
Инженерия признаков с Python и MQL5 (Часть II): Угол наклона цены

Модели машинного обучения очень чувствительны к данным, с которыми они работают. В этой серии статей мы исследуем, как преобразования данных влияют на результаты моделей. Помимо данных, для модели имеет большое значение то, как мы ей передаем взаимосвязь между входными данными и целевой функцией. То есть, нам может потребоваться создать новые признаки из уже имеющихся данных, чтобы модель могла эффективно обучаться.
Если говорить о рыночных данных, на их основе можно создать неограниченное количество признаков. Преобразования, которые мы применяем к рыночным данным, и любые новые признаки, которые мы из них формируем, будут влиять на уровень ошибки модели. Наша цель — определить, какие преобразования и методы создания признаков приближают уровень ошибки к нулю. Кроме того, вы заметите, что разные модели по-разному реагируют на одни и те же преобразования. Поэтому мы также попробуем определить, какие преобразования нужно выбирать в зависимости от архитектуры модели.
Обзор торговой стратегии
На форуме MQL5 сожно найти множество сообщений с вопросами о том, как вычислить угол, образуемый изменениями ценовых уровней. Интуитивно понятно, что медвежьи тренды приводят к отрицательным углам, а бычьи — к положительным. И хотя идея проста для понимания, ее реализация на практике значительно сложнее. Есть целый ряд сложностей, которые нудно преодолеть для разработки стратегии с учетом угла наклона цены. В этой статье мы рассмотрим и попробуем решить основные из них. При этом мы будем простор критиковать недостатки стратегии, а обязательно поищем варианты улучшений.
Обычно угол, образуемый изменениями цены, измеряют, чтобы получить дополнительное подтверждение сигнала. Трендовые линии позволяют определить доминирующий тренд на рынке. Как правило, такие линии соединяют 2 или 3 экстремума прямой. Если цена пробивает трендовую линию, это можно рассматривать как признак силы рынка — это вариант, чтобы присоединиться к тренду. Напротив, если цена уходит от трендовой линии в противоположную сторону, это может быть воспринято как сигнал слабости и завершении тренда.
Один из ключевых недостатков трендовых линий состоит в их субъективности. Трейдер может произвольно корректировать линии тренда, подгоняя анализ под свою точку зрения, даже если она ошибочна. Поэтому вполне логично стремиться к более объективному способу построения трендовых линий. Один из популярных вариантов — рассчитать угол наклона, создаваемого изменениями цены. Основное предположение здесь — знание наклона эквивалентно знанию направления линии тренда, образованной ценовым движением.
И вот мы подошли к первой проблеме: как определить наклон. Чаще всего угол наклона высчитывают как разницу цены, поделенную на разницу во времени. Однако такой подход имеет несколько ограничений. Во-первых, фондовые рынки закрыты по выходным. В терминале MetaTrader 5 время, прошедшее во время закрытия рынков, не учитывается — его необходимо выводить из имеющихся данных. Это значит, что если мы используем такую простую модель, она не будет учитывать время, прошедшее за выходные. В случае, если цена изменилась скачком за выходные, полученная оценка угла наклона будет завышенной.
Очевидно, что такой расчет будет очень сильно зависеть от способа представления времени. Если не учитывать время выходных, как говорилось выше, коэффициенты будут завышенными. Если же мы это время учитываем, коэффициенты станут заниженными В результате, одна и та же выборка данных может дать два разных значения угла наклона. Это не самый хороший вариант. Все же наши вычисления должны быть детерминированными. То есть при анализе одних и тех же данных результат должен быть одинаковым.
Давайте рассмотрим альтернативный способ расчета. Угол наклона можно рассчитать на основе разницы между ценами открытия поделенными на разницу цен закрытия. То есть мы заменим время по шкале X. Полученный коэффициент показывает, насколько чувствительна цена закрытия к изменению цены открытия. Если абсолютное значение коэффициента больше 1, это означает, что даже значительные изменения цены открытия слабо влияют на цену закрытия. Если же абсолютное значение меньше 1 — это говорит о том, что даже незначительные изменения цены открытия могут сильно повлиять на цену закрытия. Кроме того, отрицательное значение коэффициента свидетельствует о том, что цена открытия и цена закрытия имеют тенденцию изменяться в противоположных направлениях.
Однако и у этой метрики есть свои ограничения. Особенно — чувствительность к свечам типа Доджи (Doji). Доджи возникают, когда цены открытия и закрытия практически совпадают. Проблема еще хуже, если много таких свечей идет подряд, как показано на Рисунке 1 ниже. В лучшем случае такие свечи могут привести к тому, что результат вычислений окажется равным нулю или бесконечности. В худшем — ошибки, если дальше будет деление на ноль.
Рис. 1: Группа свечей доджи.
Обзор методологии
Мы проанализировали 10 000 строк минутных данных валютной пары USDZAR. Данные мы получили из терминала MetaTrader 5 с помощью MQL5-скрипта. Сначала мы рассчитали угол наклона по предложенной ранее формуле. Для вычисления угла наклона использовалась обратная тригонометрическая функция тангенса, т.е. арктангенс. Полученное значение показало крайне низкий уровень корреляции с рыночными котировками.
