
Desarrollo de asesores expertos autooptimizables en MQL5 (Parte 4): Dimensionamiento dinámico de posiciones

Las computadoras electrónicas y digitales existen desde la década de 1950, pero los mercados financieros han existido durante siglos. Los operadores humanos han tenido éxito históricamente sin herramientas computacionales avanzadas, lo que supone un reto a la hora de diseñar software de trading moderno. ¿Deberíamos aprovechar toda la potencia computacional o alinearnos con los principios exitosos del comercio humano? Este artículo aboga por encontrar el equilibrio entre la simplicidad y la tecnología moderna. A pesar de las avanzadas herramientas actuales, muchos operadores han tenido éxito en complejos sistemas descentralizados sin necesidad de utilizar potentes programas informáticos como MQL5 API.
La mayoría de los procesos de toma de decisiones cotidianos que utilizamos los seres humanos pueden resultar difíciles de transmitir de forma significativa a un ordenador. Por ejemplo, al operar, es común escuchar a alguien comentar «Estaba muy seguro de mi decisión, así que aumenté el tamaño del lote». ¿Cómo podemos indicar a nuestras aplicaciones de trading que hagan lo mismo y aumenten el tamaño de la posición si se sienten «seguras» con respecto a la operación?
Espero que el lector comprenda de inmediato que no es posible alcanzar este objetivo sin introducir complejidad en el sistema para medir el «grado de confianza» que «siente» el ordenador. Un enfoque consiste en crear modelos probabilísticos para cuantificar la «confianza» de una operación. En este artículo, crearemos un modelo de regresión logística sencillo para medir la confianza de nuestras operaciones, lo que permitirá a nuestra aplicación escalar nuestras posiciones de forma independiente.
Nos centraremos en la estrategia de las Bandas de Bollinger, tal y como la propuso originalmente John Bollinger. Nuestro objetivo es perfeccionar esta estrategia, corrigiendo sus deficiencias sin perder la esencia de la idea.
Nuestra aplicación comercial tendrá como objetivo:
- Realice una operación adicional con un tamaño de lote mayor si el modelo confía en la operación.
- Realice una sola operación con un tamaño de lote más pequeño si el modelo es menos fiable.
La estrategia de trading original propuesta por John Bollinger realizó 493 operaciones en nuestra prueba retrospectiva de la estrategia. De todas las operaciones realizadas, el 62 % fueron rentables. Aunque se trata de una proporción saludable de operaciones ganadoras, no fue suficiente para generar una estrategia de trading rentable. Perdimos 813 dólares durante nuestro periodo de backtesting y obtuvimos un ratio de Sharpe de -0,33. Nuestra versión perfeccionada del algoritmo realizó un total de 495 operaciones, de las cuales el 63 % fueron rentables. Nuestra ganancia total al final de la prueba retrospectiva aumentó drásticamente a 2427 dólares durante el mismo período de tiempo y nuestro índice de Sharpe se situó en 0,74.
El objetivo de este artículo no es socavar el poder de las herramientas computacionales avanzadas, como las redes neuronales profundas (DNN) o los algoritmos de aprendizaje por refuerzo. Por el contrario, estoy profundamente entusiasmado con las posibilidades que estas tecnologías ofrecen. Sin embargo, es importante reconocer que la complejidad por sí misma no necesariamente conduce a mejores resultados.
Comprendo los desafíos que conlleva ser un nuevo miembro de una comunidad de trading algorítmico. Yo también he pasado por eso, lleno de ambición pero sin saber por dónde empezar. Es fácil sentirse abrumado por la gran cantidad de herramientas, técnicas y opciones que están al alcance de la mano.
Este artículo pretende servir de guía para quienes están empezando. Al empezar por lo sencillo, se puede adquirir la confianza necesaria para abordar problemas más complejos por cuenta propia, con una comprensión más profunda de su aplicación. Los resultados publicados en este artículo se obtuvieron conservando las reglas de negociación originales y sencillas sugeridas por John Bollinger y complementándolas con complejidad para emular el proceso de toma de decisiones humano, en lugar de introducir complejidad por el simple hecho de hacerlo.
Resumen de la estrategia comercial

Figura 1: Imagen de nuestra estrategia de Bandas de Bollinger en acción.
Nuestra estrategia de trading se basa en seguir las señales de trading propuestas por John Bollinger. Las reglas originales de la estrategia se cumplen si vendemos siempre que los niveles de precio superen la banda superior de Bollinger, y compraremos si los niveles de precio caen por debajo de la banda inferior.
En términos generales, podemos extender estas reglas para que también sirvan como condiciones de salida. Es decir, que siempre que los niveles de precios aparezcan por encima de la banda superior, cerraremos cualquier operación de compra que pueda estar abierta, además de abrir nuestras operaciones de venta. Estos conjuntos de reglas son suficientes para crear un sistema autogestionado que sabe cuándo abrir y cerrar sus posiciones por sí mismo.
Probaremos nuestra estrategia de trading en el par GBPUSD desde el 1 de enero de 2022 hasta el 30 de diciembre de 2024 en el marco temporal M15.
Introducción a MQL5
Para comenzar a trabajar con MQL5, primero definimos las constantes del sistema, como el par que se va a negociar, el tamaño del lote que se va a utilizar y otras constantes que no queremos que el usuario cambie.
