
PythonとMQL5を使用した特徴量エンジニアリング(第2回):価格の角度

機械学習モデルは非常に繊細なツールです。本連載では、データに適用する変換がモデルのパフォーマンスにどのような影響を与えるのかを、これまで以上に詳しく掘り下げていきます。また、モデルは入力とターゲットの関係性の表現方法にも敏感です。つまり、モデルが効果的に学習するためには、手元のデータをもとに新たな特徴量を作成する必要があるかもしれません。
市場データから生成できる特徴量の数に制限はありません。データに適用する変換や、新たに作成する特徴量は、誤差レベルを変化させます。本記事では、どの変換や特徴量エンジニアリング手法が誤差をゼロに近づけるのかを見極める手助けをしたいと考えています。また、同じ変換でもモデルによって影響が異なることにも注目します。そのため、この記事では、使用するモデルアーキテクチャに応じた適切な変換の選び方についても解説します。
取引戦略の概要
MQL5フォーラムを検索すると、価格レベルの変化によって形成される角度をどのように計算するかについての投稿が多数見つかります。直感的には、弱気トレンドでは負の角度が生じ、強気トレンドでは0より大きい角度が生じると考えられます。このアイデア自体は理解しやすいものの、実装はそれほど簡単ではありません。価格の変化による角度を組み込んだ戦略を構築しようとするトレーダーにとって、克服すべき課題は多く存在します。本記事では、実際に資本を投じる前に検討すべき重要な問題点を取り上げます。また、単に戦略の欠点を指摘するだけでなく、改善策についても提案します。
価格変動による角度の計算は、トレンドの確認手法の一つと考えられます。トレーダーは通常、トレンドラインを利用して市場の主要なトレンドを特定します。トレンドラインは一般的に、2〜3点の極端な価格ポイントを直線で結びます。価格がトレンドラインを上抜けた場合、一部のトレーダーはそれを市場の強さのサインと見なし、そのタイミングでトレンドに参加します。逆に、価格がトレンドラインを下抜けた場合、市場の弱さの兆候と捉えられ、トレンドが終息に向かっていると判断されることがあります。
しかし、トレンドラインには大きな制約があります。それは「主観的に引かれる」という点です。トレーダーは、自分の市場観を裏付けるようにトレンドラインを引き直すことが可能であり、その市場観が誤っている場合でも分析結果を歪めてしまう恐れがあります。したがって、より客観的で堅牢な方法でトレンドラインを定義しようとするのは自然な流れです。その手法の一つとして、多くのトレーダーは価格変化によって生じる傾斜(スロープ)を数値的に計算しようとします。根本的な前提として、「傾斜を知ることは、価格変動によって形成されるトレンドラインの方向を知ることと同義である」と考えられています。
ここで、最初に直面する課題は「傾斜の定義」です。多くのトレーダーは、傾斜を「価格の変化量 ÷ 時間の変化量」として計算しようとします。しかし、このアプローチにはいくつかの問題点があります。このアプローチにはいくつかの問題点があります。第一に、株式市場は週末に休場するため、MetaTrader 5のチャート上では市場が閉じている間の時間経過は記録されません。そのため、手元のデータから経過時間を推測する必要があります。単純な「価格の変化量 ÷ 時間の変化量」という計算式を採用すると、週末の時間経過が考慮されないため、週末に大きな価格変動(ギャップ)があった場合、傾斜の計算値が実際よりも過大評価されてしまいます。
また、この手法では、時間の取り扱いによって計算結果が大きく変わる可能性があります。例えば、週末の時間を無視すると傾斜の値は過大になりますが、逆に週末の時間を考慮すると傾斜は小さくなります。つまり、同じデータを分析しているにもかかわらず、異なる傾斜値が得られる可能性があるということです。これは望ましくありません。理想的には、同じデータに対して一貫性のある決定論的な(変動しない)計算結果が得られるべきです。
これらの問題を克服するために、別の計算方法を提案します。それは、「傾斜を『始値の変化量 ÷ 終値の変化量』として計算する」方法です。この手法では、時間の要素をx軸から排除することで、終値が始値の変化に対してどれほど敏感に反応するかを測定できます。この量の絶対値が1より大きい場合、始値の大きな変化は終値にほとんど影響を与えないことがわかります。同様に、数量の絶対値が1未満の場合、始値の小さな変化が終値に大きな影響を与える可能性があることがわかります。さらに、傾斜の係数が負の場合、始値と終値は反対方向に変化する傾向があることがわかります。
しかし、この新しい指標にも課題があります。特に、トレーダーにとって重要な問題の一つは、この指標が十字線に敏感すぎる ことです。十字線は、ローソク足の始値と終値がほぼ同じ場合に形成されるパターンです。問題は、十字線が集中的に発生すると、傾斜の計算に大きな影響を与えてしまうことです(下図1参照)。最良のケースでは、これらの十字線により、計算結果が0または無限大になることがあります。しかし、最悪のケースでは、0での除算が発生するため 実行時エラー につながる可能性があります。
図1:十字線の束
方法論の概要
USDZARペアのM1データ10,000行を分析しました。データはMQL5スクリプトを用いてMetaTrader 5ターミナルから取得しました。まず、先に提案した式を用いて傾斜を計算し、その角度を求めるために逆正接の三角関数を使用しました。しかし、算出された値は市場相場との相関が極めて低いことが判明しました。
相関レベルが低いにもかかわらず、USDZARの将来の為替レートを予測するために、以下の3種類の入力データを用いて12種類のAIモデルをトレーニングしました。
- MetaTrader 5ターミナルから取得したOHLC(始値・高値・安値・終値)データ
- 価格変動から算出した傾斜と角度
- 上記の全データを組み合わせたもの
最も優れたパフォーマンスを示したのは、OHLCデータを用いた単純線形回帰モデルでした。ただし、このモデルの入力をグループ1(OHLCデータのみ)からグループ3(全データの組み合わせ)に変更しても、精度に変化は見られませんでした。また、観察したモデルの中で、グループ2(傾斜と角度のみ)の方がグループ1よりも優れた結果を示したものはありませんでした。しかし、検証したモデルのうち2つは、利用可能なすべてのデータを組み合わせたときに最も高いパフォーマンスを発揮しました。特に、KNeighborsアルゴリズムは新たに導入した特徴量により、パフォーマンスが20%向上しました。この結果から、さらなるデータ変換を行うことで、さらなる精度向上が可能かどうかを検討する価値があると考えています。
最終的に、KNeighborsモデルのパラメータを過学習を防ぎつつ適切に調整し、ONNX形式にエクスポートして、AI搭載のエキスパートアドバイザー(EA)に統合することに成功しました。
必要なデータの取得
以下のスクリプトは、MetaTrader5ターミナルから必要なデータを取得し、CSV形式で保存します。分析したい市場にスクリプトをドラッグアンドドロップするだけで、私たちと一緒に作業を進めることができます。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/ja/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- File name string file_name = "Market Data " + Symbol() +".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
探索的データ分析
分析を始めるには、まず必要なライブラリをインポートしましょう。
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
次に市場データを読み取ります。
#Read in the data data = pd.read_csv("Market Data USDZAR.csv")
データの順序が間違っているので、逆にします。
#The data is in reverse order, correct that data = data[::-1]
どのくらい先の将来を予測したいかを定義します。
#Define the forecast horizon look_ahead = 20
傾斜計算を適用してみましょう。残念ながら、傾斜の計算結果が必ずしも実数になるとは限りません。これは、現在のバージョンのアルゴリズムの制限の1つです。データフレーム内の欠損値をどのように処理するかを決定する必要があることに留意してください。今のところ、データフレーム内のすべての欠損値を削除します。
#Calculate the angle formed by the changes in price, using a ratio of high and low price. #Then calculate arctan to realize the angle formed by the changes in pirce data["Slope"] = (data["Close"] - data["Close"].shift(look_ahead))/(data["Open"] - data["Open"].shift(look_ahead)) data["Angle"] = np.arctan(data["Slope"]) data.describe()
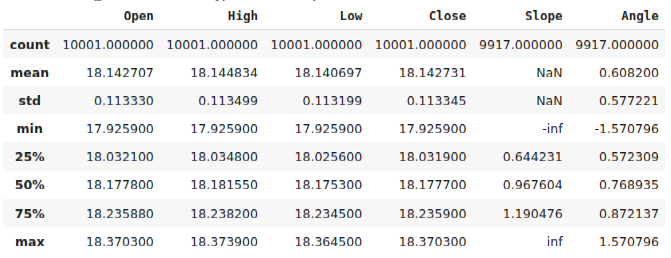
図2:価格によって作られた角度を計算した後のデータフレーム
傾斜計算が無限大と評価されたインスタンスを拡大してみましょう。
data.loc[data["Slope"] == np.inf]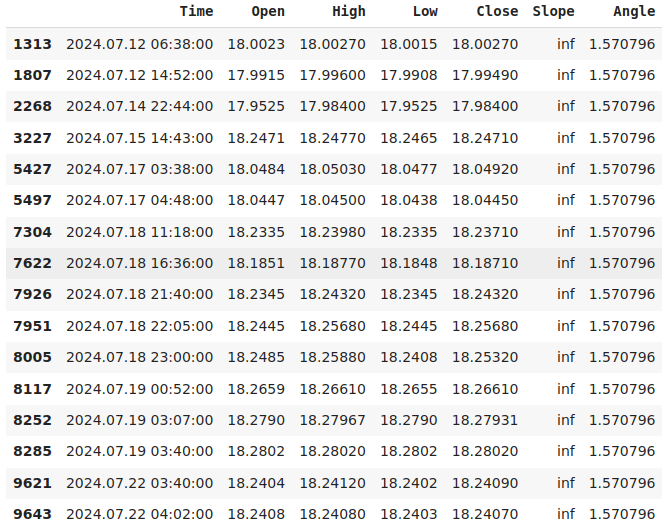
図3:無限傾斜の記録は、始値が変わらなかった例を示している
下の図4のプロットでは、傾斜の計算が無限大になるインスタンスの1つをランダムに選択しました。プロットは、これらのレコードが価格変動にマッピングされており、始値は変化していないことを示しています。
pt = 1807 y = data.loc[pt,"Open"] plt.plot(data.loc[(pt - look_ahead):pt,"Open"]) plt.axhline(y=y,color="red") plt.xlabel("Time") plt.ylabel("USDZAR Open Price") plt.title("A slope of INF means the price has not changed")
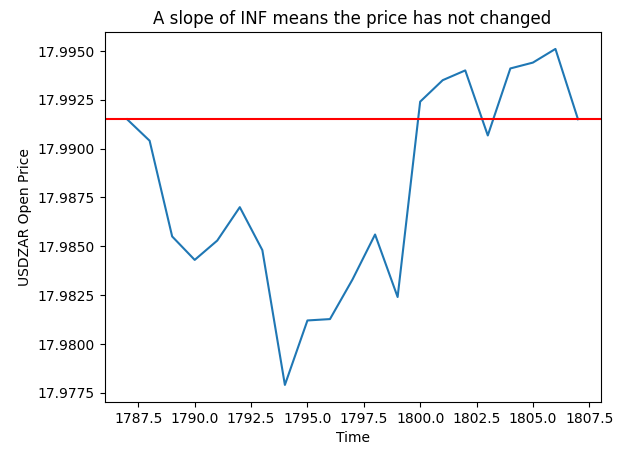
図3:計算した傾斜値を視覚化する
今のところ、欠損値をすべて削除して議論を簡素化します。
data.dropna(inplace=True)
それでは、データのインデックスをリセットしましょう。
data.reset_index(drop=True,inplace=True)
角度の計算結果をプロットしてみましょう。下の図4からわかるように、角度の計算は0を中心におこなわれます。0から離れるほど価格レベルの変化が大きくなるため、これによりコンピューターにスケールの感覚が与えられる可能性があります。
data.loc[:100,"Angle"].plot()
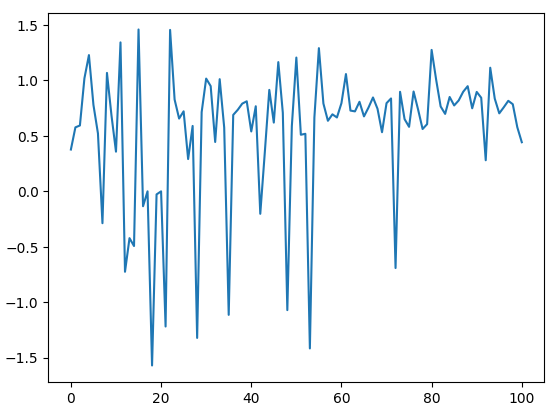
図4:価格変動によって生じる角度を視覚化する
ここで、作成した新しい特徴量のノイズを推定してみましょう。ここでは、ノイズを「価格によって形成された角度が減少したにもかかわらず、同じ期間内に価格レベルが上昇した回数」と定義します。理想的には、この特徴量が価格レベルと一貫して増減することが望ましいため、この性質は好ましくありません。しかし、実際には、新しい計算手法による値は半分のケースでは価格と連動するものの、残りの半分では独立して変動する可能性があります。
ノイズを定量化するために、まず「価格の傾きが増加したが、将来の価格レベルが減少したケース」の行数を数えました。その後、この数を「傾きが増加した全インスタンスの総数」で割りました。この指標を用いることで、「線の傾きの将来値を知っていたとしても、同じ予測期間内での価格レベルの変化を正確に把握することは難しい」という結論が得られました。
#How clean are the signals generated? 1 - (data.loc[(data["Slope"] < data["Slope"].shift(-look_ahead)) & (data["Close"] > data["Close"].shift(-look_ahead))].shape[0] / data.loc[(data["Slope"] < data["Slope"].shift(-look_ahead))].shape[0])
探索的データ分析
まず、入力と出力を定義する必要があります。
#Define our inputs and target ohlc_inputs = ["Open","High","Low","Close"] trig_inputs = ["Angle"] all_inputs = ohlc_inputs + trig_inputs cv_inputs = [ohlc_inputs,trig_inputs,all_inputs] target = "Target"
ここで、古典的な目標である将来の価格を定義します。
#Define the target data["Target"] = data["Close"].shift(-look_ahead)
各ローソク足を作成したプライスアクションをモデルに伝えるために、いくつかのカテゴリも追加しましょう。現在のローソク足が過去20本のローソク足で起こった強気の動きの結果である場合、カテゴリ値を1に設定してそれをシンボル化します。それ以外の場合、値は0に設定されます。角度の変更に対しても同じラベル付け手法を実行します。
#Add a few labels data["Bull Bear"] = np.nan data["Angle Up Down"] = np.nan data.loc[data["Close"] > data["Close"].shift(look_ahead), "Bull Bear"] = 0 data.loc[data["Angle"] > data["Angle"].shift(look_ahead),"Angle Up Down"] = 0 data.loc[data["Close"] < data["Close"].shift(look_ahead), "Bull Bear"] = 1 data.loc[data["Angle"] < data["Angle"].shift(look_ahead),"Angle Up Down"] = 1
データを書式設定します。
data.dropna(inplace=True) data.reset_index(drop=True,inplace=True) data
データの相関レベルを分析してみましょう。新しい角度計算に関連するノイズレベルを推定したときに、価格と角度計算が一致するのは約50%の時間だけであることがわかったことを思い出してください。したがって、図5で観察された相関レベルが低いことは驚くべきことではありません。
#Let's analyze the correlation levels sns.heatmap(data.loc[:,all_inputs].corr(),annot=True)
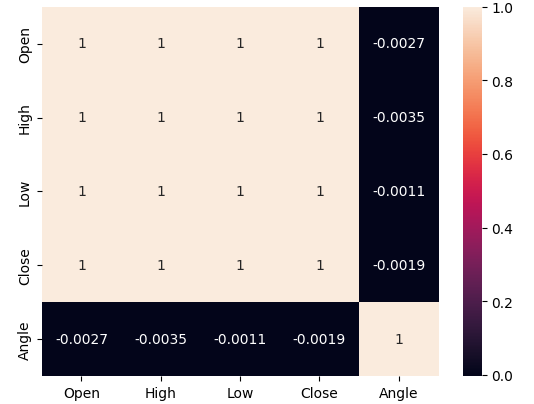
図5:角度計算と価格特徴とはほとんど相関がない
また、価格によって作成された角度をx軸に、終値をy軸に取った散布図も作成してみましょう。得られた結果は期待できるものではありません。価格レベルが下がった場合(青い点)と価格レベルが上昇した場合の間には、過剰な重複があります。このため、機械学習モデルでは、価格変動の2つの可能なクラス間のマッピングを推定することが困難になります。
sns.scatterplot(data=data,y="Close",x="Angle",hue="Bull Bear")
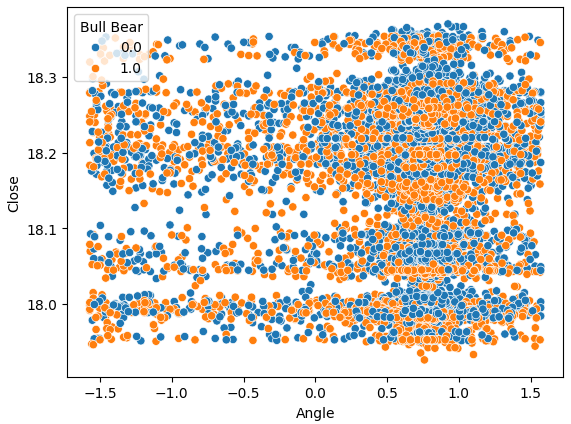
図6:角度計算ではデータの分離がうまくいかない
傾斜と角度という2つの設計された特徴量を相互に散布図にプロットすると、データに適用した非線形変換を明確に観察できます。データの大部分は、曲線状に広がる両端の間に収まっています。しかし残念ながら、強気と弱気の価格変動を明確に区別できるようなパターンは見られず、これを利用して将来の価格レベルを予測する上での優位性は得られませんでした。
sns.scatterplot(data=data,x="Angle",y="Slope",hue="Bull Bear")
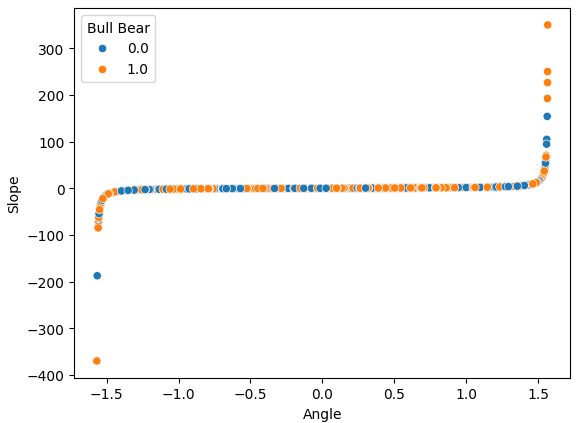
図7:OHLC価格データに適用した非線形変換を視覚化する
先ほど51%と推定したノイズを、視覚的に確認してみましょう。x軸には2つの値を設定し、それぞれ「角度計算が増加した場合」と「角度計算が減少した場合」を表します。y軸には終値を記録し、各ドットは価格レベルの変動を示します。青色の点は、将来の価格レベルが下落したケースを示しています。
これまではノイズを数値で推定していましたが、今回のプロットによって、その実態を視覚的に捉えることができるようになりました。下の図8を見てもわかるように、将来の価格レベルの変動は、価格によって形成される角度の変化とはほとんど関係がないことが明確に示されています。
sns.swarmplot(data=data,x="Angle Up Down",y="Close",hue="Bull Bear")
