
機械学習におけるガウス過程:MQL5による回帰モデル

はじめに
ガウス過程(GP, Gaussian Process)は、機械学習において回帰や分類問題に広く利用されているベイズ的ノンパラメトリックモデルです。従来の多くのモデルが点予測のみを提供するのに対し、GPは予測値に対する確率分布全体を生成します。そのため、単なる予測値だけでなく、信頼区間などによる不確実性の評価も可能です。これは、事前知識と観測データを統合して予測分布を導くベイズアプローチの大きな特徴です。
GPは、共分散関数(カーネル)を用いてデータ間の依存関係をモデル化するカーネル法の一種です。異なるカーネルを加算や乗算によって組み合わせることで、予測関数の特性を柔軟に表現できます。また、各カーネルには固有のハイパーパラメータが存在し、これらを最適化することでモデル性能を向上させることができます。
本記事では、ガウス過程回帰モデルによる予測の仕組みを詳しく解説し、GPが高精度な予測を実現するだけでなく、その予測に伴う不確実性も定量的に評価できることを示します。
ガウス過程とは
確率論的な観点から見ると、ガウス過程は関数上の確率分布を表現する確率過程です。通常の正規分布が単一の確率変数を記述するのに対し、ガウス過程は確率変数の集合を定義し、その任意の有限部分集合が多変量正規分布に従うという性質を持ちます。
機械学習におけるGPは、線形回帰や多項式回帰のように事前に関数形を決める必要がないノンパラメトリックモデルです。代わりに、データの背後に存在する真の関係性を表す潜在関数f(x)をモデル化します。ただし、この関数(f(x))自体を直接観測することはできません。観測できるのは、与えられたxの点における関数値にノイズが加わった値だけです。ガウス過程では、この未知の関数(f(x))が以下のような正規分布に従うと仮定します。
f (x)~ N( μ, Σ),
ここで
- f(x):観測点における値を生成すると考えられる潜在関数
- μ:平均ベクトル(事前平均関数によって決まる。簡単のためゼロとすることが多い)
- Σ:共分散行列。各要素は共分散関数(カーネル) (K(x, x')) によって定義され、点 (x) と (x') の相関の強さを表します。
GPの本質は、カーネルによって定義される共分散構造を通じて関数の分布を表現することです。カーネルの選択によって、関数の滑らかさ、周期性、非定常性など、さまざまな性質をモデル化できます。
GPの主な目的は、有限のデータセットD=(X,y)を用いて潜在関数f(x)を再構成することです。ここで、Xは入力特徴量、yはノイズを含む観測値を表します。
ガウス過程におけるベイズアプローチ
ガウス過程は、ベイズ統計に基づく推論手法を採用しています。ベイズアプローチでは、事前知識と観測データを組み合わせることで確率的な予測をおこないます。この点が、ニューラルネットワークやサポートベクターマシン(SVM)など多くの機械学習手法と異なる特徴であり、GPは予測値だけでなく、その予測に伴う不確実性も評価できます。ベイズ推論は、以下のベイズの定理に基づいています。

ここで
- P(H):事前確率 - データを観測する前の仮説Hに対する信念や事前知識を表します。
- P(D|H):尤度 - 仮説Hが与えられたときにデータDが観測される確率です。
- P(H|D):事後確率 - データDを観測した後に更新された仮説Hの確率です。
- P(D):周辺尤度 - 事後分布を正規化するための定数です。
ガウス過程の文脈では、仮説Hは「データを生成した可能性のある関数の分布」を意味し、データDは学習データセット((X, y))を表します。
GPにおけるベイズの定理は、次のように表現できます。
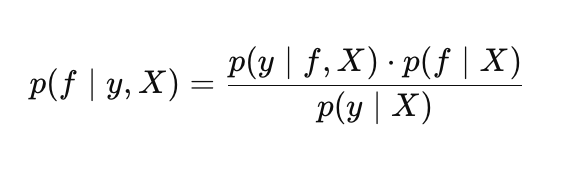
ここで
- p(f |X):関数fに対する事前分布
- p(y |f, X):尤度
- p(f |y, X):関数fに関する事後分布
- p(y |X):周辺尤度(証拠)。特に周辺尤度は、ガウス過程のハイパーパラメータを最適化する際に重要な役割を果たします。
事前分布
事前分布は、データを観測する前の段階で、対象となる関数がどのような形状を取り得るかについての初期的な仮定を表します。言い換えると、事前分布は「候補となる関数の集合」を定義するものであり、ガウス過程は学習データを観測した後、その中からデータに最も適合する関数を選択します。関数の性質を決定する上で中心的な役割を果たすのがカーネル(共分散関数)です。カーネルにはさまざまな種類があり、それぞれ異なる特徴を持つデータに適しています。
RBF (Radial Basis Function)カーネルは、滑らかな非線形関数をモデル化するために広く利用されます。

ここで
- σ_f:振幅。関数値の変動スケールを決定します(コードではparams.rbf.sigma_f)
- l:長さ尺度。相関がどの程度の速さで減衰するかを制御します(params.rbf.length)
- ∥x−x′∥:点(x)と(x')のユークリッド距離
線形カーネルは線形な依存関係をモデル化します。
![]()
- x*x':2つのベクトルの内積
- σ_l:線形トレンドのスケールを表すパラメータ(params.linear.sigma_l)
周期カーネルは、周期的なパターンを捉えます。

- σ_f:振幅。振動の大きさを決定します (params.periodic.sigma_f)
- l:長さ尺度。周期変動の滑らかさを制御します(params.periodic.length)
- p:周期。繰り返しの間隔を表します(params.periodic.period)
事前分布の性質を理解するために、異なるカーネルを用いて生成された関数サンプルを考えてみましょう。図1は、RBFカーネルを用いて生成した事前分布からの関数サンプルを示しています。生成された軌跡は滑らかな非線形関数となっており、その形状はカーネルのパラメータによって変化します。

図1:RBFカーネルを用いたGPの事前分布から生成した関数fのサンプル
図2は、線形カーネルを用いて生成した関数サンプルを示しています。軌跡は傾きの異なる直線として表れ、線形カーネルが線形トレンドを表現できることを示しています。

図2:線形カーネルを用いたGPの事前分布から生成した関数fのサンプル
図3は、周期カーネルによる事前分布から生成した関数サンプルを示しています。軌跡は周期pを持つ周期関数となり、季節性や周期的変動を持つデータのモデリングに適していることが分かります。

図3:周期カーネルを用いたGPの事前分布から生成した関数fのサンプル
図4はよく知られているウィーナー過程(Wiener Process)の共分散関数K(x,x') = min(x, x')を用いて生成した関数サンプルを示しています。

図4:ウィーナー過程の共分散関数を用いたGPの事前分布から生成した関数fのサンプル
ガウス過程の大きな特徴の一つは、複数のカーネルを組み合わせられることです。カーネル同士を加算または乗算することで、さまざまな性質を持つ関数を柔軟に表現できます。たとえば、線形トレンドと非線形変動の組み合わせ、長期トレンドと周期変動の同時表現、複数の周期成分を含む時系列パターンなどを自然にモデル化できます。なお、このセクションで示した関数サンプルは、SamplesPrior スクリプトを用いて生成しています。尤度
ガウス過程において、尤度p(y |f, X)は、事前分布から得られた特定の関数fと入力データXが与えられたときに、観測データyが得られる確率を表します。尤度はベイズ推論において重要な役割を果たしており、関数に対する事前分布と実際に観測されたデータを結び付ける役割を担います。データセットに対する尤度は、一般に次の多変量正規分布として表されます。

ここで
- f(x):観測点Xにおける潜在関数の値ベクトル
- σy^2:観測ノイズの分散
- ∥y−f(x)∥^2:観測データと関数値との差のユークリッドノルムの二乗
事後分布
事後分布は、事前分布に対して観測データと尤度の情報を反映した結果として得られる分布です。ガウス過程では、事後分布は新たな入力点X*における潜在関数値f(x)の分布を記述します。この分布は、予測を表す平均μ*と、予測の不確実性を表す共分散行列Σ*によって特徴付けられます。
つまり、事前分布は関数の集合を規定し、尤度はデータに基づいてそれらの関数を「重み付け」し、事後分布は最も尤もらしい関数とその不確実性の推定を与えます。
ガウス過程回帰とガウス尤度
ガウス過程は、ガウスノイズと組み合わせることで、回帰問題を線形代数の手法を用いて解析的に解くことができます。これにより計算が大幅に簡略化され、複雑な数値的手法を用いる必要がなくなります。ガウス過程は、ノイズを含むデータとノイズを含まないデータの両方のモデリングに適用できます。まずは理想化されたケースとして、ターゲット値(y)が関数の真の値そのものでありノイズを含まない場合、すなわちy = f(x)となる場合(補間の状況)を考えます。
ノイズなしの場合:補間
D = {(xn, yn) : n = 1 :N}というデータセットがあるとします。ただしyn = f(xn)であり、これは関数fを点x_nで評価した正確でノイズのない観測値です。私たちの目的は、テスト集合X*(サイズN*×d)における関数f*の値を予測することです。
学習点Xとテスト点X*に対して、関数値fとf*の同時事前分布は多変量正規分布として次のように表されます。

ここで
- f:学習点における潜在関数の値ベクトル
- f*:テスト点における潜在関数の値ベクトル
- m(X):学習点における平均ベクトル(簡略化のためゼロとする)
- m(X*):テスト点における平均ベクトル(簡略化のためゼロとする)
- K(X,X):学習点同士のNxN共分散行列
- K(X,X*):学習点とテスト点間のNxN*共分散行列
- K(X*,X*):すべてのテスト点間のN*xN*共分散行列
- N: 入力データポイントの数
- N*:テストデータポイントの数
- d:入力データの次元(特徴量の数)
この場合、観測値yは潜在関数fと一致し(すなわち y=f)、つまり尤度はデルタ関数であるため、yが与えられたときのf*の条件付き分布にすぐに進むことができます。多変量正規分布の条件付き分布の性質により、観測データyが与えられたときの事後分布は次のようになります。

ここで
- μf*:事後平均。学習データに基づく新規(テスト)点における潜在関数f*の最良推定値
- Σf*:テスト点における事後共分散行列。予測の不確実性を定量化するもの
ノイズありの場合:回帰
現実の問題では、観測データyには通常ノイズが含まれます(y=f(X)+ϵ、ここでϵ∼N(0,σ^2)がノイズ)。この場合、ガウス過程は訓練データを完全に補間するのではなく(すべての点を正確に通過するのではなく)、ノイズレベルを考慮してデータを平滑化します。このとき事後分布は、学習データの共分散行列の対角成分にノイズ分散を加えることで修正されます。

ここでノイズパラメータσはモデルのハイパーパラメータであり、カーネルのパラメータと同時に最適化されます。
非常に重要なのは、ノイズを導入すると、潜在関数f*だけでなく新しい観測値y*に対しても信頼区間を予測できるようになることです。ノイズがない場合には、f*とy*の予測分布は同一でしたが、ノイズがある場合には両者は異なります。その違いは主に共分散行列に現れます。Σf*の共分散は潜在関数そのものの不確実性を示しています。Σy*共分散には、潜在関数の不確実性に加えて観測ノイズの分散も含まれます。

- μy*:新しい観測y*に対する事後平均。ノイズの期待値が0であるためμf*と一致します。
- Σy*:新しい観測y*に対する事後共分散
ガウス過程がデータにどのように適応するかを理解するために、事後分布から生成された関数サンプルを考えます。図5は、RBFカーネルを用い、5つの学習点を観測した後に生成された3つの関数サンプルを示しています。

図5:ノイズなし(RBFカーネル)における事後分布からの関数fのサンプル
事前分布では、ガウス過程は無限個の関数集合を記述していました。しかし訓練データを与えると、事後分布はその候補集合を絞り込み、観測点を正確に通過する関数のみを残します。つまり、データを厳密に補間する関数のみに焦点が絞られます。
学習点Xにおいては、分散(事後共分散行列Σ*の対角成分)はゼロとなり、不確実性は存在しません。これは、事後分布からサンプリングされたすべての関数が、必ず学習点を正確に通過することを意味します。一方で、学習点から離れた領域では関数値は変動し得ます。これはデータが存在しない領域におけるモデルの不確実性を反映しています。ただしその挙動は、選択されたカーネル(この場合はRBF)の構造によって依然として制約されています。
次に、観測データ (y) にガウスノイズが含まれる場合の事後分布から生成された関数サンプルを考えます(図6)。

図6:ノイズあり(RBFカーネル)における事後分布からの関数fのサンプル
ノイズが存在する場合、事後分布から得られる関数は観測データ点を厳密に通過する必要はありません。つまり、関数は観測値からノイズの範囲内で逸脱することが許容されるため、データを説明し得る関数の集合はより広くなります。灰色の破線は2シグマ(2σ)の信頼区間を表し、これはf*の事後分布の約95%の確率をカバーします。訓練データから遠い領域では不確実性がさらに増大し、信頼区間は大きく広がります。これは、その領域においてモデルの確信度が低下していることを示しています。重要な点として、灰色の破線は潜在関数f*の信頼区間であり、新しい観測値y*の信頼区間ではないことに注意が必要です。
ガウス過程におけるハイパーパラメータ最適化
ガウス過程モデルの性能は、そのハイパーパラメータの最適な選択に大きく依存します。ハイパーパラメータを適切に設定することで、モデルはデータによりよく適合し、観測された関係性を説明する能力を最大化できます。これらのハイパーパラメータには、カーネルのパラメータおよびノイズ分散が含まれます。ガウス過程では、ハイパーパラメータの最適化は負の対数周辺尤度(NLML, Negative Log Marginal Likelihood)を最小化することによっておこなわれます。

nが大きい場合、(K+σ^2*I)^−1 * yを直接計算すると、n×n行列の逆行列を計算する必要があるため、計算コストが高くなります。そのため、数値計算の効率性と安定性を高めるために、コレスキー分解が用いられます。この分解を用いることで、NLML方程式は次のように書き換えることができます。

- z:線形方程式系をコレスキー分解を用いて解くことで得られるベクトル、z=L^−1*y
- L:コレスキー分解K+σ^2*I = LL^Tによって得られる下三角行列
この方程式は、NegativeLogMarginalLikelihood 関数に実装されています。
//+------------------------------------------------------------------+ //| Calculate the negative log-likelihood | //+------------------------------------------------------------------+ double NegativeLogMarginalLikelihood(const matrix &x, const matrix &y, int &kernel_list[], KernelParams ¶ms) { int n = (int)x.Rows(); //--- Calculate the K covariance matrix matrix K = ComputeKernelMatrix(x, x, kernel_list, params); //--- Add white noise variance if KERNEL_WHITE is selected double white_noise_variance = 0.0; for (int i = 0; i < ArraySize(kernel_list); i++) { if (kernel_list[i] == KERNEL_WHITE) { white_noise_variance = params.white.sigma * params.white.sigma; break; } } // Adding a little jitter prevents problems, // if the K matrix is singular or close to singular // due to the peculiarities of the calculations or the chosen kernel double jitter = 1e-6; K += matrix::Identity(n, n) * (white_noise_variance + jitter); // ---Perform the Cholesky decomposition: K + sigma^2*I = L * L^T matrix L; if (!K.Cholesky(L)) { Print("Error: Cholesky decomposition failed"); return DBL_MAX; } //--- Solve the linear system L * z = y to find z = L^(-1) * y vector z = L.LstSq(y.Col(0)); if (z.Size() == 0) { Print("Error: Unable to solve the system L * z = y"); return DBL_MAX; } //--- Calculate the first term in the NLML equation: // 1/2 * y^T * (K + sigma^2*I)^-1 * y = 1/2 * z^T * z double data_term = 0.5 * z @ z; // Scalar product z^T * z //--- Calculate the second term: 1/2 * log|K + sigma^2*I| = sum(log(L_ii)) vector diag = L.Diag(); double log_det = 0.0; for (int i = 0; i < n; i++) log_det += MathLog(diag[i]); // sum the logarithms of the L diagonal elements //--- Calculate the third term: n/2 * log(2π) double const_term = 0.5 * n * MathLog(2 * M_PI); return data_term + log_det + const_term; }
K共分散行列は、ComputeKernelMatrix関数を使用して計算されます。この関数は、選択されたすべてのカーネル(RBF、線形、周期など)からの寄与を合計します。
//+------------------------------------------------------------------+ //| Calculate the covariance matrix | //+------------------------------------------------------------------+ matrix ComputeKernelMatrix(const matrix &X1, const matrix &X2, int &kernel_list[], KernelParams ¶ms) { matrix K = matrix::Zeros(X1.Rows(), X2.Rows()); for (int i = 0; i < ArraySize(kernel_list); i++) { switch (kernel_list[i]) { case KERNEL_RBF: K += RBF_kernel(X1, X2, params.rbf.sigma_f, params.rbf.length); break; case KERNEL_LINEAR: K += Linear_kernel(X1, X2, params.linear.sigma_l); break; case KERNEL_PERIODIC: K += Periodic_kernel(X1, X2, params.periodic.sigma_f, params.periodic.length, params.periodic.period); break; case KERNEL_WHITE: // WhiteKernel is added separately as sigma^2 * I break; } } return K; }
OptimizeGP関数では、ハイパーパラメータ最適化の目的関数としてNLMLが使用されます。最適化は、ALGLIBライブラリのBLEICメソッドを使用して実行されます。
//+------------------------------------------------------------------+ //| Gaussian process hyperparameter optimization | //+------------------------------------------------------------------+ KernelParams OptimizeGP(int &kernel_list[], matrix &x_train, matrix &y_train) { double w[]; // Array of initial hyperparameter values double s[]; // Array of scales for hyperparameters used for normalization in optimization double bndl[], bndu[]; // Arrays of lower and upper bounds for each hyperparameter CObject Obj; CNDimensional_GP ffunc(kernel_list, x_train, y_train);// Object of a class implementing the NLML target function CNDimensional_Rep frep; // Object for storing the optimization report // Initialize parameters InitializeKernelParams(kernel_list, w, s, bndl, bndu); /* The total number of parameters (num_params) is calculated depending on the kernel types in kernel_list. The initial values of the w parameters, scale and bounds for the parameters are set */ CMinBLEICStateShell state; CMinBLEICReportShell rep; // Object for storing optimization results. double epsg = 0; // Gradient precision (0 means gradient stopping is disabled) double epsf = 0.0001; // Precision by function value double epsw = 0; // accuracy by parameters double diffstep = 0.0001; // Step for numerical calculation of derivatives. double epso = 0.00001; // Parameters for external and internal convergence conditions in BLEIC double epsi = 0.00001; CAlglib::MinBLEICCreateF(w, diffstep, state); // Create a BLEIC optimization object with w initial parameters and diffstep for numerical derivatives CAlglib::MinBLEICSetBC(state, bndl, bndu); // Set parameter bounds (bndl, bndu). CAlglib::MinBLEICSetScale(state, s); // Sets the scale of (s) parameters. CAlglib::MinBLEICSetInnerCond(state, epsg, epsf, epsw); CAlglib::MinBLEICSetOuterCond(state, epso, epsi); CAlglib::MinBLEICOptimize(state, ffunc, frep, 0, Obj); CAlglib::MinBLEICResults(state, w, rep); Print("TerminationType =", rep.GetTerminationType()); // Optimization completion code /* * -8 internal integrity control detected infinite or NAN values in function/gradient. Abnormal termination signalled. * -3 inconsistent constraints. Feasible point is either nonexistent or too hard to find. Try to restart optimizer with better initial approximation * 1 relative function improvement is no more than EpsF. * 2 scaled step is no more than EpsX. * 4 scaled gradient norm is no more than EpsG. * 5 MaxIts steps was taken * 8 terminated by user who called minbleicrequesttermination(). X contains point which was "current accepted" when termination request was submitted. */ Print("IterationsCount =", rep.GetInnerIterationsCount()); // Number of iterations Print("Parameters:"); PrintKernelParams(w, kernel_list); // Display optimized parameters in the log Print("NLML = ", ffunc.GetNLML()); // final NLML value for optimal parameters KernelParams optimized_params; CRowDouble parameters = w; // determine the correct distribution of parameters across kernels ExtractKernelParams(parameters, kernel_list, optimized_params); return optimized_params; }
MQL5におけるガウス過程回帰
ガウス過程回帰モデルの機能を示すために、合成データを用いた例を考えます。実装はGP_Regressorスクリプトで示されており、モデルの作成、学習、およびテストの一連の流れを実演します。
データはDataset関数によって生成されます。この関数は、学習用およびテスト用の合成データ行列を生成します。データセットは、区間[-5,5]に一様分布する100個の点から構成されており、関数y=sin(x)+0.5xにガウスノイズを加えたものとして生成されます。このアプローチにより、線形トレンドと周期成分の両方を含み、さらに不確実性も考慮した実データに近いデータをシミュレーションすることができます。
回帰モデルを構築するためには、共分散関数を構成するカーネルの一覧を定義する必要があります。各カーネルは共分散行列Kに固有の寄与を行い、モデルが捉えることのできる依存関係の性質を決定します。カーネルの一覧は SetKernelList関数によって設定されます。この関数は、入力パラメータ kernel_combination(列挙型 KernelCombination)に基づいてkernel_list配列を生成します。以下の組み合わせがサポートされています。
- COMBINATION_1:[RBF, Linear, White] (3個のカーネル)
- COMBINATION_2:[RBF, Linear, Periodic, White](4個のカーネル)
- COMBINATION_3:[RBF, White](2個のカーネル)
カーネルを選択した後、モデルのハイパーパラメータはOptimizeGP関数によって最適化されます。この関数は負の対数周辺尤度(NLML, Negative Log Marginal Likelihood)を最小化し、その結果として各カーネルの最適なパラメータを格納したKernelParams構造体を返します。最適化されるパラメータには、振幅(σ_f)、長さ尺度(l)、周期(p)などです。
最適なパラメータが求められた後、Predict関数を用いて予測を実行します。
//+------------------------------------------------------------------------+ //| Predict the Gaussian posterior distribution for new points | //+------------------------------------------------------------------------+ GPPredictionResult Predict(const matrix &x_train, const matrix &y_train, const matrix &x_test, int &kernel_list[], KernelParams ¶ms) { GPPredictionResult result; // Calculate the K covariance matrix for the training points matrix K = ComputeKernelMatrix(x_train, x_train, kernel_list, params); // Obtain the observation noise variance double observation_noise_variance = 0.0; for (int i = 0; i < ArraySize(kernel_list); i++) { if (kernel_list[i] == KERNEL_WHITE) { observation_noise_variance = params.white.sigma * params.white.sigma; break; } } // Form a noise matrix for the training data: K + sigma_n^2 * I matrix K_noisy_train = K + matrix::Identity((int)x_train.Rows(), (int)x_train.Rows()) * observation_noise_variance; // Calculate the K* cross-covariance matrix between training and test points matrix K_star = ComputeKernelMatrix(x_train, x_test, kernel_list, params); // Calculate the posterior mean matrix inv_term = K_noisy_train.Inv(); result.mu_f_star = K_star.Transpose() @ (inv_term @ y_train); // Matches mu_y_star // Calculate the posterior covariance matrix for the latent function (Sigma_f_star) matrix K_star_star = ComputeKernelMatrix(x_test, x_test, kernel_list, params); result.Sigma_f_star = K_star_star - K_star.Transpose() @ (inv_term @ K_star); // Calculate the posterior covariance matrix for a new observation (Sigma_y_star) // Sigma_y_star = Sigma_f_star + sigma_n^2 * I result.Sigma_y_star = result.Sigma_f_star + matrix::Identity((int)x_test.Rows(), (int)x_test.Rows()) * observation_noise_variance; return result; }
Predict関数はGPモデル実装の中核となる要素です。この関数は単に予測値を返すだけではなく、テスト点における事後分布に関する完全な情報を提供します。この関数は、以下の内容を含むGPPredictionResult構造体を返します。
- 潜在関数f*の事後平均(μf* = μy*)
- 潜在関数f*の事後共分散行列Σf*
- 観測値y*の事後共分散行列Σy*これは、潜在関数の不確実性に加えて、WhiteKernelパラメータの最適化によって決定された観測ノイズ分散(σ^2)も含む行列です。
それでは、異なるカーネルの組み合わせに対する予測結果を見てみましょう。まず、データにノイズが存在すると仮定し、RBFカーネルのみを用いて関数を予測してみます(図7)。

図7: RBFカーネルによる予測
- 赤い点:学習データ(TrainData)
- 青い線:予測平均
- 緑色の星印:テスト点(X*)に対する予測
- 青い点:学習範囲外のテストデータ
- 灰色の破線:信頼区間( f*またはy*に対する±2シグマ)
ここで分かるように、テスト点が学習データの範囲 ([-5,5]) から離れるにつれて、予測値はGPの事前平均へと収束していきます。事前平均は通常ゼロに設定されます。これは、学習データから離れた領域では、RBFカーネルにおける共分散K*(新しい点x*と学習点xの間の共分散)が指数関数的にゼロへ減衰するためです。そのため、RBFカーネルはデータの補間には適していますが、相関が急速に減衰するため、外挿への適用には限界があります。
外挿性能を改善するために、線形カーネルを追加します(図8)。

図8:RBFカーネルと線形カーネルの和による予測(f*の信頼区間)
線形カーネルは線形関係をモデル化するため、特にデータに線形あるいはそれに近いトレンドが存在する場合には、外挿に適しています。今回の例では、y=sin(x)+0.5xという関数が対象であり、線形成分0.5xが含まれています。線形カーネルを追加することで、この線形成分を捉えることができ、学習データ範囲外での予測が改善されました。しかし、グラフから分かるように、モデルは依然としてデータ構造を完全には表現できておらず、周期的な成分を十分に捉えられていません。
データ中のsin(x)のような季節性または周期的変動をモデル化するために、周期カーネルを使用します(図9)。

図9:RBFカーネル、周期カーネル、および線形カーネルの和による予測(f*の信頼区間)
周期カーネルを追加した結果、モデルはデータ中に存在するすべての重要な依存関係を捉えることができるようになり、非常に高い予測精度を達成しました。その結果、潜在関数f*に対する信頼区間は事後平均とほぼ重なっています。一方で、観測値y*に対する予測区間は大幅に広くなっています。これは、観測ノイズの分散が考慮されているためであり、図10に示されています。
")
図10:RBFカーネル、周期カーネル、および線形カーネルの和による予測(y*の信頼区間)
GPによる予測について、重要な注意点があります。ノイズ分散を適切に考慮しない場合、f*(x)に対する信頼区間をy*に対する予測区間として誤って解釈してしまう可能性があります。y*に対する正しい予測区間を得るためには、共分散行列に観測ノイズ分散を明示的に含める必要があります。
結論
本記事では、回帰問題を例として、ガウス過程(GP)の基礎について詳しく見てきました。まず、GPを構成する主要な要素である事前分布、尤度、および事後分布について説明しました。事後分布は、不確実性を定量化した完全な確率的予測を提供します。また、RBF、Linear、Periodicといった基本的なカーネル関数を実装しました。もちろん、実際にはこれ以外にも多くの種類のカーネルが存在します。
特に、GPをデータに適応させる上で重要となるハイパーパラメータ最適化に重点を置いて説明しました。この最適化は、負の対数周辺尤度(Negative Log Marginal Likelihood: NLML)の最小化によって実現されます。また、計算効率と数値安定性を向上させるために、コレスキー分解(Cholesky decomposition)を利用しました。実装したモデルでは、最適化アルゴリズムとして、ALGLIBライブラリの勾配法BLEICを使用しています。
本記事ではGPの基本原理に焦点を当てており、いくつかの発展的なトピックについては扱っていません。たとえば、NLMLの勾配を解析的に計算する手法、大規模データを扱うためのスパース近似(Sparse Approximation)などが挙げられます。特にこれらの手法は、最適化効率の大幅な向上や大規模データセットへの適用において重要な役割を果たします。これらは今後のGP研究における重要な発展方向です。
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | GP_Samples_Prior.mq5 | スクリプト | 事前分布から生成したサンプルのデモンストレーション |
| 2 | GP_Samples_Posterior.mq5 | スクリプト | 事後分布から生成したサンプルのデモンストレーション |
| 3 | GP_Regressor | スクリプト | 回帰モデルの構築 |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/18427
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
回帰のためのガウス過程と ウィーナー・キンチン定理の間には強い関連性があります。 https://danmackinlay.name/notebook/wiener_khintchine.htmlhttps://www.numberanalytics.com/blog/wiener-khinchin-theorem-guide この方向で引き続き解説していただければ、 大変ありがたいです。
確かにあまり人気のある手法ではありませんが、私はそこに将来性を感じています。 私が惹かれるのは、カーネルアプローチを理解することで、データ分析に対する統一された一貫した視点を得られるという点です。ここには、回帰分析、分類、カーネル密度推定、特徴量の選択、独立性の統計的検定などがすべて含まれています。
いずれにせよ、興味深いですね :)