
Entwicklung eines Expert Advisors für mehrere Währungen (Teil 21): Vorbereitungen für ein wichtiges Experiment und Optimierung des Codes
Einführung
Im vorangegangenen Teil haben wir damit begonnen, das automatische Optimierungsband in Betrieb zu nehmen, das es uns ermöglicht, einen neuen endgültigen EA unter Berücksichtigung der akkumulierten Preisdaten zu erhalten. Wir haben jedoch noch nicht die vollständige Automatisierung erreicht, da noch schwierige Entscheidungen darüber getroffen werden müssen, wie die letzten Schritte am besten umgesetzt werden können. Sie sind schwierig, denn wenn wir die falsche Wahl treffen, müssen wir vieles neu machen. Deshalb möchte ich mir die Mühe sparen und versuchen, die richtige Wahl zu treffen. Und nichts hilft bei schwierigen Entscheidungen so sehr, wie... sie aufzuschieben! Vor allem, wenn wir es uns leisten können.
Aber wir können sie auf verschiedene Weise aufschieben. Anstatt den Moment der Entscheidung einfach hinauszuzögern, sollten wir versuchen, uns einer anderen Aufgabe zuzuwenden, die uns scheinbar ablenkt, deren Lösung aber zumindest dazu beitragen kann, die Motivation zu erhöhen, eine Entscheidung zu treffen, wenn nicht sogar den richtigen Weg zu finden.
Interessante Frage
Der Stolperstein in vielen Debatten über den Einsatz der Parameteroptimierung ist die Frage, wie lange die erhaltenen Parameter für den Handel in der Zukunft verwendet werden können, während die Rentabilität und der Drawdown auf dem vorgegebenen Niveau bleiben. Und ist das überhaupt möglich?
Es gibt zwar die weit verbreitete Ansicht, dass man sich nicht auf die Wiederholbarkeit von Testergebnissen in der Zukunft verlassen kann und es nur eine Frage des Glücks ist, wann die Strategie „versagt“. Wahrscheinlich wollen fast alle Entwickler von Handelsstrategien dies wirklich glauben, da sonst der Sinn des enormen Aufwands für Entwicklung und Tests verloren geht.
Es wurde bereits mehrfach versucht, durch die Wahl guter Parameter das Vertrauen zu erhöhen, dass die Strategie für einige Zeit erfolgreich arbeiten kann. Es gibt Artikel, die sich auf die eine oder andere Weise mit dem Thema der periodischen automatischen Auswahl der besten EA-Parameter befassen. Der EA Validate von @fxsaber verdient eine gesonderte Erwähnung, da er gerade für die Durchführung eines sehr interessanten Experiments gedacht ist.
Mit diesem Tool können wir einen beliebigen EA (den zu untersuchenden) nehmen und nach Auswahl eines bestimmten Zeitraums (z.B. 3 Jahre) den folgenden Prozess starten: Der zu untersuchende EA wird über einen bestimmten Zeitraum (z.B. 2 Monate) optimiert, um dann mit den besten Einstellungen über einen Zeitraum von z.B. zwei Wochen im Strategietester zu handeln. Am Ende jeder zweiwöchigen Periode wird der untersuchte EA erneut für die vorangegangenen zwei Monate optimiert und für weitere zwei Wochen gehandelt. Dies wird so lange fortgesetzt, bis das Ende des gewählten 3-Jahres-Intervalls erreicht ist.
Das Endergebnis wird ein Handelsbericht sein, der zeigt, wie der untersuchte EA im Laufe aller drei Jahre gehandelt hätte, wenn er wirklich regelmäßig neu optimiert und mit aktualisierten Parametern gestartet worden wäre. Es ist klar, dass Sie die genannten Zeitintervalle nach eigenem Ermessen frei wählen können. Wenn ein EA mit einer solchen Re-Optimierung akzeptable Ergebnisse vorweisen kann, dann zeigt dies sein erhöhtes Potenzial für den Einsatz im realen Handel.
Dieses Tool hat jedoch eine wesentliche Einschränkung – der untersuchte EA muss offene Eingabeparameter haben, um eine Optimierung durchzuführen. Nehmen wir zum Beispiel unsere endgültigen EAs, die wir in den vorangegangenen Teilen durch die Kombination vieler einzelner Instanzen erhalten haben, so verfügen sie nicht über Eingaben, die es ihnen ermöglichen würden, die Handelslogik der Positionseröffnung zu beeinflussen. Wir werden die Parameter des Geld- und Risikomanagements nicht berücksichtigen, da ihre Optimierung zwar möglich, aber ziemlich sinnlos ist. Denn es ist klar, dass, wenn wir die Größe der eröffneten Positionen erhöhen, das Ergebnis des Passes einen größeren Gewinn ausweist, als das, was zuvor als Ergebnis des Passes mit einer kleineren Positionsgröße erzielt wurde.
Versuchen wir daher, etwas Ähnliches zu implementieren, das jedoch auf unsere entwickelten EAs anwendbar ist.
Der Weg ist vorgezeichnet
Im Allgemeinen benötigen wir ein Skript, um die Datenbank mit nahezu identischen Projekten zu füllen. Der Hauptunterschied besteht lediglich im Anfangs- und Enddatum des Optimierungszeitraums. Die Zusammensetzung der Etappen, der Etappenarbeiten und der Aufgaben innerhalb der Arbeit kann völlig identisch sein. Daher können Sie einen EA-Dienst mit einer geringen Anzahl von Eingaben erstellen, einschließlich des Startdatums und der Dauer des Optimierungszeitraums. Wenn wir das Programm im Optimierungsmodus mit einer Suche nach Startdaten ausführen, können wir die Datenbank mit ähnlichen Projekten füllen. Es ist noch nicht klar, welche anderen Parameter sinnvollerweise in die Eingaben aufgenommen werden sollten; wir werden darüber im Laufe der Entwicklung entscheiden.
Die vollständige Durchführung aller Optimierungsaufgaben, selbst innerhalb eines einzelnen Projekts, kann viel Zeit in Anspruch nehmen. Wenn nicht nur ein einziges Projekt, sondern ein Dutzend oder mehr abgeschlossen werden muss, dann handelt es sich um ziemlich zeitaufwändige Aufgaben. Daher ist es sinnvoll zu prüfen, ob es möglich ist, die Arbeit von Stage EAs irgendwie zu beschleunigen. Um Engpässe zu erkennen, die behoben werden müssen, werden wir den in MetaEditor enthaltenen Profiler verwenden.
Als Nächstes müssen wir entscheiden, wie die Arbeit aus mehreren erhaltenen Initialisierungsstrings simuliert werden soll (jedes Projekt wird nach Abschluss seiner Aufgaben einen Initialisierungsstring des endgültigen EA liefern). Höchstwahrscheinlich müssen wir einen neuen Test-EA erstellen, der speziell für diese Art von Arbeit konzipiert ist. Aber das werde ich wahrscheinlich auf den nächsten Artikel verschieben.
Beginnen wir zunächst mit der Optimierung des Codes der Test-EAs. Danach beginnen wir mit der Erstellung eines Skripts zum Befüllen der Datenbank.
Codeoptimierung
Bevor wir uns mit der Implementierung der Hauptaufgabe befassen, wollen wir sehen, ob es eine Möglichkeit gibt, den Code der an der automatischen Optimierung beteiligten EAs zu beschleunigen. Um mögliche Engpässe aufzuspüren, nehmen wir den letzten EA aus dem vorherigen Teil zur Untersuchung. Er kombiniert 32 Instanzen von einzelnen Handelsstrategien (2 Symbole * 1 Zeitrahmen * 16 Instanzen = 32). Dies ist natürlich viel weniger als die erwartete Gesamtzahl der Instanzen im endgültigen EA, aber während der Optimierung wird die absolute Mehrheit unserer Durchläufe entweder eine Instanz (in der ersten Stufe) oder nicht mehr als 16 Instanzen (in der zweiten Stufe) verwenden. Daher ist eine solcher EA als Testobjekt perfekt für uns geeignet.
Starten wir den EA im Profilingmodus mit historischen Daten. Wenn Sie in diesem Modus arbeiten, wird automatisch eine spezielle Version des EA für das Profiling kompiliert und im Strategietester gestartet. Wir zitieren die Beschreibung der Profilerstellung aus der Referenz:
Die Stichprobenmethode wird für die Profilerstellung verwendet. Der Profiler hält den Betrieb eines MQL-Programms an (~10 000 Mal pro Sekunde) und sammelt Statistiken darüber, wie oft eine Pause in einem bestimmten Codeteil aufgetreten ist. Dazu gehört die Analyse von Aufrufstapeln, um den „Beitrag“ jeder Funktion zur gesamten Code-Ausführungszeit zu ermitteln.