//+------------------------------------------------------------------+ //| GBPUSD BB Breakout Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define BB_SHIFT 0 // Our bollinger band should not be shifted #define SYMBOL "GBPUSD" // The intended pair for our trading system #define BB_PRICE PRICE_CLOSE // The price our bollinger band should work on #define LOT 0.1 // Our intended lot size
Desde ahí, carguemos la biblioteca de operaciones.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
Algunos aspectos de la estrategia de negociación pueden ser controlados por el usuario final, como el marco temporal que debemos utilizar para los cálculos de nuestros indicadores técnicos y el período del indicador de Bandas de Bollinger.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input group "Technical Indicators" input ENUM_TIMEFRAMES TF = PERIOD_M15; // Intended time frame input int BB_PERIOD = 30; // The period for our bollinger bands input double BB_SD = 2.0; // The standard deviation for our bollinger bands
También necesitaremos definir las variables globales que se utilizarán a lo largo de nuestro programa.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int bb_handler; double bb_u[],bb_m[],bb_l[]; //+------------------------------------------------------------------+ //| System variables | //+------------------------------------------------------------------+ int state; double o,h,l,c,bid,ask;
Cuando nuestra aplicación de negociación se cargue por primera vez, llamaremos a nuestra función de inicialización.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our system if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); }
Si nuestra aplicación deja de estar en uso, publicaremos los indicadores técnicos que ya no utilizamos.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release resources we no longer need release(); }
Al recibir información actualizada sobre los precios, necesitamos almacenar los nuevos datos y procesarlos para tomar una decisión comercial.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Update our system variables update(); } //+------------------------------------------------------------------+
Esta función se encarga de configurar nuestro indicador técnico.
//+------------------------------------------------------------------+ //| Custom functions | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Setup our technical indicators and other variables | //+------------------------------------------------------------------+ bool setup(void) { //--- Setup our system bb_handler = iBands(SYMBOL,TF,BB_PERIOD,BB_SHIFT,BB_SD,BB_PRICE); state = 0; //--- Validate our system has been setup correctly if((bb_handler != INVALID_HANDLE) && (Symbol() == SYMBOL)) return(true); //--- Something went wrong! return(false); }
Si ya no utilizamos nuestra aplicación de trading, liberaremos la memoria que estaba asociada al indicador técnico que seleccionamos.
//+------------------------------------------------------------------+ //| Release the resources we no longer need | //+------------------------------------------------------------------+ void release(void) { //--- Free up system resources for our end user IndicatorRelease(bb_handler); }
Cuando recibamos información actualizada sobre los precios del mercado, actualizaremos nuestras variables globales y luego comprobaremos si existen configuraciones de negociación válidas si no tenemos posiciones abiertas.
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update(void) { static datetime timestamp; datetime current_time = iTime(Symbol(),PERIOD_CURRENT,0); if(timestamp != current_time) { timestamp = current_time; //--- Update our system CopyBuffer(bb_handler,0,1,1,bb_m); CopyBuffer(bb_handler,1,1,1,bb_u); CopyBuffer(bb_handler,2,1,1,bb_l); Comment("U: ",bb_u[0],"\nM: ",bb_m[0],"\nL: ",bb_l[0]); //--- Market prices o = iOpen(SYMBOL,PERIOD_CURRENT,1); c = iClose(SYMBOL,PERIOD_CURRENT,1); h = iHigh(SYMBOL,PERIOD_CURRENT,1); l = iLow(SYMBOL,PERIOD_CURRENT,1); bid = SymbolInfoDouble(SYMBOL,SYMBOL_BID); ask = SymbolInfoDouble(SYMBOL,SYMBOL_ASK); //--- Should we reset our system state? if(PositionsTotal() == 0) { state = 0; find_setup(); } if(PositionsTotal() == 1) { manage_setup(); } } }
Nuestras reglas para encontrar puntos de entrada son las reglas originales propuestas por John Bollinger.
//+------------------------------------------------------------------+ //| Find an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { //--- Check if we have breached the bollinger bands if(c > bb_u[0]) { Trade.Sell(LOT,SYMBOL,bid); state = -1; return; } if(c < bb_l[0]) { Trade.Buy(LOT,SYMBOL,ask); state = 1; } }
Como ya hemos indicado anteriormente, las reglas proporcionadas por John Bollinger también pueden utilizarse para crear reglas de salida que definan perfectamente cuándo cerrar una posición.
//+------------------------------------------------------------------+ //| Manage our open trades | //+------------------------------------------------------------------+ void manage_setup(void) { if(((c < bb_l[0]) && (state == -1))||((c > bb_u[0]) && (state == 1))) Trade.PositionClose(SYMBOL); } //+------------------------------------------------------------------+
Comenzaremos seleccionando primero el período de tiempo previsto para el M15. Estos marcos temporales de bajo nivel son ideales para estrategias de scalping como la nuestra, que buscan aprovechar los patrones que se forman diariamente en los mercados financieros. Nuestro símbolo elegido es el par GBPUSD, y realizaremos nuestra prueba desde el 1 de enero de 2022 hasta el 30 de diciembre de 2024.

Figura 2: Selección del período de tiempo para nuestra prueba retrospectiva.
Ahora ajustaremos los parámetros de nuestra prueba. Al seleccionar «Retraso aleatorio» se comprueba la fiabilidad de nuestro sistema de negociación cuando las condiciones del mercado son inestables. Además, he seleccionado «Cada tick a base de ticks reales» porque esto nos proporciona la simulación más realista de los datos históricos del mercado. En este modo de modelado, nuestra terminal MetaTrader 5 obtendrá todos los ticks en tiempo real que fueron enviados por el bróker ese día. Este proceso puede llevar mucho tiempo, dependiendo de la velocidad de tu conexión a Internet. Sin embargo, al final, es probable que arroje resultados cercanos a la verdad.
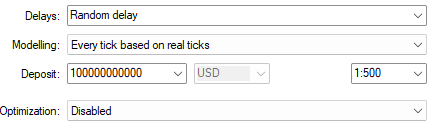
Figura 3: Selección de las condiciones de la prueba retrospectiva para nuestra prueba.
Por último, definiremos los ajustes que controlarán el comportamiento de nuestra aplicación. Tenga en cuenta que, en nuestra segunda prueba, la configuración que hemos seleccionado en la figura 4 se mantendrá constante utilizando nuestras variables del sistema. Por lo tanto, no otorgaremos a la segunda versión de nuestra aplicación una ventaja injusta sobre esta versión actual que estamos a punto de probar.
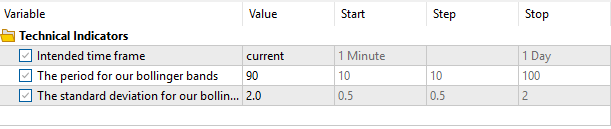
Figura 4: Parámetros de entrada para nuestro asesor experto durante esta única prueba retrospectiva.
La curva de beneficios que genera nuestro algoritmo actual es inherentemente inestable. Sufre de forma impredecible periodos de rápido crecimiento y pérdidas excesivas. La versión actual de nuestra estrategia de trading dedica la mayor parte del tiempo a recuperarse de periodos de pérdidas, en lugar de acumular beneficios y asumir pérdidas ocasionales. Esto dista mucho de ser lo ideal. Al final de nuestra prueba, nuestro algoritmo solo logró hacernos perder el capital. Es evidente que queda mucho trabajo por hacer antes de que podamos siquiera considerar el uso de este algoritmo.

Figura 5: La curva de capital producida por nuestra versión actual de la estrategia de negociación original.
Al examinar detenidamente los resultados de nuestra prueba retrospectiva, observamos que nuestro sistema tuvo una proporción saludable de operaciones ganadoras; el 63% de todas las operaciones realizadas fueron rentables. El problema es que nuestros beneficios fueron casi la mitad de nuestras pérdidas. Dado que no deseamos cambiar las reglas de negociación originales, nuestro nuevo objetivo es dirigir el crecimiento de nuestro beneficio promedio hacia un nivel más cercano a su máximo, al tiempo que nos aseguramos de que nuestras operaciones perdedoras crezcan a un ritmo menor. Este delicado equilibrio nos dará los resultados que deseamos.

Figura 6: Análisis detallado de los resultados obtenidos con la versión original de la estrategia de negociación.
Mejorando nuestros resultados iniciales
Como podemos ver, los resultados iniciales no son muy alentadores. Sin embargo, sabemos que el operador humano que inventó las Bandas de Bollinger y propuso estas reglas de negociación fue, sin duda alguna, un operador exitoso. ¿Dónde reside, entonces, la discrepancia entre las reglas creadas por John Bollinger y los resultados que hemos obtenido al seguirlas algorítmicamente?

Figura 7: El inventor de las Bandas de Bollinger, John Bollinger.
Parte de la diferencia puede radicar en la aplicación humana de estas reglas. Es probable que, con el tiempo, Bollinger desarrollara una intuición sobre las condiciones del mercado en las que su estrategia prospera y las condiciones en las que tiende a fracasar. Nuestra aplicación actual arriesga constantemente la misma cantidad en cada operación y trata todas las oportunidades de negociación por igual. Sin embargo, los seres humanos pueden usar su criterio para arriesgar más o menos, dependiendo de sus expectativas aprendidas y sus niveles de confianza sobre el futuro.
Los operadores humanos buscan asumir riesgos cuando creen que es más probable que resulten rentables; no siguen rígidamente un conjunto de reglas preestablecidas. Queremos dotar a nuestro ordenador de un nivel adicional de flexibilidad, además de la estrategia original. Lograr este objetivo podrá, con suerte, explicar la diferencia entre los resultados que esperábamos y los que hemos obtenido hasta ahora. Por lo tanto, introduciremos complejidad para intentar acercar nuestra máquina a lo que hacen los profesionales a diario, en lugar de limitarnos a intentar pronosticar directamente los niveles de precios futuros.
Podemos construir un modelo de regresión logística para dotar a nuestra aplicación de una mayor "confianza". Los parámetros de nuestro modelo se optimizarán utilizando datos históricos del mercado que obtendremos de nuestro terminal MetaTrader 5. Nuestra implementación nativa de MQL5 significa que nuestro Asesor Experto puede trabajar en cualquier período de tiempo, siempre que haya suficientes datos sobre ese período.
Un modelo de regresión logística es posiblemente el modelo más simple que podemos construir hoy en día. Existen muchas formas de modelos logísticos, sin embargo, la forma que cubriremos hoy solo se puede utilizar para modelar 2 clases. Los lectores que deseen clasificar más de dos clases deberían considerar consultar más bibliografía sobre modelos logísticos.
Para implementar los cambios deseados y acercar el proceso de toma de decisiones de nuestra aplicación al proceso de toma de decisiones humano, implementaremos algunos cambios importantes en nuestra versión actual del sistema de negociación:
| Cambio propuesto | Propósito previsto |
|---|---|
| Constantes adicionales del sistema | Necesitaremos crear nuevas constantes del sistema para dar cabida al modelo probabilístico que queremos construir, y a todas las demás partes nuevas del sistema que necesitamos. |
| Análisis técnico complementario | Utilizar dos estrategias a la vez puede desbloquear mayores niveles de rentabilidad para nuestro sistema. También buscaremos confirmación del oscilador estocástico antes de abrir nuestras operaciones para aumentar las probabilidades de obtener operaciones rentables. |
| Nuevas entradas de usuario | Para permitir que nuestro usuario controle las nuevas partes de nuestro sistema, necesitamos crear nuevas entradas de usuario que controlen la nueva funcionalidad que estamos implementando. |
| Modificación de funciones personalizadas | Las funciones personalizadas que hemos desarrollado hasta ahora necesitan ser revisadas y ampliadas para adaptarse a todas las nuevas variables y tareas que nuestra aplicación debe realizar. |
Primeros pasos
Para comenzar a construir nuestra versión revisada de la aplicación de negociación, primero necesitaremos crear nuevas constantes del sistema para mantener la coherencia de nuestras pruebas en todas las versiones propuestas del algoritmo.
//+------------------------------------------------------------------+ //| GBPUSD BB Breakout Benchmark.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define BB_SHIFT 0 // Our bollinger band should not be shifted #define SYMBOL "GBPUSD" // The intended pair for our trading system #define BB_PRICE PRICE_CLOSE // The price our bollinger band should work on #define BB_PERIOD 90 // The period for our bollinger bands #define BB_SD 2.0 // The standard deviation for our bollinger bands #define LOT 0.1 // Our intended lot size #define TF PERIOD_M15 // Our intended time frame #define ATR_MULTIPLE 20 // ATR Multiple #define ATR_PERIOD 14 // ATR Period #define K_PERIOD 12 // Stochastic K period #define D_PERIOD 20 // Stochastic D period #define STO_SMOOTHING 12 // Stochastic smoothing #define LOGISTIC_MODEL_PARAMS 5 // Total inputs to our logistic model
Además, queremos que nuestro usuario controle la funcionalidad de nuestro modelo de regresión logística. El parámetro "fetch" determina la cantidad de datos que se deben usar para construir nuestro modelo. Tenga en cuenta que, en términos generales, cuanto mayor sea el período de tiempo que el usuario desee utilizar, menos datos tendremos. Por otro lado, "look_ahead" determina hasta qué punto en el futuro nuestro modelo debería intentar pronosticar.
//+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int fetch = 5; // How many historical bars of data should we fetch? input int look_ahead = 10; // How far ahead into the future should we forecast?
Además, necesitaremos nuevas variables globales en nuestra aplicación. Estas variables servirán como controladores para nuestros nuevos indicadores técnicos, así como para las partes móviles de nuestro modelo de regresión logística.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int bb_handler,atr_handler,stoch_handler; double bb_u[],bb_m[],bb_l[],atr[],stoch[]; double logistic_prediction; double learning_rate = 5E-3; vector open_price = vector::Zeros(fetch); vector open_price_old = vector::Zeros(fetch); vector close_price = vector::Zeros(fetch); vector close_price_old = vector::Zeros(fetch); vector high_price = vector::Zeros(fetch); vector high_price_old = vector::Zeros(fetch); vector low_price = vector::Zeros(fetch); vector low_price_old = vector::Zeros(fetch); vector target = vector::Zeros(fetch); vector coef = vector::Zeros(LOGISTIC_MODEL_PARAMS); double max_forecast = 0; double min_forecast = 0; double baseline_forecast = 0;
La mayoría de las demás partes de nuestro sistema de negociación permanecerán igual, a excepción de algunas funciones que necesitan ser ampliadas y nuevas funciones que necesitamos definir. Lo primero en la lista que debemos editar es nuestra función de inicialización. Tenemos que realizar algunos pasos adicionales antes de estar listos para comenzar a operar. Necesitaremos configurar el ATR y el modelo estocástico, y además, debemos definir la función "setup_logistic_model()".
