
Selbstoptimierende Expert Advisors in MQL5 (Teil 12): Aufbau von linearen Klassifikatoren durch Matrixfaktorisierung

Die Matrixfaktorisierung ist ein wichtiges Werkzeug für algorithmische Händler, die an der Entwicklung numerisch gesteuerter Anwendungen interessiert sind. Mit diesen Tools können wir verschiedene Arten von Algorithmen für das maschinelle Lernen und noch mehr erstellen. Bislang haben wir in unserer Diskussion nur Regressionsaufgaben berücksichtigt. Wenden wir uns nun dem Problem der Klassifizierung zu. In der heutigen Diskussion werden wir uns der Herausforderung stellen, einen Marktklassifikator zu erstellen. Dieser Klassifikator wird in der Lage sein, zwischen Aufwärts- und Abwärtsbewegungen auf dem Markt zu unterscheiden. Wir wollen, dass es uns hilft, unsere Handelsgeschäfte richtig zu platzieren. Die Aufgabe des Klassifizierers besteht darin, aus historischen Beobachtungen des Marktverhaltens zu lernen und daraus die richtigen Maßnahmen abzuleiten, die wir an einem bestimmten Handelstag ergreifen sollten.
Unsere Handelsstrategie funktioniert wie unten beschrieben. Ziel ist es, Marktbewegungen auf der Grundlage des erwarteten Verhaltens des gleitenden Durchschnittsindikators zu antizipieren. Außerdem wollen wir, dass sich der Kurs in Übereinstimmung mit dem gleitenden Durchschnitt verhält. Das heißt, wenn unser Klassifizierungsmodell einen Rückgang des gleitenden Durchschnitts erwartet, wollen wir auch Kursniveaus beobachten, die unter den Indikator fallen. Wenn wir davon ausgehen, dass sowohl der gleitende Durchschnitt als auch der Preis fallen werden, eröffnen wir Verkaufspositionen. Der gleitende Durchschnitt zeigt die Richtung des Preises an, aber wir wollen auch, dass sich die Preisniveaus über den Indikator hinaus beschleunigen, bevor wir unsere Positionen eröffnen.
Die gleiche Logik gilt für Kaufpositionen. Wir gehen davon aus, dass der gleitende Durchschnitt ansteigt, und die Kurse sollten sich deutlich darüber bewegen, damit wir einen starken Kauf tätigen können.
Aus dieser Beschreibung geht hervor, dass unser Modell zwei kategoriale Ausgaben gleichzeitig vorhersagen wird. Dies sollte jedoch nicht mit einem Mehrklassen-Klassifikationsmodell verwechselt werden. Jede der beiden Variablen, die unser Modell vorhersagt, ist ein binäres Ergebnis. Mit anderen Worten: Das Modell verfolgt zwei getrennte binäre Ergebnisse. Die hier beschriebene Architektur ist nicht geeignet, mehr als zwei Klassen gleichzeitig zu klassifizieren.
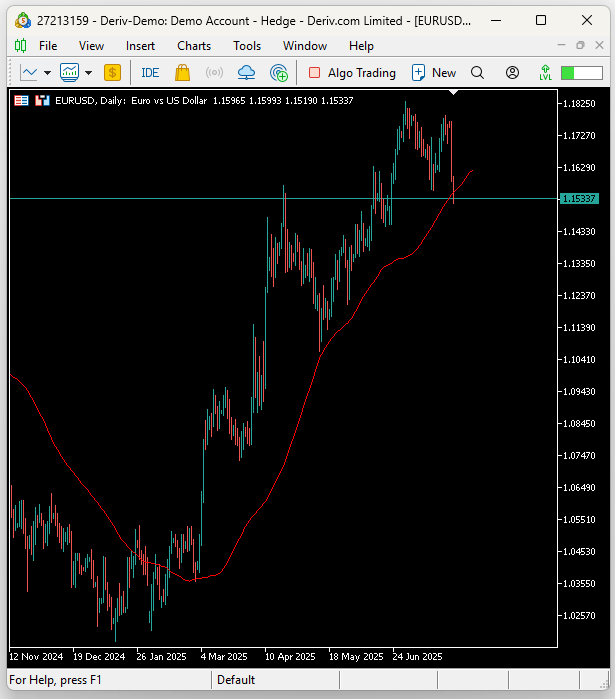
Abbildung 1: Visualisierung unserer Handelsstrategie in Aktion
Matrixfaktorisierung zum Aufbau linearer Klassifikatoren
Wie bei den meisten unserer Handelsanwendungen beginnen wir mit der Definition von Systemdefinitionen. In diesem speziellen Fall haben wir sechs Eingaben, die wir in unserer Eingabedatenmatrix X festhalten.