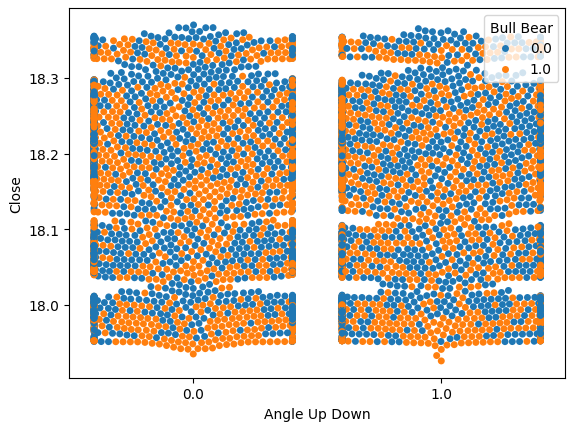
図8:将来の価格水準は角度の変化とは関係がないようだ
データを3Dで視覚化すると、信号にどれだけノイズが多いかがわかります。少なくとも、強気または弱気のポイントの集まりがいくつか観察されると予想されます。しかし、この特定の例では、何も存在しません。クラスタの存在により、取引シグナルとして解釈できるパターンが特定される可能性があります。
#Define the 3D Plot fig = plt.figure(figsize=(7,7)) ax = plt.axes(projection="3d") ax.scatter(data["Slope"],data["Angle"],data["Close"],c=data["Bull Bear"]) ax.set_xlabel("Slope") ax.set_ylabel("Angle") ax.set_zlabel("Close")
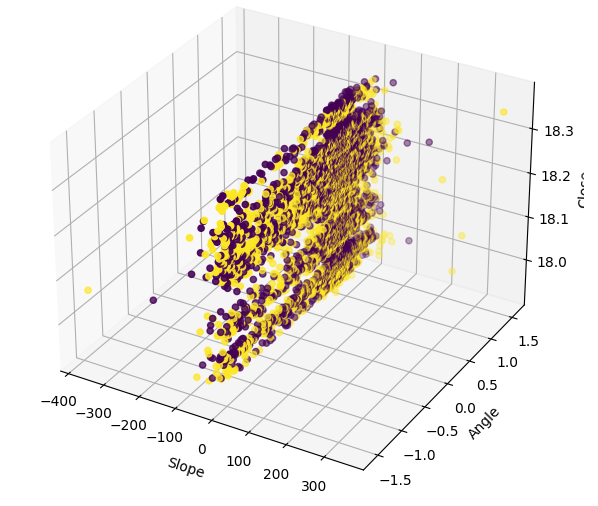
図9:傾斜データを3次元で視覚化する
バイオリン図を用いることで、2つの分布を視覚的に比較できます。このプロットの中心には箱ひげ図が組み込まれており、それぞれの分布の数値的な特徴を要約しています。下の図10を見ると、角度の計算が無駄ではない可能性が示唆されます。各箱ひげ図の平均値は白い線で示されており、角度の変動に応じた2つのケースにおいて、平均値がわずかに異なっていることが明確に確認できます。このわずかな違いは、人間にとっては些細なものに見えるかもしれません。しかし、機械学習モデルはデータ分布の微細な差異を検出し、それを学習するのに十分な感度を持っています。
sns.violinplot(data=data,x="Angle Up Down",y="Close",hue="Bull Bear",split=True)
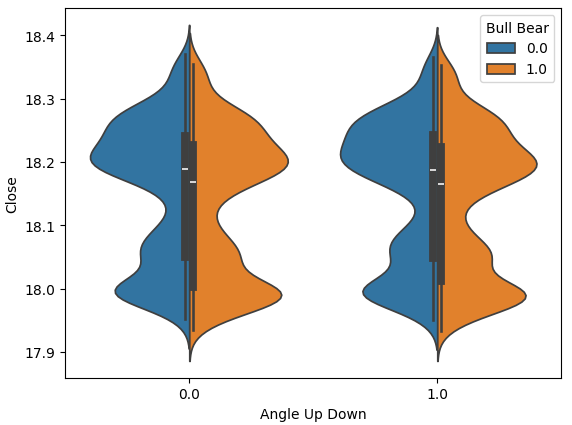
図10:2つの角度の動きのクラス間の価格データの分布を比較する
データモデル化の準備
それでは、データをモデル化してみましょう。まず、必要なライブラリをインポートします。
from sklearn.model_selection import train_test_split,cross_val_score from sklearn.preprocessing import StandardScaler from sklearn.ensemble import RandomForestRegressor, BaggingRegressor, GradientBoostingRegressor,AdaBoostRegressor from sklearn.svm import LinearSVR from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet from sklearn.neighbors import KNeighborsRegressor from sklearn.tree import DecisionTreeRegressor from sklearn.neural_network import MLPRegressor from sklearn.metrics import mean_squared_error
データを訓練とテストの分割に分割します。
#Let's split our data into train test splits train_data, test_data = train_test_split(data,test_size=0.5,shuffle=False)
データをスケーリングすることで、モデルの学習効率を向上させることができます。ただし、スケーラーオブジェクトは訓練セットのみに適用し、テストセットを変換する際には再度適合させないように注意してください。データセット全体に対してスケーラーを適合させてしまうと、スケーリングの際に学習したパラメータが将来の情報を過去に漏らしてしまう(データリークの発生)可能性があります。
#Scale the data
scaler = StandardScaler()
scaler.fit(train_data[all_inputs])
train_scaled= pd.DataFrame(scaler.transform(train_data[all_inputs]),columns=all_inputs)
test_scaled = pd.DataFrame(scaler.transform(test_data[all_inputs]),columns=all_inputs)各モデルの精度を保存するためのデータフレームを定義します。
#Create a dataframe to store our accuracy in training and testing columns = [ "Random Forest", "Bagging", "Gradient Boosting", "AdaBoost", "Linear SVR", "Linear Regression", "Ridge", "Lasso", "Elastic Net", "K Neighbors", "Decision Tree", "Neural Network" ] index = ["OHLC","Angle","All"] accuracy = pd.DataFrame(columns=columns,index=index)
モデルをリストに保存します。
#Store the models models = [ RandomForestRegressor(), BaggingRegressor(), GradientBoostingRegressor(), AdaBoostRegressor(), LinearSVR(), LinearRegression(), Ridge(), Lasso(), ElasticNet(), KNeighborsRegressor(), DecisionTreeRegressor(), MLPRegressor(hidden_layer_sizes=(4,6)) ]
