
Нейросети в трейдинге: Агент с многоуровневой памятью

Введение
Растущий объем финансовых данных требует от трейдеров не только их быстрой обработки, но и глубокого анализа для принятия точных и своевременных решений. Однако ограничения человеческой памяти, внимания и способности обрабатывать большие объемы информации могут приводить к упущению критически важных событий или к ошибочным выводам. Это приводит к необходимости создания автономных торговых агентов, способных эффективно интегрировать разрозненные данные, делать это быстро и с высокой точностью. Одно из таких решений было предложено в работе "FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design".
Предложенный фреймворк FinMem — это инновационный агент на основе больших языковых моделей (LLM), который предлагает уникальную многоуровневую систему памяти. Этот подход позволяет эффективно работать с данными разной природы и временной важности. Модуль памяти FinMem делится на рабочую память, предназначенную для обработки краткосрочных данных, и стратифицированную долговременную память, в которой информация классифицируется по её значимости и актуальности. Например, ежедневные новости и краткосрочные рыночные колебания анализируются на поверхностном уровне, тогда как отчёты и исследования с долгосрочным воздействием направляются в глубокие слои памяти. Такая структура позволяет агенту приоритизировать информацию, концентрируясь на наиболее релевантных данных.
Модуль профилирования FinMem позволяет адаптировать агента под профессиональный контекст и рыночные условия. Учитывая индивидуальные предпочтения и риск-профиль пользователя, агент настраивает свою стратегию для обеспечения максимальной эффективности. Модуль принятия решений интегрирует текущие рыночные данные и сохранённые воспоминания, генерируя продуманные стратегии. Это позволяет учитывать как краткосрочные тренды, так и долгосрочные закономерности. Такой когнитивно-инспирированный подход делает FinMem способным запоминать и использовать ключевые рыночные события, повышая точность и адаптивность принимаемых решений.
Результаты многочисленных экспериментов, представленных в авторской работе, показали, что FinMem превосходит другие модели автономной торговли по эффективности. Даже при обучении на ограниченных данных агент демонстрирует выдающиеся результаты в обработке информации и принятии инвестиционных решений. Благодаря уникальной способности регулировать когнитивную нагрузку, FinMem обрабатывает большой объём событий без потери качества анализа. Например, он может одновременно анализировать десятки независимых рыночных сигналов, структурировать их по важности и принимать обоснованные решения в условиях ограниченного времени.
Ещё одним важным аспектом FinMem является его способность обучаться и адаптироваться к новым данным в реальном времени. Это позволяет агенту не только справляться с текущими задачами, но и постоянно совершенствовать свои торговые стратегии, реагируя на изменения в рыночных условиях. Такая комбинация когнитивной гибкости и технологической мощи делает FinMem важным шагом вперёд в области автономной торговли. FinMem представляет собой современное решение, объединяющее когнитивные принципы и передовые технологии для успешной работы в условиях сложных и изменчивых финансовых рынков.
Архитектура FinMem
Фреймворк FinMem включает три основных модуля:
- профилирования;
- памяти;
- принятия решений.
Модуль профилирования позволяет FinMem разрабатывать динамический характер агента, специально предназначенный для эффективной навигации по сложной динамике финансовых рынков. Динамический характер FinMem включает в себя два основных компонента: фундаментальную профессиональную базу знаний, сродни торговому эксперту, и агента с тремя различными склонностями к инвестиционному риску.
Первый компонент включает в себя два типа информации: введение в основные торговые сектора, имеющие отношение к компании, акциями которой будет торговаться FinMem, и краткий обзор исторических финансовых показателей указанного тикера, охватывающий весь период обучения. Прежде чем начать торги акциями новой компании, FinMem получает доступ и обновляет эти отраслевые и исторические финансовые данные из серверной базы данных. Эта профессиональная настройка знаний сужает информацию для запоминания событий, относящихся к конкретным торговым задачам.
Второй компонент дизайна FinMem включает в себя три различных варианта склонности к риску:
- поиск риска,
- неприятие риска,
- самоадаптирующийся характер риска.
В режиме поиска риска FinMem ориентируется на агрессивный подход с высокой доходностью, в то время как режим "неприятие риска" переориентирует торговлю на консервативную стратегию с меньшим риском. Отличительной чертой FinMem является его способность динамически переключаться между указанными настройками риска в ответ на текущие рыночные условия. В частности, он смещает предпочтения в отношении риска, когда совокупная доходность падает ниже нуля в течение короткого периода времени. Эта гибкая конструкция функционирует как защитный механизм, смягчая затяжные спады в турбулентной рыночной среде.
На начальном этапе обучения FinMem настраивается с учетом выбранных предпочтений риска, каждое из которых дополняется подробными текстовыми пояснениями с помощью подсказок для LLM. Эти рекомендации определяют, как FinMem обрабатывает входящие сообщения и определяет свои последующие действия в соответствии с назначенной склонностью к риску. Система поддерживает каталог всех склонностей к риску и их подробные объяснения в бэклоге, что позволяет легко адаптироваться к различным акциям путем переключения между этими профилями рисков по мере необходимости.
Динамическая настройка символов в модуле профилирования FinMem обеспечивает субъективные и профессиональные знания, а так же гибкий выбор склонностей к риску. Что предоставляет важный контекст для фильтрации и извлечения информации, относящейся к торговле, и событий, связанных с памятью, тем самым улучшая точный вывод и адаптируемость к изменяющимся рыночным условиям.
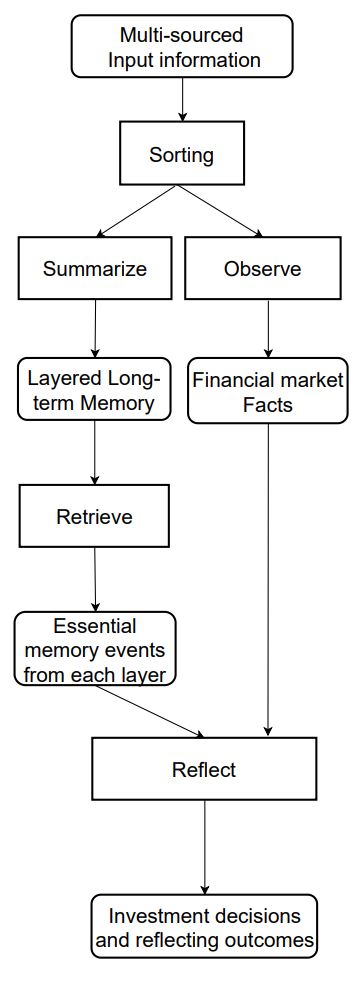
Модуль памяти FinMem эмулирует когнитивную систему трейдера, чтобы она могла эффективно обрабатывать иерархическую финансовую информацию и расставлять приоритеты в критически важных сообщениях для принятия высококачественных инвестиционных решений. Кроме того, он гибко регулирует объем памяти, что позволяет агенту работать с более широким диапазоном событий в течении более длительного периода извлечения. Модуль памяти FinMem включает в себя рабочую и долговременную память с возможностью многоуровневой обработки и инициируется конкретным инвестиционным запросом.
Рабочая память относится к функциям когнитивной системы человека по временному хранению и разнообразным операциям. Авторы фреймоврка включили эту концепцию в разработку модуля памяти FinMem, создав центральное рабочее пространство для принятия обоснованных решений. В отличие от рабочей памяти человека, которая имеет максимальный объем памяти семь плюс-минус два события, FinMem имеет возможность расширения мощностей в зависимости от конкретных требований. Рабочая память FinMem, предназначенная для преобразования финансовых данных в торговые действия, включает в себя три ключевые операции: обобщение, наблюдение и рефлексию.
FinMem использует данные внешнего рынка для получения критически важных инвестиционных идей и настроений, адаптированных к конкретным запросам торговли акциями. Система сжимает исходный текст в компактный, но информативный абзац, тем самым повышая эффективность обработки FinMem. Он эффективно извлекает и обобщает соответствующие данные и настроения для принятия инвестиционных решений. Впоследствии FinMem направляет эти выводы на соответствующий слой в своей архитектуре долговременной памяти, выбирая слой на основе чувствительности информации ко времени.
Инициировав тот же запрос, FinMem инициирует операцию по наблюдению для сбора рыночных фактов. Информация, доступная FinMem, варьируется между этапами обучения и тестирования. На этапе обучения FinMem имеет доступ к исчерпывающим данным о ценах на акции за указанный период. После получения торговых запросов, в которых указываются тикер и дата акции, FinMem фокусируется на ежедневной скорректированной разнице цен закрытия, сравнивая цену следующего дня с ценой текущего дня. Эти различия в ценах используются в качестве рыночных ориентиров. В частности, снижение цены указывает на действие «Продать», в то время как увеличение или отсутствие изменения цены указывает на действие «Купить».
На этапе тестирования, в определенный момент времени, FinMem теряет возможность доступа к будущим ценовым данным. Его акцент смещается на анализ исторических движений цен на акции, в зависимости от ретроспективной оценки совокупной доходности за анализируемый период. Этот этап, характеризующийся отсутствием прогнозируемых рыночных оснований, служит критической оценкой развития FinMem. Он проверяет, имеет ли система адекватно установленные логические связи между тенденциями цен на акции и различными источниками финансовой информации, такими как новости, отчеты и индикаторы. Этот этап является ключевым для оценки способности FinMem самостоятельно развивать свои торговые стратегии для последующих задач, используя свой анализ и интерпретацию исторических данных.
Существует два типа реакций: непосредственная и расширенная реакция. Немедленная реакция активируется при получении ежедневного торгового запроса по конкретному тикеру. Используя LLM и конкретные подсказки агент объединяет рыночные индикаторы и топ-K ранжированных событий из каждого слоя долговременной памяти. Рыночные индикаторы выводятся из результатов операций по наблюдению и различаются между этапами обучения и тестирования. Во время тестирования этот процесс дает три типа результатов: направление торговли («Купить», «Продать» или «Держать»), обоснование этого решения и наиболее влиятельные события памяти, а также их идентификаторы с каждого уровня, на основе которого было принято решение. На этапе обучения нет необходимости указывать направление торговли, так как FinMem уже проинформирован о будущих направлениях движения акций. Топ-K ранжированных событий памяти инкапсулируют ключевые выводы и настроения, полученные из критически важных входящих сообщений, связанных с инвестициями, и все это с помощью расширенных возможностей обобщается FinMem.
Расширенная реакция переоценивает непосредственные результаты действий агента для тикера на заданном интервале трассировки. Она включает в себя такие данные, как тенденции цен на акции, доходность торгов и обоснования действий на основе нескольких непосредственных размышлений. В то время как непосредственная реакция позволяет осуществлять прямую торговлю и записывать текущие отзывы, расширенная реакция обобщает рыночные тенденции и переоценивает недавнюю совокупную доходность инвестиций. Расширенная реакция в конечном итоге сохраняется в глубоком слое долговременной памяти, чтобы подчеркнуть её критичность.
Долговременная память FinMem организует иерархические аналитические финансовые данные в стратифицированную структуру. FinMem использует многоуровневую структуру памяти, чтобы учесть различную чувствительность ко времени, присущую различным типам финансовых данных. Эта структура классифицирует обобщенные выводы по их своевременности и скорости распада (забывания). Выводы генерируются с помощью операции обобщения рабочей памяти. События, направленные в более глубокие слои памяти, получают меньшую скорость распада, что указывает на более длительное удержание, в то время как данные, находящиеся в более мелких слоях, получают более высокую скорость распада для более короткого удержания. Каждое событие памяти может принадлежать только одному слою памяти.
