
Neuronale Netze im Handel: Ein Multi-Agenten-System mit konzeptioneller Verstärkung (letzter Teil)

Einführung
Im vorangegangenen Artikel haben wir die theoretischen Aspekte des FinCon-Rahmens untersucht, der als Werkzeug für die Analyse und Automatisierung im Finanzbereich entwickelt wurde. Sein Ziel ist es, die Entscheidungsfindung auf den Finanzmärkten zu unterstützen, indem es Big-Data-Verarbeitung, natürliche Sprachverarbeitung (NLP) und Portfoliomanagementtechniken einsetzt. Der Kerngedanke des Systems liegt in der Verwendung einer Multi-Agenten-Architektur, bei der jedes Modul spezifische Aufgaben ausführt und mit anderen interagiert, um gemeinsame Ziele zu erreichen.
Eine Schlüsselkomponente dieser Architektur ist der Manager-Agent, der die Arbeit der Analysten-Agenten koordiniert. Der Manager aggregiert die von den Analysten ermittelten Ergebnisse, führt eine Risikokontrolle durch und verfeinert die Anlagestrategie. FinCon beschäftigt spezialisierte Analysten, die jeweils für verschiedene Aspekte der Datenverarbeitung und -analyse, Marktprognosen und Risikobewertung zuständig sind. Diese Arbeitsteilung verringert die Informationsredundanz und beschleunigt die Datenverarbeitung.
Der Rahmen sieht eine zweistufige Risikomanagement-Architektur vor:
- Die erste Ebene arbeitet in Echtzeit und minimiert kurzfristige Verluste.
- Auf der zweiten Ebene werden die Maßnahmen des Systems auf der Grundlage der abgeschlossenen Episoden bewertet, um Fehler zu ermitteln und Strategien zu verbessern.
Eines der wichtigsten Merkmale von FinCon ist die Verwendung von Conceptual Verbal Reinforcement Feedback (CVRF). Mit diesem Mechanismus werden sowohl die Leistung der Analystenvertreter als auch die Handelsentscheidungen des Managers bewertet. Es ermöglicht dem System, aus seinen eigenen Erfahrungen zu lernen und seine Verhaltenspolitik zu verfeinern, indem es sich auf die einflussreichsten Marktfaktoren konzentriert.
Der Rahmen umfasst auch ein dreistufiges Speichersystem:
- Der Arbeitsspeicher speichert vorübergehend de Daten, die für laufende Operationen benötigt werden.
- Der prozedurale Speicher speichert bewährte Methoden und Algorithmen zur Wiederverwendung.
- Der episodische Speicher speichert Schlüsselereignisse und deren Ergebnisse und ermöglicht es dem System, vergangene Erfahrungen zu analysieren und Lehren für zukünftige Entscheidungen zu ziehen.
Die Originalvisualisierung des FinCon-Rahmens finden Sie unten.

Im vorigen Artikel haben wir begonnen, unsere eigene Interpretation der von den Autoren des Rahmens vorgeschlagenen Ansätze umzusetzen. Innerhalb des Objekts CNeuronMemoryDistil haben wir Algorithmen für das dreischichtige Speichersystem entwickelt. Heute setzen wir diese Arbeit fort.
Das Objekt „Analyst Agent“
Wir beginnen mit dem Aufbau des Moduls Analyst Agent. Die Autoren von FinCon haben ein universelles Agentenmodul entwickelt, das unabhängig von den spezifischen Aufgaben in verschiedenen Bereichen eingesetzt werden kann. Diese Flexibilität wird durch eine Architektur erreicht, die auf einem vortrainierten großen Sprachmodell (LLM) basiert, das nach dem Frage-Antwort-Prinzip (QA) funktioniert. Das Verhalten des Agenten hängt von der Frage oder Aufgabe ab, die er erhält.
Obwohl unsere Modelle kein LLM verwenden, können wir dennoch ein universelles Objekt schaffen, das für verschiedene spezialisierte Analysten-Agenten anpassbar ist. Dieser Ansatz gewährleistet die Flexibilität und Modularität des Systems.
Nach Angaben der Autoren integrieren FinCon-Agenten mehrere Schlüsselmodule, die zusammen ihre Funktionalität unterstützen.
Das Konfigurations- und Profiling-Modul spielt eine wichtige Rolle bei der Festlegung der Aufgabentypen, die der Agent ausführt. Darin werden nicht nur die Handelsziele festgelegt, einschließlich der Einzelheiten zu den Wirtschaftssektoren und den Leistungskennzahlen, sondern auch die Aufgaben und Zuständigkeiten der Akteure verteilt. Das Modul bildet einen grundlegenden textuellen Rahmen, der zur Erstellung funktionaler Abfragen an die Speicherdatenbank verwendet wird.
Darüber hinaus ermöglicht das Konfigurations- und Profiling-Modul den Agenten die Anpassung an verschiedene Wirtschaftssektoren, indem es die für die jeweilige Aufgabe relevantesten Metriken ermittelt. Die von ihm generierten Informationen bilden die Grundlage für eine kohärente Interaktion zwischen allen anderen Systemkomponenten.
