
Gaußsche Prozesse im maschinellen Lernen: Regressionsmodellierung in MQL5

Einführung
Gauß-Prozesse (GPs) sind ein bayessches, nichtparametrisches Modellierungsverfahren, das im maschinellen Lernen häufig für Regressions- und Klassifizierungsprobleme eingesetzt wird. Im Gegensatz zu vielen herkömmlichen Modellen, die lediglich Punktprognosen liefern, erzeugen GPs eine vollständige Wahrscheinlichkeitsverteilung für die Prognosewerte. Dadurch kann das Modell nicht nur Punktvorhersagen liefern, sondern auch Unsicherheitsschätzungen, die in der Regel als Konfidenzintervalle ausgedrückt werden. Dies ist ein charakteristisches Merkmal des bayesianischen Ansatzes, bei dem Vorwissen mit beobachteten Daten kombiniert wird, um eine Vorhersageverteilung zu erhalten.
GPs gehören zur Klasse der Kernel-Methoden, die Kovarianzfunktionen (oder Kernel) verwenden, um Abhängigkeiten zwischen Daten zu modellieren. Die Möglichkeit, verschiedene Kernel zu kombinieren (z. B. durch Addition oder Multiplikation), ermöglicht eine gewisse Flexibilität bei der Beschreibung möglicher Vorhersagefunktionen. Jeder Kernel verfügt über eigene Hyperparameter, die optimiert werden müssen, um eine maximale Modellgenauigkeit zu erreichen.
In diesem Artikel werden wir den Prognoseprozess unter Verwendung eines Regressionsmodells auf Basis eines GPs eingehend untersuchen und dabei deutlich aufzeigen, wie GPs es ermöglichen, nicht nur genaue Prognosen zu erstellen, sondern auch deren Unsicherheit umfassend zu bewerten.
Was ist ein Gauß-Prozess (GP)?
Aus probabilistischer Sicht ist ein GP ein Zufallsprozess, der eine Wahrscheinlichkeitsverteilung über Funktionen beschreibt. Im Gegensatz zur gewöhnlichen Normalverteilung, die eine einzelne Zufallsvariable beschreibt, definiert die GP eine Menge von Zufallsvariablen, von denen jede endliche Teilmenge einer mehrdimensionalen Normalverteilung folgt.
Im maschinellen Lernen bezeichnet der Begriff „GP“ nichtparametrische Modelle, die keine vordefinierte Funktionsform erfordern (z. B. linear oder polynomisch, wie bei der klassischen Regression). Stattdessen modelliert der GP eine latente Funktion f(x), von der angenommen wird, dass sie die tatsächlichen Abhängigkeiten in den Daten erfasst. Die Funktion f(x) selbst ist jedoch nicht direkt beobachtbar; wir haben lediglich Zugriff auf ihre Werte mit Rauschen an bestimmten x-Punkten. Das GP-Modell basiert auf der Annahme, dass die Verteilung dieser unbekannten Funktion f(x) normalverteilt ist:
f (x)~ N( μ, Σ),
wobei:
- f(x) – latente Funktion, deren Werte an den beobachteten Punkten wir schätzen bzw. rekonstruieren möchten.
- μ – Vektor der Mittelwerte, abhängig von der Prior-Mittelwertfunktion (der der Einfachheit halber oft mit Null angenommen wird),
- Σ – Kovarianzmatrix, deren Elemente durch die Kovarianzfunktion (oder den Kernel) K(x, x') bestimmt werden, die den Grad der Korrelation zwischen den Punkten x und x' angibt.
Der Kerngedanke der GP-Methode besteht darin, die Verteilung von Funktionen durch eine durch einen Kernel definierte Kovarianzstruktur zu modellieren, die wiederum verschiedene Eigenschaften der Funktionen bestimmt, wie beispielsweise ihre Glattheit, Periodizität, Nichtstationarität usw.
Das Hauptziel von GP besteht darin, die latente Funktion f(x) auf der Grundlage eines endlichen Datensatzes D=(X,y) zu rekonstruieren, wobei X eine Menge von Merkmalen und y verrauschte Beobachtungen sind.
Bayesscher Ansatz für GP
GPs nutzen einen bayesschen Ansatz zur statistischen Inferenz, bei dem Vorwissen mit beobachteten Daten kombiniert wird, um probabilistische Vorhersagen zu treffen. Dies unterscheidet GP von vielen anderen Methoden des maschinellen Lernens (wie neuronalen Netzen oder SVMs), da es damit nicht nur Werte vorhersagen, sondern auch deren Unsicherheit abschätzen kann. Dieser Ansatz basiert auf dem Bayes-Theorem:

wobei:
- P(H) – A-priori-Wahrscheinlichkeit: die anfängliche Wahrscheinlichkeit der Hypothese H, die das Vorwissen oder die Annahmen vor der Beobachtung der Daten widerspiegelt,
- P(D|H) – Likelihood: die Wahrscheinlichkeit, die Daten D unter der Hypothese H zu beobachten,
- P(H|D) – A-posteriori-Wahrscheinlichkeit: die Wahrscheinlichkeit der Hypothese H nach Beobachtung der Daten D,
- P(D) – Randwahrscheinlichkeit der Daten (Normierungskonstante), die die Korrektheit der A-posteriori-Verteilung gewährleistet.
Im Zusammenhang mit GP wird der bayessche Ansatz wie folgt angewendet: Die Hypothese H wird als Verteilung über Funktionen f(x) interpretiert, unter der unsere Daten generiert worden sein könnten, und D ist der Trainingsdatensatz (X, y).
Im GP-Kontext nimmt der Satz von Bayes die folgende Form an:
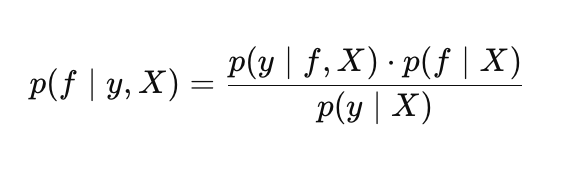
wobei:
- p(f | X) – A-priori-Verteilung über f-Funktionen,
- p(y | f, X) – Likelihood-Funktion,
- p(f | y, X) – A-posteriori-Verteilung über die Funktionen f,
- p(y | X) – marginale Likelihood (Evidenz). Wird zur Optimierung der Hyperparameter von GPs verwendet.
A-priori-Verteilung
Die A-priori-Verteilung beschreibt unsere anfänglichen Annahmen über mögliche Funktionen, bevor wir die Daten sehen. Im Wesentlichen handelt es sich bei der Prior-Verteilung um eine Menge möglicher Funktionen, aus der der GP anhand der Trainingsdaten die am besten geeigneten auswählt. Der Kernel spielt eine entscheidende Rolle bei der Festlegung der Eigenschaften dieser Funktionen. Es gibt viele verschiedene Kernel-Typen, die jeweils für unterschiedliche Arten von Daten geeignet sind, zum Beispiel:
Der RBF-Kernel (Gauß-Kernel) modelliert glatte nichtlineare Funktionen.

wobei:
- σ_f – Amplitude, gibt den Umfang der Schwankungen an (im Code „params.rbf.sigma_f“),
- l – Die Längenskala bestimmt die Abklingrate der Korrelation (params.rbf.length),
- ∥x−x′∥ – Euklidischer Abstand zwischen den Punkten x und x'.
Der lineare Kernel modelliert lineare Abhängigkeiten:
![]()
- x*x' – Skalarprodukt zweier Vektoren,
- σ_l – Skalierung des linearen Trends (params.linear.sigma_l)
Ein periodischer Kernel erfasst zyklische Muster:

- σ_f – Amplitude, legt die Schwankungsbreite fest (params.periodic.sigma_f),
- l – Skalenlänge, bestimmt die Glätte der Schwingungen (params.periodic.length),
- p – Die Periode bestimmt die Wiederholungsfrequenz (params.periodic.period).
Um die A-priori-Verteilung zu veranschaulichen, betrachten wir Stichproben von f(x)-Funktionen, die unter Verwendung verschiedener Kernel erzeugt wurden. Abbildung 1 zeigt Stichproben aus einer A-priori-Verteilung mit einem RBF-Kernel. Die Trajektorien sind glatte nichtlineare Funktionen, die sich in Abhängigkeit von den Kernel-Parametern ändern.

Abb. 1. Stichproben von f-Funktionen aus der A-priori-Verteilung des GPs (RBF-Kernel)
Abbildung 2 zeigt Stichproben aus einer A-priori-Verteilung mit einem linearen Kernel. Die Kurven sind Geraden mit unterschiedlichen Steigungen, was die Fähigkeit des Kernels widerspiegelt, lineare Trends abzubilden.

Abb. 2. Stichproben von f-Funktionen aus der A-priori-Verteilung des GP (linearer Kernel)
Abb. 3 zeigt Beispiele mit einem periodischen Kernel. Die Trajektorien sind zyklische Funktionen mit der Periode p, wodurch sich der Kernel ideal zur Modellierung periodischer Komponenten eignet.

Abb. 3. Stichproben von f-Funktionen aus der A-priori-Verteilung des GP (periodischer Kernel)
Abbildung 4 zeigt die Trajektorien des bekannten Wiener-Prozesses mit der Kovarianzfunktion K(x, x') = min(x, x').

Abb. 4. Stichproben von f-Funktionen aus der A-priori-Verteilung des GP mit der Kovarianzfunktion des Wiener-Prozesses
Die Flexibilität des GP-Modells beruht auf der Möglichkeit, Kernel zu kombinieren (durch Addition oder Multiplikation), wodurch Funktionen mit einer Vielzahl von Eigenschaften modelliert werden können, wie beispielsweise eine Kombination aus linearen und nichtlinearen Trends, periodischen Schwingungen usw. Die Beispiele wurden mit dem Skript „SamplesPrior“ erstellt.Likelihood
Bei GPs beschreibt die Likelihood p(y | f, X) die Wahrscheinlichkeit, die Daten y zu beobachten, wenn eine bestimmte Funktion f aus der Priorverteilung und die Daten X gegeben sind. Sie spielt eine zentrale Rolle bei der bayesschen Inferenz, indem sie die A-priori-Verteilung über Funktionen mit den beobachteten Daten in Verbindung bringt. Für einen Datensatz wird die Likelihood durch die multivariate Normalverteilung bestimmt:

wobei:
- f(x) – Vektor der Werte der verborgenen Funktion an den Punkten X,
- σy² – Varianz des Rauschens,
- ∥y−f(x)∥² – das Quadrat der euklidischen Norm der Differenz zwischen den beobachteten Daten und den Werten der Funktion f.
A-posteriori-Verteilung
Die A-posteriori-Verteilung ist das Ergebnis einer bayesschen Aktualisierung der A-priori-Verteilung unter Berücksichtigung der beobachteten Daten und der Likelihood-Funktion. Sie beschreibt die Verteilung der Werte der latenten Funktion f(x) an neuen Testpunkten X*. Diese Verteilung zeichnet sich dadurch aus, dass der aktualisierte Mittelwert μ* die Prognose darstellt und die Kovarianzmatrix Σ* die Unsicherheit der Prognosen beschreibt.
Die A-priori-Verteilung legt also eine Menge von Funktionen fest, die Likelihood gewichtet diese anhand der Daten, und die A-posteriori-Verteilung liefert die wahrscheinlichste Funktion zusammen mit einer Schätzung der Unsicherheit.
GP-Regression mit gaußscher Likelihood-Funktion
Gaußsche Prozesse ermöglichen in Verbindung mit gaußschem Beobachtungsrauschen die Lösung des Regressionsproblems in analytischer Form unter Verwendung linearer Algebra. Dies vereinfacht die Berechnungen erheblich und macht den Einsatz komplexer numerischer Methoden überflüssig. GP-Modelle eignen sich sowohl für die Modellierung von verrauschten als auch von rauschfreien Daten. Betrachten wir zunächst den idealisierten Fall, in dem die y-Zielwerte die rauschfreien wahren Werte der Funktion sind, d. h., wenn y = f(x) gilt (Interpolationsszenario).
Fall ohne Rauschen: Interpolation
Angenommen, wir haben einen Datensatz D = {(xn, yn) : n = 1 : N}, wobei yn = f(xn) die exakte, rauschfreie Beobachtung der Funktion f am Punkt xn ist. Unsere Aufgabe besteht darin, die Werte der f*-Funktion für den X*-Testdatensatz der Größe N*×d vorherzusagen.
Für X Trainingspunkte und X* Testpunkte ist die gemeinsame A-priori-Verteilung der Funktionswerte f und f* eine multivariate Normalverteilung:

wobei:
- f – Vektor der wahren Werte der versteckten Funktion an den Trainingspunkten,
- f* – Vektor der wahren Werte der versteckten Funktion an den Testpunkten,
- m(X) – Vektor der Mittelwerte der Funktion für die Trainingspunkte (der Einfachheit halber ein Vektor aus Nullen),
- m(X*) – Vektor der Mittelwerte der Funktion für die Testpunkte (zur Vereinfachung ein Vektor aus Nullen),
- K(X,X) – N×N-Kovarianzmatrix zwischen allen Paaren von Trainingspunkten,
- K(X,X*) – N×N*-Kovarianzmatrix zwischen Trainings- und Testpunkten,
- K(X*,X*) – N*×N*-Kovarianzmatrix zwischen allen Paaren von Testpunkten
- N – Anzahl der Eingabedatenpunkte,
- N* – Anzahl der Testdatenpunkte,
- d – Dimension der Eingabedaten (Anzahl der Merkmale).
Da die y-Werte in diesem Fall genau mit f übereinstimmen (y = f), d. h. die Likelihood-Funktion ist eine Deltafunktion, können wir direkt zur bedingten Verteilung von f* gegeben y übergehen. Aufgrund der Eigenschaften der bedingten Verteilungen der multivariaten Normalverteilung lautet die A-posteriori-Verteilung für f* unter Berücksichtigung der beobachteten y-Daten:

wobei:
- μf* – A-posteriori-Mittelwert, die beste Vorhersage der Werte der versteckten Funktion f* an neuen (Test-)Punkten auf der Grundlage der Trainingsdaten,
- Σf* – A-posteriori-Kovarianzmatrix für die Testpunkte. Sie quantifiziert die Unsicherheit bei der Vorhersage der versteckten f*-Funktion.
Rauschen: Regression
In realen Problemstellungen enthalten die y-Daten in der Regel unvorhersehbares Rauschen: y = f(X) + ϵ, wobei ϵ ∼ N(0, σ²) ein gaußsches Rauschen ist. In diesem Fall interpoliert der GP die Trainingsdaten nicht exakt (d. h., er verläuft nicht genau durch jeden Punkt), sondern glättet sie unter Berücksichtigung des zu erwartenden Rauschpegels. Die A-posteriori-Verteilung für verrauschte Daten wird modifiziert, indem die Varianz des Rauschens zu den Diagonalelementen der Kovarianzmatrix der Trainingsdaten addiert wird:

Der Rauschparameter σ ist ein Hyperparameter des Modells und wird zusammen mit den Kernel-Parametern optimiert.
Ein sehr wichtiger Punkt: Durch das Hinzufügen von Rauschen können wir Konfidenzintervalle nicht nur für die latente Funktion f*, sondern auch für neue y*-Beobachtungen vorhersagen. Im Gegensatz zum Fall ohne Rauschen, in dem die Vorhersageverteilungen für f* und y* identisch waren, unterscheiden sich diese Verteilungen nun voneinander. Der Hauptunterschied liegt in ihren Kovarianzmatrizen. Die Σf*-Kovarianz spiegelt die Unsicherheit der latenten Funktion selbst an den Testpunkten wider. Die Kovarianz Σy* umfasst die Unsicherheit der latenten Funktion sowie die Varianz des Beobachtungsrauschens.

- μy* – A-posteriori-Mittelwert für die neue y*-Beobachtung. Es stimmt mit μf* überein, da der Erwartungswert des Rauschens null ist,
- Σy* – A-posteriori-Kovarianz für die neue y*-Beobachtung.
Um zu veranschaulichen, wie sich GPs an Daten anpassen, betrachten wir eine Darstellung von Stichproben von f-Funktionen, die aus der A-posteriori-Verteilung ohne Rauschen generiert wurden. Abbildung 5 zeigt drei f-Funktionen, die nach Einbeziehung von fünf Trainingspunkten unter Verwendung des RBF-Kernels konstruiert wurden.

Abb. 5. Stichproben von f-Funktionen aus der A-posteriori-Verteilung (RBF-Kernel, ohne Rauschen)
Bevor Daten erhoben werden, beschreibt die durch die GP gegebene A-priori-Verteilung eine unendliche Menge von Funktionen. Nachdem wir Trainingsdaten hinzugefügt haben, schränkt die A-posteriori-Verteilung diese Menge ein, sodass nur noch Funktionen übrig bleiben, die genau durch die beobachteten Punkte verlaufen. Mit anderen Worten: Die A-posteriori-Verteilung konzentriert sich ausschließlich auf jene Funktionen, die die Daten genau interpolieren.
An den X Trainingspunkten ist die Varianz (die Diagonalelemente der A-posteriori-Kovarianzmatrix Σ*) gleich null, was bedeutet, dass an diesen Punkten keine Unsicherheit besteht: Alle aus der A-posteriori-Verteilung gezogenen Funktionen verlaufen garantiert exakt durch die Trainingspunkte. Außerhalb der Trainingspunkte können die Funktionen variieren, was die Modellunsicherheit in Bereichen widerspiegelt, in denen Daten fehlen. Ihr Verhalten wird jedoch nach wie vor von der Struktur des gewählten Kernels bestimmt, in diesem Fall RBF.
Betrachten wir nun ein Diagramm mit Stichproben von f-Funktionen aus der A-posteriori-Verteilung, wenn die beobachteten y-Daten gaußsches Rauschen enthalten. (Abb. 6)

Abb. 6. Stichproben von f-Funktionen aus der A-posteriori-Verteilung (RBF-Kernel, mit Rauschen)
Bei Vorhandensein von Rauschen müssen die A-posteriori-Funktionen nicht exakt durch die beobachteten y-Daten verlaufen. Das bedeutet, dass sich die Menge der möglichen Funktionen, die die Daten erklären können, vergrößert, da sie innerhalb des Rauschens von den beobachteten Werten abweichen können. Die grauen gestrichelten Linien stellen 2-Sigma-Konfidenzintervalle dar, die etwa 95 % der A-posteriori-Verteilung enthalten. In Bereichen, die weit von den Trainingsdaten entfernt liegen, nimmt die Unsicherheit noch stärker zu, und die Konfidenzintervalle werden deutlich breiter, was auf eine geringere Zuverlässigkeit des Modells in diesen Bereichen hindeutet. Es ist wichtig zu beachten, dass die grauen gestrichelten Linien Konfidenzintervalle für die latente Funktion f* darstellen, nicht für neue y*-Beobachtungen.
Optimierung der Hyperparameter von GPs
Die Leistungsfähigkeit eines GP-Modells hängt in hohem Maße von der optimalen Wahl seiner Hyperparameter ab, wodurch das Modell an die Daten angepasst und seine Fähigkeit, die beobachteten Zusammenhänge zu erklären, maximiert wird. Zu diesen Hyperparametern gehören Kernel-Parameter und die Varianz des Rauschens. In GP erfolgt die Optimierung durch Minimierung der negativen logarithmischen RandLikelihood (NLML):

Die direkte Berechnung von (K + σ² * I)^(−1) * y ist bei großen n rechenintensiv, da hierfür die Inversion der n×n-Matrix erforderlich ist. Daher wird die Cholesky-Zerlegung verwendet, um die Berechnung effizienter und robuster zu gestalten. Unter Berücksichtigung dieser Zerlegung lässt sich die NLML-Gleichung wie folgt umschreiben:

- z – Vektor, der durch Lösen eines linearen Gleichungssystems mittels der Cholesky-Zerlegung erhalten wird, z=L^−1*y
- L – die untere Dreiecksmatrix aus der Cholesky-Zerlegung K + σ²*I = LL^T
Diese Gleichung ist in der Funktion „NegativeLogMarginalLikelihood“ implementiert.
//+------------------------------------------------------------------+ //| Calculate the negative log-likelihood | //+------------------------------------------------------------------+ double NegativeLogMarginalLikelihood(const matrix &x, const matrix &y, int &kernel_list[], KernelParams ¶ms) { int n = (int)x.Rows(); //--- Calculate the K covariance matrix matrix K = ComputeKernelMatrix(x, x, kernel_list, params); //--- Add white noise variance if KERNEL_WHITE is selected double white_noise_variance = 0.0; for (int i = 0; i < ArraySize(kernel_list); i++) { if (kernel_list[i] == KERNEL_WHITE) { white_noise_variance = params.white.sigma * params.white.sigma; break; } } // Adding a little jitter prevents problems, // if the K matrix is singular or close to singular // due to the peculiarities of the calculations or the chosen kernel double jitter = 1e-6; K += matrix::Identity(n, n) * (white_noise_variance + jitter); // ---Perform the Cholesky decomposition: K + sigma^2*I = L * L^T matrix L; if (!K.Cholesky(L)) { Print("Error: Cholesky decomposition failed"); return DBL_MAX; } //--- Solve the linear system L * z = y to find z = L^(-1) * y vector z = L.LstSq(y.Col(0)); if (z.Size() == 0) { Print("Error: Unable to solve the system L * z = y"); return DBL_MAX; } //--- Calculate the first term in the NLML equation: // 1/2 * y^T * (K + sigma^2*I)^-1 * y = 1/2 * z^T * z double data_term = 0.5 * z @ z; // Scalar product z^T * z //--- Calculate the second term: 1/2 * log|K + sigma^2*I| = sum(log(L_ii)) vector diag = L.Diag(); double log_det = 0.0; for (int i = 0; i < n; i++) log_det += MathLog(diag[i]); // sum the logarithms of the L diagonal elements //--- Calculate the third term: n/2 * log(2π) double const_term = 0.5 * n * MathLog(2 * M_PI); return data_term + log_det + const_term; }
Die K-Kovarianzmatrix wird mithilfe der Funktion ComputeKernelMatrix berechnet, die die Beiträge aller ausgewählten Kernel (z. B. RBF, Linear, Periodic usw.) summiert.
//+------------------------------------------------------------------+ //| Calculate the covariance matrix | //+------------------------------------------------------------------+ matrix ComputeKernelMatrix(const matrix &X1, const matrix &X2, int &kernel_list[], KernelParams ¶ms) { matrix K = matrix::Zeros(X1.Rows(), X2.Rows()); for (int i = 0; i < ArraySize(kernel_list); i++) { switch (kernel_list[i]) { case KERNEL_RBF: K += RBF_kernel(X1, X2, params.rbf.sigma_f, params.rbf.length); break; case KERNEL_LINEAR: K += Linear_kernel(X1, X2, params.linear.sigma_l); break; case KERNEL_PERIODIC: K += Periodic_kernel(X1, X2, params.periodic.sigma_f, params.periodic.length, params.periodic.period); break; case KERNEL_WHITE: // WhiteKernel is added separately as sigma^2 * I break; } } return K; }
NLML wird als Zielfunktion für die Hyperparameteroptimierung in der Funktion „OptimizeGP“ verwendet. Die Optimierung erfolgt mithilfe der BLEIC-Methode aus der ALGLIB-Bibliothek.
//+------------------------------------------------------------------+ //| Gaussian process hyperparameter optimization | //+------------------------------------------------------------------+ KernelParams OptimizeGP(int &kernel_list[], matrix &x_train, matrix &y_train) { double w[]; // Array of initial hyperparameter values double s[]; // Array of scales for hyperparameters used for normalization in optimization double bndl[], bndu[]; // Arrays of lower and upper bounds for each hyperparameter CObject Obj; CNDimensional_GP ffunc(kernel_list, x_train, y_train);// Object of a class implementing the NLML target function CNDimensional_Rep frep; // Object for storing the optimization report // Initialize parameters InitializeKernelParams(kernel_list, w, s, bndl, bndu); /* The total number of parameters (num_params) is calculated depending on the kernel types in kernel_list. The initial values of the w parameters, scale and bounds for the parameters are set */ CMinBLEICStateShell state; CMinBLEICReportShell rep; // Object for storing optimization results. double epsg = 0; // Gradient precision (0 means gradient stopping is disabled) double epsf = 0.0001; // Precision by function value double epsw = 0; // accuracy by parameters double diffstep = 0.0001; // Step for numerical calculation of derivatives. double epso = 0.00001; // Parameters for external and internal convergence conditions in BLEIC double epsi = 0.00001; CAlglib::MinBLEICCreateF(w, diffstep, state); // Create a BLEIC optimization object with w initial parameters and diffstep for numerical derivatives CAlglib::MinBLEICSetBC(state, bndl, bndu); // Set parameter bounds (bndl, bndu). CAlglib::MinBLEICSetScale(state, s); // Sets the scale of (s) parameters. CAlglib::MinBLEICSetInnerCond(state, epsg, epsf, epsw); CAlglib::MinBLEICSetOuterCond(state, epso, epsi); CAlglib::MinBLEICOptimize(state, ffunc, frep, 0, Obj); CAlglib::MinBLEICResults(state, w, rep); Print("TerminationType =", rep.GetTerminationType()); // Optimization completion code /* * -8 internal integrity control detected infinite or NAN values in function/gradient. Abnormal termination signalled. * -3 inconsistent constraints. Feasible point is either nonexistent or too hard to find. Try to restart optimizer with better initial approximation * 1 relative function improvement is no more than EpsF. * 2 scaled step is no more than EpsX. * 4 scaled gradient norm is no more than EpsG. * 5 MaxIts steps was taken * 8 terminated by user who called minbleicrequesttermination(). X contains point which was "current accepted" when termination request was submitted. */ Print("IterationsCount =", rep.GetInnerIterationsCount()); // Number of iterations Print("Parameters:"); PrintKernelParams(w, kernel_list); // Display optimized parameters in the log Print("NLML = ", ffunc.GetNLML()); // final NLML value for optimal parameters KernelParams optimized_params; CRowDouble parameters = w; // determine the correct distribution of parameters across kernels ExtractKernelParams(parameters, kernel_list, optimized_params); return optimized_params; }
GP-Regression in MQL5
Um die Leistungsfähigkeit des GP-Regressionsmodells zu veranschaulichen, betrachten wir ein Beispiel mit synthetischen Daten. Die Umsetzung wird im Skript „GP_Regressor“ vorgestellt, das die Erstellung, das Training und das Testen des Modells veranschaulicht.
Die Datengenerierung erfolgt mithilfe der Funktion Dataset, die Matrizen mit synthetischen Daten für das Training und das Testen erzeugt. Der Datensatz besteht aus 100 Punkten, die gleichmäßig im Intervall [−5,5] verteilt sind, und stellt die Funktion y = sin(x) + 0,5x dar, der gaußsches Rauschen hinzugefügt wurde. Dieser Ansatz ermöglicht die Simulation realer Daten, die sowohl einen linearen Trend als auch eine periodische Komponente enthalten, wobei Unsicherheiten berücksichtigt werden.
Um ein Regressionsmodell zu erstellen, muss die Liste der Kernel bestimmt werden, die die Kovarianzfunktion bilden. Jeder Kernel leistet einen einzigartigen Beitrag zur K-Kovarianzmatrix und bestimmt damit die Art der Abhängigkeiten, die das Modell erfassen kann. Die Kernel-Liste wird mithilfe der Funktion „SetKernelList“ konfiguriert, die das Array „kernel_list“ auf der Grundlage des Eingabeparameters „kernel_combination“ (Enum-Typ „KernelCombination“) generiert. Die folgenden Kombinationen werden unterstützt:
- COMBINATION_1: [RBF, Linear, White] (3 kernels),
- COMBINATION_2: [RBF, Linear, Periodic, White] (4 kernels),
- COMBINATION_3: [RBF, White] (2 kernels).
Nach der Auswahl der Kernel werden die Hyperparameter des Modells mithilfe der Funktion „OptimizeGP“ optimiert. Diese Funktion minimiert die negative Log-Likelihood (NLML) und gibt die Struktur KernelParams zurück, die die optimalen Parameter für jeden Kernel enthält, wie beispielsweise Amplitude (σ_f), Skalenlänge (l) oder Periode (p).
Sobald die optimalen Parameter ermittelt wurden, fahren wir mit der Prognose unter Verwendung der Predict-Funktion fort.
//+------------------------------------------------------------------------+ //| Predict the Gaussian posterior distribution for new points | //+------------------------------------------------------------------------+ GPPredictionResult Predict(const matrix &x_train, const matrix &y_train, const matrix &x_test, int &kernel_list[], KernelParams ¶ms) { GPPredictionResult result; // Calculate the K covariance matrix for the training points matrix K = ComputeKernelMatrix(x_train, x_train, kernel_list, params); // Obtain the observation noise variance double observation_noise_variance = 0.0; for (int i = 0; i < ArraySize(kernel_list); i++) { if (kernel_list[i] == KERNEL_WHITE) { observation_noise_variance = params.white.sigma * params.white.sigma; break; } } // Form a noise matrix for the training data: K + sigma_n^2 * I matrix K_noisy_train = K + matrix::Identity((int)x_train.Rows(), (int)x_train.Rows()) * observation_noise_variance; // Calculate the K* cross-covariance matrix between training and test points matrix K_star = ComputeKernelMatrix(x_train, x_test, kernel_list, params); // Calculate the posterior mean matrix inv_term = K_noisy_train.Inv(); result.mu_f_star = K_star.Transpose() @ (inv_term @ y_train); // Matches mu_y_star // Calculate the posterior covariance matrix for the latent function (Sigma_f_star) matrix K_star_star = ComputeKernelMatrix(x_test, x_test, kernel_list, params); result.Sigma_f_star = K_star_star - K_star.Transpose() @ (inv_term @ K_star); // Calculate the posterior covariance matrix for a new observation (Sigma_y_star) // Sigma_y_star = Sigma_f_star + sigma_n^2 * I result.Sigma_y_star = result.Sigma_f_star + matrix::Identity((int)x_test.Rows(), (int)x_test.Rows()) * observation_noise_variance; return result; }
Die Predict-Funktion ist ein zentraler Bestandteil der GP-Modellimplementierung, da sie nicht nur die Vorhersagewerte zurückgibt, sondern auch umfassende Informationen über die A-posteriori-Verteilung an den Testpunkten liefert. Die Funktion gibt die Struktur „GPPredictionResult“ zurück, die Folgendes enthält:
- posteriorer Mittelwert für die latente Funktion f* (μf* = μy*),
- Σf*-Posterior-Kovarianzmatrix für die latente Funktion f*,
- Σy* – A-posteriori-Kovarianzmatrix für die y*-Werte. Die Matrix umfasst sowohl die Unsicherheit der latenten Funktion als auch die Varianz des Beobachtungsrauschens (σ²), die bei der Optimierung des WhiteKernel-Parameters ermittelt wurde.
Sehen wir uns nun die Prognoseergebnisse für verschiedene Kombinationen von Kerneln an. Versuchen wir zunächst, unsere Funktion ausschließlich mit dem RBF-Kernel zu prognostizieren, wobei wir davon ausgehen, dass die Daten Rauschen enthalten (Abb. 7).

Abb. 7. Prognose unter Verwendung eines RBF-Kernels
- Rote Punkte – Trainingsdaten (TrainData),
- Blaue Linie – vorhergesagter Mittelwert,
- Grüne Sterne – Prognose für Testpunkte (X*),
- Blaue Punkte – Testdaten außerhalb des Trainingsbereichs,
- Graue gestrichelte Linien – Konfidenzintervalle (± 2 Sigma für f* oder y*)
Hier sehen wir, dass sich die Vorhersagen, je weiter sich die Testpunkte vom Trainingsdatenbereich [-5,5] entfernen, dem Mittelwert der GP-Prior-Verteilung annähern, der üblicherweise mit Null angenommen wird. Dies geschieht, weil die K*-Kovarianzen (zwischen den x* neuen Punkten und den x Trainingspunkten) für den RBF-Kernel außerhalb des Trainingsdatensatzes exponentiell gegen Null abnehmen. Daher eignet sich der RBF-Kernel besser für die Dateninterpolation, während seine Eignung für die Extrapolation aufgrund des raschen Abklingens der Korrelationen eingeschränkt ist.
Um die Extrapolation zu verbessern, fügen wir einen linearen Kernel hinzu (Abb. 8).

Abb. 8. Prognose unter Verwendung der Summe aus RBF- und linearem Kernel, f*-Intervalle
Der lineare Kernel bildet lineare Beziehungen ab und eignet sich daher gut für Extrapolationen, insbesondere wenn die Daten einen linearen oder nahezu linearen Trend aufweisen, wie in unserem Beispiel mit der Funktion y = sin(x) + 0,5x. Durch die Einbeziehung eines linearen Kernels konnten die Prognosen außerhalb des Trainingsdatenbereichs verbessert werden, da dadurch eine lineare Komponente (0,5x) erfasst wurde. Wie aus der Grafik jedoch ersichtlich ist, spiegelt das Modell die Struktur der Daten noch immer nicht vollständig wider, da die periodische Komponente der Daten nicht erfasst wird.
Zur Modellierung saisonaler oder zyklischer Schwankungen, wie beispielsweise sin(x) in unseren Daten, wird ein periodischer Kernel verwendet (Abbildung 9).

Abb. 9. Prognose unter Verwendung der Summe aus RBF-, periodischen und linearen Kerneln sowie f*-Intervallen
Nach Hinzufügen des periodischen Kernels lieferte das Modell nahezu perfekte Vorhersagen, da es alle in den Daten vorhandenen wesentlichen Abhängigkeiten erfassen konnte. Infolgedessen fallen die Konfidenzintervalle für f* (die latente Funktion) praktisch mit dem A-posteriori-Mittelwert zusammen. Bei den beobachteten y*-Werten sind die Konfidenzintervalle hingegen deutlich breiter, was logisch ist, da sie die Varianz des Beobachtungsrauschens berücksichtigen, wie in Abb. 10. dargestellt.
")
Abb. 10. Prognose unter Verwendung der Summe aus RBF-, periodischen und linearen Kerneln, y*-Intervalle
Ein wichtiger Hinweis zu Prognosen in GP. Ohne angemessene Berücksichtigung der Varianz des Rauschens können Konfidenzintervalle für f*(x) fälschlicherweise als Vorhersageintervalle für y* interpretiert werden. Um korrekte Prognoseintervalle für y* zu erhalten, muss die Varianz des Rauschens explizit in die Kovarianzmatrix einbezogen werden, was in der Funktion „Predict“ umgesetzt ist.
Schlussfolgerung
In diesem Artikel haben wir uns anhand eines Regressionsproblems eingehend mit den Grundlagen von GPs befasst. Wir haben die Schlüsselkomponenten des GP untersucht: die A-priori-Verteilung, die Likelihood und die A-posteriori-Verteilung, die umfassende probabilistische Prognosen mit quantifizierter Unsicherheit liefert. Wir haben die grundlegenden Kernel-Funktionen wie RBF-, lineare und periodische Kernel implementiert, obwohl es natürlich noch viele weitere gibt.
Besonderes Augenmerk wurde auf die Hyperparameter-Optimierung gelegt, die für die Anpassung des GP an bestimmte Daten von entscheidender Bedeutung ist. Wir haben gezeigt, dass diese Optimierung durch die Minimierung der negativen log-marginalen Likelihood (NLML) erreicht wird, wobei die Cholesky-Zerlegung zur Verbesserung der Recheneffizienz und der numerischen Stabilität eingesetzt wird. Als Optimierungsverfahren wurde im implementierten Modell die Gradientenmethode BLEIC aus der ALGLIB-Bibliothek verwendet.
Dieser Artikel konzentriert sich auf die Grundprinzipien von GP; eine Reihe fortgeschrittener Themen wird dabei ausgeklammert. Dazu gehören beispielsweise die Verwendung analytischer Ausdrücke für NLML-Gradienten, die die Optimierungseffizienz erheblich verbessern können, sowie der Einsatz spärlicher Approximationen, die für die Verarbeitung großer Datenmengen von entscheidender Bedeutung sind. Diese Ansätze eröffnen neue Perspektiven für die weitere Erforschung von GP-Modellen.
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | GP_Samples_Prior.mq5 | Skript | Veranschaulichung von Stichproben aus der A-priori-Verteilung |
| 2 | GP_Samples_Posterior.mq5 | Skript | Veranschaulichung von Stichproben aus der A-posteriori-Verteilung |
| 3 | GP_Regressor | Skript | Erstellen eines Regressionsmodells |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/18427
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Die Übertragung der Trading-Signale in einem universalen Expert Advisor.
Die Übertragung der Trading-Signale in einem universalen Expert Advisor.
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Es besteht ein enger Zusammenhang zwischen den Gaußschen Prozessen für die Regression und dem Wiener-Khinchin-Theorem https://danmackinlay.name/notebook/wiener_khintchine.html https://www.numberanalytics.com/blog/wiener-khinchin-theorem-guide Es wäre toll, wenn Sie in dieser Richtung weitermachen könnten, um uns aufzuklären.
Es ist natürlich kein besonders beliebtes Werkzeug, aber ich sehe darin Potenzial. Mich reizt, dass man, wenn man den Kernel-Ansatz einmal verstanden hat, sozusagen eine einheitliche, abgestimmte Sichtweise auf die Datenanalyse erhält. Hier kommen sowohl Regression als auch Klassifizierung, die Kernel-Dichte-Schätzung, die Auswahl signifikanter Merkmale sowie statistische Unabhängigkeitstests usw. zum Einsatz.
Auf jeden Fall interessant :)