
Procesos gaussianos en aprendizaje automático: modelo de regresión en MQL5

Introducción
Los procesos gaussianos (GP) son una herramienta de modelado bayesiano ampliamente usada en el aprendizaje automático para problemas de regresión y clasificación. A diferencia de muchos modelos tradicionales que solo ofrecen pronósticos puntuales, los GP generan una distribución de probabilidad completa para los valores previstos. Esto nos permite no solo obtener predicciones puntuales, sino también una evaluación importante de la incertidumbre de estas predicciones, expresada a través de intervalos de confianza. Esta es una característica distintiva del enfoque bayesiano, que combina el conocimiento previo con los datos observados para obtener una distribución predictiva.
Los GP pertenecen a la clase de métodos de kernel que usan funciones de covarianza (o kernels) para modelar dependencias entre datos. La capacidad de combinar diferentes kernels (por ejemplo, mediante suma o multiplicación) permite cierta flexibilidad al describir posibles funciones predictivas. Cada kernel tiene sus propios hiperparámetros que deben optimizarse para lograr la máxima precisión del modelo.
En este artículo, examinaremos con detalle el proceso de predicción utilizando un modelo de regresión de proceso gaussiano y demostrando claramente cómo los GP permiten no solo generar pronósticos precisos sino también evaluar exhaustivamente su incertidumbre.
¿Qué es un proceso gaussiano?
Desde un punto de vista probabilístico, un proceso gaussiano es un proceso aleatorio que describe una distribución de probabilidad sobre funciones. A diferencia de la distribución normal ordinaria, que describe una sola variable aleatoria, los GP definen un conjunto infinito de variables aleatorias, cualquier subconjunto finito de las cuales sigue una distribución normal multidimensional.
En el aprendizaje automático, los GP se refieren a modelos no paramétricos que no necesitan una forma de función predefinida (por ejemplo, lineal o polinomial, como en la regresión clásica). En cambio, los GP modelan una función latente f(x) que se supone capta las verdaderas dependencias en los datos. No obstante, la función f(x) en sí no es directamente observable; solo tenemos acceso a sus valores con ruido en los puntos dados x. El modelo GP se basa en el supuesto de que la distribución de esta función desconocida f(x) es normal:
f(x)~ N(μ, Σ),
donde:
- f(x) — función oculta (latente) cuyos valores en los puntos observados queremos modelar,
- μ — vector de valores medios que dependen de la función media a priori (que a menudo se toma como cero para simplificar),
- Σ — matriz de covarianza cuyos elementos están determinados por la función de covarianza (o kernel) K(x, x'), que especifica el grado de correlación entre los puntos x y x'.
La idea clave de los GP consiste en modelar la distribución de funciones a través de una estructura de covarianza definida por un kernel, que a su vez determina varias propiedades de las funciones, como su suavidad, periodicidad, no estacionariedad, etc.
El objetivo principal de los GP supone la reconstrucción de la función latente f(x) basándose en un conjunto de datos finitos D=(X,y), donde X es un conjunto de características e y son observaciones ruidosas.
Enfoque bayesiano para GP
Los procesos gaussianos usan un enfoque bayesiano para la inferencia estadística que combina el conocimiento previo con los datos observados para realizar predicciones probabilísticas. Esto distingue a los GP de muchos otros métodos de aprendizaje automático (como redes neuronales o SVM) al permitirle no solo predecir valores sino también estimar su incertidumbre. Este enfoque se basa en el teorema de Bayes:

donde:
- P(H) — probabilidad previa: la probabilidad inicial de la hipótesis H que refleja el conocimiento previo o las suposiciones antes de observar los datos,
- P(D|H) — verosimilitud: la probabilidad de observar los datos D si la hipótesis H es verdadera,
- P(H|D) — probabilidad posterior: la probabilidad de la hipótesis H después de observar los datos D,
- P(D) — probabilidad marginal de los datos (constante normalizadora) que garantiza la correcta normalización de la distribución.
En el contexto de los GP, el enfoque bayesiano se aplica de la siguiente manera. La hipótesis H se interpreta como una distribución sobre funciones f(x) a partir de la cual se podría generar nuestra muestra de datos, mientras que los datos D son el conjunto de datos de entrenamiento (X, y).
Así, el teorema de Bayes en GP toma la forma:
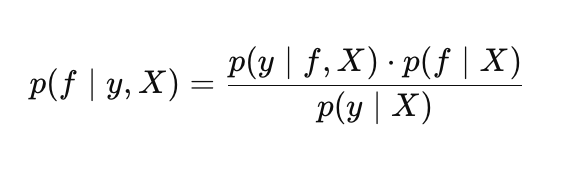
donde:
- p(f |X) — distribución previa sobre las funciones f,
- p(y |f, X) — verosimilitud,
- p(f |y, X) — distribución posterior sobre las funciones f ,
- p(y |X) — verosimilitud marginal (evidencia). Se usa para optimizar los hiperparámetros del proceso gaussiano.
Distribución previa
La distribución previa describe nuestras conjeturas iniciales sobre posibles funciones antes de ver los datos. En esencia, lo anterior supone un conjunto de funciones posibles de las cuales el GP seleccionará las más apropiadas en función de los datos de entrenamiento. El kernel juega un papel clave en la definición de las propiedades de estas funciones. Hay muchos tipos de kernels, cada uno de ellos adecuado para diferentes tipos de datos, por ejemplo:
RBF (kernel gaussiano): modela funciones no lineales suaves:

donde:
- σ_f — amplitud, especifica la escala de variaciones (en el código params.rbf.sigma_f),
- l — escala de longitud, controla la tasa de disminución de la correlación (params.rbf.length),
- ∥x−x′∥ — distancia euclidiana entre los puntos x y x'.
kernel lineal: modela dependencias lineales:
![]()
- x*x' — producto escalar de dos vectores,
- σ_l — escala de la tendencia lineal (params.linear.sigma_l)
kernel periódico: captura patrones cíclicos:

- σ_f — amplitud, especifica la escala de oscilaciones (params.periodic.sigma_f),
- l — longitud de la escala, controla la suavidad de las oscilaciones (params.periodic.length),
- p — periodo, determina la frecuencia de repetición (params.periodic.period).
Para visualizar la distribución previa, consideraremos muestras de funciones f(x) generadas utilizando diferentes kernels. La figura 1 muestra muestras de una distribución anterior con un kernel RBF. Las trayectorias son funciones no lineales suaves que varían dependiendo de los parámetros del kernel.

Fig. 1 Muestras de funciones f de la distribución previa del GP (kernel RBF)
La figura 2 muestra muestras de una distribución previa con un kernel lineal. Las trayectorias son líneas rectas con pendientes variables, lo cual refleja la capacidad del kernel para modelar tendencias lineales.

Fig. 2 Muestras de funciones f de la distribución previa del GP (kernel lineal)
La figura 3 muestra muestras con un kernel periódico. Las trayectorias son funciones cíclicas con periodo p, lo cual hace que el kernel sea ideal para modelar componentes periódicos.

Fig. 3 Muestras de funciones f de la distribución previa del GP (kernel periódico)
La figura 4 muestra las trayectorias del conocido proceso de Wiener con función de covarianza K(x, x') = min(x, x').

Fig. 4 Muestras de funciones f de la distribución previa del GP con la función de covarianza del proceso de Wiener
La flexibilidad del GP se logra mediante la capacidad de combinar kernels (sumándolos o multiplicándolos), lo cual permite modelar funciones con diversas propiedades, como una combinación de tendencias lineales y no lineales, oscilaciones periódicas, etc. Las muestras se han generado utilizando el script SamplesPrior.Verosimilitud
En los procesos gaussianos, la verosimilitud p(y |f, X) describe la probabilidad de observar datos y, dada una función particular f de la distribución previa y los datos X. Desempeña un papel clave en la inferencia bayesiana al relacionar la distribución previa de las funciones con los datos observados. Para un conjunto de datos, la verosimilitud viene dada por la distribución normal multidimensional:

donde:
- f(x) — vector de valores de la función oculta en los puntos X,
- σy^2 — varianza de ruido,
- ∥y−f(x)∥^2 — cuadrado de la norma euclidiana de la diferencia entre los datos observados y los valores de la función f.
Distribución posterior
La distribución posterior es el resultado de una actualización bayesiana de la distribución previa dados los datos observados y la verosimilitud. Describe la probabilidad de valores de la función oculta f(x) en nuevos puntos de prueba X*. Esta distribución se caracteriza por una media actualizada μ* que representa la predicción y una matriz de covarianza Σ* que describe la incertidumbre de los pronósticos.
Así, la distribución previa especifica un conjunto de funciones, la verosimilitud las "pondera" según los datos y la distribución posterior proporciona la función más probable con una estimación de la incertidumbre.
Regresión de verosimilitud gaussiana
Los procesos gaussianos, en combinación con el ruido de observación gaussiano, permiten resolver el problema de regresión en forma analítica usando métodos de álgebra lineal. Esto simplifica sustancialmente los cálculos y elimina la necesidad de utilizar métodos numéricos complejos. Los GP son adecuados para modelar datos tanto ruidosos como no ruidosos. Vamos a analizar primero el caso idealizado donde los valores objetivo y son los valores verdaderos sin ruido de la función, es decir, cuando y = f(x) (el escenario de interpolación).
El caso sin ruido: interpolación
Supongamos que tenemos un conjunto de datos D = {(xn, yn) : n = 1 : N}, donde yn = f(xn) — observación exacta libre de ruido de la función f, calculada en el punto xn. Nuestra tarea consiste en predecir los valores de la función f* para un conjunto de prueba X* de tamaño N*×d.
Para los puntos de entrenamiento X y los puntos de prueba X*, la distribución previa conjunta de los valores de la función f y f* será una distribución normal multidimensional:

donde:
- f — vector de valores verdaderos de la función oculta en los puntos de entrenamiento,
- f* — vector de valores verdaderos de la función oculta en los puntos de prueba,
- m(X) — vector de valores medios de la función para los puntos de entrenamiento (vector de ceros para simplificar),
- m(X*) — vector de valores medios de la función para los puntos de prueba (vector de ceros para simplificar),
- K(X,X) — matriz de covarianza NxN entre todos los pares de puntos de entrenamiento,
- K(X,X*) — matriz de covarianza NxN* entre los puntos de entrenamiento y de prueba,
- K(X*,X*) — matriz de covarianza N*xN* entre todos los pares de puntos de prueba
- N — número de puntos de datos de entrada,
- N* — número de puntos de datos de prueba,
- d — dimensionalidad de los datos de entrada (número de características).
Dado que las observaciones y en este caso corresponden exactamente a f (y=f), es decir, la verosimilitud es una función delta, podemos ir inmediatamente a la distribución condicional de f* dado y. Debido a las propiedades de las distribuciones condicionales de la distribución normal multidimensional, la distribución posterior para f* dados los datos observados y será:

donde:
- μf* — media posterior, la mejor predicción de los valores de la función oculta f* en nuevos puntos (de prueba), basados en los datos de entrenamiento,
- Σf* — matriz de covarianza posterior para los puntos de prueba. Cuantifica la incertidumbre en la predicción de la función oculta f*.
El caso del ruido: la regresión
En problemas del mundo real, los datos y generalmente contienen ruido impredecible: y=f(X)+ϵ, donde ϵ∼N(0,σ^2) es ruido gaussiano. En este caso, los GP no interpolan los datos de entrenamiento con exactitud (es decir, no pasan exactamente por cada punto), sino que los suavizan considerando el nivel de ruido esperado. La distribución posterior de datos ruidosos se modifica agregando la varianza del ruido a los elementos diagonales de la matriz de covarianza de los datos de entrenamiento:

El parámetro de ruido σ es un hiperparámetro del modelo y se optimiza junto con los parámetros del kernel.
Un punto muy importante: al agregar ruido, obtenemos la capacidad de predecir intervalos de confianza no solo para la función latente f*, sino también para nuevas observaciones y*. A diferencia del caso sin ruido, donde las distribuciones predictivas para f* e y* eran las mismas, estas distribuciones ahora se distinguen. La principal diferencia radica en sus matrices de covarianza. La covarianza Σf* refleja la incertidumbre de la propia función latente en los puntos de prueba. La covarianza Σy* incluye la incertidumbre de la función latente más la varianza del ruido de observación.

- μy* — media posterior de la nueva observación y*. Coincide con μf* ya que el valor esperado del ruido es cero,
- Σy* — covarianza posterior para la nueva observación y*.
Para visualizar cómo los procesos gaussianos se adaptan a los datos, consideraremos una visualización de muestras de funciones f generadas a partir de la distribución posterior en ausencia de ruido. La figura 5 muestra tres funciones f construidas después de observar cinco puntos de entrenamiento usando el kernel RBF.

Fig. 5 Muestras de funciones f de la distribución posterior (kernel RBF, sin ruido)
Antes de observar cualquier dato, la distribución previa dada por el GP describe un conjunto infinito de funciones. Después de agregar datos de entrenamiento, la distribución posterior restringe este conjunto, dejando solo las funciones que pasan exactamente por los puntos observados. En otras palabras, se centra exclusivamente en aquellas funciones que interpolan los datos con precisión.
En los puntos de entrenamiento X, la varianza (los elementos diagonales de la matriz de covarianza posterior Σ*) es cero, lo que significa que no hay incertidumbre en estos puntos: se garantiza que todas las funciones muestreadas de la distribución posterior pasan exactamente por los puntos de entrenamiento. Fuera de los puntos de entrenamiento, las funciones pueden variar, lo cual refleja la incertidumbre del modelo en áreas donde faltan datos. Sin embargo, su comportamiento todavía está determinado por la estructura del kernel elegido, en este caso RBF.
Consideremos ahora la gráfica de muestras de funciones f de la distribución posterior cuando los datos observados y contienen ruido gaussiano. (Fig. 6)

Fig. 6 Muestras de funciones f de la distribución posterior (kernel RBF, con ruido)
En presencia de ruido, las funciones posteriores no necesitan pasar exactamente por los datos observados y Esto significa que el conjunto de posibles funciones que pueden explicar los datos se vuelve más amplio, ya que pueden desviarse de los valores observados dentro del ruido. Las líneas discontinuas grises representan intervalos de confianza de 2 sigma que abarcan aproximadamente el 95% de la probabilidad de la distribución posterior de f*. En regiones alejadas de los datos de entrenamiento, la incertidumbre aumenta aún más y los intervalos de confianza se vuelven significativamente más amplios, lo cual indica una disminución de la confianza del modelo en estas regiones. Debemos considerar que las líneas punteadas grises representan intervalos de confianza para la función latente f*, no para nuevas observaciones y*.
Optimización de hiperparámetros del proceso gaussiano
El rendimiento de un modelo de proceso gaussiano depende en gran medida de la selección óptima de sus hiperparámetros, lo que permite que el modelo se ajuste a los datos, maximizando su capacidad para explicar las relaciones observadas. Estos hiperparámetros incluyen parámetros de kernel y varianza de ruido. En GP, la optimización se realiza usando la minimización de verosimilitud marginal logarítmica negativa (NLML):

El cálculo directo de (K+σ^2*I)^−1 * y es computacionalmente costoso para n grandes, ya que requiere invertir una matriz n×n. Por lo tanto, para hacer el cálculo más eficiente y robusto, se utiliza la descomposición de Cholesky. Teniendo en cuenta esta descomposición, la fórmula NLML se puede reescribir como:

- z — vector que se obtiene al resolver un sistema de ecuaciones lineales utilizando la descomposición de Cholesky, z=L^−1*y
- L — matriz triangular inferior de la descomposición de Cholesky K+σ^2*I = LL^T
Esta fórmula se implementa en la función NegativeLogMarginalLikelihood.
//+------------------------------------------------------------------+ //| Вычисление отрицательного логарифмического правдоподобия | //+------------------------------------------------------------------+ double NegativeLogMarginalLikelihood(const matrix &x, const matrix &y, int &kernel_list[], KernelParams ¶ms) { int n = (int)x.Rows(); //--- Вычисляем ковариационную матрицу K matrix K = ComputeKernelMatrix(x, x, kernel_list, params); //--- Добавляем дисперсию белого шума, если выбран KERNEL_WHITE double white_noise_variance = 0.0; for (int i = 0; i < ArraySize(kernel_list); i++) { if (kernel_list[i] == KERNEL_WHITE) { white_noise_variance = params.white.sigma * params.white.sigma; break; } } // Добавление небольшого джиттера предотвращает проблемы, // если матрица K оказывается сингулярной или близкой к сингулярной // из-за особенностей вычислений или выбранного ядра double jitter = 1e-6; K += matrix::Identity(n, n) * (white_noise_variance + jitter); // ---Выполняем разложение Холецкого: K + sigma^2*I = L * L^T matrix L; if (!K.Cholesky(L)) { Print("Ошибка: Разложение Холецкого не удалось"); return DBL_MAX; } //--- Решаем линейную систему L * z = y для нахождения z = L^(-1) * y vector z = L.LstSq(y.Col(0)); if (z.Size() == 0) { Print("Ошибка: Не удалось решить систему L * z = y"); return DBL_MAX; } //--- Вычисляем первое слагаемое в формуле NLML : // 1/2 * y^T * (K + sigma^2*I)^-1 * y = 1/2 * z^T * z double data_term = 0.5 * z @ z; // Скалярное произведение z^T * z //--- Вычисляем второе слагаемое: 1/2 * log|K + sigma^2*I| = sum(log(L_ii)) vector diag = L.Diag(); double log_det = 0.0; for (int i = 0; i < n; i++) log_det += MathLog(diag[i]); // суммируем логарифмы диагональных элементов L //--- Вычисляем третье слагаемое: n/2 * log(2π) double const_term = 0.5 * n * MathLog(2 * M_PI); return data_term + log_det + const_term; }
La matriz de covarianza K se calcula usando la función ComputeKernelMatrix, que suma las contribuciones de todos los kernels seleccionados (por ejemplo, RBF, lineal, periódico, etc.).
//+------------------------------------------------------------------+ //| Вычисление ковариационной матрицы | //+------------------------------------------------------------------+ matrix ComputeKernelMatrix(const matrix &X1, const matrix &X2, int &kernel_list[], KernelParams ¶ms) { matrix K = matrix::Zeros(X1.Rows(), X2.Rows()); for (int i = 0; i < ArraySize(kernel_list); i++) { switch (kernel_list[i]) { case KERNEL_RBF: K += RBF_kernel(X1, X2, params.rbf.sigma_f, params.rbf.length); break; case KERNEL_LINEAR: K += Linear_kernel(X1, X2, params.linear.sigma_l); break; case KERNEL_PERIODIC: K += Periodic_kernel(X1, X2, params.periodic.sigma_f, params.periodic.length, params.periodic.period); break; case KERNEL_WHITE: // WhiteKernel добавляется отдельно в виде sigma^2 * I break; } } return K; }
NLML se usa como función objetivo para la optimización de hiperparámetros en la función OptimizeGP. La optimización se realiza usando el método BLEIC de la biblioteca ALGLIB.
//+------------------------------------------------------------------+ //| Оптимизация гиперпараметров гауссовского процесса | //+------------------------------------------------------------------+ KernelParams OptimizeGP(int &kernel_list[], matrix &x_train, matrix &y_train) { double w[]; //Массив начальных значений гиперпараметров double s[]; //Массив масштабов для гиперпараметров, используемых для нормализации в оптимизации double bndl[], bndu[]; // Массивы нижних и верхних границ для каждого гиперпараметра CObject Obj; CNDimensional_GP ffunc(kernel_list, x_train, y_train);// Объект класса, реализующего целевую функцию NLML CNDimensional_Rep frep; // Объект для хранения отчета об оптимизации // Инициализация параметров InitializeKernelParams(kernel_list, w, s, bndl, bndu); /* Подсчитывается общее количество параметров (num_params) в зависимости от типов ядер в kernel_list. Задает начальные значения параметров w,масштаб и границы для параметров */ CMinBLEICStateShell state; CMinBLEICReportShell rep; //Объект для хранения результатов оптимизации. double epsg = 0; //Точность по градиенту (0 означает, что остановка по градиенту отключена) double epsf = 0.0001; //Точность по значению функции double epsw = 0; // точность по параметрам double diffstep = 0.0001; // Шаг для численного вычисления производных. double epso = 0.00001; // Параметры для внешних и внутренних условий сходимости в BLEIC double epsi = 0.00001; CAlglib::MinBLEICCreateF(w, diffstep, state); // Создает объект оптимизации BLEIC с начальными параметрами w и шагом для численных производных diffstep CAlglib::MinBLEICSetBC(state, bndl, bndu); //Устанавливает границы параметров (bndl, bndu). CAlglib::MinBLEICSetScale(state, s); //Устанавливает масштабы параметров (s). CAlglib::MinBLEICSetInnerCond(state, epsg, epsf, epsw); CAlglib::MinBLEICSetOuterCond(state, epso, epsi); CAlglib::MinBLEICOptimize(state, ffunc, frep, 0, Obj); CAlglib::MinBLEICResults(state, w, rep); Print("TerminationType =", rep.GetTerminationType()); // Код завершения оптимизации /* * -8 internal integrity control detected infinite or NAN values in function/gradient. Abnormal termination signalled. * -3 inconsistent constraints. Feasible point is either nonexistent or too hard to find. Try to restart optimizer with better initial approximation * 1 relative function improvement is no more than EpsF. * 2 scaled step is no more than EpsX. * 4 scaled gradient norm is no more than EpsG. * 5 MaxIts steps was taken * 8 terminated by user who called minbleicrequesttermination(). X contains point which was "current accepted" when termination request was submitted. */ Print("IterationsCount =", rep.GetInnerIterationsCount()); // Количество итераций Print("Parameters:"); PrintKernelParams(w, kernel_list); // Выводит оптимизированные параметры в журнал Print("NLML = ", ffunc.GetNLML()); // финальное значение NLML для оптимальных параметров KernelParams optimized_params; CRowDouble parameters = w; //определяем правильное распределение параметров по ядрам ExtractKernelParams(parameters, kernel_list, optimized_params); return optimized_params; }
Regresión GP en MQL5
Para ilustrar las capacidades del modelo de regresión del proceso gaussiano, consideraremos un ejemplo que utiliza datos sintéticos. La implementación se presenta en el script GP_Regressor, que muestra el proceso de creación, entrenamiento y prueba del modelo.
La generación de datos se realiza usando la función Dataset, que produce matrices de datos sintéticos para entrenamiento y pruebas. El conjunto de datos consta de 100 puntos distribuidos uniformemente en el rango [−5,5] y representa una función y=sin(x)+0.5x con ruido gaussiano añadido. Este enfoque permite simular datos reales que contengan tanto una tendencia lineal como un componente periódico, considerando la incertidumbre.
Para construir un modelo de regresión, deberemos determinar la lista de kernels que forman la función de covarianza. Cada kernel hace una contribución única a la matriz de covarianza K, determinando la naturaleza de las dependencias que el modelo es capaz de capturar. La lista de kernel se configura usando la función SetKernelList, que genera la matriz kernel_list en función del parámetro de entrada kernel_combination (tipo de enumeración KernelCombination). Se admiten las siguientes combinaciones:
- COMBINATION_1: [RBF, Linear, White] (3 kernels),
- COMBINATION_2: [RBF, Linear, Periodic, White] (4 kernels),
- COMBINATION_3: [RBF, White] (2 kernels).
Tras seleccionar los kernels, los hiperparámetros del modelo se optimizan utilizando la función OptimizeGP. Esta función minimiza la verosimilitud negativa (NLML) al devolver una estructura KernelParams que contenga los parámetros óptimos para cada kernel, como amplitud (σ_f), longitud de escala (l) o periodo (p).
Una vez encontrados los parámetros óptimos, pasamos a la previsión mediante la función Predict.
//+------------------------------------------------------------------------+ //| Предсказание гауссовского апостериорного распределения для новых точек | //+------------------------------------------------------------------------+ GPPredictionResult Predict(const matrix &x_train, const matrix &y_train, const matrix &x_test, int &kernel_list[], KernelParams ¶ms) { GPPredictionResult result; // Вычисляет ковариационную матрицу K для обучающих точек matrix K = ComputeKernelMatrix(x_train, x_train, kernel_list, params); // Получаем дисперсию шума наблюдений double observation_noise_variance = 0.0; for (int i = 0; i < ArraySize(kernel_list); i++) { if (kernel_list[i] == KERNEL_WHITE) { observation_noise_variance = params.white.sigma * params.white.sigma; break; } } // Формируем матрицу шума для обучающих данных: K + sigma_n^2 * I matrix K_noisy_train = K + matrix::Identity((int)x_train.Rows(), (int)x_train.Rows()) * observation_noise_variance; // Вычисляет кросс-ковариационную матрицу K* между обучающими и тестовыми точками matrix K_star = ComputeKernelMatrix(x_train, x_test, kernel_list, params); // Вычисление апостериорного среднего matrix inv_term = K_noisy_train.Inv(); result.mu_f_star = K_star.Transpose() @ (inv_term @ y_train); // Совпадает с mu_y_star // Вычисление апостериорной ковариационной матрицы для скрытой функции (Sigma_f_star) matrix K_star_star = ComputeKernelMatrix(x_test, x_test, kernel_list, params); result.Sigma_f_star = K_star_star - K_star.Transpose() @ (inv_term @ K_star); // Вычисление апостериорной ковариационной матрицы для нового наблюдения (Sigma_y_star) // Sigma_y_star = Sigma_f_star + sigma_n^2 * I result.Sigma_y_star = result.Sigma_f_star + matrix::Identity((int)x_test.Rows(), (int)x_test.Rows()) * observation_noise_variance; return result; }
La función Predict es un elemento clave de la implementación del modelo GP, ya que no simplemente devuelve los valores predichos, sino que proporciona información completa sobre la distribución posterior en los puntos de prueba. La función retorna una estructura GPPredictionResult que contiene:
- la media posterior de la función latente f* (μf* = μy*),
- la matriz de covarianza posterior Σf* para la función latente f*,
- la matriz de covarianza posterior Σy* para los nuevos valores observados y*. Esta matriz incluye tanto la incertidumbre de la función latente como la varianza del ruido de observación (σ^2), que se determina durante la optimización del parámetro WhiteKernel.
Ahora veamos los resultados de la predicción para distintas combinaciones de kernels. Para comenzar, intentaremos predecir nuestra función utilizando solo el kernel RBF, asumiendo que hay ruido en los datos (fig. 7).

Fig. 7 Predicción utilizando el kernel RBF
- Los puntos rojos son datos de entrenamiento (TrainData),
- La línea azul es la media prevista,
- Las estrellas verdes son la predicción de los puntos de prueba (X*),
- Los puntos azules son datos de prueba fuera del rango de entrenamiento.
- Las líneas discontinuas grises son intervalos de confianza (±2 sigma para f* o y*)
Aquí vemos que a medida que los puntos de prueba se alejan del rango de datos de entrenamiento [-5,5], las predicciones tienden al GP medio previo, que generalmente se toma como cero. Esto sucede porque, lejos de los datos de entrenamiento, las covarianzas K* (entre los nuevos puntos x* y los puntos de entrenamiento x) para el kernel RBF se reducen exponencialmente hasta cero. Por ello, el kernel RBF resulta más adecuado para la interpolación de datos, pero su uso para la extrapolación es limitado debido a la rápida disminución de las correlaciones.
Para mejorar la extrapolación, agregaremos un kernel lineal (fig. 8).

Fig. 8 Predicción usando la suma de RBF y kernel lineal, intervalos f*
El kernel lineal modela relaciones lineales, lo cual lo hace adecuado para la extrapolación, especialmente si los datos tienen una tendencia lineal o casi lineal, como en nuestro ejemplo con la función y=sin(x)+0.5x. La inclusión de un kernel lineal ha mejorado las predicciones fuera del rango de datos de entrenamiento al capturar un componente lineal (0,5x). Sin embargo, como se puede ver en el gráfico, el modelo aún no captura por completo el componente periódico de los datos.
Para modelar variaciones estacionales o cíclicas, como sin(x) en nuestros datos, usamos un kernel periódico (figura 9).

Fig. 9 Predicción usando la suma de RBF, kernels periódicos y lineales, intervalos f*
Tras agregar el kernel periódico, el modelo ha logrado una predicción casi perfecta porque ha sido capaz de capturar todas las dependencias significativas presentes en los datos. Como resultado, los intervalos de confianza para f* (la función latente) prácticamente se fusionan con la media posterior. Por el contrario, para los valores y* observados, los intervalos de confianza resultan mucho más amplios, lo cual es lógico ya que tienen en cuenta la varianza del ruido de observación, como se muestra en la figura 10.
")
Fig. 10 Predicción usando la suma de RBF, kernels periódicos y lineales, intervalos y*
Una nota importante sobre las predicciones en GP. Sin una consideración adecuada de la varianza del ruido, los intervalos de confianza para f*(x) pueden interpretarse erróneamente como intervalos de predicción para y*. Para obtener intervalos de predicción correctos para y*, deberemos incluir explícitamente la varianza del ruido en la matriz de covarianza, que se implementa en la función Predict.
Conclusión
En este artículo, hemos analizado con detalle los conceptos básicos de los procesos gaussianos utilizando un problema de regresión como ejemplo. Asimismo, hemos estudiado los componentes clave del GP: la distribución previa, la verosimilitud y la distribución posterior, que proporciona pronósticos probabilísticos completos con incertidumbre cuantificada. También hemos implementado las funciones básicas del kernel como RBF, lineal y periódica, aunque, por supuesto, hay muchas más.
Hemos prestado especial atención a la optimización de hiperparámetros, que es fundamental para adaptar el GP a datos específicos. Después hemos demostrado que esta optimización se logra minimizando la verosimilitud marginal logarítmica negativa (NLML), donde se utiliza la descomposición de Cholesky para mejorar la eficiencia computacional y la estabilidad numérica. En el modelo implementado hemos utilizado como optimizador el método de gradiente BLEIC de la biblioteca ALGLIB.
Este artículo se centra en los principios básicos de la GP y se omiten varios temas avanzados. Estos incluyen, por ejemplo, el uso de expresiones analíticas para gradientes NLML, que pueden mejorar significativamente la eficiencia de la optimización, así como el uso de aproximaciones dispersas, que resultan fundamentales para procesar grandes cantidades de datos. Estas direcciones abren perspectivas para futuras investigaciones sobre el modelo GP.
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | GP_Samples_Prior.mq5 | Script | Demostración de muestras de distribución anterior |
| 2 | GP_Samples_Posterior.mq5 | Script | Demostración de muestras de la distribución posterior |
| 3 | GP_Regresor | Script | Construcción del modelo de regresión |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18427
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Existe una fuerte relación entre los Procesos Gaussianos para la regresión y el teorema de Wiener-Khinchin https://danmackinlay.name/notebook/wiener_khintchine.html https://www.numberanalytics.com/blog/wiener-khinchin-theorem-guide Sería estupendo que continuaras en esta dirección para ilustrarnos .
No es una herramienta muy popular, desde luego, pero la veo prometedora. Me atrae el hecho de que, una vez comprendido el enfoque kernel, se obtiene un único punto de vista coherente sobre el análisis de datos. Hay regresión y clasificación y estimación de la densidad del núcleo y selección de características significativas y pruebas estadísticas de independencia, etc.
En fin, interesante :)