Несмотря на разочаровывающие показатели корреляции, мы продолжили работу и обучили 12 различных моделей искусственного интеллекта для прогнозирования будущего значения валютного курса USDZAR. Модели обучались на трех различных группах входных данных:
- Цены OHLC из терминала MetaTrader 5
- Угол и наклон, образованные движением цены
- Комбинация всех признаков
лучшие результаты показала простая модель линейной регрессии, использующая только данные OHLC. Однако стоит отметить, что точность линейной модели не изменилась при замене входных данных с первой группы на третью. Ни одна из моделей не продемонстрировала улучшения качества предсказаний при использовании второй группы по сравнению с первой. Тем не менее, только две модели достигли лучших результатов, когда использовались все доступные признаки. Алгоритм KNeighbors (K ближайших соседей)улучшил показатели на 20% благодаря добавлению новых признаков. Так, какие еще улучшения можно получить, применяя дополнительные полезные преобразования к нашим данным.
Мы успешно настроили параметры модели KNeighbors, у нас не было переобучения на обучающей выборке. Затем мы экспортировали модель в формат ONNX для использования в торговом советнике на базе искусственного интеллекта.
Сбор данных
Скрипт ниже получает данные из терминала MetaTrader 5 и сохранит их в формате CSV. Просто набрасываем скрипт на необходимый рынок, который хотим проанализировать, и следуем инструкциям.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- File name string file_name = "Market Data " + Symbol() +".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Разведочный анализ данных
Для анализа импортируем необходимые библиотеки.
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
Читаем рыночные данные.
#Read in the data data = pd.read_csv("Market Data USDZAR.csv")
Данные расположены в неправильном порядке, развернем.
#The data is in reverse order, correct that data = data[::-1]
Определим, насколько далеко в будущее мы хотим заглянуть.
#Define the forecast horizon look_ahead = 20
Рассчитаем угол наклона. К сожалению, при расчете угла наклона мы не всегда получаем действительные числа. Это одно из ограничений текущей версии алгоритма. Нам еще нужно решить, как обрабатывать отсутствующие значения в нашей таблице данных. Пока удалим пустые значения в фрейме данных.
#Calculate the angle formed by the changes in price, using a ratio of high and low price. #Then calculate arctan to realize the angle formed by the changes in pirce data["Slope"] = (data["Close"] - data["Close"].shift(look_ahead))/(data["Open"] - data["Open"].shift(look_ahead)) data["Angle"] = np.arctan(data["Slope"]) data.describe()
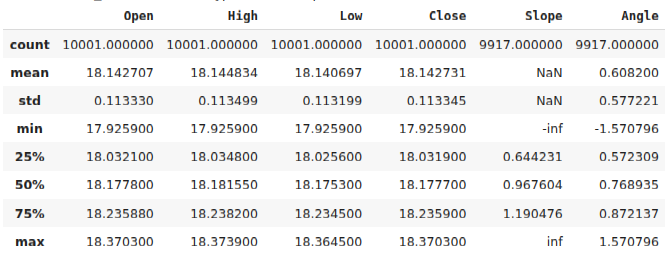
Рис. 2: Датафрейм после расчета угла
Давайте рассмотрим случаи, когда наши расчеты приводили к бесконечности.
data.loc[data["Slope"] == np.inf]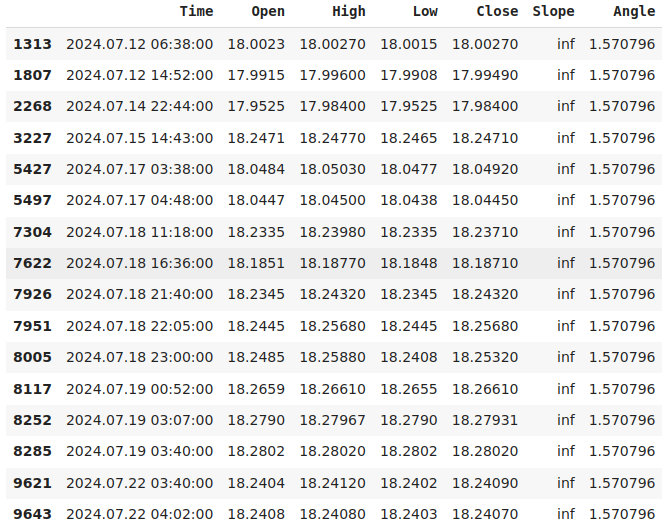
Рис. 3. Бесконечный угол наклона получался, представляют, когда цена открытия не менялась.