Die Probenahme ist eine leichte und genaue Methode. Im Gegensatz zu anderen Methoden werden beim Sampling keine Änderungen am analysierten Code vorgenommen, die sich auf dessen Laufgeschwindigkeit auswirken könnten.
Der Profiling-Bericht wird als Funktionen oder Programmzeilen dargestellt, für die jeweils zwei Indikatoren verfügbar sind:
- Total CPU [unit,%] – wie oft die Funktion im Aufrufstapel erschien.
- Self CPU [Maßeinheit, %] – die Anzahl der „Pausen“, die direkt innerhalb der angegebenen Funktion aufgetreten sind. Diese Variable ist für die Ermittlung von Engpässen von entscheidender Bedeutung: Laut Statistik treten Pausen häufiger dort auf, wo mehr Prozessorzeit benötigt wird.
Der Wert wird als absolute Menge und als Prozentsatz der Gesamtmenge angezeigt.
Dies ist das Ergebnis nach Abschluss des Passes:
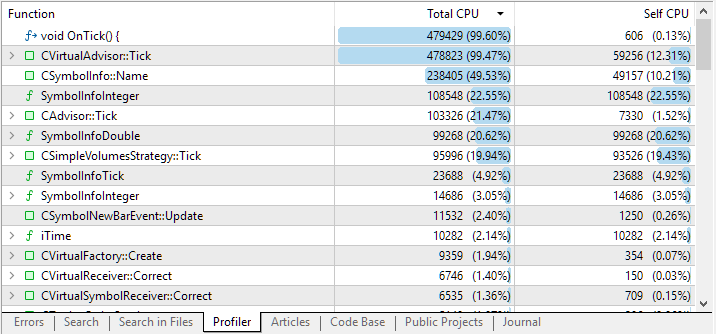
Abb. 1. Ergebnisse der Profilerstellung des Codes des untersuchten EA
Standardmäßig werden in der Profilergebnisliste große Funktionen auf den obersten Ebenen angezeigt. Wenn man jedoch auf die Zeichenkette mit dem Funktionsnamen klickt, sieht man eine verschachtelte Liste von Funktionen, die von dieser einen Funktion aus aufgerufen wurden. So können wir genauer bestimmen, welche Codeabschnitte die meiste CPU-Zeit beanspruchen.
In den ersten beiden Zeilen wurde erwartungsgemäß OnTick() sowie das von ihm aufgerufene CVirtualAdvisor::Tick() angezeigt. Tatsächlich verbringt der EA neben der Initialisierung die meiste Zeit damit, eingehende Ticks zu verarbeiten. Die dritte und vierte Zeile der Ergebnissen werfen jedoch berechtigte Fragen auf.
Warum gibt es so viele Aufrufe der Methode „current symbol select“? Warum wird so viel Zeit darauf verwendet, einige ganzzahlige Eigenschaften des Symbols zu erhalten? Lassen Sie es uns herausfinden.
Durch die Erweiterung der Zeichenkette, die dem Aufruf der Methode CSymbolInfo::Name(string name) entspricht, können wir feststellen, dass fast die gesamte Zeit damit verbracht wird, sie von der Funktion zur Überprüfung der Notwendigkeit, die virtuelle Position zu schließen, aufzurufen.
//+------------------------------------------------------------------+ //| Check the need to close by SL, TP or EX | //+------------------------------------------------------------------+ bool CVirtualOrder::CheckClose() { if(IsMarketOrder()) { // If this is a market virtual position, s_symbolInfo.Name(m_symbol); // Select the desired symbol s_symbolInfo.RefreshRates(); // Update information about current prices // ... } return false; }
Dieser Code wurde vor ziemlich langer Zeit geschrieben. Zu diesem Zeitpunkt war es für uns wichtig, dass offene virtuelle Positionen korrekt in reale Positionen umgewandelt wurden. Die Schließung einer virtuellen Position sollte zu einer sofortigen (oder fast sofortigen) Schließung eines gewissen Volumens an realen Positionen führen. Daher sollte diese Prüfung bei jedem Tick und für jede offene virtuelle Position durchgeführt werden.
Aus Gründen der Autarkie haben wir jedes Objekt der Klasse CVirtualOrder mit einer Objektinstanz der Klasse CSymbolInfo versehen, über die wir alle erforderlichen Informationen über Preise und Spezifikationen des gewünschten Handelsinstruments (Symbol) abfragen. Bei 16 Instanzen von Handelsstrategien, die jeweils drei virtuelle Positionen verwenden, gibt es also 16*3 = 48 davon im Array der virtuellen Positionen. Wenn der EA mehrere hundert Instanzen von Handelsstrategien enthält und auch eine größere Anzahl virtueller Positionen verwendet, steigt die Anzahl der Aufrufe der Symbolauswahlmethode um ein Vielfaches. Aber ist das notwendig?
Wann ist es wirklich notwendig, die Methode für die Symbolselektion aufzurufen? Nur wenn sich das virtuelle Positionssymbol geändert hat. Wenn es sich seit dem letzten Tick nicht geändert hat, ist der Aufruf dieser Symbolmethode nutzlos. Das Symbol kann sich nur ändern, wenn eine virtuelle Position eröffnet wird, die entweder noch nicht eröffnet wurde oder für ein anderes Symbol eröffnet wurde. Dies geschieht natürlich nicht bei jedem Tick, aber viel, viel seltener. Außerdem wird bei der verwendeten Modellstrategie nie das Symbol für eine virtuelle Position geändert, da eine Instanz der Handelsstrategie mit einem einzigen Symbol arbeitet, das für alle virtuellen Positionen dieser Instanz der Strategie gilt.
Dann können Sie die Objekte der Klasse CSymbolInfo an die Instanzebene der Handelsstrategie senden, aber auch dies kann redundant sein, da verschiedene Instanzen der Handelsstrategie das gleiche Symbol verwenden können. Deshalb werden wir sie noch weiter nach oben bringen – auf die globale Ebene. Auf dieser Ebene müssen wir nur die Anzahl der Instanzen der Objekte der Klasse CSymbolInfo haben, die der Anzahl der verschiedenen Symbole entspricht, die im EA verwendet werden. Jede Instanz von CSymbolInfo wird nur erstellt, wenn der EA auf die Eigenschaften eines neuen Symbols zugreifen muss. Einmal erstellt, wird eine Kopie dauerhaft einem bestimmten Symbol zugewiesen.
Angeregt durch das folgende Beispiel aus dem Buch, werden wir unsere eigene Klasse CSymbolsMonitor erstellen. Im Gegensatz zum Beispiel werden wir keine neue Klasse erstellen, die, obwohl sie viel ordentlicher geschrieben ist, im Wesentlichen die Funktionalität einer bestehenden Klasse in der Standardbibliothek wiederholt. Unsere Klasse wird als Container für mehrere Objekte der Klasse CSymbolInfo fungieren und dafür sorgen, dass für jedes verwendete Symbol ein eigenes Informationsobjekt der Klasse erstellt wird.
Um den Zugriff von jeder Stelle des Codes aus zu ermöglichen, verwenden wir bei der Implementierung wieder das Singleton-Designmuster. Die Basis der Klasse bildet das Array m_symbols[], in dem die Zeiger auf die Objekte der Klasse CSymbolInfo gespeichert sind.
//+--------------------------------------------------------------------+ //| Class for obtaining information about trading instruments (symbols)| //+--------------------------------------------------------------------+ class CSymbolsMonitor { protected: // Static pointer to a single class instance static CSymbolsMonitor *s_instance; // Array of information objects for different symbols CSymbolInfo *m_symbols[]; //--- Private methods CSymbolsMonitor() {} // Closed constructor public: ~CSymbolsMonitor(); // Destructor //--- Static methods static CSymbolsMonitor *Instance(); // Singleton - creating and getting a single instance // Tick handling for objects of different symbols void Tick(); // Operator for getting an object with information about a specific symbol CSymbolInfo* operator[](const string &symbol); }; // Initializing a static pointer to a single class instance CSymbolsMonitor *CSymbolsMonitor::s_instance = NULL;
Die Implementierung der statischen Methode zur Erzeugung einer einzelnen Instanz einer Klasse ähnelt den Implementierungen, die wir bereits kennengelernt haben. Der Destruktor enthält eine Schleife zum Löschen der erstellten Informationsobjekte.
