
Neural Networks in Trading: An Agent with Layered Memory

Introduction
The growing volume of financial data requires traders not only to process it rapidly but also to analyze it deeply in order to make accurate and timely decision. However, the limitations of human memory, attention, and the ability to handle large amounts of information can lead to missed critical events or erroneous conclusions. This creates a need for autonomous trading agents capable of efficiently integrating heterogeneous data - quickly and with high precision. One such solution has been proposed in the paper "FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design".
The proposed FinMem framework is an innovative large language model (LLM)-based agent that introduces a unique multi-level memory system. This approach enables efficient processing of data with varying types and temporal significance. The FinMem memory module is divided into a working memory, designed for short-term data processing, and a stratified long-term memory, where information is categorized according to its relevance and importance. For instance, daily news and short-term market fluctuations are analyzed at a superficial level, while reports and studies with long-term implications are stored in deeper memory layers. This structure allows the agent to prioritize information, focusing on the most relevant data.
The profiling module in FinMem allows the agent to adapt to professional contexts and market conditions. Taking into account individual preferences and the user's risk profile, the agent tailors its strategy for maximum efficiency. The decision-making module integrates current market data with stored memories to generate well-reasoned strategies. This enables the consideration of both short-term trends and long-term patterns. Such a cognitively inspired design allows FinMem to remember and utilize key market events, thereby increasing the accuracy and adaptability of its decisions.
Results from multiple experiments presented in the original research demonstrate that FinMem outperforms other autonomous trading models in efficiency. Even when trained on limited data, the agent exhibits outstanding performance in information processing and investment decision-making. Thanks to its unique ability to regulate cognitive load, FinMem can process a large number of events without sacrificing analytical quality. For example, it can simultaneously analyze dozens of independent market signals, structure them by importance, and make well-founded decisions under time constraints.
Another significant advantage of FinMem is its capacity to learn and adapt to new data in real time. This allows the agent not only to manage current tasks but also to continuously refine its trading strategies in response to changing market conditions. This combination of cognitive flexibility and technological sophistication makes FinMem a major step forward in autonomous trading. FinMem represents a cutting-edge solution that merges cognitive principles with advanced technologies for successful performance in complex and dynamic financial markets.
FinMem Architecture
The FinMem framework consists of three primary modules:
- Profiling
- Memory
- Decision-making
The profiling module enables FinMem to develop a dynamic agent character designed to navigate the complex dynamics of financial markets efficiently. The dynamic character of FinMem comprises two key components: a fundamental professional knowledge base, akin to that of a trading expert, and an agent with three distinct risk tendencies.
The first component encompasses two types of information: an introduction to the primary trading sectors related to the company whose stocks FinMem will trade and a brief overview of the ticker's historical financial performance over the entire training period. Before trading the stock of a new company, FinMem accesses and updates these sectoral and historical financial data from a server-side database. This professional knowledge configuration narrows the scope of memory to events relevant to specific trading tasks.
The second component of FinMem design includes three different risk preference profiles:
- Risk-seeking,
- Risk-averse,
- Self-adaptive risk character.
In risk-seeking mode, FinMem adopts an aggressive, high-return strategy, whereas in risk-averse mode, it reorients toward a conservative, lower-risk approach. FinMem's distinctive feature is its ability to dynamically switch between these risk settings in response to current market conditions. Specifically, it shifts its risk preference when cumulative returns fall below zero over a short period. This flexible design acts as a safeguard mechanism, mitigating prolonged drawdowns in turbulent markets.
At the initial training stage, FinMem is configured according to the selected risk preference, each accompanied by detailed textual instructions in the form of LLM prompts. These guidelines determine how FinMem processes incoming messages and defines its subsequent actions in accordance with the assigned risk profile. The system maintains a catalog of all risk profiles and their detailed explanations in its backlog, allowing easy adaptation to different stocks by switching between these profiles as needed.
This dynamic character configuration within the FinMem's profiling module provides both subjective and professional knowledge, as well as flexible risk behavior selection. It supplies essential context for filtering and extracting trade-relevant information and memory-related events, thereby enhancing the precision of inference and adaptability to changing market conditions.
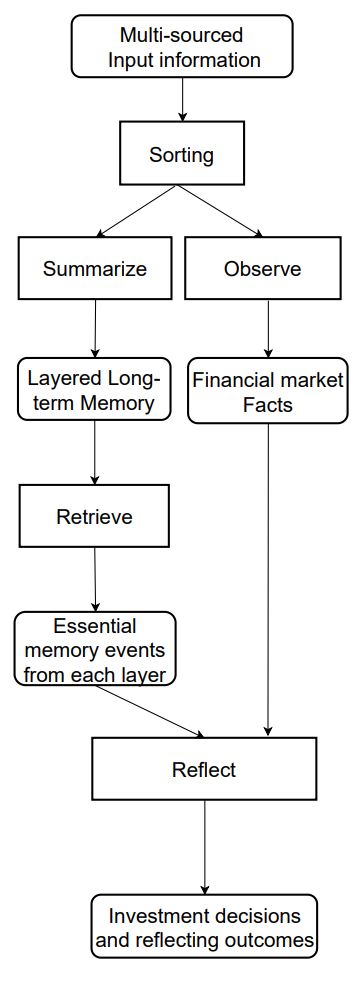
The FinMem memory module emulates a trader's cognitive system to efficiently process hierarchical financial information and prioritize critical messages for high-quality investment decisions. It can dynamically adjust memory capacity, allowing the agent to handle a wider range of events over longer retrieval periods. The memory module in FinMem includes working memory and long-term memory, both capable of layered processing, and is activated by a specific investment query.
Working memory corresponds to the human cognitive function responsible for temporary storage and mental operations. The framework's authors incorporated this concept into the FInMem memory design by creating a central workspace for informed decision-making. Unlike human working memory, which can hold around seven ± two events, FinMem's working memory is scalable based on specific requirements. Designed to transform financial data into trading actions, FinMem's working memory performs three key operations: summarization, observation, and reflection.
FinMem uses external market data to derive critical investment insights and sentiments tailored to specific stock-trading queries. The system condenses raw text into compact yet informative paragraphs, improving FinMem's processing efficiency. It extracts and summarizes relevant data and sentiments for investment decision-making. Then FinMem directs these outputs to the appropriate layer in long-term memory, selected according to the temporal sensitivity of the information.
When initiating the same query, FinMem performs an observation operation to collect market facts. The information available to FinMem differs between training and testing phases. During training, it has access to comprehensive stock price data for the specified period. Upon receiving trading queries specifying a ticker and date, FinMem focuses on the daily adjusted closing price differences, comparing the next day's price with the current day's. These price differences are used as market benchmarks. Price decreases signal a "Sell" action, while increases or no change indicate a "Buy".
During the testing phase, FinMem loses access to future price data. It instead focuses on analyzing historical price movements and evaluating cumulative returns for the analyzed period. This phase, characterized by the absence of predictive market data, serves as a critical test of FinMem's ability to establish logical connections between stock price trends and diverse financial information sources such as news, reports, and indicators. It is crucial for assessing FinMem's ability to autonomously evolve its trading strategies using analysis and interpretation of historical data.
There are two types of responses: immediate and extended. The immediate response is triggered upon receiving a daily trading query for a specific ticker. Using LLM and predefined prompts, the agent combines market indicators and top-K ranked memory events from each long-term memory layer. Market indicators are derived from the results of observation operations and differ between the training and testing stages. During testing, this produces three outputs: the trading direction ("Buy", "Sell", or "Hold"), the rationale for the decision, and the most influential memory events with their identifiers. During the training stage, there is no need to indicate the trade direction, since FinMem already knows about the future directions of the stock's movement. Top-K ranked memory event encapsulate key insights and sentiment derived from critical investment-related incoming messages, all summarized by FinMem using advanced capabilities.
The extended response reevaluates the agent's immediate results over a defined tracking interval. It includes stock price trends, trading performance, and action rationales based on several immediate reflections. While the immediate response enables direct trading and feedback recording, the extended response generalizes market trends and reassesses recent cumulative investment performance. These extended responses are ultimately stored in the deep long-term memory layer, emphasizing their critical importance.
FinMem's long-term memory organizes analytical financial data hierarchically. FinMem uses a layered structure to account for different temporal sensitivities inherent in various financial data types. This structure classifies summarized findings according to timeliness and decay rate (forgetting speed). The outputs are generated using a working memory generalization operation. Events directed to deeper layers have slower decay rates = longer retention, whereas shallow-layer data decays faster and is retained for shorter periods. Each memory event belongs to only one layer.