//+------------------------------------------------------------------+ //| Setup our technical indicators and other variables | //+------------------------------------------------------------------+ bool setup(void) { //--- Setup our system bb_handler = iBands(SYMBOL,TF,BB_PERIOD,BB_SHIFT,BB_SD,BB_PRICE); atr_handler = iATR(SYMBOL,TF,ATR_PERIOD); stoch_handler = iStochastic(SYMBOL,TF,K_PERIOD,D_PERIOD,STO_SMOOTHING,MODE_EMA,STO_LOWHIGH); state = 0; higher_state = 0; setup_logistic_model(); //--- Validate our system has been setup correctly if((bb_handler != INVALID_HANDLE) && (Symbol() == SYMBOL)) return(true); //--- Something went wrong! return(false); }
Nuestro modelo de regresión logística toma un conjunto de entradas y predice una probabilidad entre cero y uno de que la variable objetivo pertenezca a la clase predeterminada, dado el valor actual de x. El modelo utiliza una función sigmoide, representada en la figura 8 a continuación, para calcular estas probabilidades.
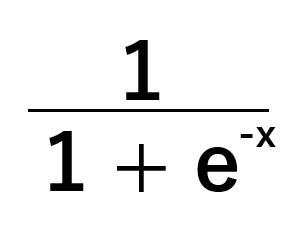
Imaginemos que nos interesa resolver el siguiente problema: "Dado el peso y la altura de una persona, ¿cuál es la probabilidad de que sea hombre?". En esta pregunta de ejemplo, ser masculino es la clase predeterminada. Las probabilidades superiores a 0,5 implican que se cree que la persona es hombre, y las probabilidades inferiores a 0,5 implican que se supone que el género es femenino. Esta es la versión más simple posible del modelo logístico. Existen versiones del modelo logístico que pueden clasificar más de dos objetivos, pero no las consideraremos hoy.
La función sigmoide generalizada en la figura 8 anterior transformará cualquier valor de x y nos dará un valor de salida entre 0 y 1, tal y como se muestra en la figura 9 siguiente.
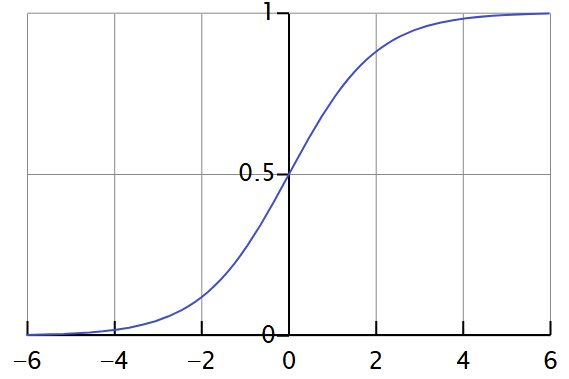
Figura 9: Visualización de la transformación de una función sigmoide.
Podemos calibrar cuidadosamente nuestra función sigmoide para que produzca estimaciones cercanas a 1 para todas las observaciones en nuestros datos de entrenamiento que pertenecen a la clase 1 y, del mismo modo, estimaciones cercanas a 0 para todos los valores en nuestros datos de entrenamiento que pertenecen a la clase 0. Este algoritmo se conoce como estimación de máxima verosimilitud. Podemos aproximar estos resultados utilizando un algoritmo mucho más simple conocido como descenso de gradiente.
En el código que se proporciona a continuación, comenzamos preparando nuestros datos de entrada. Analizamos la variación en los precios de apertura, máximo, mínimo y cierre; estos serán nuestros datos de entrada para el modelo. Posteriormente, registramos el cambio futuro de precio asociado. Si los niveles de precios caen, lo registraremos como clase 0. La clase 0 es nuestra clase predeterminada. Las predicciones por encima de nuestro punto de corte implican que nuestro modelo prevé una caída de los niveles de precios futuros. Asimismo, las predicciones por debajo del punto de corte implican que la clase predeterminada no es cierta, o en nuestro caso, nuestro modelo espera que los niveles de precios aumenten. Normalmente, se prefiere un punto de corte de 0,5.
Después de etiquetar nuestros datos, inicializamos todos los coeficientes de nuestro modelo a 0 y luego procedemos a realizar la primera predicción con estos coeficientes deficientes. Con cada predicción, corregimos los coeficientes utilizando la diferencia entre nuestra predicción y la etiqueta verdadera. Este proceso se repite para cada barra que recuperamos.
Por último, como indiqué anteriormente, clásicamente se prefiere un punto de corte de 0,5. Sin embargo, los mercados financieros no se caracterizan precisamente por ser entornos de buen comportamiento. El enfoque clásico no nos proporcionó probabilidades útiles como operadores, así que amplié el algoritmo clásico y lo calibré aún más.
Incluí un paso adicional para calcular un punto de corte óptimo, registrando primero las probabilidades máxima y mínima pronosticadas por nuestro modelo. Luego, dividimos por la mitad el rango real de predicciones proporcionado por nuestro modelo para encontrar nuestro punto de corte. Dado que el mercado financiero puede ser volátil, puede resultar difícil para nuestros modelos aprender de forma eficaz, y es posible que necesitemos ser creativos y encontrar nuevas formas de interpretar nuestros modelos. Este punto de corte dinámico ayudará a nuestro modelo a tomar decisiones independientemente de nuestro sesgo inherente.

Figura 10: Visualización de cómo establecemos dinámicamente nuestro punto de corte.
En nuestro caso, las probabilidades superiores a nuestro punto de corte dinámico se interpretarán como la clase predeterminada, lo que significa que nuestro modelo cree que deberíamos "vender". Y lo contrario es cierto para las predicciones que se encuentran por debajo de nuestro punto de corte dinámico.