На графике ниже (Рисунок 4) мы случайным образом выбрали один из моментов, когда расчет оказался бесконечным. График показывает, что в эти моменты цена открытия не изменилась.
pt = 1807 y = data.loc[pt,"Open"] plt.plot(data.loc[(pt - look_ahead):pt,"Open"]) plt.axhline(y=y,color="red") plt.xlabel("Time") plt.ylabel("USDZAR Open Price") plt.title("A slope of INF means the price has not changed")
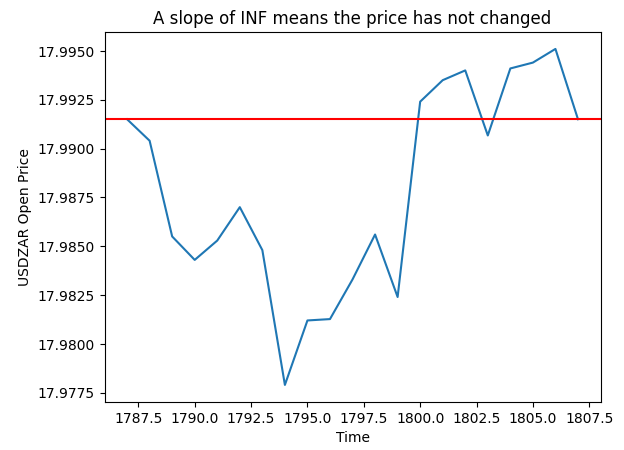
Рис. 4. Визуализация рассчитанных значений
Пока мы упростим нашу задачу и просто отбросим все пропущенные значения.
data.dropna(inplace=True)
Сбросим индекс данных.
data.reset_index(drop=True,inplace=True)
Построим график расчетов. Как мы видим на рисунке 5 ниже, расчет угла колеблется около 0, это может дать компьютеру некоторое представление о масштабе, поскольку чем дальше мы удаляемся от 0, тем больше изменение уровней цен.
data.loc[:100,"Angle"].plot()
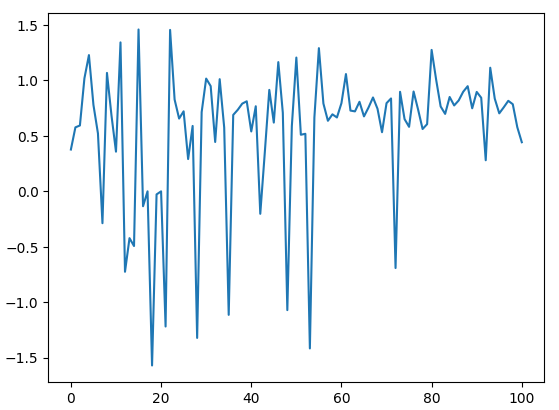
Рис. 5: Визуализация углов, созданных изменениями цен
Давайте теперь попробуем оценить шум в новом созданном признаке. Под "шумом" мы будем понимать количество случаев, когда угол, образованный ценой, снижался, несмотря на то что ценовые уровни за тот же период росли. Это нежелательное свойство, так как в идеале мы стремимся к тому, чтобы показатель возрастал и снижался синхронно с изменением цен. К сожалению, по нашим наблюдениям, новое вычисление совпадает по направлению с движением цены лишь в половине случаев, а в остальное время ведет себя независимо.
Чтобы количественно оценить это, мы просто подсчитали количество строк, в которых наклон цены увеличился, а будущие уровни цены снижались. Затем поделили это количество на общее число случаев, когда наклон увеличивался. Этот показатель говорит нам о том, что знание будущего значения наклона линии практически не дает информации о том, как изменится цена в пределах того же прогноза.
#How clean are the signals generated? 1 - (data.loc[(data["Slope"] < data["Slope"].shift(-look_ahead)) & (data["Close"] > data["Close"].shift(-look_ahead))].shape[0] / data.loc[(data["Slope"] < data["Slope"].shift(-look_ahead))].shape[0])
Разведочный анализ данных
Сначала определим входные и выходные параметры.
#Define our inputs and target ohlc_inputs = ["Open","High","Low","Close"] trig_inputs = ["Angle"] all_inputs = ohlc_inputs + trig_inputs cv_inputs = [ohlc_inputs,trig_inputs,all_inputs] target = "Target"
Теперь определим классическую цель — будущую цену.
#Define the target data["Target"] = data["Close"].shift(-look_ahead)
Также добавим несколько категориальных признаков, которые будут информировать модель о характере ценового движения, приведшего к формированию каждой свечи. Если текущая свеча является результатом бычьего движения на последних 20 свечах, мы обозначим это категориальным значением, равным 1. В противном случае значение будет равно 0. Мы применим ту же технику разметки и к изменениям угла наклона.
#Add a few labels data["Bull Bear"] = np.nan data["Angle Up Down"] = np.nan data.loc[data["Close"] > data["Close"].shift(look_ahead), "Bull Bear"] = 0 data.loc[data["Angle"] > data["Angle"].shift(look_ahead),"Angle Up Down"] = 0 data.loc[data["Close"] < data["Close"].shift(look_ahead), "Bull Bear"] = 1 data.loc[data["Angle"] < data["Angle"].shift(look_ahead),"Angle Up Down"] = 1
Отформатируем данные.
data.dropna(inplace=True) data.reset_index(drop=True,inplace=True) data
Проанализируем уровни корреляции в данных. Напомню, что при оценке уровня шума, связанного с новой методикой расчета угла, мы установили, что цена и рассчитанный угол совпадают по направлению лишь примерно в 50% случаев. Поэтому низкие уровни корреляции, которые мы наблюдаем ниже на Рисунке 6, вполне ожидаемы.
#Let's analyze the correlation levels sns.heatmap(data.loc[:,all_inputs].corr(),annot=True)
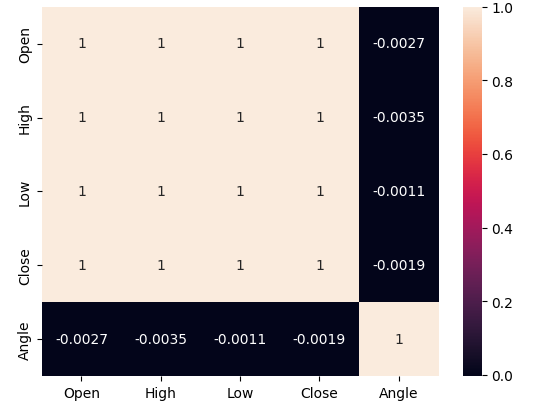
Рис. 6. Расчетный угол практически не коррелирует ни с одним из ценовых признаков
Попробуем также построить диаграмму рассеяния, где по оси X отложим угол, образованный движением цены, а по оси Y — цены закрытия (Close). Результаты оказались неутешительными. На графике наблюдается сильное наложение точек, соответствующих снижению цен (синие точки), и точек, соответствующих росту цен. Это затрудняет для моделей машинного обучения задачу построения четкой границы между двумя классами ценовых движений.
sns.scatterplot(data=data,y="Close",x="Angle",hue="Bull Bear")
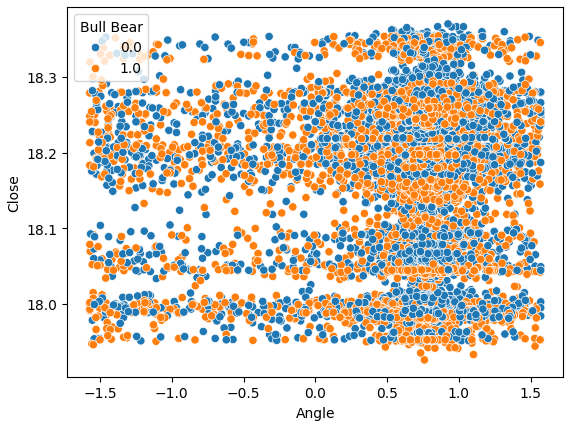
Рис. 7: Наш расчет угла не помог разделить данные
Если построить диаграмму рассеяния для двух созданных нами признаков — наклона и угла, — можно четко увидеть нелинейное преобразование, которое мы применили к данным. Основная масса данных располагается между двумя изогнутыми краями диаграммы, и, к сожалению, здесь отсутствует явная граница между бычьими и медвежьими ценовыми движениями, которая могла бы дать нам какое-либо преимущество в прогнозировании будущих уровней цен.
sns.scatterplot(data=data,x="Angle",y="Slope",hue="Bull Bear")
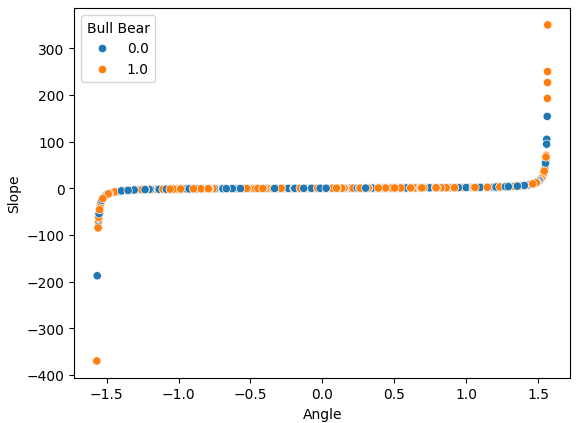
Рис. 8. Визуализация нелинейного преобразования, примененного к данным OHLC
Теперь визуализируем уровень шума. Напомню, ранее мы получили значение 51%. Построим график, в котором по оси X будут отображены два значения. Они означают увеличение и уменьшение угла соответственно. По оси Y отложим цену закрытия, а каждая точка будет показывать, двигалась ли цена в том же направлении, что и угол, согласно методике, описанной ранее. Синие точки обозначают случаи, в которых будущие уровни цен снижались.
Ранее мы оценивали уровень шума количественно, теперь мы его визуализируем. На рисунке 9 видно, что изменения будущих цен не имеют никакой явной зависимости от изменений угла, образованного ценой.
sns.swarmplot(data=data,x="Angle Up Down",y="Close",hue="Bull Bear")
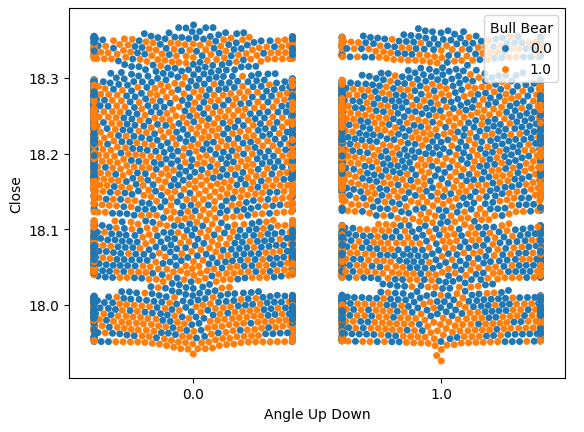
Рис. 9: Будущие уровни цен, по-видимому, никак не связаны с изменением угла
Визуализация данных в 3D дает полное представление о том, насколько зашумлен сигнал. Можно было бы ожидать, что появятся хотя бы несколько кластеров точек, представляющих собой явно бычьи или медвежьи движения. Однако таких кластеров нет. Такие кластеры могли бы указывать на паттерн, который можно было бы интерпретировать как торговый сигнал.
#Define the 3D Plot fig = plt.figure(figsize=(7,7)) ax = plt.axes(projection="3d") ax.scatter(data["Slope"],data["Angle"],data["Close"],c=data["Bull Bear"]) ax.set_xlabel("Slope") ax.set_ylabel("Angle") ax.set_zlabel("Close")
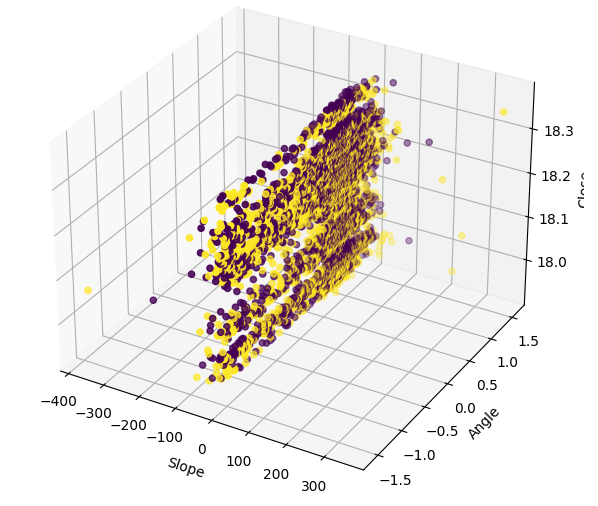
Рис. 10. Визуализация данных по наклону в трехмерном пространстве
График "скрипка" (violin plot) позволяет визуально сравнивать два распределения. В его основе лежит диаграмма box-plot, которая отражает числовые характеристики каждого распределения. Рисунок 11 внушает некоторую надежду, что ым все же не зря рассчитываем угол. Посмотрите, среднее значение выделено белой линией. Явно видим, что при обоих направлениях изменения угла средние значения распределений немного различаются. И если для нас это различие может показаться незначительным, модели машинного обучения достаточно чувствительны, чтобы уловить такие отклонения и использовать их для обучения.
sns.violinplot(data=data,x="Angle Up Down",y="Close",hue="Bull Bear",split=True)
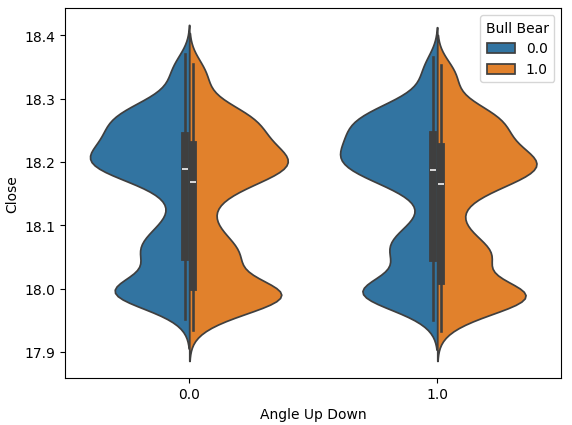
Рис. 11. Сравнение распределения ценовых данных между двумя классами угловых движений
Подготовка к моделированию данных
Перейдем к моделированию данных. Сначала импортируем необходимые библиотеки.
from sklearn.model_selection import train_test_split,cross_val_score from sklearn.preprocessing import StandardScaler from sklearn.ensemble import RandomForestRegressor, BaggingRegressor, GradientBoostingRegressor,AdaBoostRegressor from sklearn.svm import LinearSVR from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet from sklearn.neighbors import KNeighborsRegressor from sklearn.tree import DecisionTreeRegressor from sklearn.neural_network import MLPRegressor from sklearn.metrics import mean_squared_error
Разделим данные на обучающую и тестовую части.
#Let's split our data into train test splits train_data, test_data = train_test_split(data,test_size=0.5,shuffle=False)
Чтобы помочь модели в обучении, масштабируем данные. Важно убедиться, что объект масштабирования (scaler) обучается только на обучающем наборе данных. После этого тот же самый scaler можно использовать только для трансформации тестового набора, без повторного обучения на нем. Нельзя обучать scaler на всем наборе данных целиком, так как в этом случае параметры масштабирования будут включать информацию из будущего, т.е. информация о будущем будет "записана" в прошлое.
#Scale the data
scaler = StandardScaler()
scaler.fit(train_data[all_inputs])
train_scaled= pd.DataFrame(scaler.transform(train_data[all_inputs]),columns=all_inputs)
test_scaled = pd.DataFrame(scaler.transform(test_data[all_inputs]),columns=all_inputs)Определим датафрейм для хранения точности каждой модели.
#Create a dataframe to store our accuracy in training and testing columns = [ "Random Forest", "Bagging", "Gradient Boosting", "AdaBoost", "Linear SVR", "Linear Regression", "Ridge", "Lasso", "Elastic Net", "K Neighbors", "Decision Tree", "Neural Network" ] index = ["OHLC","Angle","All"] accuracy = pd.DataFrame(columns=columns,index=index)
Сохраним модели в списке.
#Store the models models = [ RandomForestRegressor(), BaggingRegressor(), GradientBoostingRegressor(), AdaBoostRegressor(), LinearSVR(), LinearRegression(), Ridge(), Lasso(), ElasticNet(), KNeighborsRegressor(), DecisionTreeRegressor(), MLPRegressor(hidden_layer_sizes=(4,6)) ]
Проведем перекрестную проверку каждой модели.
#Cross validate the models #First we have to iterate over the inputs for k in np.arange(0,len(cv_inputs)): current_inputs = cv_inputs[k] #Then fit each model on that set of inputs for i in np.arange(0,len(models)): score = cross_val_score(models[i],train_scaled[current_inputs],train_data[target],cv=5,scoring="neg_mean_squared_error",n_jobs=-1) accuracy.iloc[k,i] = -score.mean()
Мы протестировали модели с тремя наборами входных данных:
- Только цены OHLC
- Только рассчитанные наклон и угол
- Все доступные данные
Не все модели из нашего пула смогли эффективно использовать новые признаки. Из 12 протестированных моделей только KNeighbors показала прирост производительности на 20% благодаря новым признакам и стала, безусловно, лучшей на текущем этапе.
Хотя линейная регрессия продемонстрировала наилучший результат среди всех моделей, эти эксперименты подсказывают нам, что могут существовать и другие преобразования, о которых мы пока не знаем, и которые могли бы еще больше снизить уровень ошибок модели.
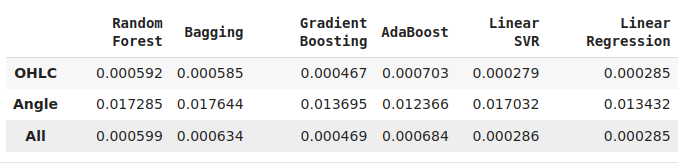
Рис. 12: Показатели точности наших моделей. Обратите внимание, что только две модели показали способность эффективно использовать новые признаки.
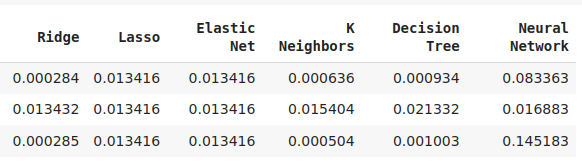
Рис. 13: Модели AdaBoost и KNeighbors показали наибольший потенциал, сосредоточимся на оптимизации модели KNeighbors
Глубокая оптимизация
Попробуем подобрать более подходящие параметры для нашего индикатора вместо параметров по умолчанию.
from sklearn.model_selection import RandomizedSearchCV
Создадим экземпляры модели.
model = KNeighborsRegressor(n_jobs=-1)Определим параметры настройки.
tuner = RandomizedSearchCV(model,
{
"n_neighbors": [2,3,4,5,6,7,8,9,10],
"weights": ["uniform","distance"],
"algorithm": ["auto","ball_tree","kd_tree","brute"],
"leaf_size": [1,2,3,4,5,10,20,30,40,50,60,100,200,300,400,500,1000],
"p": [1,2]
},
n_iter = 100,
n_jobs=-1,
cv=5
)Установим объект тюнера.
tuner.fit(train_scaled.loc[:,all_inputs],train_data[target])
Лучшие параметры, которые мы нашли.
tuner.best_params_
'p': 1,
'n_neighbors': 10,
'leaf_size': 100,
'algorithm': 'ball_tree'}
Лучший результат на обучающей выборке составил 71%. Нас не слишком волнуют ошибки на обучающей выборке. Гораздо больше интересует, насколько хорошо модель обобщает знания на новые, ранее не виденные данные.
tuner.best_score_
Проверка на переобучение
Теперь проверим, не переобучилась ли модели на обучающей выборке, не было ли подгонки. Подгонка возникает тогда, когда модель запоминает несущественные или шумовые закономерности из обучающих данных. Существует несколько способов проверить подгонку. Один из них — сравнить настроенную модель с моделью по умолчанию, которая не имеет никакой предварительной информации о данных.
#Testing for over fitting model = KNeighborsRegressor(n_jobs=-1) custom_model = KNeighborsRegressor(n_jobs=-1,weights= 'uniform',p=1,n_neighbors= 10,leaf_size= 100,algorithm='ball_tree')
Если оптимизированная модель не превосходит модель по умолчанию, это является серьезным признаком переобучения. Однако, как видно из результатов, мы смогли превзойти модель по умолчанию, что является хорошим знаком. Значит, мы настроили все правильно.
model.fit(train_scaled.loc[:,all_inputs],train_data[target]) custom_model.fit(train_scaled.loc[:,all_inputs],train_data[target])
| Модель по умолчанию | Настроенная модель |
|---|---|
| 0.0009797322460441842 | 0.0009697248896608824 |
Экспорт в ONNX
Open Neural Network Exchange (ONNX) — это протокол с открытым исходным кодом для создания и развертывания моделей машинного обучения независимо от языка. С помощью ONNX API экспортируем нашу модель из Python и импортируем ее в MQL5-программу.
Прежде всего, необходимо применить к ценовым данным те преобразования, которые можно будет всегда воспроизвести в MQL5. Поэтому мы сохраним значения среднего (mean) и стандартного отклонения (standard deviation) для каждого столбца в отдельный CSV-файл.
data.loc[:,all_inputs].mean().to_csv("USDZAR M1 MEAN.csv") data.loc[:,all_inputs].std().to_csv("USDZAR M1 STD.csv")
Затем применим преобразование к данным.
data.loc[:,all_inputs] = ((data.loc[:,all_inputs] - data.loc[:,all_inputs].mean())/ data.loc[:,all_inputs].std())
Импортируем необходимые библиотеки.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Определим тип входных данных нашей модели.
#Define the input shape
initial_type = [('float_input', FloatTensorType([1, len(all_inputs)]))]Обучим модель на всех имеющихся данных.
#Fit the model on all the data we have custom_model.fit(data.loc[:,all_inputs],data.loc[:,"Target"])
Конвертируем модель в формат ONNX и сохраним ее.
#Convert the model to ONNX format onnx_model = convert_sklearn(model, initial_types=initial_type,target_opset=12) #Save the ONNX model onnx.save(onnx_model,"USDZAR M1 OHLC Angle.onnx")
Создание торгового советника в MQL5
Теперь нужно интегрировать полученную модель в торговое приложение. Наша торговая стратегия будет использовать AI-модель для определения тренда на минутном таймфрейме. Дополнительное подтверждение сигнала мы будем получать, анализируя поведение валютной пары USDZAR на дневном графике. Если модель находит восходящий тренд, на дневном графике тоже должно быть бычье движение. Более того, для дополнительного подтверждения мы также будем использовать индекс доллара. Так, если на минутном графике мы видим сигнал на покупку, на дневном графике индекса доллара также должно наблюдаться бычье поведение, что будет служить признаком вероятного продолжения роста доллара на старших таймфреймах.
Начнем с импорта нашей ONNX-модели.
//+------------------------------------------------------------------+ //| Slope AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the ONNX files | //+------------------------------------------------------------------+ #resource "\\Files\\USDZAR M1 OHLC Angle.onnx" as const uchar onnx_buffer[];
Также загрузим торговую библиотеку для управления позициями.
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Определим глобальные переменные.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double mean_values[5] = {18.143698,18.145870,18.141644,18.143724,0.608216}; double std_values[5] = {0.112957,0.113113,0.112835,0.112970,0.580481}; long onnx_model; int macd_handle; int usd_ma_slow,usd_ma_fast; int usd_zar_slow,usd_zar_fast; double macd_s[],macd_m[],usd_zar_s[],usd_zar_f[],usd_s[],usd_f[]; double bid,ask; double vol = 0.3; double profit_target = 10; int system_state = 0; vectorf model_forecast = vectorf::Zeros(1);
Мы подошли к инициализации нашего приложения. На данный момент нам нужно загрузить нашу модель ONNX и индикаторы.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX file if(!onnx_load()) { //--- We failed to load the ONNX file return(INIT_FAILED); } //--- Load the MACD Indicator macd_handle = iMACD("EURUSD",PERIOD_CURRENT,12,26,9,PRICE_CLOSE); usd_zar_fast = iMA("USDZAR",PERIOD_D1,20,0,MODE_EMA,PRICE_CLOSE); usd_zar_slow = iMA("USDZAR",PERIOD_D1,60,0,MODE_EMA,PRICE_CLOSE); usd_ma_fast = iMA("DXY_Z4",PERIOD_D1,20,0,MODE_EMA,PRICE_CLOSE); usd_ma_slow = iMA("DXY_Z4",PERIOD_D1,60,0,MODE_EMA,PRICE_CLOSE); //--- Everything went fine return(INIT_SUCCEEDED); }
Если программа больше не используется, нужно освободить ресурсы
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release the handles don't need OnnxRelease(onnx_model); IndicatorRelease(macd_handle); IndicatorRelease(usd_zar_fast); IndicatorRelease(usd_zar_slow); IndicatorRelease(usd_ma_fast); IndicatorRelease(usd_ma_slow); }
Каждый раз при получении новых ценовых данных нужно обновить рыночную информацию, получить новое прогнозное значение от нашей модели и затем принять решение — открывать ли новую позицию на рынке или закрывать имеющуюся.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Update our market data update(); //--- Get a prediction from our model model_predict(); if(PositionsTotal() == 0) { find_entry(); } if(PositionsTotal() > 0) { manage_positions(); } } //+------------------------------------------------------------------+
Ниже определена функция, которая отвечает за обновление рыночных данных. Мы используем команду CopyBuffer, чтобы получить актуальные значения каждого индикатора и записать их в соответствующие массивы. Для подтверждения тренда будем использовать скользящие средние.