//+------------------------------------------------------------------+ //| Singleton - creating and getting a single instance | //+------------------------------------------------------------------+ CSymbolsMonitor* CSymbolsMonitor::Instance() { if(!s_instance) { s_instance = new CSymbolsMonitor(); } return s_instance; } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CSymbolsMonitor::~CSymbolsMonitor() { // Delete all created information objects for symbols FOREACH(m_symbols, if(!!m_symbols[i]) delete m_symbols[i]); }
Die öffentliche Tick-Handling-Methode sorgt für regelmäßige Aktualisierungen der Symbolangaben und Kursinformationen. Möglicherweise ändert sich die Spezifikation im Laufe der Zeit gar nicht, aber vorsichtshalber werden wir sie einmal am Tag aktualisieren. Wir werden die Kurse jede Minute aktualisieren, da wir den Betriebsmodus des EA nur für die Eröffnung von Minutenbalken verwenden (für eine bessere Wiederholbarkeit der Modellierungsergebnisse im 1-Minuten-OHLC-Modus und im Every-Tick-Modus, der auf echten Ticks basiert).
//+------------------------------------------------------------------+ //| Handle a tick for the array of virtual orders (positions) | //+------------------------------------------------------------------+ void CSymbolsMonitor::Tick() { // Update quotes every minute and specification once a day FOREACH(m_symbols, { if(IsNewBar(m_symbols[i].Name(), PERIOD_D1)) { m_symbols[i].Refresh(); } if(IsNewBar(m_symbols[i].Name(), PERIOD_M1)) { m_symbols[i].RefreshRates(); } }); }
Schließlich fügen wir einen überladenen Indizierungsoperator hinzu, um einen Zeiger auf das gewünschte Objekt mit einem Symbolnamen zu erhalten. In diesem Operator erfolgt die automatische Erstellung neuer Informationsobjekte für Symbole, auf die zuvor noch nicht über diesen Operator zugegriffen wurde.
//+-------------------------------------------------------------------------+ //| Operator for getting an object with information about a specific symbol | //+-------------------------------------------------------------------------+ CSymbolInfo* CSymbolsMonitor::operator[](const string &name) { // Search for the information object for the given symbol in the array int i; SEARCH(m_symbols, m_symbols[i].Name() == name, i); // If found, return it if(i != -1) { return m_symbols[i]; } else { // Otherwise, create a new information object CSymbolInfo *s = new CSymbolInfo(); // Select the desired symbol for it if(s.Name(name)) { // If the selection is successful, update the quotes s.RefreshRates(); // Add to the array of information objects and return it APPEND(m_symbols, s); return s; } else { PrintFormat(__FUNCTION__" | ERROR: can't create symbol with name [%s]", name); } } return NULL; }
Wir speichern den Code in der Datei SymbolsMonitor.mqh im aktuellen Ordner. Jetzt kommt der Code an die Reihe, der die erstellte Klasse verwenden wird.
Änderung des CVirtualAdvisor
In dieser Klasse gibt es bereits mehrere Objekte, die jeweils als einzige Kopie existieren und bestimmte Aufgaben erfüllen: einen Empfänger von virtuellen Positionsvolumina, einen Risikomanager und eine Nutzerinformationsschnittstelle. Fügen wir ihnen ein Symbol-Monitor-Objekt hinzu. Genauer gesagt werden wir ein Klassenfeld erstellen, das einen Zeiger auf das Symbolmonitorobjekt speichert:
class CVirtualAdvisor : public CAdvisor { protected: CSymbolsMonitor *m_symbols; // Symbol monitor object CVirtualReceiver *m_receiver; // Receiver object that brings positions to the market CVirtualInterface *m_interface; // Interface object to show the status to the user CVirtualRiskManager *m_riskManager; // Risk manager object ... public: ... };
Die Erstellung des Symbolmonitor-Objekts wird beim Aufruf des Konstruktors durch den Aufruf der statischen Methode CSymbolsMonitor::Instance() eingeleitet, ähnlich wie bei anderen bereits erwähnten Objekten. Wir werden die Löschung dieses Objekts in den Destruktor aufnehmen.
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualAdvisor::CVirtualAdvisor(string p_params) { ... // If there are no read errors, if(IsValid()) { // Create a strategy group CREATE(CVirtualStrategyGroup, p_group, groupParams); // Initialize the symbol monitor with a static symbol monitor m_symbols = CSymbolsMonitor::Instance(); // Initialize the receiver with the static receiver m_receiver = CVirtualReceiver::Instance(p_magic); // Initialize the interface with the static interface m_interface = CVirtualInterface::Instance(p_magic); ... } } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ void CVirtualAdvisor::~CVirtualAdvisor() { if(!!m_symbols) delete m_symbols; // Remove the symbol monitor if(!!m_receiver) delete m_receiver; // Remove the recipient if(!!m_interface) delete m_interface; // Remove the interface if(!!m_riskManager) delete m_riskManager; // Remove risk manager DestroyNewBar(); // Remove the new bar tracking objects }
Fügen wir die neue Tick-Behandlung dem Aufruf der Methode Tick() hinzu, um Symbole zu überwachen. Hier werden die Notierungen aller im EA verwendeten Symbole aktualisiert:
//+------------------------------------------------------------------+ //| OnTick event handler | //+------------------------------------------------------------------+ void CVirtualAdvisor::Tick(void) { // Define a new bar for all required symbols and timeframes bool isNewBar = UpdateNewBar(); // If there is no new bar anywhere, and we only work on new bars, then exit if(!isNewBar && m_useOnlyNewBar) { return; } // Symbol monitor updates quotes m_symbols.Tick(); // Receiver handles virtual positions m_receiver.Tick(); // Start handling in strategies CAdvisor::Tick(); // Risk manager handles virtual positions m_riskManager.Tick(); // Adjusting market volumes m_receiver.Correct(); // Save status Save(); // Render the interface m_interface.Redraw(); }
Bei dieser Gelegenheit fügen wir die Ereignisbehandlung durch ChartEvent zu dieser Klasse hinzu, mit Blick auf die Zukunft. Vorerst wird darin die gleichnamige Methode des Schnittstellenobjekts m_interface aufgerufen. In diesem Stadium bewirkt sie nichts.
Wir speichern die an der Datei VirtualAdvisor.mqh vorgenommenen Änderungen im aktuellen Ordner.
Änderung an CVirtualOrder
Wie bereits erwähnt, erfolgt die Beschaffung von Informationen über Symbole in der Klasse der virtuellen Positionen. Beginnen wir also damit, von dieser Klasse aus Änderungen vorzunehmen, und fügen wir zunächst einmal Zeiger auf den Monitor (die KlasseCSymbolsMonitor) und das Informationsobjekt für ein Symbol (die KlasseCSymbolInfo) hinzu:
class CVirtualOrder { private: //--- Static fields static ulong s_count; // Counter of all created CVirtualOrder objects CSymbolInfo *m_symbolInfo; // Object for getting symbol properties //--- Related recipient objects and strategies CSymbolsMonitor *m_symbols; CVirtualReceiver *m_receiver; CVirtualStrategy *m_strategy; ... }
Das Hinzufügen von Zeigern zur Komposition von Klassenfeldern bedeutet, dass ihnen Zeiger auf einige erstellte Objekte zugewiesen werden sollten. Und wenn diese Objekte innerhalb der Methoden von Objekten dieser Klasse erstellt werden, dann ist es notwendig, für ihre korrekte Löschung zu sorgen.
Fügen wir die Initialisierung des Zeigers auf den Symbolmonitor und die Löschung des Zeigers auf das Symbolinformationsobjekt hinzu. Wir rufen die statische Methode CSymbolsMonitor::Instance() auf, um den Zeiger auf den Symbolmonitor zu erhalten. Die Erstellung eines einzelnen Monitorobjekts (falls noch nicht vorhanden) erfolgt innerhalb dieses Objekts. Im Destruktor tragen wir das Löschen der Informationsobjekts ein, wenn es erstellt wurde und noch nicht gelöscht wurde:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CVirtualOrder::CVirtualOrder(CVirtualStrategy *p_strategy) : // Initialization list m_id(++s_count), // New ID = object counter + 1 ... m_point(0) { PrintFormat(__FUNCTION__ + "#%d | CREATED VirtualOrder", m_id); m_symbolInfo = NULL; m_symbols = CSymbolsMonitor::Instance(); } //+------------------------------------------------------------------+ //| Destructor | //+------------------------------------------------------------------+ CVirtualOrder::~CVirtualOrder() { if(!!m_symbolInfo) delete m_symbolInfo; }
Ich habe den Zeiger auf das Info-Objekt m_symbolInfo nicht in den Konstruktor aufgenommen, da zum Zeitpunkt des Konstruktoraufrufs nicht immer genau bekannt ist, welches Symbol an dieser virtuellen Position verwendet werden soll. Dies wird erst beim Öffnen einer virtuellen Position deutlich, d. h. beim Aufruf der Methode CVirtualOrder::Open(). Wir werden die Initialisierung des Zeigers auf das Symbolinformationsobjekt hinzufügen:
//+------------------------------------------------------------------+ //| Open a virtual position (order) | //+------------------------------------------------------------------+ bool CVirtualOrder::Open(string symbol, // Symbol ENUM_ORDER_TYPE type, // Type (BUY or SELL) double lot, // Volume double price = 0, // Open price double sl = 0, // StopLoss level (price or points) double tp = 0, // TakeProfit level (price or points) string comment = "", // Comment datetime expiration = 0, // Expiration time bool inPoints = false // Are the SL and TP levels set in points? ) { if(IsOpen()) { // If the position is already open, then do nothing PrintFormat(__FUNCTION__ "#%d | ERROR: Order is opened already!", m_id); return false; } // Get a pointer to the information object for the desired symbol from the symbol monitor m_symbolInfo = m_symbols[symbol]; if(!!m_symbolInfo) { // Actions to open ... return true; } else { ... return false; } }
Da der Symbolmonitor für die Aktualisierung der Informationen zu den Symbolkursen zuständig ist, können wir nun die Klasse CVirtualOrder von allen Aufrufen der Methoden Name() und RefreshRates() für das Informationsobjekt m_symbolInfo der Symboleigenschaften befreien. Wenn wir eine virtuelle Position in m_symbolInfo öffnen, speichern wir den Zeiger auf das Objekt, für das das gewünschte Symbol bereits ausgewählt wurde. Beim Begleiten einer zuvor geöffneten virtuellen Position wurde die Methode RefreshRates() bereits einmal für diesen Tick aufgerufen – dies wurde vom Symbolmonitor für alle in der Methode CSymbolsMonitor::Tick() durchgeführt.
Lassen Sie uns das Profiling noch einmal durchführen. Das Bild hat sich zum Besseren gewandelt, aber der Aufruf der Funktion SymbolInfoDouble() beansprucht immer noch 9%. Eine schnelle Suche ergab, dass diese Anrufe erforderlich sind, um den Spread-Wert zu erhalten. Wir können diese Operation jedoch durch die Berechnung der Preisdifferenz (Ask – Bid) ersetzen, die bereits beim Aufruf der Methode RefreshRates() ermittelt wurde und keine zusätzlichen Aufrufe der Funktion SymbolInfoDouble() erfordert.
Darüber hinaus wurden an dieser Klasse Änderungen vorgenommen, die nicht direkt mit der Erhöhung der Betriebsgeschwindigkeit zusammenhängen und für die betrachtete Modellstrategie nicht erforderlich waren:
- Übergabe des aktuellen Objekts an die CVirtualStrategy::OnOpen() und CVirtualStrategy::OnClose() Handler hinzugefügt;
- zusätzliche Berechnung der Gewinne aus geschlossenen virtuellen Positionen;
- Getter und Setter für StopLoss- und TakeProfit-Level hinzugefügt;
- ein eindeutiges Ticket hinzugefügt, das bei der Eröffnung einer virtuellen Position zugewiesen wird.
Vielleicht steht dieser Bibliothek eine radikalere Überarbeitung bevor. Daher werden wir uns nicht mit der Beschreibung dieser Änderungen aufhalten.
Wir speichern in der Datei VirtualOrder.mqh vorgenommenen Änderungen im aktuellen Ordner.
Änderung der Strategie
Um den Symbolmonitor verwenden zu können, mussten wir auch einige kleinere Änderungen an der Handelsstrategieklasse vornehmen. Zunächst haben wir, wie in der Klasse für virtuelle Positionen, dafür gesorgt, dass ein Mitglied der Klasse m_symbolInfo nun einen Zeiger auf das Objekt speichert und nicht mehr das Objekt selbst:
//+------------------------------------------------------------------+ //| Trading strategy using tick volumes | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { protected: ... CSymbolInfo *m_symbolInfo; // Object for getting information about the symbol properties ... public: ... };
Und fügte seine Initialisierung im Konstruktor hinzu:
//+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { ... // Register the event handler for a new bar on the minimum timeframe //IsNewBar(m_symbol, PERIOD_M1); m_symbolInfo = CSymbolsMonitor::Instance()[m_symbol]; ... }
Wir haben die Registrierung eines neuen Balken auskommentiert, da das nun im Symbolmonitor registriert wird.
Zweitens haben wir die Aktualisierung der aktuellen Preise aus dem Strategiecode entfernt (in den Methoden zur Überprüfung des Eröffnungssignals und der Positionseröffnung selbst), da der Symbolmonitor dies ebenfalls übernimmt.
Lassen Sie uns die Änderungen an der Datei SimpleVolumesStrategy.mqh im aktuellen Ordner speichern.
Gültigkeitsprüfung
Vergleichen wir die Ergebnisse des Tests des untersuchten EA im gleichen Zeitintervall vor und nach den Änderungen, die im Zusammenhang mit dem Hinzufügen des Symbolmonitors vorgenommen wurden.
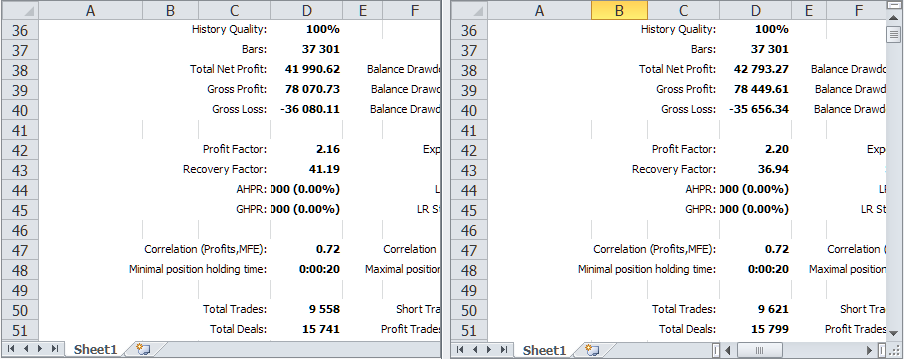
Abb. 2. Vergleich der Testergebnisse der Vorgängerversion und der aktuellen Version mit dem Symbolmonitor
Wie wir sehen, sind sie im Allgemeinen gleich, aber es gibt einige kleine Unterschiede. Der Übersichtlichkeit halber wollen wir sie in Form einer Tabelle darstellen.
| Version | Profit | Drawdown | Normalisierter Gewinn |
|---|---|---|---|
| Vorherige Version | 41 990.62 | 1 019.49 (0.10%) | 6 867.78 |
| Aktuelle Version | 42 793.27 | 1 158.38 (0.11%) | 6 159.87 |
Wenn wir die ersten Handelsgeschäfte in den Berichten vergleichen, können wir sehen, dass die vorherige Version zusätzliche Positionen enthält, die in der aktuellen Version nicht vorhanden sind und umgekehrt. Höchstwahrscheinlich liegt dies daran, dass beim Start des Testers auf dem EURGBP-Symbol ein neuer Balken für EURGBP um mm:00 entsteht, während er für ein anderes Symbol, z. B. GBPUSD, entweder um mm:00 oder mm:20 entstehen kann.
Um diesen Effekt zu eliminieren, werden wir eine zusätzliche Prüfung auf das Auftreten eines neuen Balkens in die Strategie einbauen:
//+------------------------------------------------------------------+ //| "Tick" event handler function | //+------------------------------------------------------------------+ void CSimpleVolumesStrategy::Tick() override { if(IsNewBar(m_symbol, PERIOD_M1)) { // If their number is less than allowed if(m_ordersTotal < m_maxCountOfOrders) { // Get an open signal int signal = SignalForOpen(); if(signal == 1 /* || m_ordersTotal < 1 */) { // If there is a buy signal, then OpenBuyOrder(); // open the BUY_STOP order } else if(signal == -1) { // If there is a sell signal, then OpenSellOrder(); // open the SELL_STOP order } } } }
Nach dieser Änderung wurden die Ergebnisse nur noch besser. Die aktuelle Version wies den höchsten normalisierten Gewinn auf:
| Version | Profit | Drawdown | Normalisierter Gewinn |
|---|---|---|---|
| Vorherige Version | 46 565.39 | 1 079.93 (0.11%) | 7 189.77 |
| Aktuelle Version | 47 897.30 | 1 051.37 (0.10%) | 7 596.31 |
Belassen wir es also bei den vorgenommenen Änderungen und machen wir mit der Erstellung eines Skripts zur Befüllung der Datenbank weiter.
Füllen der Datenbank mit Projekten
Wir werden kein Skript, sondern einen EA erstellen, der sich aber wie ein Skript verhält. Die gesamte Arbeit wird in der Initialisierungsfunktion ausgeführt, nach der der EA beim ersten Tick entladen wird. Diese Implementierung ermöglicht es uns, sie sowohl auf dem Chart als auch im Optimierer auszuführen, wenn wir mehrere Durchläufe mit sich innerhalb der festgelegten Grenzen ändernden Parametern erhalten wollen.
Da es sich um die erste Implementierung handelt, werden wir uns nicht zu viele Gedanken darüber machen, welcher Satz von Eingaben am besten geeignet ist, sondern wir werden versuchen, nur einen minimalen funktionierenden Prototyp zu erstellen. Hier ist die Liste der Parameter, die wir erhalten haben:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Database" sinput string fileName_ = "article.16373.db.sqlite"; // - Main database file input group "::: Project parameters" sinput string projectName_ = "SimpleVolumes"; // - Name sinput string projectVersion_ = "1.20"; // - Version sinput string symbols_ = "GBPUSD;EURUSD;EURGBP"; // - Symbols sinput string timeframes_ = "H1;M30;M15"; // - Timeframes input datetime fromDate_ = D'2018-01-01'; // - Start date input datetime toDate_ = D'2023-01-01'; // - End date
Der Name und die Version des Projekts sind offensichtlich, dann gibt es zwei Parameter, in denen wir Listen von Symbolen und Zeitrahmen, getrennt durch Semikolons, übergeben werden. Sie werden verwendet, um einzelne Instanzen der Handelsstrategie zu erhalten. Für jedes Symbol werden alle Zeitrahmen der Reihe nach betrachtet. Wenn wir also drei Symbole und drei Zeitrahmen in den Standardwerten angeben, würde dies dazu führen, dass neun einzelne Instanzen erstellt werden.
Jede einzelne Instanz muss eine erste Optimierungsphase durchlaufen, in der die besten Parameterkombinationen speziell für sie ausgewählt werden. Genauer gesagt, können wir während der Optimierung viele Kombinationen ausprobieren, aus denen wir dann eine bestimmte Anzahl „guter“ Kombinationen auswählen können.
Diese Entscheidung wird bereits in der zweiten Phase der Optimierung getroffen. Das Ergebnis ist eine Gruppe von mehreren „guten“ Instanzen, die an einem bestimmten Symbol und in einem bestimmten Zeitrahmen arbeiten. Nachdem wir den zweiten Schritt für alle Symbol-Zeitrahmen-Kombinationen wiederholt haben, erhalten wir neun Gruppen von Einzelinstanzen für jede Kombination.
Im dritten Schritt werden wir diese neun Gruppen kombinieren, indem wir einen Initialisierungsstring erhalten und in der Bibliothek speichern, der verwendet werden kann, um einen EA zu erstellen, der alle einzelnen Instanzen aus diesen Gruppen enthält.
Erinnern wir uns daran, dass der Code, der für die sequentielle Ausführung aller oben genannten Schritte verantwortlich ist, bereits geschrieben wurde und funktionieren kann, wenn die notwendigen „Anweisungen“ in der Datenbank generiert werden. Zuvor haben wir sie manuell in die Datenbank eingegeben. Nun wollen wir diese Routineprozedur auf das entwickelte EA-Skript übertragen.
Die verbleibenden zwei Parameter dieses EA ermöglichen es uns, das Start- und Enddatum des Optimierungsintervalls festzulegen. Wir werden sie verwenden, um eine periodische Re-Optimierung zu simulieren und zu sehen, wie lange nach der Re-Optimierung der endgültige EA mit den gleichen Ergebnissen wie im Optimierungsintervall handeln wird.
Der Code der Initialisierungsfunktion könnte also etwa so aussehen:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Connect to the database DB::Connect(fileName_); // Create a project CreateProject(projectName_, projectVersion_, StringFormat("%s - %s", TimeToString(fromDate_, TIME_DATE), TimeToString(toDate_, TIME_DATE) ) ); // Create project stages CreateStages(); // Creating jobs and tasks CreateJobs(); // Queueing the project for execution QueueProject(); // Close the database DB::Close(); // Successful initialization return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Tick handling | //+------------------------------------------------------------------+ void OnTick() { // Since all work is done in OnInit(), delete the EA ExpertRemove(); }
Das heißt, wir erstellen nacheinander einen Eintrag in der Projekttabelle, fügen dann Phasen zur Projektstufentabelle hinzu und füllen dann die Arbeits- und Aufgabentabellen für jeden Auftrag aus. Zum Schluss setzen wir den Projektstatus auf „Queued“ (in der Warteschlange). Dank der Auslöser in der Datenbank werden alle Phasen, Aufträge und Aufgaben des Projekts ebenfalls in den Status „Queued“ versetzt.
Schauen wir uns nun den Code der erstellten Funktionen genauer an. Am einfachsten ist es, ein Projekt zu erstellen. Sie enthält eine SQL-Abfrage zum Einfügen von Daten und zum Speichern der ID des neu erstellten Datensatzes in der globalen Variablen id_project:
//+------------------------------------------------------------------+ //| Create a project | //+------------------------------------------------------------------+ void CreateProject(string name, string ver, string desc = "") { string query = StringFormat("INSERT INTO projects " " VALUES (NULL,'%s','%s','%s',NULL,'Done') RETURNING rowid;", name, ver, desc); PrintFormat(__FUNCTION__" | %s", query); id_project = DB::Insert(query); }
Als Projektbeschreibung bilden wir eine Zeichenkette aus dem Start- und Enddatum des Optimierungsintervalls. Auf diese Weise können wir zwischen Projekten für dieselbe Version der Handelsstrategie unterscheiden.
Die Funktion zum Anlegen von Stufen wird etwas länger dauern: Es werden drei SQL-Abfragen benötigt, um drei Stufen anzulegen. Natürlich kann es noch mehr Stufen geben, aber wir beschränken uns vorerst auf die drei, die bereits erwähnt wurden. Nach der Erstellung der einzelnen Stufen speichern wir auch deren IDs in den globalen Variablen id_stage1, id_stage2 und id_stage3.
//+------------------------------------------------------------------+ //| Create three stages | //+------------------------------------------------------------------+ void CreateStages() { // Stage 1 - single instance optimization string query1 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%s," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project "NULL", // id_parent_stage "First", // name "SimpleVolumesStage1.ex5", // expert "GBPUSD", // symbol "H1", // period 2, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query1); id_stage1 = DB::Insert(query1); // Stage 2 - selection of a good group of single specimens string query2 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%d," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project id_stage1, // id_parent_stage "Second", // name "SimpleVolumesStage2.ex5", // expert "GBPUSD", // symbol "H1", // period 2, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query2); id_stage2 = DB::Insert(query2); // Stage 3 - saving the initialization string of the final EA to the library string query3 = StringFormat("INSERT INTO stages VALUES(" "NULL," // id_stage "%I64u," // id_project "%d," // id_parent_stage "'%s'," // name "'%s'," // expert "'%s'," // symbol "'%s'," // period "%d," // optimization "%d," // model "'%s'," // from_date "'%s'," // to_date "%d," // forward_mode "'%s'," // forward_date "%d," // deposit "'%s'," // currency "%d," // profit_in_pips "%d," // leverage "%d," // execution_mode "%d," // optimization_criterion "'%s'" // status ") RETURNING rowid;", id_project, // id_project id_stage2, // id_parent_stage "Save to library", // name "SimpleVolumesStage3.ex5", // expert "GBPUSD", // symbol "H1", // period 0, // optimization 2, // model TimeToString(fromDate_, TIME_DATE), // from_date TimeToString(toDate_, TIME_DATE), // to_date 0, // forward_mode "0", // forward_date 1000000, // deposit "USD", // currency 0, // profit_in_pips 200, // leverage 0, // execution_mode 7, // optimization_criterion "Done" // status ); PrintFormat(__FUNCTION__" | %s", query3); id_stage3 = DB::Insert(query3); }
Für jede Stufe geben wir ihren Namen, die ID der übergeordneten Stufe und den Namen des EA für die Stufe an. Die übrigen Felder in der Stufentabelle sind für die verschiedenen Stufen meist gleich: Optimierungsintervall, Ersteinzahlung usw.
Die Hauptarbeit fällt auf die Funktion zum Erstellen von Jobs und Aufgaben CreateJobs(). Jeder Auftrag bezieht sich auf eine Kombination aus Symbol und Zeitrahmen. Also erstellen wir zunächst Arrays für alle verwendeten Symbole und Zeitrahmen, die in den Eingaben aufgeführt sind. Für Zeitrahmen habe ich die Funktion StringToTimeframe() hinzugefügt, die den Namen des Zeitrahmens von einem String in einen Wert des Typs ENUM_TIMEFRAMES umwandelt.
// Array of symbols for strategies string symbols[]; StringSplit(symbols_, ';', symbols); // Array of timeframes for strategies ENUM_TIMEFRAMES timeframes[]; string sTimeframes[]; StringSplit(timeframes_, ';', sTimeframes); FOREACH(sTimeframes, APPEND(timeframes, StringToTimeframe(sTimeframes[i])));
Anschließend gehen wir in einer Doppelschleife alle Kombinationen von Symbolen und Zeitrahmen durch und erstellen drei Optimierungsaufgaben mit einem nutzerdefinierten Kriterium.
// Stage 1 FOREACH(symbols, { for(int j = 0; j < ArraySize(timeframes); j++) { // Use the optimization parameters template for the first stage string params = StringFormat(paramsTemplate1, ""); // Request to create the first stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage1, symbols[i], IntegerToString(timeframes[j]), params); ulong id_job = DB::Insert(query); // Add the created job ID to the array APPEND(id_jobs1, id_job); // Create three tasks for this job for(int i = 0; i < 3; i++) { query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 6); DB::Execute(query); } } });
Diese Anzahl von Aufgaben wird einerseits dadurch bestimmt, dass wir bei der Optimierung einer Kombination mindestens 10-20 Tausend Durchläufe angesammelt haben, und andererseits, dass es nicht so viele sind, dass die Optimierung zu lange dauern würde. Das nutzerdefinierte Kriterium für alle drei Aufgaben wird gewählt, weil der genetische Algorithmus für diese Handelsstrategie bei verschiedenen Durchläufen fast immer zu verschiedenen Parameterkombinationen konvergiert. Daher ist es nicht notwendig, unterschiedliche Kriterien für verschiedene Läufe zu verwenden, da wir bereits eine ziemlich große Auswahl an verschiedenen guten Parameterkombinationen für eine einzige Instanz der Strategie haben.
In Zukunft können die Anzahl der Aufgaben und die verwendeten Optimierungskriterien in die Skriptparameter aufgenommen werden, aber jetzt sind sie einfach fest im Code codiert.
Für jeden Auftrag der ersten Stufe wird dieselbe Optimierungsparametervorlage verwendet, die in der globalen Variable paramsTemplate1 angegeben ist:
// Template of optimization parameters at the first stage string paramsTemplate1 = "; === Open signal parameters\n" "signalPeriod_=212||12||40||240||Y\n" "signalDeviation_=0.1||0.1||0.1||2.0||Y\n" "signaAddlDeviation_=0.8||0.1||0.1||2.0||Y\n" "; === Pending order parameters\n" "openDistance_=10||0||10||250||Y\n" "stopLevel_=16000||200.0||200.0||20000.0||Y\n" "takeLevel_=240||100||10||2000.0||Y\n" "ordersExpiration_=22000||1000||1000||60000||Y\n" "; === Capital management parameters\n" "maxCountOfOrders_=3||3||1||30||N\n";
Speichern wir die IDs der hinzugefügten Aufträge im Array id_jobs1 zur Verwendung bei der Erstellung der Aufträge der zweiten Stufe.
Zur Erstellung der zweiten Stufe wird ebenfalls die in der globalen Variable paramsTemplate2 angegebene Vorlage verwendet, die jedoch bereits einen variablen Teil enthält:
// Template of optimization parameters for the second stage string paramsTemplate2 = "idParentJob_=%s\n" "useClusters_=false||false||0||true||N\n" "minCustomOntester_=500.0||0.0||0.000000||0.000000||N\n" "minTrades_=40||40||1||400||N\n" "minSharpeRatio_=0.7||0.7||0.070000||7.000000||N\n" "count_=8||8||1||80||N\n";
Der Wert nach „idParentJob_=“ ist die ID des ersten Stage Jobs, der eine bestimmte Kombination aus Symbol und Zeitrahmen verwendet. Vor der Erstellung der Aufträge der ersten Stufe sind diese Werte nicht bekannt, sodass sie unmittelbar vor der Erstellung jedes Auftrags der zweiten Stufe aus dem Array id_jobs1 in diese Vorlage eingesetzt werden.
Der Parameter count_ in dieser Vorlage ist gleich 8, d.h. wir werden Gruppen von acht einzelnen Instanzen von Handelsstrategien sammeln. Unser EA der zweiten Stufe ermöglicht es uns, für diesen Parameter einen Wert zwischen 1 und 16 einzustellen. Ich habe den Wert 8 aus denselben Gründen gewählt wie die Anzahl der Aufgaben für einen Auftrag in der ersten Phase – nicht zu wenig und nicht zu viel. Ich werde sie vielleicht später in die Skripteingaben verschieben.
// Stage 2 int k = 0; FOREACH(symbols, { for(int j = 0; j < ArraySize(timeframes); j++) { // Use the optimization parameters template for the second stage string params = StringFormat(paramsTemplate2, IntegerToString(id_jobs1[k])); // Request to create a second stage job for a given symbol and timeframe string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage2, symbols[i], IntegerToString(timeframes[j]), params); ulong id_job = DB::Insert(query); // Add the created job ID to the array APPEND(id_jobs2, id_job); k++; // Create one task for this job query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 6); DB::Execute(query); } });
In der zweiten Stufe erstellen wir nur eine Optimierungsaufgabe für einen einzelnen Auftrag, da wir in einer Optimierungsschleife recht gute Gruppen von Einzelinstanzen der Handelsstrategie auswählen. Wir werden ein Nutzerkriterium als Optimierungskriterium verwenden.
Wir speichern auch die IDs der hinzugefügten Jobs in dem Array id_jobs2 (wir brauchten sie am Ende nicht). Diese IDs können beim Hinzufügen von Stufen nützlich sein, daher werden wir sie nicht entfernen.
In der dritten Stufe enthält die Parametervorlage nur noch den Namen der endgültigen Gruppe, unter dem sie in die Bibliothek aufgenommen werden soll:
// Template of optimization parameters at the third stage string paramsTemplate3 = "groupName_=%s\n" "passes_=";
Wir bilden den Namen der endgültigen Gruppe aus dem Namen und der Version des Projekts sowie dem Enddatum des Optimierungsintervalls und setzen ihn in die Vorlage ein, die für die Erstellung der Arbeit der dritten Stufe verwendet wird. Da wir in der dritten Phase die Ergebnisse aller vorherigen Phasen zusammenfassen, werden nur ein Auftrag und seine Aufgabe erstellt:
// Stage 3 // Use the optimization parameters template for the third stage string params = StringFormat(paramsTemplate3, projectName_ + "_v." + projectVersion_ + "_" + TimeToString(toDate_, TIME_DATE)); // // Request to create a third stage job string query = StringFormat("INSERT INTO jobs " " VALUES (NULL,%I64u,'%s','%s','%s','Done') " " RETURNING rowid;", id_stage3, "GBPUSD", "D1", params); ulong id_job = DB::Insert(query); // Create one task for this job query = StringFormat("INSERT INTO tasks " " VALUES (NULL,%I64u,%d,NULL,NULL,'Done');", id_job, 0); DB::Execute(query);
Danach muss nur noch der Projektstatus geändert werden, sodass das Projekt in der Warteschlange für die Ausführung steht:
//+------------------------------------------------------------------+ //| Queueing the project for execution | //+------------------------------------------------------------------+ void QueueProject() { string query = StringFormat("UPDATE projects SET status='Queued' WHERE id_project=%d;", id_project); DB::Execute(query); }
Speichern Sie die an der neuen Datei CreateProject.mq5 vorgenommenen Änderungen im aktuellen Ordner.
Es gibt noch eine weitere Sache. Es ist wahrscheinlich davon auszugehen, dass die Datenbankstruktur dauerhaft sein wird, sodass sie in die Bibliothek integriert werden kann. Um diese Aufgabe zu erfüllen, haben wir die Datei db.schema.sql mit der Datenbankstruktur als eine Reihe von SQL-Befehlen erstellt und sie als Ressource mit Database.mqh verbunden:
// Import sql file for creating DB structure #resource "db.schema.sql" as string dbSchema
Wir haben auch die Logik der Connect()-Methode leicht geändert – wenn es keine Datenbank mit dem angegebenen Namen gibt, wird sie automatisch mit SQL-Befehlen aus einer als Ressource geladenen Datei erstellt. Gleichzeitig haben wir die Methode ExecuteFile() abgeschafft, da sie nirgendwo mehr verwendet wird.
Endlich sind wir an dem Punkt angelangt, an dem wir versuchen können, den implementierten Code auszuführen.
Füllen der Datenbank
Wir werden nicht viele Projekte auf einmal entwickeln, sondern uns auf vier beschränken. Dazu platzieren wir das EA-Skript einfach viermal auf einem beliebigen Chart und setzen jedes Mal die erforderlichen Parameter. Lassen Sie die Werte aller Parameter, mit Ausnahme des Enddatums, gleich den Standardwerten bleiben. Wir werden das Enddatum ändern, indem wir jedes Mal einen zusätzlichen Monat zum Testintervall hinzufügen.
Als Ergebnis erhalten wir ungefähr den folgenden Datenbankinhalt. Der Projekttisch enthält vier Projekte:
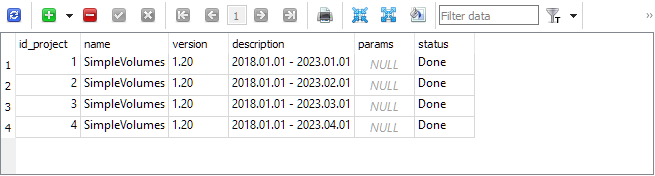
Die Stufentabelle enthält vier Stufen für jedes Projekt. Eine zusätzliche Stufe mit dem Namen „Einzelner Testerdurchlauf“ wird automatisch bei der Erstellung des Projekts erstellt und verwendet, wenn wir einen einzelnen Strategietesterdurchlauf außerhalb des automatischen Optimierungsförderers starten wollen:
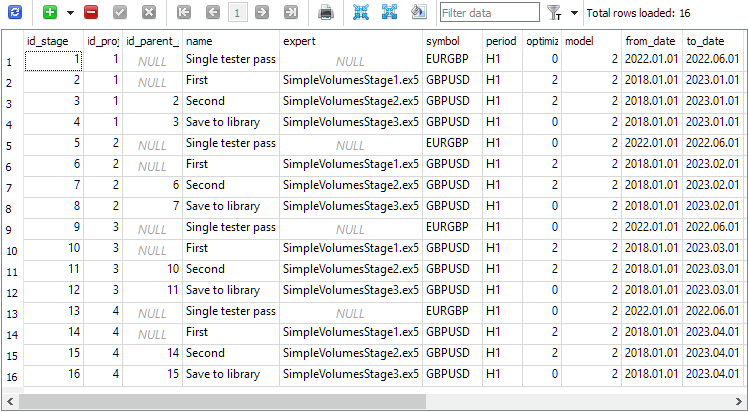
Die entsprechenden Aufträge wurden in die Auftragstabelle aufgenommen:
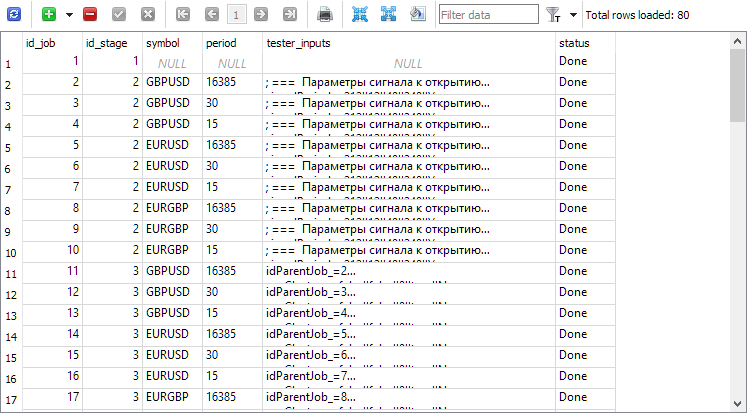
Nachdem die Projekte zur Ausführung freigegeben wurden, wurde das Ergebnis in etwa vier Tagen erreicht. Das ist trotz aller Bemühungen um Leistungsoptimierung nicht gerade wenig Zeit. Aber auch nicht so groß, dass er nicht zugewiesen werden kann. Sie ist in der Bibliothekstabelle der Gruppe strategy_groups zu sehen:

Prüfen wir z. B. id_pass, um die Initialisierungszeichenfolge in der Tabelle passes zu sehen:
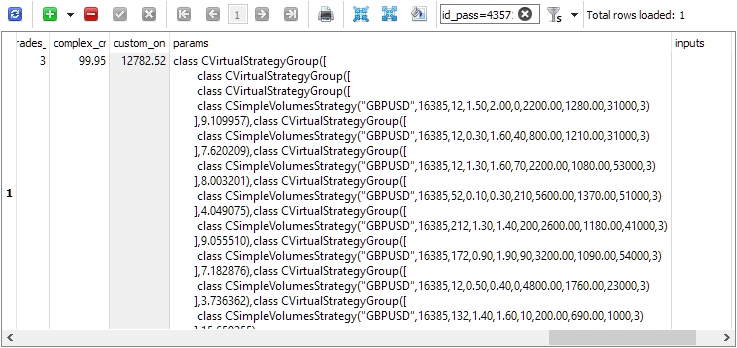
Oder wir können die Pass-ID als Eingabe für die dritte Stufe des EA SimpleVolumesStage3.ex5 verwenden und sie im Tester im gewählten Zeitintervall ausführen:
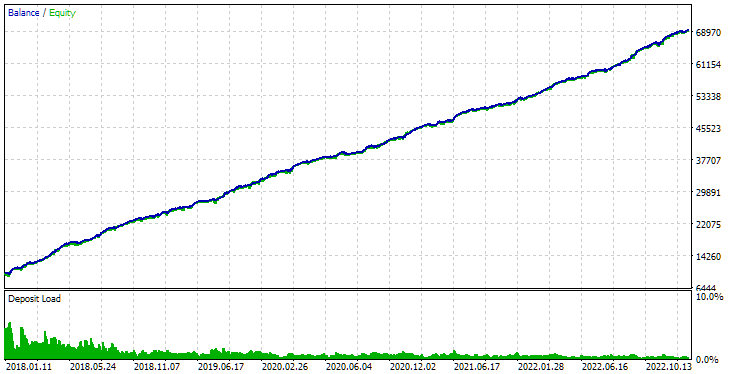
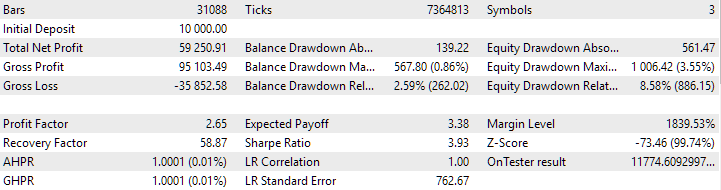
Abb. 3. SimpleVolumesStage3.ex5 EA-Pass-Ergebnisse mit id_pass=876663 im Zeitraum 2018.01.01 – 2023.01.01
Wir werden an dieser Stelle eine Pause einlegen und die erzielten Ergebnisse in den nächsten Artikeln genauer analysieren.
Schlussfolgerung
Wir haben also die Möglichkeit, automatisch Aufgaben zu erstellen, um das automatische Optimierungsband zu starten, das drei Stufen umfasst. Noch handelt es sich lediglich um einen Entwurf, der es uns ermöglichen wird, die bevorzugten Richtungen für die weitere Entwicklung zu bestimmen. Die Fragen der Implementierung der automatischen Zusammenführung oder des Ersetzens der Initialisierungsstrings der endgültigen EAs nach Abschluss der Förderstufen für jedes Projekt bleiben offen.
Aber eines kann man schon jetzt mit Sicherheit sagen. Die gewählte Reihenfolge der Ausführung von Optimierungsaufgaben in der Förderanlage ist nicht sehr gut. Nun müssen wir warten, bis alle Arbeiten der ersten Phase abgeschlossen sind, um mit der zweiten beginnen zu können. Und ebenso wird die dritte Stufe erst dann beginnen, wenn alle Arbeiten der zweiten Stufe abgeschlossen sind. Wenn wir planen, eine „heiße“ Ersetzung der Initialisierungsstrings des endgültigen EA zu implementieren, die parallel zur Optimierung kontinuierlich am Konto arbeitet, können wir diese Aktualisierungen kleiner, aber häufiger machen. Dies könnte die Ergebnisse verbessern, ist aber nach wie vor nur eine Hypothese, die noch getestet werden muss.
Es ist auch erwähnenswert, dass das entwickelte EA-Skript auf die Erstellung von Optimierungsprojekten nur für die betrachtete Modellhandelsstrategie ausgerichtet ist. Eine andere Strategie erfordert einige kleinere Änderungen am Quellcode. Zumindest müssen Sie die Vorlage des Eingabeparameter-Strings für die erste Stufe der Optimierung ändern. Wir haben diese Vorlagen noch nicht in die Eingänge verschoben, da es unpraktisch ist, sie dort direkt einzustellen. In Zukunft werden wir jedoch wahrscheinlich ein Format für die Beschreibung der Aufgabe zur Erstellung eines Projekts entwickeln, das das Skript EA aus einer Datei hochlädt.
Vielen Dank für Ihre Aufmerksamkeit! Bis bald!