Das Wahrnehmungsmodul steuert die Interaktion des Agenten mit seiner Umwelt. Sie regelt die Wahrnehmung von Marktinformationen, indem sie Daten filtert und aussagekräftige Muster identifiziert. Dadurch kann sich der Agent an veränderte Bedingungen anpassen und gleichzeitig die Genauigkeit und Effizienz seiner Prognosen aufrechterhalten.
Das Speichermodul ist eine kritische Komponente, die die für die Entscheidungsfindung erforderlichen Daten speichert und verarbeitet. Es besteht aus drei Hauptbestandteilen: Arbeitsspeicher, prozeduraler Speicher und episodischer Speicher. Das Arbeitsspeicher ermöglicht es dem Agenten, laufende Aufgaben auszuführen, Marktveränderungen zu beobachten und seine Handlungen anzupassen. Das Verfahrensspeicher speichert alle Schritte, die der Bearbeiter unternimmt, einschließlich der Ergebnisse und Schlussfolgerungen. Der episodische Speicher speichert Daten über abgeschlossene Aufgaben und trägt zur Bildung langfristiger Strategien bei.
In der vorherigen Arbeit haben wir bereits das Speichermodul entwickelt und können nun diese fertige Lösung verwenden. Der ursprüngliche FinCon-Rahmen gewährte nur dem Manager Zugang zum episodischen Speicher. In unserer Implementierung werden jedoch alle Agenten die dreistufige Speicherstruktur verwenden. Jeder Agent verfügt über ein eigenes Speichermodul, das natürlich den Zugriff auf die Daten beschränkt, die nur für seine spezifischen Aufgaben relevant sind. Auf diese Weise kann jeder Agent nicht nur die jüngsten Veränderungen berücksichtigen, sondern auch den breiteren zeitlichen Kontext.
Die Funktionalität des Konfigurations- und Profiling-Moduls setzt das Vorhandensein eines dedizierten externen Objekts voraus, das Aufgaben entsprechend der Spezialisierung der einzelnen Agenten und der verfügbaren Eingabedaten generiert. In unserer Implementierung gehen wir von einheitlichen Eingangsdaten aus. Das bedeutet, dass bei einer festen Agentenrolle bei jedem Schritt identische Abfragen generiert werden. Während des Modelltrainings können diese Abfragen jedoch angepasst werden, um sie besser auf die aktuelle Rolle und die Fähigkeiten des Agenten abzustimmen.
Diese Überlegung führt uns zu der Idee, einen trainierbaren Abfrage-Tensor innerhalb des Agentenmoduls selbst zu erstellen. Mit diesem Ansatz entfällt die Notwendigkeit eines zusätzlichen externen Informationsstroms. Die Anfangswerte dieses Tensors werden bei der Objekterstellung zufällig initialisiert. Diese Parameter bilden die „angeborenen kognitiven Fähigkeiten“ des Agenten. Diese dienen als einzigartige Grundlage für das zukünftige Lernen.
Mit fortschreitendem Training entwickelt der Agent allmählich eine Rolle, die seinen bei der Initialisierung definierten Fähigkeiten am besten entspricht. Auf diese Weise kann sich der Agent organisch an seine Aufgaben anpassen und gleichzeitig seine „angeborenen“ Eigenschaften effizient nutzen, wodurch eine solide Grundlage für die weitere Entwicklung geschaffen wird. Der trainierbare Abfragetensor wird zu einem Schlüsselinstrument für die Identifizierung und Verstärkung des am besten geeigneten Entwicklungsverlaufs. Dieses Design gewährleistet die Kohärenz zwischen dem zufälligen Ausgangszustand des Agenten und seiner Zielrolle, wodurch die Trainingskosten gesenkt und die Effizienz des Modells insgesamt verbessert werden.
Das Hauptziel des Wahrnehmungsmoduls ist es, Methoden zu identifizieren, die die relevantesten Muster aus dem Datenstrom für die Aufgaben des Agenten extrahieren. Um diese Funktionalität zu implementieren, können wir Mechanismen der Kreuzaufmerksamkeit verwenden. Diese ermöglichen es dem Modell, die relevantesten Informationen „hervorzuheben“ und eine effektive Filterung und Datenverarbeitung zu gewährleisten.
Nach der Konstruktion der internen Module des Agenten besteht der nächste wichtige Schritt in der Analyse seiner Ausgabe. Eine zentrale Frage ist die nach der Spezifität der Ergebnisse. Einerseits hängt diese Besonderheit von der Aufgabe des Agenten ab, was dem Konzept eines universellen Agenten zu widersprechen scheint. Andererseits erschweren unterschiedliche Ausgaben die Verarbeitung der Ergebnisse, sodass eine Standardisierung unerlässlich ist.
In unserer Implementierung produziert jeder Agent einen Tensor, der eine vorgeschlagene Handelsentscheidung als Ausgabe darstellt. Der ursprüngliche FinCon-Rahmen gewährt dem Manager die ausschließliche Befugnis, Handelsentscheidungen zu treffen. Es gibt jedoch keine Einschränkung für Agenten, die ihre eigenen Vorschläge einreichen. Dieser Ansatz ermöglicht es uns, eine einheitliche Datenstruktur für die Darstellung von Agenten-Outputs zu schaffen, unabhängig von deren spezifischen Rollen. Eine solche Standardisierung vereinfacht die Ergebnisverarbeitung und erhöht die Effizienz des gesamten Systems.
