
Das Hilbert-Schmidt-Unabhängigkeitskriterium (HSIC)

Einführung
Die Hauptaufgabe eines Händlers bei der Arbeit mit Kursen von Finanzinstrumenten besteht darin, ein Handelssystem (EA) mit einer positiven mathematischen Erwartung zu erstellen. Bei der Entwicklung solcher Systeme wird häufig davon ausgegangen, dass es versteckte Abhängigkeiten in den für das Training und den anschließenden Handel verwendeten Daten gibt. Eine statistische Überprüfung dieser Annahme erfolgt jedoch in der Regel nicht. Es wird angenommen, dass eine indirekte Antwort durch die Prüfung der Ergebnisse auf Daten außerhalb der Trainingsstichprobe gefunden werden kann.
Gleichzeitig ist eine statistisch fundierte Antwort auf die Frage, ob ein Zusammenhang zwischen den Merkmalen und der Zielvariablen besteht, von zentraler Bedeutung. Eine positive Antwort unterstützt den Einsatz von Vorhersagemodellen, während eine negative Antwort die Frage aufwirft: Was genau versucht der Algorithmus vorherzusagen?
In der mathematischen Statistik wird die Frage, ob eine probabilistische Abhängigkeit zwischen Zufallsvariablen besteht, durch Unabhängigkeitstests beantwortet. Ein solches Kriterium ist der statistische HSIC-Test, eine leistungsfähige nichtparametrische Methode, die 2005 von dem Statistiker Arthur Gretton entwickelt wurde.
Im Gegensatz zum Korrelationskoeffizienten, der nur lineare Beziehungen aufzeigt, ist der HSIC in der Lage, sowohl lineare als auch nicht-lineare Beziehungen zu erkennen. Aus diesem Grund wird HSIC beim maschinellen Lernen häufig für die Auswahl von Merkmalen, die Kausalanalyse und andere Aufgaben verwendet. In diesem Artikel werden wir das Funktionsprinzip von HSIC analysieren und es in der MQL5-Umgebung implementieren.
Was ist HSIC?
HSIC ist ein Maß für die Abhängigkeit zwischen zwei Zufallsvariablen X und Y auf der Grundlage des Kernel-Ansatzes. Die Methode nutzt die mathematische „Magie" von Kernel-Funktionen (z. B. die Gaußsche (Abb. 1)), die die Daten in einen speziellen RKHS-Raum (Reproducing Kernel Hilbert Spaces) transformieren, in dem Abhängigkeiten leichter zu erkennen sind.
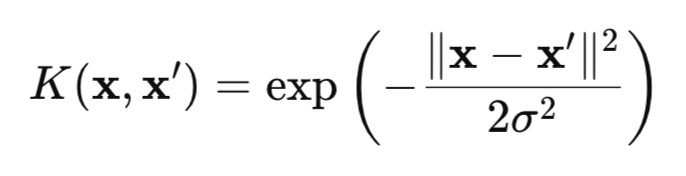
Abb. 1. Gaußsche Kernel (RBF-Kernel)
wobei:
- x, x' – Vektoren (Punkte) von Beobachtungen,
- || ||2 – Quadrat der euklidischen Norm,
- σ – Kernel-Breite.
Es gibt viele Kernel, die für den HSIC-Test verwendet werden können, z. B. Kernel für kategoriale Daten oder der Laplace-Kernel. In diesem Artikel werden wir uns jedoch auf den Gaußschen Kernel konzentrieren, da er eine charakteristische Kernel-Eigenschaft besitzt, die das Erkennen beliebiger Abhängigkeiten ermöglicht, was den Gaußschen Kernel besonders effizient macht.
Der klassische HSIC testet die paarweise Unabhängigkeit zwischen zwei Zufallsvariablen X und Y, indem er überprüft, ob die Bedingung P(X,Y) = P(X)P(Y) erfüllt ist. Zu diesem Zweck analysiert HSIC anhand von Kernel-Matrizen die Abweichung der gemeinsamen Verteilung vom Produkt der Randverteilungen (eine Tabelle, in der jedes Element die Ähnlichkeit zwischen Datenpunktpaaren widerspiegelt, die mithilfe einer Kernel-Funktion berechnet wird).
Ein wichtiger Vorteil von HSIC ist die Fähigkeit, mit Daten beliebiger Dimensionen zu arbeiten: Skalar, Vektor oder Kombinationen aus beiden. Dies ist besonders wertvoll bei Problemen, bei denen die explizite Konstruktion multivariater gemeinsamer Verteilungen P(X,Y) aufgrund der hohen Dimensionalität der Daten schwierig ist.
Aus mathematischer Sicht ist das HSIC-Kriterium definiert als das Quadrat der Hilbert-Schmidt-Norm des Kreuzkovarianzoperators in RKHS:
![]()
wobei:
- K(X,X') – Kernel-Funktion für die Zufallsvariable X,
- L(Y,Y') – Kernel-Funktion für die Zufallsvariable Y,
- || ||HS – Hilbert-Schmidt-Norm.
Hier ist es angebracht, den HSIC mit der üblichen Kovarianz zu vergleichen. Die klassische Kovarianz misst die lineare Beziehung zwischen den Größen X und Y in ihrem ursprünglichen Raum, während HSIC mit Abbildungen von X und Y in einen RKHS (Reproducing Kernel Hilbert Space) arbeitet, d. h. in einen Raum von Funktionen, der es ermöglicht, die Daten zu transformieren, um komplexe nichtlineare Abhängigkeiten aufzudecken.
In der Praxis ist die Berechnung der Hilbert-Schmidt-Norm nicht direkt erforderlich. Stattdessen wird der HSIC durch empirische Statistiken geschätzt, die sich auf Kernel-Matrizen stützen, die für die Datenstichprobe konstruiert wurden:
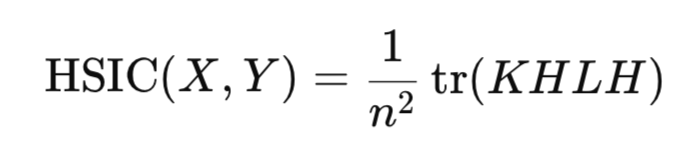
wobei:
- K,L – n*n Kernel-Matrizen,
- H – n*n Zentriermatrix (I -1/n11^T),
- tr() – Matrix-Spur,
- n – Anzahl der Beobachtungen.
Ähnlich wie der Korrelationskoeffizient schätzt der HSIC das Vorhandensein einer Beziehung zwischen den Zufallsvariablen X und Y anhand von Stichprobenstatistiken, ohne dass die Verteilungen dieser Variablen konstruiert werden müssen.
Die HSIC-Statistik ist immer nicht-negativ:
- HSIC > 0 weist auf das Vorhandensein einer Abhängigkeit hin,
- während HSIC = 0 die Unabhängigkeit der Daten anzeigt.
HSIC-Signifikanztest
Die Berechnung von Statistiken reicht jedoch nicht aus, um zuverlässige Schlussfolgerungen zu ziehen. Ihre statistische Signifikanz sollte bestätigt werden, um ein Zufallsergebnis auszuschließen. Für die HSIC-Statistik gibt es keine exakte analytische Form der Verteilung unter der Nullhypothese. Das heißt, wir können nicht einfach z. B. eine Normalverteilung verwenden und schnell und einfach einen kritischen Wert oder einen p-Wert ohne Rechenaufwand erhalten. Es gibt zwei Hauptansätze, um dieses Problem zu lösen:
- Permutationstest,
- Gamma-Approximation.
Der Permutationstest ist die grundlegende und genaueste Methode zur Schätzung der HSIC-Verteilung unter H0. Sein Ziel ist es, jede Abhängigkeit zwischen X und Y aufzubrechen, indem die Indizes einer der Variablen zufällig vertauscht oder die resultierende Kernel-Matrix dieser Variablen gemischt wird. Um ein genaues Ergebnis zu erhalten, sollten eine ganze Reihe solcher Permutationen (etwa 1000) durchgeführt werden. Daher ist der Permutationstest recht aufwendig, da er die Berechnung des HSIC für jede dieser Permutationen erfordert.
Der Hauptvorteil des Permutationstests ist, dass er keine Annahmen über die Form der Datenverteilung erfordert. Stattdessen stützt er sich auf die empirische Verteilung der durch Permutationen erhaltenen Statistik. Die empirische HSIC-Verteilung wird dann verwendet, um einen p-Wert zu schätzen.
Die Gamma-Approximation wird eingesetzt, um die Berechnung der statistischen Signifikanz zu beschleunigen. Bei diesem Ansatz wird die HSIC-Statistik durch den Stichprobenumfang skaliert (n*HSIC), und die Parameter der Gamma-Verteilung werden anhand der HSIC-Stichprobenmomente (Mittelwert und Varianz) geschätzt. Diese Methode ist wesentlich schneller als der Permutationstest, aber ihre Genauigkeit kann bei kleinen Stichproben geringer sein. Es gibt noch andere Methoden zur Schätzung der HSIC-Verteilung unter der Nullhypothese der Unabhängigkeit, aber sie sind kompliziert zu implementieren und werden in der Praxis selten verwendet, weshalb sie in diesem Artikel nicht behandelt werden.
Implementierung der HSIC-Permutation in MQL5
Der Permutationstest ist in der Funktion hsic_test implementiert.
//+------------------------------------------------------------------+ //| Permutation test function | //+------------------------------------------------------------------+ vector hsic_test(matrix &X,matrix &Y,const double alpha,bool Bootstrap = false,int n_permutations=1000) { vector ret = vector::Zeros(3); int n = (int)X.Rows(); matrix K = RBF_kernel(X); // kernel matrix for X matrix L = RBF_kernel(Y); // kernel matrix for Y matrix H = matrix::Eye(n, n) - matrix::Ones(n, n)/n; // Centering matrix //-------------------------------------- // Kc centered kernel matrix К matrix Kc(n, n); if(!Kc.GeMM(H, K, 1.0, 0.0)) { Print("Error: Failed to calculate Kc = H * K"); return ret; } if(!Kc.GeMM(Kc, H, 1.0, 0.0)) { Print("Error: Failed to calculate temp = Kc * H"); return ret; } Kc = Kc.Transpose(); double coef = 1/pow(n,2); // Calculate the observed value of the HSIC statistic double hsic_obs = compute_hsic(L,Kc,coef); ret[0]= hsic_obs; //------------ Permutation test ---------------------------------------- if (Bootstrap == true){ vector hsic_perms = vector::Zeros(n_permutations); for ( int i = 0; i<n_permutations; i++) { ShuffleMatrix(L); // Shuffle the matrix hsic_perms[i] = compute_hsic(L,Kc,coef); } int count = 0; for(int i = 0; i < n_permutations; i++) { if(hsic_perms[i] >= hsic_obs) count++; } // Calculate the p-value double p_value = (n_permutations > 0) ? (double)count / n_permutations : 0.0; ret[1] = p_value; // Calculate the critical value double hsic_sort[]; VectortoArray(hsic_perms,hsic_sort); ArraySort(hsic_sort); double CV = hsic_sort[(int)round((1-alpha)*n_permutations)]; ret[2] = CV; } //---------------------------------------------------------------------------------- return ret; }
Die Funktion nimmt zwei Datensätze X und Y an (das sind Matrizen der Größe n*d, wobei n die Anzahl der Beobachtungen und d die Dimension der Daten ist),
Der Parameter „alpha" legt das Signifikanzniveau fest (dies ist ein Fehler vom Typ I, d. h. die Wahrscheinlichkeit, die Nullhypothese zurückzuweisen, wenn sie tatsächlich wahr ist),
Bootstrap-Parameter (wenn „true“, wird ein Permutationstest durchgeführt, um einen p-Wert zu erhalten, andernfalls wird nur die Statistik berechnet),
n_permutations – Anzahl der zufälligen Permutationen,
gibt die Funktion einen Vektor zurück, der den beobachteten HSIC-Wert, den p_Wert und den kritischen Wert für das ausgewählte „Alpha"-Niveau enthält.
Die Berechnung der Gaußschen Kernel-Matrix wird in der Funktion RBF_kernel durchgeführt.
//+------------------------------------------------------------------+ //| Gaussian kernel | //+------------------------------------------------------------------+ matrix RBF_kernel(const matrix &X) { int n = (int)X.Rows(); // Calculate the distance matrix using the scalar product matrix XX(n, n); if(!XX.GeMM(X, X.Transpose(), 1.0, 0.0)) { Print("Error: Failed to calculate XX = X * X^T"); } matrix diag(n,1); diag.Col(XX.Diag(),0); // vector of diagonal elements // squares of distances matrix D_sq = matrix::Ones(n, 1).MatMul(diag.Transpose()) + diag.MatMul(matrix::Ones(1, n)) - 2*XX; // Calculate sigma on the first n_sigma rows int n_sigma = MathMin(n, 100); int num_elements = (n_sigma * (n_sigma - 1)) / 2; vector upper_tri(num_elements); int idx = 0; for(int i = 0; i < n_sigma; i++) { for(int j = i + 1; j < n_sigma; j++) { upper_tri[idx] = D_sq[i, j]; idx++; } } double sigma = MathSqrt(0.5 * upper_tri.Median()); return MathExp((-1* D_sq) / (2 * sigma*sigma)); }
Die Funktion berechnet das Quadrat der Abstände zwischen den Datenpunkten, die Breite des Sigma-Kernels, und gibt die gewünschte n*n-Kernel-Matrix zurück.
Um die quadrierten Abstände effizient zu berechnen, wird eine Matrixform anstelle einer regulären Schleife verwendet:
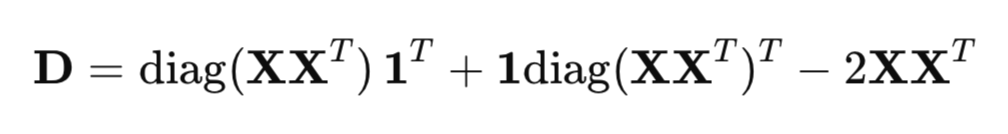
wobei:
- XX^T – Gram-Matrix (Skalarproduktmatrix),
- diag(XX^T ) – Vektor der Diagonalelemente,
- 1 – Vektor der Einsen.
Der Sigma-Parameter im Gaußschen Kernel bestimmt die Breite des Kernels und beeinflusst die Empfindlichkeit von HSIC bei der Erkennung von Abhängigkeiten in den Daten erheblich. Der Sigma-Parameter bestimmt die Skala der Ähnlichkeit: große Sigma-Werte machen den Kernel breiter (weiter auseinander liegende Punkte werden noch als ähnlich angesehen), während kleine Werte ihn enger machen (nur sehr nahe Punkte werden als ähnlich angesehen).
Eine gängige Methode zur Auswahl von Sigma ist die Verwendung der folgenden Median-Heuristik:

Der Faktor 0,5 wird verwendet, um sicherzustellen, dass der Nenner des RBF-Kernels gleich dem Median der quadrierten euklidischen Abstände zwischen den Datenpunkten ist, was eine adaptive Schätzung gewährleistet, die den Maßstab der Daten berücksichtigt.
Die Variable n_sigma = MathMin (n, 100) begrenzt die Menge der Daten für die Berechnung von sigma auf 100. Dies geschieht, um die Rechenkosten für große Stichproben zu reduzieren und gleichzeitig die Repräsentativität der Sigma-Schätzung zu erhalten. Die quadrierten euklidischen Abstände werden in den upper_tri-Vektor kopiert, wobei nur das obere Dreieck der Abstandsmatrix (ohne die Diagonale, i=j) verwendet wird, um Doppelungen und Nullabstände zu vermeiden.
Funktion zur Berechnung der HSIC-Statistik compute_hsic.
//+------------------------------------------------------------------+ //| Function to calculate HSIC | //+------------------------------------------------------------------+ double compute_hsic(const matrix &L, const matrix& Kc, const double coef){ matrix KcL= Kc*L; return coef*KcL.Sum(); }
Nach der Berechnung der beobachteten HSIC-Statistik wird ein Permutationstest durchgeführt, um ihre statistische Signifikanz zu prüfen. Die Funktion ShuffleMatrix(matrix &m) implementiert diese Permutation für die L-Kernel-Matrix, die der Variablen Y entspricht. Statistisch gesehen macht es keinen Unterschied, ob L oder K gemischt wird, da HSIC in Bezug auf X und Y symmetrisch ist, was beim Permutationstest für HSIC zu gleichen Ergebnissen führt. Es ist ineffizient, die Variable Y selbst zu mischen und dann die L-Matrix für jede Permutation neu zu berechnen.
//+------------------------------------------------------------------+ //| Function for shuffling matrix data | //+------------------------------------------------------------------+ void ShuffleMatrix(matrix &m) { int rows = (int)m.Rows(); int cols = (int)m.Cols(); if (rows != cols) { Print("Error: Matrix should be square"); } int perm[]; GeneratePermutation(rows, perm); // Generate a random permutation of indices matrix temp = m; // Rearrange rows and columns for(int i = 0; i < rows; i++) { for(int j = 0; j < cols; j++) { m[i,j] = temp[perm[i], perm[j]]; } } }
Die Erzeugung von Zufallsindizes erfolgt mit der Funktion GeneratePermutation.
//+------------------------------------------------------------------+ //| Function to create a random permutation of indices | //+------------------------------------------------------------------+ void GeneratePermutation(int size, int &perm[]) { MathSequence(0,size,1,perm); // Fisher-Yates algorithm for permutation for(int i = size - 1; i > 0; i--) { // Generate a random index from 0 to i int j = (int)(MathRand() / 32768.0 * (i + 1)); int temp = perm[i]; perm[i] = perm[j]; perm[j] = temp; } }
Nach mehrfachen Permutationen der L-Kernel-Matrix wird die empirische Verteilung der HSIC-Statistik unter der Nullhypothese der Unabhängigkeit mithilfe der Funktion ShuffleMatrix gebildet. Der p-Wert ist definiert als der Anteil der HSIC-Permutationswerte, die größer oder gleich der beobachteten Statistik sind. Ist der p-Wert kleiner als das Signifikanzniveau „alpha", wird die Nullhypothese der Unabhängigkeit verworfen.
Als kritischer Wert wird das Quantil der empirischen Verteilung auf dem 1-Alpha-Niveau gewählt, d. h. der Wert, über dem alpha⋅100 % der HSIC-Permutationsberechnungen gefunden werden.
Umsetzung von HSIC Gamma
Die Funktion hsic_Gamma_test ist für die Berechnung der Gamma-Approximation zuständig.
//+------------------------------------------------------------------+ //| HSIC Gamma approximation function | //+------------------------------------------------------------------+ double hsic_Gamma_test(matrix &X, matrix &Y, double &CV, double & pvalue) { int n = (int)X.Rows(); matrix K = RBF_kernel(X); // kernel matrix for X matrix L = RBF_kernel(Y); // kernel matrix for Y matrix H = matrix::Eye(n, n) - matrix::Ones(n, n)/n; // Centering matrix matrix Kc(n, n); // Calculate the centered X kernel matrix if(!Kc.GeMM(H, K, 1.0, 0.0)) { Print("Error: Failed to calculate Kc = H * K"); return 0; } if(!Kc.GeMM(Kc, H, 1.0, 0.0)) { Print("Error: Failed to calculate temp = Kc * H"); return 0; } matrix KcT = Kc.Transpose(); matrix Lc(n, n); // Calculate the centered Y kernel matrix if(!Lc.GeMM(H, L, 1.0, 0.0)) { Print("Error: Failed to calculate Lc = H * L"); return 0; } if(!Lc.GeMM(Lc, H, 1.0, 0.0)) { Print("Error: Failed to calculate temp = Lc * H"); return 0; } double m = (double)n; double coef = 1/m; // Calculate the observed HSIC value matrix KcLc; double hsic_obs = compute_hsic_Gamma(Lc,KcT,coef,KcLc); // n*HSIC matrix varHSIC_m = KcLc*KcLc; varHSIC_m = (1.0/36.0)*varHSIC_m; double varHSIC = 1/(m)/(m-1) * (varHSIC_m.Sum() - varHSIC_m.Trace() ); varHSIC = 72*(m-4)*(m-5)/m/(m-1)/(m-2)/(m-3) * varHSIC; // HSIC variance matrix KD; KD.Diag(K.Diag(),0); matrix LD; LD.Diag(L.Diag(),0); K = K-KD; L = L-LD; matrix one = matrix::Ones(n,1); matrix a = 1/m/(m-1)*one.Transpose(); matrix muX; muX.GeMM(a,K.MatMul(one),1,0); matrix muY; muY.GeMM(a,L.MatMul(one),1,0); double mHSIC = 1/m * ( 1 +muX[0,0]*muY[0,0] - muX[0,0] - muY[0,0] ) ; // HSIC mathematical expectation //Gamma distribution parameters double alphaG = mHSIC*mHSIC / varHSIC; double beta = varHSIC*m / mHSIC; int err; CV = MathQuantileGamma(1-alpha_,alphaG,beta,err); // Critical value pvalue = 1 - MathCumulativeDistributionGamma(hsic_obs,alphaG,beta,err); // p-value //---------------------------------------------------------------------------------- return hsic_obs; }
Hier wird die mit dem Stichprobenumfang n skalierte HSIC-Statistik (n*HSIC) berechnet, die durch eine Gamma-Verteilung mit den Parametern Form (Alpha) und Skala (Beta) approximiert wird. Diese Parameter werden auf der Grundlage der mathematischen Erwartung und der Varianz der HSIC-Statistiken bestimmt.
Test mit synthetischen Daten
Um die Fähigkeit von HSIC, nicht-lineare Abhängigkeiten zu erkennen, zu bewerten, simulieren wir ein für Handelsprobleme typisches Experiment. Betrachten wir zwei Merkmale X={X 1 ,X 2 }, die nichtlinear mit der skalaren Zielvariablen Y zusammenhängen, aber keine lineare Korrelation mit ihr aufweisen (Abb. 2). Diese Situation spiegelt eine reale Herausforderung wider, mit der ein Händler konfrontiert ist: Er muss testen, ob die ausgewählten Merkmale die vorhergesagte Variable beeinflussen, bevor er sie in einem Handelssystem verwendet.
Lassen Sie uns die Daten wie folgt generieren:
Y = X1^2 * cos(pi * X2) + Noise
wobei:
- X1 und X2 – unabhängige und gleichverteilte Zufallsvariablen im Intervall [-5,5],
- Noise – Gaußsches Rauschen,
- Y – Zielvariable, die mit X1 und X2 durch eine nicht lineare Beziehung verbunden ist.

Abb. 2. Streudiagramm für die Zielvariable Y und die Merkmale X
Ziel des Experiments ist es, die Unabhängigkeitshypothese in der Form zu testen:
P(X1,X2,Y) = P(X1,X2)P(Y),
d. h. um festzustellen, ob beide Merkmale gemeinsam die Zielvariable beeinflussen oder ob kein Zusammenhang zwischen ihnen besteht.
Bei realen Problemen, bei denen die Anzahl der Merkmale groß sein kann, ermöglicht HSIC eine flexible Prüfung von Abhängigkeiten: sowohl für einzelne Merkmale (z. B. X1 oder X2 mit Y) als auch für beliebige Untergruppen von Daten. Dies macht die Methode nützlich für die Auswahl informativer Merkmale, z. B. durch eine Rangfolge nach dem p-Wert, um die wichtigsten Merkmale für den Aufbau eines Handelssystems auszuwählen.
Abbildung 3 zeigt die Ergebnisse des HSIC-Tests unter Verwendung der Gamma-Approximation. Der erhaltene HSIC-Wert und der entsprechende p-Wert und kritische Wert bestätigen eine statistisch signifikante nicht-lineare Beziehung zwischen X und Y. Dies zeigt die Fähigkeit von HSIC, komplexe Beziehungen in Daten effektiv zu identifizieren, was besonders wichtig für die Börsenanalyse ist, wo Merkmale oft eine nicht-lineare Wirkung auf die vorhergesagte Variable haben. Im Vergleich dazu lag der für X1, X2 und Y berechnete Korrelationskoeffizient nahe bei Null, was auf keinen linearen Zusammenhang schließen lässt.

Abb. 3. HSIC-Testergebnisse, Gamma-Approximation
Der exakte HSIC-Permutationstest, der mit derselben Stichprobengröße durchgeführt wurde, dauerte auf dem für heutige Verhältnisse eher bescheidenen PC des Autors (ein 4-Core Ryzen 3) 8,5 Sekunden. Die Berechnungszeit der Gamma-Näherung ist jedoch erheblich schneller, sodass sie für Aufgaben, bei denen die Berechnungsgeschwindigkeit eine wichtige Rolle spielt, wie z. B. bei der Analyse großer Mengen von Finanzdaten in Echtzeit, die bevorzugte Wahl ist. Die Gamma-Approximation bietet trotz möglicher Ungenauigkeiten bei kleinen Stichproben ein ausgewogenes Verhältnis zwischen Geschwindigkeit und Genauigkeit, was sie zu einem wertvollen Werkzeug für die Implementierung von HSIC in MQL5-Handelsalgorithmen macht.
Schlussfolgerung
In diesem Artikel haben wir HSIC (Hilbert-Schmidt Independence Criterion) erörtert, eine leistungsfähige nichtparametrische Methode zur Bewertung der Beziehung zwischen Zufallsvariablen. HSIC verwendet einen Kernel-Ansatz, der es ermöglicht, komplexe nicht-lineare Beziehungen zu identifizieren, ohne dass eine explizite Modellierung der gemeinsamen Verteilungen erforderlich ist.
Die wichtigsten Vorteile von HSIC:
- arbeitet mit skalaren und vektoriellen Daten beliebiger Dimension,
- erfasst komplexe nichtlineare Abhängigkeiten,
- ist relativ einfach zu implementieren.
Allerdings hat die Methode auch ihre Grenzen:
- Empfindlichkeit gegenüber der Wahl des Parameters Kernel-Breite σ,
- Abhängigkeit vom Stichprobenumfang: Bei kleinen Stichproben kann der Permutationstest weniger aussagekräftig sein, und bei großen Stichproben ist die Berechnung der K- und L-Kernel-Matrizen recht zeitaufwändig,
- Der HSIC zeigt nur das Vorhandensein einer Beziehung an, sagt aber nichts über deren Stärke aus, anders als der Korrelationskoeffizient.
In diesem Artikel haben wir die Anwendung von HSIC auf synthetische Daten mit nichtlinearer Abhängigkeit demonstriert und bestätigt, dass HSIC Beziehungen aufdecken kann, die mit herkömmlichen Methoden wie der Pearson-Korrelation nicht erkennbar sind. Die Implementierung von HSIC in MQL5 hat seine praktische Anwendbarkeit für die Auswahl informativer Merkmale bei der Entwicklung von Handelssystemen gezeigt.
In diesem Artikel wurde die Grundversion der Methode mit einem Gaußschen Kernel vorgestellt, aber HSIC verfügt über fortgeschrittenere Fähigkeiten, einschließlich der Verarbeitung kategorischer Daten und der Prüfung bedingter Unabhängigkeit. Diese Richtungen eröffnen Perspektiven für die weitere Forschung und Anwendung der Methode bei Problemen des Handels, des maschinellen Lernens und der Datenanalyse.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/18099
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Die als Summe von iid erhaltene Reihe wird nicht abhängig, sie verliert die Eigenschaft der Stationarität und erlaubt nicht die Anwendung statistischer Kriterien.
Ich bezweifle, dass dies im Hinblick auf rechenintensive Kriterien akzeptiert werden sollte.
Wenn kein Informationsverlust vorliegt, sollten Transformationen keinen Einfluss auf das Ergebnis der Abhängigkeitsschätzung haben.
Forum über Handel, automatisierte Handelssysteme und das Testen von Handelsstrategien
Diskussion über den Artikel "Hilbert-Schmidt-Unabhängigkeitskriterium (HSIC)".
fxsaber, 2025.05.13 05:46 Uhr.
Behauptung.
Wenn wir nach der Transformation der Reihen (ohne Informationsverlust - wir können zum Ausgangszustand zurückkehren) Unabhängigkeit erhalten, dann sind die ursprünglichen Reihen unabhängig.
Ich bezweifle, dass dies im Hinblick auf rechenintensive Kriterien akzeptiert werden sollte.
Wenn kein Informationsverlust vorliegt, sollten Transformationen keinen Einfluss auf das Ergebnis der Abhängigkeitsbewertung haben.
Leider trifft dies auf die meisten statistischen Methoden zu, sowohl auf komplexe als auch auf einfachere. Das heißt, 95 % der MO-Methoden basieren auf iid-Annahmen (mit Ausnahme von ARIMA, dynamischen neuronalen Netzen, Hidden-Markov-Modellen usw.). Es ist notwendig, sich daran zu erinnern, da wir sonst Unsinn machen werden.
95 % der IO-Methoden beruhen auf iid-Annahmen
Ich vermute, dass es Versuche gibt, ein Abhängigkeitskriterium über MO zu erstellen - gleicher Ansatz, aber nur das Kriterium selbst in einer ONNX-Datei.
Ich vermute, dass es Versuche gibt, ein Abhängigkeitskriterium über MO zu erstellen - gleicher Ansatz, aber nur das Kriterium selbst in einer ONNX-Datei.
MO-Modelle lernen, eine Vorhersage zu treffen, und wenn diese Vorhersage besser ist als die "naive", dann schließen wir daraus, dass es eine Beziehung in den Daten gibt. Es handelt sich also um einen indirekten Nachweis einer Beziehung, ohne Signifikanztest. Das Unabhängigkeitskriterium wiederum macht keine Vorhersagen, sondern liefert eine statistische Bestätigung der festgestellten Abhängigkeiten. Es sind sozusagen zwei Seiten einer Medaille. Das R-Paket enthält eine Implementierung des allgemeineren dHSIC-Kriteriums. Es enthält die Implementierung, die ich für die paarweise Unabhängigkeit gegeben habe, und erweitert den Test auf die gemeinsame Unabhängigkeit.