
Erkennung und Klassifizierung fraktaler Muster mit maschinellem Lernen
Einführung
Im ersten Artikel haben wir die grundlegenden Aspekte der multifraktalen Markttheorie eingehend untersucht. Wir haben festgestellt, dass Kurscharts unter dem Einfluss externer Informationen, die sie strukturieren, bestimmte sich wiederholende Muster bilden können. Die Marktteilnehmer bilden ein komplexes dynamisches System, das über Gedächtniselemente verfügt, die sich in Form bestimmter Marktsymmetrien (Muster) äußern. Diese Muster können sich im Laufe der Zeit weiterentwickeln oder sich wiederholen. Aufgrund der Selbstähnlichkeit fraktaler Marktstrukturen lassen sich Muster über verschiedene Zeitskalen hinweg darstellen.
Dieser Artikel stellt einen neuartigen Ansatz zur Erkennung und Klassifizierung fraktaler Muster vor. Die Analyse wird in Python durchgeführt, wobei die finalen Modelle im ONNX-Format in das MetaTrader-5-Terminal exportiert werden können.
Bevor Sie beginnen, stellen Sie sicher, dass Sie alle erforderlichen Pakete und Module installiert haben. Einige der importierten Module sind im untenstehenden Anhang enthalten.
import pandas as pd import math from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import test_model from bots.botlibs.export_lib import export_model_to_ONNX
Implementierung der Suchfunktion für fraktale Muster
In diesem Artikel schlage ich einen einfachen Ansatz vor, um symmetrische multifraktale Marktstrukturen anhand von Korrelationen zu ermitteln. Wir können sowohl fraktale als auch multifraktale Muster untersuchen, die skalierungsinvariant sind, das heißt, sie weisen unterschiedliche Größen auf. Dazu muss eine Suche nach Mustern mittels Korrelation auf verschiedenen Zeitskalen durchgeführt werden, die in den Einstellungen festgelegt werden. Im Folgenden wird eine Funktion vorgestellt, die die Korrelation in einem gleitenden Fenster berechnet und dabei die variable Länge der Muster berücksichtigt.
@njit def calculate_symmetric_correlation_dynamic(data, min_window_size, max_window_size): n = len(data) min_w = max(2, min_window_size) max_w = max(min_w, max_window_size) num_correlations = max(0, n - min_w + 1) if num_correlations == 0: return np.zeros(0, dtype=np.float64), np.zeros(0, dtype=np.int64) correlations = np.zeros(num_correlations, dtype=np.float64) best_window_sizes = np.full(num_correlations, -1, dtype=np.int64) for i in range(num_correlations): max_abs_corr_for_i = -1.0 best_corr_for_i = 0.0 current_best_w = -1 current_max_w = min(max_w, n - i) start_w = min_w if start_w % 2 != 0: start_w += 1 for w in range(start_w, current_max_w + 1, 2): if w < 2 or i + w > n: continue half_window = w // 2 window = data[i : i + w] first_half = window[:half_window] second_half = (window[half_window:] * -1)[::-1] std1 = np.std(first_half) std2 = np.std(second_half) if std1 > 1e-9 and std2 > 1e-9: mean1 = np.mean(first_half) mean2 = np.mean(second_half) cov = np.mean((first_half - mean1) * (second_half - mean2)) corr = cov / (std1 * std2) if abs(corr) > max_abs_corr_for_i: max_abs_corr_for_i = abs(corr) best_corr_for_i =corr current_best_w = w correlations[i] = best_corr_for_i best_window_sizes[i] = current_best_w return correlations, best_window_sizes
Um eine Schleife mit ähnlichen Berechnungen zu beschleunigen (Schleifen sind in Python langsam), wird der Dekorator @njit verwendet, der Berechnungen mithilfe des Numba-Pakets beschleunigt.
Die Funktion erwartet als Eingabe einen Datenrahmen mit Schlusskursen sowie die minimale und maximale „Fenster“-Größe für Muster. Wir möchten beispielsweise die Korrelation für Muster berechnen, deren Länge zwischen 100 und 200 Bars liegt. Anschließend nehmen wir die entsprechenden Einstellungen vor; danach wird für jede neue Ausgangsposition und für jede vorgegebene Musterlänge die Korrelation zwischen dem linken und dem spiegelbildlich umgekehrten rechten Teil überprüft. Die Umkehrung der rechten Hälfte ist gelb markiert. Das ist sehr wichtig, da wir nach Symmetrie in den Daten suchen.
Die Werte der besten absoluten Korrelationen für jeden Startpunkt werden in das Array „correlations[]“ geschrieben. Die Fenstergröße (Musterlänge), die der besten Korrelation entspricht, wird in ein weiteres Array namens best_window_sizes[] geschrieben. Somit gibt die Funktion für jeden Startpunkt die maximalen Korrelationswerte und das entsprechende Muster zurück.
Sichtprüfung der festgestellten Muster
Sobald alle Muster berechnet sind, können wir die Richtigkeit unseres Algorithmus visuell überprüfen. Zu diesem Zweck schlage ich eine weitere Funktion vor, die die besten gefundenen Muster anzeigt, sortiert nach dem höchsten, absoluten Pearson-Korrelationskoeffizienten.
def plot_best_n_patterns(data, min_window_size, max_window_size, n_best): # 1. Calculate correlations and best window sizes corrs, window_sizes = calculate_symmetric_correlation_dynamic(data, min_window_size, max_window_size) # 2. Find N best patterns # Assuming -1 in window_sizes means invalid/not found by the calculation logic valid_calc_mask = window_sizes != -1 if not np.any(valid_calc_mask): print("No suitable patterns found (all window sizes were marked as -1 by calculation).") return filtered_corrs = corrs[valid_calc_mask] filtered_window_sizes = window_sizes[valid_calc_mask] original_indices_all = np.arange(len(corrs)) filtered_start_indices = original_indices_all[valid_calc_mask] if len(filtered_corrs) == 0: print("No suitable patterns found after filtering out -1 window_sizes.") return # Sort by absolute correlation value in descending order sorted_indices_of_filtered = np.argsort(np.abs(filtered_corrs))[::-1] # Determine how many of the top patterns to consider num_to_consider = min(n_best, len(sorted_indices_of_filtered)) if num_to_consider == 0: print("No patterns to plot (either n_best is too small, or no patterns passed the initial filter).") return # Pre-filter these top candidates to find those actually plottable (even window size >= 2) patterns_to_plot_details = [] for i in range(num_to_consider): idx_in_filtered_arrays = sorted_indices_of_filtered[i] # Index within the already filtered (by valid_calc_mask) arrays w_best_candidate = filtered_window_sizes[idx_in_filtered_arrays] actual_data_start_index = filtered_start_indices[idx_in_filtered_arrays] correlation_value = filtered_corrs[idx_in_filtered_arrays] # Check if the window size is valid for plotting (even and sufficiently large) if w_best_candidate >= 2 and w_best_candidate % 2 == 0 : patterns_to_plot_details.append({ "original_rank_in_consider_list": i, # Rank among the num_to_consider items "data_start_index": actual_data_start_index, "correlation": correlation_value, "window_size": int(w_best_candidate) # Ensure it's int }) else: print(f"Info: Top candidate (originally rank {i+1} among considered, " f"Start Index: {actual_data_start_index}) " f"skipped due to invalid window size for plotting: {w_best_candidate} (must be even and >= 2).") num_actually_plotted = len(patterns_to_plot_details) fig, ax = plt.subplots(1, 1, figsize=(10, 5)) # Single axes for combined plot title_fontsize = 12 label_fontsize = 10 legend_fontsize = 8 tick_labelsize = 9 if num_actually_plotted == 0: # This message is shown if, out of the top 'num_to_consider' patterns, none had a valid window size for plotting. print("No patterns with valid window sizes (even, >=2) found among the top candidates to display on the chart.") ax.text(0.5, 0.5, "No valid patterns to display on the chart.", horizontalalignment='center', verticalalignment='center', transform=ax.transAxes, fontsize=title_fontsize, color='red') ax.set_xticks([]) ax.set_yticks([]) fig.suptitle(f"Symmetric Patterns Overlaid", fontsize=title_fontsize) # Generic title else: # Generate distinct colors for each pattern that will actually be plotted plot_colors = plt.cm.viridis(np.linspace(0, 1, num_actually_plotted)) for plot_idx, pattern_info in enumerate(patterns_to_plot_details): actual_data_start_index = pattern_info["data_start_index"] correlation_value = pattern_info["correlation"] w_best = pattern_info["window_size"] half_window = w_best // 2 # Ensure indices are within data bounds if actual_data_start_index + w_best > len(data): print(f"Warning: Pattern P{plot_idx+1} (Idx:{actual_data_start_index}, W:{w_best}) extends beyond data length {len(data)}. Skipping.") continue left_part_data = data[actual_data_start_index : actual_data_start_index + half_window] right_part_data = data[actual_data_start_index + half_window : actual_data_start_index + w_best] x_indices = np.arange(w_best) # X-axis relative to pattern start current_color = plot_colors[plot_idx] # Plot left part ax.plot(x_indices[:half_window], left_part_data, color=current_color, linestyle='-', label=f"P{plot_idx+1} (Idx:{actual_data_start_index}, W:{w_best}, C:{correlation_value:.2f})") # Plot right part ax.plot(x_indices[half_window:], right_part_data, color=current_color, linestyle='--') # Add a vertical line to mark the split point for this pattern ax.axvline(x=half_window - 0.5, color=current_color, linestyle=':', linewidth=1, alpha=0.6) ax.set_xlabel("Index within Pattern Window", fontsize=label_fontsize) ax.set_ylabel("Data Value", fontsize=label_fontsize) ax.tick_params(axis='both', which='major', labelsize=tick_labelsize) ax.grid(True) ax.legend(fontsize=legend_fontsize, loc='best') # Add a text note to explain line styles fig.text(0.99, 0.01, 'Solid: Left Part, Dashed: Right Part (Original)', horizontalalignment='right', verticalalignment='bottom', fontsize=legend_fontsize - 1, color='dimgray', transform=fig.transFigure) fig.suptitle(f"Top {num_actually_plotted} Symmetric Patterns Overlaid", fontsize=title_fontsize) plt.tight_layout(rect=[0, 0.03, 1, 0.96]) # Adjust rect for suptitle and fig.text plt.show()
Diese Funktion ist ziemlich lang, aber der Großteil des Codes befasst sich mit der Sortierung und Darstellung von Mustern. Zunächst werden die Muster selbst berechnet, anschließend werden sie nach den Werten des Korrelationskoeffizienten sortiert. Die Position jedes Musters im Kursverlauf wird ermittelt und anschließend grafisch dargestellt. Das Ergebnis dieser Funktion ist unten dargestellt.
Auf dem ersten Bild sehen wir ein einzelnes ausgewähltes Muster, das die höchste absolute Korrelation aufweist. Es ähnelt einem bestimmten Höchststand – sei es lokal oder global –, der eine Trendumkehr symbolisiert. Die gepunktete vertikale Linie markiert die Aufteilung der Reihe in zwei gleiche Hälften. Die rechte Hälfte ist das Vorzeichen umgekehrt, und sie ist gespiegelt. Anschließend wird die Korrelation zwischen dem linken und dem rechten Abschnitt berechnet. Die Charts zeigen nicht die umgekehrten rechten Seiten, sondern die ursprünglichen Kursreihen.
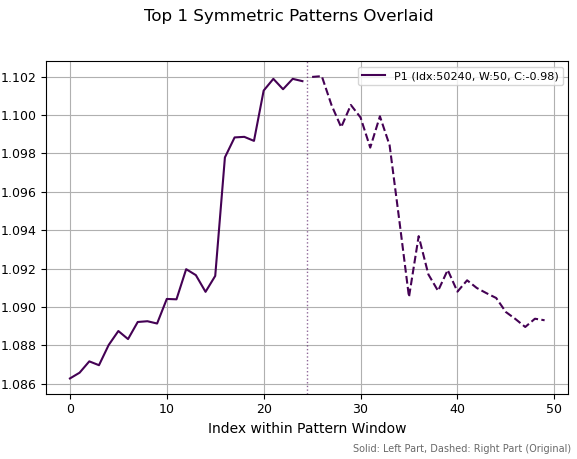
Abb. 1. Das beste Muster hat eine Periodenlänge von 50 und eine Korrelation von -0,98
In der zweiten Abbildung habe ich die fünf besten Muster mit einer Periode von 50 dargestellt. Von diesen fünf Mustern ähneln drei einem Hoch, zwei einem Tief; eines davon sieht zudem wie die Fortsetzung eines Aufwärtstrends aus. Die linke Skala zeigt die historischen Kursniveaus, denen diese Muster entsprechen.
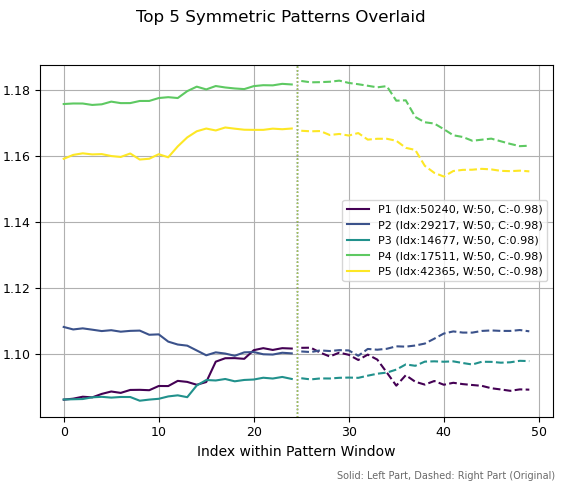
Abb. 2. Die fünf besten 50-Perioden-Muster
Wenn wir die Musterperioden auf 150 Bars erhöhen, lassen sich völlig andere Strukturen beobachten. Es wurden drei ähnliche Muster gefunden (oben). Das liegt daran, dass eine kleine Verschiebung in den historischen Daten zur Entdeckung derselben Struktur führte. Die beiden anderen Muster unterschieden sich voneinander.
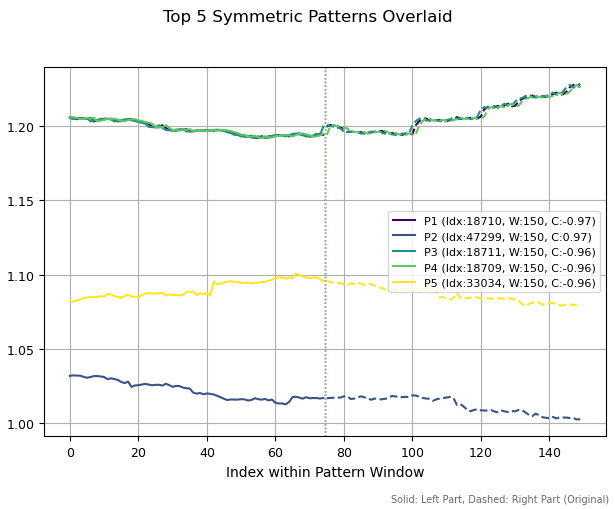
Abb. 3. Die fünf besten Muster mit einer Periodenlänge von 150
Wenn wir das Berechnungsfenster für die Muster auf 250 erweitern, gehören dieselben Muster erneut zu den besten, allerdings mit einer leichten Verschiebung im Verlauf. Es lassen sich auch einige Umkehrmuster beobachten, da ihre Korrelationen negativ sind.
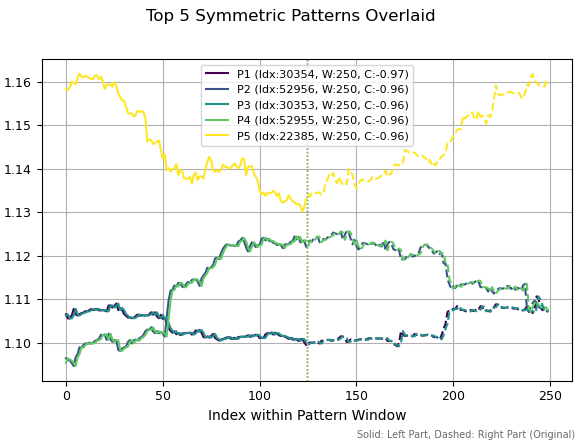
Abb. 4. Die fünf besten Muster mit einer Periodenlänge von 250
Diese Darstellungen veranschaulichen eine Vielzahl selbstaffiner (selbstähnlicher) Marktstrukturen. Theoretisch kann diese Vielfalt nur durch die Länge der untersuchten Reihe begrenzt werden. In diesem Fall ist es ziemlich schwierig zu bestimmen, welches Muster Vorhersagepotenzial hat und welches nicht. Es würde Monate dauern, jede einzelne Struktur zu untersuchen. Maschinelles Lernen kann uns hier helfen, da es uns ermöglicht, alle Muster auf einmal zu klassifizieren.
Es ist durchaus möglich, dass die Suche nach Strukturen mittels Korrelation nicht ideal ist und andere, genauere Schätzverfahren in Betracht gezogen werden sollten. Dieser Ansatz ist jedoch ein guter Ausgangspunkt für weitere Forschungen und ist intuitiv nachvollziehbar. Nun müssen wir herausfinden, wie wir diese Marktfraktale analysieren und auf dieser Grundlage mithilfe von maschinellem Lernen ein Handelssystem entwickeln können.
Kennzeichnung von Trades auf der Grundlage symmetrischer Strukturen
Die Funktion zum Aufspüren symmetrischer Strukturen ist gewissermaßen eine Funktion für Data Mining. Wir legen klare Kriterien fest, wonach wir in den Daten suchen – selbstähnliche fraktale Strukturen. Als Nächstes müssen die erhaltenen Informationen gesammelt und klassifiziert werden. Doch selbst das wird nicht ausreichen, denn wir müssen einen Weg finden, die Handelsgeschäfte anhand dieser Daten zu kennzeichnen – und genau das werden wir in diesem Abschnitt tun.
Ich schlage folgende Methode zur Kennzeichnung von Trades für die spätere Klassifizierung vor. Es ist nicht die einzig mögliche Lösung, spiegelt jedoch das Verständnis des Autors wider, wie sie umgesetzt werden kann. Ich bin der Meinung, dass zu diesem Thema weitere Untersuchungen erforderlich sind, doch vorerst beschränken wir uns auf die bestehende Kennzeichnungsmethode.
@njit def generate_future_outcome_labels_for_patterns( close_data_len, # Total length of the original close_data correlations_at_window_start, # Correlation array window_sizes_at_window_start, # Array of window sizes source_close_data, # Full close_data array correlation_threshold, min_future_horizon, # Minimum horizon for determining the future price max_future_horizon, # Maximum horizon markup_points # "Markup" for determining a significant price change ): labels = np.full(close_data_len, 2.0, dtype=np.float64) # 2.0: no signal/neutral/no pattern num_potential_windows = len(correlations_at_window_start) for idx_window_start in range(num_potential_windows): corr_value = correlations_at_window_start[idx_window_start] w = window_sizes_at_window_start[idx_window_start] # Condition 1: The correlation should be strong enough if abs(corr_value) < correlation_threshold: continue # Condition 2: A valid window should be found if w < 2: continue # The point in time (index) when the correlation pattern is fully formed signal_time_idx = idx_window_start + w - 1 if signal_time_idx >= close_data_len: # Theoretically, this should not happen continue # Array for storing labels for the entire pattern (both left and right parts) pattern_labels = [] # Calculate individual marks for all points of the pattern for point_idx in range(idx_window_start, signal_time_idx + 1): # Current price for this particular point current_price = source_close_data[point_idx] # Define the forecast horizon current_horizon = min_future_horizon if max_future_horizon > min_future_horizon: current_horizon = random.randint(min_future_horizon, max_future_horizon) # Index of future price relative to the current point future_price_idx = point_idx + current_horizon if future_price_idx >= close_data_len: continue future_price = source_close_data[future_price_idx] # Define a label for the current point current_label = 2.0 # Neutral by default if future_price > current_price + markup_points: current_label = 0.0 # Price increased elif future_price < current_price - markup_points: current_label = 1.0 # Price fell # Add the label to the array if it is not neutral if current_label != 2.0: pattern_labels.append(current_label) # If there are no significant marks in the pattern, move on to the next pattern if len(pattern_labels) == 0: continue # Calculate the average mark for all points of the pattern avg_label = 0.0 for l in pattern_labels: avg_label += l avg_label /= len(pattern_labels) # Define a common label for the entire pattern pattern_label = 0.0 if avg_label < 0.5 else 1.0 # Assign this label to all points of the pattern for i in range(idx_window_start, signal_time_idx + 1): labels[i] = pattern_label return labels
Die Funktion generate_future_outcome_labels_for_patterns() bietet folgende Funktionen:
- Als Eingabe dienen das ursprüngliche Preisarray, ein Array mit Korrelationen sowie ein Array mit Musterlängen, die den höchsten Korrelationen für einen bestimmten Datenpunkt entsprechen. Die Funktion akzeptiert außerdem einen minimalen und maximalen Prognosehorizont in Bars.
- Zunächst werden alle Trades mit 2,0 gekennzeichnet (nicht handeln).
- Die Schleife überprüft den Korrelationswert für jeden Punkt der Zeitreihe. Wenn die Korrelation den Schwellenwert „correlation_threshold“ überschreitet, wird diese Beobachtung einer zusätzlichen Verarbeitung unterzogen; andernfalls bleibt die Klassifizierung für dieses Beispiel bei 2,0.
- Anschließend werden über die gesamte Länge des Musters, die anhand der maximalen Korrelation ermittelt wird, Handelsgeschäfte auf der Grundlage künftiger Kursänderungen berechnet. Für jeden Punkt gilt: Ist der Kurs gestiegen, ist dies die 0-Marke – kaufen; ist der Kurs gefallen, ist dies die 1 – verkaufen. Der Durchschnittswert wird über alle Transaktionen hinweg ermittelt, und jeder Beobachtung des aktuellen Musters wird eine gemittelte Kennzeichenung zugewiesen.
Die Philosophie hinter diesem Ansatz besagt, dass stark korrelierte Strukturen eine Art „Gedächtnis“ für ihre Ausgangsbedingungen besitzen und ein gewisses Maß an Regelmäßigkeit aufweisen. Das bedeutet, dass die Beobachtungen innerhalb dieser Gruppen besser vorhergesagt werden können; um jedoch eine Überanpassung zu vermeiden, weisen wir jedem Wert eine durchschnittliche Klassifizierung zu. Umgekehrt lassen sich Beobachtungen innerhalb von Strukturen mit geringer Korrelation nur schlecht vorhersagen, da sie weniger regelmäßig sind.
Daher nutzen wir folgendes Prinzip: Das eine Modell bestimmt die Qualität des Musters (ob es sich derzeit lohnt, zu handeln oder nicht), und das andere Modell bestimmt die Richtung des Handels. Maschinelles Lernen wird die Aufgabe haben, alle möglichen Muster und Handelsrichtungen zu modellieren.
Als Nächstes benötigen wir eine weitere Orchestrator-Funktion, die direkt zum Kennzeichnen von Trades aufgerufen wird.
Die endgültige, auf fraktalen Mustern basierende Kennzeichnungsfunktion
Es ist an der Zeit, alles zusammenzufassen und ein einsatzbereites Tool zur Kennzeichnung von Trades zu entwickeln.
def get_fractal_pattern_labels_from_future_outcome( dataset, min_window_size=6, max_window_size=60, correlation_threshold=0.7, min_future_horizon=5, max_future_horizon=5, markup_points=0.00010, ): if 'close' not in dataset.columns: raise ValueError("Dataset must contain a 'close' column.") close_data = dataset['close'].values n_data = len(close_data) if min_window_size < 2: min_window_size = 2 if max_window_size < min_window_size: max_window_size = min_window_size if min_future_horizon <= 0: raise ValueError("min_future_horizon must be > 0") if max_future_horizon < min_future_horizon: raise ValueError("max_future_horizon must be >= min_future_horizon") correlations_at_start, best_window_sizes_at_start = calculate_symmetric_correlation_dynamic( close_data, min_window_size, max_window_size, ) labels = generate_future_outcome_labels_for_patterns( n_data, correlations_at_start, best_window_sizes_at_start, close_data, correlation_threshold, min_future_horizon, max_future_horizon, markup_points ) result_df = dataset.copy() result_df['labels'] = pd.Series(labels, index=dataset.index) return result_df
Die Funktion get_fractal_pattern_labels_from_future_outcome() wird direkt aufgerufen, um Ihren Datensatz zu beschriften:
- Die Eingabe ist ein Datenrahmen, der eine Spalte „close“ mit Schlusskursen sowie Merkmale (optional) enthalten sollte;
- Die Mindest- und Höchstlänge der Muster, die bei der Markierung von Trades verwendet werden, wird festgelegt;
- Es wird ein Korrelationsschwellenwert festgelegt, mit dem sich die Strenge der für die Kennzeichnung berücksichtigten Muster anpassen lässt.
- Die Mindest- und Höchsthaltedauer (in Bars) für die Kennzeichnung von Trades sollte ebenfalls festgelegt werden;
- Optional können wir einen Schwellenwert festlegen.
Die Funktion nimmt einen Datensatz mit Schlusskursen entgegen und kennzeichnet die Handelsgeschäfte anhand fraktaler Muster, wobei eine Spalte „labels“ mit den Kennzeichnungen hinzugefügt wird.
Training eines Modells für maschinelles Lernen auf Basis fraktaler Kennzeichnungen
Nun ist alles für die Experimente vorbereitet, und Sie können die Modelle trainieren. Als Ausgangsdaten habe ich die stündlichen EUR/USD-Kurse von 2010 bis heute herangezogen.
Es wurde beschlossen, Standardabweichungen in gleitenden Fenstern unterschiedlicher Perioden als Merkmale zu verwenden:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Als Nächstes müssen Sie die Hyperparameter des Modells korrekt einstellen:
# set hyper parameters hyper_params = { 'symbol': 'EURUSD_H1', 'export_path': '/Users/dmitrievsky/Library//drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/', 'model_number': 0, 'markup': 0.00010, 'stop_loss': 0.00500, 'take_profit': 0.00500, 'periods': [i for i in range(15, 300, 30)], 'backward': datetime(2010, 1, 1), 'forward': datetime(2024, 1, 1), }
- Stop-Loss und Take-Profit sind identisch und entsprechen 500 fünfstelligen Punkten;
- Als Nächstes müssen wir den Pfad angeben, in den die trainierten Modelle in unseren Ordner exportiert werden sollen;
- Wir werden die Perioden der Merkmale (Standardabweichungen) im Bereich von 15 bis 300 mit einem Schritt von 30 festlegen (insgesamt gibt es 10 Merkmale);
- Der Trainingszeitraum erstreckt sich von 2010 bis 2024; die übrigen Daten werden nicht für das Training herangezogen.
Die Haupttrainingsschleife ermöglicht das gleichzeitige Trainieren mehrerer Modelle und das Durchlaufen der Hyperparameter:
# fit the models models = [] for i in range(10): print('Learn ' + str(i) + ' model') dataset = get_features(get_prices()) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() data = get_fractal_pattern_labels_from_future_outcome(data, 100, 100, 0.9, 15, 25, 0.00010) models.append(fit_final_models(data))
In dieser Schleife ermitteln wir zunächst Preise und Merkmale und legen dann den Zeitraum fest, für den das Modell trainiert werden soll.
Übergeben Sie in der Funktion get_fractal_pattern_labels_from_future_outcome() die folgenden Parameter:
- Ursprünglicher Datenrahmen mit Preisen und Merkmalen
- Mindestfenster für die Berechnung der Korrelation
- Maximales Zeitfenster für die Berechnung der Korrelation
- Schwellenwert für den Korrelationskoeffizienten bei Mustern, Standardwert 0,9
- Mindestprognosehorizont in Bars
- Maximaler Prognosehorizont in Bars
- Schwellenwert in Punkten
Die gekennzeichneten Daten werden dann in eine Funktion eingespeist, die zwei Klassifikatoren trainiert:
def fit_final_models(dataset: pd.DataFrame) -> list: feature_columns = dataset.columns[1:-1] # 1. Data for the main model # Filter the dataset: only those examples where 'labels' are equal to 0 or 1 are used for the main model. main_model_df = dataset[dataset['labels'].isin([0, 1])].copy() X = main_model_df[feature_columns] y = main_model_df['labels'].astype('int16') # 2. Data for the meta model X_meta = dataset[feature_columns] # Modify labels for the meta model: if 'labels' contains 1 or 0, then the new label is 1, if 2, then 0. y_meta = dataset['labels'].apply(lambda label_val: 1 if label_val in [0, 1] else 0).astype('int16') # For the main model train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) # For the meta model train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # Train the main model model = CatBoostClassifier(iterations=1000, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', ) # Check if the samples are empty after splitting (unlikely if X is large enough) if not train_X.empty and not test_X.empty: model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) elif not train_X.empty: # If the test sample is empty, but the training sample exists print("Warning: The test sample (test_X) for the main model is empty. The model is trained without eval_set.") model.fit(train_X, train_y, early_stopping_rounds=15, plot=False) # use_best_model may not work correctly without eval_set else: # If the training set is empty print("Error: The training set (train_X) for the main model is empty. The model cannot be trained.") # In this case, test_model will most likely throw an error later. # Return R2=-1 and the untrained model, the meta model will also not make sense without the main one. print("R2 is fixed at -1.0, models are not trained.") return [-1.0, model, None] # model - instance, but not trained # Meta model training meta_model = CatBoostClassifier(iterations=1000, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', ) if not train_X_m.empty and not test_X_m.empty: meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=25, plot=False) elif not train_X_m.empty: print("Warning: The test sample (test_X_m) for the meta model is empty. The meta model is trained without eval_set.") meta_model.fit(train_X_m, train_y_m, early_stopping_rounds=25, plot=False) else: print("Error: The training set (train_X_m) for the meta model is empty. The meta model cannot be trained.") print("R2 fixed as -1.0.") return [-1.0, model, meta_model] # meta_model - instance, but not trained data_for_test = get_features(get_prices()) R2 = test_model(data_for_test, [model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 fixed as -1.0') print('R2: ' + str(R2)) result = [R2, model, meta_model] return result
Punkte, die besondere Beachtung verdienen, sind fett hervorgehoben. Das Hauptmodell wird ausschließlich auf die Klassen 0 und 1 trainiert, während das zusätzliche Metamodell vorhersagt, ob ein Handel stattfinden soll oder nicht.
Tests und Endergebnisse
Zunächst einmal sollte ich erwähnen, dass ich den Algorithmus ausschließlich am EURUSD-Paar getestet habe. Ich konnte eine Musterfenstergröße auswählen, die mit neuen Daten am besten funktioniert. Sie beträgt 100. Die optimalen Parameter des Algorithmus sind bereits im Code festgelegt, sodass Sie das Ergebnis selbst nachstellen können.
Die Saldenkurve für Trainings- und Testdaten sieht wie folgt aus:
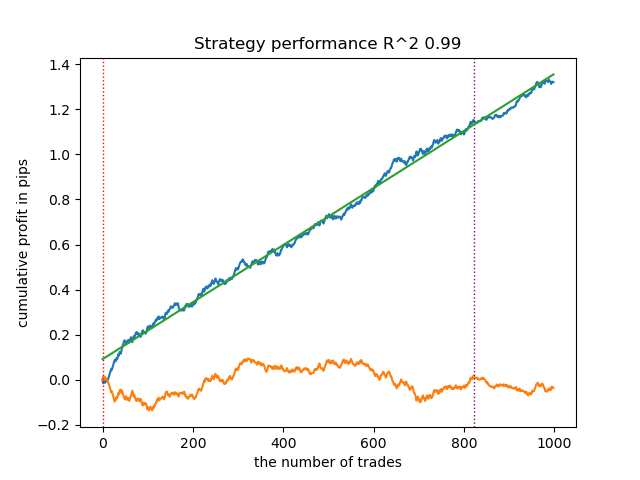
Abb. 5. Testen eines Algorithmus auf Basis fraktaler Kennzeichnungen
Es besteht ein direkter Zusammenhang zwischen der Korrelationsschwelle und den Handelsergebnissen mit neuen Daten. Bei einem Schwellenwert von 0,7 beispielsweise zeigt die Saldenkurve bereits eine deutliche Überanpassung an. Dies spiegelt die Tatsache wider, dass eine schwache Korrelation zwischen zwei Teilen einer Zeitreihe zu einer schwachen Abhängigkeit führt. Eine schwache Abhängigkeit wiederum verhindert die korrekte Klassifizierung zuverlässiger Muster, da diese mit unzuverlässigen Mustern vermischt sind.
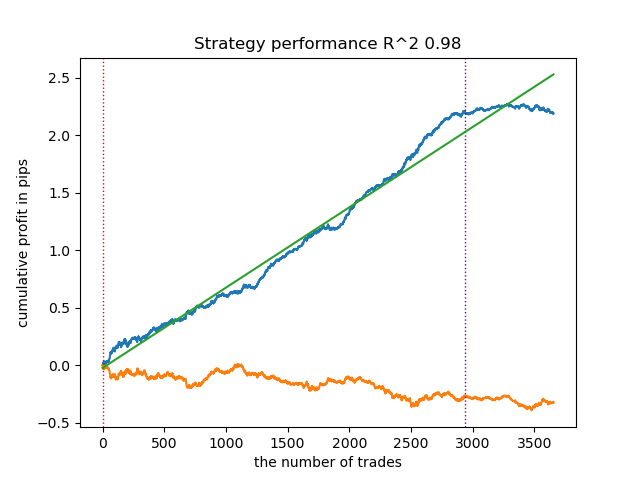
Abb. 6. Testen des Algorithmus mit einem Schwellenwert von 0,7
Es scheint, dass die korrekte Mustererkennung entscheidend ist. Es bedarf weiterer Forschungen und Erkenntnisse darüber, wie die Suche nach fraktalen Strukturen am besten organisiert werden kann.
Auch die Qualität und Quantität der Merkmale beeinflussen die Klassifizierungsergebnisse. Wenn wir anstelle der Standardabweichungen Inkremente verwenden, sieht die Saldenkurve anders aus.
Es ist zudem notwendig, die Methode zur Klassifizierung von Handelsgeschäften auf der Grundlage der festgestellten Muster zu analysieren und sachlich zu kritisieren.
Die Fehleranalyse der CatBoost-Modelle zeigt, dass die Modelle mit geringer Fehlerquote trainiert wurden:
>>> models[-1][1].get_best_score()['validation'] {'Accuracy': 0.9700523560209424, 'Logloss': 0.17002244404784328} >>> models[-1][2].get_best_score()['validation'] {'Logloss': 0.25629795409043277, 'F1': 0.8455473098330242} >>>
Exportieren und Testen von Modellen im MetaTrader 5-Terminal
Um Modelle zu exportieren, müssen wir die folgende Funktion aufrufen:
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Nach dem Exportieren und Kompilieren des EA erhielten wir folgende Ergebnisse:
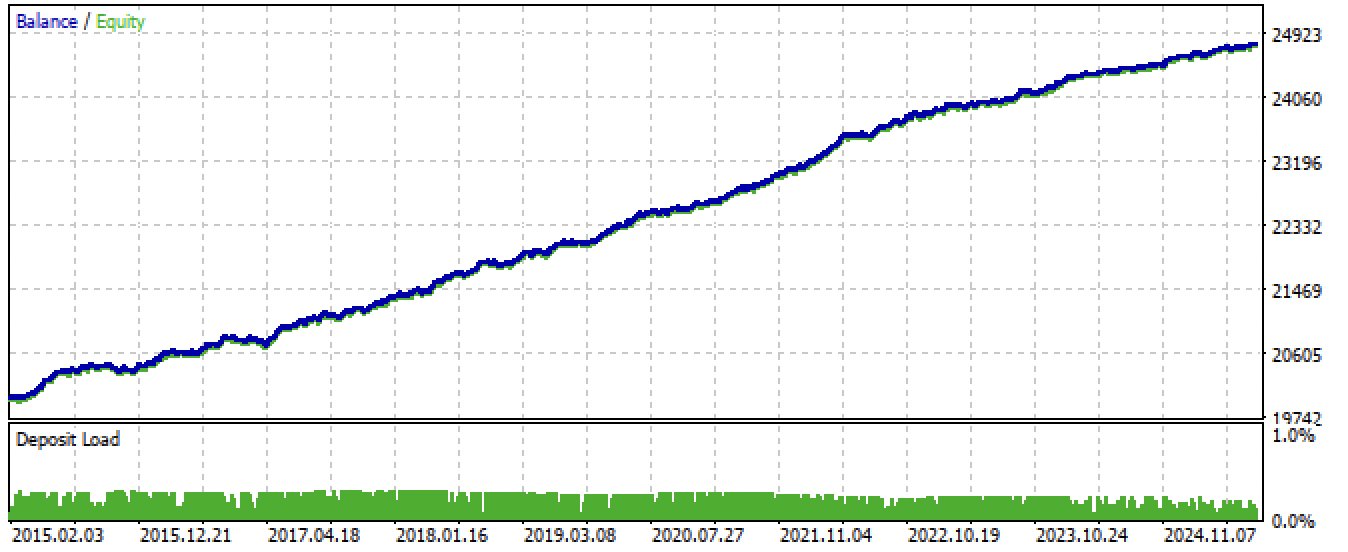
Abb. 7. Testen des EAs für den gesamten Zeitraum
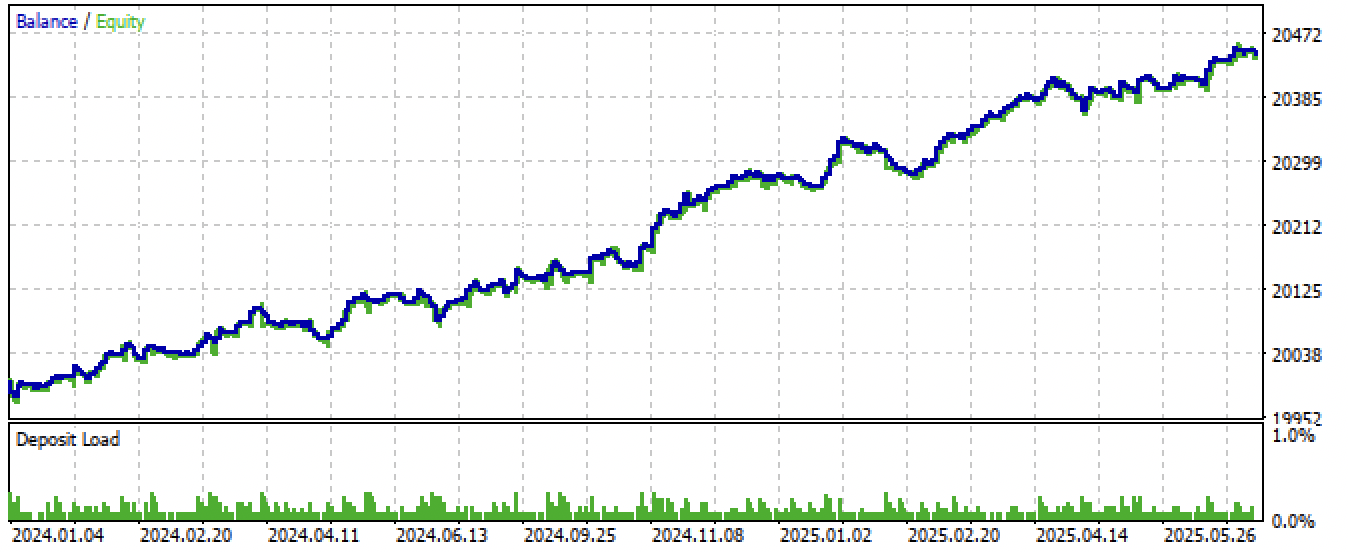
Abb. 8. Testen des EAs mit neuen Daten
Schlussfolgerung
In diesem Artikel haben wir das spannende Thema der fraktalen Analyse und der Marktprognose mithilfe maschinellen Lernens behandelt. Dies sind nur die ersten Schritte auf dem Weg zur Erforschung der vielfältigen fraktalen Strukturen, die sich in Finanzkurscharts bilden.
Es ist zu beachten, dass Korrelationsanalysen die Zusammenhänge zwischen vergangenen und zukünftigen Kursverläufen möglicherweise nicht vollständig widerspiegeln, weshalb dieses Thema weiterer Forschung bedarf. Beispielsweise kann eine Regressionsanalyse besser geeignet sein als eine Korrelationsanalyse. Gleichzeitig zeigt der aktuelle Algorithmus bei richtiger Konfiguration gute Vorhersagefähigkeiten, was das Vorhandensein fraktaler, selbstähnlicher Strukturen in finanziellen Zeitreihen bestätigt.
Das Archiv Python files.zip enthält die folgenden Dateien für die Entwicklung in der Python-Umgebung:
| Dateiname | Beschreibung |
|---|---|
| fractal patterns.py | Das Hauptskript für das Training von Modellen |
| labeling_lib.py | Aktualisiertes Modul zur Handelskennzeichnung |
| tester_lib.py | Aktualisierter benutzerdefinierter Strategietester basierend auf maschinellem Lernen |
| export_lib.py | Modul zum Exportieren von Modellen in das Terminal |
| EURUSD_H1.csv | Aus MetaTrader 5 exportierte Kursdaten |
Das Archiv MQL5 files.zip enthält Dateien für das MetaTrader 5-Terminal:
| Dateiname | Beschreibung |
|---|---|
| fractal trader.ex5 | Der kompilierte Bot aus dem Artikel |
| fractal trader.mq5 | Der Quellcode des Bots aus dem Artikel |
| Include//Trend following folder | Die ONNX-Modelle und die Header-Datei für die Verbindung mit dem Bot |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/18566
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Mir geht es nicht nur um diesen Artikel. Der Artikel ist nicht schlecht, zumindest im Mainstream-Kontext. Es geht um etwas anderes.
„Ich habe noch nicht herausgefunden, wie man die zeitliche Variabilität von Fraktalen berücksichtigen kann“ – dabei ist dies ein entscheidender Parameter, der die Aussagekraft jeder Prognose bestimmt.
Und das ist nicht nur Ihr Problem, sondern ein globales Problem – die Veränderung aller Koeffizienten bei zeitabhängigen Variablen.
Um das Wesen des Problems zu verstehen, muss man einen Schritt zurücktreten und die Grundbegriffe neu überdenken. Beispielsweise sind die meisten Fraktale nicht selbstähnlich: 1 Dollar im Jahr 2000 entspricht nicht 1 Dollar im Jahr 2025 (das heißt, 1 ist nicht gleich 1).
Man könnte noch viele weitere Beispiele anführen: In der Gesellschaft (Wirtschaft) herrscht die Pareto-Verteilung vor und nicht die Gaußsche Verteilung, weshalb die meisten statistischen Methoden nicht auf die Marktanalyse anwendbar sind usw.
Simons’ Erfolg legt nahe, dass es eine Lösung für das Problem gibt, man muss sie nur an anderer Stelle suchen.
Bei ihm geht es anscheinend um Arbitrage. Auch viele Arbitrage-Strategien funktionieren mit der Zeit nicht mehr.
Bei ihm geht es anscheinend um Arbitrage. Viele Arbitrage-Strategien funktionieren mit der Zeit ebenfalls nicht mehr.
Er befasst sich mit mehrdimensionalen Räumen.
Er verfügt über mehrdimensionale Räume.
Die Hilbertos?
Im Grunde gibt es so gut wie keine detaillierten Informationen über Simons’ Arbeitsmethoden, was verständlich ist. Es ist jedoch bekannt, dass er sein Kapital jährlich verdoppelte und sein Vermögen gegen Ende seines Lebens auf über 20 Milliarden geschätzt wurde.
Aber es geht nicht um ihn, sondern um die Möglichkeit an sich, eine Formel zu finden. Mehrdimensionale Räume sind die heutige Terminologie für pythagoreische Ideen. Das ist ein sehr tiefgründiges Thema. Auch die Multifraktalität lässt sich als eine Art primitives Analogon zum mehrdimensionalen Raum betrachten, in dem Knoten und Kanten Projektionen verborgener Bewegungen auf ein Diagramm darstellen. Falls Sie sich für dieses Thema interessieren, kann ich Ihnen gerne meine Überlegungen und Erkenntnisse mitteilen – am besten jedoch in einem persönlichen Schriftwechsel.
Im Grunde gibt es so gut wie keine detaillierten Informationen über Simons’ Arbeitsweise, was verständlich ist. Bekannt ist jedoch, dass er sein Kapital jedes Jahr verdoppelte und sein Vermögen am Ende seines Lebens auf über 20 Mrd. geschätzt wurde.
Aber es geht nicht um ihn, sondern um die Möglichkeit an sich, eine Formel zu finden. Mehrdimensionale Räume sind die heutige Terminologie für pythagoreische Ideen. Das ist ein sehr tiefgründiges Thema. Auch die Multifraktalität lässt sich als eine Art primitives Analogon zum mehrdimensionalen Raum betrachten, in dem Knoten und Kanten Projektionen verborgener Bewegungen auf ein Diagramm darstellen. Falls Sie sich für dieses Thema interessieren, kann ich Ihnen gerne meine Überlegungen und Erkenntnisse mitteilen – am besten jedoch im Rahmen eines persönlichen Schriftwechsels.
Ich glaube, im vorherigen Artikel wurde gerade die Entstehung verborgener Attraktoren (Selbstorganisation) unter dem Einfluss äußerer Bedingungen beschrieben, die sich über einen mehrdimensionalen Merkmalsraum bestimmen lassen.