Alle oben genannten Konzepte sind in dem Objekt CNeuronFinConAgent implementiert. Seine Struktur wird im Folgenden dargestellt.
class CNeuronFinConAgent : public CNeuronRelativeCrossAttention { protected: CNeuronMemoryDistil cStatesMemory; CNeuronMemoryDistil cActionsMemory; CNeuronBaseOCL caRole[2]; CNeuronRelativeCrossAttention cStateToRole; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return feedForward(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return updateInputWeights(NeuronOCL); } public: CNeuronFinConAgent(void) {}; ~CNeuronFinConAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConAgent; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
In der vorgestellten Struktur finden sich eine Reihe von Methoden, die überschrieben werden können, sowie mehrere Objekte, die zur Organisation der oben beschriebenen Ansätze verwendet werden. Wir werden den spezifischen Zweck jeder dieser Komponenten untersuchen, wenn wir mit der Implementierung der Algorithmen für die Objektmethoden fortfahren.
Es ist auch wichtig zu beachten, dass das Objekt der Kreuzaufmerksamkeit als übergeordnete Klasse verwendet wird. Die geerbten Methoden und Objekte dieser Klasse werden ebenfalls verwendet, um den Betrieb des Moduls zu organisieren, das wir erstellen.
Alle internen Objekte werden als statisch deklariert, wodurch die Klassenstruktur vereinfacht wird und sowohl der Konstruktor als auch der Destruktor leer bleiben können. Die Initialisierung von internen und geerbten Objekten wird in der Methode Init durchgeführt. Diese Methode benötigt eine Reihe von Konstanten, die klar und eindeutig die Architektur des zu erstellenden Objekts definieren.
bool CNeuronFinConAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, 3, window_key, action_space / 3, heads, window, units_count, optimization_type, batch)) return false;
Innerhalb des Methodenkörpers beginnen wir (wie immer) mit dem Aufruf der gleichnamigen Methode der Elternklasse, die bereits die Initialisierung der geerbten Objekte und die Schnittstellen für den Datenaustausch mit externen Komponenten organisiert.
Wie bereits erwähnt, wurde das Objekt der Kreuzaufmerksamkeit als übergeordnete Klasse gewählt. Diese Objekte sind so konzipiert, dass sie zwei Datenströme verarbeiten können, was im Zusammenhang mit FinCon-Agenten fragwürdig erscheinen mag, da diese zunächst mit einem einzigen, für die ihnen zugewiesene Aufgabe spezifischen Informationsstrom arbeiten. Die Agenten erhalten jedoch auch Daten aus dem Speichermodul. Damit wird ein zweiter Datenstrom eingeführt. Darüber hinaus ist ein entscheidender Aspekt der Tätigkeit eines Agenten seine sequentielle Analyse – seine Fähigkeit, seine eigenen Handlungen zu reflektieren und Anpassungen als Reaktion auf veränderte Marktbedingungen vorzunehmen. Dieser Reflexionsprozess schafft einen dritten Informationsstrom.
In unserer Implementierung wird die Reflexionsfunktionalität mit Hilfe von Mechanismen organisiert, die von der übergeordneten Klasse geerbt werden. Der Kreuzaufmerksamkeits-Ansatz dürfte sich als wirksam erweisen, wenn es darum geht, den Tensor früherer Ergebnisse im Zusammenhang mit den sich verändernden Marktbedingungen anzupassen. So besteht der primäre Datenstrom des übergeordneten Objekts aus den Parametern des Ergebnistensors, während der zweite Datenstrom Informationen über den aktuellen Zustand der Umgebung enthält.
Erinnern Sie sich daran, dass wir am Ausgang des Agenten einen Tensor von empfohlenen Handelsoperationen erwarten.
Als Nächstes initialisieren wir zwei Aufmerksamkeitsmodule. Diese Module speichern separat die Dynamik der Marktbedingungen und die Abfolge der vom Agenten vorgeschlagenen Handelsentscheidungen. Diese Struktur ermöglicht es uns, die Wirksamkeit der angewandten Verhaltenspolitik im Kontext der aktuellen Marktdynamik besser zu bewerten.
int index = 0; if(!cStatesMemory.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, stack_size, optimization, iBatch)) return false; index++; if(!cActionsMemory.Init(0, index, OpenCL, iWindow, iWindowKey, iUnits, iHeads, stack_size, optimization, iBatch)) return false;
Das Profiling-Modul besteht aus zwei sequentiellen, vollständig verknüpften Schichten. Die erste Schicht enthält ein einzelnes Element mit einem festen Wert von 1, während die zweite Schicht einen Tensor mit einer bestimmten Größe erzeugt. In unserer Implementierung ist die Länge des generierten Vektors zehnmal größer als die Beschreibung eines einzelnen Elements in der Eingabesequenz. Dies kann so interpretiert werden, dass die Rolle des Agenten durch eine Sequenz aus zehn Elementen dargestellt wird.
index++; if(!caRole[0].Init(10 * iWindow, index, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = caRole[0].getOutput(); if(!out || !out.Fill(1)) return false; index++; if(!caRole[1].Init(0, index, OpenCL, 10 * iWindow, optimization, iBatch)) return false;
Das Wahrnehmungsmodul wird, wie bereits erwähnt, durch ein internes Cross-Attention-Objekt dargestellt. Es analysiert die empfangenen Eingabedaten im Kontext der Agentenspezialisierung.
index++; if(!cStateToRole.Init(0, index, OpenCL, window, iWindowKey, iUnitsKV, iHeads, iWindow, 10, optimization, iBatch)) return false; //--- return true; }
Nach erfolgreicher Initialisierung aller internen und geerbten Objekte geben wir ein logisches Ergebnis an das aufrufende Programm zurück und beenden die Ausführung der Methode.