//+------------------------------------------------------------------+ //| Linear Regression.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define TOTAL_INPUTS 6
Nachdem wir unsere Systemdefinitionen festgelegt haben, definieren wir nun Nutzereingaben, die der Endbenutzer anpassen kann. Insbesondere möchten wir, dass der Endnutzer in der Lage ist, den geeigneten Zeitrahmen und die Größe des Stop-Loss zu wählen.
//+------------------------------------------------------------------+ //| System Inputs | //+------------------------------------------------------------------+ int bars = 200;//Number of historical bars to fetch int horizon = 1;//How far into the future should we forecast int MA_PERIOD = 50; //Moving average period ENUM_TIMEFRAMES TIME_FRAME = PERIOD_D1;//User Time Frame input ENUM_TIMEFRAMES RISK_TIME_FRAME = PERIOD_D1; input double sl_size = 2;
Darüber hinaus müssen wir auch wichtige Systembibliotheken einbinden, die wir benötigen, wie die Handelsbibliothek und zwei nutzerdefinierte Bibliotheken, die ich geschrieben habe, um die Zeit zu verfolgen und wichtige Handelsinformationen zu erhalten.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh>
Weiterhin ist unser System auch darauf angewiesen, dass wir wichtige globale Variablen für unsere Übung erstellen. In diesem speziellen Fall benötigen wir globale Variablen, die als Handler für unsere technischen Indikatoren dienen. Wir brauchen globale Variablen, um die Eingangsdaten und die Ausgangsdaten zu verfolgen, die wir vom Markt erhalten. Außerdem benötigen wir Puffer für unsere technischen Indikatoren, um ihre aktuellen Werte abzurufen.
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ int ma_close_handler; double ma_close[]; Time *Timer; TradeInfo *TradeInformation; vector bias,temp,Z1,Z2; matrix X,y,prediction,b; int time; CTrade Trade; int state; int atr_handler; double atr[];
Wenn unser System zum ersten Mal geladen wird, haben wir eine spezielle Methode namens initialize, die aufgerufen wird, um alle Systemvariablen zu initialisieren.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- initialize(); //--- return(INIT_SUCCEEDED); }
Wenn unser System nicht mehr gebraucht wird, geben wir den Speicher frei, der von den technischen Indikatoren verbraucht wurde.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(atr_handler); IndicatorRelease(ma_close_handler); }
Immer wenn sich neue aktualisierte Preiskerzen gebildet haben, rufen wir zwei spezielle Methoden auf. Die erste Methode ist die Setup-Methode, und die letzte ist die findSetup-Einheit. Wir werden diese später im Detail besprechen, wenn wir fortfahren.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(Timer.NewCandle()) { setup(); find_setup(); } }
Wenn unser System zum ersten Mal initialisiert wird, laden wir neue Instanzen von Handlern in ihre entsprechenden Bezeichner. So werden wir zum Beispiel dynamisch ein neues Objekt für unsere Zeitbibliothek erstellen, das die Kerzenbildung verfolgt. Wir erstellen auch ein neues Objekt für unsere Handelsinformationsklasse. Denken Sie daran, dass diese Klasse für die Überwachung wichtiger Details verantwortlich ist, wie z. B. das kleinste auf dem aktuellen Markt für den Handel zulässige Losgrößenvolumen und die aktuellen Geld- und Briefkurse. Darüber hinaus ist die Funktion initialize für das Laden aller Standardwerte in unsere Matrizen und die zugehörigen Bezeichner verantwortlich.