Wichtige Warnung
Alle in diesem Artikel und in allen vorangegangenen Artikeln dieser Reihe vorgestellten Ergebnisse beruhen lediglich auf historischen Testdaten und sind keine Garantie für zukünftige Gewinne. Die Arbeiten im Rahmen dieses Projekts haben Forschungscharakter. Alle veröffentlichten Ergebnisse können von jedermann auf eigenes Risiko verwendet werden.
Inhalt des Archivs
| # | Name | Version | Beschreibung | Jüngste Änderungen |
|---|---|---|---|---|
| MQL5/Experten/Artikel.16373 | ||||
| 1 | Advisor.mqh | 1.04 | EA-Basisklasse | Teil 10 |
| 2 | ClusteringStage1.py | 1.01 | Programm zum Clustern der Ergebnisse der ersten Optimierungsstufe | Teil 20 |
| 3 | CreateProject.mq5 | 1.00. | EA-Skript zur Erstellung eines Projekts mit Phasen, Aufträgen und Optimierungsaufgaben. | Teil 21 |
| 4 | Database.mqh | 1.09 | Klasse für den Umgang mit der Datenbank | Teil 21 |
| 5 | db.schema.sql | 1.05 | Struktur der Datenbank | Teil 20 |
| 6 | ExpertHistory.mqh | 1.00. | Klasse für den Export der Handelshistorie in eine Datei | Teil 16 |
| 7 | ExportedGroupsLibrary.mqh | — | Generierte Datei mit den Namen der Strategiegruppen und dem Array ihrer Initialisierungs-Strings | Teil 17 |
| 8 | Factorable.mqh | 1.02 | Basisklasse von Objekten, die aus einer Zeichenkette erstellt werden | Teil 19 |
| 9 | GroupsLibrary.mqh | 1.01 | Klasse für die Arbeit mit einer Bibliothek ausgewählter Strategiegruppen | Teil 18 |
| 10 | HistoryReceiverExpert.mq5 | 1.00. | EA für die Wiedergabe der Historie von Geschäften mit dem Risikomanager | Teil 16 |
| 11 | HistoryStrategy.mqh | 1.00. | Klasse der Handelsstrategie für die Wiederholung der Handelshistorie | Teil 16 |
| 12 | Interface.mqh | 1.00. | Basisklasse zur Visualisierung verschiedener Objekte | Teil 4 |
| 13 | LibraryExport.mq5 | 1.01 | EA, der Initialisierungszeichenfolgen ausgewählter Durchläufe aus der Bibliothek in der Datei ExportedGroupsLibrary.mqh speichert | Teil 18 |
| 14 | Macros.mqh | 1.02 | Nützliche Makros für Array-Operationen | Teil 16 |
| 15 | Money.mqh | 1.01 | Grundkurs Geldmanagement | Teil 12 |
| 16 | NewBarEvent.mqh | 1.00. | Klasse zur Definition eines neuen Balkens für ein bestimmtes Symbol | Teil 8 |
| 17 | Optimization.mq5 | 1.03 | EA verwaltet die Einleitung von Optimierungsaufgaben | Teil 19 |
| 18 | Optimizer.mqh | 1.01 | Klasse für den Projektautooptimierungsmanager | Teil 20 |
| 19 | OptimizerTask.mqh | 1.01 | Klasse der Optimierungsaufgaben | Teil 20 |
| 20 | Receiver.mqh | 1.04 | Basisklasse für die Umwandlung von offenen Volumina in Marktpositionen | Teil 12 |
| 21 | SimpleHistoryReceiverExpert.mq5 | 1.00. | Vereinfachter EA für die Wiedergabe des Geschäftsverlaufs | Teil 16 |
| 22 | SimpleVolumesExpert.mq5 | 1.20 | EA für den parallelen Betrieb von mehreren Gruppen von Modellstrategien. Die Parameter werden aus der integrierten Gruppenbibliothek übernommen. | Teil 17 |
| 23 | SimpleVolumesStage1.mq5 | 1.18 | Handelsstrategie Einzelinstanzoptimierung EA (Phase 1) | Teil 19 |
| 24 | SimpleVolumesStage2.mq5 | 1.02 | Handelsstrategien Instanzen Gruppe Optimierung EA (Phase 2) | Teil 19 |
| 25 | SimpleVolumesStage3.mq5 | 1.02 | Der EA, der eine generierte standardisierte Gruppe von Strategien in einer Bibliothek von Gruppen mit einem bestimmten Namen speichert. | Teil 20 |
| 26 | SimpleVolumesStrategy.mqh | 1.10 | Klasse der Handelsstrategie mit Tick-Volumen | Teil 21 |
| 27 | Strategy.mqh | 1.04 | Handelsstrategie-Basisklasse | Teil 10 |
| 28 | SymbolsMonitor.mqh | 1.00. | Klasse zur Beschaffung von Informationen über Handelsinstrumente (Symbole) | Teil 21 |
| 29 | TesterHandler.mqh | 1.05 | Klasse zur Behandlung von Optimierungsereignissen | Teil 19 |
| 30 | VirtualAdvisor.mqh | 1.08 | Klasse des EA, der virtuelle Positionen (Aufträge) bearbeitet | Teil 21 |
| 31 | VirtualChartOrder.mqh | 1.01 | Grafische virtuelle Positionsklasse | Teil 18 |
| 32 | VirtualFactory.mqh | 1.04 | Objekt-Fabrik-Klasse | Teil 16 |
| 33 | VirtualHistoryAdvisor.mqh | 1.00. | Die Klasse des EA zur Wiederholung des Handelsverlaufs | Teil 16 |
| 34 | VirtualInterface.mqh | 1.00. | EA GUI-Klasse | Teil 4 |
| 35 | VirtualOrder.mqh | 1.08 | Klasse der virtuellen Aufträge und Positionen | Teil 21 |
| 36 | VirtualReceiver.mqh | 1.03 | Klasse für die Umwandlung von offenen Volumina in Marktpositionen (Empfänger) | Teil 12 |
| 37 | VirtualRiskManager.mqh | 1.02 | Klasse Risikomanagement (Risikomanager) | Teil 15 |
| 38 | VirtualStrategy.mqh | 1.05 | Klasse einer Handelsstrategie mit virtuellen Positionen | Teil 15 |
| 39 | VirtualStrategyGroup.mqh | 1.00. | Klasse der Handelsstrategien Gruppe(n) | Teil 11 |
| 40 | VirtualSymbolReceiver.mqh | 1.00. | Symbol-Empfängerklasse | Teil 3 |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16373
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Der Artikel Developing a Multicurrency Expert Advisor (Part 21) wurde veröffentlicht: Vorbereitungen für ein wichtiges Experiment und Optimierung des Codes:
Autor: Yuriy Bykov
Leider ist allesnicht so einfach wie wir es gerne hätten. Um in der Lagezu sein,den Expert Advisor der drittenStufe zu starten, ist esnotwendig, dieIDs der Durchläufe anzugeben, dieals Ergebnis dervorherigen Stufen der Optimierungspipeline erhalten wurden. Wie man sieerhält, wird in den Artikelnbeschrieben.
Das ist klar. Da Sie sich jedoch so viel Mühe gegeben haben, Ihre Arbeit auf einfachere Weise zu beschreiben, wäre es sogar großartig, wenn Sie ein Video-Tutorial erstellen könnten, um die Funktionsweise/Optimierung der von Ihnen erstellten EAs zu erklären. Vielen Dank
Verstanden. Da Sie sich jedoch so viel Mühe gegeben haben, Ihre Arbeit in einer einfacheren Weise zu beschreiben, wäre es sogar großartig, wenn Sie ein Video-Tutorial erstellen könnten, um die Funktionsweise/Optimierung der von Ihnen erstellten EAs zu vermitteln. Vielen Dank
Hallo, danke für die Anregung. Ich kann nicht versprechen, dass ich tatsächlich in der Lage sein werde, Videos für Artikel aufzunehmen, aber ich werde darüber nachdenken, wie und in welcher Form ich ein Video erstellen kann, das den Lesern der Artikel hilft.
Hallo, danke für die Anregung. Ich kann nicht versprechen, dass ich tatsächlich in der Lage sein werde, Videos für Artikel aufzunehmen, aber ich werde darüber nachdenken, wie und in welcher Form ich ein Video machen kann, das den Lesern der Artikel hilft.
Ein Dankeschön. Ein sehr einfaches Video von wenigen Sekunden Dauer wird ausreichen. Da das Testen und Optimieren von Strategien im MT5 komplexer ist als im MT4, fällt es Umsteigern manchmal schwer. Alles, was Sie tun können, ist, die genauen Einstellungen zu zeigen, die Sie verwenden, um die Ergebnisse zu erhalten, die Sie in den Artikeln veröffentlichen.
HI Download Last Part Files (21) How I Can User This Advisor Can u Help me please