas, que usan Excel como si fuera una base de datos. Muchos de ustedes quizá no lo crean, o ni siquiera se hayan dado cuenta de que esto ocurre. Y no es solo Excel: hay otros programas que también se usan así. Pero, por ahora, nos limitaremos a Excel. Cuando tú usas Excel para manipular una base de datos, aparece una opción en la cinta de opciones. En la imagen de abajo, tú puedes ver a qué me refiero.

Para que esta pestaña llegue a aparecer, necesitamos hacer algunas cosas. Una de ellas, y quizá la más simple, es abrir un archivo que tenga un formato o una estructura determinados. Esto se hace desde el lugar que se muestra en la imagen de abajo.
Recuerda que estoy mostrando una forma, pero no es la única. Ahora viene la pregunta: ¿qué tipo de archivo pretendo usar aquí? Tú, muy probablemente, usarás diversos tipos de archivos. Y, cuando digo esto, me refiero a que la estructura interna del archivo puede ser cualquiera. Pero, para facilitar y, sobre todo, para que tú entiendas a dónde quiero llegar, vayamos a MetaTrader 5. En la imagen de abajo, vemos a dónde quiero llegar.
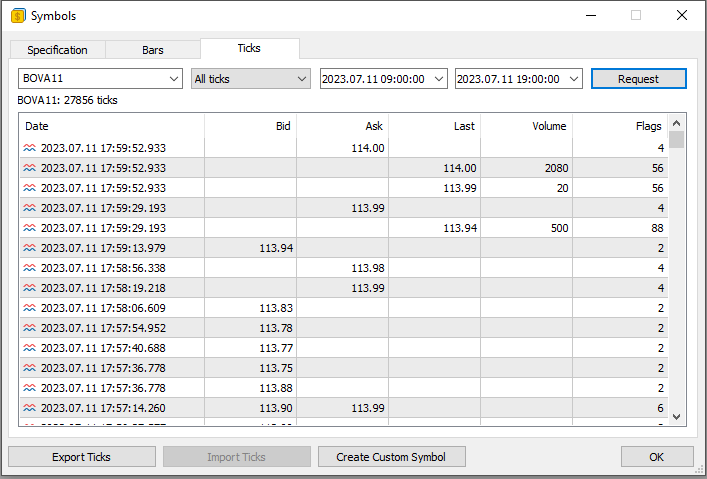
Observa que aquí hicimos la solicitud al servidor de trading para obtener todos los ticks negociados en un día determinado, para un símbolo específico. Lo que se muestra en la imagen de arriba es, justamente, un conjunto de información proveniente de una base de datos. Sin embargo, en esta ventana tú no puedes manipular los datos como sí es posible cuando usamos un programa adecuado para ello. Aun así, tú podrías exportar esa información a un archivo. Este puede tener el formato CSV.
Una vez que este archivo esté guardado en un disco local, tú podrás, de hecho, usarlo en un programa que manipule archivos de bases de datos. Pero, y es importante que entiendas esto, antes de manipular realmente el contenido del archivo e interpretarlo como una tabla de datos, necesitamos convertirlo en una base de datos. Y es en este punto donde está la magia del proceso. Y es exactamente a donde quiero llegar.
El primer contacto fuera de una WorkBench
Entonces, una vez que tú hayas guardado en un archivo la información que se ve en la imagen de arriba, podrás, en un primer momento, cargarla en Excel. El resultado es que Excel ya no tratará el archivo como tú, posiblemente, estás imaginando. Excel, de hecho, convertirá el archivo en un equivalente a una base de datos. Así, la interfaz de Excel cambiará y quedará como se muestra abajo.
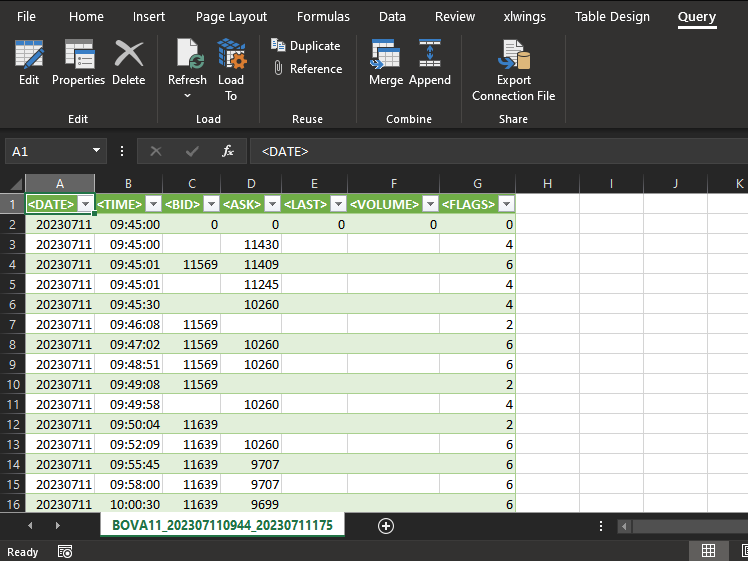
Bien. Tú puedes pensar que aquí podrás trabajar de la misma forma que trabajarías si usaras comandos en SQL. En realidad, no funciona exactamente así cuando tú usas Excel u otro programa que te permite cierto acceso a una base de datos. Aunque, de hecho, podrás hacer varias cosas aquí, la experiencia no será ni de cerca la misma que cuando se usa SQL puro. Entonces, olvidemos Excel y vayamos en otra dirección. Esto, para que podamos entender el comando que se explicará.
Usando MetaEditor para investigar la base de datos
Muy probablemente tú estés imaginando que tenemos un gran problema entre manos, ya que, en muchos casos, el archivo descargado por MetaTrader 5 y guardado como CSV puede tener varios megabytes. Y convertir algo así en algo aceptable, para poder usar búsquedas SQL en esos datos descargados, parece muy complicado, y solo sería posible para grandes gurús o maestros de la computación. Sin embargo, la verdad es que, si tú no entiendes las herramientas que tienes en tus manos, siempre tendrás un problema por resolver, incluso cuando la solución esté frente a ti.
Así, la forma más simple, y sin usar ninguna programación, de convertir todos esos datos descargados por MetaTrader 5 en algo más agradable es usando MetaEditor. Esto, de hecho, convertirá el archivo CSV descargado en un verdadero archivo de base de datos. Pero, ¿cómo? ¿Cómo puedo convertir un archivo CSV guardado por MetaTrader 5 en un archivo de base de datos usando, para eso, MetaEditor? Parece algo extremadamente complicado. No es tan complicado así, mi querido lector. Todo es cuestión de entender la herramienta que tú tienes en las manos.
Primero, haz lo siguiente: empecemos creando una base de datos nueva y completamente limpia. Ya expliqué cómo hacer esto usando MetaEditor. Una vez creado este archivo de base de datos, tú necesitarás seguir los pasos siguientes.
Primero, selecciona la opción indicada en la imagen de abajo:
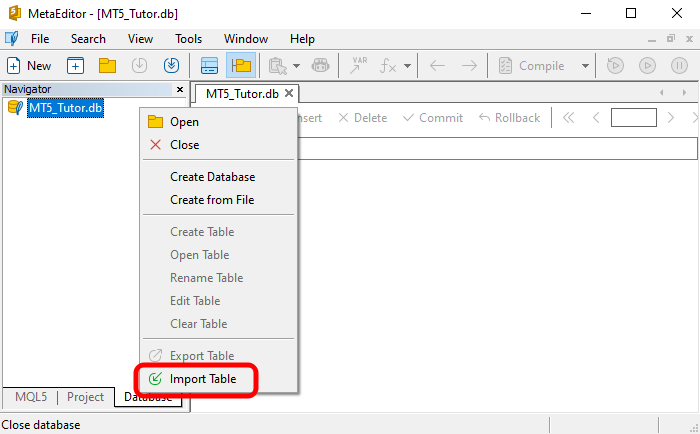
Esta opción te permite importar una tabla dentro de la base de datos. Recuerda que una tabla es un conjunto de registros. Y, como el archivo CSV es un conjunto de registros, lo importaremos como si fuera una tabla. Una vez que tú hayas seleccionado la opción indicada, se te dirigirá a una ventana cuyo objetivo es configurar cómo MetaEditor importará los datos, creando así la tabla final. Tú puedes ver esta ventana en la imagen de abajo.
