
Utilizando hojas de cálculo para construir estrategias comerciales

Introducción
Las hojas de cálculo son una invención bastante antigua. Los programas modernos de esta clase tienen un poder enorme y nos permiten analizar visualmente los datos presentados en forma de recuadro. En este caso, además, podemos realizar el análisis en diferentes planos, desde diferentes ángulos de visión, y todo ocurre con bastante rapidez. Gráficos, cuadros sinópticos, análisis hipotéticos, formato de celda condicional y muchas cosas más sobre las que se han escrito gruesos manuales y largos cursos.
Proponemos al lector poner a prueba aquí parte de este poder para analizar nuestras estrategias.
En nuestro caso, usamos Libre Office Calc porque es gratis y funciona donde sea que trabajemos :-) No obstante, el propio enfoque funciona con otras hojas de cálculo: Microsoft Excel, Google Sheets, etc. Hoy en día, todos permiten la conversión mutua, y el principio de construcción de sus fórmulas es también similar.
Entonces, supondremos que el lector tiene algún tipo de programa de hojas de cálculo. Además, usted dispone de datos en formato de archivo de texto (*.txt o *.csv) que desea analizar. El presente artículo describe brevemente cómo importar dichos archivos. Usaremos la historia del terminal MetaTrader, pero cualquier otro dato servirá, por ejemplo, de Dukas Copy o de Finam. Asimismo, esperamos dejar claro que debemos tener una idea de estrategia lo suficientemente clara como para configurar las señales. Esto es todo lo que necesitamos para aplicar los materiales del artículo a la práctica.
Esperamos que el artículo resulte útil para diferentes categorías de tráders, por lo que trataremos de escribirlo de forma que sea comprensible incluso para aquellos que nunca antes habían visto programas de este tipo, abarcando al mismo tiempo un rango de problemas que no resulten conocidos a todos los tráders experimentados.
Un vistazo rápido a los recuadros — para principiantes
La figura 1 muestra una vista típica de un programa de hojas de cálculo.
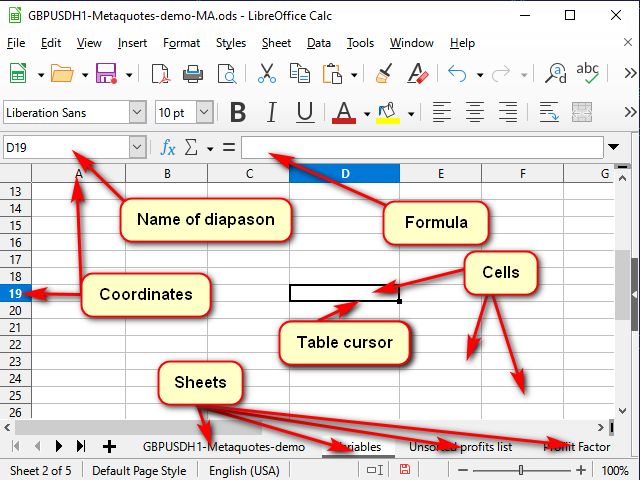
Figura 1. Ventana típica de un programa de hojas de cálculo.
Cualquier recuadro se representa como un conjunto de "hojas". Piense en ellos como "pestañas" separadas para diferentes tareas.
Cada hoja consta de "celdas". En esencia, cada celda es una calculadora pequeña pero muy poderosa.
Para que el programa comprenda qué celda queremos procesar en este momento, cada celda presenta coordenadas, igual que en un tablero de ajedrez o en el juego de mesa Hundir la Flota. Estas coordenadas juntas definen una "dirección" de celda única. La dirección consta de un número de columna o nombre y un número de fila (por ejemplo, la figura 1 muestra la celda "D19" resaltada por el cursor del recuadro). Podemos ver esto tanto en los nombres de las coordenadas resaltadas como en la línea del nombre.
Además de las coordenadas, la dirección puede contener el nombre de la hoja e incluso el nombre del archivo del recuadro. Generalmente, utilizamos la misma dirección como nombre de la celda. Pero, si lo deseamos, podemos establecer nuestros propios nombres para dejar claro qué es lo que almacena exactamente esta celda o rango de celdas. Podemos ver (y cambiar) estos nombres en la línea de nombre.
Una celda puede contener datos simples (como cotizaciones o volúmenes) o las "fórmulas" que se usan para calcular su valor.
Podemos ver (y cambiar) el contenido de la celda resaltada en la "línea de fórmulas".
Para editar un valor de la celda, debemos clicar dos veces sobre él o hacer nuestras correcciones en la línea de fórmulas. También podemos resaltar una celda y presionar "F2". Si necesitamos crear un texto nuevo, podemos resaltar una celda y comenzar a escribir de inmediato. No obstante, hay que tener en cuenta que todos los datos anteriores se eliminarán de la celda.
Podrá cancelar la edición sin guardarla presionando "ESC" (esquina superior izquierda del teclado). Confirmamos la edición presionando "Enter" (el cursor se mueve hacia abajo) o "Tab" (el cursor se mueve hacia un lado).
Si resaltamos varias celdas, "Enter" y "Tab" funcionarán solo en el fragmento resaltado. Podemos utilizar esto para acelerar el trabajo.
En cuanto a los otros botones y menús, creemos que son bastante fáciles de entender.
Comenzamos a trabajar: importando las cotizaciones
Bien, vamos a comenzar a preparar los datos para poner a prueba nuestras estrategias. Como ya hemos dicho, tomaremos los datos del terminal. Para hacer esto, en cualquier ventana de gráfico, podremos presionar la combinación de teclas Ctrl+S o seleccionar "Archivo "->" Guardar ". El terminal ofrecerá la habitual ventana de sistema, en la que deberemos introducir el nombre del archivo y la ruta.
Si la extensión del archivo es *.csv, generalmente no habrá problemas. Si es *.txt, entonces, como norma general, deberemos clicar en el archivo con el botón derecho del ratón y seleccionar "Abrir con" -> "Seleccionar otra aplicación" o primero abrir la aplicación para trabajar con recuadros, y solo abrir el archivo desde ella, ya que por defecto, el sistema intenta abrir los archivos con esta extensión utilizando el bloc de notas u otro procesador de texto.
Para convertir números, deberemos seleccionar la columna apropiada en la ventana de conversión y luego indicar al programa el separador de las partes enteras y fraccionarias. Asimismo, si fuera necesario, indicaremos el separador de los grupos de dígitos (para los volúmenes). En Excel, esto se realiza con el botón "Más detalles...", en Calc de la lista "Tipo de columna"; seleccionamos el elemento "Inglés de EE. UU.".
Y otro matiz a prestar atención: después de realizar la importación con éxito, deberíamos dejar entre 5 y 7 mil filas en el recuadro con los datos. El hecho es que cuantos más datos haya, más difícil resultará para el programa calcular el resultado de cada celda. En este caso, además, la precisión de la valoración aumenta de manera insignificante: por ejemplo, cuando comparamos los resultados de la verificación para los datos de 5.000 filas y 100.000 filas, los resultados se distinguen en aproximadamente un 1%, mientras que el cálculo difiere sustancialmente.
Algunos atajos de teclado para trabajar con los recuadros
| Atajo de teclado | Acción realizada |
|---|---|
| Ctrl + flecha | Salto al borde más cercano de una serie de datos continuos |
| Tab | Confirma los datos introducidos y salta a la celda de la derecha |
| Shift + Tab | Confirma los datos introducidos y salta a la celda de la izquierda |
| Enter | Confirma los datos introducidos y salta a la celda de abajo |
| Shift + Enter | Confirma los datos introducidos y salta a la celda de arriba |
| Ctrl + D | Completa las columnas seleccionadas de arriba hacia abajo |
| Shift + Cttrl + flecha | Selecciona a partir de la posición actual hasta el final del rango continuo |
¿Cómo podemos llenar una columna larga con la misma fórmula?
Para rangos pequeños, podemos utilizar el método mostrado en la figura 2: para ello, moveremos el ratón hacia el "marcador de selección" (el cuadrado en la esquina inferior derecha del cursor del recuadro) y, cuando el cursor del ratón se convierta en una cruceta delgada, arrastraremos este marcador a la fila o columna deseada.
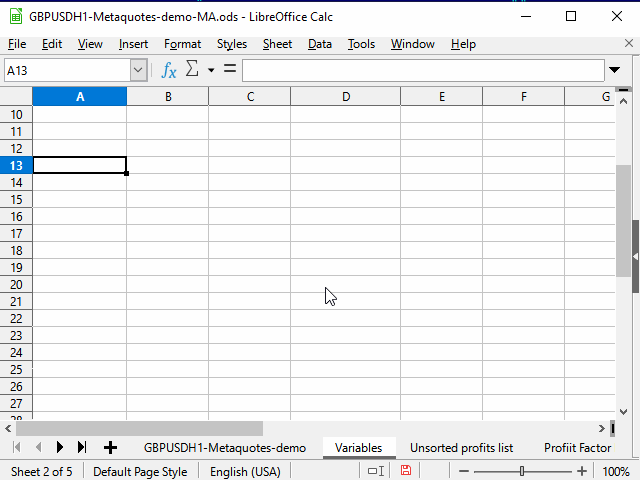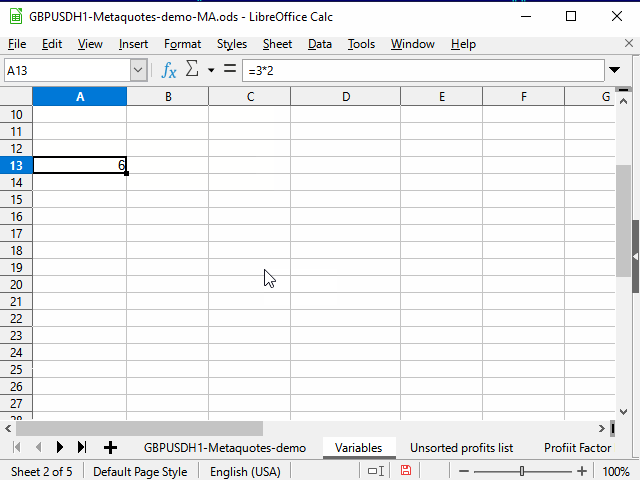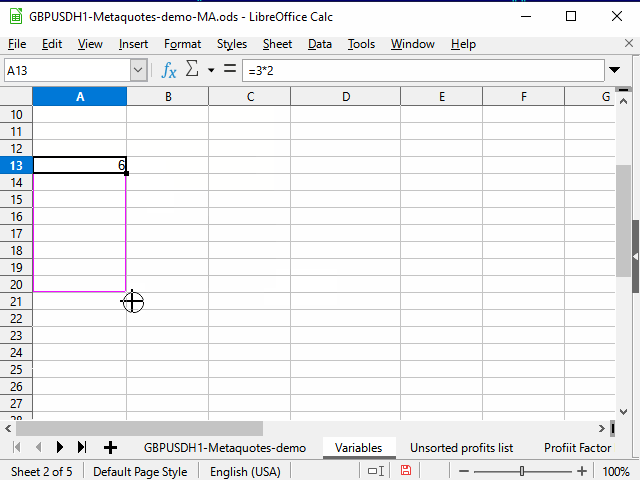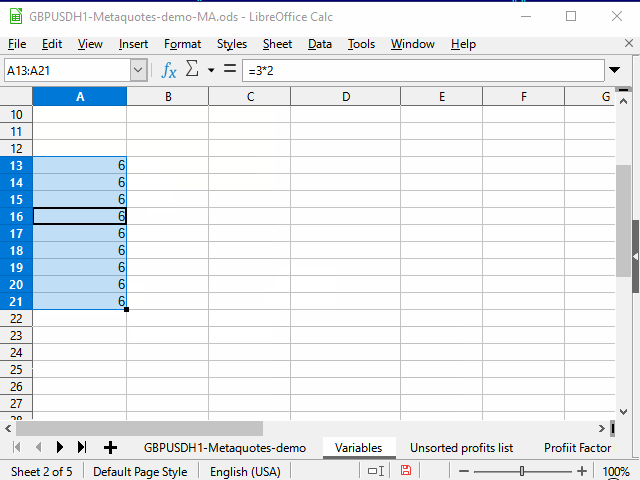
Figura 2. Rellenamos con arrastre
No obstante, para grandes cantidades de datos, esto resultaría muy incómodo.
Por consiguiente, usaremos cualquiera de los métodos siguientes.
Método 1 Limitación del rango
La secuencia de acciones se muestra en la figura 3.
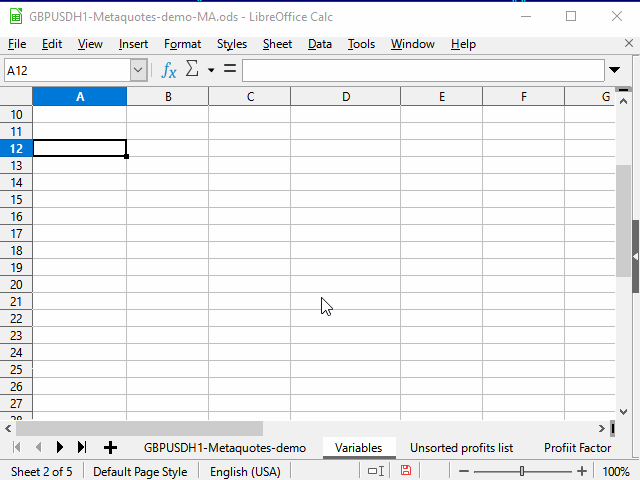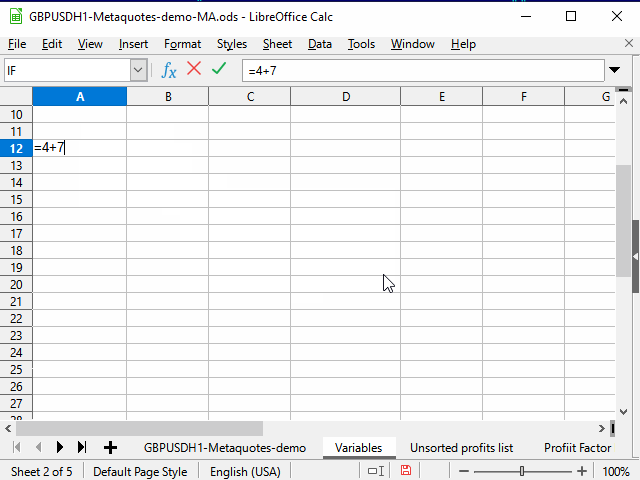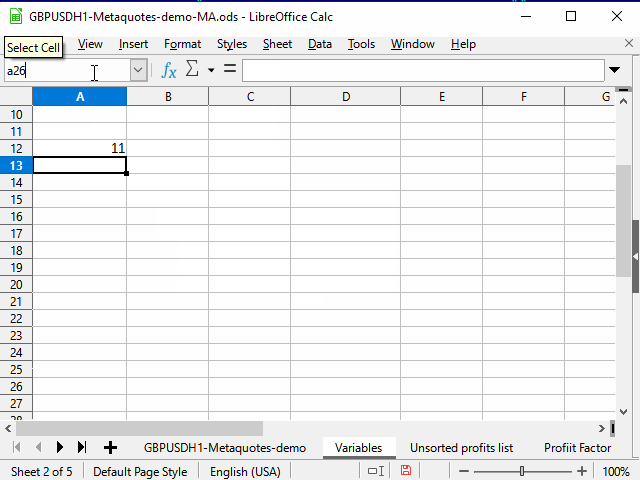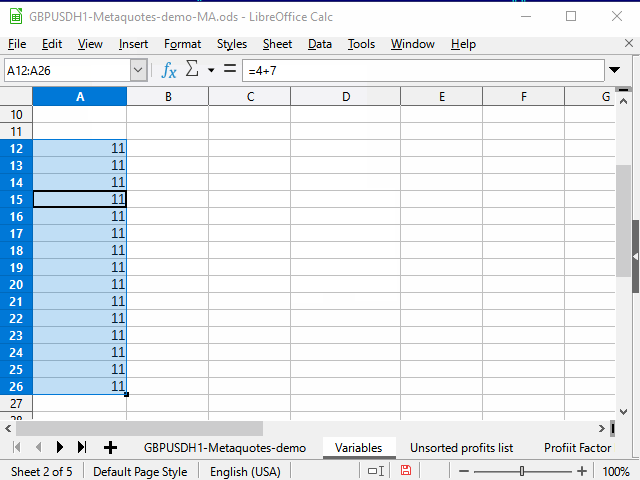
Figura 3. Rellenado con limitación de rango
- Introducimos la fórmula deseada en la celda superior del rango y confirmamos la información introducida.