Der nächste Entwicklungsschritt besteht in der Implementierung des Algorithmus für den Vorwärtsdurchlauf innerhalb der Methode feedForward. Hier müssen wir den Informationsfluss zwischen den zuvor initialisierten Objekten organisieren.
bool CNeuronFinConAgent::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !caRole[1].FeedForward(caRole[0].AsObject())) return false;
Die Methodenparameter enthalten einen Zeiger auf das Eingabedatenobjekt, das Beschreibungen des Umweltzustands enthält. Es ist wichtig, daran zu erinnern, dass jeder Agent die eingehenden Informationen entsprechend seiner spezifischen Rolle analysiert. Daher erzeugen wir zunächst einen Tensor, der die zugewiesene Aufgabe beschreibt.
Beachten Sie, dass der Tensor der Agentenrollen nur während des Trainings erzeugt wird. Im Test- und Produktionsmodus bleibt die Spezialisierung des Agenten konstant, und es ist nicht notwendig, diesen Tensor bei jeder Iteration neu zu erstellen.
Als Nächstes verwenden wir das interne Kreuzaufmerksamkeits-Objekt, um Muster zu extrahieren, die für die Lösung der dem Agenten zugewiesenen Aufgabe relevant sind.
if(!cStateToRole.FeedForward(NeuronOCL, caRole[1].getOutput())) return false; if(!cStatesMemory.FeedForward(cStateToRole.AsObject())) return false;
Die erhaltenen Werte werden dann an das Modul für den Umgebungszustandsspeicher weitergeleitet und reichern den aktuellen Zustand mit Informationen über die vorangegangene Marktdynamik an. Dieser Ansatz ermöglicht ein tieferes kontextuelles Verständnis.
In ähnlicher Weise fügen wir die Ergebnisse des vorangegangenen Vorwärtsdurchlaufs dem Agenten-Aktionsspeichermodul hinzu.
if(!cActionsMemory.FeedForward(this.AsObject())) return false;
Als Ergebnis geben die beiden Speichermodule Tensoren aus, die die letzten Handlungen des Agenten und die entsprechenden Umweltveränderungen beschreiben. Diese Daten werden an die gleichnamige Methode der übergeordneten Klasse weitergegeben, die den Tensor der empfohlenen Handelsoperationen unter Berücksichtigung der aktuellen Marktdynamik anpasst.
Vor diesem Schritt ist es jedoch notwendig, die Zeiger auf die Datenpuffer zu tauschen, wodurch der vorherige Ergebnissensor erhalten bleibt. Dadurch wird die korrekte Ausführung der Backpropagation-Operationen während des Modelltrainings sichergestellt.
if(!SwapBuffers(Output, PrevOutput)) return false; //--- return CNeuronRelativeCrossAttention::feedForward(cActionsMemory.AsObject(), cStatesMemory.getOutput()); }
Das logische Ergebnis dieser Operationen wird an das aufrufende Programm zurückgegeben, und die Methode ist beendet.
Nach Fertigstellung des Algorithmus des Vorwärtsdurchlaufs wird der Informationsfluss für den Rückwärtsdurchlauf organisiert. Bekanntlich spiegelt der Datenfluss bei der Gradientenfortpflanzung die Struktur der Feedforward-Phase wider, bewegt sich aber in die entgegengesetzte Richtung. Dank des identischen Routings der Vorwärts- und Rückwärtsgänge kann das Modell den Einfluss jedes Parameters auf das Endergebnis effizient berücksichtigen.
Die Operationen zur Gradientenverteilung sind in der Methode calcInputGradients implementiert. Diese Methode erhält einen Zeiger auf das Eingabedatenobjekt, aber dieses Mal müssen wir Fehlergradientenwerte übergeben, die den Einfluss der Eingabedaten auf das Endergebnis des Modells widerspiegeln.
bool CNeuronFinConAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Innerhalb der Methode prüfen wir zunächst die Gültigkeit des empfangenen Zeigers, denn wenn er ungültig ist, sind weitere Operationen sinnlos.
Der eigentliche Prozess der Gradientenverteilung beginnt mit einem Aufruf der gleichnamigen Methode der Elternklasse. Es gibt die Fehlergradienten an die Aufmerksamkeitsmodule weiter.
if(!CNeuronRelativeCrossAttention::calcInputGradients(cActionsMemory.AsObject(), cStatesMemory.getOutput(), cStatesMemory.getGradient(), (ENUM_ACTIVATION)cStatesMemory.Activation())) return false;
Über das Modul Handelsoperationen-Vorschlagsspeicher geben wir dann den Fehlergradienten an unser aktuelles Objekt zurück. Denn seine früheren Vorsteuerergebnisse wurden als Eingabe für dieses Speichermodul verwendet. Allerdings enthält der Ergebnispuffer nun andere Werte, die aus der letzten Vorwärtsoperation stammen. Außerdem wollen wir die aktuellen Werte des Gradientenpuffers erhalten. Um dies zu erreichen, stellen wir zunächst die Ergebnisse des vorherigen Vorwärtsdurchlaufs wieder her, indem wir die Ergebnispufferzeiger vertauschen. Als Nächstes wird der Zeiger auf den Gradientenpuffer durch einen freien Datenpuffer ersetzt. Erst nach Abschluss dieser Vorarbeiten gehen wir dazu über, die Fehlergradienten zu verteilen.
