Diskussion zum Artikel "Verschaffen Sie sich einen Vorteil auf jedem Markt (Teil III): Visa-Ausgabenindex"
Vielen Dank, Gamu
Toller Artikel, vielen Dank für den Austausch!
linfo2 #:
Nochmals vielen Dank, Gamu. Gut geschrieben wie immer. Eine großartig kommentierte Vorlage, wie man visualisiert, skaliert, testet, auf Überanpassung prüft, einen Datafeed implementiert, ein Handelssystem aus einem Datensatz vorhersagt und implementiert. Fantastisch, sehr geschätzt
Vielen Dank, Neil, für dein Feedback, es ist schön, so freundliche Worte zu hören.Nochmals vielen Dank, Gamu. Gut geschrieben wie immer. Eine großartig kommentierte Vorlage, wie man visualisiert, skaliert, testet, auf Überanpassung prüft, einen Datafeed implementiert, ein Handelssystem aus einem Datensatz vorhersagt und implementiert. Fantastisch, sehr geschätzt
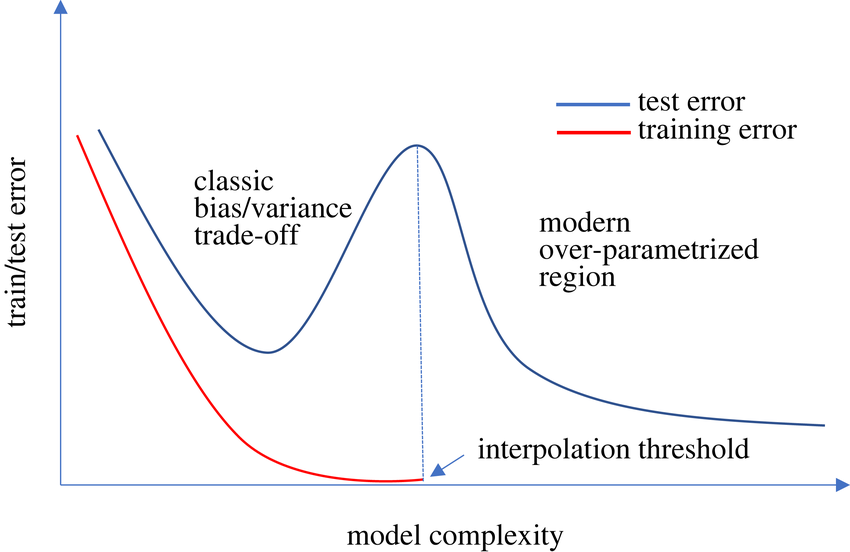
Das Verrückte daran ist, dass es jeden Tag neue Forschungsergebnisse gibt, die alles in Frage stellen, was wir zu wissen glaubten. Ich habe vor kurzem von dem Phänomen des doppelten Abstiegs erfahren.
Wenn die Theorie stimmt, gibt es so etwas wie Überanpassung nicht. Dem Phänomen zufolge sinkt der Validierungsfehler immer weiter, wenn wir größere tiefe neuronale Netze über längere Zeiträume mit demselben Trainingssatz trainieren.
Das Bild, das ich unten angehängt habe, verdeutlicht das Phänomen visuell. Der Haken an der Sache ist, dass das Training eines so großen Modells über einen so langen Zeitraum hinweg teuer ist, und wenn die Daten zudem verrauscht sind, dauert das Phänomen noch länger. Ich war nicht in der Lage, die Ergebnisse auf meinem Computer zu reproduzieren, aber dieses Papier macht die Runde
{kind=link}
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Neuer Artikel Verschaffen Sie sich einen Vorteil auf jedem Markt (Teil III): Visa-Ausgabenindex :
In der Welt der Big Data gibt es Millionen von alternativen Datensätzen, die das Potenzial haben, unsere Handelsstrategien zu verbessern. In dieser Artikelserie werden wir Ihnen helfen, die informativsten öffentlichen Datensätze zu finden.
VISA ist ein amerikanisches multinationales Zahlungsdienstleistungsunternehmen. Das Unternehmen wurde 1958 gegründet und betreibt heute eines der größten Transaktionsverarbeitungsnetzwerke der Welt. VISA ist gut positioniert, um eine Quelle für seriöse alternative Daten zu sein, da das Unternehmen fast alle Märkte in der entwickelten Welt durchdrungen hat. Darüber hinaus erhebt auch die Federal Reserve Bank of St. Louis einen Teil ihrer makroökonomischen Daten bei VISA.
In dieser Diskussion werden wir den VISA Spending Momentum Index (SMI) analysieren. Der Index ist ein makroökonomischer Indikator für das Ausgabeverhalten der Verbraucher. Die Daten werden von VISA unter Verwendung der firmeneigenen Netzwerke und der VISA-Debit- und -Kreditkarten gesammelt. Alle Daten sind entpersonalisiert und werden hauptsächlich in den Vereinigten Staaten erhoben. Da VISA weiterhin Daten aus verschiedenen Märkten sammelt, könnte dieser Index schließlich zu einem Maßstab für das weltweite Verbraucherverhalten werden.
Wir werden einen von der Federal Reserve Bank of St. Louis bereitgestellten API-Dienst nutzen, um die VISA SMI-Datensätze abzurufen. Die API der Federal Reserve Economic Database (FRED) ermöglicht uns den Zugang zu Hunderttausenden verschiedener wirtschaftlicher Zeitreihendaten, die auf der ganzen Welt gesammelt wurden.
Autor: Gamuchirai Zororo Ndawana