- Pasamos a la celda que se encuentra más abajo en el rango utilizando el campo de nombre.
- Pulsamos las teclas Ctrl + Shift + flecha hacia arriba para saltar a la celda superior del rango y seleccionamos todas las celdas intermedias.
- Presionamos la combinación Ctrl + D para rellenar las celdas con datos.
En nuestra opinión, una pequeña desventaja del método es que necesitamos conocer el número de la línea que se halla más abajo en el rango.
Método 2. Utilizando el rango continuo adyacente
La secuencia de acciones se muestra en la figura 4.
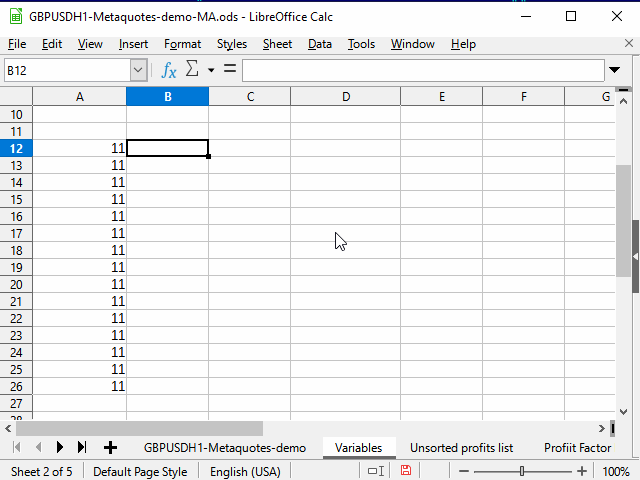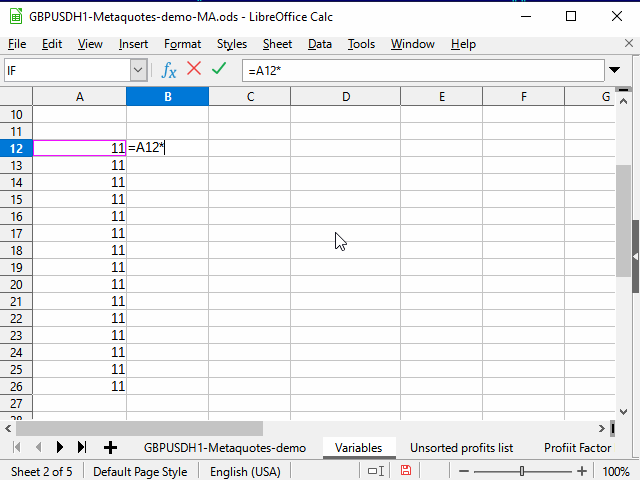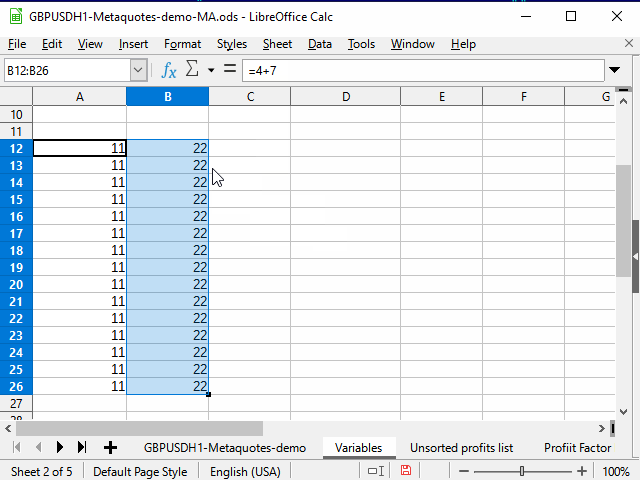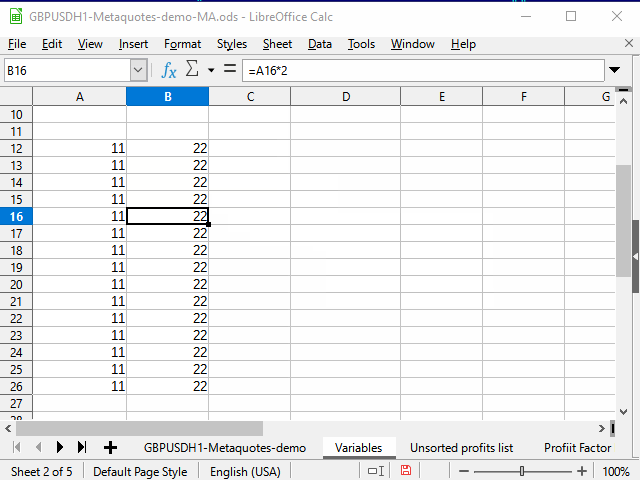
Figura 4. Rellenado con la ayuda del rango adyacente
- Seleccionamos la celda con la ecuación necesaria.
- Con la ayuda de la combinación Shift + flecha a la izquierda, destacamos la celda colindante.
- Presionamos la tecla Tab para que el cursor del recuadro se desplace a la celda de la izquierda. Aquí, usamos la capacidad del cursor del recuadro para moverse solo dentro de la selección.
- Ctrl + Shift + flecha hacia abajo: seleccionamos dos columnas hasta la fila inferior de un rango contiguo.
- Shift + flecha derecha — anulamos la selección de la columna izquierda. La columna de la derecha permanecerá resaltada.
- Ctrl + D — rellenamos la columna con datos.
En la figura, podemos ver el contenido de la línea de fórmulas. Se ve que al copiar una fórmula que contiene un enlace a otra celda, este enlace cambia automáticamente según la posición del cursor. Por consiguiente, dicho vínculo se denomina "relativo".
Si queremos que al realizar el copiado el enlace a la celda permanezca constante, deberemos seleccionar este enlace y presionar F4. El signo $ aparecerá delante del número de fila y el nombre de la columna, y el valor no cambiará al copiar la fórmula.
A veces, resulta útil no cambiar todo el enlace, sino solo una columna o solo una fila. Entonces debemos dejar el signo del dólar en la parte no modificable (puede presionar F4 una o dos veces más).
Bueno, ahora que ya dominamos los métodos básicos para acelerar el trabajo, podemos pasar directamente a la descripción de la estrategia.
Descripción de la estrategia
Como ejemplo, tomaremos la estrategia implementada en el asesor estándar "Examples\Moving Average".
La posición se abrirá si:
- No hay posiciones abiertas y
- La vela cruza la media móvil con el cuerpo (Open — en un lado de la MA, Close — en el otro).
La posición se cerrará si:
- Hay una posición abierta y
- La vela cruza la МА en la dirección opuesta a la apertura.
Añadiendo los datos del indicador
La característica distintiva de la ejecución de cálculos usando hojas de cálculo es que los subtotales de los cálculos, en general, deben guardarse por separado. Esto nos facilita la comprensión de las ecuaciones y la detección de errores, y también simplifica la creación de ecuaciones basadas en los datos de celdas adyacentes. Además, precisamente esta "fragmentación" da a veces lugar a nuevas ideas.
Pero regresemos a nuestra tarea.
Después de la importación y el formateo, nuestras cotizaciones originales se ven así (Figura 5):
Figura 5. Cotizaciones originales
Tenga en cuenta la fila en blanco entre el nombre del recuadro en general y los nombres de las columnas. Esta fila permite que el procesador de la hoja de cálculo trate los dos bloques como recuadros aparte, de forma que podamos combinar las celdas para el rango superior, pero aún así usar filtros diferentes para el rango inferior, sin interferencia mutua. Quitar dicha línea podría causar problemas.
Hemos arreglado las primeras filas y columnas para ocultar la información innecesaria en este momento, pero todos los datos están todavía presentes en el recuadro (consulte la guía de ayuda de su procesador de hojas de cálculo para saber cómo hacer esto).
La hora y la fecha se encuentran en la columna A, los precios de apertura están en la columna B, y así sucesivamente. La última fila del recuadro tiene el número 6038.
El primer paso para construir una estrategia es construir un indicador. Para que el indicador sea personalizable, añadiremos otra hoja y crearemos un recuadro de variables en ella. A continuación, asignaremos un nombre propio a cada variable utilizando una línea de nombre, de modo que al escribir las fórmulas quede claro de dónde viene.
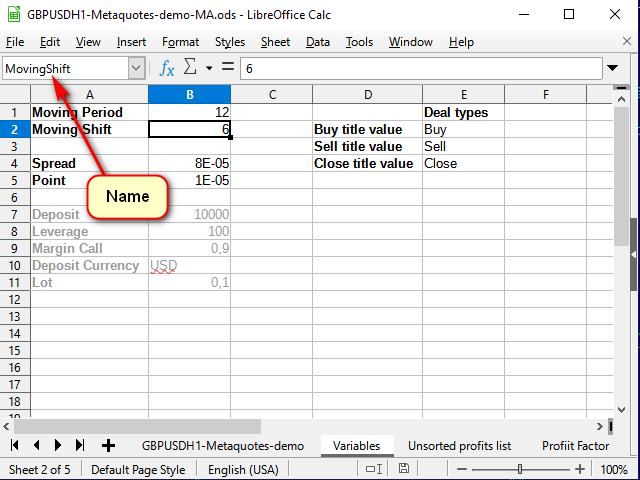
Figura 6. Hoja de variables
Ahora, regresemos a la hoja de datos. Para simplificar ligeramente la fórmula final, primero, en la columna G, escribimos el número de la cotización en la lista. Es igual al número de línea menos 3:
=ROW()-3
Escribiendo esta fórmula en la celda G4, la extenderemos a todas las celdas inferiores.
Esto es necesario para que la fórmula de cálculo de la MA sea universal. Si (desplazamiento + periodo) de la MA es superior a los datos que tenemos, entonces el cálculo del promedio no tendrá sentido.
En sí, la fórmula de cálculo de la media móvil (SMA) se escribirá en la celda H4 de la hoja con los datos principales y se verá así:
=IF( G4>(MovingPeriod+MovingShift), AVERAGE( INDIRECT( "E" & ( ROW()-MovingShift-MovingPeriod) & ":" & "E" & ( ROW()-MovingShift) ) ), "" )
Al introducir ecuaciones que requieren enlaces a otras celdas, podemos especificar las celdas con el ratón.
La fórmula actual se inicia llamando a la función IF(). Esta es, como podemos adivinar, la función de verificación de la condición. A propósito, todas las expresiones lógicas como And, Or, Not, si se requieren en el futuro, también serán funciones.
Al llamar las funciones, los argumentos se especifican entre paréntesis y separados por comas (como en este caso) o por punto y coma.
La función IF toma tres argumentos: la condición, el valor si la condición es verdadera, y el valor si la condición es falsa.
En este caso, lo hemos utilizado para verificar si hay suficientes datos para calcular un punto completo para la curva de la MA. Si no existen suficientes datos, solo tendremos que guardar una línea vacía; de lo contrario, calcularemos el valor promedio de un cierto rango.
La función Indirect retorna un valor (o varios valores) del rango especificado por una línea de texto. Esto es exactamente lo que necesitamos, ya que las direcciones de los rangos requeridos para calcular el promedio deben formarse según los valores de entrada.
El símbolo "&" en los programas de hojas de cálculo denota la concatenación de dos filas. Por consiguiente, hemos "pegado" la dirección de varias partes. La primera parte es el nombre de columna en la que se encuentran los precios de cierre ("Е"), mientras que la segunda es una dirección "remota" calculada como el número de fila actual menos la longitud promedio y menos el desplazamiento. La tercera parte de esta expresión es el signo de dos puntos que indica la continuidad del rango. Le siguen los nombres de columna y fila teniendo en cuenta el desplazamiento. Hemos decidido no resaltarlos demasiado. Esperamos que los cortes de con ampersand resulten útiles para aclararse.
Está claro que esta fórmula deberá extenderse a todas las filas siguientes.
Como resultado, obtendremos algo así:
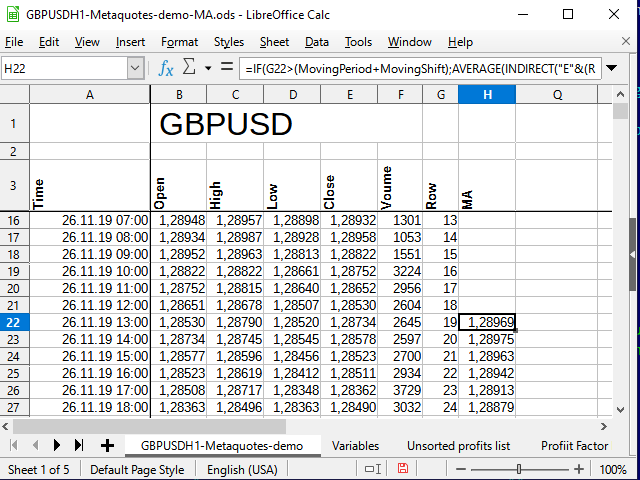
Figura 7. Recuadro después de añadir los cálculos de la МА.
Podemos ver que los números en la columna H han comenzado a aparecer solo en la línea 22 (19 entradas). ¿Por qué sucede así? Vamos a mirar la figura 6.
Bien, ya tenemos los datos iniciales y los datos del indicador. Podemos comenzar a implementar la estrategia.
Implementando la estrategia
La estrategia se implementará en forma de señales simples. Si se ha cruzado la MA hacia abajo, escribiremos el valor "-1" en la celda; si se ha cruzado hacia arriba, escribiremos "1". Si no hay intersecciones en este momento, la celda contendrá el valor de una línea vacía.
Pasemos a la celda I4. La fórmula básica de esta celda tendrá el aspecto que sigue:
=IF( AND( B4>H4,E4<H4 ),-1 , IF( AND( B4<H4,E4>H4 ), 1 , "") )
Podemos comprobarlo en el gráfico, funciona. Pero esta es una fórmula de inversión simple. No permite monitorear el estado de la transacción. Podemos experimentar con él y obtener resultados interesantes, pero nuestra tarea ahora consiste en implementar la estrategia descrita al principio del artículo. Por consiguiente, necesitamos registrar el estado de la transacción en cada barra (es decir, en cada línea).
La columna J resulta bastante adecuada para esto. La fórmula en la celda J4 tiene el aspecto siguiente:
=IF(AND(I4=-1,J3=""), -1 ,IF(AND(I4=1,J3=""), 1 ,IF(OR(AND(I4="",J3=1),AND(I4="",J3=-1),I4=J3), J3 ,"")))
Si ha sucedido un evento (cruzamiento), verificamos el estado de la transacción anterior. Si esta se encuentra abierta y el cruzamiento tiene lugar en la dirección opuesta, la cerramos. Si la transacción está cerrada, la abrimos. En todos los demás casos, solo guardaremos el estado.
Para que se vea de forma más clara dónde habríamos comprado y vendido si hubiéramos implementado esta estrategia en el periodo al que corresponden nuestros datos, y también para que resulte más cómodo analizar la estrategia, introduciremos otra columna, esta con señales.
Podemos obtener los nombres de las señales a partir de la guía de ayuda que podemos crear en la hoja de variables.
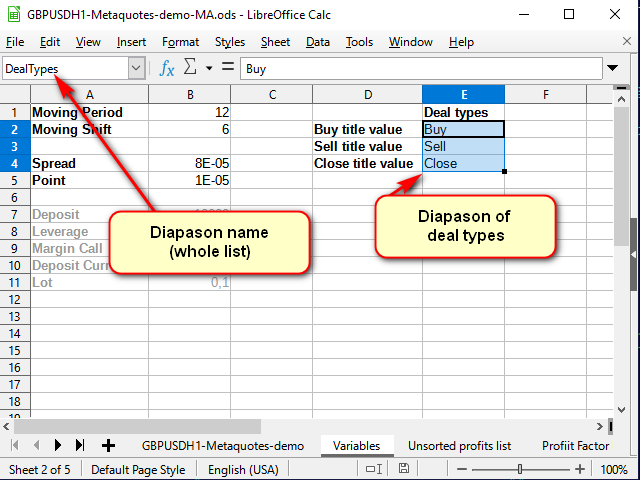
Figura 8. Hoja "Variables" tras añadir el directorio con los nombres de las transacciones
Preste atención a la línea del nombre: aquí la hemos nombrado como todo el rango de selección, no como una sola celda.
Ahora, en la celda K4 de la hoja principal (con los datos), podemos escribir lo siguiente:
=IF(AND(J3=1,J2=""),INDEX(DealTypes,1),IF(AND(J3=-1,J2=""),INDEX(DealTypes,2),IF(OR(AND(J3="",J2=1),AND(J3="",J2=-1)),INDEX(DealTypes,3),"")))
La transacción se abre después de la señal, en la apertura de la siguiente vela. Por consiguiente, debemos prestar atención al cambio de los índices en esta fórmula.
Si no ha habido transacción (la celda anterior en la columna de estado está vacía) y ha llegado una señal, le indicaremos qué tipo de transacción debe hacerse. Si se ha abierto una transacción, la cerraremos según la señal.
La función Index toma como primer parámetro el rango en el que sucederá la búsqueda. En nuestro caso, se establece según el nombre. El segundo parámetro es el número de línea en este rango. En caso necesario, si el rango consta de varias columnas, podemos especificar la columna deseada; si especificamos varios rangos separados por punto y coma, entonces indicaremos el número del rango partiendo desde 1 (el tercer y el cuarto parámetro, respectivamente).
Como resultado, tras extender esta fórmula a todas las celdas a continuación y aplicar el formato condicional (para que resulte más bonito, el formato no será necesario durante el análisis), obtendremos algo similar a lo siguiente:
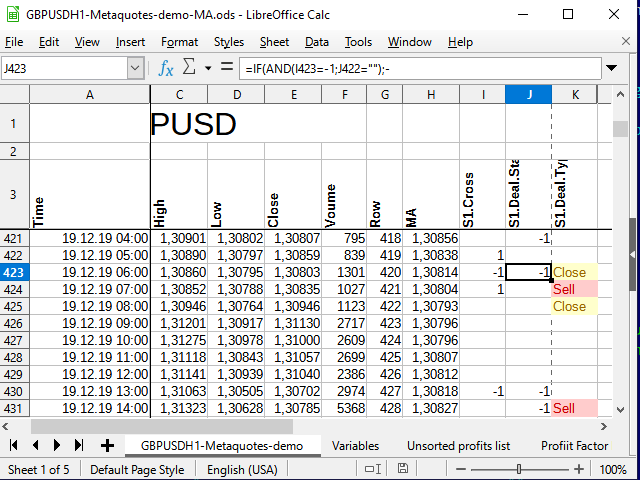
Figura 9. Señales para las transacciones.
Análisis de la estrategia
Para analizar la rentabilidad de la estrategia, necesitaremos calcular la distancia recorrida por el precio durante el periodo de la transaccióon. Resulta más sencillo hacer esto en varias etapas.
Primero, elegimos el precio de la transacción. Si se abre una transacción, escribimos el precio en la columna junto a la señal (L) y lo copiamos en cada celda subsiguiente hasta que se cierre la transacción. Si no hay ninguna transacción, escribimos una línea vacía en la celda. Fórmula en la celda L4:
=IF(K4=INDEX(DealTypes;1);B4+Spread;IF(K4=INDEX(DealTypes;2); B4 ;IF(OR(K4=INDEX(DealTypes;3);N(L3)=0); "" ;L3)))
Si la celda de señal ( K4 ) contiene la palabra "Buy", el precio de apertura de la transacción será igual al precio de apertura de la vela más el spread. Si la señal es la palabra "Sell", simplemente anotaremos el precio de apertura de la vela, si es "Close" (o la celda anterior de la columna no contiene un número) se tratará de una línea vacía, y si la celda anterior de la misma columna contiene un número y la columna de señal no contiene ninguna palabra, simplemente copiaremos la celda anterior.
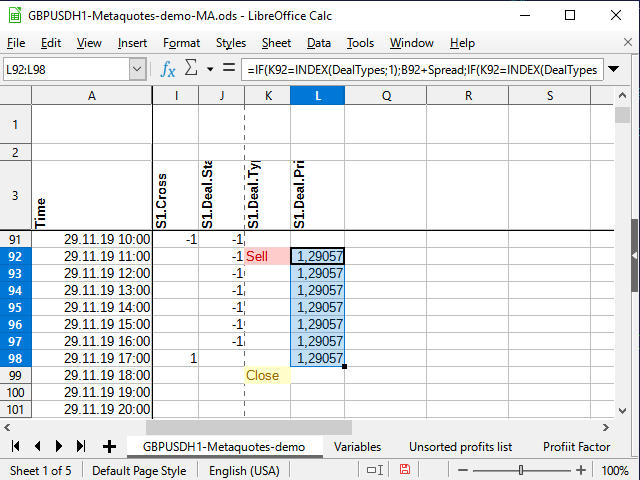
Figura 10. Precio de apertura de la transacción
Por consiguiente, podremos calcular fácilmente el beneficio de la transacción en el momento del cierre.
Asegúrese de extender la fórmula a continuación.
Podríamos calcular inmediatamente la diferencia entre los precios de apertura y cierre en la columna adyacente, sin embargo, haremos algo más complicado. Vamos a calcular la diferencia en la columna N para poder así clasificar solo los datos únicos y luego calcular su frecuencia.
En el presente caso, que representa una valoración más simple, no usaremos ninguna gestión de capital, ya que nuestro objetivo consiste en evaluar la eficiencia de la estrategia. Por consiguiente, bastará con calcular la diferencia de precio en pips. Por ejemplo, así:
=IF(K4=INDEX(DealTypes;3);IF(I3=-1;ROUND((B4-L3)/Point);ROUND((L3-B4)/Point)); "" )
Obviamente, en lugar de verificar la condición promedio, podríamos simplemente multiplicar (B3-L3)*I3, pero, en nuestra opinión, eso resultaría un poco menos visual para los principiantes.
Bien, hablemos ahora del truco en sí. En la columna М numeraremos todas las entradas únicas sobre el rango de la transacción, dejando las no únicas sin números.
=IF(N4<>"";IF(COUNTIF(N$3:N4;N4)=1;MAX(M3:M$4)+1;"");"")
Todo queda claro respecto a la condición externa: si la celda de la derecha (N4) no está vacía, verificaremos la unicidad y el número, si fuera necesario; de lo contrario, dejaremos una línea vacía.
Pero, ¿cómo funciona la numeración?
La función Countif cuenta el número de cifras en el rango determinado, siempre que el valor de la celda cumpla con la condición especificada en el segundo parámetro. Supongamos que la fórmula se calcula para la celda M71, y que la celda N71 contiene el número 531 (ver figura 11). Antes, este número no se había encontrado en ninguna parte.
Si el signo de acción no se determina en la celda con la condición, entonces se supondrá que queremos verificar la igualdad de dos valores. El número es igual a sí mismo (N71=N71), y esto significa que intentaremos contar. El cálculo siempre parte desde la celda N$3 (como lo indica el signo de dólar delante del número tres) hasta la celda actual (no hay signo de dólar en la fórmula). Analizamos el rango N$3:N71 completo y tratamos de calcular el número total de cifras 531 en este rango. Como antes no existían tales números, el total es de 1 (justo lo que hemos hallado ahora). Esto significa que se cumple la condición: el resultado de la función es 1. Por ello, vamos a tomar el siguiente rango: la columna en la que se encuentra esta fórmula, partiendo desde la primera celda con cifras (M$4) hasta la celda que precede a la actual (M70). Si antes había algunos números, tomaremos el mayor de ellos y le sumaremos 1. De lo contrario, el mayor será igual a 0 y, en consecuencia, ¡el primer número ordinal estará listo!
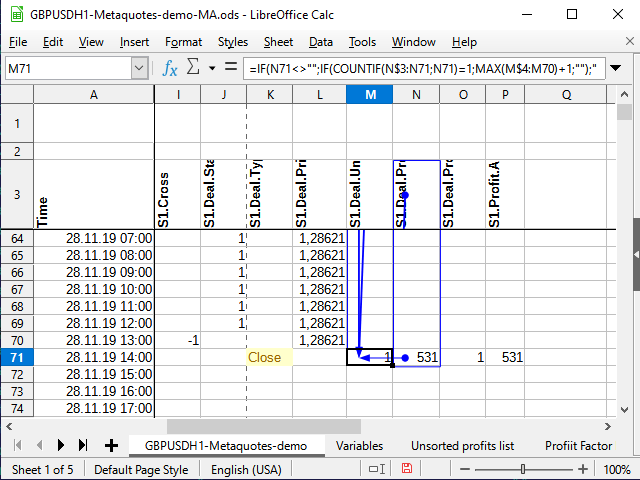
Figura 11. Numeración. Celdas que influyen (punto final del intervalo)
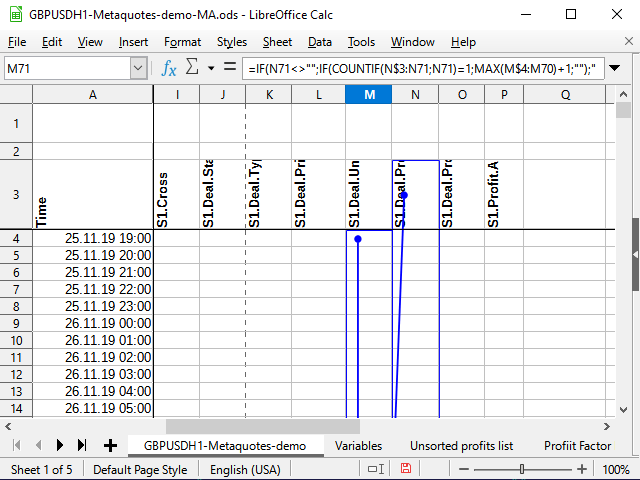
Figura 12. Numeración (punto inicial del intervalo)
En la figura 11, hemos intentado utilizar la herramienta de análisis incorporada que muestra las celdas que influyen en una celda determinada. El punto con la flecha indica el comienzo de los rangos o celdas "exactas"; los rectángulos indican los rangos. Para mayor claridad, adjuntamos la figura 12 para ver que la flecha es continua y comienza exactamente en N$3, y para ver el comienzo de los rangos en los que se realiza la comparación.A todo esto le añadiremos dos columnas más de valores: el tipo de resultado y el "módulo" de la transacción.
Para el tipo de resultado, usaremos números: si la transacción ha sido una compra, entonces el tipo será 1; si ha sido una venta, el tipo será - 2. En este caso, el resultado podrá ser positivo o negativo, dependiendo de si obtenemos beneficios o pérdidas como resultado de la transacción. Esto acortará las fórmulas de análisis final.
Aquí tenemos la fórmula escrita en la celda O4:=IF(AND(N(N4)>0;I3=-1); 1 ;IF(AND(N(N4)<0;I3=-1); -1 ;IF(AND(N(N4)>0;I3=1); 2 ;IF(AND(N(N4)<0;I3=1); -2 ;""))))
"Módulo" es simplemente la magnitud del beneficio o las pérdidas sin considerar el signo, una descripción de la distancia que ha recorrirdo el precio en una dirección hasta que ha llegado la señal de cierre de transacción. Esto puede ayudarnos a seleccionar el stop loss y el take profit (incluso si no son necesarios para la estrategia original).
=IF(N4<>"";ABS(N4);"")
Para crear un gráfico de frecuencia (probabilidad), resulta mejor ordenar de forma ascendente los datos sobre la relación beneficios-pérdidas de las transacciones. Para lograr esto, debemos copiarlas en otra hoja, ya que los datos originales se ordenan según la fecha y la hora, y no se pueden ordenar de otra manera.
Como cada resultado de beneficio único tiene su propio número único (columna M), existen al menos dos formas de copiar los datos sin clasificar en una nueva hoja.
Una de ellas consiste simplemente en usar el filtro estándar para seleccionar celdas "no vacías" en la columna M y luego copiar los datos de la columna N y pegarlos en otra hoja de una manera especial (solo los valores).
La segunda consiste en usar una fórmula. La ventaja es que estos datos cambiarán cuando cambien los datos originales (las mismas variables, o si decidimos usar un intervalo de prueba diferente), pero la desventaja es que ordenarlos generalmente no funcionará de cualquier forma, y a la hora de ordenar, seguiremos necesitando copy/paste.
Para nosotros, resulta más conveniente que los datos ordenados y no ordenados se encuentren en la misma hoja, porque necesitamos menos movimientos para copiar los datos. Por consiguiente, mostraramos una opción en la que los datos sin clasificar se copian mediante una fórmula, copiándose luego nuevamente de forma manual a la hora de ser clasificados.
En una nueva hoja llamada Profit data, creamos una fórmula en la celda A2:
=VLOOKUP( ROW(1:1);'GBPUSDH1-Metaquotes-demo'.$M$3:$N$6038; 2 )
La función Row(1:1) retorna el número de la primera línea. Al rellenar las celdas, el número de línea cambiará y, en consecuencia, se mostrará el número de la segunda línea, de la tercera, etc.
Vlookup — busca algún valor (primer parámetro) en la primera columna del rango (segundo parámetro) y luego retorna el valor que se encuentra en la misma fila encontrada, pero en la columna especificada en el tercer parámetro (en nuestro caso, en la columna con el número 2 del rango especificado). Es decir, secuencialmente, partiendo desde el número 1, se copiarán todas las cifras numerados (únicas) de la columna N.
Después de mirar el último número en la hoja principal usando el filtro estándar, podemos limitar el rango para copiar el resto de los datos.
A continuación, todo sucederá como en la animación de la figura 13.
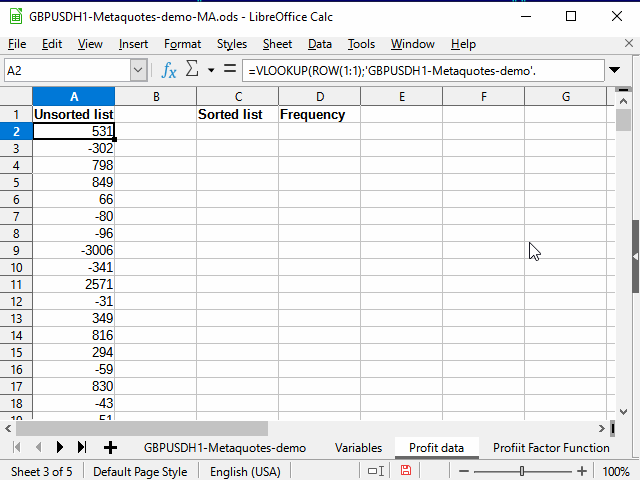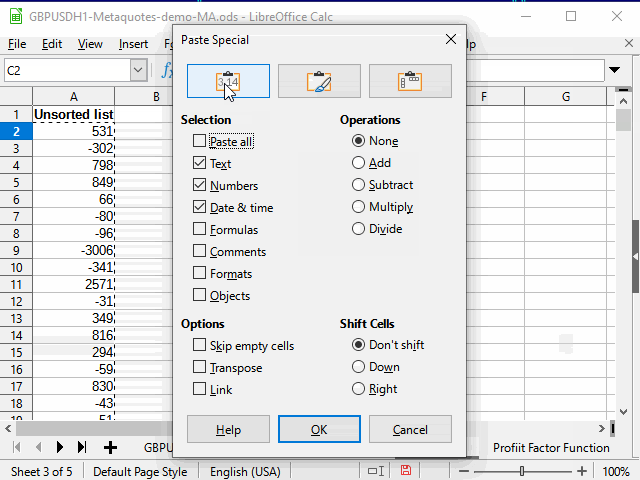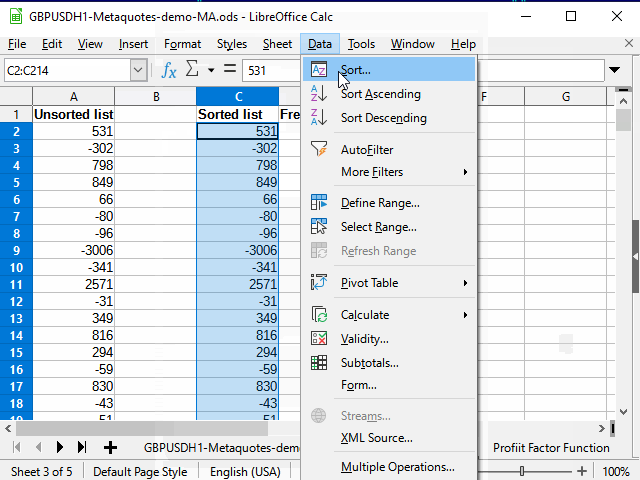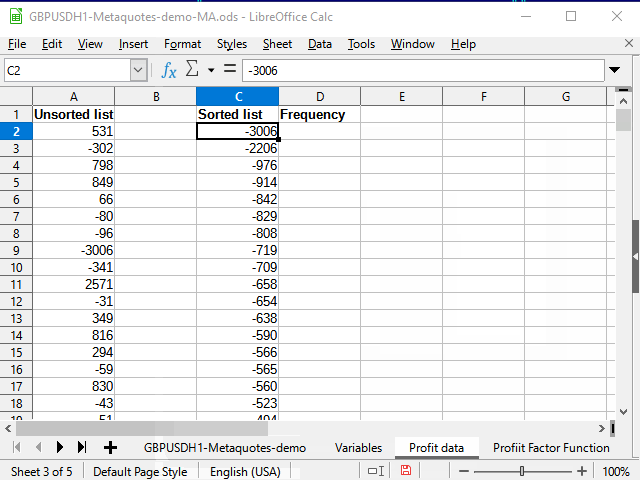
Figura 13. Copiando los datos para la clasificación.
Ahora necesitamos describir la frecuencia de las transacciones rentables y no rentables, es decir, construir una serie de probabilidades.
En la celda D2 de la misma hoja (Profit data), podemos escribir la fórmula siguiente:
=COUNTIF('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;C2)/COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:'GBPUSDH1-Metaquotes-demo'.$N$6038)
Esta describe la frecuencia (o probabilidad) de aparición de cada valor de beneficio.
La función Count calcula el número de cifras en el intervalo; Countif hace lo mismo si se cumple la condición (en este caso, solo se cuentan las celdas cuyo valor es igual al valor en la celda de la columna C).
Los manuales recomiendan hacer series de variaciones a intervalos. En teoría, ¿resulta posible decir que el número de transacciones puede ser bastante elevado?
Los manuales sugieren calcular el tamaño del intervalo utilizando la fórmula
=(MAX($'Profit data'.C2:$'Profit data'.C214)-MIN($'Profit data'.C2:$'Profit data'.C214))/(1+3,222*LOG10(COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:'GBPUSDH1-Metaquotes-demo'.$N$6038)))
Hemos puesto esta fórmula en la celda 'Variables'. E7 y llamado a este valor "Interval". El intervalo ha resultado demasiado grande, y no nos ha quedado claro en general cómo se distribuían las probabilidades, así que lo hemos dividido adicionalmente entre 4. El número final, 344, ha resultado más aceptable para nuestros propósitos.
En la hoja 'Profit data' en la celda F2, hemos copiado el primer número de la lista ordenada:
=C2
Todas las demás celdas se rellenan con la fórmula:
=F2+Interval
Las celdas se han rellenado hasta que el último valor ha superado el valor máximo del tamaño de la transacción.
La celda G2 contiene la siguiente fórmula:
=COUNTIFS('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;">="&F2;'GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;"<"&F3)/COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038)
CountifS, a diferencia de Countif, nos permite aceptar múltiples condiciones, combinándolas con el operador "Y". El resto es igual.
Y cuando hayamos construido estas dos filas, inmediatamente querremos verlas gráficamente. Afortunadamente, cualquier procesador de recuadros lo permite.
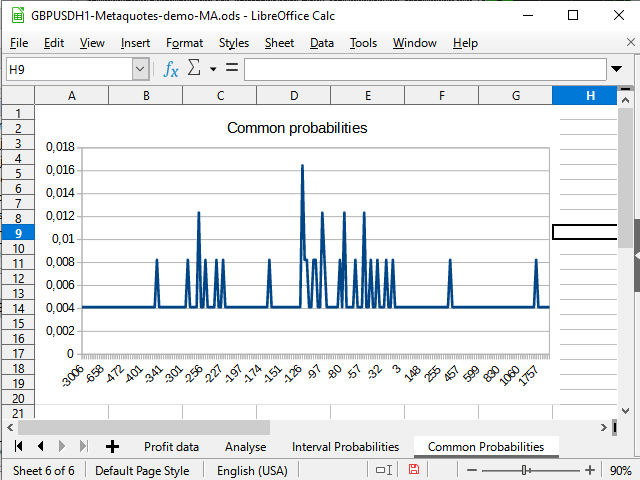
Figura 14. Gráfico de distribución de probabilidades "inmediatas"
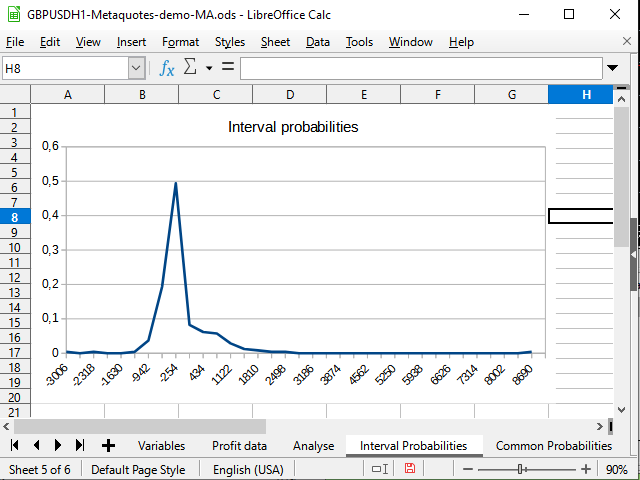
Figura 15. Gráfico de distribuciones de intervalo de las probabilidades de transacciones completadas
En la figura 14, podemos ver un cambio negativo en la densidad de la probabilidad. La figura 15 muestra un pico pronunciado de -942 hasta 2154 y un pico (1 transacción) en 8944.
Bueno, la hoja de análisis (considerando todo lo que hemos analizado), creemos, no causará ninguna dificultad particular.
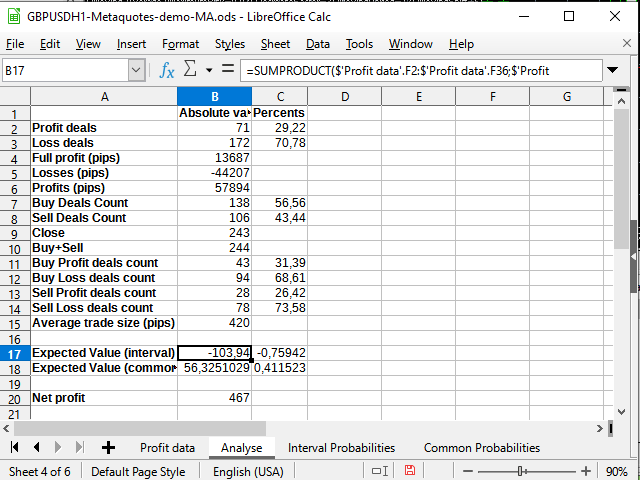
Figura 16. Algunos cálculos matemáticos
Lo único nuevo aquí es el uso de la función Sumproduct, que toma dos intervalos como parámetros y retorna la suma de los productos de los miembros de estos intervalos (digamos, la primera línea con la primera línea, la segunda con la segunda, y así sucesivamente). Precisamente con esta función hemos intentado calcular el valor esperado. Igualmente, decidimos no mezclarnos con métodos de integración más complejos.
Podemos observar que el valor esperado es significativamente inferior al benficio obtenido, y en tanto por ciento oscila alrededor de 0.
Por consiguiente, podemos concluir que la estrategia está funcionando, pero podría tener grandes reducciones. Probablemente pueda funcionar perfectamente en una tendencia muy fuerte (un aumento de ~ 9000 pips, en principio, se vería interesante si no estuviera tan solo), no obstante, lo más probable es que el flat pase factura. La estrategia necesita una seria mejora, por ejemplo, introduciendo órdenes pendientes, digamos, algún take profit (alrededor de 420-500 pips) o algunos filtros de tendencia. Las mejoras requieren de investigación adicional.
Ejecutando la estrategia en el simulador
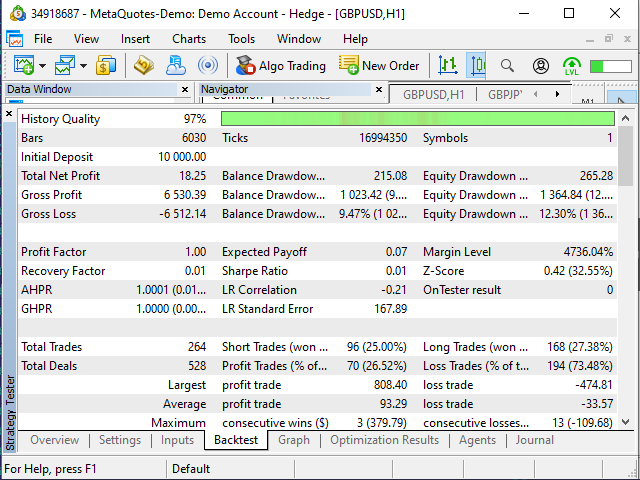
Figura 17. Resultados de las pruebas del asesor "Examples\Moving Average"
Para ser honestos, los resultados del asesor resultan sorprendentes. Bueno, el hecho de que el asesor haya abierto transacciones donde el recuadro sugería cerrar y viceversa, en principio, es normal, probablemente. Podría basarse en más o menos datos (por ejemplo, nuestro recuadro del 25/11/2019 comienza a las 19:00, y le hemos dado al asesor la tarea de comenzar desde el inicio del día).
Pero el hecho de que algunas de sus transacciones tuvieran más o menos este aspecto...
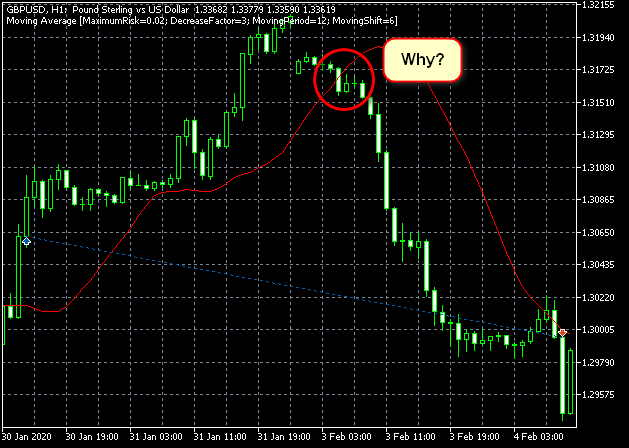
Figura 18. ¿Ha sido un error en la comprensión del algoritmo? ¿O del simulador?
Lo más probable es que simplemente hayamos buscado mal, por lo que no hemos encontrado la razón de este comportamiento en el algoritmo.
El segundo hecho extraño es que el asesor experto ha realizado 20 transacciones más de las que sugería nuestro recuadro. No obstante, los resultados, paradójicamente, resultan próximos a los nuestros.
Asi que:
| Asesor experto en el simulador | Recuadro |
|---|---|
| Esperanza matemática — +0,07 (casi 0) | Esperanza matemática — -0,76 — +0,41 (oscila alrededor de 0) |
| Transacciones rentables/no rentables: 26,52%/73,48% | Transacciones rentables/no rentables — 29,22%/70,78% (una diferencia del 3% en este caso; si tenemos en cuenta una diferencia del 8% en el número de transacciones, podemos considerarlo insignificante) |
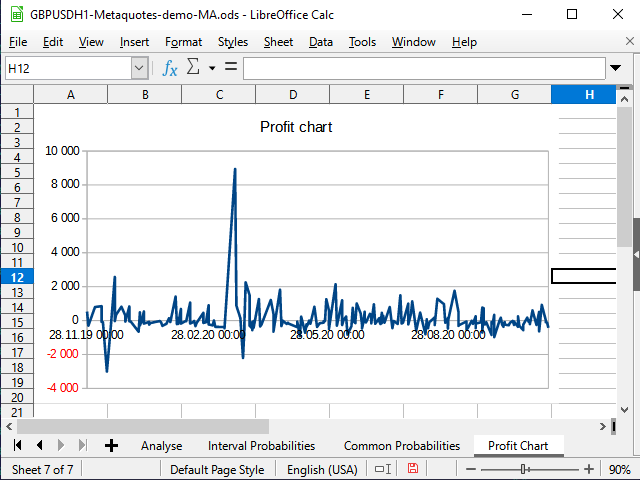
Figura 19. Gráfico de rentabilidad en el recuadro
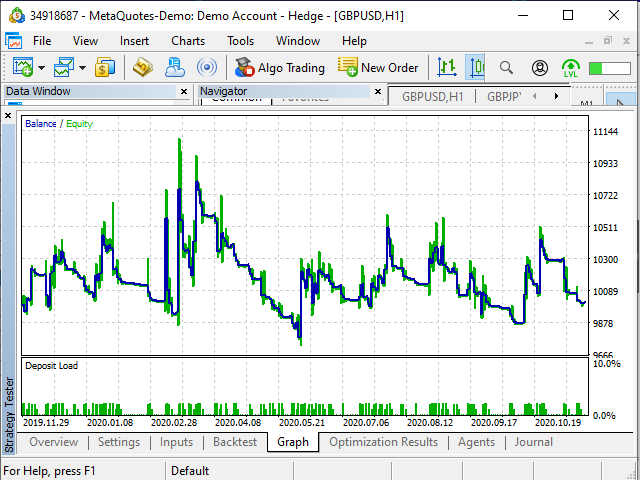
Figura 20. Gráfico de beneficios en el simulador
El tiempo de preparación del recuadro y el "juego" con los números es de aproximadamente media hora. Es hora de escribir un asesor... No hemos escrito uno, lo hemos buscado ya listo. Hemos necesitado unos 10 minutos para tener una idea aproximada del algoritmo. No obstante, no necesitamos escribir un nuevo asesor experto para entender que probablemente no lo necesitemos... No debemos perder tiempo en ello. Ahora bien, si entendemos que la estrategia vale la pena; bueno, entonces sí que podemos. Entre tanto, preferimos el comercio manual :-)
Conclusión
En nuestra opinión, las hojas de cálculo son una muy buena herramienta para probar y desarrollar nuestras estrategias, especialmente si no sabemos o no nos gusta programar, o queremos crear rápidamente un prototipo y luego transferirlo a MQL.
Las fórmulas de los procesadores de recuadros, obviamente, se asemejan a veces al código del programa, y el formato allí es, digamos, menos obvio.
No obstante, la visibilidad de los propios recuadros, la prueba instantánea de nuevas ideas, el resaltado de las celdas influyentes, la capacidad de construir diagramas de cualquier tipo, etcétera, hacen de los recuadro una herramienta indispensable.
Y si mantenemos un registro de transacciones en un recuadro o podemos importarlo usando procesadores de recuadros, podremos mejorar fácilmente nuestra estrategia y ver si hay errores en nuestra forma de comerciar.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/8699
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Desarrollando un algoritmo de autoadaptación (Parte I): Encontrando un patrón básico
Desarrollando un algoritmo de autoadaptación (Parte I): Encontrando un patrón básico
 Redes neuronales: así de sencillo (Parte 8): Mecanismos de atención
Redes neuronales: así de sencillo (Parte 8): Mecanismos de atención
 Perceptrón Multicapa y Algoritmo de Retropropagación
Perceptrón Multicapa y Algoritmo de Retropropagación
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Oleh Fedorov,
Muchas gracias por escribir este artículo. Tengo más de 75 años y conocimientos básicos de Excel. Pero debido a más de 35 años en el comercio, entiendo conjuntos de datos y cómo utilizarlos para hacer un estudio de probabilidad.
Somos un grupo de personas mayores que operamos en pequeñas cuentas por diversión y para mantener vivo el cerebro. Crear e implementar ideas a partir de un estudio de probabilidades nos mantiene activos y felices.
Así que doy la bienvenida a su artículo. Felicitaciones.
1. ¿Puede usted por favor me da una herramienta para generar MT5 datos de la historia en un formato que puedo utilizar y generar datos según hoja de cálculo diseñado.
En la actualidad, si el indicador tiene botón de exportación, soy capaz de generar un archivo csv que lo guardo como una hoja de Excel y hacer el análisis.
Me han dicho que hay un csv haciendo indicador mql que puede utilizar la lógica de cualquier otro indicador y generar datos csv en un archivo de formato pre-hechos que pueden ser modificados para hacer nuevas columnas de hoja de cálculo.
Puede usted por favor informar donde puedo comprar este indicador?
2. Quiero realizar estudios de probabilidades creando heatmaps como este en Excel. ¿Puede por favor enseñar esto en su nuevo artículo?
Ejemplo: Quiero crear un mapa de calor como este. Después de generar el archivo csv a través de un indicador, ¿cómo puedo hacerlo paso a paso convertirlo en un Excel, filtrarlo y producir heatmaps u otros informes como este archivo adjunto?
Gracias de nuevo