各モデルを交差検証します。
#Cross validate the models #First we have to iterate over the inputs for k in np.arange(0,len(cv_inputs)): current_inputs = cv_inputs[k] #Then fit each model on that set of inputs for i in np.arange(0,len(models)): score = cross_val_score(models[i],train_scaled[current_inputs],train_data[target],cv=5,scoring="neg_mean_squared_error",n_jobs=-1) accuracy.iloc[k,i] = -score.mean()
次の3セットの入力を使用してモデルをテストしました。
- OHLCの価格のみ
- 作成した傾斜と角度のみ
- 保有するすべてのデータ
すべてのモデルがこれらの特徴量を効果的に活用できたわけではありません。候補として検討した12のモデルの中で、KNeighborsモデルは新しい特徴量によってパフォーマンスが20%向上し、現時点で最も優れたモデルとなりました。
一方で、線形回帰は全体の中で最も優れたモデルではあるものの、今回の結果は私たちがまだ気づいていない他のデータ変換が存在し、それによって精度がさらに低下する可能性もあることを示唆しています。
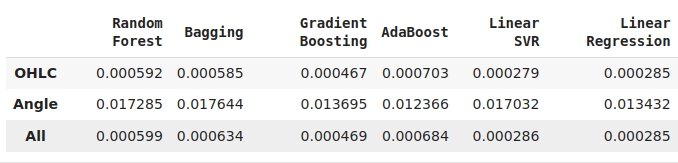
図11:精度レベルの一部(開発した新しい特徴量の使用スキルを実証したモデルは2つだけであることに注意)
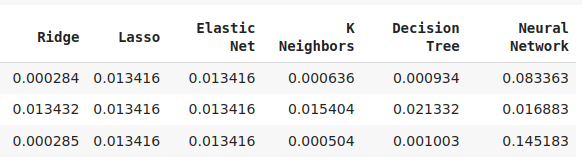
図12:AdaBoostとKNeighborsが最も有望なモデルだったので、KNeighborsモデルを最適化することにした
より深い最適化
インジケーターのデフォルト設定よりも優れた設定を見つけてみましょう。
from sklearn.model_selection import RandomizedSearchCV
モデルのインスタンスを作成します。
model = KNeighborsRegressor(n_jobs=-1)チューニングパラメータを定義します。
tuner = RandomizedSearchCV(model,
{
"n_neighbors": [2,3,4,5,6,7,8,9,10],
"weights": ["uniform","distance"],
"algorithm": ["auto","ball_tree","kd_tree","brute"],
"leaf_size": [1,2,3,4,5,10,20,30,40,50,60,100,200,300,400,500,1000],
"p": [1,2]
},
n_iter = 100,
n_jobs=-1,
cv=5
)チューナーオブジェクトを適合させます。
tuner.fit(train_scaled.loc[:,all_inputs],train_data[target])
私たちが見つけた最良のパラメータ。
tuner.best_params_
'p':1,
'n_neighbors':10,
'leaf_size':100,
'algorithm':'ball_tree'}
訓練セットでの最高スコアは71%でした。訓練誤差についてはあまり気にしません。私たちがより関心を持っているのは、モデルが新しいデータにどれだけうまく一般化できるかということです。
tuner.best_score_
過剰適合のテスト
モデルが訓練セットに過剰適合していないか確認してみましょう。過剰適合とは、モデルが訓練データの本質的ではないパターンやノイズまで学習してしまうことで発生します。過剰適合をテストする方法はいくつかありますが、そのひとつとして、カスタマイズされたモデルと、データに関する事前知識を持たないモデルを比較する方法があります。
#Testing for over fitting model = KNeighborsRegressor(n_jobs=-1) custom_model = KNeighborsRegressor(n_jobs=-1,weights= 'uniform',p=1,n_neighbors= 10,leaf_size= 100,algorithm='ball_tree')
デフォルトのモデルを上回るパフォーマンスが得られなかった場合、モデルを訓練セットに過剰にカスタマイズしてしまった可能性が高いと考えられます。今回の結果では、デフォルトのモデルを明確に上回るパフォーマンスを発揮しており、これは良いニュースです。
model.fit(train_scaled.loc[:,all_inputs],train_data[target]) custom_model.fit(train_scaled.loc[:,all_inputs],train_data[target])
| デフォルトモデル | カスタマイズモデル |
|---|---|
| 0.0009797322460441842 | 0.0009697248896608824 |
ONNXへのエクスポート
Open Neural Network Exchange (ONNX)は、モデルに依存しない方法で機械学習モデルを構築および共有するためのオープンソースプロトコルです。ONNX APIを利用して、PythonからAIモデルをエクスポートし、MQL5プログラムにインポートします。
まず、MQL5で常に再現できる変換を価格データに適用する必要があります。各列の平均値と標準偏差値をCSVファイルに保存しましょう。