Получив инвестиционный запрос, FinMem извлекает топ-K ключевых событий памяти из каждого слоя и направляют их к компоненту непосредственного отражения рабочей памяти. Эти события выбираются в порядке убывания их оценки, которая включает в себя три показателя: новизну, релевантность и важность. Отдельные баллы метрики, превышающие 1.0, масштабируются до диапазона [0,1] перед суммированием.
По торговому запросу, поступающему в технологический слой, с помощью запроса к LLM агент вычисляет оценку новизны, которая обратно коррелирует с временным разрывом между запросом и временной меткой события в памяти, отражая кривую забывания. Срок стабильности частично контролирует скорость распада на разных слоях, указывая на более длительную персистенцию памяти в долговременном слое с более высоким значением стабильности. В контексте торговли годовые отчеты компаний считаются более актуальными по сравнению с ежедневными финансовыми новостями. Следовательно, им присваивается более высокое значение стабильности, и они классифицируются в пределах более глубокого уровня обработки. Эта классификация отражает их расширенную актуальность и влияние на сценарии принятия финансовых решений.
Оценка релевантности количественно определяет косинусное сходство между векторами эмбедингов. Эти векторы являются производными от текстового содержимого события в памяти. Запрос к LLM включает в себя исходные данные, связанные с торговыми запросами и настройкой символов торгового агента.
Модуль принятия решений FinMem эффективно интегрирует операционные результаты из модулей профилирования и памяти для поддержки обоснованных инвестиционных решений. В своих ежедневных торговых решениях FinMem предлагается выбрать одно из трех различных действий для одной конкретной акции с помощью функции проверки текста: «Купить», «Продать» или «Держать». Кроме того, исходные данные и результаты, необходимые для модуля принятия решений FinMem, варьируются между этапами обучения и тестирования.
На этапе обучения FinMem получает доступ к широкому спектру информации из нескольких источников, относящейся ко всему периоду обучения. Когда FinMem получает торговые запросы, содержащие биржевой тикер и дату, а также тексты, связанные с персонажами трейдера, он одновременно инициирует операции наблюдения и обобщения в своей рабочей памяти. FinMem наблюдает за рыночными метками, которые включают ежедневные скорректированные ценовые различия между последовательными днями, указывающие на действия «Купить» или «Продать». Используя эти сигналы об изменении цен, FinMem определяет и приоритизирует топ-K воспоминаний, ранжируя их на основе оценок извлечения из каждого слоя долговременной памяти. Эта процедура позволяет FinMem создавать всесторонние анализы, которые обеспечивают обоснование и глубокий вывод о корреляции между рыночными основными метками и восстановленными воспоминаниями. Благодаря повторяющимся торговым операциям, реакции и событиям памяти со значительным влиянием переходят к более глубокому уровню обработки памяти, сохраняющейся для принятия будущих инвестиционных решений на этапе тестирования.
На этапе тестирования, когда FinMem не может получить доступ к будущим ценовым данным, он полагается на совокупную доходность по сравнению с анализируемым периодом для прогнозирования будущих рыночных тенденций. Чтобы компенсировать отсутствие информации о будущих рыночных ценах, FinMem использует расширенные реакции, полученные из непосредственных реакций в качестве дополнительных меток. Сталкиваясь с конкретным торговым запросом, FinMem интегрирует информацию из различных источников, включая историческую совокупную доходность, результаты расширенных размышлений и топ-K восстановленных воспоминаний. Такой комплексный подход позволяет FinMem принимать обоснованные торговые решения.
Следует отметить, что FinMem генерирует исполняемые действия исключительно в модуле непосредственной реакции на этапе тестирования. Так как направление торговли ориентируется на фактический ценовой тренд, то на этапе обучения FinMem не принимаются инвестиционные решения. Вместо этого этот этап посвящен накоплению торгового опыта путем сравнения рыночных тенденций с входящими финансовыми сообщениями из нескольких источников. Кроме того, на этом этапе FinMem заполняет модуль памяти, обогащенный обширной базой знаний, тем самым развивая свои возможности для самостоятельного принятия решений в будущей торговой деятельности.
Авторская визуализация фреймворка FinMem представлена ниже.
Реализация средствами MQL5
После рассмотрения теоретических аспектов фреймворка FinMem мы переходим к реализации предложенных подходов средствами MQL5. И здесь сразу надо сказать, что в данном случае наша реализация будет, наверное, максимально отличаться от авторского решения по сравнению со всеми предыдущими работами. И прежде всего это связано с использованием в авторском решении предварительно обученной LLM, которая составляет основу фреймворка. Поэтому мы возьмем за основу предложенные авторами фреймворка подходы обработки информации и посмотрим на их реализацию с другой стороны.
Модуль памяти
А начнем мы роботу с построения модуля памяти. В авторской реализации фреймворка FinMem, благодаря использованию LLM, память Агента заполняется текстовым описанием обобщения событий, полученных из различных источников, и их эмбедингами. Мы же в своей реализации не будем использовать LLM. И, соответственно, будем работать только с числовой информацией, получаемой непосредственно из терминала.
Далее нам предстоит задуматься о построении многоуровневой памяти с различными скоростями распада на отдельных уровнях. И тут же возникает вопрос приоритизации анализируемых событий. При анализе только текущего состояния среды, представленного данными ценового движения и различных технических индикаторов довольно сложно определить приоритеты двух последующих состояний.
В ходе рассмотрения различных вариантов было принято решение использовать рекуррентные блоки для организации уровней памяти. А чтобы эмитировать различные скорости забывания, мы использовали различные архитектуры рекуррентных блоков для отдельных уровней памяти, которые в силу архитектурных решений имеют различные степени распада. При этом мы не стали искусственно приоритизировать различные состояния окружающей среды. Вместо этого, мы будем обрабатывать исходные данные одинаково всеми слоями памяти, а приоритеты предлагаем выучить модели.
Сопоставление данных различных уровней памяти реализуем с помощью блока кросс-внимания.
Предложенный выше алгоритм мы построим в рамках объекта CNeuronMemory, структура которого представлена ниже.
class CNeuronMemory : public CNeuronRelativeCrossAttention { protected: CNeuronLSTMOCL cLSTM; CNeuronMambaOCL cMamba; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronMemory(void){}; ~CNeuronMemory(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMemory; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
В нашей библиотеке реализовано 2 рекуррентных блока: LSTM и Mamba. Ими мы и воспользуемся для организации уровней памяти. Для сопоставления результатов их работы будем использовать модуль относительного кросс-внимания. Однако, с целью уменьшения количества внутренних объектов нашего блока внимания мы воспользуемся объектом кросс-внимания в качестве родительского класса.
Объекты внутренних слоев памяти мы объявляем статично, что позволяет нам оставить пустыми конструктор и деструктор класса. А инициализация всех объявленных и унаследованных объектов, как обычно, осуществляется в методе Init.
bool CNeuronMemory::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, window, window_key, units_count, heads, window, units_count, optimization_type, batch)) return false;
В параметрах метода мы видим уже знакомые нам константы, используемые в одноименном методе родительского класса. Однако в данном случае мы исключаем параметры второго источника исходных данных. Ведь наш новый объект работает с одним источником данных. А при вызове одноименного метода родительского класса в параметрах второго источника данных мы повторяем значения основного потока информации.
После успешного выполнения операций родительского метода мы инициализируем рекуррентные объекты слоев памяти с аналогичными параметрами источника данных.
if(!cLSTM.Init(0, 0, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cMamba.Init(0, 1, OpenCL, iWindow, 2 * iWindow, iUnits, optimization, iBatch)) return false; //--- return true; }
И в завершении работы метода мы возвращаем логический результат выполнения операций метода вызывающей программе.
Следующим шагом мы построим алгоритм прямого прохода feedForward. Здесь все довольно просто. В параметрах метода получаем указатель на объект исходных данных, который передаем в одноименные методы внутренних слоев памяти.
bool CNeuronMemory::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cLSTM.FeedForward(NeuronOCL)) return false; if(!cMamba.FeedForward(NeuronOCL)) return false;
А затем сопоставим результаты работы рекуррентных объектов средствами родительского класса кросс-внимания и вернем логический результат выполнения операций вызывающей программе.
return CNeuronRelativeCrossAttention::feedForward(cMamba.AsObject(), cLSTM.getOutput());
}
Немного сложнее построен алгоритм распределения градиентов ошибки calcInputGradients. Здесь нам предстоит передать погрешность от двух информационных потоков на уровень объекта исходных данных, указатель которого мы получаем в параметрах метода.
bool CNeuronMemory::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В теле метода мы сначала проверяем актуальность полученного указателя на объект исходных данных. Ведь в противном случае передача градиента ошибки становится невозможной.
И в случае успешного прохождения контрольного блока, распределяем градиент ошибки между внутренними слоями памяти средствами родительского объекта.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cMamba.AsObject(), cLSTM.getOutput(), cLSTM.getGradient(), (ENUM_ACTIVATION)cLSTM.Activation())) return false;
Далее мы сначала спускаем градиент ошибки до уровня исходных данных от одного слоя памяти.
if(!NeuronOCL.calcHiddenGradients(cMamba.AsObject())) return false;
А затем осуществляем подмену указателя на буфер градиентов объекта исходных данных свободным буфером и проводим данные по второму информационному потоку.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cMamba.getPrevOutput(), false)) return false; if(!NeuronOCL.calcHiddenGradients(cLSTM.AsObject())) return false; if(!NeuronOCL.SetGradient(temp, false) || !SumAndNormilize(temp, cMamba.getPrevOutput(), temp, iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
Теперь нам остается суммировать данные двух информационных потоков и вернуть указатели на буферы данных в исходное состояния. А по завершении всех операций мы проинформируем вызывающую программу о ходе выполнения операций и завершим работу метода.
Алгоритм метода обновления параметров модели updateInputWeights не выделяется какими-либо сложными моментами. И я предлагаю Вам ознакомиться с ним самостоятельно. Полный код представленного модуля памяти и всех его методов Вы можете найти во вложении. Ну а мы движемся далее.
Построение фреймворка FinMem
Следующим этапом нашей работы является реализация комплексного алгоритма фреймворка FinMem, который мы построим в рамках объекта CNeuronFinMem. Структура нового класса представлена ниже.
class CNeuronFinMem : public CNeuronRelativeCrossAttention { protected: CNeuronTransposeOCL cTransposeState; CNeuronMemory cMemory[2]; CNeuronRelativeCrossAttention cCrossMemory; CNeuronRelativeCrossAttention cMemoryToAccount; CNeuronRelativeCrossAttention cActionToAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinMem(void) {}; ~CNeuronFinMem(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint accoiunt_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinMem; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Как можно заметить, в структуре нового объекта объявлено 2 выше представленных модуля памяти и несколько блоков кросс-внимания. Их назначение, я думаю, лучше рассмотреть в процессе реализации алгоритмов методов класса.
Все внутренние объекты были объявлены статично, что позволяет оставить пустыми конструктор и деструктор класса. А инициализации всех объявленных и унаследованных объектов осуществляется в методе Init.
Здесь стоит обратить внимание, что в данном случае мы создаем объект Агента. Он анализирует исходные данные и возвращает некоторый вектор действий, что и отражается на параметрах инициализации объекта. Поэтому в константы метода инициализации помимо привычной информации о тензоре описания состояния окружающей среды мы добавляем размерность вектора описания состояния счета (account_descr) и пространства действий (nactions).
Кроме того, имитируя работу предложенного авторами фреймворка FinMem модуля расширенной реакции, мы планируем рекуррентно использовать информацию о предпринятых ранее агентом действиях в сопоставлении с переходом в новое состояние окружающей среды. Поэтому в качестве родительского класса был избран модуль кросс-внимания.
bool CNeuronFinMem::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint account_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, nactions / 2, window_key, 2, heads, window, units_count, optimization_type, batch)) return false;
В теле метода инициализации объекта мы, по уже сложившейся традиции, сначала вызываем одноименный метод родительского класса. Как было сказано выше, это объект кросс-внимания. По основному потоку информации он получает вектор предыдущих действий агента, который мы разделили на 2 равных блока (предположительно данные операций покупки и продажи). А по второму потоку информации мы планируем подавать обработанные данные о текущем состоянии окружающей среды.
После успешного выполнения операций родительского класса мы переходим к инициализации вновь объявленных объектов. И первым мы инициализируем объект транспонирования данных описания состояния окружающей среды.
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false;
Напомню, что на вход модели мы получаем описания состояния окружающей среды в разрезе векторов описания отдельных баров. А транспонирования данного тензора позволит нам осуществить анализ в разрезе отдельных унитарных последовательностей.
Воспользовавшись выше указанным свойством, мы используем два модуля памяти для анализа исходных данных в различных проекциях.
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false; index++; if(!cMemory[1].Init(0, index, OpenCL, units_count, window_key, window, heads, optimization, iBatch)) return false;
Результаты анализа, проведенного модулями памяти, агрегируем в блоке кросс-внимания.
index++; if(!cCrossMemory.Init(0, index, OpenCL, window, window_key, units_count, heads, units_count, window, optimization, iBatch)) return false;
Следующий модуль кросс-внимания обогащает информацию описания состояния окружающей среды данными о накопленных прибылях и убытках из вектора состояния счета. Там же содержится временная метка анализируемого состояния.
index++; if(!cMemoryToAccount.Init(0, index, OpenCL, window, window_key, units_count, heads, account_descr, 1, optimization, iBatch)) return false;
И в завершении метода мы инициализируем еще один блок кросс-внимания, который сопоставит последние действия Агента и полученный результат, отраженный в текущем состоянии счета.
index++; if(!cActionToAccount.Init(0, index, OpenCL, nactions / 2, window_key, 2, heads, account_descr, 1, optimization, iBatch)) return false; //--- if(!Clear()) return false; //--- return true; }
После чего очищаем внутренне состояние рекуррентных объектов и возвращаем логический результат выполнения операций вызывающей программе.
Незаметно мы исчерпали объем статьи, но наша работа ещё не завершена. Мы сделаем небольшой перерыв. А в следующей статье доведем нашу реализацию до логического завершения и оценим эффективность реализованных решений на реальных исторических данных.
Заключение
В данной статье мы познакомились с фреймворком FinMem, который представляет собой новый этап в развитии автономных торговых систем. Он объединяет когнитивные принципы и передовые алгоритмы на базе больших языковых моделей. Его многоуровневая память и способность к адаптации в реальном времени позволяют агенту принимать точные и обоснованные инвестиционные решения, даже в условиях нестабильных рынков.
В практической части мы начали реализацию собственного видения предложенных подходов средствами MQL5, исключив использование языковой модели. И в следующей работе мы доведем начатое дело до логического завершения.
Ссылки
- FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Здравствуйте, интересная статья. К сожалению не могу скомпилировать файл Research.mq5 - ругается на строчку if(!CreateDescriptions(actor, critic, critic)) - неверное количество параметров. Не могу сдвинуться дальше(
Добрый день, Из какого каталога загружен файл Research? Здесь действительно много параметров. В данной работе используется только одна модель.
Добрый день, Из какого каталога загружен файл Research? Здесь действительно много параметров. В данной работе используется только одна модель.
По каталогам лазил и уже запутался где взял((
Направьте пожалуйста каким каталогом пользоваться для этой статьи?
По каталогам лазил и уже запутался где взял((
Направьте пожалуйста каким каталогом пользоваться для этой статьи?
Все файлы, относящиеся к этой статье находятся в папке FinMem.
Всячески пробовал, но не вышел на ваши результаты.
Вы уж простите, можно дать правильную инструкцию, что и за чем запускать и какие файлы в каком порядке.
Спасибо.