//+------------------------------------------------------------------+ //| Setup our logistic regression model | //+------------------------------------------------------------------+ void setup_logistic_model(void) { open_price.CopyRates(SYMBOL,TF,COPY_RATES_OPEN,(fetch + look_ahead),fetch); open_price_old.CopyRates(SYMBOL,TF,COPY_RATES_OPEN,(fetch + (look_ahead * 2)),fetch); high_price.CopyRates(SYMBOL,TF,COPY_RATES_HIGH,(fetch + look_ahead),fetch); high_price_old.CopyRates(SYMBOL,TF,COPY_RATES_HIGH,(fetch + (look_ahead * 2)),fetch); low_price.CopyRates(SYMBOL,TF,COPY_RATES_LOW,(fetch + look_ahead),fetch); low_price_old.CopyRates(SYMBOL,TF,COPY_RATES_LOW,(fetch + (look_ahead * 2)),fetch); close_price.CopyRates(SYMBOL,TF,COPY_RATES_CLOSE,(fetch + look_ahead),fetch); close_price_old.CopyRates(SYMBOL,TF,COPY_RATES_CLOSE,(fetch + (look_ahead * 2)),fetch); open_price = open_price - open_price_old; high_price = high_price - high_price_old; low_price = low_price - low_price_old; close_price = close_price - close_price_old; CopyBuffer(atr_handler,0,0,fetch,atr); for(int i = (fetch + look_ahead); i > look_ahead; i--) { if(iClose(SYMBOL,TF,i) > iClose(SYMBOL,TF,i - look_ahead)) target[i-look_ahead-1] = 0; if(iClose(SYMBOL,TF,i) < iClose(SYMBOL,TF,i - look_ahead)) target[i-look_ahead-1] = 1; } //Fitting our coefficients coef[0] = 0; coef[1] = 0; coef[2] = 0; coef[3] = 0; coef[4] = 0; for(int i =0; i < fetch; i++) { double prediction = 1 / (1 + MathExp(-(coef[0] + (coef[1] * open_price[i]) + (coef[2] * high_price[i]) + (coef[3] * low_price[i]) + (coef[4] * close_price[i])))); coef[0] = coef[0] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * 1.0; coef[1] = coef[1] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * open_price[i]; coef[2] = coef[2] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * high_price[i]; coef[3] = coef[3] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * low_price[i]; coef[4] = coef[4] + (learning_rate * (target[i] - prediction)) * prediction * (1 - prediction) * close_price[i]; } for(int i =0; i < fetch; i++) { double prediction = 1 / (1 + MathExp(-(coef[0] + (coef[1] * open_price[i]) + (coef[2] * high_price[i]) + (coef[3] * low_price[i]) + (coef[4] * close_price[i])))); if(i == 0) { max_forecast = prediction; min_forecast = prediction; } max_forecast = (prediction > max_forecast) ? (prediction) : max_forecast; min_forecast = (prediction < min_forecast) ? (prediction) : min_forecast; } baseline_forecast = ((max_forecast + min_forecast) / 2); Print(coef); Print("Baseline: ",baseline_forecast); }
Si no utilizamos nuestro Asesor Experto, hay algunos indicadores técnicos adicionales que debemos publicar.
//+------------------------------------------------------------------+ //| Release the resources we no longer need | //+------------------------------------------------------------------+ void release(void) { //--- Free up system resources for our end user IndicatorRelease(bb_handler); IndicatorRelease(atr_handler); IndicatorRelease(stoch_handler); }
Nuestras condiciones para establecer posiciones siguen siendo prácticamente las mismas, excepto que si las predicciones de nuestro modelo coinciden con las reglas de negociación propuestas por John Bollinger, redoblaremos la apuesta por esa oportunidad e instruiremos a nuestra aplicación para que asuma más riesgos solo bajo esas condiciones.
//+------------------------------------------------------------------+ //| Find an oppurtunity to trade | //+------------------------------------------------------------------+ void find_setup(void) { double open_input = iOpen(SYMBOL,TF,0) - iOpen(SYMBOL,TF,look_ahead); double close_input = iClose(SYMBOL,TF,0) - iClose(SYMBOL,TF,look_ahead); double high_input = iHigh(SYMBOL,TF,0) - iHigh(SYMBOL,TF,look_ahead); double low_input = iLow(SYMBOL,TF,0) - iLow(SYMBOL,TF,look_ahead); double prediction = 1 / (1 + MathExp(-(coef[0] + (coef[1] * open_input) + (coef[2] * high_input) + (coef[3] * low_input) + (coef[4] * close_input)))); Print("Odds: ",prediction - baseline_forecast); //--- Check if we have breached the bollinger bands if((c > bb_u[0]) && (stoch[0] < 50)) { Trade.Sell(LOT,SYMBOL,bid); state = -1; if(((prediction - baseline_forecast) > 0)) { Trade.Sell((LOT * 2),SYMBOL,bid); Trade.Sell((LOT * 2),SYMBOL,bid); state = -1; } return; } if((c < bb_l[0]) && (stoch[0] > 50)) { Trade.Buy(LOT,SYMBOL,ask); state = 1; if(((prediction - baseline_forecast) < 0)) { Trade.Buy((LOT * 2),SYMBOL,ask); Trade.Buy((LOT * 2),SYMBOL,ask); state = 1; } return; } }
Además, queremos tener un stop loss que se ajuste si nuestra operación está ganando, y que se mantenga en su lugar en caso contrario. Esto garantizará que reduzcamos nuestro riesgo si estamos ganando, lo cual es algo inteligente que los operadores humanos hacen todo el tiempo.