//+------------------------------------------------------------------+ //| Initialize our system variables | //+------------------------------------------------------------------+ void initialize(void) { Timer = new Time(Symbol(),TIME_FRAME); TradeInformation = new TradeInfo(Symbol(),TIME_FRAME); ma_close_handler = iMA(Symbol(),TIME_FRAME,MA_PERIOD,0,MODE_SMA,PRICE_CLOSE); atr_handler = iATR(Symbol(),RISK_TIME_FRAME,14); bias = vector::Ones(TOTAL_INPUTS); Z1 = vector::Ones(TOTAL_INPUTS); Z2 = vector::Ones(TOTAL_INPUTS); X = matrix::Ones(TOTAL_INPUTS,bars); y = matrix::Ones(1,bars); time = 0; state = 0; }
Die Funktion „find_setup()“ ist etwas komplizierter als die anderen Funktionen, die wir bisher betrachtet haben. Die Funktion findSetup ermittelt zunächst den aktuellen Schlusskurs und kopiert dann den aktuellen Wert unserer Indikatoren. Daher kopieren wir die ATR- und die gleitenden Durchschnittswerte in die entsprechenden Puffer. Wenn dann keine Positionen mehr offen sind, wird der Systemstatus zurückgesetzt. Nun müssen wir die Vorhersage betrachten, die wir von unserem linearen Klassifikator erhalten.
Erinnern Sie sich, dass unser Klassifikator zwei Ausgaben gleichzeitig modelliert. Die erste Vorhersage ist die Richtung, die der gleitende Durchschnittsindikator in der Zukunft voraussichtlich einschlagen wird, während die zweite Vorhersage der Abstand zwischen dem Preis und dem gleitenden Durchschnitt sein wird. Wir wollen also, dass diese beiden Vorhersagen miteinander übereinstimmen. Wenn der Indikator für den gleitenden Durchschnitt voraussichtlich fallen wird, wollen wir auch sehen, dass die Kursniveaus weiter unter ihn fallen. Und wenn ein Anstieg des gleitenden Durchschnitts erwartet wird, wollen wir, dass die Kurse über ihn steigen.
Diese beiden Einstellungen bilden die Grundlage für unsere Handelsstrategie. Beide Vorhersagen sollten größer als 0,5 sein, damit wir kaufen können. Außerdem sollten beide Vorhersagen unter 0,5 liegen, damit wir verkaufen können. Andernfalls, wenn wir bereits offene Positionen haben, werden wir einfach unsere Position und die Erwartungen unseres linearen Klassifikators im Auge behalten. Wenn wir verkaufen, aber unser Modell einen Anstieg des gleitenden Durchschnittsindikators erwartet, schließen wir unsere Position. Umgekehrt verhält es sich, wenn wir kaufen.
Andernfalls, wenn alles in Ordnung zu sein scheint, werden wir einfach unseren Stop-Loss auf eine profitablere Einstellung aktualisieren und von dort aus weitermachen.
