
Redes neurais em trading: Agente com memória em camadas

Introdução
O volume crescente de dados financeiros exige dos traders não apenas processamento rápido, mas também análise profunda para decisões precisas e oportunas. No entanto, as limitações da memória humana, da atenção e da capacidade de lidar com grandes quantidades de informação podem levar à perda de eventos críticos ou a conclusões equivocadas. Isso torna necessária a criação de agentes de trading autônomos, capazes de integrar dados dispersos com eficiência, rapidez e alta precisão. Uma dessas soluções foi proposta no trabalho "FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design".
O framework FinMem proposto é um agente inovador baseado em grandes modelos de linguagem (LLM), que oferece um sistema de memória em camadas único. Essa abordagem permite trabalhar de forma eficaz com dados de diferentes naturezas e relevância temporal. O módulo de memória FinMem é dividido em memória de trabalho, voltada para o processamento de dados de curto prazo, e memória de longo prazo estratificada, onde as informações são classificadas de acordo com sua importância e atualidade. Por exemplo, notícias diárias e oscilações de mercado de curto prazo são analisadas em um nível superficial, enquanto relatórios e pesquisas com impacto duradouro são direcionados às camadas mais profundas da memória. Essa estrutura permite ao agente priorizar informações, concentrando-se nos dados mais relevantes.
O módulo de perfilamento FinMem permite adaptar o agente ao contexto profissional e às condições de mercado. Levando em conta as preferências individuais e o perfil de risco do usuário, o agente ajusta sua estratégia para garantir a máxima eficiência. O módulo de tomada de decisão integra dados atuais do mercado e memórias armazenadas, gerando estratégias bem elaboradas. Isso permite considerar tanto tendências de curto prazo quanto padrões de longo prazo. Essa abordagem inspirada na cognição torna FinMem capaz de memorizar e utilizar eventos-chave do mercado, aumentando a precisão e a adaptabilidade das decisões tomadas.
Os resultados de numerosos experimentos apresentados no trabalho original demonstraram que FinMem supera outros modelos de trading autônomo em termos de eficiência. Mesmo sendo treinado com dados limitados, o agente mostra desempenho notável no processamento de informações e na tomada de decisões de investimento. Graças à sua capacidade única de regular a carga cognitiva, FinMem processa um grande volume de eventos sem comprometer a qualidade da análise. Por exemplo, ele pode analisar simultaneamente dezenas de sinais de mercado independentes, organizá-los por importância e tomar decisões fundamentadas mesmo em situações com tempo limitado.
Outro aspecto importante do FinMem é sua capacidade de aprendizado e adaptação em tempo real a novos dados. Isso permite ao agente não apenas lidar com as tarefas atuais, mas também aprimorar continuamente suas estratégias de trading, reagindo a mudanças nas condições de mercado. Essa combinação de flexibilidade cognitiva e poder tecnológico torna FinMem um avanço significativo na área do trading autônomo. O FinMem representa uma solução moderna que integra princípios cognitivos e tecnologias de ponta para operar com sucesso em mercados financeiros complexos e voláteis.
A arquitetura do FinMem
O framework FinMem inclui três módulos principais:
- perfilamento;
- memória;
- tomada de decisão.
O módulo de perfilamento permite ao FinMem desenvolver um caráter dinâmico do agente, projetado especialmente para navegar de forma eficaz pela complexa dinâmica dos mercados financeiros. O caráter dinâmico do FinMem é composto por dois elementos principais: uma base profissional de conhecimento fundamental, semelhante à de um especialista em trading, e um agente com três diferentes inclinações ao risco de investimento.
O primeiro componente abrange dois tipos de informação: uma introdução aos setores de mercado mais relevantes à empresa cujas ações serão negociadas pelo FinMem, e um resumo dos indicadores financeiros históricos do respectivo ticker, abrangendo todo o período de treinamento. Antes de iniciar operações com ações de uma nova empresa, o FinMem acessa e atualiza esses dados setoriais e históricos financeiros a partir de um banco de dados no servidor. Essa configuração profissional do conhecimento restringe as informações memorizadas a eventos diretamente ligados às tarefas específicas de trading.
O segundo componente do design do FinMem envolve três diferentes perfis de inclinação ao risco:
- busca por risco,
- aversão ao risco,
- perfil de risco auto-adaptável.
No modo de busca por risco, o FinMem adota uma abordagem agressiva com alto retorno, enquanto o modo de "aversão ao risco" redireciona a operação para uma estratégia conservadora com menor exposição. Uma característica distintiva do FinMem é sua capacidade de alternar dinamicamente entre essas configurações de risco em resposta às condições atuais do mercado. Em especial, ele altera sua inclinação ao risco quando a rentabilidade acumulada cai abaixo de zero por um curto período de tempo. Essa estrutura flexível funciona como um mecanismo de proteção, atenuando quedas prolongadas em ambientes de mercado turbulentos.
Na fase inicial de treinamento, o FinMem é ajustado com base nas preferências de risco escolhidas, cada uma acompanhada de explicações textuais detalhadas através de instruções para o LLM. Essas instruções determinam como o FinMem processa mensagens recebidas e define suas ações subsequentes de acordo com a inclinação ao risco atribuída. O sistema mantém um catálogo de todas as inclinações ao risco e suas descrições detalhadas em um backlog, o que permite uma adaptação fácil a diferentes ações através da troca entre esses perfis de risco conforme necessário.
A configuração dinâmica de perfis no módulo de perfilamento do FinMem fornece conhecimento subjetivo e profissional, além de uma escolha flexível de inclinação ao risco. Isso oferece um contexto importante para filtrar e extrair informações relevantes à operação, assim como eventos associados à memória, melhorando assim a precisão das inferências e a adaptabilidade às mudanças nas condições do mercado.
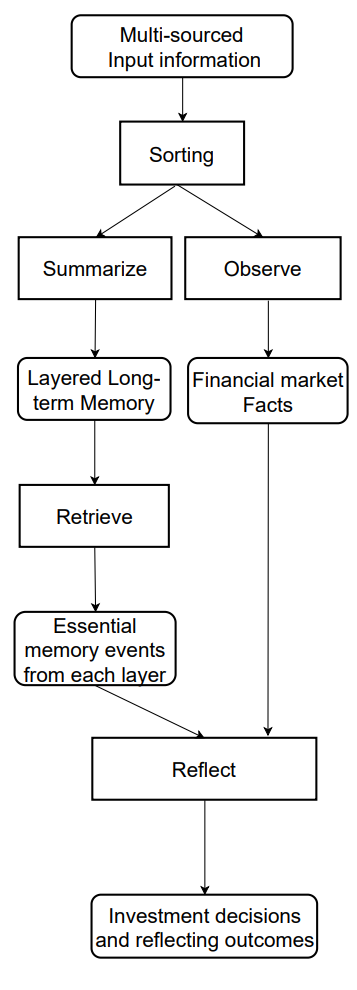
O módulo de memória do FinMem emula o sistema cognitivo de um trader para que ele possa processar informações financeiras hierárquicas de maneira eficaz e priorizar mensagens críticas para tomar decisões de investimento com alta qualidade. Além disso, ele regula de forma flexível o volume de memória, permitindo que o agente lide com uma gama mais ampla de eventos ao longo de um período mais extenso de recuperação de informações. O módulo de memória do FinMem inclui memória de trabalho e memória de longo prazo com capacidade de processamento em camadas, sendo ativado por uma solicitação de investimento específica.
A memória de trabalho se refere às funções do sistema cognitivo humano para armazenamento temporário e diversas operações. Os autores do framework incorporaram esse conceito ao desenvolver o módulo de memória do FinMem, criando um espaço central de trabalho para tomada de decisões fundamentadas. Diferente da memória de trabalho humana, que comporta no máximo sete eventos, mais ou menos dois, o FinMem tem a capacidade de expansão conforme as exigências específicas. A memória de trabalho do FinMem, projetada para transformar dados financeiros em ações de trading, inclui três operações-chave: generalização, observação e reflexão.
O FinMem utiliza dados do mercado externo para obter ideias e sentimentos de investimento críticos, adaptados a solicitações específicas de trading com ações. O sistema comprime o texto original em um parágrafo compacto, porém informativo, aumentando assim a eficiência de processamento do FinMem. Ele extrai e resume de forma eficaz os dados e sentimentos relevantes para a tomada de decisões de investimento. Em seguida, o FinMem direciona essas conclusões para a camada apropriada dentro de sua arquitetura de memória de longo prazo, escolhendo a camada com base na sensibilidade temporal da informação.
Ao iniciar o mesmo tipo de solicitação, o FinMem executa uma operação de observação para reunir fatos de mercado. As informações disponíveis ao FinMem variam entre as etapas de treinamento e de teste. Durante o treinamento, o FinMem tem acesso a dados completos sobre os preços das ações no período especificado. Após receber solicitações de trading contendo o ticker e a data da ação, o FinMem se concentra na diferença diária ajustada entre os preços de fechamento, comparando o preço do dia seguinte com o preço do dia atual. Essas variações de preço são usadas como referências de mercado. Especificamente, uma queda no preço indica uma ação de "Venda", enquanto um aumento ou estabilidade no preço indica uma ação de "Compra".
Na fase de teste, em determinado momento, o FinMem perde o acesso a dados futuros de preços. Seu foco passa então para a análise dos movimentos históricos de preços das ações, com base em uma avaliação retrospectiva da rentabilidade acumulada durante o período analisado. Essa etapa, caracterizada pela ausência de fundamentos de mercado previsíveis, representa uma avaliação crítica do desenvolvimento do FinMem. Ela verifica se o sistema estabeleceu de forma adequada conexões lógicas entre tendências nos preços das ações e diversas fontes de informação financeira, como notícias, relatórios e indicadores. Essa fase é essencial para avaliar a capacidade do FinMem de desenvolver autonomamente suas estratégias de trading para tarefas futuras, utilizando sua própria análise e interpretação de dados históricos.
Existem dois tipos de reação: a imediata e a ampliada. A reação imediata é ativada ao receber uma solicitação diária de trading para um determinado ticker. Utilizando um LLM e instruções específicas, o agente combina indicadores de mercado e os eventos top-K classificados de cada camada da memória de longo prazo. Os indicadores de mercado são derivados dos resultados das operações de observação e variam entre as fases de treinamento e de teste. Durante os testes, esse processo gera três tipos de resultado: a direção da operação ("Comprar", "Vender" ou "Manter"), a justificativa dessa decisão e os eventos de memória mais influentes, junto com seus identificadores em cada nível sobre os quais a decisão foi baseada. Na fase de treinamento, não é necessário indicar a direção da operação, pois o FinMem já está informado sobre os movimentos futuros das ações. Os eventos de memória classificados como top-K encapsulam conclusões e sentimentos-chave derivados de mensagens de entrada relacionadas a investimentos, e tudo isso é resumido de forma avançada pelo FinMem.
A reação ampliada reavalia os resultados imediatos das ações do agente para um ticker dentro de um intervalo de rastreamento definido. Ela inclui dados como tendências nos preços das ações, rentabilidade das operações e justificativas baseadas em várias reflexões imediatas. Enquanto a reação imediata permite executar trades diretos e registrar feedback atual, a reação ampliada resume as tendências de mercado e reavalia a rentabilidade acumulada recente dos investimentos. Essa reação ampliada é posteriormente armazenada em uma camada profunda da memória de longo prazo para destacar sua criticidade.
A memória de longo prazo do FinMem organiza dados financeiros analíticos hierárquicos em uma estrutura estratificada. O FinMem utiliza uma estrutura de memória em camadas para lidar com diferentes sensibilidades temporais inerentes aos diversos tipos de dados financeiros. Essa estrutura classifica as conclusões generalizadas de acordo com sua atualidade e taxa de esquecimento. As conclusões são geradas através da operação de generalização da memória de trabalho. Eventos destinados a camadas mais profundas da memória recebem uma taxa de esquecimento menor, indicando retenção por um período mais longo, enquanto os dados posicionados nas camadas mais superficiais recebem uma taxa de esquecimento maior, o que indica retenção de curto prazo. Cada evento de memória pode pertencer a apenas uma camada de memória.
Após receber uma solicitação de investimento, o FinMem extrai os eventos de memória top-K mais relevantes de cada camada e os direciona ao componente de reflexão imediata da memória de trabalho. Esses eventos são selecionados em ordem decrescente de pontuação, que é baseada em três critérios: novidade, relevância e importância. As pontuações individuais das métricas que excedem 1.0 são ajustadas para o intervalo [0,1] antes da soma.
Quando um pedido de trading é recebido na camada tecnológica, com uma consulta ao LLM, o agente calcula a pontuação de novidade, que está inversamente correlacionada com o intervalo temporal entre a solicitação e o carimbo de data/hora do evento na memória, refletindo a curva de esquecimento. O prazo de estabilidade controla parcialmente a taxa de esquecimento em diferentes camadas, indicando uma persistência de memória mais longa nas camadas profundas da memória de longo prazo quando o valor de estabilidade é mais alto. No contexto do trading, relatórios anuais de empresas são considerados mais relevantes do que notícias financeiras diárias. Assim, recebem uma pontuação de estabilidade mais alta e são classificados dentro de um nível mais profundo de processamento. Essa classificação reflete sua relevância estendida e impacto sobre os cenários de tomada de decisão financeira.
A pontuação de relevância é calculada com base na similaridade cosseno entre os vetores de incorporação. Esses vetores derivam do conteúdo textual do evento armazenado na memória. A consulta ao LLM inclui os dados brutos relacionados aos pedidos de trading e à configuração dos perfis do agente de negociação.
O módulo de tomada de decisão do FinMem integra de maneira eficaz os resultados operacionais dos módulos de perfilamento e memória para apoiar decisões de investimento fundamentadas. Em suas decisões diárias de trading, o FinMem propõe a escolha de uma entre três ações distintas para uma determinada ação com base em uma função de verificação textual: "Comprar", "Vender" ou "Manter". Além disso, os dados brutos e os resultados exigidos pelo módulo de tomada de decisão do FinMem variam entre as fases de treinamento e de teste.
Durante a fase de treinamento, o FinMem tem acesso a um amplo espectro de informações de várias fontes, abrangendo todo o período de aprendizado. Quando o FinMem recebe solicitações de trading contendo um ticker de bolsa e uma data, além de textos ligados ao perfil do trader, ele inicia simultaneamente operações de observação e generalização em sua memória de trabalho. O FinMem observa os rótulos de mercado, que incluem diferenças ajustadas de preço diário entre dias consecutivos, indicando ações de "Comprar" ou "Vender". Utilizando esses sinais de variação de preços, o FinMem identifica e prioriza os eventos top-K da memória, classificando-os com base nas pontuações de recuperação extraídas de cada camada da memória de longo prazo. Essa procedimento permite ao FinMem criar análises completas que fundamentam e geram inferências profundas sobre a correlação entre os rótulos principais do mercado e as memórias recuperadas. Graças às operações de trading recorrentes, reações e eventos de memória com impacto significativo são promovidos a camadas mais profundas da memória de longo prazo, permanecendo armazenados para apoiar decisões de investimento futuras na fase de teste.
Na fase de teste, quando o FinMem não tem acesso a dados futuros de preços, ele se baseia na rentabilidade acumulada ao longo do período analisado para prever tendências futuras do mercado. Para compensar a ausência de informações sobre os preços futuros do mercado, o FinMem utiliza reações ampliadas derivadas das reações imediatas como rótulos adicionais. Ao lidar com uma solicitação de trading específica, o FinMem integra informações de diversas fontes, incluindo rentabilidade histórica acumulada, resultados de reflexões ampliadas e os top-K eventos de memória recuperados. Essa abordagem abrangente permite que o FinMem tome decisões de trading fundamentadas.
É importante observar que o FinMem gera ações executáveis exclusivamente no módulo de reação imediata durante a fase de teste. Como a direção do trade se baseia na tendência real dos preços, o FinMem não toma decisões de investimento na fase de treinamento. Em vez disso, essa etapa é dedicada ao acúmulo de experiência operacional por meio da comparação de tendências de mercado com mensagens financeiras recebidas de várias fontes. Além disso, durante essa fase, o FinMem preenche seu módulo de memória com uma base de conhecimento extensa, desenvolvendo assim sua capacidade de tomar decisões de forma autônoma em atividades futuras de trading.
A visualização original do framework FinMem é apresentada a seguir.
Implementação com MQL5
Após abordarmos os aspectos teóricos do framework FinMem, passamos à implementação das abordagens propostas usando MQL5. E aqui é preciso destacar de imediato que, neste caso, nossa implementação será provavelmente a mais distinta da solução original em comparação com todos os trabalhos anteriores. Isso se deve principalmente ao uso, na versão original, de uma LLM previamente treinada, que constitui o núcleo do framework. Por isso, adotaremos como base as abordagens de processamento de informação propostas pelos autores do framework e analisaremos sua implementação sob outra perspectiva.
Módulo de memória
Começamos o robô com a construção do módulo de memória. Na implementação original do framework FinMem, graças ao uso de LLM, a memória do Agente é preenchida com descrições textuais de generalizações de eventos extraídos de diferentes fontes, além de suas incorporações. Já na nossa implementação, não utilizaremos LLM. Consequentemente, trabalharemos apenas com informações numéricas obtidas diretamente do terminal.
Em seguida, precisamos refletir sobre a construção de uma memória em camadas com diferentes velocidades de esquecimento em cada nível. E surge imediatamente a questão da priorização dos eventos analisados. Ao analisar apenas o estado atual do ambiente, representado por dados de movimentação de preços e vários indicadores técnicos, é bastante difícil determinar a prioridade de dois estados futuros.
Após considerar diferentes alternativas, foi tomada a decisão de usar blocos recorrentes para estruturar os níveis da memória. E, para simular diferentes velocidades de esquecimento, utilizamos arquiteturas distintas de blocos recorrentes para os diferentes níveis de memória, que, por suas características estruturais, apresentam diferentes graus de degradação. Ao mesmo tempo, optamos por não priorizar artificialmente os diferentes estados do ambiente. Em vez disso, processaremos os dados brutos da mesma forma em todas as camadas de memória, e deixaremos que a própria rede aprenda os pesos de prioridade.
A correspondência entre os dados de diferentes níveis da memória será realizada por meio de um bloco de atenção cruzada.
O algoritmo descrito acima será construído dentro do objeto CNeuronMemory, cuja estrutura é apresentada a seguir.
class CNeuronMemory : public CNeuronRelativeCrossAttention { protected: CNeuronLSTMOCL cLSTM; CNeuronMambaOCL cMamba; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronMemory(void){}; ~CNeuronMemory(void){}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMemory; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Nossa biblioteca implementa dois blocos recorrentes: LSTM e Mamba. São esses que utilizaremos para organizar os níveis da memória. Para cruzar os resultados de cada um, utilizaremos um módulo de atenção cruzada relativa. Contudo, com o objetivo de reduzir a quantidade de objetos internos no bloco de atenção, faremos uso do objeto de atenção cruzada como classe base.
Os objetos das camadas internas da memória serão declarados estaticamente, o que nos permite manter o construtor e o destrutor da classe vazios. A inicialização de todos os objetos declarados e herdados, como de costume, será realizada no método Init.
bool CNeuronMemory::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, window, window_key, units_count, heads, window, units_count, optimization_type, batch)) return false;
Nos parâmetros do método, vemos constantes já conhecidas, usadas no método homônimo da classe base. Entretanto, neste caso, excluímos os parâmetros do segundo conjunto de dados de entrada, pois nosso novo objeto trabalha com uma única fonte de dados. E, ao invocar o método da classe base, nos parâmetros do segundo conjunto de dados, simplesmente repetimos os valores do fluxo principal de informação.
Após a execução bem-sucedida das operações do método da classe base, inicializamos os objetos recorrentes das camadas de memória com os mesmos parâmetros da fonte de dados.
if(!cLSTM.Init(0, 0, OpenCL, iWindow, iUnits, optimization, iBatch)) return false; if(!cMamba.Init(0, 1, OpenCL, iWindow, 2 * iWindow, iUnits, optimization, iBatch)) return false; //--- return true; }
E, ao final do método, retornamos o resultado lógico da execução das operações para o programa que chamou o método.
No passo seguinte, construiremos o algoritmo de propagação para frente feedForward. Aqui, tudo é bastante direto. Nos parâmetros do método, recebemos um ponteiro para o objeto de dados brutos, que será repassado para os métodos homônimos das camadas internas de memória.
bool CNeuronMemory::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cLSTM.FeedForward(NeuronOCL)) return false; if(!cMamba.FeedForward(NeuronOCL)) return false;
Em seguida, comparamos os resultados dos objetos recorrentes utilizando os recursos da classe pai de atenção cruzada e retornamos o resultado lógico da execução das operações ao programa que chamou o método.
return CNeuronRelativeCrossAttention::feedForward(cMamba.AsObject(), cLSTM.getOutput());
}
O algoritmo de distribuição dos gradientes de erro, calcInputGradients, é um pouco mais complexo. Aqui, precisamos transmitir os erros de dois fluxos de informação até o nível do objeto de dados brutos, cujo ponteiro é recebido nos parâmetros do método.
bool CNeuronMemory::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
No corpo do método, verificamos inicialmente se o ponteiro para o objeto de dados brutos é válido. Afinal, caso contrário, a transmissão do gradiente de erro não é possível.
E, ao passar com sucesso pelo bloco de verificação, distribuímos o gradiente de erro entre as camadas internas de memória utilizando os recursos da classe pai.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cMamba.AsObject(), cLSTM.getOutput(), cLSTM.getGradient(), (ENUM_ACTIVATION)cLSTM.Activation())) return false;
Depois, realizamos a propagação do gradiente de erro até o nível dos dados brutos a partir de uma das camadas de memória.
if(!NeuronOCL.calcHiddenGradients(cMamba.AsObject())) return false;
Em seguida, trocamos o ponteiro do buffer de gradientes do objeto de dados brutos por um buffer livre e propagamos os dados pelo segundo fluxo de informação.
CBufferFloat *temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(cMamba.getPrevOutput(), false)) return false; if(!NeuronOCL.calcHiddenGradients(cLSTM.AsObject())) return false; if(!NeuronOCL.SetGradient(temp, false) || !SumAndNormilize(temp, cMamba.getPrevOutput(), temp, iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
Agora, basta somar os dados dos dois fluxos e restaurar os ponteiros dos buffers ao estado original. Após concluir todas as operações, informamos o programa que chamou o método sobre o andamento das execuções e encerramos o método.
O algoritmo do método de atualização dos parâmetros do modelo, updateInputWeights, não apresenta nenhuma dificuldade particular. E deixo aqui o convite para que você explore esse método por conta própria. O código completo do módulo de memória apresentado e todos os seus métodos estão disponíveis no anexo. E agora seguimos em frente.
Construção do framework FinMem
A próxima etapa do nosso trabalho é a implementação do algoritmo completo do framework FinMem, que será estruturado no objeto CNeuronFinMem. A estrutura da nova classe é apresentada a seguir.
class CNeuronFinMem : public CNeuronRelativeCrossAttention { protected: CNeuronTransposeOCL cTransposeState; CNeuronMemory cMemory[2]; CNeuronRelativeCrossAttention cCrossMemory; CNeuronRelativeCrossAttention cMemoryToAccount; CNeuronRelativeCrossAttention cActionToAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinMem(void) {}; ~CNeuronFinMem(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint accoiunt_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinMem; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Como pode ser observado, a estrutura do novo objeto declara os dois módulos de memória descritos acima, além de vários blocos de atenção cruzada. O papel de cada um será mais bem compreendido durante a implementação dos métodos da classe.
Todos os objetos internos foram declarados de forma estática, permitindo manter vazios tanto o construtor quanto o destrutor da classe. A inicialização de todos os objetos declarados e herdados será realizada dentro do método Init.
Aqui vale destacar que estamos criando o objeto do Agente. Ele analisa os dados brutos e retorna um vetor de ações, o que se reflete nos parâmetros de inicialização do objeto. Por isso, além das informações habituais sobre o tensor que descreve o estado do ambiente, adicionamos às constantes do método de inicialização a dimensionalidade do vetor de descrição do saldo da conta (account_descr) e do espaço de ações (nactions).
Além disso, ao imitar o funcionamento do módulo de reação ampliada proposto pelos autores do framework FinMem, planejamos utilizar de forma recorrente as informações sobre ações anteriores realizadas pelo agente, em comparação com a transição para um novo estado do ambiente. Por isso, escolhemos como classe pai o módulo de atenção cruzada.
bool CNeuronFinMem::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint account_descr, uint nactions, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, nactions / 2, window_key, 2, heads, window, units_count, optimization_type, batch)) return false;
No corpo do método de inicialização do objeto, como já é tradição, chamamos primeiro o método homônimo da classe pai. Como dito anteriormente, trata-se de um objeto de atenção cruzada. Pelo fluxo principal de informação, ele recebe o vetor das ações anteriores do agente, que dividimos em dois blocos iguais (presumivelmente dados de operações de compra e venda). Já pelo segundo fluxo de informação, planejamos fornecer os dados processados sobre o estado atual do ambiente.
Após a execução bem-sucedida das operações da classe pai, passamos à inicialização dos novos objetos declarados. E o primeiro a ser inicializado é o objeto de transposição dos dados de descrição do estado do ambiente.
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false;
Vale lembrar que o modelo recebe como entrada as descrições do estado do ambiente sob a forma de vetores correspondentes a barras individuais. A transposição desse tensor nos permitirá realizar a análise por meio de sequências unitárias distintas.
Aproveitando essa propriedade mencionada, utilizamos dois módulos de memória para analisar os dados brutos sob diferentes projeções.
index++; if(!cMemory[0].Init(0, index, OpenCL, window, window_key, units_count, heads, optimization, iBatch)) return false; index++; if(!cMemory[1].Init(0, index, OpenCL, units_count, window_key, window, heads, optimization, iBatch)) return false;
Os resultados da análise realizada pelos módulos de memória são agregados no bloco de atenção cruzada.
index++; if(!cCrossMemory.Init(0, index, OpenCL, window, window_key, units_count, heads, units_count, window, optimization, iBatch)) return false;
O módulo seguinte de atenção cruzada enriquece as informações de descrição do ambiente com os dados de lucros e perdas acumulados, extraídos do vetor de estado da conta. Nesse mesmo local, também está presente o carimbo de tempo do estado analisado.
index++; if(!cMemoryToAccount.Init(0, index, OpenCL, window, window_key, units_count, heads, account_descr, 1, optimization, iBatch)) return false;
E, por fim, inicializamos outro bloco de atenção cruzada que irá correlacionar as últimas ações do Agente com o resultado obtido, refletido no estado atual da conta.
index++; if(!cActionToAccount.Init(0, index, OpenCL, nactions / 2, window_key, 2, heads, account_descr, 1, optimization, iBatch)) return false; //--- if(!Clear()) return false; //--- return true; }
Depois disso, limpamos o estado interno dos objetos recorrentes e retornamos o resultado lógico da execução das operações ao programa chamador.
Sem perceber, chegamos ao fim do espaço deste artigo, mas nosso trabalho ainda não terminou. Faremos uma pequena pausa. E na próxima parte, levaremos nossa implementação à sua conclusão lógica e avaliaremos a eficácia das soluções implementadas com base em dados históricos reais.
Considerações finais
Neste artigo, conhecemos o framework FinMem, que representa uma nova etapa na evolução dos sistemas autônomos de trading. Ele combina princípios cognitivos e algoritmos avançados baseados em grandes modelos de linguagem. Sua memória em camadas e a capacidade de adaptação em tempo real permitem ao agente tomar decisões de investimento precisas e fundamentadas, mesmo em mercados instáveis.
Na parte prática, iniciamos a implementação da nossa própria visão das abordagens propostas utilizando os recursos do MQL5, excluindo o uso de modelos de linguagem. E no próximo trabalho, levaremos o que foi iniciado até sua conclusão lógica.
Referências
- FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos com o método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para o treinamento de modelos |
| 4 | Test.mq5 | Expert Advisor | EA para testes do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e arquitetura dos modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código para programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16804
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Olá, artigo interessante. Infelizmente não consigo compilar o arquivo Research.mq5 - a linha if((!CreateDescriptions(actor, critic, critic))) - Número incorreto de parâmetros. Não consigo prosseguir(
Boa tarde, de qual catálogo o arquivo Research é carregado? De fato, há muitos parâmetros. Apenas um modelo é usado neste trabalho.
Boa tarde, De qual catálogo o arquivo de pesquisa foi baixado? De fato, há muitos parâmetros aqui. Neste documento, apenas um modelo é usado.
Dei uma olhada nos catálogos e já estou confuso sobre onde o obtive((
Você poderia me indicar qual catálogo usar para este trabalho?
Em catálogos preguiçosamente e já confuso onde eu peguei((
Por favor, me indique qual catálogo usar para este artigo?
Todos os arquivos relacionados a este artigo estão localizados na pasta FinMem.
Tentei todo tipo de coisa, mas não obtive seus resultados.
Desculpe-me, mas você pode dar instruções adequadas sobre o que executar e quais arquivos, em que ordem.
Obrigado.