
机器学习中的高斯过程:MQL5中的回归模型

引言
高斯过程(GP)是一种贝叶斯非参数建模框架,在机器学习中被广泛用于回归与分类任务。传统多数模型仅输出单点预测值,而高斯过程能够给出预测值的完整概率分布。这意味着模型不仅能给出预测数值,还能量化预测的不确定性,通常以预测区间的形式呈现。这正是贝叶斯方法的核心特色:融合先验知识与观测数据,最终得到预测分布。
高斯过程属于核方法,依靠协方差函数(核函数)刻画数据之间的关联关系。我们可以通过相加、相乘等方式组合不同核函数,灵活拟合各类潜在预测函数。每种核函数都包含超参数,需要优化取值以最大化模型精度。
本文将详细讲解高斯过程回归的完整预测流程,清晰展示高斯过程如何在生成预测的同时评估其不确定性。
什么是高斯过程?
从概率视角来看,高斯过程是一类随机过程,用于描述函数的概率分布。普通正态分布仅描述单个随机变量,而高斯过程定义一组随机变量,其中任意有限子集均服从多元正态分布。
在机器学习领域,高斯过程属于非参数模型,无需提前预设函数形式(例如经典回归里的线性、多项式形式)。高斯过程会建模一个潜在隐函数f(x) ,假定该函数能够刻画数据中的真实依赖关系。但隐函数f(x)无法直接观测,我们只能获取若干自变量x处叠加噪声后的观测值。高斯过程模型的基本假设 —— 未知隐函数f(x)服从正态分布:
f (x)~ N( μ, Σ),
其中:
- f(x) —— 待拟合的隐函数,我们希望刻画其在观测点上的取值;
- μ —— 均值向量,由先验均值函数决定(为简化计算常直接取0);
- Σ —— 协方差矩阵,矩阵元素由协方差函数(核函数)K(x, x')计算得出,代表两点x与x'之间的相关程度。
高斯过程的关键思路:通过核函数定义的协方差结构刻画函数分布,核函数直接决定函数的光滑度、周期性、非平稳性等特征。
高斯过程的主要目标:基于有限数据集D=(X,y)还原隐函数f(x),其中,X为特征集合,y为带噪声的观测标签。
高斯过程中的贝叶斯(Bayesian)方法
高斯过程采用贝叶斯统计推断逻辑,融合先验信息与观测数据来输出概率化预测。这一点区别于神经网络、支持向量机等多数机器学习算法 —— 高斯过程既能输出预测值,又能量化预测不确定性。整套推导基于贝叶斯定理:

其中:
- P(H) —— 先验概率,观测数据前对假设 H 的初始概率,代表先验认知;
- P(D|H) —— 似然,给定假设H时观测到数据集D的概率;
- P(H|D) —— 后验概率,观测数据D之后假设H成立的概率;
- P(D) —— 数据边缘概率(归一化常数),保证后验分布满足概率定义。
落实到高斯过程场景中,贝叶斯方法的应用如下:假设H代表能够生成训练样本的函数分布f(x),数据集D即训练集(X, y)。
在高斯过程下,贝叶斯定理表达形式如下:
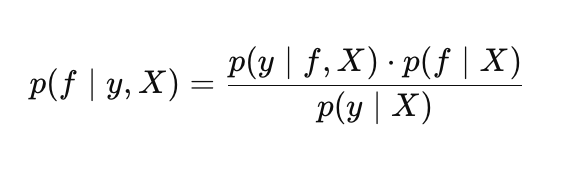
其中:
- p(f |X) —— 函数f的先验分布;
- p(y |f, X) —— 似然;
- p(f |y, X) —— 函数f的后验分布;
- p(y |X) —— 边缘似然(证据),用于高斯过程超参数优化。
先验分布
先验分布描述了在观测数据前,我们对潜在函数形式的初始假设。本质上,先验是一组候选函数,高斯过程会基于训练数据从中筛选出最贴合的函数。核函数是决定这些函数特征的核心。核函数种类繁多,适用于不同数据类型,例如:
RBF核(高斯核)用于拟合光滑的非线性函数:

其中:
- σ_f —— 幅值,控制函数波动幅度(代码中对应params.rbf.sigma_f);
- l —— 长度尺度,控制相关性衰减速度(代码中对应params.rbf.length);
- ∥x−x′∥—— 点x与x'之间的欧氏距离。
线性核用于拟合线性依赖关系:
![]()
- x*x' —— 两个向量的点积;
- σ_l —— 线性趋势幅度(代码中对应params.linear.sigma_l)。
周期核用于捕捉周期性规律:

- σ_f —— 振幅,控制波动幅度(代码中对应params.periodic.sigma_f);
- l —— 尺度长度,控制波动的平滑程度(代码中对应params.periodic.length);
- p —— 周期,决定波动重复频率(代码中对应params.periodic.period)。
为了直观理解先验分布,可以观察不同核函数生成的隐函数f(x)采样曲线。图例1展示了采用RBF核的先验分布采样结果。曲线均为光滑非线性函数,形态随核参数变化。

图例1:高斯过程先验分布下的函数采样(RBF核)
图例2展示了线性核的先验分布采样结果。曲线为斜率各不相同的直线,体现该核拟合线性趋势的特性。

图例2. 高斯过程先验分布的函数采样(线性核)
图例3展示了周期核生成的采样函数。曲线为周期等于p的循环函数,因此该核非常适合建模周期性成分。

图例3. 高斯过程先验分布的函数采样(周期核)
图例4展示了维纳(Wiener)过程曲线,其协方差函数定义为K(x,x') = min(x, x')。

图例4. 采用维纳过程协方差函数的高斯过程先验分布函数采样
高斯过程具备灵活性的核心原因在于可以对核函数进行组合(相加或相乘),以此拟合具备多种特征的函数,例如线性趋势与非线性趋势叠加、周期性波动组合等。文中所有采样曲线均由脚本SamplesPrior生成。似然
在高斯过程中,似然p(y |f, X)描述了在给定先验分布中的某一隐函数f与输入数据集X时,观测到标签数据y的概率。它是贝叶斯推断的核心环节,搭建起函数先验分布与真实观测数据之间的关联。对于完整数据集,似然服从多元正态分布。

其中:
- f(x) —— 隐函数在观测点X上的取值向量;
- σy^2 —— 噪声方差;
- ∥y−f(x)∥^2 —— 观测数据与隐函数取值之差的欧几里得范数平方。
后验分布
后验分布是在给定观测数据后,结合似然对先验分布进行贝叶斯更新得到的结果。它描述了隐函数f(x)在新测试点X*上的取值分布。该分布的特征在于:μ*为更新后的均值,即模型预测值;Σ*为协方差矩阵,用于衡量预测的不确定性。
简言之,先验分布给出候选函数集,似然依据数据对其进行加权,后验分布则给出最可信的函数及其不确定性估计。
基于高斯似然的高斯过程回归
搭配高斯观测噪声的高斯过程,可以通过线性代数方法解析求解回归问题,大幅简化计算,无需使用复杂数值算法。高斯过程既可拟合含噪声数据,也可处理无噪声数据。我们先从理想场景入手:目标值y是函数的无噪声真实值,即y = f(x)(插值场景)。
无噪声情形:插值
假设我们有数据集:D = {(xn, yn) : n = 1 : N},其中, yn = f(xn)是函数f在点xn处的精确无噪声观测。我们的任务是对大小为N*×d的测试集X*预测函数值f*。
对训练点X和测试点X*,函数值f与 f*的联合先验分布服从多元正态分布:

其中:
- f —— 隐函数在训练点上的真实值向量;
- f* —— 隐函数在测试点上的真实值向量;
- m(X) —— 训练点对应的函数均值向量(为简化计算通常取零向量);
- m(X*) —— 测试点对应的函数均值向量(为简化计算通常取零向量);
- K(X,X) —— 所有训练点两两之间的协方差矩阵,大小为NxN;
- K(X,X*) —— 训练点与测试点之间的协方差矩阵,大小为NxN*;
- K(X*,X*) —— 所有测试点两两之间的协方差矩阵,大小为N*xN*;
- N —— 训练样本点数量;
- N* —— 测试样本点数量;
- d —— 输入数据维度(特征数量)。
在本场景中,观测值y与隐函数f的真实值完全一致(即y=f),似然为狄拉克δ函数,因此可以直接推导在给定y的条件下f*的条件分布。根据多元正态分布的条件分布性质,在已知观测数据y时,f*的后验分布为:

其中:
- μf* —— 后验均值,基于训练数据对新测试点上隐函数f*取值的最优预测;
- Σf* —— 测试点的后验协方差矩阵,用于量化隐函数f*预测值的不确定性。
含噪声情形:回归问题
在实际问题中,观测数据y通常包含不可预测的噪声:y=f(X)+ϵ,其中ϵ∼N(0,σ^2)为高斯噪声。在此情况下,高斯过程不会严格插值训练数据(即不会精确穿过每一个点),而是在考虑预期噪声水平的前提下对数据进行平滑拟合。含噪声数据对应的后验分布,需通过在训练数据协方差矩阵的对角元素上加入噪声方差进行修正:

噪声参数σ属于模型超参数,会与核函数参数一同进行优化。
有一点至关重要:引入噪声项后,我们不仅能为隐函数f*计算预测区间,还能对新观测值y*给出预测区间。无噪声场景下,f*与y*的预测分布完全一致;但加入噪声后,二者分布不再相同,核心差异体现在协方差矩阵上。Σf*仅体现测试点处隐函数自身的不确定性;Σy*则同时包含隐函数的不确定性与观测噪声方差。
")
- μy* —— 新观测值y*的后验均值,由于噪声期望为0,该均值与μf*相等;
- Σy* —— 新观测值y*的后验协方差。
为了直观地展示高斯过程对数据的拟合效果,我们可以绘制无噪声条件下,从后验分布中采样得到的多条隐函数f曲线。图例5展示了基于5个训练样本、采用RBF核函数拟合得到的三条隐函数曲线。

图例5. 从后验分布中采样得到的函数f样本(RBF核,无噪声)
在观测任何数据之前,高斯过程给出的先验分布描述了无穷多组可能的函数。加入训练数据后,后验分布会对这一集合进行约束,只保留严格穿过观测点的函数。换言之,模型会只聚焦于能精确插值训练数据的函数。
在训练点X处,方差(后验协方差矩阵Σ*的对角元素)为0,意味着在这些点上不存在不确定性:从后验分布中采样的所有函数都必定严格穿过训练点。在训练点之外,函数可以发生变化,反映出模型在无数据区域的不确定性。然而,它们的行为变化仍由所选核函数决定,此处为RBF核。
现在来看观测数据y包含高斯噪声时,从后验分布中采样得到的函数f曲线图。(图例6)

图例6. 从后验分布中采样得到的函数f样本(RBF核,含噪声)
在存在噪声的情况下,后验函数不需要严格穿过观测数据点y。这意味着能够解释数据的可行函数范围变得更宽,它们可以在噪声允许的范围内偏离观测值。灰色虚线表示2σ预测区间,覆盖了隐函数f*后验分布约95%的概率。在远离训练数据的区域,不确定性会显著增加,预测区间也会明显变宽,表明模型在这些区域的不确定性更高。需要特别注意的是,灰色虚线表示的是隐函数f*的预测区间,而非新观测值y*的预测区间。
高斯过程超参数优化
高斯过程模型的效果高度依赖于超参数的最优选择,这能让模型更好地拟合数据,最大化其对观测规律的解释能力。这类超参数包括核函数参数与噪声方差。在高斯过程中,通过最小化负对数边缘似然(NLML)来完成超参数优化:

直接计算(K+σ^2*I)^−1*y在样本量n较大时计算成本极高,因为该操作需要对n×n矩阵求逆。因此,工程上采用乔列斯基(Cholesky)分解提升计算效率与数值稳定性。结合该分解形式,负对数边缘似然(NLML)公式可改写为:

- z —— 通过乔列斯基分解求解线性方程组得到的向量,满足z=L^−1*y;
- L —— 乔列斯基分解得到的下三角矩阵,满足K+σ^2*I = LL^T。
该公式已在负对数边缘似然(NegativeLogMarginalLikelihood)函数中封装实现。
//+------------------------------------------------------------------+ //| Calculate the negative log-likelihood | //+------------------------------------------------------------------+ double NegativeLogMarginalLikelihood(const matrix &x, const matrix &y, int &kernel_list[], KernelParams ¶ms) { int n = (int)x.Rows(); //--- Calculate the K covariance matrix matrix K = ComputeKernelMatrix(x, x, kernel_list, params); //--- Add white noise variance if KERNEL_WHITE is selected double white_noise_variance = 0.0; for (int i = 0; i < ArraySize(kernel_list); i++) { if (kernel_list[i] == KERNEL_WHITE) { white_noise_variance = params.white.sigma * params.white.sigma; break; } } // Adding a little jitter prevents problems, // if the K matrix is singular or close to singular // due to the peculiarities of the calculations or the chosen kernel double jitter = 1e-6; K += matrix::Identity(n, n) * (white_noise_variance + jitter); // ---Perform the Cholesky decomposition: K + sigma^2*I = L * L^T matrix L; if (!K.Cholesky(L)) { Print("Error: Cholesky decomposition failed"); return DBL_MAX; } //--- Solve the linear system L * z = y to find z = L^(-1) * y vector z = L.LstSq(y.Col(0)); if (z.Size() == 0) { Print("Error: Unable to solve the system L * z = y"); return DBL_MAX; } //--- Calculate the first term in the NLML equation: // 1/2 * y^T * (K + sigma^2*I)^-1 * y = 1/2 * z^T * z double data_term = 0.5 * z @ z; // Scalar product z^T * z //--- Calculate the second term: 1/2 * log|K + sigma^2*I| = sum(log(L_ii)) vector diag = L.Diag(); double log_det = 0.0; for (int i = 0; i < n; i++) log_det += MathLog(diag[i]); // sum the logarithms of the L diagonal elements //--- Calculate the third term: n/2 * log(2π) double const_term = 0.5 * n * MathLog(2 * M_PI); return data_term + log_det + const_term; }
协方差矩阵K通过ComputeKernelMatrix函数计算,该函数会对所有选定核函数(如RBF、线性核、周期核等)的贡献进行求和。
//+------------------------------------------------------------------+ //| Calculate the covariance matrix | //+------------------------------------------------------------------+ matrix ComputeKernelMatrix(const matrix &X1, const matrix &X2, int &kernel_list[], KernelParams ¶ms) { matrix K = matrix::Zeros(X1.Rows(), X2.Rows()); for (int i = 0; i < ArraySize(kernel_list); i++) { switch (kernel_list[i]) { case KERNEL_RBF: K += RBF_kernel(X1, X2, params.rbf.sigma_f, params.rbf.length); break; case KERNEL_LINEAR: K += Linear_kernel(X1, X2, params.linear.sigma_l); break; case KERNEL_PERIODIC: K += Periodic_kernel(X1, X2, params.periodic.sigma_f, params.periodic.length, params.periodic.period); break; case KERNEL_WHITE: // WhiteKernel is added separately as sigma^2 * I break; } } return K; }
NLML在OptimizeGP函数中作为超参数优化的目标函数。优化过程通过ALGLIB库中的BLEIC算法实现。
//+------------------------------------------------------------------+ //| Gaussian process hyperparameter optimization | //+------------------------------------------------------------------+ KernelParams OptimizeGP(int &kernel_list[], matrix &x_train, matrix &y_train) { double w[]; // Array of initial hyperparameter values double s[]; // Array of scales for hyperparameters used for normalization in optimization double bndl[], bndu[]; // Arrays of lower and upper bounds for each hyperparameter CObject Obj; CNDimensional_GP ffunc(kernel_list, x_train, y_train);// Object of a class implementing the NLML target function CNDimensional_Rep frep; // Object for storing the optimization report // Initialize parameters InitializeKernelParams(kernel_list, w, s, bndl, bndu); /* The total number of parameters (num_params) is calculated depending on the kernel types in kernel_list. The initial values of the w parameters, scale and bounds for the parameters are set */ CMinBLEICStateShell state; CMinBLEICReportShell rep; // Object for storing optimization results. double epsg = 0; // Gradient precision (0 means gradient stopping is disabled) double epsf = 0.0001; // Precision by function value double epsw = 0; // accuracy by parameters double diffstep = 0.0001; // Step for numerical calculation of derivatives. double epso = 0.00001; // Parameters for external and internal convergence conditions in BLEIC double epsi = 0.00001; CAlglib::MinBLEICCreateF(w, diffstep, state); // Create a BLEIC optimization object with w initial parameters and diffstep for numerical derivatives CAlglib::MinBLEICSetBC(state, bndl, bndu); // Set parameter bounds (bndl, bndu). CAlglib::MinBLEICSetScale(state, s); // Sets the scale of (s) parameters. CAlglib::MinBLEICSetInnerCond(state, epsg, epsf, epsw); CAlglib::MinBLEICSetOuterCond(state, epso, epsi); CAlglib::MinBLEICOptimize(state, ffunc, frep, 0, Obj); CAlglib::MinBLEICResults(state, w, rep); Print("TerminationType =", rep.GetTerminationType()); // Optimization completion code /* * -8 internal integrity control detected infinite or NAN values in function/gradient. Abnormal termination signalled. * -3 inconsistent constraints. Feasible point is either nonexistent or too hard to find. Try to restart optimizer with better initial approximation * 1 relative function improvement is no more than EpsF. * 2 scaled step is no more than EpsX. * 4 scaled gradient norm is no more than EpsG. * 5 MaxIts steps was taken * 8 terminated by user who called minbleicrequesttermination(). X contains point which was "current accepted" when termination request was submitted. */ Print("IterationsCount =", rep.GetInnerIterationsCount()); // Number of iterations Print("Parameters:"); PrintKernelParams(w, kernel_list); // Display optimized parameters in the log Print("NLML = ", ffunc.GetNLML()); // final NLML value for optimal parameters KernelParams optimized_params; CRowDouble parameters = w; // determine the correct distribution of parameters across kernels ExtractKernelParams(parameters, kernel_list, optimized_params); return optimized_params; }
MQL5中的高斯过程回归
为演示高斯过程回归模型的功能,我们以合成数据为例进行说明。相关实现已编写在GP_Regressor脚本中,展示了模型的创建、训练与测试全过程。
数据生成由Dataset函数完成,该函数会生成用于训练和测试的合成数据矩阵。数据集包含100个在区间[−5,5]上均匀分布的点,对应函数:y=sin(x)+0.5x,并叠加了高斯噪声。该设置可以模拟真实数据:既包含线性趋势,又包含周期分量,同时体现数据的不确定性。
构建回归模型时,需要指定构成协方差函数的核函数列表。每个核函数都会对协方差矩阵K产生独特贡献,决定模型能够捕捉的依赖关系类型。核函数列表通过SetKernelList函数配置,该函数根据输入参数kernel_combination(枚举类型KernelCombination)生成kernel_list数组。支持以下组合:
- COMBINATION_1:[RBF核,线性核,白噪声核](3个核);
- COMBINATION_2:[RBF核,线性核,周期核,白噪声核](4个核);
- COMBINATION_3:[RBF核,白噪声核](2个核)。
选定核函数后,通过OptimizeGP函数对模型超参数进行优化。该函数以最小化NLML为目标,返回包含各核最优参数的KernelParams结构体,例如幅值(σ_f)、长度尺度(l)或周期(p)。
得到最优参数后,即可调用Predict函数进行预测。
//+------------------------------------------------------------------------+ //| Predict the Gaussian posterior distribution for new points | //+------------------------------------------------------------------------+ GPPredictionResult Predict(const matrix &x_train, const matrix &y_train, const matrix &x_test, int &kernel_list[], KernelParams ¶ms) { GPPredictionResult result; // Calculate the K covariance matrix for the training points matrix K = ComputeKernelMatrix(x_train, x_train, kernel_list, params); // Obtain the observation noise variance double observation_noise_variance = 0.0; for (int i = 0; i < ArraySize(kernel_list); i++) { if (kernel_list[i] == KERNEL_WHITE) { observation_noise_variance = params.white.sigma * params.white.sigma; break; } } // Form a noise matrix for the training data: K + sigma_n^2 * I matrix K_noisy_train = K + matrix::Identity((int)x_train.Rows(), (int)x_train.Rows()) * observation_noise_variance; // Calculate the K* cross-covariance matrix between training and test points matrix K_star = ComputeKernelMatrix(x_train, x_test, kernel_list, params); // Calculate the posterior mean matrix inv_term = K_noisy_train.Inv(); result.mu_f_star = K_star.Transpose() @ (inv_term @ y_train); // Matches mu_y_star // Calculate the posterior covariance matrix for the latent function (Sigma_f_star) matrix K_star_star = ComputeKernelMatrix(x_test, x_test, kernel_list, params); result.Sigma_f_star = K_star_star - K_star.Transpose() @ (inv_term @ K_star); // Calculate the posterior covariance matrix for a new observation (Sigma_y_star) // Sigma_y_star = Sigma_f_star + sigma_n^2 * I result.Sigma_y_star = result.Sigma_f_star + matrix::Identity((int)x_test.Rows(), (int)x_test.Rows()) * observation_noise_variance; return result; }
Predict函数是高斯过程模型实现的核心部分,它并非简单地返回预测值,而是完整给出测试点上后验分布的全部信息。该函数返回GPPredictionResult结构体,包含:
- 隐函数f*的后验均值μf*(与μy*相等);
- 隐函数f*的后验协方差矩阵Σf*;
- 观测值y*的后验协方差矩阵Σy*。该矩阵同时包含隐函数的不确定性,以及在优化白噪声核(WhiteKernel)参数时确定的观测噪声方差(σ^2)。
现在,让我们来看一下不同核函数组合下的预测结果。首先,我们仅使用RBF核对目标函数进行预测,并假设数据中存在噪声(图例7)。

图例7. 基于RBF核的预测结果
- 红色点 —— 训练数据(TrainData);
- 蓝色线 —— 预测均值;
- 绿色星号 —— 测试点(X*)上的预测值;
- 蓝色点 —— 训练区间以外的测试数据;
- 灰色虚线 —— 预测区间(f*或y*的±2σ区间)。
由此可见,当测试点远离训练数据区间[-5,5]时,预测值会逐渐趋近于高斯过程的先验均值(通常设置为0)。出现这一现象的原因是:对于RBF核,当远离训练数据时,新样本点x*与训练点x之间的协方差K*会指数级衰减至0。因此,RBF核更适合用于数据插值,但由于相关性快速衰减,其外推能力有限。
为了提升外推效果,我们增加线性核(图例8)。

图例8. 基于RBF核与线性核叠加预测(隐函数f*预测区间)
线性核用于刻画线性相关关系,具备良好的外推能力;当数据带有线性或近似线性趋势时效果尤为突出,本文的示例函数y=sin(x)+0.5x正是如此。引入线性核后,模型能够捕捉数据中的线性分量(0.5x),训练区间外的预测效果得到改善。然而,由图表可见,模型仍无法完整还原数据特征,缺失了周期性成分。
为拟合季节性、周期性波动(本例中的sin(x)项),我们引入周期核(图例9)。

图例9. 基于RBF核、周期核与线性核组合预测(隐函数f*预测区间)
加入周期核后,模型几乎实现了完美预测,成功捕捉到数据中的全部关键相关特征。此时隐函数f*的预测区间几乎与后验均值重合。反观观测值y*,其预测区间会宽很多,这一点合乎逻辑 —— 该区间额外计入了观测噪声方差,详见图例10。
")
图例10. 基于RBF核、周期核与线性核组合预测(观测值y*预测区间)
高斯过程预测的重要注意事项:如果未合理纳入噪声方差,人们容易将隐函数f*(x)的预测区间误当作观测值y*的预测区间。为了得到观测值y*准确的预测区间,必须在协方差矩阵中显式加入噪声方差,该逻辑已在Predict函数中实现。
结论
本文以回归问题为例,详细讲解了高斯过程的基础原理。我们学习了高斯过程的核心组成部分:先验分布、似然与后验分布,其中后验分布能够给出完整的概率预测,并对不确定性进行量化。我们实现了几种基础核函数:RBF核、线性核与周期核,当然实际可用的核函数远不止这些。
本文特别关注了超参数优化,这是让高斯过程适配特定数据的关键步骤。我们展示了通过最小化NLML实现优化,并采用乔列斯基分解提升计算效率与数值稳定性。在实现的模型中,使用了ALGLIB库中的BLEIC梯度算法作为优化器。
本文聚焦于高斯过程的基础原理,暂未涉及诸多进阶主题。例如,使用负对数边缘似然梯度的解析表达式(可大幅提升优化效率),以及稀疏近似方法(对处理海量数据至关重要)等。这些方向为高斯过程模型的后续研究提供了广阔前景。
| # | 名称 | 类型 | 描述 |
|---|---|---|---|
| 1 | GP_Samples_Prior.mq5 | 脚本 | 先验分布采样演示 |
| 2 | GP_Samples_Posterior.mq5 | 脚本 | 后验分布采样演示 |
| 3 | GP_Regressor | 脚本 | 构建回归模型 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/18427
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 新手在交易中的10个基本错误
新手在交易中的10个基本错误
回归的高斯过程与 维纳-欣钦定理之间存在着密切的联系 https://danmackinlay.name/notebook/wiener_khintchine.html https://www.numberanalytics.com/blog/wiener-khinchin-theorem-guide 如果您能继续沿着这个方向深入探讨,为我们解惑, 那 将非常棒。
当然,这并不是一种很流行的工具,但我认为它很有前景。 吸引我的地方在于,一旦掌握了核方法,你就能获得一种统一且协调的数据分析视角。这里既包括回归和分类,也涵盖核密度估计、特征选择以及独立性统计检验等内容。
无论如何,这都很有意思 :)