
Ingeniería de características con Python y MQL5 (Parte II): El ángulo del precio

Los modelos de aprendizaje automático son instrumentos muy sensibles. En esta serie de artículos, prestaremos mucha más atención a cómo las transformaciones que aplicamos a nuestros datos afectan el rendimiento de nuestro modelo. Asimismo, nuestros modelos también son sensibles a cómo se transmite la relación entre la entrada y el objetivo. Esto significa que es posible que necesitemos crear nuevas características a partir de los datos que tenemos a mano para que nuestro modelo aprenda de manera efectiva.
No hay límite para la cantidad de funciones nuevas que podemos crear a partir de nuestros datos de mercado. Las transformaciones que aplicamos a nuestros datos de mercado, y cualquier característica nueva que creemos a partir de los datos que tenemos, cambiarán nuestros niveles de error. Buscamos ayudarle a identificar qué transformaciones y técnicas de ingeniería de características cambiarán sus niveles de error más cerca de 0. Además, también observarás que cada modelo se ve afectado de forma diferente por las mismas transformaciones. Por lo tanto, este artículo también le guiará sobre qué transformaciones elegir, dependiendo de la arquitectura del modelo que tenga.
Descripción general de la estrategia comercial
Si busca en el foro MQL5, encontrará muchas publicaciones que preguntan cómo podemos calcular el ángulo formado por los cambios en los niveles de precios. La intuición es que las tendencias bajistas resultarán en ángulos negativos, mientras que las tendencias alcistas resultarán en ángulos mayores que 0. Si bien la idea es fácil de entender, no es igualmente fácil de implementar. Hay muchos obstáculos que deben superar cualquier miembro de nuestra comunidad que esté interesado en construir una estrategia que incorpore el ángulo formado por el precio. Este artículo destacará algunas de las principales cuestiones que deben abordarse antes de considerar invertir completamente su capital. Además, no sólo criticaremos las deficiencias de la estrategia, sino que también sugeriremos posibles soluciones que puedes utilizar para mejorarla.
La idea detrás del cálculo del ángulo formado por los cambios de precios es que es una fuente de confirmación. Los comerciantes normalmente utilizan líneas de tendencia para identificar la tendencia dominante en el mercado. Las líneas de tendencia normalmente unen 2 o 3 puntos de precio extremos con una línea recta. Si los niveles de precios superan la línea de tendencia, algunos operadores lo ven como una señal de fortaleza del mercado y se unen a la tendencia en ese punto. Por el contrario, si el precio se aleja de la línea de tendencia en la dirección opuesta, podría percibirse como un signo de debilidad y de que la tendencia está terminando.
Una limitación clave de las líneas de tendencia es que se definen subjetivamente. Por lo tanto, un comerciante puede ajustar arbitrariamente sus líneas de tendencia para crear un análisis que respalde su perspectiva, incluso si su perspectiva es errónea. Por lo tanto, es natural intentar definir líneas de tendencia con un enfoque más sólido. La mayoría de los comerciantes esperan hacer esto calculando la pendiente creada por los cambios en los niveles de precios. El supuesto clave es que conocer la pendiente equivale a conocer la dirección de la línea de tendencia formada por la acción del precio.
Hemos llegado ahora al primer obstáculo a superar, definir la pendiente. La mayoría de los traders intentan definir la pendiente creada por el precio como la diferencia de precio dividida por la diferencia de tiempo. Este enfoque tiene varias limitaciones. En primer lugar, los mercados de valores estarán cerrados durante el fin de semana. En nuestros terminales MetaTrader 5 no se registra el tiempo transcurrido mientras los mercados estuvieron cerrados, hay que deducirlo de los datos disponibles. Por lo tanto, al utilizar un modelo tan simple, debemos tener en cuenta que el modelo no tiene en cuenta el tiempo transcurrido durante el fin de semana. Esto significa que, si los niveles de precios abrieron durante el fin de semana, entonces nuestra estimación de la pendiente estará sobreinflada.
Debería ser inmediatamente obvio que la pendiente calculada con nuestro enfoque actual será muy sensible a nuestra representación del tiempo. Si decidimos ignorar el tiempo transcurrido durante el fin de semana, como dijimos anteriormente, obtendremos coeficientes sobreinflados. Y si tenemos en cuenta el tiempo del fin de semana, obtendremos coeficientes relativamente menores. Por lo tanto, bajo nuestro modelo actual, es posible obtener 2 cálculos de pendiente diferentes al analizar los mismos datos. Esto es indeseable. Preferiríamos que nuestro cálculo fuera determinista. Lo que significa que nuestro cálculo de la pendiente siempre será el mismo, si estamos analizando los mismos datos.
Para superar estas limitaciones, me gustaría proponer un cálculo alternativo. Podríamos en cambio calcular la pendiente formada por el precio utilizando la diferencia en el precio de apertura dividida por la diferencia en el precio de cierre. Hemos sustituido el tiempo en el eje x. Esta nueva cantidad nos informa qué tan sensible es el precio de cierre a los cambios en el precio de apertura. Si el valor absoluto de esta cantidad es > 1, entonces eso nos dice que grandes cambios en el precio de apertura tienen poco efecto en el precio de cierre. Del mismo modo, si el valor absoluto de la cantidad es < 1, entonces eso nos informa que pequeños cambios en el precio de apertura podrían tener grandes efectos en el precio de cierre. Además, si el coeficiente de la pendiente es negativo, eso nos informa que el precio de apertura y el precio de cierre tienden a cambiar en direcciones opuestas.
Sin embargo, esta nueva cantidad tiene su propio conjunto de limitaciones, una de particular interés para nosotros como traders es que nuestra nueva métrica es sensible a las velas Doji. Las velas Doji se forman cuando el precio de apertura y cierre de una vela están muy cerca uno del otro. El problema se agrava cuando tenemos un grupo de velas Doji, como se muestra en la Figura 1 a continuación. En el mejor de los casos, estas velas Doji podrían hacer que nuestros cálculos evalúen 0 o infinito. Sin embargo, en el peor de los casos, podríamos obtener errores de tiempo de ejecución porque podemos intentar dividir por 0.
Fig. 1: Un grupo de velas Doji.
Descripción general de la metodología
Analizamos 10.000 filas de datos M1 del par USDZAR. Los datos se obtuvieron de nuestro terminal MetaTrader 5, utilizando un script MQL5. Primero calculamos la pendiente utilizando la fórmula que sugerimos anteriormente. Para calcular el ángulo de la pendiente, utilizamos la inversa de la función trigonométrica tangente, arcotangente. La cantidad que calculamos mostró niveles de correlación desalentadores con nuestras cotizaciones de mercado.
Aunque nuestros niveles de correlación no fueron alentadores, procedimos a entrenar una selección de 12 modelos de IA diferentes para predecir el valor futuro del tipo de cambio USDZAR, en 3 grupos de datos de entrada:
- Cotizaciones de OHLC desde nuestro terminal MetaTrader 5
- Ángulo y pendiente creados por el precio
- Una combinación de los tres.
Nuestro modelo con mejor rendimiento fue la regresión lineal simple, utilizando OHLC. Aunque vale la pena señalar que la precisión del modelo lineal se mantuvo igual cuando intercambiamos sus entradas del grupo 1 al grupo 3. Ninguno de los modelos que observamos tuvo un mejor desempeño en el grupo 2 que en el grupo 1. Sin embargo, sólo dos de los modelos que examinamos funcionaron mejor cuando utilizaron todos los datos disponibles. El rendimiento del algoritmo KNeighbors mejoró en un 20% gracias a nuestras nuevas funciones. Esta observación nos hace preguntarnos qué mejoras adicionales podemos obtener al realizar otras transformaciones útiles en nuestros datos.
Ajustamos con éxito los parámetros del modelo KNeighbors sin sobreajustar los datos de entrenamiento y exportamos nuestro modelo al formato ONNX para incluirlo en nuestro Asesor Experto impulsado por IA.
Obteniendo los datos que necesitamos
El siguiente script obtendrá los datos que necesitamos de nuestro terminal MetaTrader 5 y los guardará en formato CSV para nosotros. Simplemente arrastre y suelte el script en cualquier mercado que desee analizar y podrá seguirnos.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- File name string file_name = "Market Data " + Symbol() +".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Análisis exploratorio de datos
Para comenzar nuestro análisis, primero importemos las bibliotecas que necesitamos.
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
Ahora leeremos los datos del mercado.
#Read in the data data = pd.read_csv("Market Data USDZAR.csv")
Nuestros datos están organizados en el orden incorrecto, inviértalos.
#The data is in reverse order, correct that data = data[::-1]
Definir hasta qué punto en el futuro deseamos pronosticar.
#Define the forecast horizon look_ahead = 20
Apliquemos el cálculo de la pendiente. Desafortunadamente, nuestros cálculos de pendiente no siempre dan como resultado un número real. Esta es una de las limitaciones de nuestro algoritmo de versión actual. Tenga en cuenta que debemos tomar una decisión sobre cómo manejaremos los valores faltantes en nuestro marco de datos. Por ahora, eliminaremos todos los valores faltantes en el marco de datos.
#Calculate the angle formed by the changes in price, using a ratio of high and low price. #Then calculate arctan to realize the angle formed by the changes in pirce data["Slope"] = (data["Close"] - data["Close"].shift(look_ahead))/(data["Open"] - data["Open"].shift(look_ahead)) data["Angle"] = np.arctan(data["Slope"]) data.describe()
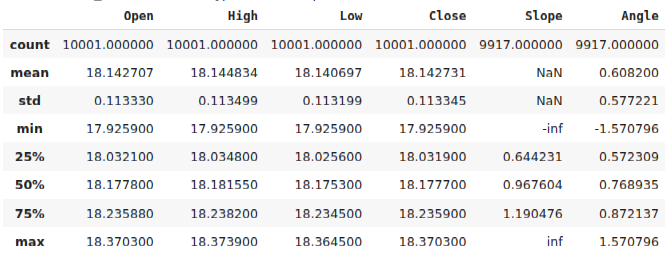
Fig. 2: Nuestro marco de datos después de calcular el ángulo creado por el precio.
Amplifiquémonos a los casos en los que nuestro cálculo de pendiente se evaluó hasta el infinito.
data.loc[data["Slope"] == np.inf] 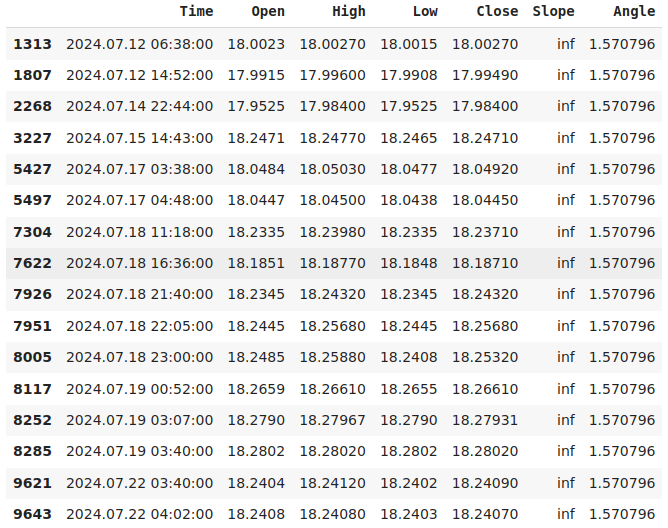
Fig. 3: Nuestros registros de pendiente infinita representan instancias en las que el precio de apertura no cambió.
En la gráfica siguiente, Fig. 4, seleccionamos aleatoriamente uno de los casos en los que nuestro cálculo de pendiente era infinito. La gráfica muestra que estos registros corresponden a fluctuaciones de precios, por lo que el precio de apertura no cambió.
pt = 1807 y = data.loc[pt,"Open"] plt.plot(data.loc[(pt - look_ahead):pt,"Open"]) plt.axhline(y=y,color="red") plt.xlabel("Time") plt.ylabel("USDZAR Open Price") plt.title("A slope of INF means the price has not changed")
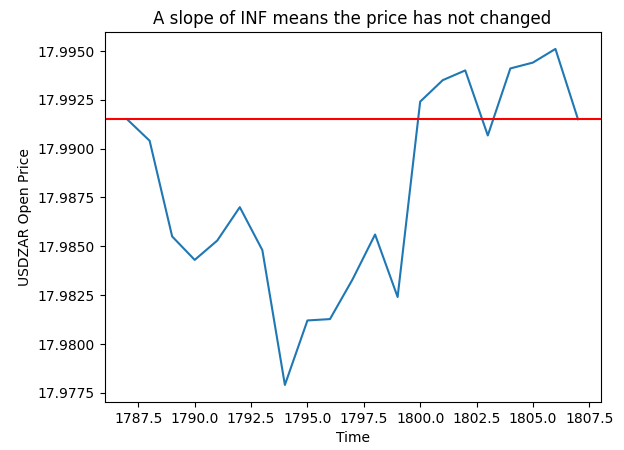
Fig. 4: Visualización de los valores de pendiente que calculamos.
Por ahora, simplificaremos nuestra discusión eliminando todos los valores faltantes.
data.dropna(inplace=True)
Ahora, restablezcamos el índice de nuestros datos.
data.reset_index(drop=True,inplace=True)
Grafiquemos nuestros cálculos de ángulos. Como podemos ver en la figura 5 a continuación, nuestro cálculo de ángulo gira alrededor de 0, esto puede darle a la computadora una idea de la escala porque cuanto más nos alejamos de 0, mayor es el cambio en los niveles de precios.
data.loc[:100,"Angle"].plot()
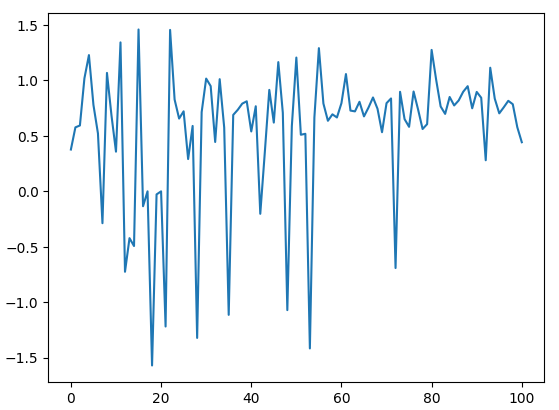
Fig. 5: Visualización de los ángulos creados por los cambios de precios.
Intentemos ahora estimar el ruido en la nueva característica que hemos creado. Cuantificaremos el ruido como el número de veces que el ángulo creado por el precio disminuyó pero los niveles de precios aumentaron durante el mismo tiempo. Esta propiedad es indeseable porque idealmente nos gustaría una cantidad que aumente y disminuya de acuerdo con los niveles de precios. Desafortunadamente, nuestro nuevo cálculo se mueve al ritmo del precio la mitad del tiempo, y la otra mitad puede moverse independientemente.
Para cuantificar esto, simplemente contamos el número de filas donde la pendiente del precio aumentó y los niveles de precios futuros disminuyeron. Y dividimos este recuento por el número total de casos en los que la pendiente aumentó. Esto nos dice que, conociendo el valor futuro de la pendiente de la línea, nos dice muy poco sobre los cambios en los niveles de precios que habrían ocurrido durante ese mismo horizonte de pronóstico.
#How clean are the signals generated? 1 - (data.loc[(data["Slope"] < data["Slope"].shift(-look_ahead)) & (data["Close"] > data["Close"].shift(-look_ahead))].shape[0] / data.loc[(data["Slope"] < data["Slope"].shift(-look_ahead))].shape[0])
Análisis exploratorio de datos
Primero debemos definir nuestras entradas y salidas.
#Define our inputs and target ohlc_inputs = ["Open","High","Low","Close"] trig_inputs = ["Angle"] all_inputs = ohlc_inputs + trig_inputs cv_inputs = [ohlc_inputs,trig_inputs,all_inputs] target = "Target"
Ahora definamos el objetivo clásico, el precio futuro.
#Define the target data["Target"] = data["Close"].shift(-look_ahead)
Agreguemos también algunas categorías para contarle a nuestro modelo sobre la acción del precio que creó cada vela. Si la vela actual es el resultado de un movimiento alcista que ocurrió durante las últimas 20 velas, lo simbolizaremos con un valor categórico establecido en 1. De lo contrario, el valor se establecerá en 0. Realizaremos la misma técnica de etiquetado para nuestros cambios de ángulo.
#Add a few labels data["Bull Bear"] = np.nan data["Angle Up Down"] = np.nan data.loc[data["Close"] > data["Close"].shift(look_ahead), "Bull Bear"] = 0 data.loc[data["Angle"] > data["Angle"].shift(look_ahead),"Angle Up Down"] = 0 data.loc[data["Close"] < data["Close"].shift(look_ahead), "Bull Bear"] = 1 data.loc[data["Angle"] < data["Angle"].shift(look_ahead),"Angle Up Down"] = 1
Formateando los datos.
data.dropna(inplace=True) data.reset_index(drop=True,inplace=True) data
Analicemos los niveles de correlación en nuestros datos. Recordemos que cuando estimamos los niveles de ruido asociados con el nuevo cálculo del ángulo, observamos que el precio y el cálculo del ángulo solo están en armonía aproximadamente el 50% del tiempo. Por lo tanto, los bajos niveles de correlación que observamos a continuación en la figura 6 no deberían sorprendernos.
#Let's analyze the correlation levels sns.heatmap(data.loc[:,all_inputs].corr(),annot=True)
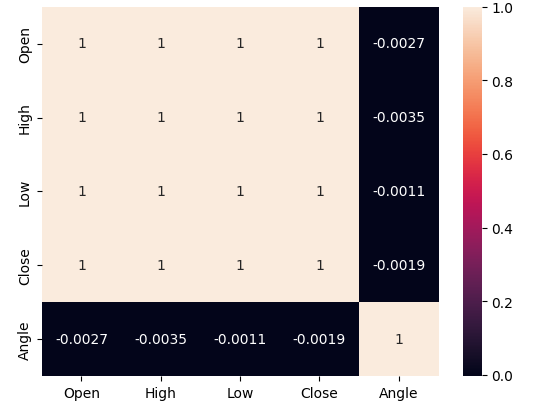
Fig. 6: Nuestro cálculo de ángulo tiene muy poca correlación con cualquiera de nuestras características de precio.
Intentemos también crear un diagrama de dispersión del ángulo creado por el precio en el eje x y el precio de cierre en el eje y. Los resultados obtenidos no son prometedores. Existe una superposición excesiva entre los casos en que los niveles de precios cayeron (los puntos azules) y los casos en que los niveles de precios aumentaron. Esto hace que sea un desafío para nuestros modelos de aprendizaje automático estimar las correspondencias entre las dos posibles clases de movimientos de precios.
sns.scatterplot(data=data,y="Close",x="Angle",hue="Bull Bear")
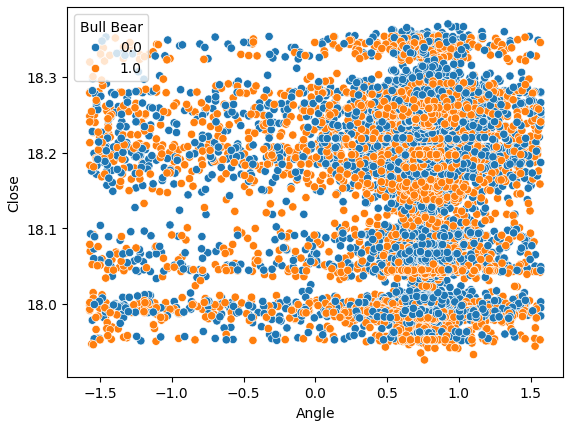
Fig. 7: Nuestro cálculo de ángulo no nos ayuda a separar mejor los datos.
Si realizamos un diagrama de dispersión de nuestras dos características diseñadas, los cálculos de pendiente y ángulo, uno contra el otro, podemos observar claramente la transformación no lineal que hemos aplicado a los datos. La mayoría de nuestros datos se encuentran entre los dos extremos curvos de los datos y, lamentablemente, no existe una división entre la acción del precio alcista y bajista que pueda darnos una ventaja al pronosticar niveles de precios futuros.
sns.scatterplot(data=data,x="Angle",y="Slope",hue="Bull Bear")
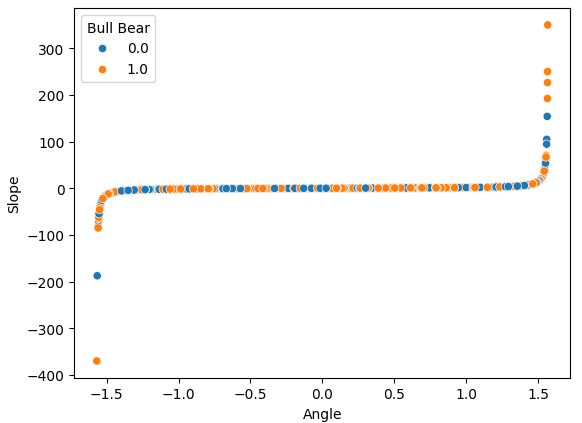
Fig. 8: Visualización de nuestra transformación no lineal que aplicamos a los datos de precios de OHLC.
Visualicemos el ruido que estimamos en 51% anteriormente. Realicemos un gráfico con 2 valores en nuestro eje x. Cada valor simbolizará si el cálculo del ángulo aumentó o disminuyó, respectivamente. Nuestro eje y registrará el precio de cierre y cada uno de los puntos resumirá si los niveles de precios se apreciaron o depreciaron de la misma manera que describimos anteriormente, las instancias azules resumen los puntos donde los niveles de precios futuros cayeron.
Al principio estimamos el ruido, pero ahora podemos visualizarlo. Podemos ver claramente en la figura 9 a continuación, que los cambios en los niveles de precios futuros parecen no tener nada que ver con los cambios en el ángulo creado por el precio.
sns.swarmplot(data=data,x="Angle Up Down",y="Close",hue="Bull Bear")
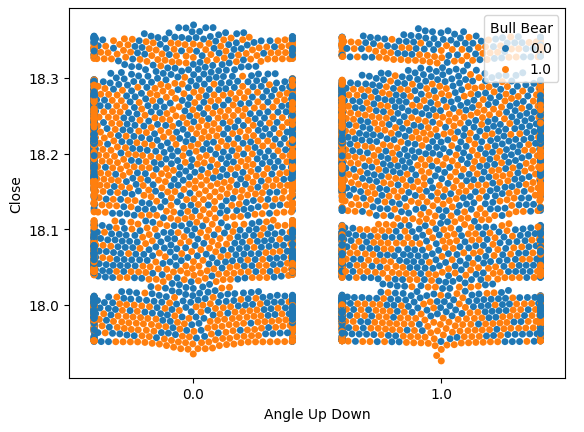
Fig. 9: Los niveles de precios futuros parecen no tener relación con el cambio en el ángulo.
Visualizar los datos en 3D muestra cuán ruidosa es la señal. Esperaríamos observar al menos algunos grupos de puntos que fueran todos alcistas o bajistas. Sin embargo, en este caso particular, no tenemos ninguno. La presencia de clusters podría posiblemente identificar un patrón que podría interpretarse como una señal comercial.
#Define the 3D Plot fig = plt.figure(figsize=(7,7)) ax = plt.axes(projection="3d") ax.scatter(data["Slope"],data["Angle"],data["Close"],c=data["Bull Bear"]) ax.set_xlabel("Slope") ax.set_ylabel("Angle") ax.set_zlabel("Close")
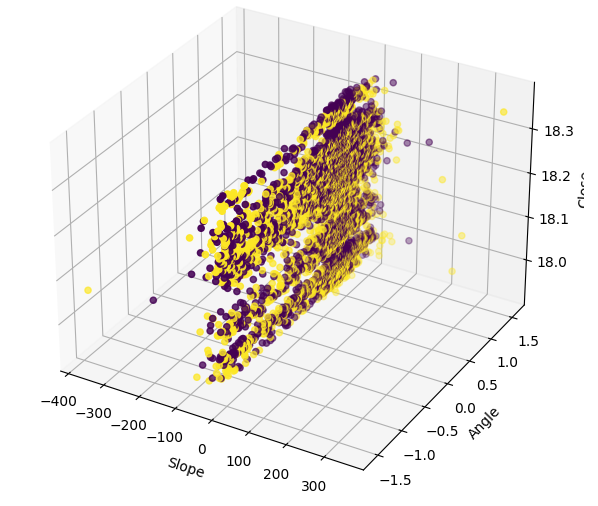
Fig. 10: Visualización de nuestros datos de pendiente en 3 dimensiones.
El gráfico de violín nos permite comparar visualmente dos distribuciones. El gráfico de violín tiene un diagrama de caja en su núcleo, para resumir las propiedades numéricas de cada distribución. La figura 10 a continuación nos da la esperanza de que el cálculo del ángulo no sea una pérdida de tiempo. Cada diagrama de caja tiene su valor promedio delineado con una línea blanca. Podemos ver claramente que en ambas instancias de movimientos angulares, los valores promedio de cada diagrama de caja fueron ligeramente diferentes. Si bien esta ligera diferencia puede parecer insignificante para nosotros como humanos, nuestros modelos de aprendizaje automático son lo suficientemente sensibles como para detectar y aprender de tales discrepancias en la distribución de los datos.
sns.violinplot(data=data,x="Angle Up Down",y="Close",hue="Bull Bear",split=True)
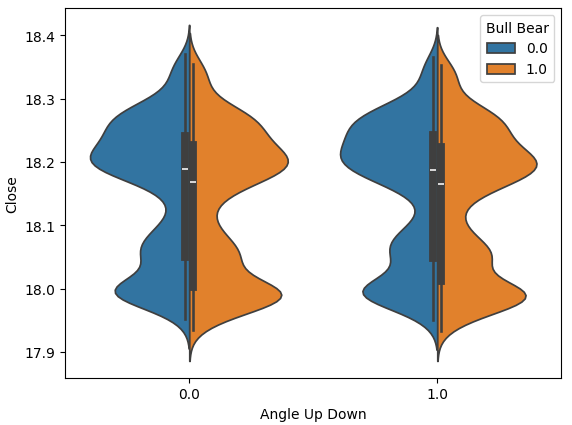
Fig. 11: Comparación de la distribución de los datos de precios entre las 2 clases de movimientos angulares.
Preparación para modelar los datos
Intentemos ahora modelar nuestros datos. Primero, importaremos las bibliotecas que necesitamos.
from sklearn.model_selection import train_test_split,cross_val_score from sklearn.preprocessing import StandardScaler from sklearn.ensemble import RandomForestRegressor, BaggingRegressor, GradientBoostingRegressor,AdaBoostRegressor from sklearn.svm import LinearSVR from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet from sklearn.neighbors import KNeighborsRegressor from sklearn.tree import DecisionTreeRegressor from sklearn.neural_network import MLPRegressor from sklearn.metrics import mean_squared_error
Divida los datos en conjuntos de entrenamiento y prueba.
#Let's split our data into train test splits train_data, test_data = train_test_split(data,test_size=0.5,shuffle=False)
Escalar los datos ayudará a que nuestros modelos aprendan de manera efectiva. Asegúrese de ajustar únicamente el objeto escalador en el conjunto de entrenamiento y, luego, transforme el conjunto de prueba sin ajustar el objeto escalador una segunda vez. No ajuste el objeto escalador a todo el conjunto de datos porque los parámetros aprendidos para escalar sus datos propagarán cierta información sobre el futuro, hacia el pasado.
#Scale the data
scaler = StandardScaler()
scaler.fit(train_data[all_inputs])
train_scaled= pd.DataFrame(scaler.transform(train_data[all_inputs]),columns=all_inputs)
test_scaled = pd.DataFrame(scaler.transform(test_data[all_inputs]),columns=all_inputs) Define un marco de datos para almacenar la precisión de cada modelo.
#Create a dataframe to store our accuracy in training and testing columns = [ "Random Forest", "Bagging", "Gradient Boosting", "AdaBoost", "Linear SVR", "Linear Regression", "Ridge", "Lasso", "Elastic Net", "K Neighbors", "Decision Tree", "Neural Network" ] index = ["OHLC","Angle","All"] accuracy = pd.DataFrame(columns=columns,index=index)
Almacene los modelos en una lista.
#Store the models models = [ RandomForestRegressor(), BaggingRegressor(), GradientBoostingRegressor(), AdaBoostRegressor(), LinearSVR(), LinearRegression(), Ridge(), Lasso(), ElasticNet(), KNeighborsRegressor(), DecisionTreeRegressor(), MLPRegressor(hidden_layer_sizes=(4,6)) ]
Validar de forma cruzada cada modelo.
#Cross validate the models #First we have to iterate over the inputs for k in np.arange(0,len(cv_inputs)): current_inputs = cv_inputs[k] #Then fit each model on that set of inputs for i in np.arange(0,len(models)): score = cross_val_score(models[i],train_scaled[current_inputs],train_data[target],cv=5,scoring="neg_mean_squared_error",n_jobs=-1) accuracy.iloc[k,i] = -score.mean()
Probamos los modelos utilizando 3 conjuntos de entradas:
- Sólo los precios OHLC.
- Sólo se crean la pendiente y el ángulo.
- Todos los datos que teníamos.
No todos nuestros modelos pudieron utilizar nuestras funciones de manera efectiva. De los 12 modelos de nuestro grupo de candidatos, el modelo KNeighbors obtuvo una mejora del 20 % en el rendimiento gracias a nuestras nuevas funciones y fue claramente el mejor modelo que teníamos en este momento.
Si bien nuestra regresión lineal es el mejor modelo de todo el conjunto, esta demostración sugiere que puede haber otras transformaciones que simplemente desconocemos y que podrían reducir aún más nuestros niveles de precisión.
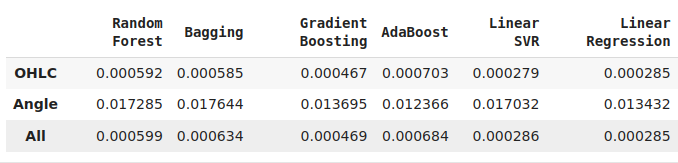
Fig. 12: Algunos de nuestros niveles de precisión. Tenga en cuenta que solo 2 de nuestros modelos demostraron habilidad al utilizar las nuevas características que hemos diseñado.
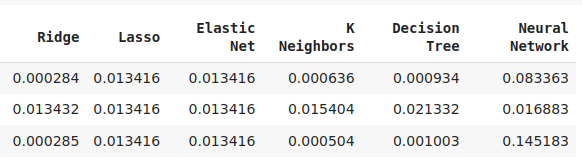
Fig. 13: AdaBoost y KNeighbors fueron nuestros modelos más prometedores, decidimos optimizar el modelo KNeighbors.
Optimización más profunda
Intentemos encontrar mejores configuraciones para nuestro indicador que las configuraciones predeterminadas que trae.
from sklearn.model_selection import RandomizedSearchCV
Crear instancias de nuestro modelo.
model = KNeighborsRegressor(n_jobs=-1) Definir los parámetros de ajuste.
tuner = RandomizedSearchCV(model,
{
"n_neighbors": [2,3,4,5,6,7,8,9,10],
"weights": ["uniform","distance"],
"algorithm": ["auto","ball_tree","kd_tree","brute"],
"leaf_size": [1,2,3,4,5,10,20,30,40,50,60,100,200,300,400,500,1000],
"p": [1,2]
},
n_iter = 100,
n_jobs=-1,
cv=5
) Ajuste el objeto 'tuner'.
tuner.fit(train_scaled.loc[:,all_inputs],train_data[target])
Los mejores parámetros que hemos encontrado.
tuner.best_params_
'p': 1,
'n_neighbors': 10,
'leaf_size': 100,
'algorithm': 'ball_tree'}
Nuestra mejor puntuación en el conjunto de entrenamiento fue 71%. En realidad, no nos preocupamos mucho por los errores de entrenamiento. Nos preocupa más lo bien que nuestro modelo se generalizará a nuevos datos.
tuner.best_score_
Prueba de sobreajuste
Veamos si estábamos sobreajustando el conjunto de entrenamiento. El sobreajuste ocurre cuando nuestro modelo aprende información sin sentido de nuestro conjunto de entrenamiento. Hay varias formas de comprobar si estamos sobreajustando. Una forma es comparar el modelo personalizado contra un modelo que no tiene conocimiento previo sobre los datos.
#Testing for over fitting model = KNeighborsRegressor(n_jobs=-1) custom_model = KNeighborsRegressor(n_jobs=-1,weights= 'uniform',p=1,n_neighbors= 10,leaf_size= 100,algorithm='ball_tree')
Si no logramos superar una instancia predeterminada del modelo, podemos estar seguros de que quizás hayamos personalizado demasiado nuestro modelo para el conjunto de entrenamiento. Podemos ver claramente que superamos el modelo predeterminado, lo cual es una buena noticia.
model.fit(train_scaled.loc[:,all_inputs],train_data[target]) custom_model.fit(train_scaled.loc[:,all_inputs],train_data[target])
| Modelo predeterminado | Modelo personalizado |
|---|---|
| 0.0009797322460441842 | 0.0009697248896608824 |
Exportando a ONNX
Open Neural Network Exchange (ONNX) es un protocolo de código abierto para crear y compartir modelos de aprendizaje automático de manera independiente del modelo. Utilizaremos la API ONNX para exportar nuestro modelo de IA desde Python e importarlo a un programa MQL5.
Primero, necesitamos aplicar transformaciones a nuestros datos de precios que siempre podamos reproducir en MQL5. Guardemos los valores de media y desviación estándar de cada columna en un archivo CSV.
data.loc[:,all_inputs].mean().to_csv("USDZAR M1 MEAN.csv") data.loc[:,all_inputs].std().to_csv("USDZAR M1 STD.csv")
Ahora aplique la transformación a los datos.
data.loc[:,all_inputs] = ((data.loc[:,all_inputs] - data.loc[:,all_inputs].mean())/ data.loc[:,all_inputs].std())
Ahora importemos las bibliotecas que necesitamos.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Define el tipo de entrada de nuestro modelo.
#Define the input shape
initial_type = [('float_input', FloatTensorType([1, len(all_inputs)]))] Ajuste el modelo a todos los datos que tenemos.
#Fit the model on all the data we have custom_model.fit(data.loc[:,all_inputs],data.loc[:,"Target"])
Convierte el modelo al formato ONNX y guárdalo.
#Convert the model to ONNX format onnx_model = convert_sklearn(model, initial_types=initial_type,target_opset=12) #Save the ONNX model onnx.save(onnx_model,"USDZAR M1 OHLC Angle.onnx")
Construyendo nuestro asesor experto en MQL5
Ahora vamos a integrar nuestro modelo de IA en una aplicación de trading, para poder operar con ventaja sobre el mercado. Nuestra estrategia de trading utilizará nuestro modelo de IA para detectar la tendencia en el M1. Buscaremos confirmación adicional en el rendimiento del par USADZAR en el marco temporal diario. Buscaremos confirmación adicional en el rendimiento del par USADZAR en el marco temporal diario. Además, también querremos una confirmación adicional del índice del dólar. Siguiendo nuestro ejemplo de compra en el M1, también tendremos que observar una acción alcista de los precios en el gráfico diario del índice del dólar como señal de que es probable que el dólar continúe repuntando en marcos temporales más amplios.
En primer lugar, debemos importar el modelo ONNX que acabamos de crear.
//+------------------------------------------------------------------+ //| Slope AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the ONNX files | //+------------------------------------------------------------------+ #resource "\\Files\\USDZAR M1 OHLC Angle.onnx" as const uchar onnx_buffer[];
Carguemos también nuestra biblioteca de operaciones para gestionar nuestras posiciones abiertas.
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Defina algunas variables globales que necesitaremos.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double mean_values[5] = {18.143698,18.145870,18.141644,18.143724,0.608216}; double std_values[5] = {0.112957,0.113113,0.112835,0.112970,0.580481}; long onnx_model; int macd_handle; int usd_ma_slow,usd_ma_fast; int usd_zar_slow,usd_zar_fast; double macd_s[],macd_m[],usd_zar_s[],usd_zar_f[],usd_s[],usd_f[]; double bid,ask; double vol = 0.3; double profit_target = 10; int system_state = 0; vectorf model_forecast = vectorf::Zeros(1);
Ahora hemos llegado al procedimiento de inicialización de nuestra aplicación de trading. Por ahora, solo necesitamos cargar nuestro modelo ONNX y los indicadores técnicos.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX file if(!onnx_load()) { //--- We failed to load the ONNX file return(INIT_FAILED); } //--- Load the MACD Indicator macd_handle = iMACD("EURUSD",PERIOD_CURRENT,12,26,9,PRICE_CLOSE); usd_zar_fast = iMA("USDZAR",PERIOD_D1,20,0,MODE_EMA,PRICE_CLOSE); usd_zar_slow = iMA("USDZAR",PERIOD_D1,60,0,MODE_EMA,PRICE_CLOSE); usd_ma_fast = iMA("DXY_Z4",PERIOD_D1,20,0,MODE_EMA,PRICE_CLOSE); usd_ma_slow = iMA("DXY_Z4",PERIOD_D1,60,0,MODE_EMA,PRICE_CLOSE); //--- Everything went fine return(INIT_SUCCEEDED); }
Si nuestro programa ya no se utiliza, liberemos los recursos que estaba utilizando.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release the handles don't need OnnxRelease(onnx_model); IndicatorRelease(macd_handle); IndicatorRelease(usd_zar_fast); IndicatorRelease(usd_zar_slow); IndicatorRelease(usd_ma_fast); IndicatorRelease(usd_ma_slow); }
Cada vez que recibamos precios actualizados, almacenemos nuestros nuevos datos de mercado, obtengamos una nueva predicción de nuestro modelo y luego decidamos si necesitamos buscar una posición en el mercado o cerrar las posiciones que tenemos.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Update our market data update(); //--- Get a prediction from our model model_predict(); if(PositionsTotal() == 0) { find_entry(); } if(PositionsTotal() > 0) { manage_positions(); } } //+------------------------------------------------------------------+
La función que realmente actualiza nuestros datos de mercado se define a continuación. Estamos utilizando el comando CopyBuffer para obtener el valor actual de cada indicador en su búfer de matriz. Utilizaremos estos indicadores de media móvil para confirmar la tendencia.
//+------------------------------------------------------------------+ //| Update our market data | //+------------------------------------------------------------------+ void update(void) { bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); CopyBuffer(macd_handle,0,0,1,macd_m); CopyBuffer(macd_handle,1,0,1,macd_s); CopyBuffer(usd_ma_fast,0,0,1,usd_f); CopyBuffer(usd_ma_slow,0,0,1,usd_s); CopyBuffer(usd_zar_fast,0,0,1,usd_zar_f); CopyBuffer(usd_zar_slow,0,0,1,usd_zar_s); } //+------------------------------------------------------------------+
No solo eso, sino que también debemos definir cómo exactamente nuestro modelo va a realizar las previsiones. Además, comencemos calculando primero el ángulo formado por las fluctuaciones de precios y, a continuación, almacenaremos las entradas de nuestro modelo en un vector. Por último, estandarizaremos y escalaremos las entradas de nuestro modelo antes de llamar a la función OnnxRun para obtener una previsión de nuestro modelo de IA.
//+------------------------------------------------------------------+ //| Get a forecast from our model | //+------------------------------------------------------------------+ void model_predict(void) { float angle = (float) MathArctan(((iOpen(Symbol(),PERIOD_M1,1) - iOpen(Symbol(),PERIOD_M1,20)) / (iClose(Symbol(),PERIOD_M1,1) - iClose(Symbol(),PERIOD_M1,20)))); vectorf model_inputs = {(float) iOpen(Symbol(),PERIOD_M1,1),(float) iHigh(Symbol(),PERIOD_M1,1),(float) iLow(Symbol(),PERIOD_M1,1),(float) iClose(Symbol(),PERIOD_M1,1),(float) angle}; for(int i = 0; i < 5; i++) { model_inputs[i] = (float)((model_inputs[i] - mean_values[i])/std_values[i]); } //--- Log Print("Model inputs: "); Print(model_inputs); if(!OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,model_forecast)) { Comment("Failed to obtain a forecast from our model: ",GetLastError()); } }
La siguiente función cargará nuestro modelo ONNX desde el búfer ONNX que definimos anteriormente.
//+------------------------------------------------------------------+ //| ONNX Load | //+------------------------------------------------------------------+ bool onnx_load(void) { //--- Create the ONNX model from the buffer we defined onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Define the input and output shapes ulong input_shape[] = {1,5}; ulong output_shape[] = {1,1}; //--- Validate the I/O parameters if(!(OnnxSetInputShape(onnx_model,0,input_shape))||!(OnnxSetOutputShape(onnx_model,0,output_shape))) { //--- We failed to define the I/O parameters Comment("[ERROR] Failed to load AI Model Correctly: ",GetLastError()); return(false); } //--- Everything was okay return(true); }
Además, nuestro sistema necesita reglas sobre cuándo debe cerrar nuestras posiciones. Si las ganancias flotantes de nuestras posiciones actuales son superiores a nuestro objetivo de ganancias, cerraremos nuestras posiciones. De lo contrario, si el sistema cambia de estado, cerraremos nuestras posiciones en consecuencia.
//+------------------------------------------------------------------+ //| Manage our open positions | //+------------------------------------------------------------------+ void manage_positions(void) { if(PositionSelectByTicket(PositionGetTicket(0))) { if(PositionGetDouble(POSITION_PROFIT) > profit_target) { Trade.PositionClose(Symbol()); } } if(system_state == 1) { if(macd_m[0] < macd_s[0]) { if(model_forecast[0] < iClose(Symbol(),PERIOD_M1,0)) { Trade.PositionClose(Symbol()); } } } if(system_state == -1) { if(macd_m[0] > macd_s[0]) { if(model_forecast[0] > iClose(Symbol(),PERIOD_M1,0)) { Trade.PositionClose(Symbol()); } } } }
La siguiente función es responsable de abrir nuestras posiciones. Solo abriremos una posición de compra si:
- La línea principal del MACD está por encima de la señal.
- Nuestra previsión basada en IA es superior al cierre actual.
- El índice del dólar y el par USDZAR están mostrando una tendencia alcista en el gráfico diario.
//+------------------------------------------------------------------+ //| Find an entry | //+------------------------------------------------------------------+ void find_entry(void) { if(macd_m[0] > macd_s[0]) { if(model_forecast[0] > iClose(Symbol(),PERIOD_M1,0)) { if((usd_f[0] > usd_s[0]) && (usd_zar_f[0] > usd_zar_s[0])) { Trade.Buy(vol,Symbol(),ask,0,0,"Slope AI"); system_state = 1; } } } if(macd_m[0] < macd_s[0]) { if(model_forecast[0] < iClose(Symbol(),PERIOD_M1,0)) { if((usd_f[0] < usd_s[0]) && (usd_zar_f[0] < usd_zar_s[0])) { Trade.Sell(vol,Symbol(),bid,0,0,"Slope AI"); system_state = -1; } } } }
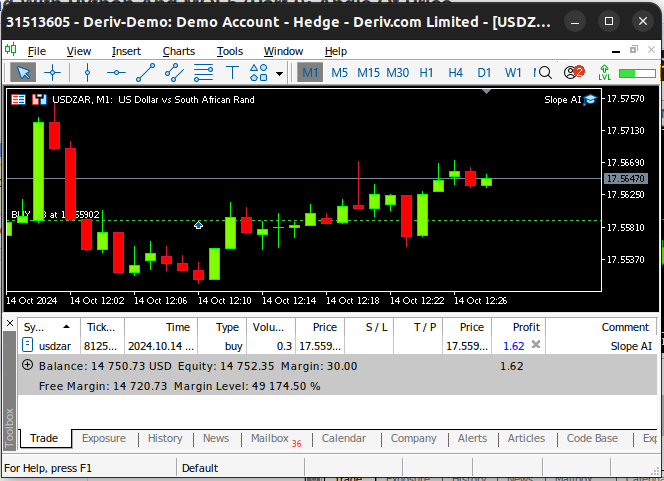
Fig. 14: Nuestro sistema de IA en acción.
Conclusión
Hasta ahora, hemos demostrado que aún existen algunos obstáculos que se interponen en el camino de los traders que desean utilizar la pendiente formada por la acción del precio en sus estrategias comerciales. Sin embargo, parece que cualquier esfuerzo aplicado en esta dirección puede valer el tiempo invertido. Al exponer la relación entre los niveles de precios mediante el uso de la pendiente mejoramos el desempeño de nuestro modelo KNeighbors en un 20%, lo que nos lleva a preguntarnos cuántas mejoras adicionales en el desempeño podemos obtener si seguimos buscando en esta dirección. Además, también destaca que cada modelo probablemente tiene su propio conjunto específico de transformaciones que mejorarán su rendimiento, nuestro trabajo ahora es realizar este mapeo.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/16124
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso