
Neuronale Netze im Handel: Ein Agent mit geschichtetem Speicher

Einführung
Die wachsende Menge an Finanzdaten erfordert von den Händlern nicht nur eine rasche Verarbeitung, sondern auch eine gründliche Analyse, um genaue und rechtzeitige Entscheidungen treffen zu können. Die Grenzen des menschlichen Gedächtnisses, der Aufmerksamkeit und der Fähigkeit, große Mengen an Informationen zu verarbeiten, können jedoch dazu führen, dass kritische Ereignisse übersehen oder falsche Schlussfolgerungen gezogen werden. Daraus ergibt sich ein Bedarf an autonomen Handelsagenten, die in der Lage sind, heterogene Daten effizient zu integrieren – schnell und mit hoher Präzision. Eine solche Lösung wurde in dem Artikel „FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design“ vorgestellt.
Das vorgeschlagene System FinMem ist ein innovativer, auf einem großen Sprachmodell (LLM) basierender Agent, der ein einzigartiges mehrstufiges Speichersystem einführt. Dieser Ansatz ermöglicht eine effiziente Verarbeitung von Daten unterschiedlicher Art und zeitlicher Bedeutung. Das Speichermodul von FinMem ist unterteilt in einen Arbeitsspeicher, der für die kurzfristige Datenverarbeitung konzipiert ist, und einen geschichteten Langzeitspeicher, in dem Informationen nach ihrer Relevanz und Wichtigkeit kategorisiert werden. So werden beispielsweise Tagesnachrichten und kurzfristige Marktschwankungen auf einer oberflächlichen Ebene analysiert, während Berichte und Studien mit langfristigen Auswirkungen in tieferen Speicherschichten abgelegt werden. Diese Struktur ermöglicht es dem Agenten, Informationen zu priorisieren und sich auf die wichtigsten Daten zu konzentrieren.
Das Profiling-Modul in FinMem ermöglicht es dem Agenten, sich an berufliche Kontexte und Marktbedingungen anzupassen. Unter Berücksichtigung der individuellen Präferenzen und des Risikoprofils des Nutzers passt der Agent seine Strategie an, um maximale Effizienz zu erzielen. Das Entscheidungsfindungsmodul integriert aktuelle Marktdaten mit gespeicherten Erinnerungen, um gut durchdachte Strategien zu entwickeln. So können sowohl kurzfristige Trends als auch langfristige Muster berücksichtigt werden. Dank eines solchen kognitiv inspirierten Designs kann sich FinMem an wichtige Marktereignisse erinnern und diese nutzen, wodurch sich die Genauigkeit und Anpassungsfähigkeit seiner Entscheidungen erhöht.
Die Ergebnisse mehrerer Experimente, die in der ursprünglichen Forschungsarbeit vorgestellt wurden, zeigen, dass FinMem andere autonome Handelsmodelle an Effizienz übertrifft. Selbst wenn er mit begrenzten Daten trainiert wird, zeigt der Agent hervorragende Leistungen bei der Informationsverarbeitung und bei Investitionsentscheidungen. Dank seiner einzigartigen Fähigkeit, die kognitive Belastung zu regulieren, kann FinMem eine große Anzahl von Ereignissen verarbeiten, ohne die analytische Qualität zu beeinträchtigen. So kann es beispielsweise Dutzende von unabhängigen Marktsignalen gleichzeitig analysieren, sie nach ihrer Bedeutung strukturieren und unter Zeitdruck fundierte Entscheidungen treffen.
Ein weiterer großer Vorteil von FinMem ist seine Fähigkeit, zu lernen und sich in Echtzeit an neue Daten anzupassen. Auf diese Weise kann der Agent nicht nur die laufenden Aufgaben bewältigen, sondern auch seine Handelsstrategien als Reaktion auf veränderte Marktbedingungen kontinuierlich verfeinern. Diese Kombination aus kognitiver Flexibilität und technologischer Raffinesse macht FinMem zu einem großen Schritt nach vorn im autonomen Handel. FinMem ist eine hochmoderne Lösung, die kognitive Prinzipien mit fortschrittlichen Technologien für eine erfolgreiche Performance in komplexen und dynamischen Finanzmärkten verbindet.
Die Architektur von FinMem
FinMem besteht aus drei Hauptmodulen:
- Profiling
- Memory
- Decision-making
Das Modul Profiling ermöglicht es FinMem, einen dynamischen Agentencharakter zu entwickeln, der die komplexe Dynamik der Finanzmärkte effizient steuern kann. Der dynamische Charakter von FinMem umfasst zwei Schlüsselkomponenten: eine grundlegende professionelle Wissensbasis, die der eines Handelsexperten ähnelt, und einen Agenten mit drei verschiedenen Risikoneigungen.
Die erste Komponente umfasst zwei Arten von Informationen: eine Einführung in die wichtigsten Handelssektoren des Unternehmens, dessen Aktien von FinMem gehandelt werden, und einen kurzen Überblick über die historische Finanzleistung des Tickers während des gesamten Ausbildungszeitraums. Bevor die Aktien eines neuen Unternehmens gehandelt werden, greift FinMem auf diese sektoralen und historischen Finanzdaten zu und aktualisiert sie in einer serverseitigen Datenbank. Durch diese professionelle Wissenskonfiguration wird der Umfang des Gedächtnisses auf Ereignisse eingegrenzt, die für bestimmte Handelsaufgaben relevant sind.
Die zweite Komponente des Designs von FinMem umfasst drei verschiedene Risikopräferenzprofile:
- Risikofreudig,
- Risikoscheu,
- Selbstadaptiver Risikocharakter.
Im risikofreudigen Modus verfolgt FinMem eine aggressive, renditestarke Strategie, während es im risikoscheue Modus einen konservativen, risikoärmeren Ansatz verfolgt. Das besondere Merkmal von FinMem ist die Fähigkeit, dynamisch zwischen diesen Risikoeinstellungen zu wechseln, um auf die aktuellen Marktbedingungen zu reagieren. Insbesondere verschiebt er seine Risikopräferenz, wenn die kumulierten Renditen über einen kurzen Zeitraum unter Null fallen. Diese flexible Gestaltung wirkt wie ein Schutzmechanismus, der längere Ausfälle in turbulenten Märkten abmildert.
In der Einarbeitungsphase wird FinMem entsprechend der gewählten Risikopräferenz konfiguriert, jeweils begleitet von detaillierten textlichen Anweisungen in Form von LLM-Prompts. Diese Richtlinien legen fest, wie FinMem eingehende Meldungen verarbeitet und die nachfolgenden Aktionen entsprechend dem zugewiesenen Risikoprofil definiert. Das System verwaltet einen Katalog aller Risikoprofile und ihrer detaillierten Erklärungen in seinem Backlog, sodass eine einfache Anpassung an verschiedene Bestände möglich ist, indem je nach Bedarf zwischen diesen Profilen gewechselt wird.
Diese dynamische Charakterkonfiguration innerhalb des Profiling-Moduls von FinMem bietet sowohl subjektives und professionelles Wissen als auch eine flexible Auswahl des Risikoverhaltens. Sie liefert den wesentlichen Kontext für das Filtern und Extrahieren von handelsrelevanten Informationen und erinnerungsrelevanten Ereignissen, wodurch die Genauigkeit der Schlussfolgerungen und die Anpassungsfähigkeit an sich ändernde Marktbedingungen verbessert werden.
Das Speichermodul von FinMem emuliert das kognitive System eines Händlers, um hierarchische Finanzinformationen effizient zu verarbeiten und kritische Nachrichten für hochwertige Investitionsentscheidungen zu priorisieren. Die Speicherkapazität kann dynamisch angepasst werden, sodass der Agent eine größere Anzahl von Ereignissen über längere Abrufzeiträume hinweg verarbeiten kann. Das Speichermodul in FinMem umfasst einen Arbeits- und einen Langzeitspeicher, die beide zu einer schichtweisen Verarbeitung fähig sind, und wird durch eine spezifische Investitionsanfrage aktiviert.
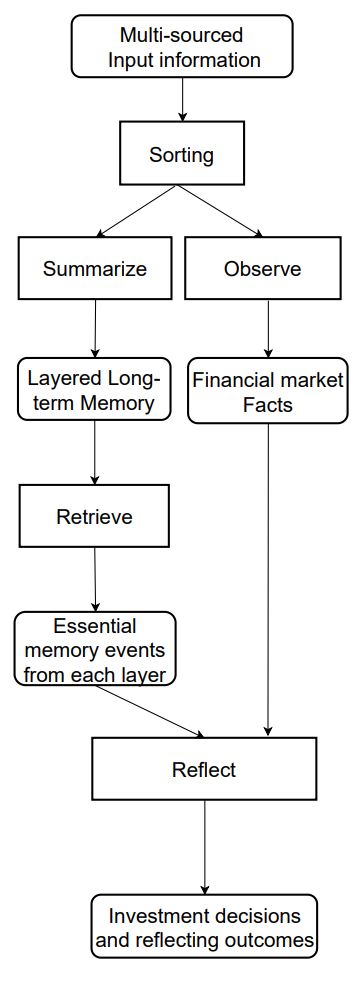
Das Arbeitsgedächtnis entspricht der kognitiven Funktion des Menschen, die für die vorübergehende Speicherung und mentale Operationen zuständig ist. Die Autoren des Frameworks haben dieses Konzept in das Speicherdesign von FInMem integriert, indem sie einen zentralen Arbeitsbereich für fundierte Entscheidungen geschaffen haben. Im Gegensatz zum menschlichen Arbeitsgedächtnis, das etwa sieben ± zwei Ereignisse speichern kann, ist der Arbeitsspeicher von FinMem je nach Bedarf skalierbar. Der Arbeitsspeicher von FinMem wurde entwickelt, um Finanzdaten in Handelsaktionen umzuwandeln, und führt drei Schlüsseloperationen durch: Zusammenfassung, Beobachtung und Reflexion.
FinMem nutzt externe Marktdaten, um kritische Investmenteinblicke und -stimmungen abzuleiten, die auf spezifische Aktienhandelsanfragen zugeschnitten sind. Das System verdichtet den Rohtext zu kompakten, aber informativen Absätzen und verbessert so die Verarbeitungseffizienz von FinMem. Es extrahiert und fasst relevante Daten und Stimmungen für Investitionsentscheidungen zusammen. Dann leitet FinMem diese Ausgaben an die entsprechende Schicht im Langzeitgedächtnis weiter, die nach der zeitlichen Empfindlichkeit der Information ausgewählt wird.
Bei der gleichen Abfrage führt FinMem eine Beobachtungsoperation durch, um Marktdaten zu sammeln. Die Informationen, die FinMem zur Verfügung stehen, unterscheiden sich zwischen Trainings- und Testphasen. Während des Trainings hat Zugang zu umfassenden Aktienkursdaten für den angegebenen Zeitraum. Bei Handelsanfragen, die einen Ticker und ein Datum angeben, konzentriert sich FinMem auf die täglich angepassten Schlusskursdifferenzen und vergleicht den Kurs des nächsten Tages mit dem des aktuellen Tages. Diese Preisunterschiede werden als Marktbenchmarks verwendet. Kursrückgänge signalisieren „Verkaufen“, während Kurssteigerungen oder keine Veränderung auf „Kaufen“ hindeuten.
Während der Testphase verliert FinMem den Zugang zu zukünftigen Preisdaten. Sie konzentriert sich stattdessen auf die Analyse historischer Kursbewegungen und die Bewertung der kumulierten Renditen für den analysierten Zeitraum. Diese Phase, die durch das Fehlen von prädiktiven Marktdaten gekennzeichnet ist, dient als kritischer Test für die Fähigkeit von FinMem, logische Verbindungen zwischen Aktienkurstrends und verschiedenen Finanzinformationsquellen wie Nachrichten, Berichten und Indikatoren herzustellen. Sie ist von entscheidender Bedeutung für die Bewertung der Fähigkeit von FinMem, seine Handelsstrategien anhand der Analyse und Interpretation historischer Daten eigenständig weiterzuentwickeln.
Es gibt zwei Arten von Antworten: unmittelbare und erweiterte. Die unmittelbare Antwort wird ausgelöst, wenn eine tägliche Handelsanfrage für einen bestimmten Ticker eingeht. Mithilfe von LLM und vordefinierten Aufforderungen kombiniert der Agent Marktindikatoren und Gedächtnisereignisse mit dem Top-Rang K aus jeder Langzeitgedächtnisschicht. Die Marktindikatoren werden aus den Ergebnissen der Beobachtungsmaßnahmen abgeleitet und unterscheiden sich zwischen der Schulungs- und der Testphase. Beim Testen werden drei Ausgaben erzeugt: die Handelsrichtung („Kaufen“, „Verkaufen“ oder „Halten“), die Begründung für die Entscheidung und die einflussreichsten Ereignisse aus dem Speicher mit ihren Bezeichnungen. In der Trainingsphase ist es nicht notwendig, die Handelsrichtung anzugeben, da FinMem die zukünftigen Bewegungsrichtungen der Aktie bereits kennt. Speicherereignisse des Top-Rangs K kapseln wichtige Erkenntnisse und Stimmungen aus kritischen, investitionsbezogenen eingehenden Nachrichten, die von FinMem mit Hilfe erweiterter Funktionen zusammengefasst werden.
Bei der erweiterten Reaktion werden die unmittelbaren Ergebnisse des Agenten über ein bestimmtes Verfolgungsintervall hinweg neu bewertet. Er umfasst Aktienkurstrends, Handelsergebnisse und Handlungsempfehlungen, die auf mehreren unmittelbaren Überlegungen beruhen. Während die unmittelbare Reaktion den direkten Handel und die Aufzeichnung von Rückmeldungen ermöglicht, verallgemeinert die erweiterte Reaktion die Markttrends und bewertet die jüngsten kumulativen Anlageergebnisse neu. Diese erweiterten Antworten werden schließlich im Langzeitgedächtnis gespeichert, was ihre entscheidende Bedeutung unterstreicht.
Der Langzeitspeicher von FinMem organisiert die analytischen Finanzdaten hierarchisch. FinMem verwendet eine mehrschichtige Struktur, um den unterschiedlichen zeitlichen Empfindlichkeiten der verschiedenen Finanzdatentypen Rechnung zu tragen. Diese Struktur klassifiziert die zusammengefassten Erkenntnisse nach Aktualität und Verfallsrate (Vergessensgeschwindigkeit). Die Ausgaben werden durch eine Generalisierungsoperation des Arbeitsspeichers erzeugt. Ereignisse, die auf tiefere Schichten gerichtet sind, haben langsamere Abklingraten = längere Speicherung, während Daten aus flachen Schichten schneller abklingen und kürzer gespeichert werden. Jedes Speicherereignis gehört nur zu einer Schicht.
Nach Erhalt einer Investitionsanfrage ruft FinMem die Top-Schlüsselspeicherereignisse K aus jeder Schicht ab und leitet sie an die Reflexionskomponente des Arbeitsspeichers weiter. Die Ereignisse werden anhand von drei Kriterien bewertet: Neuheit, Relevanz und Wichtigkeit. Werte über 1,0 werden vor der Aggregation auf einen Bereich [0,1] normalisiert.
Für die Handelsanfrage, die in die Technologieschicht eingespeist wird, verwendet der Agent eine LLM-Abfrage, um die Neuheit zu bewerten, die umgekehrt mit dem zeitlichen Abstand zwischen der Anfrage und dem Zeitstempel des Ereignisses korreliert ist, was die Vergessenskurve widerspiegelt. Die Stabilität steuert teilweise die Abklingrate auf verschiedenen Ebenen: eine höhere Stabilität bedeutet eine längere Gedächtnisdauer. Im Handelskontext werden Jahresberichte von Unternehmen als wichtiger angesehen als tägliche Finanznachrichten. Daher wird ihnen ein höherer Stabilitätswert zugewiesen und sie werden in tieferen Verarbeitungsschichten gespeichert, was ihre größere Relevanz und Auswirkung auf finanzielle Entscheidungen widerspiegelt.
Die Relevanz wird durch die Berechnung der Kosinus-Ähnlichkeit zwischen Einbettungsvektoren, die aus dem textlichen Inhalt von Gedächtnisereignissen abgeleitet werden, quantifiziert. LLM-Abfragen enthalten sowohl die ursprünglichen Daten der Handelsanfrage als auch die Zeichenkonfiguration des Agenten.
Das Entscheidungsfindungsmodul von FinMem integriert effektiv die operativen Ergebnisse der Profiling- und Speichermodule, um fundierte Investitionsentscheidungen zu unterstützen. Bei seinen täglichen Handelsentscheidungen wählt FinMem eine von drei möglichen Aktionen für eine bestimmte Aktie: kaufen, verkaufen oder halten – durch textbasierte Überprüfung. Die vom Entscheidungsmodul von FinMem benötigten Eingabedaten und Ausgaben unterscheiden sich in der Trainings- und Testphase.
Während des Trainings greift FinMem auf eine breite Palette von Daten aus verschiedenen Quellen zu, die den gesamten Trainingszeitraum abdecken. Wenn es Handelsanfragen erhält, die einen Ticker, ein Datum und eine Beschreibung des Händlers enthalten, werden gleichzeitig Beobachtungs- und Zusammenfassungsoperationen im Arbeitsspeicher initiiert. FinMem überwacht die Marktkennzeichnungen, einschließlich der täglich angepassten Preisunterschiede, die Kauf- oder Verkaufsaktionen anzeigen. Anhand dieser Preisänderungssignale identifiziert und priorisiert FinMem die gespeicherten Top-K und ordnet sie auf der Grundlage von Extraktionsergebnissen aus jeder Langzeitspeicherschicht ein. Auf diese Weise kann FinMem umfassende Analysen erstellen, die Korrelationen zwischen Marktkennzeichnungen und abgerufenen Erinnerungen begründen und interpretieren. Durch wiederholte Handelsvorgänge wandern wichtige Reaktionen und Gedächtnisereignisse in tiefere Speicherschichten, um dort gespeichert zu werden und künftige Investitionsentscheidungen während der Tests zu unterstützen.
Während der Tests, wenn FinMem keinen Zugang mehr zu zukünftigen Preisdaten hat, stützt es sich auf die kumulierten Renditen über den analysierten Zeitraum, um zukünftige Markttrends vorherzusagen. Um das Fehlen von Vorhersagedaten zu kompensieren, verwendet FinMem erweiterte Antworten, die aus unmittelbaren Überlegungen abgeleitet werden, als zusätzliche Kennzeichnungen. Bei einer spezifischen Handelsanfrage integriert FinMem Informationen aus mehreren Quellen, einschließlich historischer kumulativer Renditen, erweiterter Reflexionen und die erhaltenen gespeicherten Daten von Top-K. Dank dieses umfassenden Ansatzes ist FinMem in der Lage, gut begründete Handelsentscheidungen zu treffen.
Es ist zu beachten, dass FinMem nur während der unmittelbaren Reaktionsphase beim Testen ausführbare Aktionen erzeugt. Da die Handelsanweisungen auf den aktuellen Preistrends basieren, werden während des Trainings keine Investitionsmaßnahmen getroffen. Stattdessen konzentriert sich diese Phase auf das Sammeln von Handelserfahrungen durch den Vergleich der Marktdynamik mit eingehenden Finanzinformationen aus verschiedenen Quellen. Während dieses Prozesses reichert FinMem sein Speichermodul mit einer umfangreichen Wissensbasis an und verbessert so seine Fähigkeit zur autonomen Entscheidungsfindung in zukünftigen Handelsszenarien.
Die ursprüngliche Visualisierung des Systems von FDinMem finden Sie unten.
Die Implementation in MQL5
Nachdem wir die theoretischen Aspekte von FinMem untersucht haben, gehen wir nun dazu über, die vorgeschlagenen Ansätze mit MQL5 zu implementieren. Es sollte sofort darauf hingewiesen werden, dass sich unsere Implementierung wahrscheinlich erheblich von der ursprünglichen Lösung der Autoren im Vergleich zu allen früheren Arbeiten unterscheiden wird. Dies ist in erster Linie darauf zurückzuführen, dass der ursprüngliche Rahmen auf einer vortrainierten LLM als Kern beruht. In unserem Fall stützen wir uns bei der Umsetzung auf die von den Autoren vorgeschlagenen Informationsverarbeitungsansätze, untersuchen sie aber aus einer anderen Perspektive.
Speicher-Modul
Wir beginnen mit der Konstruktion des Speichermoduls. Im ursprünglichen System von FinMem wird der Speicher des Agenten dank der Verwendung eines LLM mit textuellen Beschreibungen gefüllt, die Ereignisse aus verschiedenen Quellen zusammenfassen, zusammen mit ihren Einbettungen. In unserer Implementierung werden wir jedoch kein LLM verwenden. Daher werden wir ausschließlich mit numerischen Informationen arbeiten, die wir direkt vom Handelsterminal erhalten.
Als Nächstes müssen wir den Aufbau eines mehrstufigen Speichers mit unterschiedlichen Abklingraten für jede Schicht in Betracht ziehen. Dies wirft sofort die Frage auf, wie die analysierten Ereignisse zu priorisieren sind. Wenn man nur den aktuellen Zustand des Umfelds analysiert, der durch die Daten der Preisentwicklung und verschiedene technische Indikatoren dargestellt wird, ist es schwierig, die Priorität von zwei nachfolgenden Zuständen zu bestimmen.
Nach der Evaluierung verschiedener Optionen haben wir uns für die Verwendung von wiederkehrenden Blöcken zur Organisation der Speicherebenen entschieden. Um unterschiedliche Vergessensraten zu emulieren, haben wir verschiedene Architekturen von rekurrenten Blöcken für separate Speicherschichten verwendet, die aufgrund ihres architektonischen Designs jeweils unterschiedliche Abklingcharakteristika aufweisen. Wir haben uns entschieden, keine künstliche Priorisierung der Umweltzustände vorzunehmen. Stattdessen verarbeiten alle Speicherschichten die Rohdaten gleichermaßen, und wir schlagen vor, das Modell die Prioritäten lernen zu lassen.
Wir implementieren den Datenabgleich über verschiedene Speicherebenen hinweg mit Hilfe eines aufmerksamkeitsübergreifenden Blocks.
Der obige Algorithmus wird im Objekt CNeuronMemory gekapselt, dessen Struktur im Folgenden skizziert wird.
class CNeuronMemory : public CNeuronRelativeCrossAttention { protected: CNeuronLSTMOCL cLSTM; CNeuronMambaOCL cMamba; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronMemory(void){}; ~CNeuronMemory(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMemory; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
In unserer Bibliothek haben wir zwei wiederkehrende Blöcke implementiert: LSTM und Mamba, die wir für die Organisation der Speicherschichten verwenden werden. Um die Ergebnisse dieser Blöcke abzugleichen, verwenden wir ein Modul für relative Kreuzaufmerksamkeit. Um die Anzahl der internen Objekte innerhalb unseres Aufmerksamkeitsblocks zu reduzieren, werden wir das Objekt einer Kreuzaufmerksamkeit als übergeordnete Klasse verwenden.
Die Objekte der internen Speicherebene werden statisch deklariert, sodass wir den Konstruktor und Destruktor der Klasse leer lassen können. Die Initialisierung aller deklarierten und geerbten Objekte wird wie üblich in der Methode Init durchgeführt.
bool CNeuronMemory::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, window, window_key, units_count, heads, window, units_count, optimization_type, batch)) return false;
Die Parameter dieser Methode enthalten bekannte Konstanten aus der Methode der übergeordneten Klasse. In diesem Fall lassen wir jedoch den zweiten Datenquellenparameter weg, da unser neues Objekt mit einem einzigen Datenstrom arbeitet. Beim Aufruf der Methode der übergeordneten Klasse replizieren wir die Werte des primären Datenstroms für den zweiten Quellparameter.
Nach erfolgreicher Ausführung der übergeordneten Methodenoperationen initialisieren wir die wiederkehrenden Objekte der Speicherschichten mit den entsprechenden Datenquellenparametern.
if(!cLSTM.Init(0, 0, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cMamba.Init(0, 1, OpenCL, iWindow, 2 * iWindow, iUnits, optimization, iBatch)) return false; //--- return true; }
Schließlich gibt die Methode dem aufrufenden Programm ein boolesches Ergebnis zurück, das den Erfolg der Operationen anzeigt.
Der nächste Schritt ist die Entwicklung des Algorithmus des Vorwärtsdurchlaufs. Hier ist alles ganz einfach. Die Methode erhält einen Zeiger auf das Quelldatenobjekt, der dann an die entsprechenden Methoden der internen Speicherschichten übergeben wird.
bool CNeuronMemory::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cLSTM.FeedForward(NeuronOCL)) return false; if(!cMamba.FeedForward(NeuronOCL)) return false;
Anschließend vergleichen wir die Ergebnisse der wiederkehrenden Objekte anhand der übergeordneten Cross-Attention-Klasse und geben ein boolesches Ergebnis an das aufrufende Programm zurück.
return CNeuronRelativeCrossAttention::feedForward(cMamba.AsObject(), cLSTM.getOutput());
}
Der Algorithmus von calcInputGradients, der die Fehlergradienten weitergibt, sieht etwas komplizierter aus. Hier müssen wir Fehlergradienten aus zwei Informationsströmen an das Quelldatenobjekt weitergeben, dessen Zeiger als Methodenparameter übergeben wird.
bool CNeuronMemory::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Innerhalb der Methode überprüfen wir zunächst die Gültigkeit des Zeigers auf das Quelldatenobjekt, da die Weitergabe des Gradienten sonst nicht möglich wäre.
Nach erfolgreicher Validierung wird der Fehlergradient mit Hilfe des übergeordneten Objekts auf die internen Speicherebenen verteilt.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cMamba.AsObject(), cLSTM.getOutput(), cLSTM.getGradient(), (ENUM_ACTIVATION)cLSTM.Activation())) return false;
Als Nächstes wird der Gradient von einer Speicherebene auf die Ebene der Quelldaten übertragen.
if(!NeuronOCL.calcHiddenGradients(cMamba.AsObject())) return false;
Dann ersetzen wir den Zeiger auf den Quelldaten-Gradientenpuffer durch einen freien Puffer und propagieren den zweiten Informationsstrom.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cMamba.getPrevOutput(), false)) return false; if(!NeuronOCL.calcHiddenGradients(cLSTM.AsObject())) return false; if(!NeuronOCL.SetGradient(temp, false) || !SumAndNormilize(temp, cMamba.getPrevOutput(), temp, iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
Zum Schluss werden die Gradienten aus beiden Strömen summiert und die Pufferzeiger in ihren ursprünglichen Zustand zurückversetzt. Nach Abschluss aller Operationen informiert die Methode das aufrufende Programm über den Ausführungsstatus und beendet sich.
Der Algorithmus der Methode updateInputWeights zur Aktualisierung der Modellparameter enthält keine komplexen Elemente. Ich möchte Sie ermutigen, sie unabhängig zu überprüfen. Der vollständige Code für das Speichermodul und alle seine Methoden sind in den beigefügten Dateien enthalten. Wir gehen nun zum nächsten Schritt über.
Aufbau des Systems von FinMem
Der nächste Schritt unserer Arbeit ist die Implementierung des umfassenden Algorithmus von FinMem, den wir innerhalb des Objekts CNeuronFinMem konstruieren werden. Die Struktur der neuen Klasse ist unten dargestellt.
class CNeuronFinMem : public CNeuronRelativeCrossAttention { protected: CNeuronTransposeOCL cTransposeState; CNeuronMemory cMemory[2]; CNeuronRelativeCrossAttention cCrossMemory; CNeuronRelativeCrossAttention cMemoryToAccount; CNeuronRelativeCrossAttention cActionToAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinMem(void) {}; ~CNeuronFinMem(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint accoiunt_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinMem; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Wie zu sehen ist, umfasst das neue Objekt zwei zuvor beschriebene Speichermodule und mehrere Blöcke mit Querbezügen. Ihr Zweck wird leichter zu verstehen sein, wenn wir mit der Implementierung der Klassenmethoden fortfahren.
Alle internen Objekte werden statisch deklariert, was es uns ermöglicht, den Konstruktor und Destruktor der Klasse leer zu lassen. Die Initialisierung aller deklarierten und geerbten Objekte wird wie üblich in der Methode Init durchgeführt.
Es ist wichtig zu beachten, dass wir in diesem Fall ein Agent-Objekt erstellen. Es analysiert die Eingabedaten und gibt einen bestimmten Aktionsvektor zurück, der sich in den Initialisierungsparametern des Objekts widerspiegelt. Daher enthält die Initialisierungsmethode neben den Standardkonstanten, die den Umweltzustandstensor beschreiben, auch Parameter für den Kontostandsdeskriptor (account_descr) und den Aktionsraum (nactions).
Um das Verhalten des erweiterten Reaktionsmoduls zu emulieren, das von den Autoren des Systems FinMem vorgeschlagen wurde, planen wir außerdem, Informationen über frühere Aktionen des Agenten im Zusammenhang mit Übergängen zu neuen Umgebungszuständen immer wieder zu verwenden. Aus diesem Grund wurde das Modul „Cross-Attention“ (Kreuzaufmerksamkeit) als übergeordnete Klasse gewählt.
bool CNeuronFinMem::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint account_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, nactions / 2, window_key, 2, heads, window, units_count, optimization_type, batch)) return false;
Im Körper der Initialisierungsmethode des Objekts folgen wir unserer bewährten Konvention: Zuerst rufen wir die Methode der Elternklasse auf. Wie bereits erwähnt, handelt es sich um ein Objekt, das die Aufmerksamkeit auf sich zieht. Der primäre Informationsstrom erhält den Vektor der vorherigen Aktionen des Agenten, den wir in zwei gleiche Teile aufteilen (die vermutlich Kauf- und Verkaufsoperationen darstellen). Der sekundäre Informationsstrom empfängt verarbeitete Daten, die den aktuellen Zustand der Umgebung beschreiben.
Nachdem wir die Operationen der übergeordneten Klasse erfolgreich ausgeführt haben, fahren wir mit der Initialisierung der neu deklarierten Objekte fort. Das erste ist das Datenumsetzungsobjekt für die Zustandsbeschreibung der Umgebung.
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false;
Der Modellinput besteht aus Zustandsbeschreibungen der Umgebung, die als Vektoren einzelner Balken dargestellt werden. Die Transposition dieses Tensors ermöglicht eine Analyse über verschiedene univariate Sequenzen hinweg.
Auf der Grundlage dieser Funktion verwenden wir zwei Speichermodule, um die Eingabedaten aus verschiedenen Perspektiven zu analysieren.
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false; index++; if(!cMemory[1].Init(0, index, OpenCL, units_count, window_key, window, heads, optimization, iBatch)) return false;
Die von diesen Speichermodulen erzeugten Ergebnisse werden dann in einem aufmerksamkeitsübergreifenden Block zusammengefasst.
index++; if(!cCrossMemory.Init(0, index, OpenCL, window, window_key, units_count, heads, units_count, window, optimization, iBatch)) return false;
Der nächste Kreuzaufmerksamkeits-Block reichert die Beschreibung des Umgebungszustands mit Informationen über kumulierte Gewinne und Verluste aus dem Kontostandsvektor an, der auch den Zeitstempel des analysierten Zustands enthält.
index++; if(!cMemoryToAccount.Init(0, index, OpenCL, window, window_key, units_count, heads, account_descr, 1, optimization, iBatch)) return false;
Schließlich initialisieren wir einen weiteren Kreuzaufmerksamkeits-Block, der die letzten Handlungen des Agenten mit den entsprechenden Ergebnissen abgleicht, die sich im aktuellen Kontostand widerspiegeln.
index++; if(!cActionToAccount.Init(0, index, OpenCL, nactions / 2, window_key, 2, heads, account_descr, 1, optimization, iBatch)) return false; //--- if(!Clear()) return false; //--- return true; }
Nach Abschluss dieser Schritte werden die internen Zustände aller wiederkehrenden Objekte gelöscht und ein boolesches Ergebnis, das den Erfolg der Operationen anzeigt, an das aufrufende Programm zurückgegeben.
Ohne es zu merken, haben wir das Ende dieses Artikels erreicht, aber unsere Arbeit ist noch nicht abgeschlossen. Wir werden eine kurze Pause einlegen. Im nächsten Artikel werden wir unsere Umsetzung zu einem logischen Abschluss bringen und die Wirksamkeit der entwickelten Lösungen anhand realer historischer Daten bewerten.
Schlussfolgerung
In diesem Artikel haben wir das System FinMem untersucht, der eine neue Stufe in der Entwicklung autonomer Handelssysteme darstellt. Es kombiniert kognitive Prinzipien mit fortschrittlichen Algorithmen, die auf großen Sprachmodellen basieren. Dank seines mehrschichtigen Speichers und seiner Anpassungsfähigkeit in Echtzeit ist der Agent in der Lage, auch unter volatilen Marktbedingungen präzise und gut begründete Anlageentscheidungen zu treffen.
Im praktischen Teil haben wir damit begonnen, unsere eigene Interpretation der vorgeschlagenen Ansätze unter Verwendung von MQL5 zu entwickeln, wobei wir bewusst auf die Verwendung eines Sprachmodells verzichtet haben. In der nächsten Folge werden wir diese Arbeit abschließen und die Leistung der implementierten Lösungen bewerten.
Referenzen
- FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
- Andere Artikel dieser Serie
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor für die Probenahme |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für die Probenahme mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | EA für das Modelltraining |
| 4 | Test.mq5 | Expert Advisor | Expert Advisor für Modelltests |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Beschreibung des Systemzustands und der Modellarchitektur |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code-Bibliothek | OpenCL-Programmcode-Bibliothek |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16804
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Evolutionärer Handelsalgorithmus mit Verstärkungslernen und Auslöschung von schwachen Individuen (ETARE)
Evolutionärer Handelsalgorithmus mit Verstärkungslernen und Auslöschung von schwachen Individuen (ETARE)
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Hallo, interessanter Artikel. Leider kann ich die Datei Research.mq5 nicht kompilieren - die Zeile if((!CreateDescriptions(actor, critic, critic))) - Falsche Anzahl von Parametern. Ich kann nicht weitermachen(
Guten Tag, aus welchem Katalog wird die Research-Datei geladen? Es gibt in der Tat sehr viele Parameter. In dieser Arbeit wird nur ein Modell verwendet.
Guten Tag, aus welchem Katalog wird die Forschungsdatei heruntergeladen? Es handelt sich in der Tat um eine Vielzahl von Parametern. In diesem Papier wird nur ein Modell verwendet.
Ich habe die Kataloge durchgesehen und bin schon verwirrt, woher ich sie habe((
Können Sie mir bitte sagen, welchen Katalog ich für diese Arbeit verwenden soll?
Auf Kataloge faul und schon verwirrt, wo ich nahm((
Bitte leiten Sie mich, welche Katalog für diesen Artikel zu verwenden?
Alle Dateien, die mit diesem Artikel zusammenhängen, befinden sich im Ordner FinMem.
Ich habe alles Mögliche ausprobiert, aber ich bin nicht auf Ihre Ergebnisse gestoßen.
Es tut mir leid, können Sie genaue Anweisungen geben, was auszuführen ist und welche Dateien in welcher Reihenfolge.
Ich danke Ihnen.