//+------------------------------------------------------------------+ //| Manage our open positions | //+------------------------------------------------------------------+ void manage_setup(void) { if(((c < bb_l[0]) && (state == -1))||((c > bb_u[0]) && (state == 1))) Trade.PositionClose(SYMBOL); //--- Update the stop loss for(int i = PositionsTotal() -1; i >= 0; i--) { string symbol = PositionGetSymbol(i); if(_Symbol == symbol) { double position_size = PositionGetDouble(POSITION_VOLUME); double risk_factor = 1; if(position_size == (LOT * 2)) risk_factor = 2; double atr_stop = atr[0] * ATR_MULTIPLE * risk_factor; ulong ticket = PositionGetInteger(POSITION_TICKET); double position_price = PositionGetDouble(POSITION_PRICE_OPEN); long type = PositionGetInteger(POSITION_TYPE); double current_take_profit = PositionGetDouble(POSITION_TP); double current_stop_loss = PositionGetDouble(POSITION_SL); if(type == POSITION_TYPE_BUY) { double atr_stop_loss = (bid - (atr_stop)); double atr_take_profit = (bid + (atr_stop)); if((current_stop_loss < atr_stop_loss) || (current_stop_loss == 0)) { Trade.PositionModify(ticket,atr_stop_loss,current_take_profit); } } else+ if(type == POSITION_TYPE_SELL) { double atr_stop_loss = (ask + (atr_stop)); double atr_take_profit = (ask - (atr_stop)); if((current_stop_loss > atr_stop_loss) || (current_stop_loss == 0)) { Trade.PositionModify(ticket,atr_stop_loss,current_take_profit); } } } } } //+------------------------------------------------------------------+
Los ajustes que controlan la duración y el marco temporal de la prueba retrospectiva se mantendrán iguales, la única variable que debemos cambiar aquí es el experto seleccionado. Hemos seleccionado la versión revisada de la aplicación que acabamos de refactorizar juntos en la sección anterior de este artículo. Asegúrate de mantener la misma configuración al seleccionar la nueva versión de la aplicación.
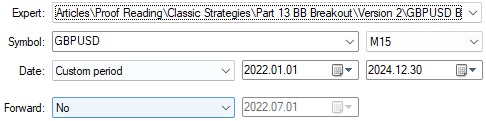
Figura 11: Selección del marco temporal y el período para nuestra segunda prueba retrospectiva con el fin de evaluar la eficacia de la configuración elegida.
Como siempre, asegúrese de seleccionar una configuración de apalancamiento que se ajuste a su acuerdo con su corredor. Si especifica incorrectamente la configuración de apalancamiento, podría generar expectativas poco realistas sobre la rentabilidad de sus operaciones. Para empeorar las cosas, puede que le resulte difícil reproducir los resultados que obtiene en su prueba retrospectiva, especialmente si la configuración de apalancamiento en su cuenta real no coincide con la configuración de apalancamiento que está utilizando en su prueba retrospectiva. Esta es una fuente de error que se suele pasar por alto al realizar pruebas retrospectivas, así que tómese su tiempo.
Figura 12: Las pruebas retrospectivas son sensibles a la configuración seleccionada al iniciar la prueba retrospectiva. Asegúrate de hacerlo bien a la primera.
Ahora definiremos cuántos datos debe obtener nuestra aplicación de negociación para estimar los parámetros de nuestro modelo de regresión logística y el horizonte de pronóstico de nuestro modelo. No intentes obtener más datos de los que te proporciona tu corredor. De lo contrario, ¡la aplicación no funcionará como se espera! Asimismo, establezca un horizonte de previsión que se ajuste a su tolerancia al riesgo.
Por ejemplo, es posible que desee entrenar su aplicación para que anticipe los datos 2000 pasos en el futuro. Sin embargo, debe tener en cuenta que 2000 pasos hacia el futuro en el marco temporal M15 corresponden a unos 20 días. Si usted, como ser humano, no suele prever con tanta antelación al realizar sus operaciones, no intente forzar a la aplicación a hacerlo. Recuerda que nuestro objetivo es crear una aplicación que emule lo que haces a diario como operador bursátil.

Figura 13: Parámetros que controlan el comportamiento de nuestra aplicación de negociación y nuestro modelo de regresión logística.
Hemos llegado ahora a la parte más informativa de nuestra prueba. Nuestro nuevo sistema generó un beneficio medio de 79 dólares. Inicialmente, esperábamos una ganancia promedio de 45 dólares. Por lo tanto, la diferencia entre nuestra ganancia esperada actual (79 dólares) y nuestra ganancia esperada anterior (45 dólares) es de 34 dólares. Esta diferencia de 34 dólares corresponde a un crecimiento de aproximadamente el 75 % del beneficio original previsto.
Al mismo tiempo, nuestra nueva pérdida esperada es de -122 dólares, mientras que nuestra pérdida esperada inicial era de -81 dólares. Esto supone una diferencia de 41 dólares, lo que corresponde a un aumento aproximado del 50 % en el tamaño de nuestra pérdida media. ¡Así que hemos logrado nuestro objetivo!
Nuestros nuevos ajustes garantizan que nuestras ganancias crezcan a un ritmo mayor que nuestras pérdidas. Esta es también la razón por la que hemos rectificado con éxito nuestro ratio de Sharpe y la rentabilidad esperada. Nuestra versión inicial de la estrategia de negociación acumuló una pérdida de -791 dólares, mientras que nuestro nuevo sistema acumuló una ganancia de 2274 dólares sin cambiar las reglas del algoritmo ni el período de la prueba retrospectiva.
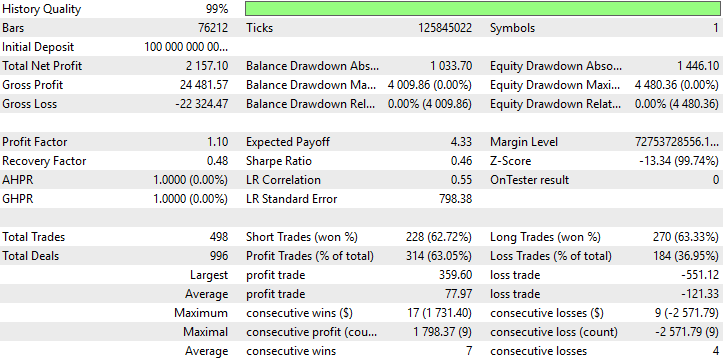
Figura 14: Lo ideal sería que nuestras pérdidas tuvieran una tasa de crecimiento del 0 %, pero el mundo real no es ideal.
Cuando observamos ahora la curva de capital que produce nuestro algoritmo, podemos ver claramente que nuestro algoritmo es más estable que inicialmente. Todas las estrategias de trading atraviesan períodos de pérdidas. Sin embargo, nos interesa la capacidad de la estrategia para recuperarse de las pérdidas y preservar sus beneficios a largo plazo. Una estrategia demasiado adversa al riesgo difícilmente generará beneficios y, por el contrario, una estrategia con una fuerte afinidad por el riesgo puede perder rápidamente todas las ganancias obtenidas. Por lo tanto, hemos logrado encontrar un equilibrio, un punto intermedio.
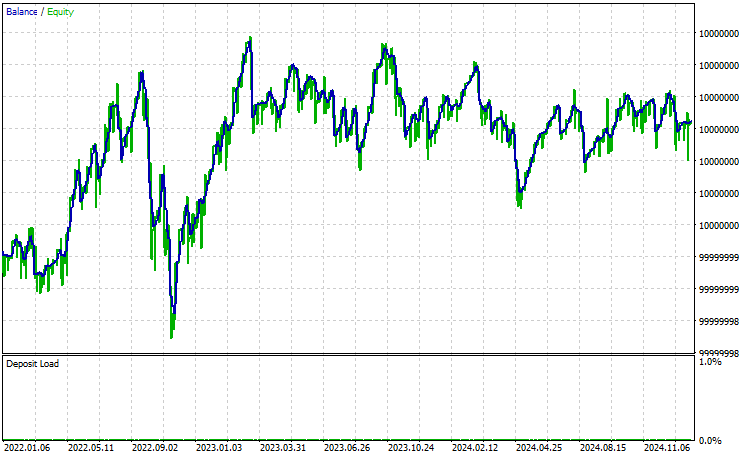
Figura 15: La curva de capital producida por nuestra nueva versión del algoritmo de negociación es más favorable que nuestros resultados iniciales.
Conclusión
Controlar el nivel de riesgo que asumen nuestras aplicaciones de negociación es fundamental para garantizar una negociación rentable y sostenible. Este artículo ha demostrado cómo se pueden diseñar aplicaciones para aumentar de forma independiente el tamaño del lote si nuestra aplicación detecta que nuestra operación tiene muchas posibilidades de ser rentable. De lo contrario, si nuestra expectativa es que la operación puede no salir bien, nuestra aplicación arriesgará la menor cantidad posible. Este dimensionamiento dinámico de las posiciones es crucial para obtener beneficios en las operaciones, ya que garantiza que aprovechamos al máximo cada oportunidad que se nos presenta y gestionamos nuestros niveles de riesgo de forma responsable. Al crear juntos un modelo logístico probabilístico, hemos aprendido una forma posible de garantizar que nuestra aplicación seleccione el tamaño de posición óptimo, basándose en lo que ha aprendido sobre el mercado en cuestión. | Archivo adjunto | Descripción |
|---|---|
| GBPUSD BB Breakout Benchmark | Esta es la versión inicial de nuestra aplicación de trading, y no resultó rentable en nuestra primera prueba. |
| GBPUSD BB Breakout Benchmark V2 | El algoritmo perfeccionado se basa en las mismas reglas de negociación, pero está diseñado para aumentar de forma inteligente el tamaño de nuestras posiciones si detecta que tenemos una buena probabilidad de ganar. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/16925
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Dominando los registros (Parte 4): Guardar registros en archivos
Dominando los registros (Parte 4): Guardar registros en archivos
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso