
Eindimensionale Singularspektralanalyse

Einführung
Die Finanzmärkte zeichnen sich durch hohe Volatilität und komplexe dynamische Prozesse aus, was Prognosen und das Erkennen von Mustern äußerst schwierig macht. Die Singularspektrumsanalyse (SSA) ist ein leistungsfähiges Verfahren zur Analyse von Zeitreihen, mit dem die komplexe Struktur einer Reihe als Zerlegung in einfache Komponenten wie Trend, saisonale (periodische) Schwankungen und Rauschen dargestellt werden kann. Die SSA-Methode, die auf der linearen Algebra basiert, erfordert keine Stationaritätsannahmen, was sie zu einem universellen Instrument für die Untersuchung der Struktur von Zeitreihen macht.
Die umfangreiche Verwendung der Vektor- und Matrizenalgebra in der SSA-Literatur schafft jedoch eine relativ hohe Einstiegshürde, die es unvorbereiteten Lesern erschweren kann, das Thema zu verstehen, und sie daran hindert, alle Feinheiten und Vorteile dieser Analysemethode zu erfassen. Der Artikel zielt darauf ab, die theoretischen Grundlagen von SSA in einer zugänglichen und klaren Form darzustellen, ohne die die Methode zu einer „Black Box“ wird, und auch eine praktische Umsetzung der beschriebenen Konzepte zu bieten.
Unter dem Begriff SSA ist eine ganze Familie von Analysemethoden zu verstehen, die jedoch alle auf der sequentiellen Anwendung von vier Schritten beruhen:
- Transformation einer Zeitreihe in eine Trajektorienmatrix (Hankel-Matrix),
- Zerlegung der Trajektorienmatrix in eine Summe elementarer Matrizen vom Rang eins,
- Gruppierung von Elementarmatrizen,
- Wiederherstellung (Rekonstruktion) einer Zeitreihe.
Schauen wir uns jede dieser Phasen genauer an.
Konstruktion der Trajektorienmatrix
Die Grundidee besteht darin, eine Zeitreihe in eine Matrix umzuwandeln, die ihre Struktur im mehrdimensionalen Raum widerspiegelt. Dies geschieht, um verborgene Abhängigkeiten zwischen aufeinanderfolgenden Werten der Reihe aufzudecken. Die Trajektorienmatrix ist wie folgt aufgebaut. Eine eindimensionale Stichprobe einer Zeitreihe der Größe N wird betrachtet und in eine Menge von K Vektoren (K = N – L + 1) umgewandelt, indem gleitende Teilstichproben der Größe L (Fensterlänge) zusammengestellt werden. Die resultierenden Vektoren der Länge L(x1,x2,...,xL},{x2,x3,...,xL+1} etc.), werden als Spalten der Trajektorienmatrix X angeordnet.

Abb. 1. X-Trajektorienmatrix
Dabei bestimmt der Parameter L die Tiefe der Analyse. In der Regel wird er gleich N/2 gesetzt.
Zerlegung der Trajektorienmatrix in eine Summe von Matrizen vom Rang eins
Nach der Konstruktion der Trajektorienmatrix wird deren Zerlegung durchgeführt. Wenn die Singulärwertzerlegung (SVD) der Trajektorienmatrix als solche Zerlegung dient, spricht man von Basic-SSA.
Mithilfe der Singulärwertzerlegung werden die sogenannten Eigentripel (√λi, Ui, Vi) gebildet, mit
- σi = √λi sind singuläre Werte, die der Wurzel der Eigenwerte der XX'-Matrix entsprechen,
- Ui – linke singuläre Vektoren,
- Vi – rechte singuläre Vektoren,
- i – Index der Singulärwerte; ihre Anzahl entspricht dem Rang der Trajektorienmatrix X.
Die singulären Werte von σi zeigen das Gewicht der einzelnen Komponenten an, wobei große Werte wichtigen Mustern (Trend, Zyklen) und kleine Werte dem Rauschen entsprechen.
Mithilfe der SVD-Zerlegung kann die Trajektorienmatrix also als Summe von Xi-Elementarmatrizen des Rangs 1 dargestellt werden:

Matrizen vom Rang 1 sind die „Bausteine“, aus denen komplexere Matrizen aufgebaut werden.
Erläutern wir das Konzept des Matrix-Rangs im Zusammenhang mit der SSA-Methode. SSA zielt darauf ab, ein deterministisches Signal aus einer Zeitreihe zu extrahieren. Deterministische Sequenzen, wie z. B. eine Exponentialfunktion, ein Polynom oder ein Sinusoid, sind durch einen endlichen Rang gekennzeichnet. Dies ist darauf zurückzuführen, dass sie linearen Rekursionsbeziehungen (LRR) genügen und ihre Trajektorienmatrizen eine begrenzte Anzahl linear unabhängiger Vektoren enthalten. Zum Beispiel hat die Trajektorienmatrix einer Exponentialsequenz den Rang 1 (nur ein linear unabhängiger Vektor), ein Sinusoid hat den Rang 2, ein Polynom vom Grad (k) hat den Rang k+1, usw.
Das Skript Rang demonstriert das Konzept des Rangs für deterministische Reihen:
//+------------------------------------------------------------------+ //| Rank.mq5 | //| Eugene | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Eugene" #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs input int N = 100; // N - length of generated time series input int L = 30; // L - window length input int T = 22; // T - period length of sine function //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { matrix X=matrix::Zeros(L,N-L+1); vector x_exp= vector::Zeros(N); vector x_sinus= vector::Zeros(N); vector x_polynom= vector::Zeros(N); for(int t=0; t <N; t++) { x_exp[t] = MathPow(1.01,t); // 1. Exponential sequence: x_t = 1.01^t x_sinus[t] = MathSin(2*M_PI*t/T); // 2. Sine wave: x_t = sin(2 * pi * t / T) x_polynom[t] = 1 + t+ MathPow(t,2); // 3. Polynomial of degree 2: x_t = 1 + t + t^2 } trajectory_matrix(x_exp,L,X); Print("Rank Exponential sequence = ",Rank_SVD(X)); trajectory_matrix(x_sinus,L,X); Print("Rank Sinus sequence = ",Rank_SVD(X)); trajectory_matrix(x_polynom,L,X); Print("Rank Polynom sequence = ",Rank_SVD(X)); } //+------------------------------------------------------------------+ //| Trajectory matrix X | //+------------------------------------------------------------------+ void trajectory_matrix(vector & series,int window_length, matrix & X) { int N_ = (int)series.Size(); int L_ = window_length; int K = N_ - L_ + 1; X=matrix::Zeros(L_,K); for(int i=0; i <L_; i++) { for(int j=0; j <K; j++) { X[i,j] = series[i+j]; } } } //+------------------------------------------------------------------+ //|Finds the rank of a matrix using SVD | //+------------------------------------------------------------------+ int Rank_SVD(matrix & X) { vector sv; matrix U,V; double tol = 1e-8; // Threshold for non-zero values X.SingularValueDecompositionDC(SVDZ_N,sv,U,V); double threshold = tol * sv.Max(); int rank=0; for(int i=0; i<(int)sv.Size(); i++) { if(sv[i] > threshold) rank++; } return rank; } //+------------------------------------------------------------------+
Reale Zeitreihen wie z. B. Aktienkurse sind aufgrund des Vorhandenseins von Rauschen keine endlichen Rangfolgen, sodass es sich um Vollrangreihen = min(L, K) handelt. Handelt es sich bei der Reihe jedoch um die Summe eines deterministischen Signals mit endlichem Rang und Rauschen, kann die SSA-Methode dieses Signal annähernd extrahieren. Dann wird die Vorhersage nur für die deterministische Komponente durchgeführt, und das Rauschen wird verworfen. Zu diesem Zweck wird die Trajektorienmatrix (X) in elementare Matrizen vom Rang 1 zerlegt, aus denen dann komplexere Matrizen gebildet werden, die dem deterministischen Nutzsignal entsprechen. Dies ist der Kerngedanke der SSA-Methode.
Gruppierung
Bei der Gruppierung werden elementare Matrizen vom Rang 1 zu Gruppen zusammengefasst, die als unterschiedliche Komponenten der Reihe (Trend, Saisonalität, Rauschen) interpretiert werden. Eine der gebräuchlichsten Methoden ist die Gruppierung von Matrizen auf der Grundlage der Nähe der Singulärwerte der Matrix X. Nachdem m disjunkte Gruppen von I bestimmt wurden, kann die Zerlegung der Trajektorienmatrix X wie folgt dargestellt werden

Zum Beispiel:
- Itrend = {1} – für einen Trend,
- Iseasonal = {2,3} – für eine Saisonalität,
- Inoise = {4....,i} – für Rauschen,
wobei i = Anzahl der Singulärwerte.
Die grafische Darstellung der linken Singulärvektoren ist nützlich, um das Vorhandensein eines deterministischen Signals visuell zu beurteilen. Enthält eine Zeitreihe beispielsweise einen Trend, so zeigt der entsprechende Singulärvektor eine sich gleichmäßig verändernde Trajektorie. Bei Vorhandensein einer periodischen Komponente ähnelt das Paar singulärer Vektoren (da das periodische Signal Rang 2 hat) Sinuskurven. Singuläre Vektoren, die visuell dem gaußschen weißen Rauschen ähneln und mit kleinen Singulärwerten verbunden sind, entsprechen der Rauschkomponente. Diese Eigenschaften ermöglichen eine Gruppierung der Komponenten auf der Grundlage einer visuellen Analyse der singulären Vektoren.
Wiederherstellung (Rekonstruktion) einer Zeitreihe
Der nächste Schritt ist die Umwandlung jeder sich ergebenden gruppierten Matrix in eine neue Zeitreihe der Länge N durch diagonale Mittelwertbildung:
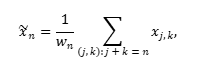
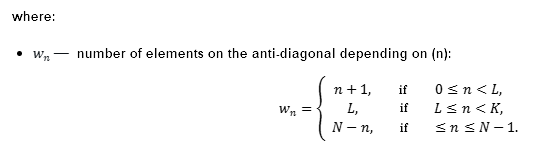
während xj und k die Elemente der gruppierten (oder elementaren) Matrix sind.
Die auf diese Weise rekonstruierten Zeitreihen repräsentieren jeweils entweder den Trend oder die periodische Komponente. Die Summe dieser Reihen ist ein nichtparametrisches Modell der ursprünglichen Zeitreihe, das von der Fensterlänge L und der Methode der Gruppierung der Elementarmatrizen abhängt. In diesem Fall wird die Summe aller rekonstruierten Reihen (einschließlich Rauschen) die ursprüngliche Zeitreihe vollständig wiederherstellen.
Vorhersage
Die Vorhersage der Werte der gi-Zeitreihen für M Schritte in der SSA-Methode erfolgt auf der Grundlage der rekonstruierten Reihen unter Verwendung der linearen Rekurrenzgleichung:

wobei:
- aj – Koeffizienten der LRR (Lineare Rekurrenzrelation)
- fi – rekonstruierte Zeitreihenwerte.
Der Koeffizientenvektor aj wird auf der Grundlage von Singulärvektoren (U_i) bestimmt:

wobei:
- First – die ersten 𝐿 – 1 Koordinaten des Ui-Singulärvektors,
- Last – die letzte Koordinate des Ui-Singulärvektors,
- 𝑑 – Anzahl der ausgewählten singulären Vektoren, die das Nutzsignal darstellen
Toeplitz-SSA
Es gibt eine weitere Variante der SSA, die sich vom traditionellen Ansatz unterscheidet. Im Gegensatz zur klassischen SSA, die eine Trajektorienmatrix auf der Grundlage eines gleitenden Fensters der Zeitreihe verwendet, konstruiert Toeplitz-SSA eine Autokovarianzmatrix mit Toeplitz-Struktur (daher der Name der Methode). Danach wird eine SVD-Zerlegung für die Autokovarianzmatrix durchgeführt. Die Gruppierungsmethode, die diagonale Mittelwertbildung, die Ermittlung der LRR-Koeffizienten und die Vorhersage werden genau so durchgeführt wie bei der Basic-SSA-Variante.
Toeplitz-SSA eignet sich besser für die Analyse stationärer Zeitreihen (es ergibt einen kleineren Vorhersagefehler im Vergleich zur Basisvariante). Bei nicht-stationären Reihen zeigt die klassische SSA jedoch bessere Ergebnisse. Da wir es auf den Aktienmärkten mit nicht-stationären Prozessen zu tun haben, habe ich beschlossen, mich in diesem Artikel auf den Basisalgorithmus zu beschränken.
Beispiel einer Basic-SSA-Analyse
Kommen wir nun von der Theorie zur praktischen Umsetzung der beschriebenen Konzepte in der Sprache MQL5. Zu diesem Zweck wurde ein Skript erstellt, das vier synthetische Zeitreihen erzeugt:
- Sinus + gaußsches weißes Rauschen,
- linearer Trend + Sinus + gaußsches weißes Rauschen,
- symmetrischer gaußscher Random Walk, gaußsches weißes Rauschen.
Diese Serien weisen die folgenden Merkmale auf:
- Die erste Reihe ist stationär, mit einer periodischen Komponente,
- Die zweite ist nicht stationär, mit einem deterministischen Trend und einer periodischen Komponente,
- Die dritte ist eine nicht-stationäre Reihe mit einem stochastischen Trend,
- Die vierte Reihe ist stationäres weißes Rauschen.
Diese Modelle decken teilweise das Spektrum der in der Praxis vorkommenden Zeitreihen ab.
Das Skript generiert eine synthetische Reihe Ihrer Wahl und führt die oben beschriebenen Schritte nacheinander aus und zeigt außerdem folgende Grafiken auf dem Bildschirm an:
- generierten Daten,
- relative singuläre Werte (der Anteil der Varianz jedes singulären Tripels),
- die ersten beiden singulären Vektoren,
- Streudiagramm der ersten beiden singulären Vektoren,
- Datenreihen + ihre Rekonstruktion + Vorhersage,
- Rekonstruktion + Prognose mit der Funktion MQL5SingularSpectrumAnalysisForecast.
Der Graph der relativen singulären Spektralwerte (der Anteil des Quadrats des singulären Werts an der Summe der Quadrate aller singulären Werte von σi^2/∑ σj^2 – Abb. 2) ermöglicht es uns, die Art der in der Zeitreihe vorhandenen Komponenten zu bestimmen und die Anzahl der singulären Tripel für die Signalrekonstruktion auszuwählen. In der Regel werden die Komponenten vor dem Punkt des starken Rückgangs (dem so genannten „Ellbogen“ im Diagramm) ausgewählt.
Bei einer periodischen Komponente sollten zwei Singulärwerte ähnlicher Größenordnung auftreten. Es kann auch ein Plateau gefolgt von einem Rückgang geben. Dies bedeutet das Vorhandensein mehrerer harmonischer Komponenten (Sinuswellen mit unterschiedlichen Frequenzen), gefolgt von Rauschen.
Eine gleichmäßige Abnahme der Spektralwerte deutet auf das Fehlen eines deterministischen Signals hin.

Abb. 2. Relatives Spektrum, Sinus+Rauschen
An dieser Stelle sei auf den Nachteil der SSA hingewiesen, der darin besteht, dass sie nicht in der Lage ist, einen stochastischen Trend von einem deterministischen Trend zu unterscheiden. Bei einer Random-Walk-Reihe gibt es zum Beispiel nur eine ausgeprägte Komponente, die für den Trend verantwortlich ist. Aber wir alle wissen, dass dieser Trend zufällig und unvorhersehbar ist. Um speziell diesen Fall zu testen, habe ich Random-Walk-Daten einbezogen.
Nach der Identifizierung einiger der größten Singulärwerte ist es nützlich, die Graphen der entsprechenden linken Singulärvektoren zu untersuchen (Abb. 3). Bei einem periodischen Signal, das mit Rauschen vermischt ist, haben die ersten beiden Singulärvektoren, die mit den größten Singulärwerten verbunden sind, in der Regel eine Form, die einer Sinus- oder Kosinuswelle ähnelt, was die periodische Natur des Signals widerspiegelt.

Abb. 3. Die ersten beiden Singulärvektoren, Sinus+Rauschen
Zusätzlich kann man ein Streudiagramm für ein Paar von Singulärvektoren erstellen, wobei der erste Singulärvektor (U1) auf der X-Achse und der zweite (U2) auf der Y-Achse aufgetragen wird (Abb. 4).

Abb. 4. Streudiagramm der ersten beiden Singulärvektoren, Sinus+Rauschen
Wenn die Daten zyklische Komponenten enthalten, nimmt das Streudiagramm oft die Form einer Ellipse oder eines Kreises an, was die sinusförmige Natur des Signals bestätigt. Dies liegt daran, dass ein Paar von Singulärvektoren für eine periodische Komponente zwei orthogonalen Harmonischen entspricht (z. B. Sinus und Kosinus). Wenn die Punkte in einem Streudiagramm eine chaotische Wolke ohne klare geometrische Struktur bilden, deutet dies auf das Fehlen einer ausgeprägten periodischen oder deterministischen Komponente hin.
Abb. 5 zeigt eine synthetische Zeitreihe aus Sinus + Rauschen, ihre Rekonstruktion und eine 100-Schritte-Vorhersage. Die visuelle Erkennung des Vorhandenseins eines periodischen Signals in den Originaldaten ist aufgrund des starken Rauschens schwierig, aber SSA extrahiert die periodische Komponente effektiv. Natürlich ist dies ein sehr einfaches Beispiel, und ein so klares Bild ist bei echten Finanzdaten selten. Die SSA bietet jedoch eine hervorragende Gelegenheit, die Hypothese des Vorhandenseins von Preiszyklen zu bestätigen oder zu widerlegen.

Abb. 5. Sinus+Rauschen Vorhersage der Zeitreihe
SSA-Implementierung in MQL5
Sehen wir uns die bestehenden Implementierungen von SSA in MQL5 an. Das Terminal wird mit der Funktion SingularSpectrumAnalysisForecast aus dem Abschnitt Matrix and Vector Methods von OpenBLAS geliefert. Aus der Beschreibung dieser Funktion war mir nicht ganz klar, welche Art von SSA sie implementiert.
Ursprünglich nahm ich an, dass es sich um eine Variante von Toeplitz-SSA handelt, die auf der Zerlegung der Autokovarianzmatrix beruht. Da aber die Ergebnisse der Vorhersage und der Rekonstruktion der Reihe mit dem Basic-SSA-Skript und der Funktion SingularSpectrumAnalysisForecast vollständig übereinstimmen, liegt vermutlich ebenfalls eine Implementierung des Basisalgorithmus vor. Als Beispiel möchte ich ein Diagramm der Vorhersage der Trend+Sinus+Rauschen-Reihe für drei Hauptkomponenten zeigen (Abb. 6). Die analysierte Reihe besteht aus 200 Werten, und wir erstellen eine Prognose für 100 Schritte im Voraus.

Abb. 6. MQL5 vs Basic-SSA Rekonstruktion und Prognoseserien
Um die Trajektorienmatrix zu zerlegen, habe ich die Funktion SingularValueDecompositionDC aus demselben OpenBLAS-Abschnitt verwendet, da die Entwickler den „Divide-and-Conquer“-Algorithmus als den schnellsten unter den anderen SVD-Algorithmen bezeichnen. Es ist sehr praktisch, dass wir mit dieser Funktion sowohl vollständige als auch abgeschnittene Matrizen von singulären Vektoren berechnen können.
Basic-SSA-Skriptcode:
//+------------------------------------------------------------------+ //| Basic-SSA.mq5 | //| Eugene | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Eugene" #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <Math\Stat\Stat.mqh> #include <Graphics\Graphic.mqh> enum SimpleData { SinusPlusNoise, Trend_Sinus_Noise, RandomWalk, WhiteNoise, }; input int L = 30; // L - window length input int N = 200; // N - length of generated time series input int T = 22; // T - period length of sine function input int fs = 100; // fs - forecast horizon input int r_ = 2; // r - singular components input SimpleData sd = SinusPlusNoise; // Data //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { int err; vector x = vector::Zeros(N); // time series double x_array[]; double original_series[]; //------------1. Data -------------------- //------------------ sinus + noise --------- if(sd == SinusPlusNoise) { for(int i=0; i <N; i++) { x[i] = MathSin(2*M_PI*(i+1)/T) + MathRandomNormal(0,1,err); } VectortoArray(x,x_array); ArrayCopy(original_series,x_array,0,0,WHOLE_ARRAY); PlotGraphic(x_array,5,1); } //------------------trend + sinus + noise ---- if(sd == Trend_Sinus_Noise) { for(int i=0; i <N; i++) { x[i] = 0.05 * i + MathSin(2*M_PI*(i+1)/T) + MathRandomNormal(0,1,err); } VectortoArray(x,x_array); ArrayCopy(original_series,x_array,0,0,WHOLE_ARRAY); PlotGraphic(x_array,5,1); } //-------------- random walk ----------------- if(sd == RandomWalk) { x[0]=100; for(int i=1; i <N; i++) { x[i] = x[i-1] + MathRandomNormal(0,1,err); } VectortoArray(x,x_array); ArrayCopy(original_series,x_array,0,0,WHOLE_ARRAY); PlotGraphic(x_array,5,1); } //-------------- white noise ----------------- if(sd == WhiteNoise) { for(int i=0; i <N; i++) { x[i] = MathRandomNormal(0,1,err); } VectortoArray(x,x_array); ArrayCopy(original_series,x_array,0,0,WHOLE_ARRAY); PlotGraphic(x_array,5,1); // white noise graph } //------------2. Trajectory matrix ------------------- matrix X; trajectory_matrix(x,L,X); //-------------3. Singular decomposition (SVD) ---- matrix U, V; vector singular_values; X.SingularValueDecompositionDC(SVDZ_A,singular_values,U,V); V = V.Transpose(); double total_variance; vector powv = singular_values*singular_values; total_variance = powv.Sum(); VectortoArray(powv/total_variance,x_array); PlotGraphic(x_array,5,2); // Singular spectrum graph double x_1[],x_2[]; VectortoArray(U.Col(0),x_1); VectortoArray(U.Col(1),x_2); PlotGraphic(x_1,x_2,5,3); // graph of the first two singular vectors PlotGraphic(x_1,x_2,5,4); // scatterplot of the first two singular vectors //---------- 4. Time series reconstruction---- int K = N - L + 1; matrix X_i = matrix::Zeros(L,K); matrix Ui = matrix::Zeros(L,1); matrix Vi = matrix::Zeros(1,K); vector x_tilde; vector recon_series = vector::Zeros(N); for(int i=0; i<r_;i++) { Ui.Col(U.Col(i),0); Vi.Row(V.Col(i),0); X_i = (Ui.MatMul(Vi))*singular_values[i]; // rank one matrices diagonal_averaging(X_i,x_tilde); recon_series = recon_series + x_tilde; // reconstructed series } double recon[]; VectortoArray(recon_series,recon); //------------5. LRR ratio vector -------------------- matrix U_r = U; U_r.Resize(L,r_); // r left singular vectors vector a = vector::Zeros(L-1); // vector a of LRR ratios double denom =0; vector u_k; double last; for(int k=0; k<r_;k++) { u_k = U_r.Col(k); // k th singular vector last = u_k[L-1]; u_k.Resize(L-1); a = a + last*u_k; denom = denom + MathPow(last,2); } denom = 1 - denom; a = a/denom; // vector a of LRR ratios //----------------- 6. Forecast using LRR ratios ----------- int forecast_steps = fs; double forecast[]; ArrayResize(forecast,forecast_steps); double fi[]; ArrayCopy(fi,recon,0,N-L+1,L-1); for(int i=0;i<forecast_steps;i++) { double sum = 0.0; for(int j = 0; j < L-1; j++) { sum += a[j] * fi[j]; } forecast[i]= sum; // Forecast // Update fi ArrayCopy(fi, fi, 0, 1, ArraySize(fi)-1); // Shift to the left fi[L-2] = forecast[i]; // Add a new value } double originalplusforecast[]; ArrayResize(originalplusforecast,N+forecast_steps); ArrayCopy(originalplusforecast,original_series,0,0,WHOLE_ARRAY); ArrayCopy(originalplusforecast,forecast,N,0,WHOLE_ARRAY); double reconstructedplusforecast[]; ArrayResize(reconstructedplusforecast,N+forecast_steps); ArrayCopy(reconstructedplusforecast,recon,0,0,WHOLE_ARRAY); ArrayCopy(reconstructedplusforecast,forecast,N,0,WHOLE_ARRAY); PlotGraphic(originalplusforecast,reconstructedplusforecast,15,5); //---- reconstructed data and forecast using the SingularSpectrumAnalysisForecast function vector MQLreconforecast; x.SingularSpectrumAnalysisForecast(L,r_,forecast_steps,MQLreconforecast); double MQL_RF[]; VectortoArray(MQLreconforecast,MQL_RF); PlotGraphic(reconstructedplusforecast,MQL_RF,10,6); } //+------------------------------------------------------------------+ //| Plot Graphic | //+------------------------------------------------------------------+ void PlotGraphic(double &data[], int sec, int n_graph) { ChartSetInteger(0,CHART_SHOW,false); CGraphic graphic; ulong width = ChartGetInteger(0,CHART_WIDTH_IN_PIXELS); ulong height = ChartGetInteger(0,CHART_HEIGHT_IN_PIXELS); if(ObjectFind(0,"Graphic")<0) graphic.Create(0,"Graphic",0,0,0,int(width),int(height)); else graphic.Attach(0,"Graphic"); string st; if(sd == SinusPlusNoise) { st = "Sinus + Noise"; } if(sd == Trend_Sinus_Noise) { st = "Trend + Sinus + Noise"; } if(sd == RandomWalk) { st = "Random Walk"; } if(sd == WhiteNoise) { st = "White Noise "; } if(n_graph==1) // data graph { CCurve *curve = graphic.CurveAdd(data,ColorToARGB(clrRed,255),CURVE_LINES,st); graphic.XAxis().Name("Series " + st); graphic.BackgroundMain(st); } if(n_graph==2) // chart of singular values (relative_variance = sigma_i^2/Sum Sigma_j^2) { CCurve *curve = graphic.CurveAdd(data,ColorToARGB(clrBlue,255),CURVE_LINES,st); graphic.XAxis().Name("Index "); graphic.YAxis().Name("Singular values "); graphic.BackgroundMain("Singular values " + st); } graphic.XAxis().NameSize(18); graphic.YAxis().NameSize(18); graphic.BackgroundMainColor(ColorToARGB(clrBlack,255)); graphic.BackgroundMainSize(24); graphic.CurvePlotAll(); graphic.Update(); Sleep(sec*1000); ChartSetInteger(0,CHART_SHOW,true); graphic.Destroy(); ChartRedraw(0); } //+------------------------------------------------------------------+ //| Plot Graphic | //+------------------------------------------------------------------+ void PlotGraphic(double &data1[],double &data2[], int sec,int n_graph) { ChartSetInteger(0,CHART_SHOW,false); CGraphic graphic; ulong width = ChartGetInteger(0,CHART_WIDTH_IN_PIXELS); ulong height = ChartGetInteger(0,CHART_HEIGHT_IN_PIXELS); if(ObjectFind(0,"Graphic")<0) graphic.Create(0,"Graphic",0,0,0,int(width),int(height)); else graphic.Attach(0,"Graphic"); if(n_graph==3) { CCurve *curve = graphic.CurveAdd(data1,ColorToARGB(clrRed,255),CURVE_LINES,"first"); CCurve *curve1 = graphic.CurveAdd(data2,ColorToARGB(clrBlue,255),CURVE_LINES,"second"); graphic.XAxis().Name(" "); graphic.BackgroundMain("first and second singular vectors"); } if(n_graph==4) // scatter plot of singular vectors { CCurve *curve = graphic.CurveAdd(data1,data2,ColorToARGB(clrRed,255),CURVE_LINES,"first"); graphic.XAxis().Name("first singular vector"); graphic.YAxis().Name("second singular vector"); graphic.BackgroundMain("Scatter plot of singular vectors U_1 vs U_2"); } if(n_graph==5) // data chart plus forecast { CCurve *curve = graphic.CurveAdd(data1,ColorToARGB(clrBlue,255),CURVE_LINES,"original"); CCurve *curve1 = graphic.CurveAdd(data2,ColorToARGB(clrRed,255),CURVE_POINTS_AND_LINES,"reconstructed"); graphic.XAxis().Name("Time "); graphic.YAxis().Name("Value "); graphic.BackgroundMain("Original(Blue) + reconstructed(Red) + forecast(Red) "); curve1.PointsSize(3); } // graph comparing the forecast of the MQL5 SingularSpectrumAnalysisForecast function with the Basic-SSA forecast if(n_graph==6) { CCurve *curve = graphic.CurveAdd(data1,ColorToARGB(clrBlue,255),CURVE_LINES,"BasicSSA"); CCurve *curve1 = graphic.CurveAdd(data2,ColorToARGB(clrRed,255),CURVE_LINES,"MQL5"); graphic.XAxis().Name("reconstructed + forecast "); graphic.BackgroundMain(" MQL5 SingularSpectrumAnalysisForecast vs script Basic-SSA "); curve1.PointsSize(3); } graphic.XAxis().NameSize(18); graphic.YAxis().NameSize(18); graphic.BackgroundMainColor(ColorToARGB(clrBlack,255)); graphic.BackgroundMainSize(24); graphic.CurvePlotAll(); graphic.Update(); Sleep(sec*1000); ChartSetInteger(0,CHART_SHOW,true); graphic.Destroy(); ChartRedraw(0); } //+------------------------------------------------------------------+ //| Copy the vector into an array | //+------------------------------------------------------------------+ void VectortoArray(vector &v, double &array[]) { int v_size = (int)v.Size(); ArrayResize(array,v_size); for(int i=0; i<v_size; i++) { array[i] = v[i]; } } //+------------------------------------------------------------------+ //| Trajectory matrix X | //+------------------------------------------------------------------+ void trajectory_matrix(vector & series,int window_length, matrix & X) { int N_ = (int)series.Size(); int L_ = window_length; int K = N_ - L_ + 1; X=matrix::Zeros(L_,K); for(int i=0; i <L_; i++) { for(int j=0; j <K; j++) { X[i,j] = series[i+j]; } } } //+-------------------------------------------------------------------+ //| Diagonal averaging of a matrix | //| Input: Xi - matrix L x K (elementary matrix of the i th component)| //| Output: x_tilde - reconstructed time series | //+-------------------------------------------------------------------+ void diagonal_averaging(matrix &Xi,vector &x_tilde) { int L_ = (int)Xi.Rows(); int K = (int)Xi.Cols(); int N_ = L_ + K - 1; // Length of the original time series x_tilde = vector::Zeros(N_); double total; // Sum of elements on the anti diagonal int w_n; // Number of elements on the anti diagonal int k; for(int n=0; n < N_; n++) { total = 0; w_n = 0; for(int j=0; j <L_; j++) { k = n - j ; // Column index: n = j + k ---> k = n - j if(k >= 0 && k < K) // Check that the index is within the matrix { total = total + Xi[j, k]; w_n = w_n + 1; } } x_tilde[n] = total / w_n; // Averaging } } //+------------------------------------------------------------------+
Schlussfolgerung
In diesem Artikel haben wir die Grundlagen der Singulärspektralanalyse (SSA) behandelt, einer Methode, die die Singulärwertzerlegung (SVD) einer Trajektorienmatrix verwendet, um verborgene Strukturen in Daten aufzudecken. Wir haben gezeigt, wie SSA eine Zeitreihe effektiv in interpretierbare Komponenten – Trend, Saisonalität und Rauschen – zerlegt und damit ihre Rekonstruktion und Vorhersage ermöglicht.
Die Methode hat jedoch ihre Grenzen, insbesondere die Unfähigkeit, zuverlässig zwischen deterministischen und stochastischen Trends wie einem Gaußschen Random Walk zu unterscheiden. Gleichzeitig ist anzumerken, dass SSA nicht darauf abzielt, Trends streng statistisch zu klassifizieren; seine Stärke liegt in seiner flexiblen Zerlegung und Identifizierung der Datenstruktur, was ihm gut gelingt.
Die Anwendung von SSA ist nicht auf die Analyse univariater Zeitreihen beschränkt. Die Methode ermöglicht die Arbeit mit mehrdimensionalen Daten. Sie kann dazu verwendet werden, einen Indikator zur Erkennung von Strukturbrüchen zu konstruieren, um plötzliche Veränderungen im Verhalten von Finanzinstrumenten zu erkennen. Diese Richtungen stellen vielversprechende Bereiche für die künftige Forschung dar, da ein genaues Verständnis der Art der Daten entscheidend für die Ermittlung von Marktmustern ist.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17845
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Um es kurz zu machen: "dieses" Thema ist in vielen Artikeln (z. B. 1, 2) und Diskussionen aufgetaucht, ganz zu schweigen von verwandten Ansätzen wie EMD (und einige Autoren haben in ihren Studien festgestellt, dass die Kombination von SSA und EMD die Ergebnisse verbessert).