//+------------------------------------------------------------------+ //| Find a trading setup for our linear classifier model | //+------------------------------------------------------------------+ void find_setup(void) { double c = iClose(Symbol(),TIME_FRAME,0); CopyBuffer(atr_handler,0,0,1,atr); CopyBuffer(ma_close_handler,0,0,1,ma_close); if(PositionsTotal() == 0) { state = 0; if((prediction[0,0] > 0.5) && (prediction[1,0] > 0.5)) { Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),(TradeInformation.GetBid() - (sl_size * atr[0])),0); state = 1; } if((prediction[0,0] < 0.5) && (prediction[1,0] < 0.5)) { Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),(TradeInformation.GetAsk() + (sl_size * atr[0])),0); state = -1; } } if(PositionsTotal() > 0) { if(((state == -1) && (prediction[0,0] > 0.5)) || ((state == 1)&&(prediction[0,0] < 0.5))) Trade.PositionClose(Symbol()); if(PositionSelect(Symbol())) { double current_sl = PositionGetDouble(POSITION_SL); if((state == 1) && ((ma_close[0] - (2 * atr[0]))>current_sl)) { Trade.PositionModify(Symbol(),(ma_close[0] - (2 * atr[0])),0); } else if((state == -1) && ((ma_close[0] + (2 * atr[0]))<current_sl)) { Trade.PositionModify(Symbol(),(ma_close[0] + (2 * atr[0])),0); } } } }
Wir haben spezielle Methoden, die wir für die Anpassung unseres linearen Klassifikators verwenden. Die Anpassungsmethode, wie unten gezeigt, passt unsere Daten-Mapping früheren Preis-Inputs an die beiden Ziele, die wir verfolgen wollen. Erinnern Sie sich, dass wir die in der OpenBLAS-Bibliothek enthaltene Methode der Singulärwertzerlegung (SVD) verwenden, um unser Modell schnell in eine Form zu faktorisieren, die es uns ermöglicht, die optimalen Koeffizienten zu finden und sie in B zu speichern.
//+------------------------------------------------------------------+ //| Fir our classification model | //+------------------------------------------------------------------+ void fit(void) { //--- Fit the model matrix OB_U,OB_VT,OB_SIGMA; vector OB_S; X.SingularValueDecompositionDC(SVDZ_S,OB_S,OB_U,OB_VT); OB_SIGMA.Diag(OB_S); b = y.MatMul(OB_VT.Transpose().MatMul(OB_SIGMA.Inv()).MatMul(OB_U.Transpose())); }
Wie immer ist das Abrufen und Speichern von Daten ein wichtiger Bestandteil eines jeden Modells für maschinelles Lernen. Wir subtrahieren den Mittelwert und teilen ihn durch die Standardabweichung für jeden unserer Dateneinträge.
Wir wollen zum Beispiel den Eröffnungskurs, den Höchstkurs, den Tiefstkurs und die Werte der technischen Indikatoren im Auge behalten. Alle diese Werte müssen vom Mittelwert subtrahiert und durch die Standardabweichung geteilt werden, bevor sie in der Datenmatrix X gespeichert werden.
Nachdem wir unsere Y-Matrix kopiert und umgestaltet haben, müssen wir unsere Ausgaben entweder als Nullen (um anzuzeigen, dass das Preisniveau gefallen ist) oder als Einsen (um anzuzeigen, dass das Preisniveau gestiegen ist) speichern. Auf diese Weise erstellen wir ein Klassifizierungsmodell.
//+------------------------------------------------------------------+ //| Prepare the data needed for our classifier | //+------------------------------------------------------------------+ void fetch_data(void) { //--- Reshape the matrix X = matrix::Ones(TOTAL_INPUTS,bars); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_OPEN,horizon,bars); Z1[0] = temp.Mean(); Z2[0] = temp.Std(); temp = ((temp - Z1[0]) / Z2[0]); X.Row(temp,1); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_HIGH,horizon,bars); Z1[1] = temp.Mean(); Z2[1] = temp.Std(); temp = ((temp - Z1[1]) / Z2[1]); X.Row(temp,2); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_LOW,horizon,bars); Z1[2] = temp.Mean(); Z2[2] = temp.Std(); temp = ((temp - Z1[2]) / Z2[2]); X.Row(temp,3); //--- Store the Z-scores temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,horizon,bars); Z1[3] = temp.Mean(); Z2[3] = temp.Std(); temp = ((temp - Z1[3]) / Z2[3]); X.Row(temp,4); //--- Store the Z-scores temp.CopyIndicatorBuffer(ma_close_handler,0,horizon,bars); Z1[4] = temp.Mean(); Z2[4] = temp.Std(); temp = ((temp - Z1[4]) / Z2[4]); X.Row(temp,5); //--- Reshape the output target y.Reshape(2,bars); vector temp_2,temp_3,temp_4; //--- Prepare to label the target accordingly temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,horizon,bars); temp_4.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,bars); temp_2.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,bars); temp_3.CopyIndicatorBuffer(ma_close_handler,0,0,bars); for(int i=0;i<bars;i++) { //--- Record if price levels appreciated or depreciated if(temp[i] > temp_4[i]) y[0,i] = 0; else if(temp[i] < temp_4[i]) y[0,i] = 1; //--- Record if price levels remained above the moving average indicator, or fell beneath it. if(temp_2[i] < temp_3[i]) y[1,i] = 0; if(temp_2[i] > temp_3[i]) y[1,i] = 1; } Print("Training Input Data: "); Print(X); Print("Training Target"); Print(y); }
Danach sind wir bereit, Vorhersagen von unserem Klassifizierungsmodell zu erhalten. Um einfach eine Vorhersage von unserem Klassifizierungsmodell zu erhalten, benötigen wir die letzte Zeile in unseren Eingabedaten X. Alternativ können wir sie uns auch als den aktuellen Marktwert vorstellen – die aktuellen Marktbedingungen. Wir nehmen diese aktuellen Marktbedingungen und multiplizieren sie mit den Koeffizienten, die wir aus den historischen Daten gelernt haben, und so erhalten wir eine Vorhersage.
//+------------------------------------------------------------------+ //| Obtain a prediction from our classification model | //+------------------------------------------------------------------+ void predict(void) { //--- Prepare to get a prediction //--- Reshape the data X = matrix::Ones(TOTAL_INPUTS,1); //--- Get a prediction temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_OPEN,0,1); temp = ((temp - Z1[0]) / Z2[0]); X.Row(temp,1); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_HIGH,0,1); temp = ((temp - Z1[1]) / Z2[1]); X.Row(temp,2); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_LOW,0,1); temp = ((temp - Z1[2]) / Z2[2]); X.Row(temp,3); temp.CopyRates(Symbol(),TIME_FRAME,COPY_RATES_CLOSE,0,1); temp = ((temp - Z1[3]) / Z2[3]); X.Row(temp,4); temp.CopyIndicatorBuffer(ma_close_handler,0,0,1); temp = ((temp - Z1[4]) / Z2[4]); X.Row(temp,5); Print("Prediction Inputs: "); Print(X); //--- Get a prediction prediction = b.MatMul(X); Print("Prediction"); Print(prediction); }
Es kann jedoch mühsam sein, jede dieser Methoden einzeln aufzurufen. Deshalb haben wir eine eigene Setup-Methode entwickelt, die jede dieser drei Methoden in der Reihenfolge aufruft, in der wir sie benötigen. Zuerst holen wir die Daten ab. Dann werden wir unser Modell an die Daten anpassen. Und schließlich werden wir eine Vorhersage erhalten.
Mit dieser einfachen Einrichtungsmethode können wir alle drei Schritte durchführen – immer in der richtigen Reihenfolge.
//+------------------------------------------------------------------+ //| Obtain a prediction from our model | //+------------------------------------------------------------------+ void setup(void) { fetch_data(); fit(); predict(); } //+------------------------------------------------------------------+
Schließlich müssen wir die Systemdefinitionen, die wir zu Beginn unserer Anwendung vorgenommen haben, vereinheitlichen.
#undef TOTAL_INPUTS Unser Backtest beginnt im Januar 2020 und läuft über einen Zeitraum von fünf Jahren auf täglicher Basis bis zum Jahr 2025. Wir werden unsere Anwendung mit dem Symbol EURUSD testen.
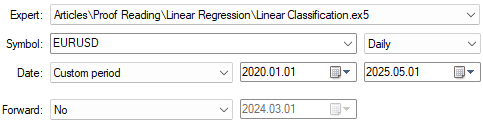
Abbildung 2: Auswahl der Backtest- und Optimierungstage
Darüber hinaus verwenden wir für die bestmöglichen Einstellungen immer zufällige Verzögerungseinstellungen, um sicherzustellen, dass die Bedingungen, unter denen wir unsere Anwendung testen, den realen Marktumgebungen entsprechen, die wir in Zukunft zu erwarten haben.
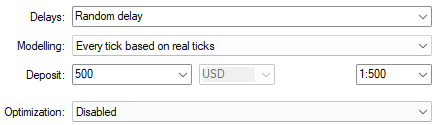
Abbildung 3: Auch die Auswahl der Backtest-Bedingungen ist wichtig
Ich habe einen Screenshot von der Leistung unserer Anwendung während des Backtests gemacht. Wie wir sehen können, zeigt uns die Anwendung die Vorhersageeingaben, die sie erhalten hat. Erinnern Sie sich daran, dass die erste Eingabe immer eine ist, um den Achsenabschnitt darzustellen. Aber eigentlich gilt unsere Aufmerksamkeit vor allem den tatsächlichen Vorhersagen, die unser Modell macht.
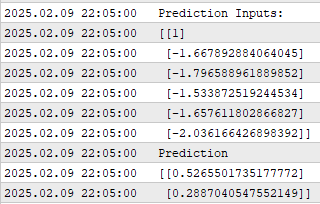
Abbildung 4: Das Ergebnis unseres linearen Klassifizierungsalgorithmus
Wie wir sehen können, liefert unser Modell zwei Vorhersagen, wie wir bereits erwähnt haben. Die erste Vorhersage bezieht sich auf die Veränderung der Position des gleitenden Durchschnitts in der Zukunft, während die zweite Vorhersage mit der Veränderung des Preises im Verhältnis zum gleitenden Durchschnitt zusammenhängt. Und denken Sie daran, dass wir wollen, dass diese beiden Veränderungen in eine einheitliche Richtung gehen.
Wir können auch die Kapitalkurve beobachten, die durch unsere Handelsstrategie entsteht. Wie wir sehen, weist die Kapitalkurve im Laufe der Zeit einen Aufwärtstrend auf, obwohl sie nicht ganz stabil ist.
Außerdem sollte sich der Leser bewusst sein, dass in dieser Kurve zwei Linien dargestellt sind. Die blaue Linie zeigt unseren Kontostand im Laufe der Zeit, die grüne Linie das Eigenkapital des Kontos im Laufe der Zeit. Wie wir sehen können, gibt es viele Fälle, in denen die Aktie – die grüne Linie – die blaue Linie übersteigt.
Nach meiner Erfahrung als Autor handelt es sich dabei um entgangene Gewinne oder um Signale in unserer Handelsstrategie, die wir immer noch nicht aufgreifen. Dieses Signal geht an unserer Handelsstrategie vorbei, und wir nutzen diese Gewinne nicht aus. Dies deutet darauf hin, dass unsere Strategie noch verbesserungsbedürftig ist.
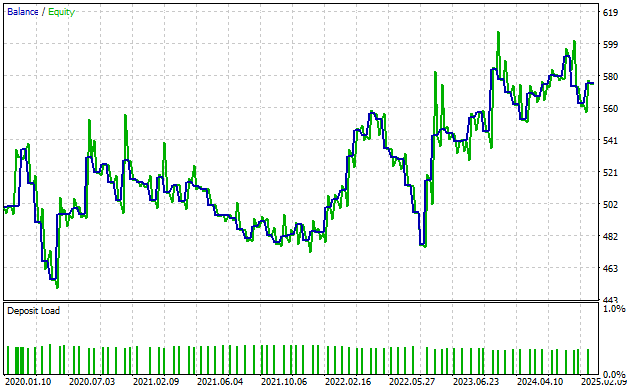
Abbildung 5: Unsere Kapitalkurve signalisiert uns, dass wir noch einiges nicht gelernt haben.
Schließlich können wir die detaillierten Statistiken über unsere Leistung im Laufe der Zeit betrachten. Und wie wir sehen können, ist unser durchschnittlicher profitabler Handel größer als unser durchschnittlicher Verlusthandel. Der größte Gewinn, den wir mit unserer Strategie erzielt haben, ist auch größer als der größte Verlust, den wir gemacht haben, was sehr ermutigend ist.
Wenn wir jedoch den Prozentsatz der gewinnbringenden Geschäfte betrachten, sehen wir, dass wir 43 % gewinnbringende Geschäfte haben, was weniger als die Hälfte ist. Dies unterstreicht, was ich dem Leser nahegelegt habe, als wir uns die Kapitalkurve ansahen und die Spitzen der verpassten Aktien sahen, die unser System nicht erkennen konnte.
Das bestärkt uns in unserer Überzeugung, dass das System noch verbessert werden kann und dass es Informationen gibt, die wir noch nicht erfasst haben. Auch wenn dies ein guter Anfang ist, gibt es noch mehr Signale, die wir aufdecken und lernen können.
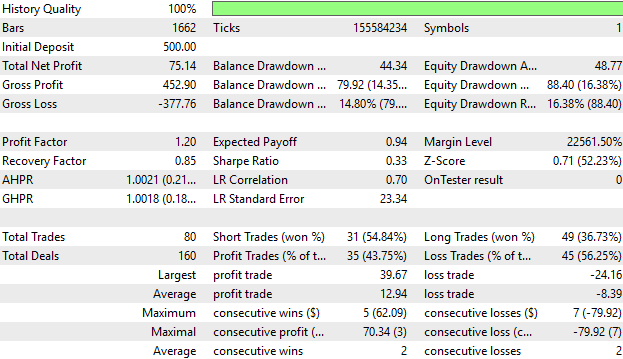
Abbildung 6: Die detaillierten Statistiken über unsere Leistung bestätigen unsere früheren Schlussfolgerungen, dass das System verbesserungswürdig ist
Schlussfolgerung
Abschließend hat dieser Artikel dem Leser die vielfältigen Anwendungen der Matrixfaktorisierung gezeigt, die wir als algorithmische Händler in unseren MQL5-Anwendungen nutzen können. Als wir die Matrixfaktorisierung zum ersten Mal vorstellten, betrachteten wir sie als ein Werkzeug, das für die Regression verwendet werden kann. Jetzt betrachten wir es als ein Werkzeug, das für die Klassifizierung verwendet werden kann.
Aber ich verspreche dem Leser nur eines: Es gibt noch viel mehr, was wir behandeln müssen. Dies sind nur die Grundlagen. Dies sind, meiner Meinung nach, die einfachen Anwendungen, die uns schnell den Wert der Matrixfaktorisierung zeigen. Wenn Sie diese Artikelserie verfolgt haben, dann wissen Sie jetzt, wie man ein Regressionsmodell mit Hilfe der Matrixfaktorisierung oder ein Klassifizierungsmodell oder eine Kombination aus beidem erstellt – Modelle, die nicht nur auf eine Vorhersage zur gleichen Zeit beschränkt sind, sondern mehrere Ziele gleichzeitig vorhersagen können.
Und doch verspreche ich Ihnen, dem Leser, dass es noch viele weitere Vorteile der Matrixfaktorisierung gibt, die wir noch nicht behandelt haben. Doch bevor wir diese Vorteile erkunden können, müssen wir zunächst die Grundlagen beherrschen. Außerdem haben Sie gesehen, wie einfach es ist – dank der speziellen Funktionen, die uns in der MQL5-API zur Verfügung stehen. Sie haben gesehen, wie einfach es ist, diese leistungsstarken Matrix-Methoden in Ihre Handelsanwendungen zu integrieren.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/18987
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.