CBufferFloat *temp = Gradient; if(!SwapBuffers(Output, PrevOutput) || !SetGradient(cActionsMemory.getPrevOutput(), false)) return false; if(!calcHiddenGradients(cActionsMemory.AsObject())) return false; if(!SwapBuffers(Output, PrevOutput)) return false; Gradient = temp;
Es ist wichtig zu beachten, dass wir die Gradienten nicht rekursiv auf frühere Durchgänge übertragen. Daher wird der aus diesen Operationen gewonnene Gradient nicht wiederverwendet. Diese Schritte sind jedoch notwendig, um eine korrekte Verteilung der Gradienten auf die internen Objekte des Speichermoduls zu gewährleisten. Nach Abschluss dieser Aktionen stellen wir die ursprünglichen Pufferzeiger wieder her.
Anschließend verteilen wir den Fehlergradienten entlang der Pipeline des Umgebungszustandsspeichermoduls. Hier wird der Gradient zunächst an das Wahrnehmungsmodul weitergeleitet, das, wie bereits erwähnt, mit einem Kreuzaufmerksamkeits-Block implementiert ist.
if(!cStateToRole.calcHiddenGradients(cStatesMemory.AsObject())) return false;
Dann verteilen wir die erhaltenen Fehlergradienten zwischen den Eingabedaten und dem MLP, der für die Generierung des Agentenrollentensors verantwortlich ist, entsprechend ihrem jeweiligen Einfluss auf die Leistung des Modells.
if(!NeuronOCL.calcHiddenGradients(cStateToRole.AsObject(), caRole[1].getOutput(), caRole[1].getGradient(), (ENUM_ACTIVATION)caRole[1].Activation())) return false; //--- return true; }
Wir propagieren keine Gradienten durch den MLP, der den Agentenrollentensor erzeugt, da seine erste Schicht einen festen Wert enthält.
Nach Abschluss aller erforderlichen Operationen gibt die Methode ein logisches Erfolgsflag an das aufrufende Programm zurück und beendet die Ausführung.
Damit ist unsere Untersuchung der Algorithmen abgeschlossen, mit denen die Methoden des universellen Objekts „Analyst Agent“ erstellt werden. Den vollständigen Code dieser Klasse und alle ihre Methoden finden Sie im Anhang.
Das Manager-Objekt
Der nächste Schritt unserer Arbeit besteht darin, das Objekt Manager-Agent zu konstruieren. Hier ergibt sich eine leichte begriffliche Dissonanz. Einerseits haben wir über den Aufbau eines universellen Agenten gesprochen, der auch als Manager fungieren kann. Die Rolle des Managers hingegen besteht darin, die Ergebnisse zu konsolidieren und die Aktionen aller Akteure zu koordinieren. Das bedeutet, dass sie Informationen aus mehreren Quellen erhalten muss.
Die folgende Umsetzung kann auf verschiedene Weise betrachtet werden. Zum Beispiel als Anpassung des zuvor gebauten Universalagenten, um Führungsaufgaben zu übernehmen. Die universelle Agentenklasse dient hier als übergeordnete Klasse für das neue Objekt – ihre Struktur wird im Folgenden vorgestellt.
class CNeuronFinConManager : public CNeuronFinConAgent { protected: CNeuronTransposeOCL cTransposeState; CNeuronFinConAgent caAgents[3]; CNeuronFinConAgent caTrAgents[3]; CNeuronFinConAgent cRiskAgent; CNeuronBaseOCL cConcatenatedAgents; CNeuronBaseOCL cAccount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override {return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronFinConManager(void) {}; ~CNeuronFinConManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFinConManager; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; virtual void TrainMode(bool flag); };
Um den externen Datenfluss zu minimieren, haben wir alle Agenten in das Managerobjekt selbst integriert. In dieser Konfiguration kann der Manager als ein in sich geschlossener FinCon-Rahmen betrachtet werden. Dies ist jedoch eher eine Frage der Interpretation. Konzentrieren wir uns nun auf die Entwicklung der funktionalen Fähigkeiten dieses neuen Objekts.
In der Struktur des neuen Objekts sehen wir wieder eine vertraute Reihe von überschreibbaren Methoden und mehrere interne Objekte, deren Rolle wir beim Entwurf der Algorithmen für die Methoden der Klasse untersuchen werden.
Alle internen Objekte werden als statisch deklariert, sodass wir den Konstruktor und Destruktor der Klasse leer lassen können. Die Initialisierung aller deklarierten und geerbten Objekte wird in der Methode Init durchgeführt. Alle internen Objekte werden als statisch deklariert, sodass sowohl der Konstruktor als auch der Destruktor der Klasse leer bleiben können.
bool CNeuronFinConManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint account_descr, uint action_space, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFinConAgent::Init(numOutputs, myIndex, open_cl, action_space, window_key, caAgents.Size() + caTrAgents.Size() + 1, heads, stack_size, action_space, optimization_type, batch)) return false;
Im Methodenkörper rufen wir wie üblich die entsprechende Methode der übergeordneten Klasse auf. Aber in diesem Fall gibt es eine Nuance. Die Ausgangsdaten für den Manager sind die Ergebnisse der Arbeit der Agenten. Daher entspricht das Eingabefenster für den Manager der Dimension des Ergebnisvektors eines einzelnen Agenten, während die Sequenzlänge der Gesamtzahl der internen Agenten, einschließlich des Risikobewertungsagenten, entspricht.
Es ist anzumerken, dass unser Manager mit zwei Arten von Analysten arbeitet, die jeweils das aktuelle Umfeld aus unterschiedlichen Perspektiven analysieren. Um die zweite Projektion der Eingabedaten zu erhalten, verwenden wir ein Matrix-Transpositionsobjekt.
int index = 0; if(!cTransposeState.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
Als Nächstes organisieren wir zwei aufeinanderfolgende Initialisierungsschleifen für die Analysten-Agenten.
for(uint i = 0; i < caAgents.Size(); i++) { index++; if(!caAgents[i].Init(0, index, OpenCL, window, iWindowKey, units_count, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
for(uint i = 0; i < caTrAgents.Size(); i++) { index++; if(!caTrAgents[i].Init(0, index, OpenCL, units_count, iWindowKey, window, iHeads, stack_size, action_space, optimization, iBatch)) return false; }
Dann fügen wir einen Risikokontrollagenten hinzu. Seine Eingaben werden durch einen Vektor dargestellt, der den Stand der Leistungsbilanz beschreibt, und dieser wird in den Initialisierungsparametern explizit angegeben.
index++; if(!cRiskAgent.Init(0, index, OpenCL, account_descr, iWindowKey, 1, iHeads, stack_size, action_space, optimization, iBatch)) return false;
Außerdem benötigen wir ein Objekt, um die Ergebnisse aller internen Agenten zu verketten. Diese kombinierte Ausgabe dient dann als Input für den Manager-Agenten, dessen Funktionalität wir von der übergeordneten Klasse erben.
index++; if(!cConcatenatedAgents.Init(0, index, OpenCL, caAgents.Size()*caAgents[0].Neurons() + caTrAgents.Size()*caTrAgents[0].Neurons() + cRiskAgent.Neurons(), optimization, iBatch)) return false;
Es ist hervorzuheben, dass die Kontostandsinformationen über einen Hilfsdatenstrom, der durch einen speziellen Datenpuffer dargestellt wird, erhalten werden. Für das ordnungsgemäße Funktionieren des initialisierten Risikokontrollagenten ist jedoch ein Objekt der neuronalen Schicht erforderlich, das diese Eingabedaten enthält. Deshalb erstellen wir ein internes Objekt, in das die Informationen aus dem sekundären Datenstrom übertragen werden.
index++; if(!cAccount.Init(0, index, OpenCL, account_descr, optimization, iBatch)) return false; //--- return true; }
Nach Abschluss aller erforderlichen Operationen gibt die Methode ein logisches Erfolgsflag an das aufrufende Programm zurück und beendet die Ausführung.
Wir fahren nun fort, den Algorithmus des Vorwärtsdurchlaufs innerhalb der Methode feedForward zu konstruieren. In diesem Fall arbeiten wir mit zwei Eingangsdatenströmen. Der primäre Strom liefert einen Tensor, der den analysierten Umweltzustand beschreibt, während der sekundäre Strom die finanziellen Ergebnisse des Modells in Form eines Kontostandsvektors enthält.
bool CNeuronFinConManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(cAccount.getOutput() != SecondInput) { if(!cAccount.SetOutput(SecondInput, true)) return false; }
Innerhalb der Methode führen wir zunächst einen kurzen Vorverarbeitungsschritt durch, bei dem der Ergebnispufferzeiger des sekundären Eingangsdatenobjekts (Kontostand) durch den entsprechenden Puffer aus dem entsprechenden Datenstrom ersetzt wird. Wir transponieren auch den Tensor der Eingabedaten aus dem Primärstrom.
if(!cTransposeState.FeedForward(NeuronOCL)) return false;
Nach Abschluss dieser vorbereitenden Schritte übergeben wir die resultierenden Daten an die Analyse-Agenten zur Analyse und Vorschlagserstellung.
//--- Agents for(uint i = 0; i < caAgents.Size(); i++) if(!caAgents[i].FeedForward(NeuronOCL)) return false; for(uint i = 0; i < caTrAgents.Size(); i++) if(!caTrAgents[i].FeedForward(cTransposeState.AsObject())) return false; if(!cRiskAgent.FeedForward(cAccount.AsObject())) return false;
Die Ausgaben der Agenten werden dann zu einem einzigen Objekt verkettet.
//--- Concatenate if(!Concat(caAgents[0].getOutput(), caAgents[1].getOutput(), caAgents[2].getOutput(), cRiskAgent.getOutput(), cConcatenatedAgents.getPrevOutput(), Neurons(), Neurons(), Neurons(), Neurons(), 1) || !Concat(caTrAgents[0].getOutput(), caTrAgents[1].getOutput(), caTrAgents[2].getOutput(), cConcatenatedAgents.getPrevOutput(), cConcatenatedAgents.getOutput(), Neurons(), Neurons(), Neurons(), 4 * Neurons(), 1)) return false;
Die zusammengefassten Ergebnisse werden dann an den Manager weitergeleitet, der auf der Grundlage der Empfehlungen aller Agenten die endgültige Handelsentscheidung trifft.
//--- Manager return CNeuronFinConAgent::feedForward(cConcatenatedAgents.AsObject()); }
Das logische Ergebnis wird an das aufrufende Programm zurückgegeben.
Damit ist die Erörterung der Algorithmen abgeschlossen, die zur Erstellung der Manager-Methoden verwendet werden. Die Methoden der Rückwärtsdurchläufe bleiben einer unabhängigen Studie vorbehalten. Die vollständige Implementierung der Klasse und aller ihrer Methoden finden Sie in den beigefügten Materialien.
Modell der Architektur
Ein paar Worte sollten über die Architektur des trainierbaren Modells gesagt werden. Bei der Vorbereitung dieses Artikels wurde nur ein einziges Modell trainiert, der Agent der Handelsentscheidungen. Dies sollte nicht mit den Akteuren des FinCon-Rahmens selbst verwechselt werden.
Die Architektur des trainierten Modells wurde fast unverändert aus früheren Arbeiten übernommen, die sich mit dem FinAgent Methode gewidmet sind. Es wurde nur eine neuronale Schicht ersetzt, was die Integration der im FinCon-Rahmen implementierten Ansätze ermöglicht.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFinConManager; //--- Windows { int temp[] = {BarDescr, 24, AccountDescr, 2 * NActions}; //Window, Stack Size, Account description, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Der vollständige Code der Modellarchitektur ist in der Anlage enthalten. Es enthält auch Programme für die Ausbildung und Prüfung. Da diese Skripte unverändert aus früheren Arbeiten übernommen wurden, werden wir sie hier nicht im Detail analysieren.
Tests
Die letzten beiden Artikel waren dem FinCon-Rahmen gewidmet, in dem wir seine Grundprinzipien eingehend untersucht haben. Unsere Interpretation der Rahmenmethoden wurde in MQL5 implementiert, und es ist nun an der Zeit, die Wirksamkeit dieser Implementierungen an realen historischen Daten zu bewerten.
Es sei darauf hingewiesen, dass sich die hier vorgestellte Implementierung erheblich von der ursprünglichen unterscheidet, was sich natürlich auf die Ergebnisse auswirkt. Daher können wir nur von einer Bewertung der Effizienz der implementierten Ansätze sprechen, nicht von einer Reproduktion der ursprünglichen Ergebnisse.
Für das Modelltraining wurden H1 EURUSD-Daten aus dem Jahr 2024 verwendet. Die Parameter der analysierten Indikatoren wurden unverändert gelassen, um sich ausschließlich auf die Bewertung der algorithmischen Leistung zu konzentrieren.
Der Trainingsdatensatz wurde aus mehreren Durchläufen mehrerer Modelle mit zufällig initialisierten Parametern gebildet. Darüber hinaus haben wir erfolgreiche Läufe einbezogen, die aus verfügbaren Marktsignaldaten unter Verwendung der Methode Real-ORL abgeleitet wurden. Dadurch wurde der Datensatz mit positiven Beispielen angereichert und die Abdeckung der möglichen Marktszenarien erweitert.
Beim Training haben wir einen Algorithmus verwendet, der „nahezu perfekte“ Zielhandlungen für den Agenten erzeugt. Dies ermöglicht ein Modelltraining, ohne dass der Datensatz ständig aktualisiert werden muss. Wir empfehlen jedoch, die Daten regelmäßig zu aktualisieren, was die Lernergebnisse durch die Erweiterung der Zustandsraumabdeckung weiter verbessern kann.
Der letzte Test wurde mit den verfügbaren Daten vom Januar 2025 durchgeführt, wobei alle anderen Parameter unverändert blieben. Die Ergebnisse werden im Folgenden vorgestellt.
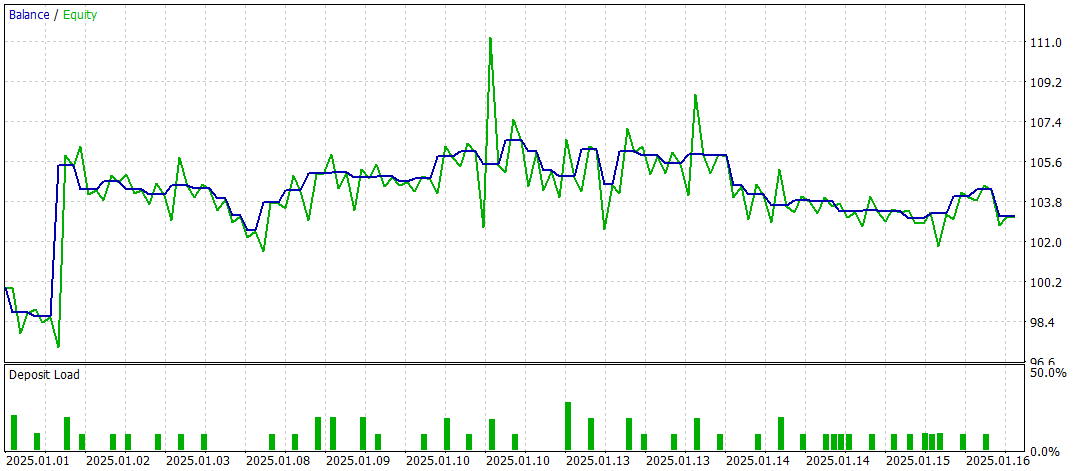
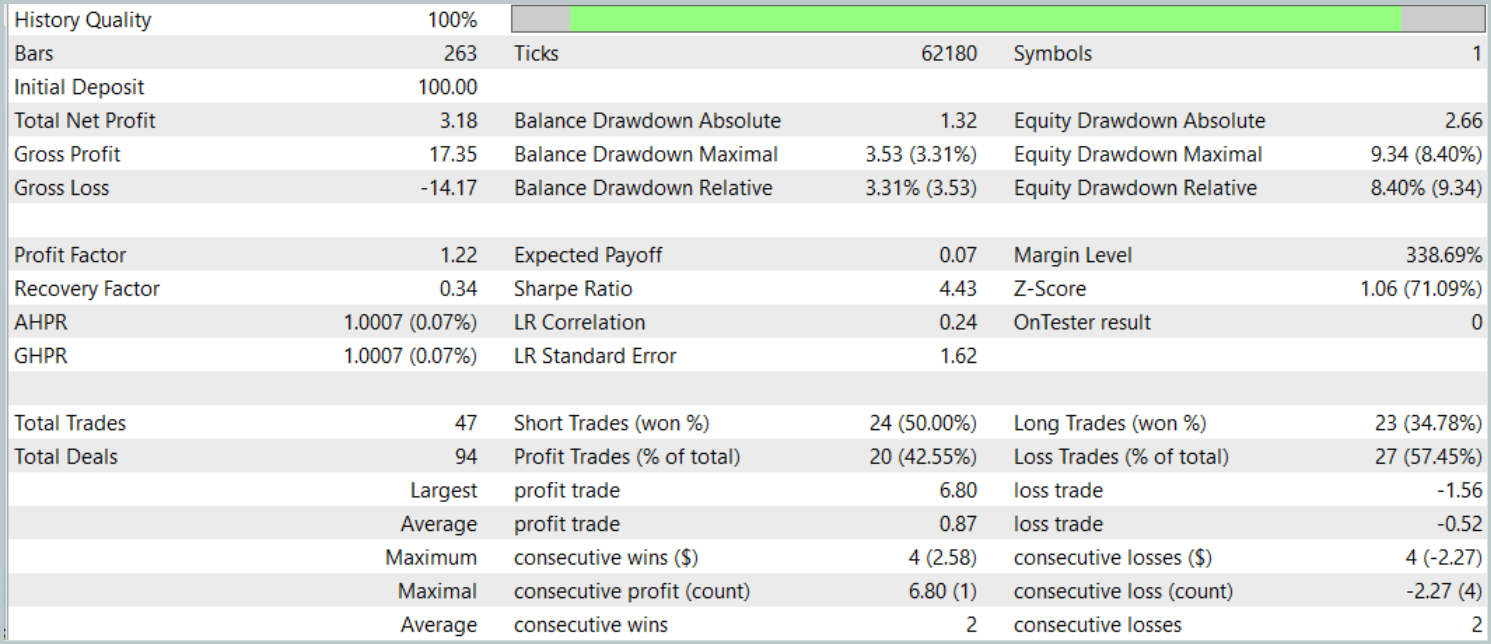
Die Testergebnisse lassen eine gemischte Bewertung der Wirksamkeit des Modells zu. Während des Testzeitraums erzielte das Modell bei 47 Handelsgeschäften einen Gewinn, aber nur 42 % dieser Handelsgeschäfte waren erfolgreich. Darüber hinaus ist der größte Teil des Saldenwachstums auf ein einziges profitables Handelsgeschäft zurückzuführen, während die Saldenkurve für den Rest der Zeit in einem engen Bereich bleibt. Dies deutet darauf hin, dass das Modell weiter optimiert werden muss.
Schlussfolgerung
In diesem Artikel haben wir die wichtigsten Komponenten und Funktionen des FinCon-Frameworks sowie seine Vorteile bei der Automatisierung und Optimierung von Handelsentscheidungen untersucht. Im praktischen Teil haben wir die vorgeschlagenen Methoden in MQL5 implementiert. Wir haben ein Modell entwickelt und trainiert, das auf realen historischen Daten basiert, und seine Leistung bewertet. Die Testergebnisse zeigen jedoch, dass das Modell zwar Potenzial aufweist, aber noch weiter verfeinert und optimiert werden muss, um eine stabilere und gleichbleibend hohe Leistung zu erzielen.
Referenzen
- FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making
- Andere Artikel aus dieser Reihe
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor für die Probenahme |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für die Probenahme mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | EA für das Modelltraining |
| 4 | Test.mq5 | Expert Advisor | Expert Advisor für Modelltests |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Beschreibung des Systemzustands und der Modellarchitektur |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code-Bibliothek | OpenCL-Programmcode |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16937
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.