//+------------------------------------------------------------------+ //| Update our market data | //+------------------------------------------------------------------+ void update(void) { bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); CopyBuffer(macd_handle,0,0,1,macd_m); CopyBuffer(macd_handle,1,0,1,macd_s); CopyBuffer(usd_ma_fast,0,0,1,usd_f); CopyBuffer(usd_ma_slow,0,0,1,usd_s); CopyBuffer(usd_zar_fast,0,0,1,usd_zar_f); CopyBuffer(usd_zar_slow,0,0,1,usd_zar_s); } //+------------------------------------------------------------------+
Но это еще не всё. Нам нужно точно определить, как именно модель будет делать прогнозы. Начнем с расчета угла, сформированного колебаниями цен, затем сохраним входные данные модели в вектор. После этого стандартизируем и масштабируем входные данные перед вызовом функции OnnxRun, которая и вернет прогноз от модели.
//+------------------------------------------------------------------+ //| Get a forecast from our model | //+------------------------------------------------------------------+ void model_predict(void) { float angle = (float) MathArctan(((iOpen(Symbol(),PERIOD_M1,1) - iOpen(Symbol(),PERIOD_M1,20)) / (iClose(Symbol(),PERIOD_M1,1) - iClose(Symbol(),PERIOD_M1,20)))); vectorf model_inputs = {(float) iOpen(Symbol(),PERIOD_M1,1),(float) iHigh(Symbol(),PERIOD_M1,1),(float) iLow(Symbol(),PERIOD_M1,1),(float) iClose(Symbol(),PERIOD_M1,1),(float) angle}; for(int i = 0; i < 5; i++) { model_inputs[i] = (float)((model_inputs[i] - mean_values[i])/std_values[i]); } //--- Log Print("Model inputs: "); Print(model_inputs); if(!OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,model_forecast)) { Comment("Failed to obtain a forecast from our model: ",GetLastError()); } }
Следующая функция загрузит нашу модель ONNX из буфера, который мы определили ранее.
//+------------------------------------------------------------------+ //| ONNX Load | //+------------------------------------------------------------------+ bool onnx_load(void) { //--- Create the ONNX model from the buffer we defined onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Define the input and output shapes ulong input_shape[] = {1,5}; ulong output_shape[] = {1,1}; //--- Validate the I/O parameters if(!(OnnxSetInputShape(onnx_model,0,input_shape))||!(OnnxSetOutputShape(onnx_model,0,output_shape))) { //--- We failed to define the I/O parameters Comment("[ERROR] Failed to load AI Model Correctly: ",GetLastError()); return(false); } //--- Everything was okay return(true); }
Также нужны четкие правила закрытия позиций. Если плавающая прибыль по текущим позициям превышает заданную цель по прибыли, закрываем позиции. Также закрываем позиции если изменилось направление сигнала.
//+------------------------------------------------------------------+ //| Manage our open positions | //+------------------------------------------------------------------+ void manage_positions(void) { if(PositionSelectByTicket(PositionGetTicket(0))) { if(PositionGetDouble(POSITION_PROFIT) > profit_target) { Trade.PositionClose(Symbol()); } } if(system_state == 1) { if(macd_m[0] < macd_s[0]) { if(model_forecast[0] < iClose(Symbol(),PERIOD_M1,0)) { Trade.PositionClose(Symbol()); } } } if(system_state == -1) { if(macd_m[0] > macd_s[0]) { if(model_forecast[0] > iClose(Symbol(),PERIOD_M1,0)) { Trade.PositionClose(Symbol()); } } } }
Посмотрим, как будем открывать позиции. Мы открываем покупку только если выполняются все условия:
- Главная линия MACD находится выше сигнальной линии;
- Прогноз от модели выше текущей цены закрытия;
- Индекс доллара и валютная пара USDZAR имеют бычье движение на дневном таймфрейме.
//+------------------------------------------------------------------+ //| Find an entry | //+------------------------------------------------------------------+ void find_entry(void) { if(macd_m[0] > macd_s[0]) { if(model_forecast[0] > iClose(Symbol(),PERIOD_M1,0)) { if((usd_f[0] > usd_s[0]) && (usd_zar_f[0] > usd_zar_s[0])) { Trade.Buy(vol,Symbol(),ask,0,0,"Slope AI"); system_state = 1; } } } if(macd_m[0] < macd_s[0]) { if(model_forecast[0] < iClose(Symbol(),PERIOD_M1,0)) { if((usd_f[0] < usd_s[0]) && (usd_zar_f[0] < usd_zar_s[0])) { Trade.Sell(vol,Symbol(),bid,0,0,"Slope AI"); system_state = -1; } } } }
Рис. 14: Работа стратегии
Заключение
Не так просто интегрировать в стратегию информацию о наклоне угла, образованного движением цены. Тем не менее, любой прогресс в этом направлении может окупить затраченное время. Применение признака, отражающего наклон цены, улучшило показатели модели KNeighbors на 20%. Каких еще улучшений можно достичь, если продолжить развивать эту область? Более того, это подчеркивает важный факт: вероятно, каждая модель имеет собственный набор преобразований, который позволяет ей улучшать результаты. Поэтому наша задача — найти соответствие между моделью и наиболее подходящими для нее трансформациями.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/16124
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Наблюдатель Connexus (Часть 8): Добавление Request Observer (Наблюдатель запросов)
Наблюдатель Connexus (Часть 8): Добавление Request Observer (Наблюдатель запросов)
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования