
Klassische Strategien neu interpretieren (Teil 14): Analyse mehrerer Strategien

In unserer vorangegangenen Diskussion aus unserer Artikelserie über selbstoptimierende Expert Advisors haben wir uns der Herausforderung gestellt, ein Ensemble aus mehreren Strategien zu erstellen und sie zu einer einzigen, leistungsfähigeren Strategie zu verschmelzen, als wir ursprünglich hatten.
Wir beschlossen, unsere Strategien demokratisch zusammenarbeiten zu lassen, bei der jede Strategie eine einzige Stimme haben sollte. Das Gewicht jeder Stimme wurde zu einem Tuning-Parameter, den wir, wie bereits erwähnt, vom genetischen Optimierer so einstellen ließen, dass die Rentabilität unserer Handelsstrategie maximiert wurde. Wir haben dann die Strategie eliminiert, der der genetische Optimierer das geringste Gewicht zugewiesen hat, sodass die beiden Strategien übrig blieben, die wir nun analysieren und um die herum wir statistische Modelle erstellen werden.
In dieser Diskussion haben wir die Marktdaten mit Hilfe eines MQL5-Skripts extrahiert, basierend auf den besten Ergebnissen, die unser genetischer Optimierer ermittelt hat. Denken Sie daran, dass wir die Ergebnisse ausgewählt haben, die sowohl im Backtest als auch im Vorwärtstest stabil waren, und dies als Entscheidungsfaktor verwendet haben.
Bei näherer Betrachtung der Renditen, die durch die beiden vom genetischen Optimierer ausgewählten Strategien erzielt wurden, stellten wir jedoch fest, dass die Strategien stark miteinander korreliert waren. Mit anderen Worten, beide Strategien neigten dazu, zu etwa denselben Zeitpunkten zu gewinnen und zu verlieren. Zwei stark korrelierte Handelsstrategien sind nicht besser als nur eine Strategie, und mit nur einer Strategie wird der gesamte Zweck der Analyse mehrerer Strategien verfehlt.
Bei dem Versuch, künstliche Intelligenz zur Entwicklung von Handelsstrategien einzusetzen, können viele Dinge schief gehen, und es scheint, dass der genetische Optimierer den von uns vorgegebenen Rahmen ausgenutzt und die am stärksten korrelierten Strategien ausgewählt hat. Aus rein mathematischer Sicht ist dies ein kluger Schachzug: Es wird für den genetischen Optimierer einfacher, den Gesamtsaldo des Kontos zu antizipieren, wenn die dominanten Strategien korreliert sind.
Ursprünglich hatte ich erwartet, dass der genetische Optimierer den profitabelsten Strategien eine höhere und den weniger profitablen eine geringere Gewichtung zuweisen würde. Da wir jedoch nur 3 Strategien zur Auswahl hatten und dieses Optimierungsverfahren nur einmal durchgeführt wurde, können wir nicht ausschließen, dass dies alles zufällig geschehen ist. Das heißt, wenn wir die Optimierung der Stimmgewichte mit einem langsamen und vollständigen Optimierungsalgorithmus wiederholen würden, dann hätte unser Optimierer vielleicht keine korrelierten Strategien ausgewählt.
Diese Erkenntnis hat mich dazu veranlasst, den Ansatz, den wir zur Auswahl der optimalen Einstellungen für unsere Strategien verwenden, zu überarbeiten. Es scheint, dass wir zunächst alle Gewichte der einzelnen Stimmen auf eins festlegen sollten. Dies zwingt den genetischen Optimierer, sich ausschließlich darauf zu konzentrieren, die profitabelsten Einstellungen für jeden von uns verwendeten Indikator zu finden. Wie wir auf unserer gemeinsamen Reise sehen werden, erweist sich dieser überarbeitete Ansatz als besser als unser ursprünglicher Plan. Wenn zwei korrelierte Strategien für die Analyse mehrerer Strategien verwendet werden, werden keine wirklichen Fortschritte erzielt. Daher haben wir gelernt, das objektive Problem der Analyse mehrerer Strategien besser zu formulieren: „Wie können wir am besten mehrere Strategien auswählen, die unkorrelierte Renditen erzielen und die Rentabilität unseres Kontos maximieren?“.
Erste Schritte in MQL5
Zunächst schreiben wir ein Skript, um historische Marktdaten mit den Einstellungen abzurufen, mit denen wir bei unserem vorherigen Test, bei dem wir die beiden bisher verwendeten Strategien ausgewählt haben, unsere Rendite maximiert haben. Unser System stützt sich auf einige feste Parameter, die wir aus den zuvor besprochenen Tests zur genetischen Optimierung gelernt haben. Diese Parameter unserer Traumstrategie bleiben fest, während wir die Daten abrufen.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 100 //--- Period for our moving average #define MA_TYPE MODE_EMA //--- Type of moving average we have #define RSI_PERIOD 24 //--- Period For Our RSI Indicator #define RSI_PRICE PRICE_CLOSE //--- Applied Price For our RSI Indicator #define HORIZON 38 //--- Holding period #define TF PERIOD_H3 //--- Time Frame
Unser System hängt von mehreren wichtigen globalen Variablen ab, die für die Überwachung unserer technischen Indikatoren verantwortlich sind und in den entsprechenden Handles und Puffern gespeichert sind, die wir während der Ausführung unseres Skripts aufrufen werden. Darüber hinaus werden wir weitere Variablen definieren, wie den Namen der Ausgabedatei und die abzufragende Datenmenge.
//--- Our handlers for our indicators int ma_handle,ma_o_handle,rsi_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],rsi_reading[]; //--- File name string file_name = Symbol() + " Market Data As Series Multiple Strategy Analysis.csv"; //--- Amount of data requested input int size = 3000;
Der Hauptteil unseres Skripts umfasst die wichtigsten Aufgaben, die wir heute erledigen wollen. Wir werden unsere Indikatoren initialisieren und die Indikatorwerte als Serien einstellen, wobei wir sicherstellen, dass die Werte chronologisch von den ältesten bis zu den jüngsten Daten geordnet sind. Auf diese Weise wollen wir unsere Daten strukturieren und weitergeben. Von dort aus werden wir alle Marktdaten ausschreiben und einige arithmetische Berechnungen durchführen, um die historischen Veränderungen der Marktdaten zu verfolgen, indem wir den Horizont-Parameter verwenden, der von unserem genetischen Optimierer in unserer vorherigen Diskussion eingestellt wurde.
//+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); rsi_handle = iRSI(_Symbol,TF,RSI_PERIOD,RSI_PRICE); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(rsi_handle,0,0,fetch,rsi_reading); ArraySetAsSeries(rsi_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","True Open","True High","True Low","True Close","True MA C","True MA O","True RSI","Open","High","Low","Close","MA Close","MA Open","RSI"); } else { FileWrite(file_handle, iTime(_Symbol,TF,i), iOpen(_Symbol,TF,i), iHigh(_Symbol,TF,i), iLow(_Symbol,TF,i), iClose(_Symbol,TF,i), ma_reading[i], ma_o_reading[i], rsi_reading[i], iOpen(_Symbol,TF,i) - iOpen(_Symbol,TF,(i + HORIZON)), iHigh(_Symbol,TF,i) - iHigh(_Symbol,TF,(i + HORIZON)), iLow(_Symbol,TF,i) - iLow(_Symbol,TF,(i + HORIZON)), iClose(_Symbol,TF,i) - iClose(_Symbol,TF,(i + HORIZON)), ma_reading[i] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_o_reading[(i + HORIZON)], rsi_reading[i] - rsi_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Analysieren der Daten in Python
Jetzt können wir mit der Analyse unserer Marktdaten beginnen, indem wir einige in Python verfügbare numerische Bibliotheken verwenden. Zu Beginn werden wir Pandas laden, um die Marktdaten einzulesen.
#Load our libraries import pandas as pd
Anschließend kennzeichnen wir die Aktionen, die unsere Trainingsstrategie unter den gegebenen Marktbedingungen durchgeführt hätte, und berechnen den Gewinn oder Verlust, den jede Aktion erzeugt hätte.
#Read in the data data = pd.read_csv("EURUSD Market Data As Series Multiple Strategy Analysis.csv") #The optimal holding period suggested by our MT5 Genetic optimizer HORIZON = 38 #Calculate the true market return data['Return'] = data['True Close'].shift(-HORIZON) - data['True Close'] #The action suggested by our first strategy, MA Cross data['Action 1'] = 0 #The action suggested by our second strategy, RSI Strategy data['Action 2'] = 0 #Buy conditions data.loc[data['True MA C'] > data['True MA O'],'Action 1'] = 1 data.loc[data['True RSI'] > 50,'Action 2'] = 1 #Sell conditions data.loc[data['True MA C'] < data['True MA O'],'Action 1'] = -1 data.loc[data['True RSI'] < 50,'Action 2'] = -1 #Perform a linear transformation of the true market return, using our trading stragies data['Return 1'] = data['Return'] * data['Action 1'] data['Return 2'] = data['Return'] * data['Action 2'] data = data.iloc[:-HORIZON,:]
Dies ist ein wesentlicher Schritt in jedem statistischen Modellierungs- und Handelsaufbau. Wir müssen sicherstellen, dass unser Modell nicht zu sehr an alle Daten angepasst ist; andernfalls wird jede Analyse oder Prüfung sinnlos, weil das Modell beeinträchtigt wurde.
#Drop our back test data _ = data.iloc[-((365 * 2 * 6)):,:] data = data.iloc[:-((365 * 2 * 6)),:]
Die Kennzeichnung unserer Ziele ist ein wichtiger Bestandteil jedes überwachten maschinellen Lernprojekts. Zur Veranschaulichung werden wir unsere Ziele kennzeichnen, um zu zeigen, ob die von Strategie 1 erzielte Rendite größer war als die von Strategie 2 oder umgekehrt. Unsere Zielvorgabe wird uns darüber informieren, ob Strategie 2 eine höhere Rendite als Strategie 1 erzielt hat. Zum Vergleich werden wir dies mit der Fähigkeit unseres Modells vergleichen, zukünftige Marktrenditen direkt vorherzusagen.
#Gether inputs X = data.iloc[:,1:15] #Both Strategies will earn equal reward data['Target 1'] = 0 data['Target 2'] = 0 #Strategy 1 is more profitable data.loc[data['Return 1'] > data['Return 2'],'Target 1'] = 1 #Strategy 2 is more profitable data.loc[data['Return 2'] > data['Return 1'],'Target 2'] = 1 #Classical Target data['Classical Target'] = 0 data.loc[data['Return'] > 0,'Classical Target'] = 1
Wir werden nun unsere Bibliotheken scikit-learn laden, um die numerischen Eigenschaften der gesammelten Marktdaten zu analysieren.
#Loading our scikit learn libraries from sklearn.model_selection import TimeSeriesSplit,cross_val_score from sklearn.linear_model import LinearRegression,LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.neural_network import MLPRegressor from sklearn.model_selection import RandomizedSearchCV
Wir beginnen mit der Erstellung von Zeitreihenvalidierungsobjekten mit fünf Teilen (splits) und stellen sicher, dass die Lücke dem von unserem genetischen Optimierer gefundenen optimalen Horizont entspricht. Als Nächstes berechnen wir die Spaltenmittelwerte und Standardabweichungen, um unseren Datensatz so zu standardisieren, dass er einen Mittelwert von Null und eine Standardabweichung von Eins hat.
#Prepare the data for time series modelling tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) Z1 = X.mean() Z2 = X.std() X = ((X-X.mean()) / X.std())
Wir werden nun die Genauigkeit der Vorhersage der von uns festgelegten neuen Ziele messen und diese mit der Genauigkeit der direkten Vorhersage des klassischen Ziels der künftigen Kursrenditen vergleichen. Mit den Kreuzvalidierungsobjekten von scikit-learn werden wir die Genauigkeit mit einem linearen Klassifikator bewerten. Diese Ergebnisse werden dann in einem Array gespeichert und ein Balkendiagramm erstellt. Wie zu beobachten ist, liegt unsere Genauigkeit beim klassischen Ziel bei knapp 50 %, während unsere Genauigkeit bei der Vorhersage, welche der beiden Strategien profitabler sein wird, bei etwa 90 % liegt und damit das klassische Ziel deutlich übertrifft.
#Measuring our accuracy on our new target res = [] model = LinearDiscriminantAnalysis() res.append(np.mean(np.abs(cross_val_score(model,X,data['Classical Target'],cv=tscv,scoring='accuracy')))) model = LinearDiscriminantAnalysis() res.append(np.mean(np.abs(cross_val_score(model,X,data['Target 1'],cv=tscv,scoring='accuracy')))) model = LinearDiscriminantAnalysis() res.append(np.mean(np.abs(cross_val_score(model,X,data['Target 2'],cv=tscv,scoring='accuracy',n_jobs=-1)))) sns.barplot(res,color='black') plt.xticks([0,1,2],['Classical Target','MA Cross Over Target','RSI Target']) plt.axhline(res[0],linestyle=':',color='red') plt.ylabel('5-Fold Percentage Accuracy %') plt.title('Outperforming The Classical Target of Direct Price Prediction')
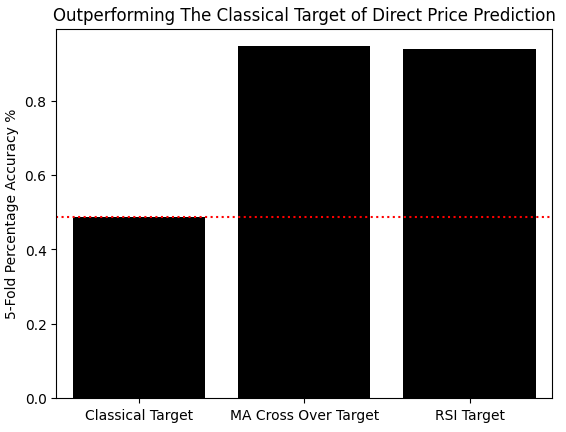
Abbildung 1: Wir machen Verbesserungen gegenüber der klassischen Aufgabe der direkten Preisvorhersage, indem wir die Beziehung zwischen unserer Strategie und dem Markt modellieren
Schließlich können wir die Bibliothek scikit-learn random search verwenden, um ein neuronales Netzwerk für unsere Marktdaten zu erstellen. Wir beginnen mit der Initialisierung unseres neuronalen Netzes mit Standardeinstellungen, die wir beibehalten wollen, wie z. B. die Shuffle- und Early-Stop-Parameter.
#Use random search to build a neural network for our market data #Initialize the model model = MLPRegressor(shuffle=False,early_stopping=False) distributions = {'solver':['lbfgs','adam','sgd'], 'hidden_layer_sizes':[(X.shape[1],2,10,20),(X.shape[1],30,50,10),(X.shape[1],14,14,14),(X.shape[1],5,20,2),(X.shape[1],1,2,3,4,5,6,10),(X.shape[1],1,14,14,1)], 'activation':['relu','identity','logistic','tanh'] } rscv = RandomizedSearchCV(model,distributions,n_jobs=-1,n_iter=50) rscv.fit(X,data.loc[:,['Target 1','Target 2']])Wir sind nun bereit, unser trainiertes neuronales Netz in das ONNX-Format zu exportieren. Um mit dem Export unseres neuronalen Netzes in unser nächstes Format zu beginnen, laden wir zunächst die ONNX-Bibliothek und dann die erforderlichen Konverter. Denken Sie daran, dass ONNX, die Abkürzung für Open Neural Network Exchange, ein Open-Source-Protokoll ist, das es uns ermöglicht, unsere Modelle für maschinelles Lernen auf einfache Weise zu erstellen und zu exportieren, und zwar modellunabhängig.
#Exporting our model to ONNX import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType initial_types = [('float_input',FloatTensorType([1,X.shape[1]]))] final_types = [('float_output',FloatTensorType([2,1]))] model = rscv.best_estimator_ model.fit(X,data.loc[:,['Target 1','Target 2']]) onnx_proto = convert_sklearn(model=model,initial_types=initial_types,final_types=final_types,target_opset=12) onnx.save(onnx_proto,'EURUSD NN MSA.onnx')
Um unser ONNX-Diagramm unseres neuronalen Netzes zu betrachten, importieren wir zunächst die Netron-Bibliothek und verwenden dann einfach die Funktion netron.start und übergeben den Pfad des ONNX-Modells, um es zu betrachten.
#Viewing our ONNX graph in netron import netron netron.start('../EURUSD NN MSA.onnx')
In der folgenden Abbildung 2 sind die Metaeigenschaften unseres ONNX-Modells dargestellt. Wir können sehen, dass unser ONNX-Modell 14 Eingänge und 2 Ausgänge hat, die beide Fließkommazahlen sind, sowie andere wichtige Metadaten wie den Produzenten und die ONNX-Version.
Abbildung 2: Visualisierung der mit unserem ONNX-Modell verbundenen Metadaten, um zu überprüfen, ob die richtigen Eingabe- und Ausgabegrößen angegeben wurden
Unser ONNX-Modell stellt Modelle des maschinellen Lernens als Graphen aus Rechenknoten und Kanten dar, die zeigen, wie Informationen von einem Rechenknoten zum nächsten weitergegeben werden. Auf diese Weise können alle Modelle des maschinellen Lernens in ein universelles Format übersetzt werden, nämlich in den ONNX-Graphen, der in Abbildung 3 dargestellt ist. Dieser Graph stellt unser neuronales Netz dar, das wir mit Hilfe der Zufallssuche der Sklearn-Bibliothek erstellt haben.

Abbildung 3: Visualisierung des Berechnungsgraphen, der unser tiefes neuronales Netz darstellt, mit der Netron-Bibliothek
Aufbau unseres Expertenberaters in MQL5
Der erste Schritt beim Aufbau unseres Expert Advisors besteht darin, das ONNX-Modell zu laden, das wir im vorherigen Schritt erstellt haben.
//+------------------------------------------------------------------+ //| MSA Test 1.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| ONNX Model | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD NN MSA.onnx" as uchar onnx_buffer[];
Die Spaltenmittelwerte und Standardabweichungen, die wir in Python für jede Spalte gemessen haben, werden in entsprechenden Arrays namens Z1 und Z2 gespeichert. Erinnern Sie sich daran, dass wir diese Werte zur Skalierung und Standardisierung unserer Eingaben verwenden werden, bevor wir Vorhersagen von unserem ONNX-Modell erhalten.
//+------------------------------------------------------------------+ //| ONNX Parameters | //+------------------------------------------------------------------+ double Z1[] = { 1.18932220e+00, 1.19077958e+00, 1.18786462e+00, 1.18931542e+00, 1.18994040e+00, 1.18994674e+00, 4.94395259e+01, -4.99204879e-04, -5.00701302e-04, -4.97575935e-04, -4.98995739e-04, -4.70848300e-04, -4.70289373e-04, -1.84697724e-02 }; double Z2[] = {1.09599015e-01, 1.09698934e-01, 1.09479324e-01, 1.09593123e-01, 1.09413744e-01, 1.09419007e-01, 1.00452009e+01, 1.31269558e-02, 1.31336302e-02, 1.31513465e-02, 1.31174740e-02, 6.88794916e-03, 6.89036979e-03, 1.28550006e+01 };
Wichtige Systemkonstanten werden definiert und während der gesamten Laufzeit unseres Programms beibehalten. Erinnern Sie sich, dass diese Konstanten in der vorangegangenen Diskussion mit Hilfe unseres genetischen Optimierers ausgewählt wurden.
//+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define MA_SHIFT 0 #define MA_TYPE MODE_EMA #define RSI_PRICE PRICE_CLOSE #define ONNX_INPUTS 14 #define ONNX_OUTPUTS 2 #define HORIZON 38
Wichtige Strategieparameter, wie die Periode des gleitenden Durchschnitts und die RSI-Periode, wurden mit Hilfe des genetischen Optimierers für uns ausgewählt, und wir werden sie während unseres Programms konstant halten.
//+------------------------------------------------------------------+ //| Strategy Parameters | //+------------------------------------------------------------------+ int MA_PERIOD = 100; //Moving Average Period int RSI_PERIOD = 24; //RSI Period ENUM_TIMEFRAMES STRATEGY_TIME_FRAME = PERIOD_H3; //Strategy Timeframe int HOLDING_PERIOD = 38; //Position Maturity Period
Wir benötigen eine ganze Reihe von Abhängigkeiten, damit unsere Anwendung vollständig ist. Einige Abhängigkeiten, wie z. B. die Handelsbibliothek, sollten für den Leser offensichtlich sein. Andere, wie z. B. die Strategien, die wir gemeinsam in unserer Artikelserie entwickelt haben, sollten Ihnen inzwischen ebenfalls bekannt sein, wenn Sie uns weiterverfolgt haben. Andernfalls sind die Strategien, die wir laden, für die Ausführung unserer Handelsanwendung erforderlich.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> #include <VolatilityDoctor\Strategies\OpenCloseMACrossover.mqh> #include <VolatilityDoctor\Strategies\RSIMidPoint.mqh>
Wir werden wichtige globale Variablen haben, die in unserem Programm verwendet werden, aber glücklicherweise benötigen wir nur eine Handvoll davon. Zum Beispiel benötigen wir globale Variablen für einige der nutzerdefinierten Klassen, die wir erstellt haben, wie die Handels- und Zeitklassen, die RSI-Strategie und die Crossover-Strategieklassen. Andere globale Variablen werden benötigt, um Messwerte von unserem ONNX-Modell zu erhalten und die Vorhersagen zu speichern, die es macht.
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ //--- Custom Types CTrade Trade; Time *TradeTime; TradeInfo *TradeInformation; RSIMidPoint *RSIMid; OpenCloseMACrossover *MACross; long onnx_model; vectorf onnx_output; //--- Our handlers for our indicators int ma_handle,ma_o_handle,rsi_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],rsi_reading[]; //--- System Types int position_timer;
Immer wenn unsere Anwendung zum ersten Mal initialisiert wird, erstellen wir neue Instanzen der benötigten dynamischen Objekte. Wir haben zum Beispiel eine Klasse, die sich mit der Zeitmessung und dem Handel von Informationen beschäftigt. Wir werden neue Instanzen dieser Klasse sowie neue Instanzen der entsprechenden Indikator-Handler, die wir benötigen, erstellen. Von dort aus erstellen wir unser ONNX-Modell aus dem gefüllten Puffer und überprüfen, ob das Modell korrekt geladen wurde.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Create dynamic instances of our custom types TradeTime = new Time(Symbol(),STRATEGY_TIME_FRAME); TradeInformation = new TradeInfo(Symbol(),STRATEGY_TIME_FRAME); MACross = new OpenCloseMACrossover(Symbol(),STRATEGY_TIME_FRAME,MA_PERIOD,MA_SHIFT,MA_TYPE); RSIMid = new RSIMidPoint(Symbol(),STRATEGY_TIME_FRAME,RSI_PERIOD,RSI_PRICE); onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); onnx_output = vectorf::Zeros(ONNX_OUTPUTS); //---Setup our technical indicators ma_handle = iMA(_Symbol,STRATEGY_TIME_FRAME,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,STRATEGY_TIME_FRAME,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); rsi_handle = iRSI(_Symbol,STRATEGY_TIME_FRAME,RSI_PERIOD,RSI_PRICE); if(onnx_model != INVALID_HANDLE) { Print("Preparing ONNX model"); ulong input_shape[] = {1,ONNX_INPUTS}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Print("Failed To Specify ONNX model input shape"); return(INIT_FAILED); } ulong output_shape[] = {ONNX_OUTPUTS,1}; if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Print("Failed To Specify ONNX model output shape"); return(INIT_FAILED); } } //--- Everything was fine Print("Successfully loaded all components for our Expert Advisor"); return(INIT_SUCCEEDED); } //--- End of OnInit Scope
Wenn unsere Anwendung nicht mehr verwendet wird, löschen wir den nicht mehr benötigten Speicher und geben diese Ressourcen für andere Anwendungen frei, um unsere Anwendung sicher zu deaktivieren.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Delete the dynamic objects delete TradeTime; delete TradeInformation; delete MACross; delete RSIMid; OnnxRelease(onnx_model); IndicatorRelease(ma_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(rsi_handle); } //--- End of Deinit Scope
Immer wenn neue Kursniveaus in der OnTick- und der OnExpertStart-Funktion empfangen werden, prüfen wir zunächst, ob sich eine neue Tageskerze vollständig gebildet hat, indem wir die Funktion new_candle innerhalb der ChangeTime-Klasse aufrufen. Wenn sich tatsächlich eine Kerze gebildet hat, werden wir die Parameter unserer Strategie aktualisieren, bevor wir nach einer Handelsmöglichkeit suchen. Wenn sich Gelegenheiten zum Handel ergeben, werden wir sie nutzen. Andernfalls warten wir, bis unsere Position fällig ist, bevor wir sie schließen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Check if a new daily candle has formed if(TradeTime.NewCandle()) { //--- Update strategy Update(); //--- If we have no open positions if(PositionsTotal() == 0) { //--- Reset the position timer position_timer = 0; //--- Check for a trading signal CheckSignal(); } //--- Otherwise else { //--- The position has reached maturity if(position_timer == HOLDING_PERIOD) Trade.PositionClose(Symbol()); //--- Otherwise keep holding else position_timer++; } } } //--- End of OnTick Scope
Unsere Aktualisierungsmethode berücksichtigt einige wichtige Parameter, wie den Prognosehorizont, den wir mit unserem genetischen Optimierer ausgewählt haben. Von dort aus werden die von uns verwendeten Strategien und die in unseren Puffern gespeicherten technischen Indikatorwerte aktualisiert.
//+------------------------------------------------------------------+ //| Update our technical indicators | //+------------------------------------------------------------------+ void Update(void) { int fetch = (HORIZON * 2); //--- Update the strategy RSIMid.Update(); MACross.Update(); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(rsi_handle,0,0,fetch,rsi_reading); ArraySetAsSeries(rsi_reading,true); } //--- End of Update Scope
Eine Vorhersage von unserem ONNX-Modell erhalten. Um eine Vorhersage aus dem ONNX-Modell zu erhalten, verwenden wir die ONNX-Run-Funktion. Vor dem Aufruf müssen wir jedoch zunächst die Eingabevariablen aktualisieren, die an das Modell übergeben werden, und dann diese Werte skalieren und standardisieren, indem wir den Mittelwert subtrahieren und durch die Standardabweichung dividieren.
//+------------------------------------------------------------------+ //| Get A Prediction from our ONNX model | //+------------------------------------------------------------------+ void OnnxPredict(void) { vectorf input_variables = { iOpen(_Symbol,STRATEGY_TIME_FRAME,0), iHigh(_Symbol,STRATEGY_TIME_FRAME,0), iLow(_Symbol,STRATEGY_TIME_FRAME,0), iClose(_Symbol,STRATEGY_TIME_FRAME,0), ma_reading[0], ma_o_reading[0], rsi_reading[0], iOpen(_Symbol,STRATEGY_TIME_FRAME,0) - iOpen(_Symbol,STRATEGY_TIME_FRAME,(0 + HORIZON)), iHigh(_Symbol,STRATEGY_TIME_FRAME,0) - iHigh(_Symbol,STRATEGY_TIME_FRAME,(0 + HORIZON)), iLow(_Symbol,STRATEGY_TIME_FRAME,0) - iLow(_Symbol,STRATEGY_TIME_FRAME,(0 + HORIZON)), iClose(_Symbol,STRATEGY_TIME_FRAME,0) - iClose(_Symbol,STRATEGY_TIME_FRAME,(0 + HORIZON)), ma_reading[0] - ma_reading[(0 + HORIZON)], ma_o_reading[0] - ma_o_reading[(0 + HORIZON)], rsi_reading[0] - rsi_reading[(0 + HORIZON)] }; for(int i = 0; i < ONNX_INPUTS;i++) { input_variables[i] = ((input_variables[i] - Z1[i])/ Z2[i]); } OnnxRun(onnx_model,ONNX_DEFAULT,input_variables,onnx_output); }
Die Prüfung auf ein Handelssignal mit unserer Crossover-Strategie beginnt damit, dass wir zunächst eine Vorhersage des ONNX-Modells erhalten. Das Modell wird vorhersagen, welche Strategie seiner Meinung nach am profitabelsten sein wird. Von dort aus überprüfen wir die jeweilige Strategie, um zu sehen, ob ein entsprechendes Einstiegssignal verfügbar ist. Wir geben nur dann ein Signal ein, wenn das Modell erwartet, dass die Strategie profitabel ist, und die Strategie uns eine gute Handelsmöglichkeit bietet.
//+------------------------------------------------------------------+ //| Check for a trading signal using our cross-over strategy | //+------------------------------------------------------------------+ void CheckSignal(void) { OnnxPredict(); //--- MA Strategy is profitable if((onnx_output[0] > 0.5) && (onnx_output[1] < 0.5)) { //--- Long positions when the close moving average is above the open if(MACross.BuySignal()) { Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),0,0,""); return; } //--- Otherwise short else if(MACross.SellSignal()) { Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),0,0,""); return; } } //--- RSI strategy is profitable else if((onnx_output[0] < 0.5) && (onnx_output[1] > 0.5)) { if(RSIMid.BuySignal()) { Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),0,0,""); return; } //--- Otherwise short else if(MACross.SellSignal()) { Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),0,0,""); return; } } } //--- End of CheckSignal Scope
Gegen Ende unseres Systems werden wir alle Systemkonstanten, die wir zu Beginn unserer Anwendung definiert haben, zurücksetzen.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef MA_SHIFT #undef RSI_PRICE #undef MA_TYPE #undef ONNX_INPUTS #undef ONNX_OUTPUTS #undef HORIZON //+------------------------------------------------------------------+
Die Auswahl der geeigneten Backtesting-Tage ist ganz einfach. Erinnern Sie sich, dass wir unsere neue Anwendung während der Vorwärts-Testphase testen wollen, die wir in unserem vorherigen Test verwendet haben. Daher wurden die Prüfungstermine entsprechend angepasst.
Abbildung 4: Auswahl der Backtest-Tage, sodass sie mit dem zuvor durchgeführten Vorwärtstest übereinstimmen
Wie immer wollen wir möglichst realistische Einstellungen verwenden, daher wählen wir die Einstellung Zufallsverzögerung.
Abbildung 5: Auswahl unserer Modellierungsbedingungen auf der Grundlage von „Random Delay“ für möglichst realistische Einstellungen
Zu meiner Überraschung haben die neuen Einstellungen für unsere Anwendung – einschließlich statistischer Modelle – unsere Leistung erheblich verschlechtert. Dies ist normalerweise ein deutlicher Hinweis darauf, dass in unserem Plan etwas schief gelaufen ist.
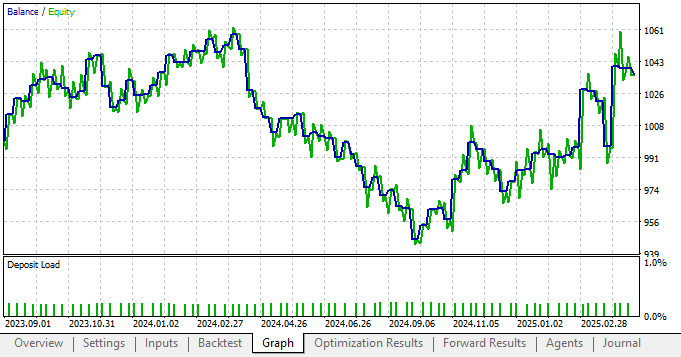
Abbildung 6: Die neue Kapitalkurve, die wir erstellt haben, ist in einem schlechten Zustand, wenn man sie mit unserer Leistung ohne statistische Modellierung vergleicht
Wenn wir uns die detaillierte Analyse der Performance unserer Anwendung genauer ansehen, sehen wir, dass der Gesamtnettogewinn zusammen mit der Sharpe Ratio gesunken ist, was kein gutes Zeichen ist. Dies zeigt, dass unsere Anwendung nicht den beabsichtigten Nutzen aus den von uns gewählten statistischen Modellierungswerkzeugen zieht.
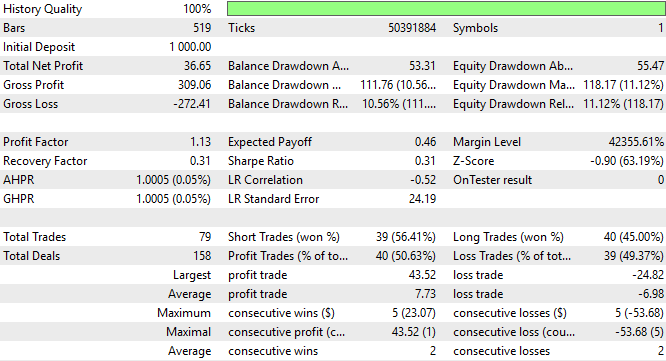
Abbildung 7: Eine detaillierte Analyse der Leistung unserer neuen Handelsstrategie, die sich auf statistische Modelle stützt
Überarbeitung unserer Marktdaten in Python
Nach einer weiteren Überarbeitung unserer Marktdaten in Python wollte ich mir genauer ansehen, was die Fehlerursache sein könnte. Ich begann also mit dem Import der Standardbibliotheken, die wir zur Visualisierung von Marktdaten verwenden. Ich habe dann die kumulierte Summe einiger der von den beiden Strategien erzielten Renditen aufgezeichnet, und sofort wurde das Problem deutlich.import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Wie aus der nachstehenden Grafik hervorgeht, weisen unsere beiden Strategien bemerkenswert ähnliche Merkmale und Steigungen auf. Die beiden Strategien tendieren dazu, im Gleichklang zu steigen und zu fallen, fast so, als ob wir eine einzige Strategie verfolgen würden.
fig , axs = plt.subplots(2,1,sharex=True) fig.suptitle('Visualizing The Individual Cumulative Return of our 2 Strategies') sns.lineplot(data['Return 1'].cumsum(),ax=axs[0],color='black') sns.lineplot(data['Return 2'].cumsum(),ax=axs[1],color='black')
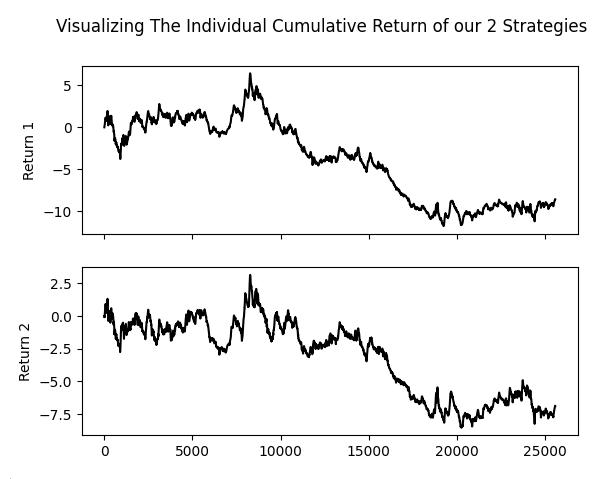
Abbildung 8: Unser Genetischer Optimierer scheint hoch korrelierte Strategien ausgewählt und ihnen die größten Stimmgewichte zugewiesen zu haben
Wenn wir das rollierende Risiko in den von unseren Strategien erzielten Renditen darstellen, sehen wir einen weiteren Grund zur Sorge. Das Risikoprofil unserer beiden Strategien unterscheidet sich kaum von dem des Marktes selbst. Auch hier scheint es, dass wir einfach dieselbe Strategie anwenden. Es ist schwer, zwischen Strategie eins und Strategie zwei zu unterscheiden, wenn ich die Spalten unseres Diagramms nicht beschriftet hätte.
fig , axs = plt.subplots(3,1,sharex=True) fig.suptitle('Visualizing The Risk In Our 2 Strategies') sns.lineplot(data['Return'].rolling(window=HORIZON).var(),ax=axs[0],color='black') axs[0].axhline(data['Return'].var(),color='red',linestyle=':') sns.lineplot(data['Return 1'].rolling(window=HORIZON).var(),ax=axs[1],color='black') axs[1].axhline(data['Return 1'].var(),color='red',linestyle=':') sns.lineplot(data['Return 2'].rolling(window=HORIZON).var(),ax=axs[2],color='black') axs[2].axhline(data['Return 2'].var(),color='red',linestyle=':')
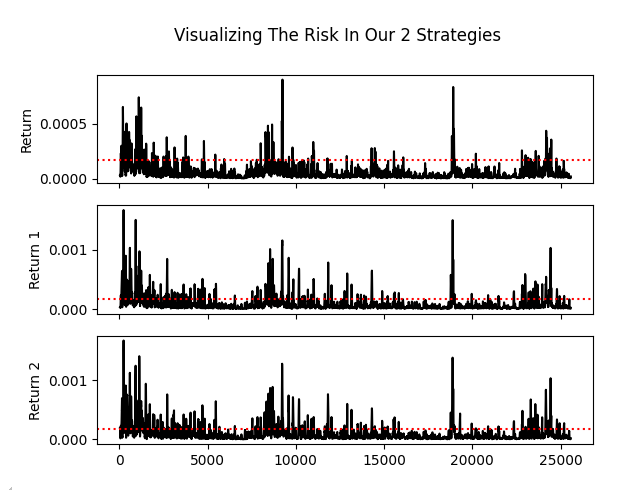
Abbildung 9: Beide Strategien sind in ihren Risiko- und Ertragsniveaus fast identisch, was die Idee hinter der Analyse mehrerer Strategien untergräbt
Der letzte Sargnagel ist die Berechnung der Korrelationsmatrix, die sich aus den drei Renditen ergibt: der Marktrendite, der Rendite der gleitenden Durchschnitts-Crossover-Strategie und der Rendite unserer RSI-Strategie. Es ist deutlich zu erkennen, dass der gleitende Durchschnitts-Crossover und die RSI-Strategie eine Korrelation von etwa 0,75 aufweisen, was sehr stark ist. Dies war der letzte Vorschlag, der mich davon überzeugte, dass der genetische Optimierer die Stimmengewichtung nicht unbedingt so anpasst, dass die Rentabilität maximiert wird. Vielmehr hat es den Anschein, dass es die Gewichte so einstellt, dass wirklich korrelierte Strategien isoliert werden – denn das macht seine Arbeit einfacher.
plt.title('Correlation Between Market Return And Strategy Returns')
sns.heatmap(data.loc[:,['Return','Return 1','Return 2']].corr(),annot=True)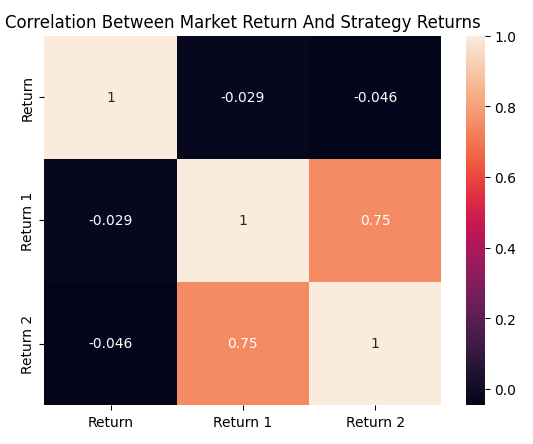
Abbildung 10: Die Korrelationsmatrix, die sich aus unseren Handelsstrategien und dem EURUSD-Markt ergibt
Verbesserungen vornehmen
Mit dem Wissen, das wir jetzt haben, können wir erneut versuchen, unsere Anwendung zu verbessern. Zunächst kehren wir zu der früheren Version unserer Handelsstrategie zurück, die alle drei Strategien enthielt, die wir verwenden wollen.
Abbildung 11: Auswahl der Backtest-Tage für unser Optimierungsverfahren
Wie immer werden wir für unseren Backtest zufällige Verzögerungseinstellungen verwenden.
Abbildung 12: Stellen Sie sicher, dass Sie die Option „Zufallsverzögerung“ verwenden, wenn Sie beabsichtigen, dem Geschehen zu folgen.
Im Gegensatz zu früheren Tests setzen wir jetzt jedoch alle Stimmgewichte auf 1, um sicherzustellen, dass der genetische Optimierer nur Änderungen vornehmen kann, die die Gesamtrentabilität der Strategie erhöhen. Darüber hinaus wollen wir den Optimierer dazu zwingen, alle drei Strategien zu verwenden und nicht nur die korrelierten herauszupicken, da dies unserem Ziel zuwiderläuft.
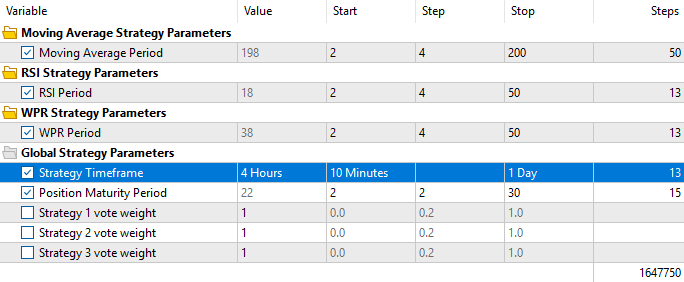
Abbildung 13: Denken Sie daran, dass wir dieses Mal alle Stimmgewichte auf 1 setzen wollen, weil wir vermuten, dass der Genetische Optimierer uns überlistet
Bei der Überprüfung der Optimierungsergebnisse können wir bereits Verbesserungen gegenüber den anfänglichen Vektoren, die wir durchgeführt haben, feststellen. Anfänglich beobachteten wir bei allen drei Strategien Rentabilitätsniveaus zwischen 40 und 50 Dollar. Aber wir sehen jetzt eine deutliche Verbesserung der Rentabilität.
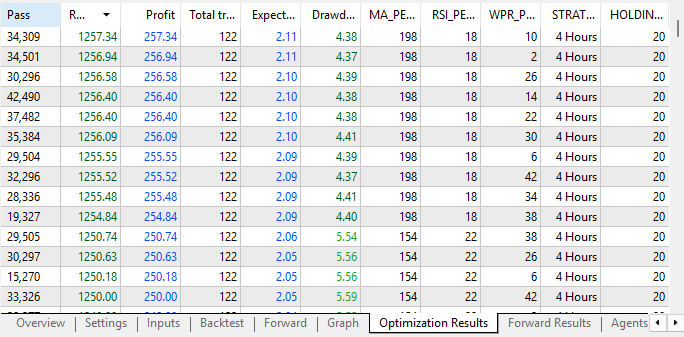
Abbildung 14: Unsere Optimierungsergebnisse haben sich gegenüber der letzten Iteration erheblich verbessert
Wenn wir die Ergebnisse des Forward-Tests betrachten, sehen wir außerdem wieder erhöhte Gewinnraten. Unsere Tests sind jetzt sowohl im Rückwärts- als auch im Vorwärtstest profitabel, was ein starkes Zeichen für die Stabilität der Konfiguration ist. Am wichtigsten ist, dass unser genetischer Optimierer nun in der Lage ist, uns Stapel von Strategiekonfigurationen zu liefern, die in beiden Tests profitabel waren. Dies waren die Ergebnisse, die wir zuvor nicht erzielen konnten, als wir dem Optimierer erlaubten, die Gewichte nach Belieben zu ändern. Dies bestärkt uns in der Annahme, dass unsere Anwendung in dieser Konfiguration stabil ist.
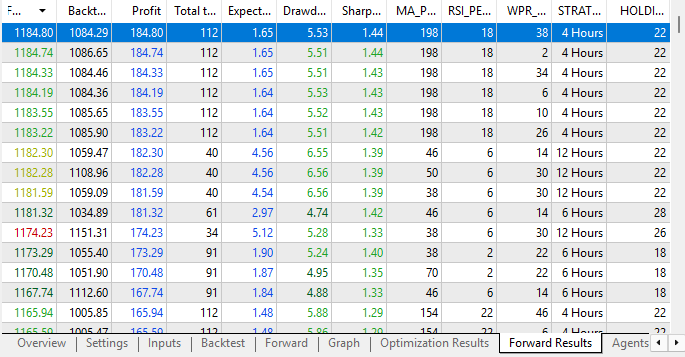
Abbildung 15: Unsere Forward-Ergebnisse zeigen nun deutliche Anzeichen von Stabilität und Rentabilität
Wenn wir schließlich einen Backtest mit den profitabelsten Einstellungen durchführen, die wir aus den Vorwärtsergebnissen ermittelt haben, können wir deutlich sehen, dass unsere neuen Parametereinstellungen sowohl im Backtest als auch im Vorwärtstest profitabel sind, und zwar mit einem Aufwärtstrend – genau das, was wir sehen wollen.
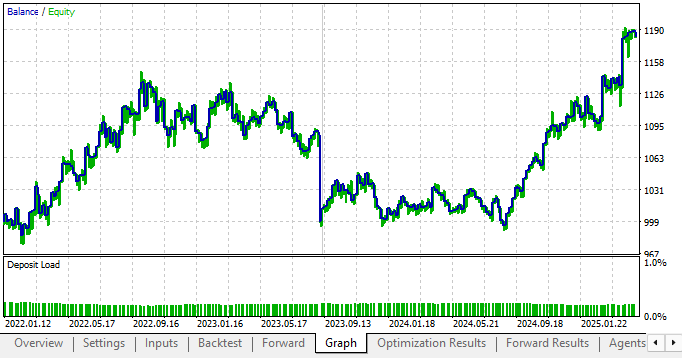
Abbildung 16: Die Kapitalkurve, die sich aus unserer neuen Handelsstrategie mit festen Stimmen ergibt, ist wesentlich profitabler
Schlussfolgerung
Aus dieser Diskussion haben wir einige wertvolle Lehren gezogen. Erstens haben wir gesehen, dass die Herausforderung des Belohnungshackings allgegenwärtig ist und auftreten kann, ob wir uns dessen bewusst sind oder nicht. Unsere KI-Tools – wie z. B. genetische Optimierer – sind schnell und intelligent, manchmal sogar intelligenter als wir. Wir müssen immer wachsam sein, um sicherzustellen, dass diese Tools uns nicht überlisten, indem sie ungültige Lösungen generieren, die lediglich die von uns festgelegten Erfolgsbedingungen erfüllen.
Durch sorgfältige Prüfung der Renditen der vom Optimierer ausgewählten Strategien haben wir gelernt, dass wir die Auswahl korrelierter Strategien vermeiden müssen, da dies den Zweck einer Multi-Strategie-Analyse zunichte macht.
Der Leser sollte beachten, dass genetische Optimierer nur durch die Zeit eingeschränkt werden, die wir bereit sind zu investieren. Andernfalls liefert unsere Diskussion nicht notwendigerweise den Beweis, dass der genetische Optimierer des MetaTrader 5 immer die ihm zugewiesenen Belohnungen hacken wird. Da wir nur eine kleine Anzahl von Strategien ausgewählt und diese Optimierung nur einmal durchgeführt haben, besteht immer die Möglichkeit, dass eine Wiederholung des Prozesses andere Ergebnisse liefern würde.
Vielmehr ist dies ein Beweis dafür, dass ich, der Autor, bei der Formulierung des Problems für den genetischen Optimierer vielleicht nicht sorgfältig genug vorgegangen bin. Ein besserer Ansatz wäre es gewesen, den Optimierer zunächst zu zwingen, alle verfügbaren Strategien zu verwenden, und dann die Abstimmungsgewichte mit mehr Bedacht anzupassen.
Am wichtigsten ist, dass wir diese Übung mit dem Wissen abschließen, dass wir in unserem nächsten Artikel sorgfältig prüfen müssen, wie wir die Rentabilität übertreffen können, die mit einheitlichen Gewichten von 1 erzielt wird. Die Leistung, die wir mit diesen einheitlichen Gewichten erzielt haben, dient als solider Benchmark, den wir in unserer nächsten Diskussion mit den statistischen Modellen, die wir ursprünglich in diesem Artikel anwenden wollten, übertreffen wollen.
| Dateiname | Beschreibung der Datei |
|---|---|
| Fetch Data MSA.mq5 | Das MQL5-Skript, das wir verwendet haben, um Daten über die 2 von unserem genetischen Optimierer ausgewählten Strategien abzurufen. |
| MSA Test 2.1.mq5 | Der Expert Advisor, den wir unter Verwendung der 2 ausgewählten Strategien und unseres ONNX-Modells erstellt haben. |
| Analyzing Multiple Strategies I.ipynb | Das Jupyter Notebook, das wir gemeinsam geschrieben haben, um die Marktdaten zu analysieren, die wir mit unserem MQL5-Skript abgerufen haben. |
| EURUSD NN MSA.onnx | Unser tiefes neuronales Netzwerk, das wir mit der sklearn random-search-Bibliothek erstellt haben. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/18847
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.