
Neuronale Netze im Handel: Modelle mit Wavelet-Transformation und Multitasking-Aufmerksamkeit (letzter Teil)

Einführung
Im letzten Artikel haben wir begonnen, die theoretischen Aspekte des Systems Multitask-Stockformer zu erforschen und die vorgeschlagenen Ansätze in MQL5 zu implementieren. Multitask-Stockformer kombiniert zwei leistungsstarke Werkzeuge: die diskrete Wavelet-Transformation, die eine tiefgreifende Zeitreihenanalyse ermöglicht, und Multitask-Selbstaufmerksamkeits-Modelle, die in der Lage sind, komplexe Abhängigkeiten in Finanzdaten zu erfassen. Diese Synergie macht es möglich, ein universelles Werkzeug für die Zeitreihenanalyse und -prognose zu schaffen.
Das System ist auf drei Kernblöcken aufgebaut. Im Modul zur Zerlegung von Zeitreihen werden die analysierten Daten in hoch- und niederfrequente Komponenten unterteilt. Die niederfrequenten Komponenten stellen globale Trends dar und unterstützen die Analyse langfristiger Muster. Die Hochfrequenzkomponenten erfassen kurzfristige Fluktuationen, einschließlich Aktivitätsausbrüche und Anomalien. Eine detaillierte Datendekomposition verbessert die Verarbeitungsqualität und erleichtert die Extraktion von Schlüsselmerkmalen, was bei der Arbeit mit Finanzzeitreihen von entscheidender Bedeutung ist.
Nach der Zerlegung werden die Daten mit einem Zweifrequenz-Raum-Zeit-Kodierer verarbeitet. Dieses Modul kombiniert mehrere Untermodule und dient der Analyse der extrahierten Frequenzkomponenten sowie deren Abhängigkeiten untereinander. Niederfrequente Signale werden durch einen zeitlichen Aufmerksamkeitsmechanismus verarbeitet, der sich auf langfristige Trends und deren Entwicklung konzentriert. Hochfrequente Daten wiederum durchlaufen erweiterte kausale Faltungsschichten, die subtile Variationen und deren Dynamik erkennen. Die verarbeiteten Signale werden dann durch Graph-Attention-Module integriert, die räumlich-zeitliche Abhängigkeiten erfassen und die Beziehungen zwischen verschiedenen Vermögenswerten und Zeitintervallen widerspiegeln. Dieser Prozess führt zu mehrstufigen Graphendarstellungen, die in mehrdimensionale Einbettungen umgewandelt werden. Diese Einbettungen werden mithilfe von Additions- und Graph-Attention-Mechanismen zusammengeführt und bilden eine umfassende Darstellung der Daten für die anschließende Analyse.
Eine Schlüsselphase der Verarbeitung ist der Zweifrequenz-Fusionsdecoder, der eine entscheidende Rolle bei der Erzeugung von Vorhersageergebnissen spielt. Der Decoder integriert Prädiktoren mit Hilfe eines Fusion-Attention-Mechanismus, der die Aggregation von nieder- und hochfrequenten Daten in eine einheitliche latente Darstellung ermöglicht. Diese Darstellung spiegelt zeitliche Muster über mehrere Skalen hinweg wider und bietet einen umfassenden Ansatz für die Datenanalyse. In dieser Phase erzeugt das Modell verborgene Repräsentationen, die anschließend von spezialisierten, voll vernetzten Schichten verarbeitet werden. Diese Schichten ermöglichen es dem Modell, mehrere Aufgaben gleichzeitig zu erfüllen: Vorhersage der Renditen von Vermögenswerten, Schätzung der Wahrscheinlichkeit von Trendänderungen und Ermittlung anderer wichtiger Merkmale von Zeitreihen. Der Multitasking-Ansatz macht das Modell flexibel und anpassungsfähig an unterschiedliche Marktbedingungen – ein besonders wichtiges Merkmal im Zusammenhang mit der hohen Volatilität der Finanzmärkte.
Eine vom Autor zur Verfügung gestellte Visualisierung des Systems Multitask-Stockformer ist unten abgebildet.
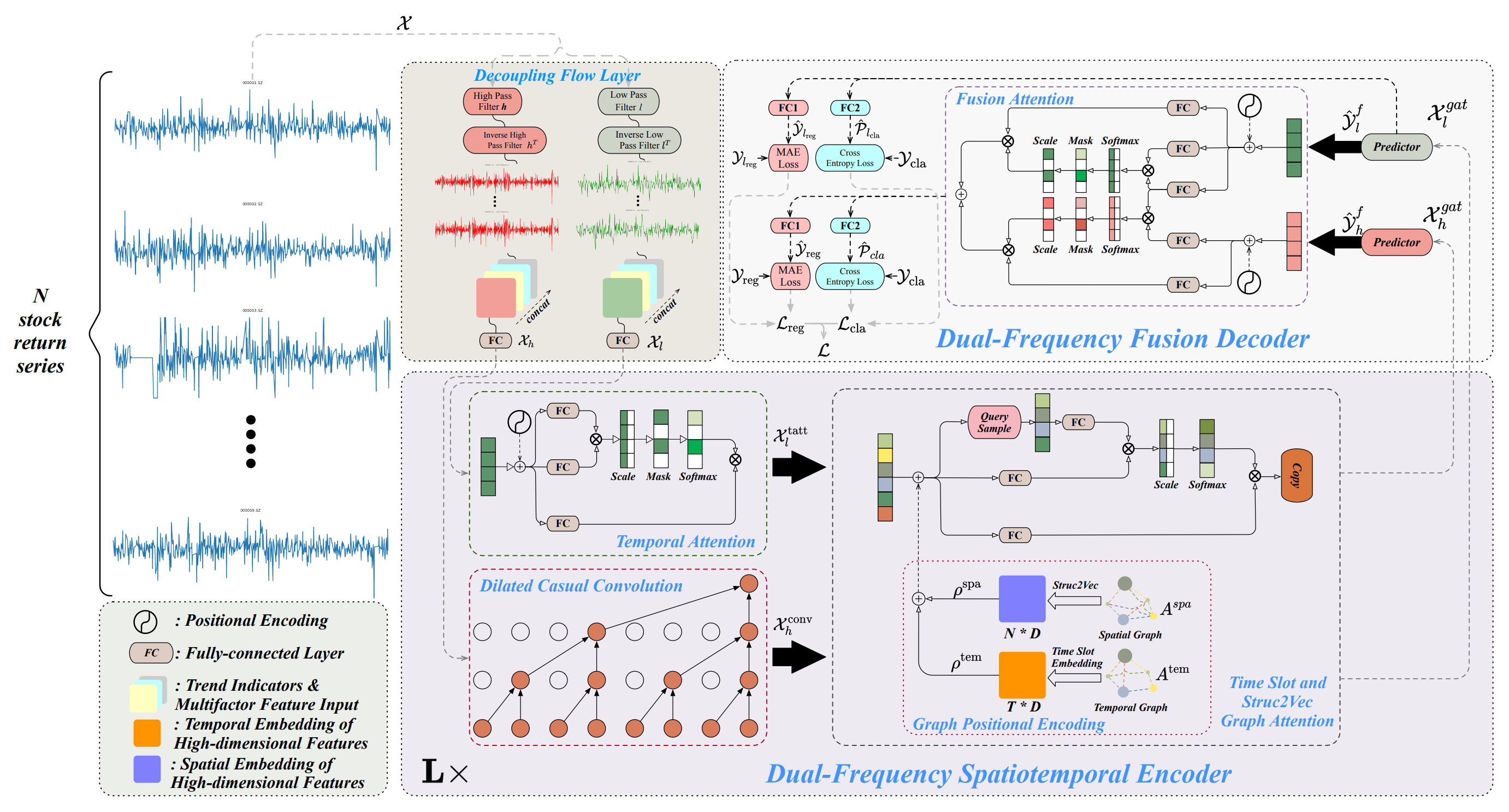
Implementierung des Systems Multitask-Stockformer
Wir setzen unsere Arbeit an der Umsetzung der von den Autoren des Multitask-Stockformer vorgeschlagenen Ansätze in MQL5 fort. Dabei geht es um die praktische Umsetzung der wichtigsten Systemkomponenten zur Optimierung der Zeitreihenanalyse.
Eines der grundlegenden Elemente des Frameworks ist das Modul zur Zerlegung von Zeitreihen, das in der Klasse CNeuronDecouplingFlow implementiert ist. Diese Komponente trennt die Eingabedaten in hoch- und niederfrequente Komponenten und bildet die Grundlage für die anschließende Analyse. Das Hauptziel dieses Moduls besteht darin, die wichtigsten strukturellen Merkmale von Zeitreihen zu extrahieren, wobei ihre Besonderheit und potenzielle Markttrends berücksichtigt werden. Im vorherigen Artikel haben wir die architektonischen und algorithmischen Lösungen untersucht, die dem Design der Klasse CNeuronDecouplingFlow zugrunde liegen.
Die nächste Stufe der Datenverarbeitung umfasst die Analyse durch einen Zweifrequenz-Raum-Zeit-Kodierer. Wie bereits erwähnt, haben die Autoren des Frameworks eine komplexe Encoder-Architektur vorgeschlagen, die zwei unabhängige Datenströme mit jeweils eigenem strukturellem Design umfasst.
Niederfrequente Komponenten werden mit Hilfe eines zeitlichen Aufmerksamkeitsmechanismus auf der Grundlage der Selbstaufmerksamkeits-Architektur analysiert. Dieser Ansatz bietet leistungsstarke Möglichkeiten zur Ermittlung langfristiger Abhängigkeiten und zur Vorhersage globaler Markttrends. Der Einsatz von Selbstaufmerksamkeit sorgt für ein tiefes Verständnis komplexer Datenstrukturen und minimiert das Risiko, wichtige Zusammenhänge zu übersehen. In unserer aktuellen Implementierung haben wir uns entschieden, eines der bestehenden Aufmerksamkeitsmodule aus unserer Bibliothek zu verwenden, das den Mechanismus der Selbstaufmerksamkeit nutzt.
Hochfrequente Zeitreihenkomponenten werden durch ein erweitertes kausales Faltungsmodul verarbeitet, das in der Klasse CNeuronDilatedCasualConv implementiert ist. Die verbesserten Algorithmen erkennen wirksam lokale Anomalien und Aktivitätsausbrüche. Diese Komponente spielt eine Schlüsselrolle bei der Analyse der kurzfristigen Marktdynamik, insbesondere in Zeiten hoher Volatilität. Die Integration dieses Moduls in die gesamte Rahmenarchitektur erhöht die Anpassungsfähigkeit und Leistung. Die architektonischen Entscheidungen und lokalen Änderungen des ursprünglichen Rahmens, die wir bei der Entwicklung von CNeuronDilatedCasualConv verwendet haben, wurden im vorherigen Artikel besprochen.
Nach der Vorverarbeitung der Hoch- und Tieffrequenzkomponenten des analysierten Signals werden die Daten in separate Zweige des Graph Attention Slots geleitet. Dieses Modul basiert auf der Erstellung von zwei speziellen Graphen. Der erste Graph modelliert zeitliche Abhängigkeiten und betont deren sequentielle Struktur. Sie spielt eine wichtige Rolle bei der Identifizierung von Trends, Zyklizität und anderen zeitlichen Merkmalen. Das zweite Schaubild basiert auf der Korrelationsmatrix der Preise von Finanzanlagen und bietet eine umfassende Integration von Informationen über die gegenseitigen Abhängigkeiten von Anlagen. Dadurch kann das Modell den Einfluss eines Vermögenswerts auf einen anderen berücksichtigen, was insbesondere für die Finanzmodellierung und -prognose wichtig ist. Zusammen bilden diese Diagramme eine mehrstufige Struktur, die die Genauigkeit der Datenanalyse und -interpretation erhöht.
Zur Umwandlung von Graphinformationen in analytisch nützliche Darstellungen wird der Algorithmus Struct2Vec verwendet. Dieser Algorithmus übersetzt die topologischen Eigenschaften von Graphen in kompakte Vektoreinbettungen, die mit Hilfe von trainierbaren voll verbundenen Schichten weiter optimiert werden. Solche Einbettungen ermöglichen die effiziente Integration von lokalen und globalen Datenmerkmalen und verbessern die Qualität der Zeitreihenanalyse. Die verarbeiteten Daten werden dann an Graph-Attention-Zweige weitergeleitet, wo sie mit Hilfe von Aufmerksamkeitsmechanismen weiter untersucht werden. In dieser Phase lassen sich sowohl kurzfristige als auch langfristige Abhängigkeiten feststellen.
Die Autoren des Systems von Multitask-Stockformer haben eine recht komplexe Architektur für den Graph Attention Slot vorgeschlagen. Seine Umsetzung würde erhebliche Rechenressourcen und eine sorgfältige Datenaufbereitung erfordern. Bei der Ausarbeitung des Modells für diese Studie haben wir mehrere Vereinfachungen vorgenommen, um die praktische Anwendbarkeit des Modells zu verbessern und gleichzeitig seine Leistungsfähigkeit zu erhalten. Die erste Vereinfachung bestand darin, dass zeitliche Informationen über den analysierten Umweltzustand ausgeschlossen wurden. Diese Entscheidung beruhte auf der Annahme, dass zeitliche Informationen zwar nützlich sind, aber die Gesamteffizienz unseres Modells in diesem Stadium nicht entscheidend beeinflussen. Im ursprünglichen Rahmen stellte die Ausgabe ein konstruiertes Aktienportfolio dar, wohingegen in unserer Implementierung das Hauptziel darin besteht, eine latente Darstellung der Umwelt zu schaffen. Diese Darstellung wird vom Akteursmodell verwendet, um Handelsentscheidungen zu treffen, ergänzt durch Kontostands- und Zeitstempeldaten, die ein kontextbezogenes Bewusstsein schaffen. Wir verschieben also lediglich den Punkt, an dem die zeitliche Information an das Modell übertragen wird.
Die Vereinfachung, die für das Diagramm der zeitlichen Abhängigkeiten gilt, kann jedoch nicht für das Diagramm der Korrelationen zwischen den Vermögenswerten verwendet werden, da dies zum Verlust wichtiger Informationen führen würde. Stattdessen schlagen wir eine alternative Lösung vor, bei der die ursprüngliche Struktur durch eine trainierbare Positionskodierungsschicht ersetzt wird. Mit diesem Ansatz können Einbettungen effektiv trainiert werden, wobei die Rechenkomplexität minimiert wird und die wesentlichen Beziehungen zwischen den Assets erhalten bleiben, die das Modell während des Trainings selbständig erlernt. Diese Verbesserung bietet eine flexiblere Architektur, die sich an unterschiedliche Marktbedingungen anpassen kann.
Zusätzlich haben wir einen weiteren Schritt nach vorne gemacht, indem wir die Graph Attention Slots durch Module des Node-Adaptive Feature Smoothing (NAFS) ersetzt. Ein entscheidender Vorteil dieser Methode ist das Fehlen von trainierbaren Parametern in den Modulen von NAFS, was nicht nur die Rechenkomplexität reduziert, sondern auch die Modellkonfiguration und das Training vereinfacht.
Bei der Verwendung von NAFS wird der Konstruktionsprozess der Einbettung flexibler und robuster, da sich die Glättungsmethode an die Topologie des Graphen und die Eigenschaften der Knoten anpasst. Dies ist besonders wichtig für Aufgaben, bei denen die Datenstruktur heterogen sein oder sich dynamisch ändern kann. Folglich ermöglicht NAFS die Erstellung hochwertiger Datendarstellungen, die sowohl lokale als auch globale Graphenbeziehungen berücksichtigen.
Die Aggregation der beiden Informationsströme erfolgt in einem Zweifrequenzdecoder, der verschiedene Aspekte der Daten integriert, um eine Grundlage für die multidimensionale Analyse zu schaffen. Dies ermöglicht eine umfassendere Darstellung der Signaldynamik. Der Zweifrequenz-Decoder basiert auf dem Mechanismus der Fusion Attention, der zwei parallele Aufmerksamkeitsmodule kombiniert. Das erste Modul, das auf der Selbstaufmerksamkeit basiert, ist auf die tiefgehende Verarbeitung niederfrequenter Komponenten spezialisiert und identifiziert wichtige langfristige Abhängigkeiten, stabile Trends und globale Muster. Dieses Modul ermöglicht die Erfassung grundlegender Zeitreihencharakteristika, die bei Prognosen eine entscheidende Rolle spielen. Das zweite Modul setzt Kreuzaufmerksamkeit ein, um hochfrequente Informationen zu integrieren und die Analyse mit kurzfristigen und feinkörnigen Komponenten anzureichern. Durch eine solche Integration werden niederfrequente Daten erheblich aufgewertet und mit Details versehen, was besonders wichtig ist, um subtile, aber aussagekräftige Schwankungen zu berücksichtigen.
Beide Aufmerksamkeitsmodule arbeiten synchron, sodass eine kohärente und komplementäre Datenrepräsentation entsteht. Ihre Ergebnisse werden durch Summation zusammengeführt und anschließend von vollständig verbundenen Schichten (MLP) verarbeitet. Dieser Ansatz ermöglicht die gleichzeitige Berücksichtigung globaler und lokaler Signalmerkmale und erfasst ein breites Spektrum von Beziehungen und Einflüssen.
Die vorgeschlagene Fusion-Attention-Architektur kann leicht mit bestehenden Kreuz- und Selbstaufmerksamkeits-Modulen implementiert werden. Außerdem erfordert seine Umsetzung keine wesentlichen Änderungen an den grundlegenden Algorithmen.
Wir können also feststellen, dass wir nun alle Schlüsselmodule für die Erstellung einer umfassenden Architektur des Multitask-Stockformer-Rahmens haben. Damit ist die Grundlage für den nächsten Entwicklungsschritt geschaffen: die Bildung eines High-Level-Objekts, das alle spezifizierten Module zu einem einzigen, funktional vollständigen Algorithmus zusammenführt. Der Hauptzweck dieses Schritts besteht nicht nur in der Integration der Komponenten, sondern auch in der Sicherstellung ihres synchronen Betriebs unter Berücksichtigung der Eigenschaften der einzelnen Module. Nachfolgend ist die Struktur des neuen Objekts CNeuronMulttaskStockformer dargestellt.
class CNeuronMultitaskStockformer : public CNeuronBaseOCL { protected: CNeuronDecouplingFlow cDecouplingFlow; CNeuronBaseOCL cLowFreqSignal; CNeuronBaseOCL cHighFreqSignal; CNeuronRMAT cTemporalAttention; CNeuronDilatedCasualConv cDilatedCasualConvolution; CNeuronLearnabledPE cLowFreqPE; CNeuronLearnabledPE cHighFreqPE; CNeuronNAFS cLowFreqGraphAttention; CNeuronNAFS cHighFreqGraphAttention; CNeuronDMHAttention cLowFreqFusionDecoder; CNeuronCrossDMHAttention cLowHighFreqFusionDecoder; CNeuronBaseOCL cLowHigh; CNeuronConvOCL cProjection; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMultitaskStockformer(void) {}; ~CNeuronMultitaskStockformer(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint neurons_out, uint filters, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMultitaskStockformer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Die vorgestellte Struktur umfasst zahlreiche interne Objekte, die direkt den oben beschriebenen Modulen des Systems Multitask-Stockformer entsprechen. Diese Komponenten sind so organisiert, dass ein hohes Maß an funktionaler Integration und Flexibilität bei der Implementierung gewährleistet ist. Wir werden die Algorithmen, die ihre Interaktion steuern, sowie den Datenfluss während der Implementierung der Methoden des Integrationsobjekts im Detail analysieren.
Alle internen Objekte werden als statisch deklariert, sodass wir den Konstruktor und Destruktor der Klasse leer lassen können. Die Initialisierung aller neu deklarierten und geerbten Objekte wird in der Methode Init durchgeführt.
bool CNeuronMultitaskStockformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint neurons_out, uint filters, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, neurons_out, optimization_type, batch)) return false;
Unter den Parametern dieser Methode gibt es neben den bekannten Konstanten einen neuen Parameter: neurons_out. Er gibt die Größe des latenten Repräsentationsvektors des analysierten Umweltzustands an, den der Nutzer als Ausgabe dieses Blocks von Multitask-Stockformer zu erhalten erwartet. Dieser Vektor wird an die entsprechende Methode der übergeordneten Klasse übergeben, die die zentralen Schnittstellen für den Datenaustausch mit externen neuronalen Schichten innerhalb des Modells initialisiert.
Nachdem die Methode der übergeordneten Klasse erfolgreich ausgeführt wurde, geht es an die Initialisierung der internen Objekte. Dieser Prozess folgt der Reihenfolge der Objektverwendung während des Vorwärtsdurchlauf. Wie bereits erwähnt, werden die Eingangsdaten zunächst durch das Signalzerlegungsmodul CNeuronDecouplingFlow in hoch- und niederfrequente Komponenten zerlegt.
uint index = 0; uint wave_window = MathMin(24, units_count); if(!cDecouplingFlow.Init(0, index, OpenCL, wave_window, 2, units_count, filters, window, optimization, iBatch)) return false; cDecouplingFlow.SetActivationFunction(None);
Beachten Sie, dass wir in den externen Parametern der Initialisierungsmethode des Integrationsobjekts die Größe und den Schritt des Fensters der diskreten Wavelet-Transformation nicht angeben. Diese Parameter werden direkt in der Methode auf feste Werte gesetzt. Bei den in diesem Artikel beschriebenen Experimenten konzentrieren wir uns auf historische Daten des Zeitraums H1. Dementsprechend begrenzen wir die Größe des Wavelet-Transformationsfensters auf einen Tag, was 24 Schritten der analysierten Sequenz entspricht, und fügen eine Prüfung hinzu, um zu verhindern, dass die Länge der multimodalen Zeitreihe überschritten wird. Der Fensterschritt wird auf 2 gesetzt, wodurch ein Element der Sequenz übersprungen wird.
Das Ergebnis des Zerlegungsmoduls ist ein einheitlicher Tensor, der sowohl Hoch- als auch Tieffrequenzkomponenten enthält. Für die Verarbeitung im Zweifrequenz-Raum-Zeit-Kodierer werden zwei parallele Ströme bereitgestellt, wobei jede Komponente separat analysiert wird. Zur Umsetzung dieses Ansatzes teilen wir die Daten in einzelne Objekte auf. Dies ist bequem und flexibel für die weitere Bearbeitung.
//--- Dual-Frequency Spatiotemporal Encoder uint wave_units_out = cDecouplingFlow.GetUnits(); index++; if(!cLowFreqSignal.Init(0, index, OpenCL, cDecouplingFlow.Neurons() / 2, optimization, iBatch)) return false; cLowFreqSignal.SetActivationFunction(None); index++; if(!cHighFreqSignal.Init(0, index, OpenCL, cDecouplingFlow.Neurons() / 2, optimization, iBatch)) return false; cHighFreqSignal.SetActivationFunction(None); index++;
Die niederfrequente Komponente wird im Modul für zeitliche Aufmerksamkeit verarbeitet, das auf dem Mechanismus der Selbstaufmerksamkeit beruht. Im ursprünglichen System von Multitask-Stockformer wird die Positionskodierung vorgeschlagen, um die Sequenzverarbeitung zu verbessern. Wir verwenden jedoch ein Aufmerksamkeitsmodul mit relativer Positionskodierung, das von sich aus die relativen Positionen der Sequenzelemente bestimmt. Dadurch entfällt die Notwendigkeit einer zusätzlichen Positionskodierung, was die Architektur vereinfacht und die Effizienz erhöht.
if(!cTemporalAttention.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, heads, layers, optimization, iBatch)) return false; cTemporalAttention.SetActivationFunction(None); index++;
Es ist wichtig zu beachten, dass die Dimension des Vektors, der ein einzelnes Sequenzelement beschreibt, der Anzahl der bei der Wavelet-Transformation verwendeten Filter entspricht. Während die Sequenzlänge alle univariaten Zeitreihen abdeckt. Dieser Ansatz ermöglicht die Untersuchung von Trendinterdependenzen über die gesamte multimodale Sequenz hinweg, anstatt ihre Komponenten isoliert zu analysieren.
Hochfrequente Abhängigkeiten werden im erweiterten Modul für kausale Faltung analysiert. Hier verwenden wir ein minimales Faltungsfenster von 2 Elementen mit demselben Schritt. Die Analyse wird innerhalb von Unit-Sequenzen durchgeführt, was eine detaillierte Untersuchung lokaler Abhängigkeiten ermöglicht.
if(!cDilatedCasualConvolution.Init(0, index, OpenCL, 2, 2, filters, wave_units_out, window, layers, optimization, iBatch)) return false; index++;
Beiden Komponenten wird dann eine Positionskodierung hinzugefügt.
if(!cLowFreqPE.Init(0, index, OpenCL, cTemporalAttention.Neurons(), optimization, iBatch)) return false; index++; if(!cHighFreqPE.Init(0, index, OpenCL, cDilatedCasualConvolution.Neurons(), optimization, iBatch)) return false; index++;
Jede Komponente erhält eine separate, trainierbare Positionskodierungsschicht. Dieser Ansatz ermöglicht eine tiefere Analyse von hoch- und niederfrequenten Strukturen unabhängig voneinander.
Nach Fertigstellung des Zweifrequenz-Encoders initialisieren wir die Module der Node-Adaptive Feature Smoothing (NAFS), die getrennt auf die hoch- und niederfrequenten Komponenten angewendet werden. Beide Module haben die gleichen Parameter mit Ausnahme der Sequenzlänge. Es wird erwartet, dass die Hochfrequenzsequenz aufgrund der Art des erweiterten kausalen Faltungsmoduls kürzer ist.
if(!cLowFreqGraphAttention.Init(0, index, OpenCL, filters, 3, wave_units_out * window, optimization, iBatch)) return false; index++; if(!cHighFreqGraphAttention.Init(0, index, OpenCL, filters, 3, cDilatedCasualConvolution.Neurons()/filters, optimization, iBatch)) return false; index++;
Als Nächstes werden die Objekte des Datenfluss-Fusionsdecoders initialisiert. Hier initialisieren wir zwei Aufmerksamkeitsblöcke: Die Selbstaufmerksamkeit für niederfrequente Komponenten und Kreuzaufmerksamkeit für die Integration von hochfrequenten Komponenten.
//--- Dual-Frequency Fusion Decoder if(!cLowFreqFusionDecoder.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, heads, layers, optimization, iBatch)) return false; index++; if(!cLowHighFreqFusionDecoder.Init(0, index, OpenCL, filters, window_key, wave_units_out * window, filters, cDilatedCasualConvolution.Neurons()/filters, heads, layers, optimization, iBatch)) return false; index++;
Die Ausgänge des Aufmerksamkeitsblocks werden summiert. Und es wird ein Basisobjekt der neuronalen Schicht erstellt, um die Ergebnisse zu speichern.
if(!cLowHigh.Init(0, index, OpenCL, cLowFreqFusionDecoder.Neurons(), optimization, iBatch)) return false; CBufferFloat *grad = cLowFreqFusionDecoder.getGradient(); if(!grad || !cLowHigh.SetGradient(grad, true) || !cLowHighFreqFusionDecoder.SetGradient(grad, true)) return false; index++;
Um unnötiges Kopieren von Daten zu vermeiden, werden die Zeiger auf die Gradientenpuffer der letzten drei Objekte synchronisiert. Dieser Ansatz reduziert den Speicherbedarf und verbessert die Effizienz der Ausbildung.
Schließlich initialisieren wir die MLP-Objekte zur Erzeugung der latenten Repräsentation des Umweltzustands. Hier verwenden wir eine Faltungsschicht zur Dimensionalitätsreduktion und eine voll verknüpfte Schicht, um die angestrebte Repräsentationsgröße zu erzeugen.
Die vollständig verknüpfte Schicht wird von der übergeordneten Klasse abgeleitet, sodass wir nur die Faltungsschicht mit den erforderlichen Ausgangsverbindungen initialisieren müssen. Um die Funktionsweise der vollständig verbundenen Schicht zu implementieren, werden wir die geerbten Fähigkeiten der übergeordneten Klasse verwenden.
if(!cProjection.Init(Neurons(), index, OpenCL, filters, filters, 3, wave_units_out, window, optimization, iBatch)) return false; //--- return true; }
Nachdem alle internen Objekte initialisiert wurden, wird die Init-Methode beendet und ein logischer Erfolgsstatus an das aufrufende Programm zurückgegeben.
Anschließend konstruieren wir den Algorithmus des Vorwärtsdurchlaufs für das Integrationsobjekt.
bool CNeuronMultitaskStockformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Decoupling Flow if(!cDecouplingFlow.FeedForward(NeuronOCL)) return false;
Die Methode erhält einen Zeiger auf das Eingabedatenobjekt, das an das Zerlegungsmodul übergeben wird.
Der sich ergebende Tensor wird zur unabhängigen Analyse auf die beiden Ströme aufgeteilt.
if(!DeConcat(cLowFreqSignal.getOutput(), cHighFreqSignal.getOutput(), cDecouplingFlow.getOutput(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetUnits()*cDecouplingFlow.GetVariables())) return false;
Die niederfrequente Komponente durchläuft das Modul für zeitliche Aufmerksamkeit. Dann erhält er eine Positionskodierung und gelangt in das Modul für die Graphendarstellung.
//--- Dual-Frequency Spatiotemporal Encoder //--- Low Frequency Encoder if(!cTemporalAttention.FeedForward(cLowFreqSignal.AsObject())) return false; if(!cLowFreqPE.FeedForward(cTemporalAttention.AsObject())) return false; if(!cLowFreqGraphAttention.FeedForward(cLowFreqPE.AsObject())) return false;
Die Hochfrequenzkomponente folgt ihrem Strom, ausgehend von dem erweiterten kausalen Faltungsmodul.
//--- High Frequency Encoder if(!cDilatedCasualConvolution.FeedForward(cHighFreqSignal.AsObject())) return false; if(!cHighFreqPE.FeedForward(cDilatedCasualConvolution.AsObject())) return false; if(!cHighFreqGraphAttention.FeedForward(cHighFreqPE.AsObject())) return false;
Die Ausgänge beider Ströme werden an den Zweifrequenz-Fusionsdecoder weitergeleitet. Hier werden die Daten zunächst von zwei Aufmerksamkeitsmodulen verarbeitet. Die Ergebnisse werden summiert und normalisiert.
//--- Dual-Frequency Fusion Decoder if(!cLowFreqFusionDecoder.FeedForward(cLowFreqGraphAttention.AsObject())) return false; if(!cLowHighFreqFusionDecoder.FeedForward(cLowFreqGraphAttention.AsObject(), cHighFreqGraphAttention.getOutput())) return false; if(!SumAndNormilize(cLowFreqFusionDecoder.getOutput(), cLowHighFreqFusionDecoder.getOutput(), cLowHigh.getOutput(), cLowFreqFusionDecoder.GetWindow(), true, 0, 0, 0, 1)) return false;
Anschließend werden die Daten über eine Faltungsprojektionsschicht komprimiert.
if(!cProjection.FeedForward(cLowHigh.AsObject())) return false; //--- return CNeuronBaseOCL::feedForward(cProjection.AsObject()); }
Das Ergebnis wird dann an die Methode der übergeordneten Klasse gesendet, um die endgültige Darstellung des analysierten Zustands der Umgebung zu erzeugen.
Der nächste Schritt ist die Implementierung der Verfahren für den Rückwärtsdurchlauf, die eine Schlüsselrolle beim Training des Modells spielen. Der Rückwärtsdurchlauf ist in calcInputGradients organisiert und folgt dem Vorwärtsdurchlauf in umgekehrter Richtung.
bool CNeuronMultitaskStockformer::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
Zu den Parametern dieser Methode gehört ein Zeiger auf das Quelldatenobjekt; in dessen Puffer muss der Fehlergradient übergeben werden, der entsprechend dem Einfluss der Eingabedaten auf die endgültige Modellausgabe verteilt wird. Und im Hauptteil der Methode wird die Relevanz des empfangenen Zeigers geprüft. Andernfalls wird die Datenübertragung unmöglich.
Gradienten werden zunächst auf die Faltungsprojektionsschicht mit Hilfe der Funktion der übergeordneten Klasse angewendet. Anschließend werden sie an die Summationsschicht des Zweifrequenzdecoders weitergeleitet.
if(!CNeuronBaseOCL::calcInputGradients(cProjection.AsObject())) return false; if(!cLowHigh.calcHiddenGradients(cProjection.AsObject())) return false;
Während der Initialisierung des Integrationsobjekts haben wir die Ersetzung von Zeigern auf die Puffer für die Fehlergradienten implementiert, die von den Aufmerksamkeitsmodulen des Decoders und der Ausgangssummierungsschicht verwendet werden. Auf diese Weise wird sichergestellt, dass der gesamte Fehlergradient, der in die Summationsschicht gelangt, vollständig an die entsprechenden Aufmerksamkeitsmodule weitergeleitet wird. Wir können also direkt zur Gradientenfortpflanzung durch die Aufmerksamkeitsmodule des Decoders übergehen.
Es ist jedoch zu beachten, dass die Daten der niederfrequenten Komponenten gleichzeitig in beiden Aufmerksamkeitsblöcken verwendet werden. Daher müssen wir den Fehlergradienten aus zwei Informationsströmen gewinnen. Zunächst führen wir die Operationen zur Verteilung des Fehlergradienten mit Hilfe des Moduls der Selbstaufmerksamkeit durch.
//--- Dual-Frequency Fusion Decoder if(!cLowFreqGraphAttention.calcHiddenGradients(cLowFreqFusionDecoder.AsObject())) return false;
Dann ersetzen wir vorübergehend den Zeiger auf den Fehlergradientenpuffer des Moduls der Selbstaufmerksamkeit durch einen freien Puffer ähnlicher Größe und führen die Operationen der Fehlergradientenfortpflanzung der Kreuzaufmerksamkeit durch.
CBufferFloat *grad = cLowFreqGraphAttention.getGradient(); if(!cLowFreqGraphAttention.SetGradient(cLowFreqGraphAttention.getPrevOutput(), false) || !cLowFreqGraphAttention.calcHiddenGradients(cLowHighFreqFusionDecoder.AsObject(), cHighFreqGraphAttention.getOutput(), cHighFreqGraphAttention.getGradient(), (ENUM_ACTIVATION)cHighFreqGraphAttention.Activation()) || !SumAndNormilize(grad, cLowFreqGraphAttention.getGradient(), grad, 1, false, 0, 0, 0, 1) || !cLowFreqGraphAttention.SetGradient(grad, false)) return false;
Dann summieren wir die Daten der beiden Informationsströme und bringen die Zeiger auf die Datenpuffer in ihren ursprünglichen Zustand zurück.
Wir haben den Fehlergradienten auf hoch- und niederfrequente Komponenten auf der Ebene des zweifrequenten raum-zeitlichen Encoderausgangs verteilt. Als Nächstes verteilen wir den Gradienten nacheinander auf die Objekte zweier unabhängiger Ströme. Niedrige Frequenzen:
//--- Dual-Frequency Spatiotemporal Encoder //--- Low Frequency Encoder if(!cLowFreqPE.calcHiddenGradients(cLowFreqGraphAttention.AsObject())) return false; if(!cTemporalAttention.calcHiddenGradients(cLowFreqPE.AsObject())) return false; if(!cLowFreqSignal.calcHiddenGradients(cTemporalAttention.AsObject())) return false;
Dann hohe Frequenzen:
//--- High Frequency Encoder if(!cHighFreqPE.calcHiddenGradients(cHighFreqGraphAttention.AsObject())) return false; if(!cDilatedCasualConvolution.calcHiddenGradients(cHighFreqPE.AsObject())) return false; if(!cHighFreqSignal.calcHiddenGradients(cDilatedCasualConvolution.AsObject())) return false;
Die Gradienten aus beiden Datenströmen werden zu einem einzigen Tensor zusammengefügt:
//--- Decoupling Flow if(!Concat(cLowFreqSignal.getGradient(), cHighFreqSignal.getGradient(), cDecouplingFlow.getGradient(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetFilters(), cDecouplingFlow.GetUnits()*cDecouplingFlow.GetVariables())) return false; if(!prevLayer.calcHiddenGradients(cDecouplingFlow.AsObject())) return false; //--- return true; }
Und dann werden sie durch das Zerlegungsmodul zurück zu den Eingabedaten propagiert. Die Methode schließt mit der Rückgabe des logischen Ergebnisses der Operation an das aufrufende Programm ab.
Die Parameteroptimierung in updateInputWeights wird in der gleichen Reihenfolge durchgeführt, jedoch nur für Objekte mit trainierbaren Parametern. Der vollständige Code des Integrationsobjekts und aller seiner Methoden ist im Anhang verfügbar.
Damit ist die Diskussion über die Implementierungsalgorithmen des Systems Multitask-Stockformer abgeschlossen. Der nächste Schritt ist die Integration der realisierten Ansätze in die Architektur von trainierbaren Modellen.
Modell der Architektur
Die oben beschriebenen Ansätze des Multitask-Stockformers werden nun auf das Modell des Umgebungszustands-Encoders angewendet. Dank der Verwendung des umfassenden Implementierungsobjekts von Multitask-Stockformer bleibt die Modellarchitektur recht kompakt – sie besteht aus nur drei Schichten. Wie üblich beginnen wir mit den Eingabedaten und den Batch-Normalisierungsschichten.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } //--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Diese Schichten führen eine Vorverarbeitung der aus der Umgebung erhaltenen Rohdaten durch. Es folgt eine neue Schicht, die die Ansätze des Systems Multitask-Stockformer umsetzt.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultitaskStockformer; //--- Windows { int temp[] = {BarDescr, 10, LatentCount}; //Window, Filters, Output if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.layers = 3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
In unserem Experiment wurden 10 Wavelet-Filter verwendet. Jedes Aufmerksamkeitsmodul hatte 4 Köpfe und enthielt 3 interne Schichten.
Die Ausgaben des Umgebungszustands-Encoders werden von zwei Modellen verwendet: dem Akteur, der Handelsentscheidungen trifft, und dem Kritiker, der die vom Actor generierten Aktionen bewertet. Die Architekturen dieser Modelle wurden aus unseren früheren Studien übernommen, ebenso wie die Interaktion mit der Umgebung und die Schulungsprogramme. Die vollständigen Modellarchitekturen und der vollständige Programmcode, der in diesem Artikel verwendet wird, sind im Anhang verfügbar. Wir gehen nun zur letzten Phase über – dem Testen der Wirksamkeit der implementierten Lösungen anhand realer historischer Daten.
Tests
Im Laufe von zwei Artikeln haben wir die von den Autoren des Systems Multitask-Stockformer vorgeschlagenen Ansätze unter Verwendung von MQL5 umfassend umgesetzt. Nun ist es an der Zeit für die spannendste Phase – das Testen der Wirksamkeit der implementierten Lösungen anhand echter historischer Daten.
Es ist wichtig klarzustellen, dass wir die implementierten Ansätze und nicht das ursprüngliche System von Multitask-Stockformer evaluieren, da während der Implementierung mehrere Änderungen vorgenommen wurden.
Bei den Tests wurden die Modelle auf historischen Daten von EURUSD für das gesamte Jahr 2023 mit dem H1-Zeitrahmen trainiert. Alle analysierten Indikatoren wurden mit ihren Standardparametereinstellungen verwendet.
Für die erste Trainingsphase haben wir einen Datensatz verwendet, der in früheren Studien gesammelt wurde. Dieser Datensatz wurde in regelmäßigen Abständen aktualisiert, um ihn an die sich entwickelnde Politik der Akteure anzupassen. Nach mehreren Trainings- und Datenaktualisierungszyklen erwies sich die resultierende Strategie sowohl bei den Trainings- als auch bei den Testdatensätzen als rentabel.
Der Test der trainierten Strategie wurde mit historischen Daten für Januar 2024 durchgeführt, wobei alle anderen Parameter unverändert blieben. Die Ergebnisse werden im Folgenden vorgestellt.
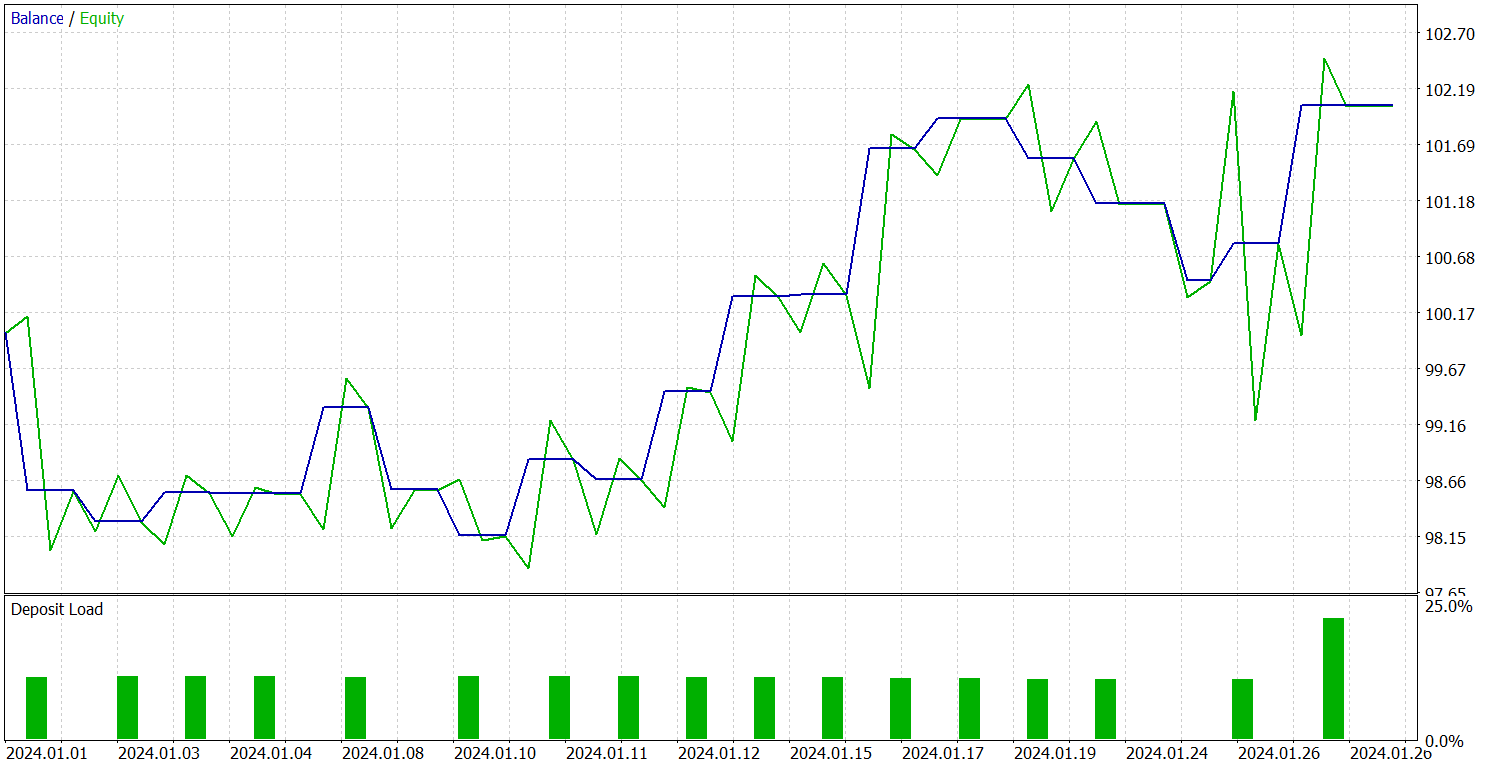
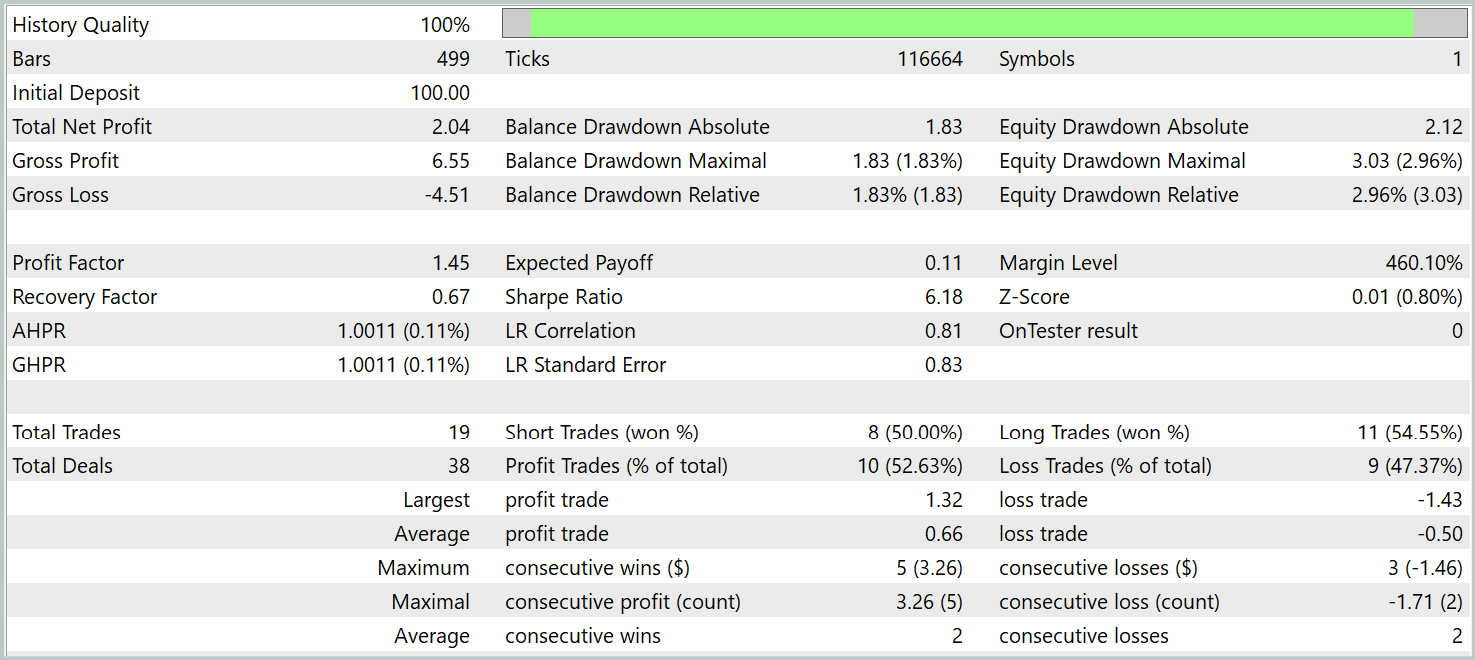
Während des Testzeitraums führte das Modell 19 Trades aus, von denen 10 mit Gewinn abgeschlossen wurden. Dies sind etwas mehr als 50 %. Aufgrund des höheren durchschnittlichen Gewinns pro gewonnenem Handel im Vergleich zu den verlorenen Positionen beendete das Modell den Testzeitraum jedoch mit einem Gesamtgewinn und erreichte einen Gewinnfaktor von 1,45.
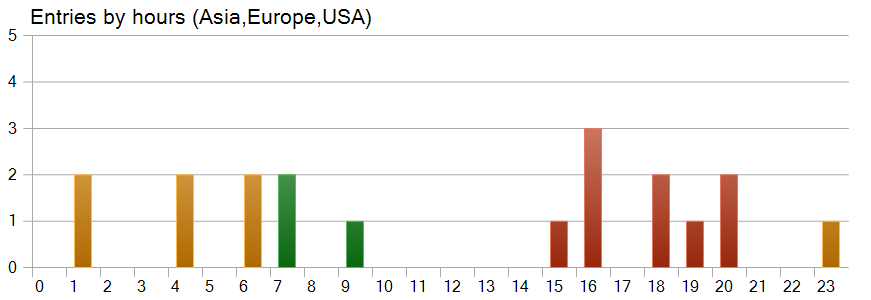
Eine interessante Beobachtung ergibt sich aus dem Zeitdiagramm für den Handel. Nahezu die Hälfte der Geschäfte wurde während der US-Handelssitzungen eröffnet, während das Modell in den Zeiten höchster Volatilität fast keine Geschäfte tätigte.
Schlussfolgerung
Wir haben das System Multitask-Stockformer untersucht – ein innovatives Aktienauswahlmodell, das diskrete Wavelet-Transformation mit Multitask-Selbstaufmerksamkeits-Modulen kombiniert. Dieser umfassende Ansatz ermöglicht die Identifizierung von Zeit- und Häufigkeitsmerkmalen in den Marktdaten und erlaubt die genaue Modellierung komplexer Wechselwirkungen zwischen den analysierten Faktoren.
Im praktischen Teil haben wir unsere eigene Implementierung der Rahmenansätze in MQL5 entwickelt. Wir integrierten die Ansätze in die Modellarchitekturen und trainierten diese Modelle auf realen historischen Daten. Die trainierten Modelle wurden dann mit dem MetaTrader 5 Strategy Tester getestet. Die Ergebnisse unserer Experimente zeigen das Potenzial der implementierten Lösungen. Bevor sie jedoch im realen Handel eingesetzt werden, sollten die Modelle auf einem repräsentativeren Datensatz trainiert und umfassenden Tests unterzogen werden.
Referenzen
- Stockformer: A Price-Volume Factor Stock Selection Model Based on Wavelet Transform and Multi-Task Self-Attention Networks
- Andere Artikel dieser Serie
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor für die Probenahme |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für die Probenahme mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | EA für das Modelltraining |
| 4 | Test.mq5 | Expert Advisor | Expert Advisor für Modellversuche |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Beschreibung des Systemzustands und der Modellarchitektur |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Code-Bibliothek des OpenCL-Programms |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16757
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.