Upon receiving an investment query, FinMem retrieves the top-K key memory events from each layer and directs them to the working memory's reflection component. Events are ranked based on three metrics: novelty, relevance, and importance. Scores exceeding 1.0 are normalized to a [0,1] range before aggregation.
For the trade request fed into the technology layer, the agent uses an LLM query to evaluate novelty, which is inversely correlated with the time gap between the query and the event timestamp, reflecting the forgetting curve. Stability partially controls the decay rate at different layers: higher stability indicates longer memory persistence. In trading contexts, company annual reports are considered more significant than daily financial news. Thus, they are assigned higher stability values and stored in deeper processing layers, reflecting their extended relevance and impact on financial decision-making.
Relevance is quantified by calculating the cosine similarity between embedding vectors derived from the textual content of memory events. LLM queries incorporate both the original trading request data and the agent’s character configuration.
FinMem's decision-making module effectively integrates operational outputs from the profiling and memory modules to support well-founded investment decisions. In its daily trading decisions, FinMem chooses one of three possible actions for a given stock: Buy, Sell, or Hold —through text-based verification. The input data and outputs required by FinMem's decision-making module differ between the training and testing phases.
During training, FinMem accesses a wide range of data from multiple sources covering the entire training period. When it receives trading queries containing a ticker, date, and trader character descriptions, it simultaneously initiates observation and summarization operations in working memory. FinMem monitors market labels, including daily adjusted price differences, which indicate "Buy" or "Sell" actions. Using these price-change signals, FinMem identifies and prioritizes top-K memories, ranking them based on extraction scores from each long-term memory layer. This process allows FinMem to generate comprehensive analyses that justify and interpret correlations between market labels and retrieved memories. Through repeated trading operations, impactful reactions and memory events migrate to deeper memory layers for retention, supporting future investment decisions during testing.
During testing, when FinMem no longer has access to future price data, it relies on cumulative returns over the analyzed period to forecast future market trends. To compensate for the absence of predictive data, FinMem uses extended responses derived from immediate reflections as supplementary labels. When faced with a specific trading query, FinMem integrates information from multiple sources, including historical cumulative returns, extended reflections, and top-K retrieved memories. This comprehensive approach enables FinMem to make well-reasoned trading decisions.
It should be noted that FinMem generates executable actions only during the immediate reaction phase in testing. Since trading directions are based on actual price trends, no investment actions are taken during training. Instead, this stage focuses on accumulating trading experience by comparing market dynamics with incoming financial information from multiple sources. During this process, FinMem enriches its memory module with a vast knowledge base, thereby enhancing its capability for autonomous decision-making in future trading scenarios.
The original visualization of the FDinMem framework is provided below.
Implementation in MQL5
After examining the theoretical aspects of the FinMem framework, we now move on to implementing the proposed approaches using MQL5. It should be noted immediately that our implementation will likely differ significantly from the authors' original solution compared to all previous works. This is primarily due to the fact that the original framework relies on a pre-trained LLM as its core. In our case, we will base our implementation on the information-processing approaches proposed by the authors but explore them from a different perspective.
Memory Module
We begin by constructing the memory module. In the original FinMem framework, thanks to the use of an LLM, the agent's memory is populated with textual descriptions summarizing events from various sources, along with their embeddings. In our implementation, however, we will not use an LLM. Accordingly, we will work solely with numerical information obtained directly from the trading terminal.
Next, we need to consider building multi-level memory with different decay rates for each layer. This immediately raises the question of how to prioritize the analyzed events. When analyzing only the current state of the environment, represented by price movement data and various technical indicators, it is difficult to determine the priority of two subsequent states.
After evaluating various options, we decided to use recurrent blocks to organize memory levels. To emulate different forgetting rates, we employed distinct architectures of recurrent blocks for separate memory layers, each inherently possessing different decay characteristics due to its architectural design. We chose not to artificially prioritize environmental states. Instead, all layers of memory process the raw data equally, and we propose allowing the model to learn the priorities.
We implement data matching across different memory levels using a cross-attention block.
The above algorithm will be encapsulated in the CNeuronMemory object, the structure of which is outlined below.
class CNeuronMemory : public CNeuronRelativeCrossAttention { protected: CNeuronLSTMOCL cLSTM; CNeuronMambaOCL cMamba; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronMemory(void){}; ~CNeuronMemory(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMemory; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
In our library, we have implemented two recurrent blocks: LSTM and Mamba, which we will use to organize memory layers. To reconcile the outputs of these blocks, we will use a relative cross-attention module. To reduce the number of internal objects within our attention block, we will use the cross-attention object as a parent class.
The internal memory layer objects are declared statically, allowing us to leave the class constructor and destructor empty. Initialization of all declared and inherited objects is performed, as usual, in the Init method.
bool CNeuronMemory::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, window, window_key, units_count, heads, window, units_count, optimization_type, batch)) return false;
The parameters of this method include familiar constants from the parent class method. However, in this case, we exclude the second data source parameter, as our new object operates on a single data stream. When calling the parent class method, we replicate the primary data stream values for the second source parameter.
After successfully executing the parent method operations, we initialize the recurrent objects of the memory layers with corresponding data source parameters.
if(!cLSTM.Init(0, 0, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cMamba.Init(0, 1, OpenCL, iWindow, 2 * iWindow, iUnits, optimization, iBatch)) return false; //--- return true; }
Finally, the method returns a boolean result indicating the success of the operations to the calling program.
The next step is constructing the feedForward algorithm. Everything is quite simple here. The method receives a pointer to the source data object, which is then passed to the corresponding methods of the internal memory layers.
bool CNeuronMemory::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cLSTM.FeedForward(NeuronOCL)) return false; if(!cMamba.FeedForward(NeuronOCL)) return false;
We then compare the results of the recurrent objects using the parent cross-attention class and return a boolean result to the calling program.
return CNeuronRelativeCrossAttention::feedForward(cMamba.AsObject(), cLSTM.getOutput());
}
The calcInputGradients algorithm that propagates error gradients looks a little more complicated. Here, we need to propagate error gradients from two information streams to the source data object, whose pointer is provided as a method parameter.
bool CNeuronMemory::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Within the method, we first check the validity of the source data object pointer, since propagating the gradient would be impossible otherwise.
Upon successful validation, we distribute the error gradient across the internal memory layers using the parent object.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cMamba.AsObject(), cLSTM.getOutput(), cLSTM.getGradient(), (ENUM_ACTIVATION)cLSTM.Activation())) return false;
Next, we propagate the gradient from one memory layer to the source data level.
if(!NeuronOCL.calcHiddenGradients(cMamba.AsObject())) return false;
Then, we replace the pointer to the source data gradient buffer with a free buffer and propagate the second information stream.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cMamba.getPrevOutput(), false)) return false; if(!NeuronOCL.calcHiddenGradients(cLSTM.AsObject())) return false; if(!NeuronOCL.SetGradient(temp, false) || !SumAndNormilize(temp, cMamba.getPrevOutput(), temp, iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
Finally, we sum the gradients from both streams and restore the buffer pointers to their original state. Upon completion of all operations, the method informs the calling program of the execution status and terminates.
The updateInputWeights method algorithm for updating model parameters does not contain any complex elements. I encourage you to review them independently. The complete code for the memory module and all its methods is included in the attached files. We now proceed to the next stage.
Building the FinMem Framework
The next stage of our work involves implementing the comprehensive FinMem framework algorithm, which we will construct within the CNeuronFinMem object. The structure of the new class is shown below.
class CNeuronFinMem : public CNeuronRelativeCrossAttention { protected: CNeuronTransposeOCL cTransposeState; CNeuronMemory cMemory[2]; CNeuronRelativeCrossAttention cCrossMemory; CNeuronRelativeCrossAttention cMemoryToAccount; CNeuronRelativeCrossAttention cActionToAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinMem(void) {}; ~CNeuronFinMem(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint accoiunt_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinMem; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
As can be seen, the new object includes two previously described memory modules and several cross-attention blocks. Their purpose will be easier to understand as we proceed through the implementation of the class methods.
All internal objects are declared statically, which allows us to leave the class constructor and destructor empty. The initialization of all declared and inherited objects, as usual, is handled within the Init method.
It is important to note that, in this case, we are creating an Agent object. It analyzes input data and returns a certain action vector, which is reflected in the object's initialization parameters. Therefore, in addition to the standard constants describing the environment state tensor, the initialization method also includes parameters for the account state descriptor (account_descr) and the action space (nactions).
Furthermore, to emulate the behavior of the extended reaction module proposed by the authors of the FinMem framework, we plan to recurrently reuse information about the agent's previous actions in relation to transitions to new environment states. For this reason, the cross-attention module was chosen as the parent class.
bool CNeuronFinMem::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint account_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, nactions / 2, window_key, 2, heads, window, units_count, optimization_type, batch)) return false;
Within the body of the object's initialization method, we follow our established convention: first, we call the parent class method. As mentioned earlier, it's the cross-attention object. The primary information stream receives the vector of the agent's previous actions, which we divide into two equal parts (presumably representing buy and sell operations). The secondary information stream receives processed data describing the current state of the environment.
After successfully executing the parent class operations, we proceed to initialize the newly declared objects. The first is the data transposition object for the environment state descriptor.
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false;
Recall that the model input consists of environment state descriptions represented as vectors of individual bars. Transposing this tensor enables analysis across separate univariate sequences.
Based on this feature, we use two memory modules to analyze the input data from different perspectives.
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false; index++; if(!cMemory[1].Init(0, index, OpenCL, units_count, window_key, window, heads, optimization, iBatch)) return false;
The results produced by these memory modules are then aggregated in a cross-attention block.
index++; if(!cCrossMemory.Init(0, index, OpenCL, window, window_key, units_count, heads, units_count, window, optimization, iBatch)) return false;
The next cross-attention block enriches the environment state description with information on accumulated profits and losses drawn from the account state vector, which also contains the timestamp of the analyzed state.
index++; if(!cMemoryToAccount.Init(0, index, OpenCL, window, window_key, units_count, heads, account_descr, 1, optimization, iBatch)) return false;
Finally, we initialize one more cross-attention block, which aligns the agent’s most recent actions with the corresponding outcomes reflected in the current account state.
index++; if(!cActionToAccount.Init(0, index, OpenCL, nactions / 2, window_key, 2, heads, account_descr, 1, optimization, iBatch)) return false; //--- if(!Clear()) return false; //--- return true; }
After completing these steps, we clear the internal states of all recurrent objects and return a boolean result indicating the success of the operations to the calling program.
Without noticing, we have reached the end of this article, but our work is not yet complete. We will take a short break. In the next article, we will bring our implementation to its logical conclusion and evaluate the effectiveness of the developed solutions using real historical data.
Conclusion
In this article, we explored the FinMem framework, which represents a new stage in the evolution of autonomous trading systems. It combines cognitive principles with advanced algorithms based on large language models. Its multi-layered memory and real-time adaptability enable the agent to make precise, well-reasoned investment decisions even under volatile market conditions.
In the practical section, we began developing our own interpretation of the proposed approaches using MQL5, deliberately excluding the use of a language model. In the next installment, we will bring this work to completion and evaluate the performance of the implemented solutions.
References
- FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
- Other articles from this series
Programs used in the article
| # | Name | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor for collecting samples |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor for collecting samples using the Real-ORL method |
| 3 | Study.mq5 | Expert Advisor | Model training EA |
| 4 | Test.mq5 | Expert Advisor | Model Testing Expert Advisor |
| 5 | Trajectory.mqh | Class library | System state and model architecture description structure |
| 6 | NeuroNet.mqh | Class library | A library of classes for creating a neural network |
| 7 | NeuroNet.cl | Code library | OpenCL program code library |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/16804
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Hello, interesting article. Unfortunately I can't compile the Research.mq5 file - the line if((!CreateDescriptions(actor, critic, critic))) - Incorrect number of parameters. I can not move on(
Good afternoon, From which catalogue is the Research file loaded? There are indeed a lot of parameters. Only one model is used in this work.
Good afternoon, From which catalogue is the Research file downloaded? There are indeed a lot of parameters here. In this paper only one model is used.
I have looked through the catalogues and I am already confused where I got it((
Can you please direct me which catalogue to use for this paper?
On catalogues lazily and already confused where I took((
Please direct me what catalogue to use for this article?
All files related to this article are located in the FinMem folder.
Tried all sorts of things but didn't come up with your results.
I'm sorry, can you give proper instructions on what to run and what files in what order.
Thank you.