data.loc[:,all_inputs].mean().to_csv("USDZAR M1 MEAN.csv") data.loc[:,all_inputs].std().to_csv("USDZAR M1 STD.csv")
次に、データに変換を適用します。
data.loc[:,all_inputs] = ((data.loc[:,all_inputs] - data.loc[:,all_inputs].mean())/ data.loc[:,all_inputs].std())
次に、必要なライブラリをインポートします。
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
モデルの入力タイプを定義します。
#Define the input shape
initial_type = [('float_input', FloatTensorType([1, len(all_inputs)]))]保有するすべてのデータにモデルを適合させます。
#Fit the model on all the data we have custom_model.fit(data.loc[:,all_inputs],data.loc[:,"Target"])
モデルをONNX形式に変換して保存します。
#Convert the model to ONNX format onnx_model = convert_sklearn(model, initial_types=initial_type,target_opset=12) #Save the ONNX model onnx.save(onnx_model,"USDZAR M1 OHLC Angle.onnx")
MQL5でEAを構築する
次に、AIモデルを取引アプリケーションに統合し、市場に対して優位に取引できるようにします。私たちの取引戦略では、AIモデルを使用してM1チャートでトレンドを検出します。その上で、USADZARペアのパフォーマンスを日足時間枠で確認し、追加の確認を求めます。AIモデルが上昇トレンドを検出している場合、日足チャートでも強気の価格変動を確認する必要があります。さらに、ドル指数からの確認も求めます。具体的には、M1チャートで買いポジションを取る場合、ドル指数の日足チャートでも強気の価格変動を観察することが重要です。これにより、ドルが大きな時間枠で上昇を続ける可能性が高いことを示す兆候が得られます。
まず、作成したONNXモデルをインポートする必要があります。
//+------------------------------------------------------------------+ //| Slope AI.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/ja/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/ja/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the ONNX files | //+------------------------------------------------------------------+ #resource "\\Files\\USDZAR M1 OHLC Angle.onnx" as const uchar onnx_buffer[];
ポジションを管理するために、取引ライブラリもロードしましょう。
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
必要となるグローバル変数をいくつか定義します。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double mean_values[5] = {18.143698,18.145870,18.141644,18.143724,0.608216}; double std_values[5] = {0.112957,0.113113,0.112835,0.112970,0.580481}; long onnx_model; int macd_handle; int usd_ma_slow,usd_ma_fast; int usd_zar_slow,usd_zar_fast; double macd_s[],macd_m[],usd_zar_s[],usd_zar_f[],usd_s[],usd_f[]; double bid,ask; double vol = 0.3; double profit_target = 10; int system_state = 0; vectorf model_forecast = vectorf::Zeros(1);
これで、取引アプリケーションの初期化手順に到達しました。現時点で必要なのは、ONNXモデルとテクニカルインジケーターをロードすることだけです。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Load the ONNX file if(!onnx_load()) { //--- We failed to load the ONNX file return(INIT_FAILED); } //--- Load the MACD Indicator macd_handle = iMACD("EURUSD",PERIOD_CURRENT,12,26,9,PRICE_CLOSE); usd_zar_fast = iMA("USDZAR",PERIOD_D1,20,0,MODE_EMA,PRICE_CLOSE); usd_zar_slow = iMA("USDZAR",PERIOD_D1,60,0,MODE_EMA,PRICE_CLOSE); usd_ma_fast = iMA("DXY_Z4",PERIOD_D1,20,0,MODE_EMA,PRICE_CLOSE); usd_ma_slow = iMA("DXY_Z4",PERIOD_D1,60,0,MODE_EMA,PRICE_CLOSE); //--- Everything went fine return(INIT_SUCCEEDED); }
プログラムが使用されなくなった場合は、使用していたリソースを解放しましょう。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release the handles don't need OnnxRelease(onnx_model); IndicatorRelease(macd_handle); IndicatorRelease(usd_zar_fast); IndicatorRelease(usd_zar_slow); IndicatorRelease(usd_ma_fast); IndicatorRelease(usd_ma_slow); }
更新された価格を受け取るたびに、新しい市場データを保存し、モデルから新しい予測を取得して、市場でポジションを探す必要があるか、または保有しているポジションを閉じる必要があるかを決定します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Update our market data update(); //--- Get a prediction from our model model_predict(); if(PositionsTotal() == 0) { find_entry(); } if(PositionsTotal() > 0) { manage_positions(); } } //+------------------------------------------------------------------+
実際に市場データを更新する関数は以下のように定義されています。各インジケーターの現在の値を配列バッファーに取得するには、CopyBufferコマンドを使用します。トレンドの確認にはこれらの移動平均指標を使用します。
//+------------------------------------------------------------------+ //| Update our market data | //+------------------------------------------------------------------+ void update(void) { bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); CopyBuffer(macd_handle,0,0,1,macd_m); CopyBuffer(macd_handle,1,0,1,macd_s); CopyBuffer(usd_ma_fast,0,0,1,usd_f); CopyBuffer(usd_ma_slow,0,0,1,usd_s); CopyBuffer(usd_zar_fast,0,0,1,usd_zar_f); CopyBuffer(usd_zar_slow,0,0,1,usd_zar_s); } //+------------------------------------------------------------------+
それだけでなく、モデルが予測をどのように行うのかを正確に定義する必要があります。さらに、まず価格変動によって形成される角度を計算し、次にモデル入力をベクトルに保存します。最後に、OnnxRun関数を呼び出してAIモデルから予測を取得する前に、モデル入力を標準化してスケーリングします。
//+------------------------------------------------------------------+ //| Get a forecast from our model | //+------------------------------------------------------------------+ void model_predict(void) { float angle = (float) MathArctan(((iOpen(Symbol(),PERIOD_M1,1) - iOpen(Symbol(),PERIOD_M1,20)) / (iClose(Symbol(),PERIOD_M1,1) - iClose(Symbol(),PERIOD_M1,20)))); vectorf model_inputs = {(float) iOpen(Symbol(),PERIOD_M1,1),(float) iHigh(Symbol(),PERIOD_M1,1),(float) iLow(Symbol(),PERIOD_M1,1),(float) iClose(Symbol(),PERIOD_M1,1),(float) angle}; for(int i = 0; i < 5; i++) { model_inputs[i] = (float)((model_inputs[i] - mean_values[i])/std_values[i]); } //--- Log Print("Model inputs: "); Print(model_inputs); if(!OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,model_forecast)) { Comment("Failed to obtain a forecast from our model: ",GetLastError()); } }
次の関数は、先ほど定義したONNXバッファからONNXモデルを読み込みます。
//+------------------------------------------------------------------+ //| ONNX Load | //+------------------------------------------------------------------+ bool onnx_load(void) { //--- Create the ONNX model from the buffer we defined onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Define the input and output shapes ulong input_shape[] = {1,5}; ulong output_shape[] = {1,1}; //--- Validate the I/O parameters if(!(OnnxSetInputShape(onnx_model,0,input_shape))||!(OnnxSetOutputShape(onnx_model,0,output_shape))) { //--- We failed to define the I/O parameters Comment("[ERROR] Failed to load AI Model Correctly: ",GetLastError()); return(false); } //--- Everything was okay return(true); }
さらに、このシステムには、いつポジションをクローズするかについてのルールが必要です。現在のポジションの浮動利益が利益目標を上回る場合、ポジションをクローズします。それ以外の場合、システムの状態が変わった場合は、それに応じてポジションをクローズします。
//+------------------------------------------------------------------+ //| Manage our open positions | //+------------------------------------------------------------------+ void manage_positions(void) { if(PositionSelectByTicket(PositionGetTicket(0))) { if(PositionGetDouble(POSITION_PROFIT) > profit_target) { Trade.PositionClose(Symbol()); } } if(system_state == 1) { if(macd_m[0] < macd_s[0]) { if(model_forecast[0] < iClose(Symbol(),PERIOD_M1,0)) { Trade.PositionClose(Symbol()); } } } if(system_state == -1) { if(macd_m[0] > macd_s[0]) { if(model_forecast[0] > iClose(Symbol(),PERIOD_M1,0)) { Trade.PositionClose(Symbol()); } } } }
次の関数はポジションを開く役割を担います。以下の場合にのみ買いポジションを開きます。
- MACDメインラインがシグナルの上にある
- AI予測が現在の終値よりも高い
- ドル指数とUSDZARペアはともに日足チャートで強気の価格変動を示している
//+------------------------------------------------------------------+ //| Find an entry | //+------------------------------------------------------------------+ void find_entry(void) { if(macd_m[0] > macd_s[0]) { if(model_forecast[0] > iClose(Symbol(),PERIOD_M1,0)) { if((usd_f[0] > usd_s[0]) && (usd_zar_f[0] > usd_zar_s[0])) { Trade.Buy(vol,Symbol(),ask,0,0,"Slope AI"); system_state = 1; } } } if(macd_m[0] < macd_s[0]) { if(model_forecast[0] < iClose(Symbol(),PERIOD_M1,0)) { if((usd_f[0] < usd_s[0]) && (usd_zar_f[0] < usd_zar_s[0])) { Trade.Sell(vol,Symbol(),bid,0,0,"Slope AI"); system_state = -1; } } } }

図12:AIシステムの動作
結論
これまでのところ、プライスアクションによって形成された傾斜を取引戦略に活用したいトレーダーにとって、依然としていくつかの障害が存在することが示されました。しかし、この方向に向けた努力は、投資した時間に見合う価値があると考えられます。価格レベル間の関係を傾斜を使って明確にした結果、KNeighborsモデルのパフォーマンスが20%向上しました。このことは、この方向でさらに調査を続けた場合、どれだけパフォーマンスが向上するのかという疑問を抱かせます。さらに、この結果は、各モデルがパフォーマンスを向上させるための独自の変換セットを持っている可能性が高いことを示唆しています。私たちの仕事は、このマッピングを実現することにあります。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/16124
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索