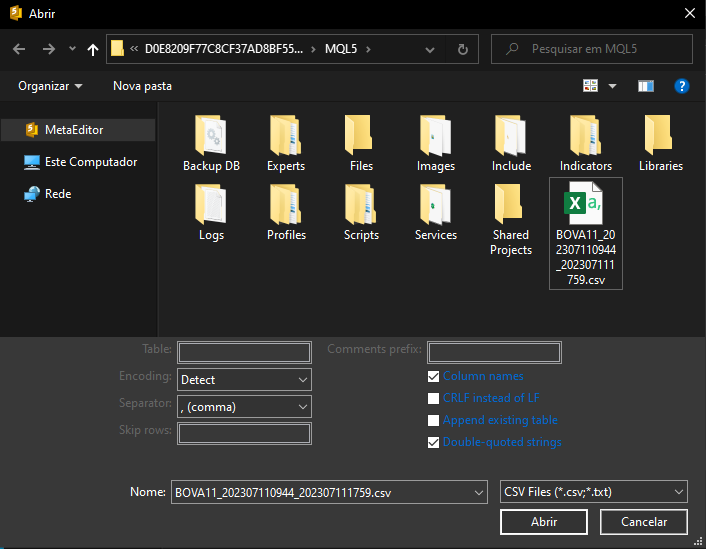
Para simplificar al máximo, coloqué el archivo CSV dentro del directorio de MQL5. Pero, al final, lo que importa es que tú selecciones el archivo correcto. Sin embargo, si tú simplemente seleccionas el archivo, como se muestra en la imagen de arriba, y, enseguida haces clic en el botón ABRIR, MetaEditor no mostrará ninguna respuesta. Esto se debe a que tú solo seleccionaste el archivo, pero todavía no lo importaste. Es necesario hacer algunas configuraciones adicionales en esa misma ventana. Cada una de las configuraciones depende de cada caso. No existe una regla fija.
Tú necesitas entender, al menos de forma básica, qué contiene el archivo que se va a importar. No sirve de nada que tú simplemente abras MetaEditor, pidas importar los datos y esperes que MetaEditor entienda lo que el archivo contiene. Las cosas no funcionan así. Entonces, lo primero que tú necesitas configurar es el separador de la información. Recuerda que esos datos fueron descargados por MetaTrader 5. Y, si tú no cambiaste el formato del archivo, el separador utilizado es el carácter de tabulación. Así que, al cambiar esa información, obtenemos la imagen de abajo.
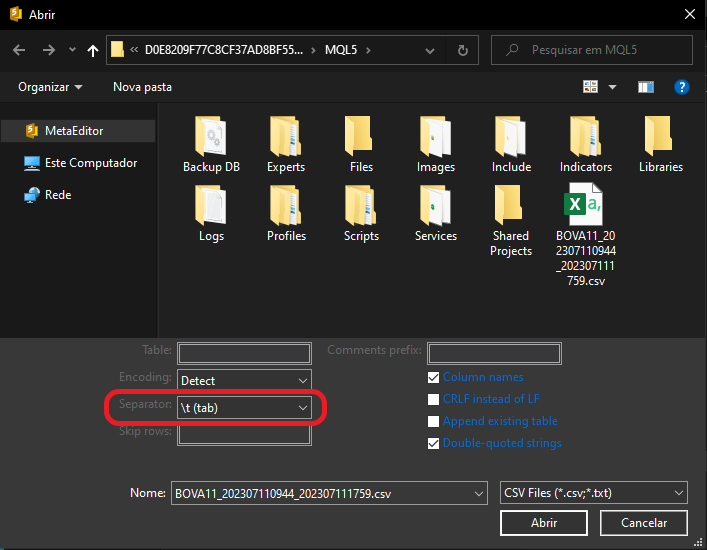
Muy bien, este es el primer punto que hay que configurar. Ahora tenemos un punto más, considerando que tú solo descargaste el archivo y lo estás importando aquí en MetaEditor. El punto en cuestión es el nombre de la tabla que se usará. Ahora es el momento en que muchos pueden quedar bastante confundidos, porque, en MetaEditor, no tenemos ninguna tabla incluida en la base de datos. Tú puedes ver esto mirando las imágenes de arriba, donde, en el momento en que pedimos importar el archivo, no existe ninguna tabla indicada.
Pero, entonces, ¿qué tipo de información debemos poner como nombre de la tabla? Tú simplemente debes indicar el nombre que tendrá la tabla cuando sea creada. Por eso te dije que usaras un archivo totalmente limpio. Así este paso quedaría más claro. Entonces, vamos a informar un nombre para el campo, como se muestra en la imagen de abajo.
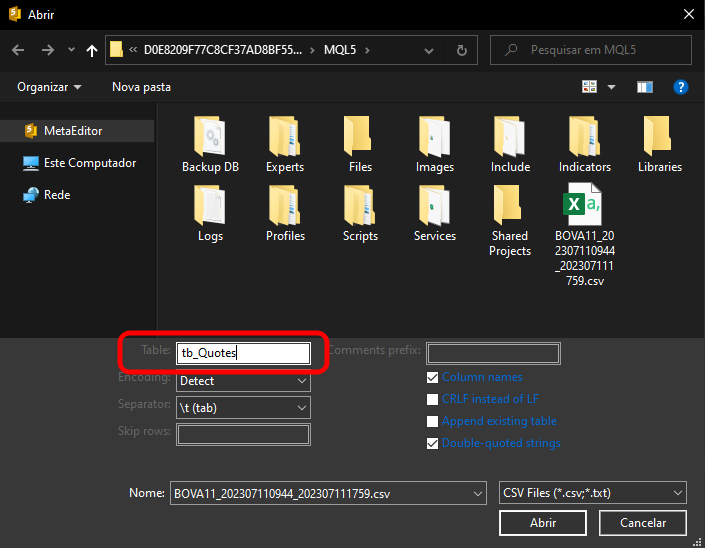
Tú puedes poner el nombre que quieras. Una vez hecho esto, podrás hacer clic en el botón ABRIR. Recuerda, una vez más, que, dependiendo del contenido del archivo que se va a importar, tú necesitarás ajustar más opciones aquí. Sin embargo, como acabamos de descargar el archivo con MetaTrader 5 y lo estamos importando usando MetaEditor, estos pasos ya serán suficientes para nuestro propósito.
En el momento en que tú hagas clic en ABRIR, deberás olvidarte por completo de todo lo que quizá ya hayas visto al usar este mismo archivo en Excel, porque aquí será completamente diferente a todo lo que tú hayas visto antes de leer estos artículos sobre bases de datos. Entonces, al mirar la pantalla de MetaEditor, tú verás, inicialmente, la siguiente imagen.
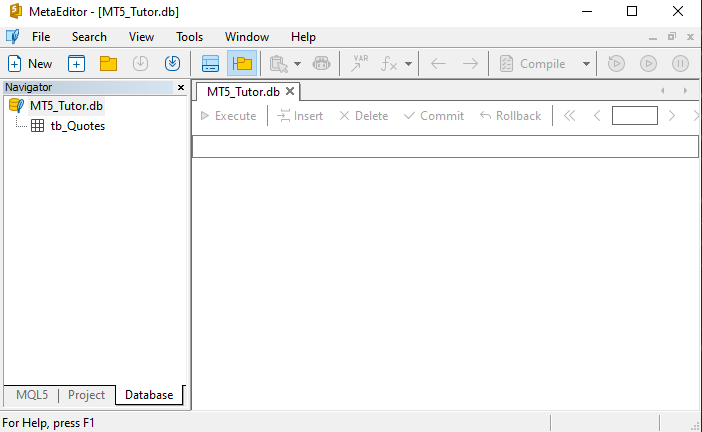
Perfecto. Si tú estás viendo esto, significa que MetaEditor transformó el archivo CSV en una tabla dentro de la base de datos llamada MT5_Tutor.db. Muy probablemente, en este momento, tú estés bastante confundido y no entiendas absolutamente nada de lo que está pasando, o de lo que acaba de pasar. Pero vamos a entenderlo, porque el concepto es importante.
Toda aquella información que fue descargada por MetaTrader 5, cuando tú le solicitaste al servidor datos de un símbolo en una fecha determinada, ahora ya no es más ese desorden de datos y más datos. Todo eso fue organizado y convertido en una tabla. Esta tabla contiene, en su encabezado, el mismo encabezado que existía en el archivo CSV. Así que, si tú quieres que las columnas dentro de tu base de datos tengan otro nombre, basta con que, antes de importar los datos del CSV, edites la primera, y solo la primera, línea, para que las columnas tengan otro nombre.
Pero solo haz esto si tú realmente entiendes lo que estás haciendo, porque, si haces una tontería, puedes terminar con una base de datos completamente inútil. Aun si esos nombres no te agradan, tú podrás cambiarlos usando un comando de SQL, ya que ahora ya no estarás tratando con un archivo CSV, sino con una base de datos.
Todo esto está muy bien. Pero, ¿cómo hago para acceder a la información dentro de esa base de datos? Yo pensé que sería algo parecido a Excel o a algún otro programa de hojas de cálculo. Pero esto que estoy viendo en MetaEditor, para mí, es completamente inútil y no tiene ningún valor.
Bien, si tú estás pensando eso, mi querido lector, es porque tú no tienes idea de lo poderoso que es una base de datos, y saber hacer cosas dentro de ella exige estudio y dedicación. Pero no quiero ofenderte ni menospreciarte, mi querido lector. Sé que muchos, al ver la imagen de arriba, se quedarían completamente frustrados, imaginando que verían un escenario mágico, lleno de cosas interesantes. Pero, visto así, esto parece tan sin sentido y sin propósito, que difícilmente tú te interesarías en estudiar y profundizar en SQL.
Pero déjame intentar cambiar un poco tu visión sobre SQL. Ahora, por fin, vamos a ver uno de los comandos que, con toda certeza, será el que más te exigirá estudio. Pero, para separar las cosas, veamos esto en un nuevo tema.
Finalmente el comando SELECT
Este comando SELECT, en su forma más básica, tiene la siguiente sintaxis.
SELECT * FROM table;
Observa que es exactamente el mismo comando que se está usando en la animación de abajo.
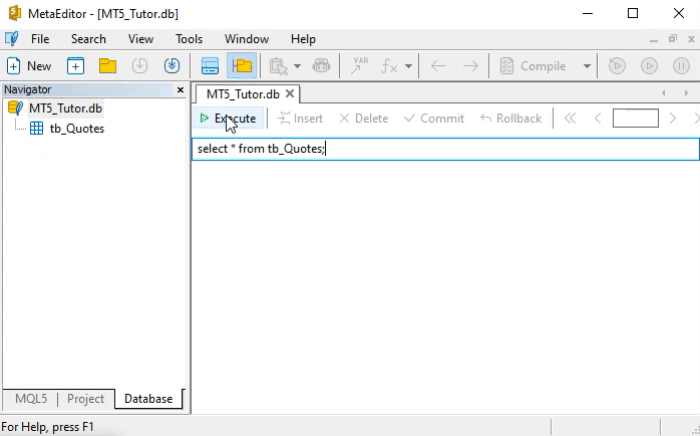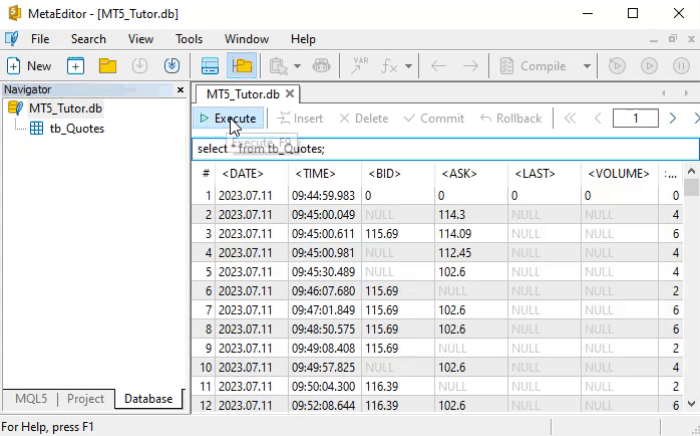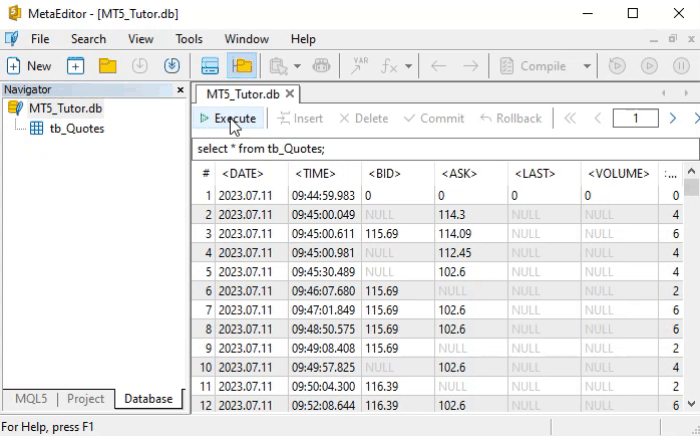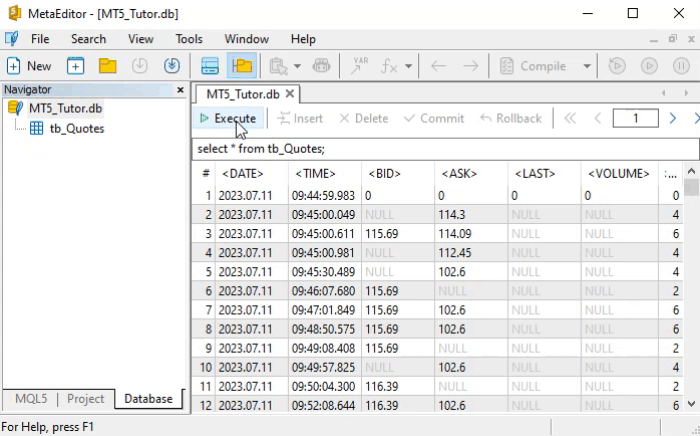
Pero, ¿cómo interpretar este comando SELECT? Interpretarlo es lo más simple. Y no solo este: todos los comandos en SQL fueron pensados con inteligencia para que su sintaxis se asimile con facilidad. Para que tú entiendas y también percibas lo que acabo de decir, veamos cómo leer el comando de arriba.
Debes leerlo de la siguiente manera: selecciona todos los datos cuyo origen es la tabla llamada table. Esta es la forma literal de leer este comando. Si tú, de hecho, entendiste cómo leerlo, ya debes estar imaginando que podemos hacer cosas bastante interesantes. Aquí te estoy dando el ejemplo de lectura literal, pero intenta hacer lo mismo con otros comandos de SQL. Pronto notarás que tu velocidad para asimilarlos será bastante alta, porque es muy simple recordar o entender cada uno de los comandos.
Pero, volviendo a lo que nos interesa en este momento, observa el resultado de la animación. Allí tenemos una cantidad bastante grande de registros siendo devueltos. Este tipo de cosa es justamente lo que yo quería que ocurriera. Esto se debe a que, si tú usas el comando SELECT en una tabla con pocos registros, vas a pensar que no tiene sentido usar SQL. Sin embargo, cuando la cantidad de registros es bastante grande, tú puedes interesarte más en aprender la programación en SQL.
¿Cuál es el problema real que tenemos aquí? El problema es la cantidad de información que se está devolviendo. Pero, si tú entendiste cómo leer de forma literal el comando SELECT, ya debes estar pensando en una manera de reducir la cantidad de datos, haciendo algún tipo de filtrado. Bien, si tú empezaste a pensar así, ya es una buena señal, Y más aún si pensaste en sustituir el asterisco por otra cosa, ya que el asterisco sería un valor comodín. Quien usa una consola de comandos sabe de qué estoy hablando. Sin embargo, sin querer desanimarte, si pensaste como acabo de decir, no vas por mal camino. Al contrario, vas por el camino correcto, solo necesitas, de alguna manera, ser guiado para hacer las cosas de una forma más adecuada.
Pero pensemos un poco. Si tú fueras a sustituir el asterisco del comando, ¿por qué deberías sustituirlo para poder filtrar los resultados que devolverá SQL? Esta es la misma pregunta que los diseñadores del lenguaje SQL tuvieron que responder cuando SQL todavía se estaba desarrollando. Piensa un poco y dime: ¿cómo harías ese filtrado, teniendo una verdadera montaña de datos y muchas columnas?
Pero, antes de explicar cómo los diseñadores y desarrolladores resolvieron brillantemente esta cuestión, quiero llamar tu atención sobre otro detalle que está presente aquí en MetaEditor. Esto se debe a que este detalle puede ser importante en algún momento futuro. Observa la imagen de abajo.

Fíjate que estoy destacando una región de la imagen. El motivo es que, si tú miras la esquina derecha de la región resaltada, notarás que se cargó una cantidad de registros. En algunos momentos, puede ser necesario que tú navegues entre esos registros para observar los datos encontrados, esto cuando ya estemos haciendo un filtrado un poco más selectivo. Al hacer clic en las flechitas dentro del área marcada, tú puedes ir al siguiente bloque de registros cargados. Observa que los bloques se cargan en incrementos de mil en mil.
Entonces, el valor indicado en la región marcada representa mil bloques. Así que, si tú deseas ir al bloque de ocho mil, bastará con cambiar el valor de uno a nueve, y se cargará el bloque ocho mil para mostrarse en MetaEditor. Pero, ¿por qué nueve? ¿El valor no debería ser ocho? El motivo es que el conteo se hace a partir del valor uno. Sin embargo, el valor uno indica que el bloque terminará en el valor mil. Al principio parece un poco confuso, pero, con un poco de uso, tú pronto entenderás la lógica.
Intenta interactuar un poco con esta interfaz de MetaEditor, para entender realmente cómo hacer las cosas aquí, ya que me parece bastante más ligera que una WorkBench. Aun así, podemos hacer algunas cosas sin necesidad de recurrir a una WorkBench más robusta, sobre todo cuando solo estamos investigando dentro de una base de datos.
Muy bien. Ahora volvamos a nuestra cuestión de cómo filtrar los resultados de la búsqueda. Tal vez tú todavía estés dándole vueltas para pensar en una solución que sea fácil de asimilar. Pero la solución que desarrollaron los diseñadores es, en mi opinión, la mejor propuesta que se podría hacer. Ese asterisco podrá cambiarse por otra cosa. Te mostraré esto en otro momento. Pero, para filtrar la búsqueda, los desarrolladores añadieron otra cosa al comando SELECT. Sin embargo, aquí tenemos un pequeño truco que, dependiendo de qué tú deseas buscar y cómo lo harás, hará que el comando SELECT quede ligeramente diferente en su sintaxis.
Lo primero que tú necesitas entender es: cómo usar el nombre de las columnas en las búsquedas. Esto quizá pueda parecer un poco extraño o extravagante. Pero, si tú ya filtraste resultados de una tabla en Excel, sabes que debes seleccionar una columna y luego indicar cómo se hará el filtrado, ya sea basado en un valor mayor, menor o igual a un punto o criterio determinado. Lo mismo ocurre aquí en SQL. Solo que aquí no hacemos las cosas como se harían en Excel. Lo que hacemos es enviar un comando para que SQL lo ejecute. Así, el filtrado se realizará correctamente.
Por ejemplo, supongamos que tú quieras que SQL te muestre todos los registros cuyo valor de FLAGS sea igual a 88. Entonces tú sabes que, de alguna forma, tendrás que poner en el comando SELECT algo del tipo:
FLAGS = 88
Esto parece obvio. Pero, para hacer esto, necesitas añadir una cosita al comando. Entonces, el comando anterior, visto al inicio del tema, quedaría como se muestra abajo:
SELECT * FROM tb_Quotes WHERE "<FLAGS>" = 88;
Recuerda que el nombre de nuestra tabla es tb_Quotes. Bien, al ejecutar el comando mostrado arriba, todos los registros cuyo valor de la columna FLAGS sea igual a 88 se mostrarán en el área de resultados. Ahora observa lo siguiente: ¿por qué el nombre de la columna está entre comillas? El motivo es que es una string. Siempre que tú vayas a usar una string en SQL, debe ir entre comillas. Además, nota que, junto al nombre de la columna, están los caracteres de mayor y menor. Si tú no usaras las comillas, SQL podría confundir esos caracteres del nombre con algún comando interno del propio SQL.
En este momento, tú puedes estar pensando: ¿pero por qué haría esto en SQL? Si yo usara Excel u otro programa similar, conseguiría los mismos resultados y, de manera incluso más simple. No veo utilidad en aprender SQL. En efecto, mi querido lector, esto que acabo de mostrar podría hacerse en Excel, incluso de una forma más simple. Pero el detalle es que tú estás ignorando algo. En este momento, apenas estamos empezando a ver cómo funciona SQL. Estas cosas iniciales, realmente, se pueden hacer en otros programas y, muchas de ellas, de forma mucho más fácil.
Sin embargo, cuando trabajamos con bases de datos reales, muchas veces usamos algo que son las tablas relacionadas y las búsquedas relacionadas. Este tipo de cosa no se puede hacer en programas como Excel. Bueno, hasta se podría, pero sería mucho más laborioso y costoso que hacerlo aquí en SQL.
Además de ese hecho, existe otro, y es lo que hace que muchos programadores de larga trayectoria no programen ciertas cosas. Ellos simplemente prefieren usar SQL, o algo parecido, para hacer ciertos tipos de trabajo. Para entender de qué estoy hablando, necesitamos volver al primer artículo sobre SQL. Allí mencioné que, muchas veces, es preferible usar una herramienta o tecnología ya establecida que tener que programar una serie de procedimientos y rutinas para hacer algunas cosas. Pues bien, en este punto, donde tú básicamente ya sabes cómo crear, insertar, modificar, eliminar y consultar registros de una base de datos, podemos profundizar un poco más sobre lo que se dijo en aquel artículo en particular.
Pensemos en algo de lo que se ha visto hasta el momento. Para hacer todo lo que hicimos, usando el mínimo de conocimiento sobre SQL, tú, querido lector, incluso usando un lenguaje que te permita trabajar con datos variados, como por ejemplo Python, tardarías mucho más tiempo en producir las mismas cosas que ya estamos haciendo, solo por el simple hecho de que, en lugar de usar SQL, decidieras hacer lo mismo usando Python. No estoy diciendo aquí que tú no podrías hacerlo. Solo estoy diciendo que tardarías mucho más tiempo, con todo el trabajo de crear, probar y desarrollar rutinas para hacer lo que se ha visto hasta aquí.
Y, recuerda que, hasta ahora, todo lo que presenté fue la parte más básica de SQL. Y, aun así, tú, si eres un programador competente y con buen conocimiento en Python, tardarías días o incluso semanas en obtener algo mínimamente parecido, o, como muchos de hecho desearían, similar a lo que se puede hacer en SQL. Vuelvo a este tema porque quiero, o mejor dicho, me gustaría que tú no perdieras tiempo intentando reinventar la rueda. Si tú estudias, aunque sea el nivel más básico de SQL, pero enfocado a usarlo para el propósito para el que realmente fue creado, verás que no tiene sentido programar algo que hace lo mismo que SQL.
Consideraciones finales
En este momento, no mostré uno de los puntos principales de SQL. Aunque lo mencioné en artículos anteriores, todavía no hemos usado algo que hace que las bases de datos sean un tema tan amplio. Pero, ya que en este artículo presenté el comando básico que nos permite buscar información en una base de datos, podemos profundizar un poco más en las cuestiones que hacen que SQL sea algo que tú debes, de hecho, tener en cuenta si realmente deseas ser un buen profesional. En el próximo artículo, todavía hablaremos un poco más sobre programación en SQL, porque hay un concepto que aún falta explorar y explicar.
Este concepto es el que involucra claves primarias y claves foráneas, algo que marca toda la diferencia cuando se está creando un sistema de tablas relacionadas. Y saber usar tablas relacionadas marca toda la diferencia, sobre todo porque ayudan mucho en una búsqueda dentro de la base de datos, pero también nos permiten hacer y crear algunas cosas que, de otra manera, no serían posibles. Así que, si tú realmente te interesaste por el tema de las bases de datos, no te pierdas el próximo artículo. Porque allí esto empezará a dejar de ser básico y comenzará a ponerse un poco más serio.
| Archivo | Descripción |
|---|---|
| Experts\Expert Advisor.mq5 | Demuestra la interacción entre Chart Trade y el Asesor Experto (es necesario el Mouse Study para la interacción) |
| Indicators\Chart Trade.mq5 | Crea la ventana para configurar la orden que se enviará (es necesario el Mouse Study para la interacción) |
| Indicators\Market Replay.mq5 | Crea los controles para la interacción con el servicio de repetición/simulador (es necesario el Mouse Study para la interacción) |
| Indicators\Mouse Study.mq5 | Permite la interacción entre los controles gráficos y el usuario (necesario tanto para operar el sistema de repetición del simulador como en el mercado real) |
| Services\Market Replay.mq5 | Crea y mantiene el servicio de repetición y simulación de mercado (archivo principal de todo el sistema) |
| Code VS C++\Servidor.cpp | Crea y mantiene un socket servidor desarrollado en C++ (versión Mini Chat) |
| Code in Python\Server.py | Crea y mantiene un socket en Python para la comunicación entre MetaTrader 5 y Excel |
| Indicators\Mini Chat.mq5 | Permite implementar un minichat mediante un indicador (requiere el uso de un servidor para funcionar) |
| Experts\Mini Chat.mq5 | Permite implementar un minichat mediante un Asesor Experto (requiere el uso de un servidor para funcionar) |
| Scripts\SQLite.mq5 | Demuestra el uso de un script SQL mediante MQL5 |
| Files\Script 01.sql | Demuestra la creación de una tabla simple, con clave foránea |
| Files\Script 02.sql | Demuestra la adición de valores en una tabla |
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/12928
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso