
Desarrollamos un asesor experto multidivisa (Parte 9): Recopilamos los resultados de optimización de las instancias individuales de una estrategia comercial
Introducción
En los artículos anteriores, ya hemos hecho bastantes cosas que son valiosas por sí mismas. Tenemos una estrategia comercial o varias estrategias comerciales que podemos implementar en el EA. Asimismo, hemos desarrollado un esquema para combinar muchas instancias de estrategias comerciales en un asesor experto. También hemos añadido herramientas para gestionar la reducción máxima permitida, y hemos estudiado posibles formas de automatizar la selección de conjuntos de parámetros de estrategias para que funcionen mejor en un grupo. Además, hemos montado un EA a partir de grupos de instancias de estrategias e incluso a partir de grupos de diferentes grupos de instancias de estrategias. Pero el valor de los resultados ya obtenidos aumentará enormemente si logramos combinarlos.
En el marco de este artículo, intentaremos esbozar un esquema general del proceso: las estrategias comerciales individuales en la entrada, así como la obtención en la salida de un asesor experto listo para usar que utiliza las instancias seleccionadas y agrupadas de las estrategias comerciales originales que ofrecen los mejores resultados comerciales.
Después de trazar un mapa aproximado, podremos ver más de cerca cualquier sección del mapa, analizar qué necesitamos para poner en marcha la etapa elegida y pasar a la ejecución.
Etapas principales
Vamos a enumerar las principales etapas por las que tenemos que pasar en el proceso de desarrollo de un asesor comercial:
- Aplicación de la estrategia comercial. Desarrollamos una clase heredera de CVirtualStrategy que implementa la lógica comercial de apertura, el mantenimiento y el cierre de posiciones y órdenes virtuales. De esto nos hemos ocupado en las cuatro primeras partes de la serie.
- Optimización de la estrategia comercial. Seleccionamos buenos conjuntos de parámetros de entrada de estrategias comerciales que muestran resultados dignos de mención. Si no se detecta ninguno, regresamos al paso 1.
Por lo general, nos sentimos más cómodos realizando la optimización en un único símbolo y marco temporal. Para la optimización genética, probablemente tendremos que ejecutarla varias veces con distintos criterios de optimización, incluidos algunos propios. La optimización por fuerza bruta total solo puede utilizarse en estrategias con un número muy reducido de parámetros. Incluso en nuestra estrategia de modelado, la iteración completa resulta demasiado costosa. Así que a continuación, cuando hablemos de optimización,
nos referiremos precisamente a la optimización genética en el simulador de estrategias de MetaTrader5. No hemos descrito el proceso de optimización detalladamente en los artículos, ya que es estándar. - Realización de la clusterización de conjuntos. Este paso es opcional, pero nos ahorrará tiempo para el siguiente paso. Aquí reducimos significativamente el número de conjuntos de parámetros de instancias de estrategias comerciales entre los que seleccionaremos buenos grupos. Se menciona en la sexta parte.
- Selección de grupos de conjuntos de parámetros. Basándonos en los resultados del paso anterior, realizamos una optimización que selecciona
los conjuntos de parámetros más compatibles de las instancias de estrategias comerciales que ofrecen los mejores resultados. También se describe en su mayor parte en la sexta parte y se desarrolla en la séptima parte. - Selección de grupos a partir de grupos de conjuntos de parámetros. Ahora combinamos los resultados del paso anterior en grupos según el mismo principio con el que combinamos los conjuntos de parámetros de instancias individuales del modo comercial de la recopilación de frames de la estrategia.
- Iteración de símbolos y marcos temporales. Luego repetiremos los pasos 2 - 5 para todos los símbolos y marcos temporales deseados. Tal vez, además del símbolo y el marco temporal, para algunas estrategias comerciales sea posible realizar una optimización por separado de determinadas clases de otros parámetros de entrada.
- Otras estrategias. Si tiene en mente otras estrategias comerciales, repita los pasos 1 a 6 para cada una de ellas.
- Montaje del asesor experto. Todos los mejores grupos de grupos encontrados para diferentes estrategias comerciales, símbolos, plazos y otros parámetros se recogen en un asesor experto final.
Cada etapa, una vez completada, genera unos datos que deben almacenarse y usarse en las etapas siguientes. Hasta ahora nos hemos conformado con herramientas temporales, lo bastante prácticas para utilizarse una o dos veces, pero no especialmente prácticas para un uso repetido.
Por ejemplo, los resultados de la optimización tras la segunda fase los guardábamos en un archivo Excel, le añadíamos manualmente las columnas que faltaban y lo utilizábamos en la tercera fase guardándolo como archivo CSV.
Los resultados de la tercera fase los utilizábamos o bien directamente desde la interfaz del simulador de estrategias o los guardábamos en archivos Excel; ahí realizábamos algunos procesamientos y volvíamos a utilizar los resultados obtenidos desde la interfaz del simulador.
En realidad, no realizábamos la quinta fase, sino que nos limitábamos a señalar la posibilidad de llevarla a cabo. Por lo tanto, no llegamos a los resultados.
Para todos estos datos resultantes nos gustaría realizar un esquema unificado de almacenamiento y uso.
Opciones de implementación
De hecho, el principal tipo de datos que necesitamos almacenar y usar son los resultados de la optimización de múltiples EAs. Como usted sabrá, el simulador de estrategias registra todos los resultados de la optimización en un archivo de caché separado con la extensión *.opt, que puede ser nuevamente abierto en el simulador o incluso abierto en el simulador de otro terminal MetaTrader5. El nombre del archivo se determina a partir de un hash calculado según el nombre del asesor experto que se está optimizando y de los parámetros de optimización. Esto nos permite no perder información sobre las pasadas ya realizadas al continuar la optimización tras su interrupción anticipada o tras cambiar el criterio de optimización.
Por lo tanto, una de las opciones a considerar sería utilizar archivos de caché de optimización para almacenar los resultados intermedios. Existe una buena biblioteca de fxsaber para trabajar con ellos, gracias a la cual podemos acceder a toda la información guardada de los programas MQL5.
Sin embargo, a medida que crezca el número de optimizaciones realizadas, también lo hará el número de archivos con sus resultados. Para no confundirnos en ellos, tendremos que idear algún esquema adicional para organizar el almacenamiento y trabajar con estos archivos de caché. Si la optimización se va a realizar en más de un servidor, tendremos que implementar la sincronización o el apilamiento de todos los archivos de caché en un solo lugar. Además, para la siguiente etapa todavía necesitaremos algún procesamiento para exportar los resultados de la optimización al EA en la siguiente etapa.
A continuación, organizaremos el almacenamiento de todos los resultados en una base de datos. A primera vista, la aplicación de esta medida requeriría mucho tiempo, pero este trabajo puede dividirse en etapas más pequeñas y sus resultados pueden utilizarse inmediatamente, sin esperar a la aplicación completa. Además, este enfoque tiene más libertad a la hora de elegir los medios más cómodos para el procesamiento intermedio de los resultados almacenados. Por ejemplo, podemos asignar parte del procesamiento a consultas SQL simples, otra parte se calculará en MQL5 y otra parte se calculará en programas escritos en Python o R, por ejemplo. Podemos probar distintas opciones de procesamiento y elegir la más adecuada.
MQL5 ofrece funciones incorporadas para trabajar con la base de datos SQLite. También hemos encontrado implementaciones de bibliotecas de terceros que permiten trabajar con MySQL, por ejemplo. Aún no está claro si SQLite nos bastará, pero lo más probable es que esta base de datos sea suficiente para nuestras necesidades. Si no es suficiente, entonces pensaremos en migrar a otro SGBD.
Empezamos a diseñar la base de datos
En primer lugar, tendremos que identificar las entidades cuya información queremos almacenar. Este es sin duda el caso de una sola pasada del simulador. Los campos de esta entidad incluirán campos de datos de entrada de prueba y campos de resultados de prueba. En principio, resulta posible separarlas en entidades distintas. La entidad de datos de entrada puede desglosarse en entidades más pequeñas: el asesor experto, los ajustes de optimización y los parámetros de una sola pasada del asesor experto. Sin embargo, le propongo seguir guiándonos por el principio de la menor acción. Para empezar, bastará con una tabla que contenga campos para los resultados de las pasadas que utilizamos en artículos anteriores y uno o dos campos de texto para colocar la información necesaria sobre los parámetros de entrada de la pasada.
Una tabla de este tipo puede crearse usando una consulta SQL:
CREATE TABLE passes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
pass INT, -- pass index
inputs TEXT, -- pass input values
params TEXT, -- additional pass data
initial_deposit REAL, -- pass results...
withdrawal REAL,
profit REAL,
gross_profit REAL,
gross_loss REAL,
max_profittrade REAL,
max_losstrade REAL,
conprofitmax REAL,
conprofitmax_trades REAL,
max_conwins REAL,
max_conprofit_trades REAL,
conlossmax REAL,
conlossmax_trades REAL,
max_conlosses REAL,
max_conloss_trades REAL,
balancemin REAL,
balance_dd REAL,
balancedd_percent REAL,
balance_ddrel_percent REAL,
balance_dd_relative REAL,
equitymin REAL,
equity_dd REAL,
equitydd_percent REAL,
equity_ddrel_percent REAL,
equity_dd_relative REAL,
expected_payoff REAL,
profit_factor REAL,
recovery_factor REAL,
sharpe_ratio REAL,
min_marginlevel REAL,
deals REAL,
trades REAL,
profit_trades REAL,
loss_trades REAL,
short_trades REAL,
long_trades REAL,
profit_shorttrades REAL,
profit_longtrades REAL,
profittrades_avgcon REAL,
losstrades_avgcon REAL,
complex_criterion REAL,
custom_ontester REAL,
pass_date DATETIME DEFAULT (datetime('now') )
NOT NULL
);
Vamos a crear la clase auxiliar CDatabase, que contendrá los métodos de trabajo con la base de datos. Podemos hacerla estática, ya que no necesitaremos muchas instancias en un programa, con una será suficiente. Como por ahora pensamos acumular toda la información en una sola base de datos, podemos establecer rígidamente el nombre del archivo de la base de datos en el código fuente.
Como parte de esta clase, tendremos el campo s_db para almacenar el handle de la base de datos abierta. El método Open(), encargado de abrir la base de datos, establecerá su valor. Si la base de datos aún no se ha creado en el momento de la apertura, se creará llamando al método Create(). Una vez abierto, podremos ejecutar consultas SQL individuales a la base de datos utilizando el método Execute() o consultas SQL masivas en una única transacción utilizando el método ExecuteTransaction(). Al final, cerraremos la base de datos usando el método Close().
También podemos declarar una macro corta que nos permita utilizar el nombre DB, más breve, en lugar del nombre de clase CDatabase, más largo.
#define DB CDatabase //+------------------------------------------------------------------+ //| Class for handling the database | //+------------------------------------------------------------------+ class CDatabase { static int s_db; // DB connection handle static string s_fileName; // DB file name public: static bool IsOpen(); // Is the DB open? static void Create(); // Create an empty DB static void Open(); // Opening DB static void Close(); // Closing DB // Execute one query to the DB static bool Execute(string &query); // Execute multiple DB queries in one transaction static bool ExecuteTransaction(string &queries[]); }; int CDatabase::s_db = INVALID_HANDLE; string CDatabase::s_fileName = "database.sqlite";
En el método de creación de la base de datos, por ahora nos limitaremos a crear un array con consultas SQL para crear tablas y ejecutarlas en una única transacción:
//+------------------------------------------------------------------+ //| Create an empty DB | //+------------------------------------------------------------------+ void CDatabase::Create() { // Array of DB creation requests string queries[] = { "DROP TABLE IF EXISTS passes;", "CREATE TABLE passes (" "id INTEGER PRIMARY KEY AUTOINCREMENT," "pass INT," "inputs TEXT," "params TEXT," "initial_deposit REAL," "withdrawal REAL," "profit REAL," "gross_profit REAL," "gross_loss REAL," ... "pass_date DATETIME DEFAULT (datetime('now') ) NOT NULL" ");" , }; // Execute all requests ExecuteTransaction(queries); }
En el método de apertura de base de datos, primero intentaremos abrir un archivo de base de datos existente. Si no existe, la crearemos y la abriremos; luego crearemos la estructura de la base de datos llamando al método Create():
//+------------------------------------------------------------------+ //| Is the DB open? | //+------------------------------------------------------------------+ bool CDatabase::IsOpen() { return (s_db != INVALID_HANDLE); } ... //+------------------------------------------------------------------+ //| Open DB | //+------------------------------------------------------------------+ void CDatabase::Open() { // Try to open an existing DB file s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_COMMON); // If the DB file is not found, try to create it when opening if(!IsOpen()) { s_db = DatabaseOpen(s_fileName, DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE | DATABASE_OPEN_COMMON); // Report an error in case of failure if(!IsOpen()) { PrintFormat(__FUNCTION__" | ERROR: %s open failed with code %d", s_fileName, GetLastError()); return; } // Create the database structure Create(); } PrintFormat(__FUNCTION__" | Database %s opened successfully", s_fileName); }
En el método ExecuteTransaction() de ejecución de consultas múltiples, crearemos una transacción y comenzaremos a ejecutar todas las consultas SQL una a una en un ciclo. Si se produce un error durante la ejecución de la siguiente solicitud, interrumpiremos el ciclo, informaremos sobre el error y cancelaremos todas las solicitudes anteriores dentro de esta transacción. Si no hay errores, confirmaremos la transacción:
//+------------------------------------------------------------------+ //| Execute multiple DB queries in one transaction | //+------------------------------------------------------------------+ bool CDatabase::ExecuteTransaction(string &queries[]) { // Open a transaction DatabaseTransactionBegin(s_db); bool res = true; // Send all execution requests FOREACH(queries, { res &= Execute(queries[i]); if(!res) break; }); // If an error occurred in any request, then if(!res) { // Report it PrintFormat(__FUNCTION__" | ERROR: Transaction failed, error code=%d", GetLastError()); // Cancel transaction DatabaseTransactionRollback(s_db); } else { // Otherwise, confirm transaction DatabaseTransactionCommit(s_db); PrintFormat(__FUNCTION__" | Transaction done successfully"); } return res; }
Luego guardaremos los cambios realizados en el archivo Database.mqh en la carpeta actual.
Modificación del asesor experto para recoger los datos de optimización
Cuando en el proceso de optimización solo se usan agentes en la computadora local, podemos hacer que los resultados de la pasada se guarden en la base de datos o bien en el manejador de eventos OnTester() o bien en el manejador de eventos OnDeinit(). Al usar agentes en la red local o agentes en la MQL5 Cloud Network, será muy difícil, si no imposible, guardar los resultados. Por fortuna, MQL5 ofrece un fabuloso método estándar para obtener cualquier información de los agentes de prueba, estén donde estén, a través de la creación, el envío y la recepción de marcos de datos.
Este mecanismo se describe con suficiente detalle en la guía y en el manual sobre trading algorítmico. Para poder utilizarlo, tendremos que añadir tres manejadores de eventos adicionales al EA optimizado: OnTesterInit(), OnTesterPass() y OnTesterDeinit().
La optimización se iniciará siempre desde cualquier terminal MetaTrader 5; en lo sucesivo, nos referiremos a este como terminal principal. Al iniciar un EA con dichos manejadores desde el terminal principal, antes de distribuir las instancias del EA a los agentes de prueba para que realicen pasadas de optimización normales con diferentes conjuntos de parámetros, se abrirá un nuevo gráfico en el terminal principal y se iniciará otra instancia del EA en este gráfico.
Esta instancia se ejecutará en un modo especial: no ejecutará los manejadores estándar OnInit(), OnTick() y OnDeinit(), sino solo estos tres nuevos manejadores. Este modo tiene incluso su propio nombre: el modo de recogida de frames de los resultados de la optimización. Si es necesario, en las funciones del asesor experto, podemos comprobar que el EA se esté ejecutando en este modo utilizando esta llamada a la función MQLInfoInteger():
// Check if the EA is running in data frame collection mode bool isFrameMode = MQLInfoInteger(MQL_FRAME_MODE);
Como sugieren sus nombres, en el modo de recogida de frames, el manejador OnTesterInit() se ejecuta una vez antes de que comience el proceso de optimización, OnTesterPass() se ejecuta cada vez que uno de los agentes de prueba completa una pasada, y OnTesterDeinit() se ejecuta una vez después de que todas las pasadas de optimización programadas se hayan completado o interrumpido.
Es precisamente la instancia del EA ejecutada en el gráfico del terminal principal en el modo de recogida de frames la que se encargará de recoger los frames de datos de todos los agentes de prueba. El "frame de datos" es solo un nombre cómodo de usar al describir los procesos de intercambio de información entre los agentes de prueba y el EA en el terminal principal. Denota un conjunto de datos con un nombre y un identificador numérico que el agente de pruebas ha creado y enviado al terminal principal tras completar la siguiente pasada de optimización.
Cabe señalar que tiene sentido crear frames de datos solo en las instancias del EA que se ejecutan en el modo normal en los agentes de pruebas, y recopilar y procesar frames de datos solo en la instancia del EA en el terminal principal que se ejecuta en el modo de recopilación de frames. Empezaremos con el proceso de creación de frames.
Podemos ubicar la creación de frames en el asesor experto en el manejador OnTester() o en cualquier función o método llamado desde OnTester(). Este manejador se iniciará justo después de finalizar la pasada, y podremos obtener en él los valores de todas las características estadísticas de la pasada realizada y, si es necesario, calcular el valor del criterio de usuario para evaluar los resultados de la pasada.
En este momento tenemos un código que calcula un criterio personalizado que muestra el beneficio proyectado que podría obtenerse suponiendo una reducción máxima alcanzable del 10%:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = fixedBalance_ * 0.1 / balanceDrawdown; // Recalculate the profit double fittedProfit = profit * coeff; return fittedProfit; }
Vamos a trasladar este código del archivo del EA SimpleVolumesExpertSingle.mq5 a un nuevo método de la clase CVirtualAdvisor, y a dejar solo el retorno del resultado de la llamada a este método en el EA:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { return expert.Tester(); }
Al realizar al traslado, deberemos tener en cuenta que ya no podemos utilizar la variable fixedBalance_ dentro del método, ya que puede no existir en otro EA. Pero su valor puede obtenerse de la clase estática CMoney llamando al método CMoney::FixedBalance(). Mientras tanto, introduciremos un cambio adicional en el cálculo de nuestro criterio personalizado. Una vez determinado el beneficio previsto, lo convertiremos en una unidad de tiempo, como el beneficio por año. Esto nos permitirá comparar a grandes rasgos los resultados de las pasadas a lo largo de distintos periodos de tiempo entre sí.
Para ello, necesitaremos recordar la fecha inicial de la prueba en el asesor experto. Vamos a añadir la nueva propiedad m_fromDate en la que escribiremos la hora actual en el constructor del objeto de asesor experto.
//+------------------------------------------------------------------+ //| Class of the EA handling virtual positions (orders) | //+------------------------------------------------------------------+ class CVirtualAdvisor : public CAdvisor { protected: ... datetime m_fromDate; public: ... virtual double Tester() override; // OnTester event handler ... }; //+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, ~((CVirtualStrategy *) m_strategies[0])); return fittedProfit; }
Puede que en el futuro realicemos algunos criterios de optimización personalizados y entonces este código se traslade otra vez a una nueva ubicación. No obstante, por ahora nos mantendremos alejados del extenso tema de la investigación de varias funciones de aptitud para optimizar EAs y dejaremos este código como está.
Ahora vamos a añadir al archivo del asesor experto SimpleVolumesExpertSingle.mq5 los nuevos manejadores OnTesterInit(), OnTesterPass() y OnTesterDeinit(). Como según nuestra idea la lógica de estas funciones debe ser la misma para todos los asesores expertos, primero bajaremos su implementación al nivel del asesor experto (un objeto de la clase CVirtualAdvisor).
Hay que tener en cuenta que cuando el asesor experto se inicie en el terminal principal en el modo de recogida de frames, la función OnInit(), en la que se crea la instancia del EA, no se ejecutará. Por lo tanto, para no añadir también la creación/eliminación de la instancia del EA a los nuevos manejadores, haremos que los métodos para procesar estos eventos sean estáticos en la clase CVirtualAdvisor. A continuación, tendremos que añadir el siguiente código al EA:
//+------------------------------------------------------------------+ //| Initialization before starting optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { return CVirtualAdvisor::TesterInit(); } //+------------------------------------------------------------------+ //| Actions after completing the next optimization pass | //+------------------------------------------------------------------+ void OnTesterPass() { CVirtualAdvisor::TesterPass(); } //+------------------------------------------------------------------+ //| Actions after optimization is complete | //+------------------------------------------------------------------+ void OnTesterDeinit(void) { CVirtualAdvisor::TesterDeinit(); }
Un cambio más que podemos introducir en el futuro es deshacernos de la llamada aparte para el método de adición de estrategias comerciales al asesor experto CVirtualAdvisor::Add() después de crear el asesor experto. En su lugar, transmitiremos la información sobre las estrategias al constructor del EA, y este llamará al método Add() por sí mismo. Entonces este método podrá eliminarse de la parte pública.
Con este enfoque, la función de inicialización OnInit() del EA tendrá este aspecto:
int OnInit() { CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor( new CSimpleVolumesStrategy( symbol_, timeframe_, signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_, takeLevel_, ordersExpiration_, maxCountOfOrders_, 0), // One strategy instance magic_, "SimpleVolumesSingle", true); return(INIT_SUCCEEDED); }
Luego guardaremos los cambios realizados en el archivo SimpleVolumesExpertSingle.mq5 en la carpeta actual.
Modificación de la clase de experto
Para no sobrecargar de código la clase de experto CVirtualAdvisor, sacaremos el código de los manejadores de eventos TesterInit, TesterPass y OnTesterDeinit a la clase aparte CTesterHandler, en la que crearemos los métodos estadísticos para procesar cada uno de estos eventos. Entonces en la clase CVirtualAdvisor solo necesitaremos añadir aproximadamente el mismo código que en el archivo de EA principal:
//+------------------------------------------------------------------+ //| Class of the EA handling virtual positions (orders) | //+------------------------------------------------------------------+ class CVirtualAdvisor : public CAdvisor { ... public: ... static int TesterInit(); // OnTesterInit event handler static void TesterPass(); // OnTesterDeinit event handler static void TesterDeinit(); // OnTesterDeinit event handler }; //+------------------------------------------------------------------+ //| Initialization before starting optimization | //+------------------------------------------------------------------+ int CVirtualAdvisor::TesterInit() { return CTesterHandler::TesterInit(); } //+------------------------------------------------------------------+ //| Actions after completing the next optimization pass | //+------------------------------------------------------------------+ void CVirtualAdvisor::TesterPass() { CTesterHandler::TesterPass(); } //+------------------------------------------------------------------+ //| Actions after optimization is complete | //+------------------------------------------------------------------+ void CVirtualAdvisor::TesterDeinit() { CTesterHandler::TesterDeinit(); }
Asimismo, realizaremos algunas adiciones al código del constructor del objeto de asesor experto. De cara al futuro, trasladaremos todas las acciones del constructor al nuevo método de inicialización Init(). Esto nos permitirá añadir múltiples constructores con distintos conjuntos de parámetros que utilizarán el mismo método de inicialización después de un pequeño preprocesamiento de los parámetros.
Luego añadiremos constructores cuyo primer argumento será un objeto de estrategia o un objeto de grupo de estrategias. Entonces podremos añadir estrategias al asesor experto directamente en el constructor. En este caso, ya no necesitaremos llamar al método Add() en la función OnInit() del asesor experto.
//+------------------------------------------------------------------+ //| Class of the EA handling virtual positions (orders) | //+------------------------------------------------------------------+ class CVirtualAdvisor : public CAdvisor { protected: ... datetime m_fromDate; public: CVirtualAdvisor(CVirtualStrategy *p_strategy, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false); // Constructor CVirtualAdvisor(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false); // Constructor void CVirtualAdvisor::Init(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ); ... }; ... //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(CVirtualStrategy *p_strategy, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ) { CVirtualStrategy *strategies[] = {p_strategy}; Init(new CVirtualStrategyGroup(strategies), p_magic, p_name, p_useOnlyNewBar); }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ) { Init(p_group, p_magic, p_name, p_useOnlyNewBar); }; //+------------------------------------------------------------------+ //| EA initialization method | //+------------------------------------------------------------------+ void CVirtualAdvisor::Init(CVirtualStrategyGroup *p_group, ulong p_magic = 1, string p_name = "", bool p_useOnlyNewBar = false ) { // Initialize the receiver with a static receiver m_receiver = CVirtualReceiver::Instance(p_magic); // Initialize the interface with the static interface m_interface = CVirtualInterface::Instance(p_magic); m_lastSaveTime = 0; m_useOnlyNewBar = p_useOnlyNewBar; m_name = StringFormat("%s-%d%s.csv", (p_name != "" ? p_name : "Expert"), p_magic, (MQLInfoInteger(MQL_TESTER) ? ".test" : "") ); m_fromDate = TimeCurrent(); Add(p_group); delete p_group; };
Guardaremos los cambios realizados en el archivo VirtualExpert.mqh en la carpeta actual.
Clase de procesamiento de eventos de optimización
Ahora nos centraremos directamente en la aplicación de las acciones anteriores y posteriores a la pasada, así como de las acciones tras la finalización de la optimización. Crearemos la clase CTesterHandler y le añadiremos los métodos de procesamiento de los eventos necesarios, además de un par de métodos auxiliares situados en la parte privada de la clase:
//+------------------------------------------------------------------+ //| Optimization event handling class | //+------------------------------------------------------------------+ class CTesterHandler { static string s_fileName; // File name for writing frame data static void ProcessFrames(); // Handle incoming frames static string GetFrameInputs(ulong pass); // Get pass inputs public: static int TesterInit(); // Handle the optimization start in the main terminal static void TesterDeinit(); // Handle the optimization completion in the main terminal static void TesterPass(); // Handle the completion of a pass on an agent in the main terminal static void Tester(const double OnTesterValue, const string params); // Handle completion of tester pass for agent }; string CTesterHandler::s_fileName = "data.bin"; // File name for writing frame data
Los manejadores de eventos para el terminal principal parecen muy simples, ya que pondremos el código principal en funciones auxiliares:
//+------------------------------------------------------------------+ //| Handling the optimization start in the main terminal | //+------------------------------------------------------------------+ int CTesterHandler::TesterInit(void) { // Open / create a database DB::Open(); // If failed to open it, we do not start optimization if(!DB::IsOpen()) { return INIT_FAILED; } // Close a successfully opened database DB::Close(); return INIT_SUCCEEDED; } //+------------------------------------------------------------------+ //| Handling the optimization completion in the main terminal | //+------------------------------------------------------------------+ void CTesterHandler::TesterDeinit(void) { // Handle the latest data frames received from agents ProcessFrames(); // Close the chart with the EA running in frame collection mode ChartClose(); } //+--------------------------------------------------------------------+ //| Handling the completion of a pass on an agent in the main terminal | //+--------------------------------------------------------------------+ void CTesterHandler::TesterPass(void) { // Handle data frames received from the agent ProcessFrames(); }
Las acciones realizadas tras completar una pasada existirán en dos variantes:
- Para el agente de pruebas. Allí se recogerá la información necesaria tras la pasada y se creará un frame de datos que se enviará al terminal principal. Estas acciones se recogerán en el manejador de eventos Tester().
- Para el terminal principal. Aquí podremos realizar acciones sobre la obtención de los frames de datos de los agentes de pruebas, el análisis sintáctico de la información obtenida en el frame y su introducción en la base de datos. Estas acciones se recogerán en el manejador TesterPass().
Las acciones para generar un frame de datos para el agente de pruebas deberán realizarse en el EA dentro del manejador OnTester. Como hemos trasladado su código al nivel del objeto de asesor experto (a la clase CVirtualAsesor), es ahí donde deberemos añadir la llamada al método CTesterHandler::Tester(). Como parámetros de este método, transmitiremos el valor recién calculado del criterio de optimización personalizado y una cadena que describa los parámetros de la estrategia utilizada en el asesor experto que estamos optimizando. Para formar dicha cadena, utilizaremos el operador ~ (tilde o virgulilla) para los objetos de la clase CVirtualStrategy.
//+------------------------------------------------------------------+ //| OnTester event handler | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Calculate the profit in annual terms long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Perform data frame generation on the test agent CTesterHandler::Tester(fittedProfit, ~((CVirtualStrategy *) m_strategies[0])); return fittedProfit; }
En el propio método CTesterHandler::Tester(), iteraremos todos los nombres posibles de las características estadísticas disponibles, obtendremos sus valores, los convertiremos en cadenas y añadiremos estas cadenas al array stats. ¿Por qué debemos convertir las características numéricas reales en cadenas? Solo para que podamos transmitirlas en el mismo frame con una descripción de cadena de los parámetros de la estrategia. En un frame, podremos transmitir un array de valores de uno de los tipos simples (a los que no pertenecen las cadenas), o un archivo creado previamente con cualquier dato. Así que, para evitar el lío de enviar dos frames diferentes (uno con números y otro con cadenas de un archivo), convertiremos todos los datos en cadenas, los escribiremos en un archivo y enviaremos su contenido en un único frame:
//+------------------------------------------------------------------+ //| Handling completion of tester pass for agent | //+------------------------------------------------------------------+ void CTesterHandler::Tester(double custom, // Custom criteria string params // Description of EA parameters in the current pass ) { // Array of names of saved statistical characteristics of the pass ENUM_STATISTICS statNames[] = { STAT_INITIAL_DEPOSIT, STAT_WITHDRAWAL, STAT_PROFIT, ... }; // Array for values of statistical characteristics of the pass as strings string stats[]; ArrayResize(stats, ArraySize(statNames)); // Fill the array of values of statistical characteristics of the pass FOREACH(statNames, stats[i] = DoubleToString(TesterStatistics(statNames[i]), 2)); // Add the custom criterion value to it APPEND(stats, DoubleToString(custom, 2)); // Screen the quotes in the description of parameters just in case StringReplace(params, "'", "\\'"); // Open the file to write data for the frame int f = FileOpen(s_fileName, FILE_WRITE | FILE_TXT | FILE_ANSI); // Write statistical characteristics FOREACH(stats, FileWriteString(f, stats[i] + ",")); // Write a description of the EA parameters FileWriteString(f, StringFormat("'%s'", params)); // Close the file FileClose(f); // Create a frame with data from the recorded file and send it to the main terminal if(!FrameAdd("", 0, 0, s_fileName)) { PrintFormat(__FUNCTION__" | ERROR: Frame add error: %d", GetLastError()); } }
Por último, un método auxiliar que aceptará frames de datos y guardará la información de los mismos en la base de datos. En él, iteraremos en un ciclo todos los frames entrantes que aún no hayan sido procesados en el momento actual. Luego obtendremos los datos de cada frame como un array de símbolos y los convertiremos en una cadena. A continuación formaremos una cadena con los nombres y valores de los parámetros de la pasada con el índice dado. Después utilizaremos los valores obtenidos para formar una consulta SQL que inserte una nueva fila en la tabla passes de nuestra base de datos. Acto seguido, añadiremos la consulta SQL creada al array de consultas SQL.
Tras procesar todos los frames de datos obtenidos hasta el momento, ejecutaremos todas las consultas SQL del array dentro de una única transacción.
//+------------------------------------------------------------------+ //| Handling incoming frames | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Open the database DB::Open(); // Variables for reading data from frames string name; // Frame name (not used) ulong pass; // Frame pass index long id; // Frame type ID (not used) double value; // Single frame value (not used) uchar data[]; // Frame data array as a character array string values; // Frame data as a string string inputs; // String with names and values of pass parameters string query; // A single SQL query string string queries[]; // SQL queries for adding records to the database // Go through frames and read data from them while(FrameNext(pass, name, id, value, data)) { // Convert the array of characters read from the frame into a string values = CharArrayToString(data); // Form a string with names and values of the pass parameters inputs = GetFrameInputs(pass); // Form an SQL query from the received data query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %s,\n'%s',\n'%s');", pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Add it to the SQL query array APPEND(queries, query); } // Execute all requests DB::ExecuteTransaction(queries); // Close the database DB::Close(); }
El método auxiliar encargado de formar una cadena con los nombres y valores de las variables de entrada de la pasada GetFrameInputs() está tomado del manual sobre trading algorítmico y ligeramente complementado para nuestras necesidades.
Luego guardaremos el código obtenido en el archivo TesterHandler.mqh en la carpeta actual.
Comprobación del funcionamiento
Para comprobar el rendimiento, ejecutaremos la optimización con un número reducido de parámetros a buscar durante un periodo de tiempo no muy amplio. Una vez finalizado el proceso de optimización, podremos consultar los resultados en el simulador de estrategias y en la base de datos creada.
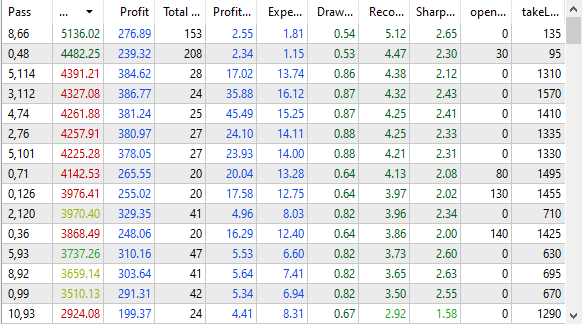
Figura 1. Resultados de la optimización en el simulador de estrategias
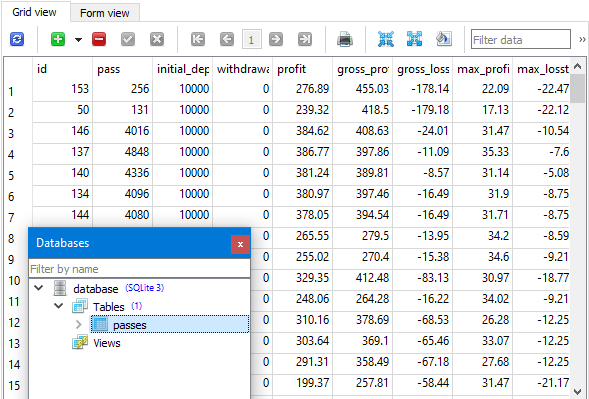
Figura 2. Resultados de la optimización en la base de datos
Como podemos observar, los resultados en la base de datos coinciden con los resultados en el simulador: con la misma clasificación según el criterio de usuario, observamos la misma secuencia de valores de beneficio en ambos lugares. La mejor pasada nos informa de que en un año el beneficio esperado puede ser superior a 5 000$ con un depósito inicial de 10 000$ y una reducción de fondos máxima alcanzable del 10% del depósito inicial (1 000$). Pero ahora no nos preocupan tanto las características cuantitativas de los resultados de la optimización como el hecho de que estos resultados puedan almacenarse en una base de datos.
Conclusión
Así pues, nos encontramos un paso más cerca de nuestro objetivo. Hemos logrado guardar en nuestra base de datos los resultados de las optimizaciones realizadas en los parámetros del EA. De este modo, hemos sentado las bases para la posterior aplicación automatizada de la segunda fase del desarrollo del asesor comercial.
Hasta ahora quedan bastantes preguntas entre bastidores. Durante el desarrollo de este artículo, hemos tenido que posponer muchas cosas para el futuro porque su aplicación habría sido costosa. Pero una vez obtenidos los resultados actuales, podemos formular con mayor claridad la dirección del futuro desarrollo del proyecto.
El almacenamiento implementado funciona hasta ahora solo para el proceso de optimización en el sentido de que guardamos la información sobre las pasadas, pero sigue resultando difícil identificar grupos de cadenas pertenecientes a un proceso de optimización. Para ello, deberemos introducir cambios en la estructura de la base de datos, lo cual ahora resulta extremadamente sencillo. En el futuro, intentaremos automatizar la ejecución de varios procesos de optimización consecutivos con la especificación previa de distintas variantes de los parámetros a optimizar.
¡Gracias por su atención y hasta la próxima!
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14680
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso