
Neuronale Netze sind einfach (Teil 59): Dichotomy of Control (DoC)

Einführung
Die Finanzmarktbranche ist ein komplexes und vielschichtiges Umfeld. Jedes Ereignis und jede Handlung hat ihre Wurzeln in wirtschaftlichen Grundprozessen. Die Gründe für bestimmte Ereignisse sind in den Nachrichten, geopolitischen Ereignissen, verschiedenen technischen Aspekten und vielen anderen Faktoren zu finden. Oftmals stellen wir solche Abhängigkeiten erst im Nachhinein fest. Bei der Analyse der Marktsituation beobachten wir nur einen kleinen Teil dieser Faktoren. Dies macht die Finanzmärkte im Allgemeinen zu einem recht schwierig zu analysierenden Umfeld. Dennoch möchten wir einige der wichtigsten Tools hervorheben, mit denen sich die wichtigsten Trends erkennen lassen. Andere Faktoren werden der Umweltstochastik zugeschrieben.
In einem derart komplexen Umfeld stellt das Verstärkungslernen ein leistungsfähiges Instrument zur Entwicklung von Strategien auf den Finanzmärkten dar. Bestehende Methoden, wie z. B. Decision Transformer, sind jedoch in hochgradig stochastischen Umgebungen möglicherweise nicht anpassungsfähig genug. Dies haben wir im praktischen Teil des vorigen Artikels beobachtet.
Wie Sie sich vielleicht erinnern, modelliert Decision Transformer im Gegensatz zu traditionellen Methoden Handlungssequenzen im Kontext eines autoregressiven Modells der gewünschten Belohnungen. Während des Trainings des Modells wird eine Beziehung zwischen der Abfolge von Zuständen, Aktionen, gewünschten Belohnungen und dem tatsächlichen Ergebnis in der Umgebung hergestellt. Eine große Anzahl von Zufallsfaktoren kann jedoch zu einer Diskrepanz zwischen der trainierten Strategie und dem gewünschten zukünftigen Ergebnis führen.
Viele Methoden des Verstärkungslernens und andere stehen vor einem ähnlichen Problem. Im Oktober 2022 stellte das Google-Team die Methode Dichotomy of Control als eine der Möglichkeiten zur Lösung dieses Problems vor.
1. Grundlagen der DoC-Methode
Die „Dichotomy of Control“ (DoC, Dichotomie der Kontrolle) ist die logische Grundlage des Stoizismus. Es setzt voraus, dass wir verstehen, dass alles, was um uns herum existiert, in zwei Teile geteilt werden kann. Die erste unterliegt uns und ist vollständig unter unserer Kontrolle. Auf den zweiten haben wir keinen Einfluss, und die Ereignisse werden unabhängig von unserem Handeln eintreten.
Wir arbeiten mit dem ersten Bereich, während wir den zweiten als selbstverständlich betrachten.
Die Autoren der Methode „Dichotomy of Control“ haben ähnliche Postulate in ihren Algorithmus eingebaut. Die DoC ermöglicht es uns zu unterscheiden, was unter der Kontrolle der Strategie steht (Handlungspolitik) und was sich ihrer Kontrolle entzieht (Umweltstochastik).
Doch bevor wir uns der Methode zuwenden, möchte ich daran erinnern, wie wir die Trajektorie in DT dargestellt haben.
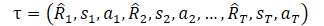
Hier stellt R1 („Zurück auf Los“) unseren Wunsch dar und steht in keinem Zusammenhang mit dem Ausgangszustand S0. Unser trainiertes Modell wählt die Aktion aus, die in der Trainingsmenge das gewünschte Ergebnis erzielt hat. Die Wahrscheinlichkeit, die gewünschte Belohnung im aktuellen Zustand zu erhalten, kann jedoch so gering sein, dass die Handlungen des Agenten alles andere als optimal sind.
Lassen Sie uns nun die Welt mit offenen Augen betrachten. In diesem Zusammenhang ist „Zurück auf Los“ (return to go) eine Anweisung an den Agenten, eine Verhaltensstrategie zu wählen. Meinen Sie nicht, dass dies einer Fähigkeit in hierarchischen Modellen oder einer Zielbezeichnung in GCRL ähnlich ist? Wahrscheinlich haben sich die Autoren der DoC-Methode ähnliche Gedanken gemacht und vorgeschlagen, eine Art verborgenen Zustand z(τ) zu verwenden. Aber wie Sie wissen, ändert das Ersetzen von Begriffen nichts an der Essenz. Es wird ein Trainingsmodell eingeführt, um den latenten Zustand z(τ) darzustellen.
Die wichtigste Beobachtung der Autoren der Methode ist, dass z keine Informationen im Zusammenhang mit der Umweltstochastik enthalten sollte. Sie sollte keine Informationen über die Zukunft Rt und St+1 enthalten, die zum Zeitpunkt der Vorgeschichte unbekannt sind. Dementsprechend wird dem Ziel eine bedingte Einschränkung der gegenseitigen Information zwischen z und jedem Paar Rt und St+1 in der Zukunft hinzugefügt. Wir werden Methoden des Kontrasttrainings verwenden, um diese Bedingung der gegenseitigen Information zu erfüllen.
Als Nächstes führen wir die bedingte Verteilung ω(rt|τ0:t-1,st,at) ein, die durch die Energiefunktion f parametrisiert wird.
Kombiniert man dies mit den Lagrange-Verhältnissen, kann man π und z(τ) trainieren, indem man das Endziel von DoC minimiert:
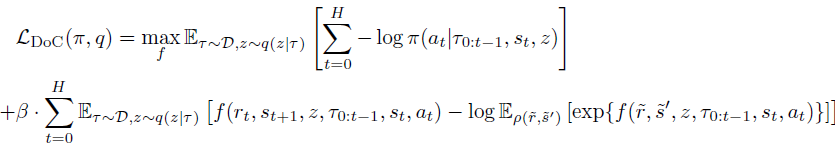
Bei Anwendung auf die Decision-Transformer-Methode erfordert die trainierte Politik DoC eine geeignete z-Bedingung. Die Autoren der Methode schlagen vor, die gewünschten z zu wählen, die mit einer hohen erwarteten Belohnung verbunden sind:
- Wähle eine große Anzahl möglicher z-Werte aus;
- Schätze die erwartete Belohnung für jeden dieser Werte von z;
- Wähle z mit der höchsten erwarteten Belohnung und übergib diese der Politik.
Um ein solches Verfahren während der Operationsphase zu gewährleisten, werden zwei zusätzliche Komponenten in die Methodenformulierung aufgenommen. Zunächst wird aus der vorherigen Verteilung p(z|s0) eine große Anzahl von z-Werten ausgewählt. Zweitens die Wertfunktion V(z), die zur Einstufung potenzieller z-Werte verwendet wird. Diese Komponenten werden trainiert, indem das folgende Ziel minimiert wird:
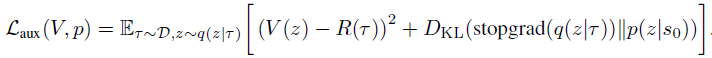
Man beachte die Verwendung des Stop-Gradienten für q(z|τ) beim Training von p, um die q-Regularisierung relativ zur vorherigen Verteilung zu vermeiden.
Der Artikel „Dichotomy of Control: Separating What You Can Control from What You Cannot“ enthält eine Reihe von Beispielen, die die deutliche Überlegenheit der vorgeschlagenen Methode in verschiedenen stochastischen Umgebungen zeigen.
Dies ist ein sehr interessanter Punkt, und ich schlage vor, in der Praxis zu testen, ob sich unsere Probleme mit diesem Ansatz lösen lassen.
2. Implementierung mit MQL5
Im praktischen Teil des Artikels werden wir die Implementierung des Dichotomie der Kontrolle Algorithmus mit MQL5 betrachten. Ich möchte Sie gleich darauf aufmerksam machen, dass es sich bei der fraglichen Umsetzung um eine persönliche Interpretation der vorgeschlagenen Methode handelt. In manchen Momenten wird sie ziemlich weit von der ursprünglichen Lösung entfernt sein.
Zunächst einmal ist diese Implementierung eine logische Fortsetzung der Programme aus dem vorherigen Artikel. Wir implementieren die vorgeschlagenen Mechanismen in den zuvor erstellten DT-Code und versuchen so, die Leistung des Modells zu optimieren und seine Effizienz zu steigern.
Außerdem werden wir versuchen, den DoC-Algorithmus ein wenig zu vereinfachen, ohne die grundlegenden Ideen zu vernachlässigen.
Wie bereits erwähnt, führen die Autoren der Methode einen latenten Zustand anstelle der Rückkehr zum Ziel ein. Während des Vorgangs wird ein bestimmtes Paket solcher latenter Zustände aus der vorherigen Verteilung p(z|s0) entnommen. Diese latenten Zustände werden anschließend mit Hilfe der Wertfunktion V(z) geschätzt. In der Praxis bedeutet dies, dass wir die ähnlichsten Zustände aus der Trainingsmenge extrahieren und die latente Repräsentation mit der höchsten erwarteten Belohnung auswählen. In Übereinstimmung mit den Ideen der Kontrolle der Dichotomie berücksichtigen wir nicht nur den absoluten Wert der Belohnung, sondern auch die Wahrscheinlichkeit, sie zu erhalten.
Natürlich werden wir nicht jedes Mal die gesamte Trainingsmenge durchgehen. Stattdessen werden wir vortrainierte Modelle verwenden, die die entsprechenden Merkmale aus dem Trainingssatz annähern. Aber in jedem Fall ist es eine recht arbeitsintensive Aufgabe, eine große Anzahl latenter Repräsentationen zu erfassen und dann zu schätzen. Können wir es irgendwie vereinfachen?
Schauen wir uns das Wesen dieser Einheiten an. Die latente Repräsentation z im Kontext des Decision Transformer ist die erwartete Belohnung. Die Wertfunktion V(z) kann also ein Spiegelbild des latenten Zustands z selbst sein. Wir könnten darüber nachdenken, die Wertfunktion als Klasse auszuschließen und die latenten Zustände direkt miteinander zu vergleichen, aber wir werden einen solchen Schritt nicht tun.
Wenn man weiter darüber nachdenkt, kann man die vorherige Verteilung p(z|s0) als eine probabilistische Verteilung der Verwendung einer bestimmten latenten Repräsentation in einem bestimmten Umweltzustand darstellen. Erinnern wir uns an die vollständig parametrisierte Quantilsfunktion (FQF). Sie ermöglicht die Kombination von Wahrscheinlichkeitsrechnungen und quantitativen Verteilungen. Dies werden wir im Modell zur Erzeugung latenter Repräsentationen verwenden.
Diese Lösung ermöglicht es uns, die vorherige Verteilung und die Kostenfunktion zu kombinieren. Außerdem können wir auf diese Weise vermeiden, eine Reihe von latenten Zuständen zu stichprobenartig zu erfassen und dann zu schätzen.
Dasselbe tun wir mit der bedingten Verteilung ω(rt|τ0:t-1,st,at), die durch die Energiefunktion f parametrisiert wird.
Beachten Sie, dass wir in beiden Fällen eine latente Repräsentation erzeugen. Um Ressourcen zu sparen, werden wir zwei Modelle erstellen und eines in beiden Fällen verwenden. Dabei ist zu beachten, dass ω(rt|τ0:t-1,st,at) von der Trajektorie abhängt. Daher sollten wir bei der Konstruktion eines Modells dessen autoregressiven Charakter berücksichtigen, ähnlich wie beim DT-Actor-Modell.
Die Architektur der beiden Modelle wird in der Methode CreateDescriptions beschrieben. In den Methodenparametern übergeben wir Zeiger auf zwei dynamische Arrays zur Beschreibung der Modellarchitekturen. Die Unterschiede in den Modellarchitekturen werden nicht signifikant sein. Aber es gibt sie noch. Aus diesem Grund schaffen wir zwei getrennte Architekturen und nicht eine gemeinsame. Zunächst erstellen wir die Architektur des Akteursmodells. Wie im vorangegangenen Artikel enthält die Quelldatenschicht nur variable Komponenten des Umweltzustands (eine Balkenangabe).
bool CreateDescriptions(CArrayObj *agent, CArrayObj *rtg) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (NRewards + BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Als Nächstes folgt die Stapel-Normalisierungsschicht, die die Rohdaten vorverarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Die normalisierten Daten werden durch die Einbettungsschicht geleitet und dem Stapel hinzugefügt.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NActions,NRewards}; ArrayCopy(descr.windows,temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Der Stapel enthält Dateneinbettungen für den gesamten analysierten Zeitraum. Wir passieren sie durch einen Block von mehrköpfigen spärlichen Aufmerksamkeiten (sparse attention).
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count*5; descr.window = prev_wout; descr.step = 4; descr.window_out = 32; descr.layers = 8; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Nach dem Aufmerksamkeitsblock reduzieren wir die Dimensionalität der Daten mithilfe einer Faltungsschicht.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; }
Anschließend werden die Daten durch einen Entscheidungsblock geleitet, der aus drei vollständig verbundenen Schichten besteht.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Am Ausgang des Modells verwenden wir die latente VAE-Schicht, um die Politik des Agenten stochastisch zu machen.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Im Folgenden wird die Architektur des latenten Repräsentationsmodells beschrieben. Wie bereits erwähnt, ist die Architektur des Modells dem vorherigen Modell sehr ähnlich. Es analysiert jedoch eine kleinere Datenmenge. Wie aus der Beschreibung im theoretischen Teil hervorgeht, erzeugt die bedingte Verteilungsfunktion ω(rt|τ0:t-1,st,at) eine latente Repräsentation, die auf dem aktuellen Zustand, den Aktionen des Agenten und der vorherigen Trajektorie basiert. Der daraus resultierende latente Zustand wird anschließend dem Agenten zur Eingabe vorgelegt. Wir werden um die Größe des latenten Zustands weniger Daten an den Input des zweiten Modells liefern.
//--- RTG if(!rtg) { rtg = new CArrayObj(); if(!rtg) return false; } //--- rtg.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Die rohen Quelldaten werden in der Batch-Normalisierungsschicht ebenfalls einer Erstverarbeitung unterzogen.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Als Nächstes folgt die Dateneinbettung. Auch hier ist eine Veränderung in der Struktur der Quelldaten zu beobachten.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NActions}; ArrayCopy(descr.windows,temp); } prev_wout = descr.window_out = EmbeddingSize; if(!rtg.Add(descr)) { delete descr; return false; }
Im Folgenden wiederholen wir die Strukturen des spärlichen Aufmerksamkeitsblocks. Achten Sie darauf, dass sich die Anzahl der analysierten Elemente in der Sequenz verringert. Während der Agent 5 Entitäten auf jedem Balken analysierte, sind es in diesem Modell nur 4. Um die manuelle Kontrolle der Anzahl der Elemente auf jedem Balken zu diesem Zeitpunkt zu vermeiden, können wir im vorherigen Schritt die Größe der Fensteranordnung der Quelldaten der Einbettungsebene in einer separaten Variablen festlegen.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count=descr.count = prev_count*4; descr.window = prev_wout; descr.step = 4; descr.window_out = 32; descr.layers = 8; descr.probability = Sparse; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Wie im vorherigen Modell reduzieren wir nach der spärlichen Aufmerksamkeitsschicht die Dimensionalität der analysierten Daten mithilfe einer Faltungsschicht. Dann übermitteln wir die empfangenen Daten an den Entscheidungsblock.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Am Ausgang des Entscheidungsblocks verwenden wir nun eine Schicht mit einer vollständig parametrisierten Quantilfunktion, wie oben beschrieben.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NRewards; descr.window_out = 32; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- return true; }
Nach der Beschreibung der Architektur der Modelle gehen wir zur Arbeit am EA für die Interaktion mit der Umgebung und der primären Datenerfassung für das Training der Modelle „\DoC\Research.mq5“ über. Die Vorteile der Dichotomie-Kontrollmethode machen sich bereits bei der Erfassung von Trainingsdaten bemerkbar. Während wir früher in ähnlichen EAs nur das Agentenmodell verwendet haben und andere Modelle nur in der Trainingsphase verbunden wurden, werden wir jetzt beide Modelle in allen Phasen verwenden, angefangen bei der Sammlung von Primärdaten bis hin zum Testen des trainierten Modells. Schließlich ist der latente Zustand, der durch das zweite Modell erzeugt wird, Teil der Ausgangsdaten unseres Agenten.
Wir werden hier nicht den gesamten Code des EA im Detail betrachten. Die meisten Methoden wurden unverändert aus früheren Artikeln übernommen. Betrachten wir nur die OnTick-Tick-Verarbeitungsmethode, in die der Hauptdatenerfassungsprozess eingebettet ist.
Zu Beginn der Methode überprüfen wir wie üblich das Eintreten des Ereignisses der Eröffnung eines neuen Balkens und aktualisieren gegebenenfalls die historischen Daten der Preisbewegung und der analysierten Indikatoren.
Ich möchte Sie daran erinnern, dass alle Operationen unseres EAs nur bei der Eröffnung eines neuen Balkens durchgeführt werden. Der Algorithmus unserer Modelle kontrolliert nicht die Veränderung der einzelnen Ticks. Alle trainierten Modelle arbeiten mit historischen Daten des Zeitrahmens H1. Die Wahl des Zeitrahmens ist jedoch eine rein subjektive Entscheidung und wird nicht durch Modellarchitekturen eingeschränkt. Wir müssen nur die Anforderung erfüllen, dass die Ausbildung und der Operation der Modelle im gleichen Zeitrahmen und mit dem gleichen Instrument erfolgen. Bevor Modelle verwendet werden, die zuvor für einen anderen Zeitrahmen und/oder ein anderes Instrument trainiert wurden, sollten sie zusätzlich für den Zielzeitrahmen und das Zielfinanzinstrument trainiert werden.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Als Nächstes wird der Quelldatenpuffer vorbereitet. Zunächst legen wir die historischen Daten der Preisbewegung des Symbols und die Parameter der analysierten Indikatoren fest.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Als Nächstes fügen wir Informationen über den aktuellen Kontostand und die offenen Positionen hinzu.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Hier fügen wir auch einen Zeitstempel hinzu.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
Und die letzte Aktion des Agenten, die uns zum aktuellen Zustand der Umgebung gebracht hat. Bei der Verarbeitung des ersten Balkens wird dieser Vektor mit Nullwerten gefüllt.
//--- Prev action
bState.AddArray(AgentResult);
Als Nächstes sollten wir dem Agenten eine Zielbezeichnung in Form von „Zurück auf Los“ (Return to go) hinzufügen. Im Rahmen des DoC-Algorithmus müssen wir jedoch noch den latenten Zustand erzeugen. Die gesammelten Daten reichen jedoch aus, damit das Modell zur Erzeugung latenter Zustände funktioniert, und wir führen einen Vorwärtsdurchlauf durch das Modell durch.
//--- Return to go if(!RTG.feedForward(GetPointer(bState))) return;
Nach erfolgreicher Durchführung eines Vorwärtsdurchlaufs durch das Modell laden wir die resultierende latente Repräsentation und fügen sie dem Quelldatenpuffer hinzu.
RTG.getResults(Result); bState.AddArray(Result);
An diesem Punkt haben wir ein komplettes Paket von Eingabedaten für unser Agentenmodell generiert, und wir können die Forward-Pass-Methode aufrufen, um optimale Aktionen in Übereinstimmung mit der zuvor gelernten Strategie zu generieren. Vergessen Sie wie immer nicht, die Ausführung der Maßnahmen zu kontrollieren.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
Hier endet die Arbeit der Modelle an der aktuellen Leiste und die Interaktion mit der Umgebung beginnt. Zunächst werden wir die Ergebnisse der Arbeit des Agenten vorverarbeiten und entschlüsseln. In früheren Artikeln haben wir das Vorhandensein von offenen Positionen in nur einer Richtung definiert. Deshalb werden wir als erstes das Volumen-Delta aus den Ergebnissen des Agenten ermitteln. Wir speichern die Differenz für die Richtung mit dem größten Volumen. In der zweiten Richtung setzen wir das Volumen der Operation zurück.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } AgentResult = temp;
Als Nächstes prüfen wir, ob Transaktionen zum Kauf eines Finanzinstruments erforderlich sind. Hier überprüfen wir das Volumen und die Stop-Stufen des vom Agenten erzeugten Vorgangs. Wenn das Transaktionsvolumen unter der möglichen Mindestposition liegt oder die Stop-Loss-/Take-Profit-Niveaus nicht den Mindestanforderungen des Brokers entsprechen, dann ist dies ein Signal, keine Kaufpositionen zu eröffnen. Zu diesem Zeitpunkt sollten wir alle zuvor geöffneten Kaufpositionen schließen, sofern sie bestehen.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Wenn der Agent entscheidet, dass eine Kaufposition eingegangen werden muss, sind je nach dem aktuellen Stand des Kontos verschiedene Optionen möglich:
- Wenn eine Position bereits offen ist und ihr Volumen das vom Agenten festgelegte Volumen übersteigt, schließen wir das überschüssige Volumen, während wir die Stop-Levels für die verbleibende Position gegebenenfalls anpassen.
- Die Höhe der offenen Position entspricht der vom Agenten angegebenen Höhe - prüfe und passe die Stop-Level gegebenenfalls an.
- Es gibt keine offene Position oder ihr Volumen ist geringer als angegeben - öffne das fehlende Volumen und passe die Stop-Level an.
else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Wie wiederholen ähnliche Vorgänge für Verkaufspositionen.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Nach der Interaktion mit der Umgebung müssen wir nur noch das Ergebnis der vorangegangenen Operationen digitalisieren und die Daten im Wiedergabepuffer für das Erlebnis speichern.
//--- int shift=BarDescr*(NBarInPattern-1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift+1]-1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Damit ist unsere Arbeit am EA für die Interaktion mit der Umwelt und die Erfassung von Trainingsdaten abgeschlossen. Den vollständigen Code des EA und alle seine Funktionen finden Sie im Anhang.
Wir fahren mit dem Modelltraining EA „\DoC\Study.mq5“ fort. In der Initialisierungsmethode OnInit des EAs wird zunächst versucht, den Trainingssatz zu laden. Da wir die Modelle offline trainieren, ist dieser Trainingssatz unsere einzige Datenquelle. Wenn also ein Fehler beim Laden der Trainingsdaten auftritt, macht die weitere Arbeit des EA keinen Sinn, und wir geben das Ergebnis des Programminitialisierungsfehlers zurück. Senden Sie zunächst eine Meldung mit der Fehler-ID an das Protokoll.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Der nächste Schritt ist das Laden von vortrainierten Modellen. Wenn keine vorhanden sind, werden neue Modelle erstellt und initialisiert.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTG.Load(FileName + "RTG.nnw", dtStudied, true)) { Print("Init new models"); CArrayObj *agent = new CArrayObj(); CArrayObj *rtg = new CArrayObj(); if(!CreateDescriptions(agent,rtg)) { delete agent; delete rtg; return INIT_FAILED; } if(!Agent.Create(agent) || !RTG.Create(rtg)) { delete agent; delete rtg; return INIT_FAILED; } delete agent; delete rtg; }
Bitte beachten Sie, dass bei einem Fehler beim Lesen eines der Modelle beide Modelle erstellt und initialisiert werden. Dies geschieht, um die Kompatibilität der Modelle zu gewährleisten.
Als Nächstes folgt der Block zur Überprüfung der Modellarchitektur. Hier überprüfen wir die Konsistenz der Schichtgrößen des Originals und der Ergebnisse der beiden Modelle. Überprüfen wir zunächst die Architektur des Agenten.
//--- Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the agent does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Agent doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; }
Dann wiederholen wir die Schritte für das Modell der latenten Repräsentation.
RTG.getResults(Result); if(Result.Total() != NRewards) { PrintFormat("The scope of the RTG does not match the rewards count (%d <> %d)", NRewards, Result.Total()); return INIT_FAILED; } //--- RTG.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of RTG doesn't match state description (%d <> %d)", Result.Total(), (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } RTG.SetUpdateTarget(1000000);
An dieser Stelle sei auch darauf hingewiesen, dass wir beim Training des latenten Repräsentationsmodells nicht vorhaben, das Zielmodell zu verwenden, das von der FQF-Architektur bereitgestellt wird. Daher setzen wir den Aktualisierungszeitraum des Zielmodells sofort auf einen recht großen Wert. Diese Methode ermöglicht es uns, unnötige Operationen bei der Ausbildung von Modellen zu vermeiden.
Nachdem alle oben genannten Vorgänge erfolgreich abgeschlossen wurden, müssen wir nur noch das Startereignis des Trainingsprozesses erzeugen und die EA-Initialisierungsmethode abschließen.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
In der Deinitialisierungsmethode OnDeinit des EAs sollten wir das Speichern des latenten Repräsentationsmodells hinzufügen. Im Gegensatz zu dem olympischen Sprichwort „Es geht nicht um das Gewinnen, sondern um das Mitmachen“, kommt es uns genau auf das Ergebnis und nicht auf den Trainingsprozess an.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Agent.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); RTG.Save(FileName + "RTG.nnw", TimeCurrent(), true); delete Result; }
Fahren wir mit der Trainingsmethode des Models Train fort. Im Hauptteil der Methode bestimmen wir die Anzahl der geladenen Trajektorien im Erfahrungswiedergabepuffer und speichern den aktuellen Stand des Tickzählers in einer lokalen Variablen, um die Zeit während des Modelltrainings zu kontrollieren.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Wie im vorangegangenen Artikel bauen wir ein System von Schleifen auf. Die äußere Schleife zählt die Anzahl der Batches des Modell-Trainings. In seinem Hauptteil wählen wir zufällig eine Trajektorie aus dem Erfahrungswiedergabepuffer und einen Zustand auf dieser Trajektorie als Ausgangspunkt für das Training. Wir leeren sofort die Stapel der beiden Modelle und setzen den Vektor der letzten Aktionen des Agenten zurück. Diese Operationen sind für das Training autoregressiver Modelle unerlässlich und müssen vor jedem Übergang zu einem neuen Segment der Trajektorie für Trainingsmodelle durchgeführt werden.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; } Actions = vector<float>::Zeros(NActions); Agent.Clear(); RTG.Clear();
Beim Training autoregressiver Modelle spielt die Einhaltung der Reihenfolge der Operationen während des Trainingsprozesses eine wichtige Rolle. Um diese Anforderung zu erfüllen, erstellen wir eine verschachtelte Schleife, in der wir die Eingangsdaten für die Modelle in der chronologischen Reihenfolge ihres Auftretens bei der Interaktion mit der Umwelt bereitstellen. Auf diese Weise können wir das Verhalten des Agenten so genau wie möglich reproduzieren und einen optimalen Trainingsprozess entwickeln.
for(int state = i; state < MathMin(Buffer[tr].Total - 2,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Um einen möglichst korrekten Trainingsprozess einzurichten, müssen wir sicherstellen, dass der Stapelpuffer vollständig mit seriellen Daten gefüllt ist. Denn genau das wird passieren, wenn das Modell über einen längeren Zeitraum verwendet wird. Daher richten wir die verschachtelte Schleife für eine Anzahl von Iterationen ein, die dreimal so lang ist wie der Stapel der analysierten Daten. Um jedoch zu verhindern, dass im gespeicherten Trajektoriendatenfeld eine Grenzverletzung auftritt, fügen wir eine Prüfung auf Fertigstellung der Trajektorie hinzu.
Als Nächstes wird im Hauptteil der Schleife der Quelldatenpuffer in strikter Übereinstimmung mit der Reihenfolge der Datenaufzeichnung während des Prozesses der Erfassung der Trainingsstichprobe gefüllt. Dabei ist zu beachten, dass diese Prozesse der Struktur der Quelldaten entsprechen müssen, die wir bei der Beschreibung der Einbettungsschicht in der Modellarchitektur festgelegt haben.
Zunächst fügen wir dem Puffer historische Daten über die Preisentwicklung eines Finanzinstruments und Indikatoren der analysierten Indikatoren hinzu. Während wir bei der Datenerfassung die Daten vom Terminal heruntergeladen haben, können wir jetzt die fertigen Daten aus dem entsprechenden Array des Erfahrungswiedergabepuffers verwenden.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Die Erstellung einer Beschreibung des Kontostands und eines Zeitstempels wiederholt ähnliche Prozesse in der Trainingsdatenerfassung EA fast vollständig.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
Als Nächstes fügen wir den Aktionsvektor des Agenten aus dem vorherigen Schritt in den Puffer ein und rufen die Vorwärtspassmethode des Modells zur Erzeugung latenter Zustände auf. Achten Sie darauf, die Ergebnisse der Operationen zu überprüfen.
//--- Prev action State.AddArray(Actions); //--- Return to go if(!RTG.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Nach erfolgreicher Ausführung der Methode des Vorwärtsdurchgangs des Modells zur Generierung latenter Zustände können wir dessen Parameter sofort aktualisieren. Wir werden das Modell trainieren, um zukünftige Belohnungen vorherzusagen. Dieser Ansatz ist mit dem DT-Algorithmus vereinbar und steht nicht im Widerspruch zum DoC-Algorithmus.
Result.AssignArray(Buffer[tr].States[state+1].rewards); if(!RTG.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
In diesem Stadium haben wir die Verwendung der Methode CAGrad zur Anpassung der Richtung des Fehlergradienten im Ergebnisvektor aufgegeben. Das liegt daran, dass wir nicht nur die absoluten Werte der Belohnungen, sondern auch deren probabilistische Verteilung in den Tiefen der FQF-Schicht lernen wollen. Die Anpassung der Zielwerte zur Optimierung der Richtung des Fehlergradienten kann die gewünschte Verteilung verzerren.
Nach der Optimierung der Parameter des latenten Repräsentationsmodells gehen wir dazu über, das Politikmodell unseres Agenten zu trainieren. Wir fügen die tatsächliche Belohnung, die wir für den Wechsel in den nächsten Zustand erhalten, dem anfänglichen Datenpuffer hinzu. Genau das haben wir bei der Schulung der Richtlinie für den Agenten von Decision Transformer getan. Außerdem wiederholen wir für das Training der Agentenpolitik den Decision Transformer-Algorithmus vollständig. Schließlich müssen wir den Agenten darauf trainieren, abgeschlossene Aktionen aus einzelnen Zuständen und die erwartete Belohnung zu vergleichen, genau wie beim Decision-Transformer-Algorithmus. Der Hauptbeitrag des Algorithmus Dichotomie der Kontrolle ist die Erstellung einer korrekten Zielbezeichnung in Form einer latenten Repräsentation, die durch das zweite Modell gebildet wird.
//--- Policy Feed Forward State.AddArray(Buffer[tr].States[state+1].rewards); if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Der nächste Schritt besteht darin, die Parameter des Agentenmodells zu aktualisieren, um die tatsächlichen Aktionen zu generieren, die zu der tatsächlichen Belohnung führen, die in den Eingabedaten des Agenten als Ziel angegeben ist.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Dieses Mal verwenden wir bereits die CAGrad-Methode, um die Richtung des Fehlergradientenvektors zu optimieren und die Konvergenzgeschwindigkeit des Modells zu erhöhen.
Nach erfolgreicher Aktualisierung der Parameter beider Modelle müssen wir den Nutzer nur noch über den Trainingsfortschritt informieren und zur nächsten Trainingsiteration übergehen.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "RTG", iter * 100.0 / (double)(Iterations), RTG.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Sobald alle Iterationen unseres Schleifensystems abgeschlossen sind, betrachten wir das Training als beendet. Wir löschen das Kommentarfeld im Chart, senden die Ergebnisse des Trainingsprozesses an das Protokoll und leiten die Beendigung des EAs ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "RTG", RTG.getRecentAverageError()); ExpertRemove(); //--- }
Damit ist unsere Überprüfung des EA-Modells „\DoC\Study.mq5“ abgeschlossen. Im Anhang finden Sie den vollständigen Code aller im Artikel verwendeten Programme. Dort finden Sie auch den EA „\DoC\Test.mq5“ zum Testen trainierter Modelle. Sein Code bildet den EA für die Interaktion mit der Umgebung und die Sammlung von Trainingsdaten fast vollständig nach. Deshalb werden wir uns jetzt nicht mit den Methoden befassen. Ich beantworte gerne alle Ihre möglichen Fragen in dem zu diesem Artikel gehörenden Forumsthread.
3. Tests
Nach Abschluss der Arbeiten zur Erstellung von EAs, in denen wir unsere Vision des Algorithmus der Dichotomie der Kontrolle umgesetzt haben, gehen wir nun zur Phase der Prüfung der geleisteten Arbeit über. In dieser Phase werden wir Trainingsdaten sammeln, die Modelle trainieren und die Ergebnisse ihrer Arbeit außerhalb des Trainingszeitraums überprüfen. Die Verwendung neuer Daten zum Testen von Modellen ermöglicht es uns, die Modellprüfung so realitätsnah wie möglich zu gestalten. Denn unser Ziel ist es, ein Modell zu erhalten, mit dem in absehbarer Zeit auf den Finanzmärkten echte Gewinne erzielt werden können.
Wie immer werden die Modelle auf historischen Daten für die ersten 7 Monate des Jahres 2023 trainiert. Für alle Tests verwenden wir eines der volatilsten Finanzinstrumente - EURUSD H1. Die Parameter aller analysierten Indikatoren haben sich seit Beginn unserer Artikelserie nicht verändert und werden standardmäßig verwendet.
Unser Modelltrainingsverfahren ist iterativ und besteht aus mehreren aufeinanderfolgenden Iterationen der Sammlung von Trainingsdaten und des Trainings von Modellen.
Ich möchte noch einmal betonen, dass die Sammlung von Trainingsdaten und das Training von Modellen wiederholt werden müssen. Natürlich können wir zunächst eine umfangreiche Datenbank mit Trainingsbeispielen sammeln und dann lange Zeit Modelle darauf trainieren. Aber unsere Ressourcen sind begrenzt. Wir sind physisch nicht in der Lage, eine Datenbank mit Beispielen zu sammeln, die den Raum der Handlungen und gegenseitigen Belohnungen vollständig abdeckt. Außerdem arbeiten wir mit einem kontinuierlichen Raum von Aktionen. Hinzu kommt die große Stochastizität der untersuchten Umwelt. Das bedeutet, dass während des Trainingsprozesses eine hohe Wahrscheinlichkeit besteht, dass das Modell in einem unerforschten Raum landet. Um unser Wissen über die Umgebung zu verfeinern, benötigen wir weitere Interaktionsiterationen.
Ein weiterer wichtiger Punkt ist, dass jeder Agent bei der anfänglichen Sammlung von Trainingsdaten eine zufällige Strategie verwendet. So können wir die Umgebung so umfassend wie möglich erkunden. Wie Sie wissen, besteht eine der größten Herausforderungen beim Reinforcement Learning darin, das Gleichgewicht zwischen Erkunden und Verwertung zu finden. Offensichtlich handelt es sich hier um 100%ige Forschung. Bei der erneuten Interaktion mit der Umgebung und der Sammlung von Trainingsdaten verwenden die Agenten eine bereits trainierte Strategie. Der Umfang der Forschung wird auf das Ausmaß der Stochastizität der geschulten Politik eingegrenzt.
Je häufiger wir die Interaktion mit der Umwelt iterativ durchführen, desto gleichmäßiger wird der Bereich der Stochastizität des Modells eingegrenzt. Durch rechtzeitiges Feedback kann die Richtung der Ausbildung angepasst werden. Dies erhöht unsere Chancen, den maximalen erwarteten Gesamtertrag zu erzielen.
Bei langen Intervallen des Offline-Trainings besteht die Gefahr, dass die Stochastizität der Aktionen des Modells sofort so weit wie möglich reduziert wird und ein lokaler Extremwert erreicht wird, ohne dass die Richtung des Modelltrainings angepasst werden kann.
Es ist auch zu beachten, dass wir in unseren Modellen einen spärlichen Aufmerksamkeitsblock verwendet haben, dessen Training ein doppelt komplexer und langwieriger Prozess ist. Zunächst gibt es einen Block Self-Atention, der eine komplexe Struktur aufweist. Eine komplexe Struktur wiederum erfordert eine lange und sorgfältige Ausbildung.
Der zweite Punkt ist der Einsatz der spärlichen Aufmerksamkeit. Daher werden, wie bei Dropout, nicht alle Neuronen in jeder Iteration des Trainings vollständig genutzt. Dies hat zur Folge, dass der Gradient die Neuronen zu bestimmten Zeitpunkten nicht erreicht und sie aus dem Training herausfallen. Der Verlust von Neuronen aus dem Training erfolgt recht stochastisch. Um das Modell vollständig zu trainieren, ist eine zusätzliche Anzahl von Iterationen erforderlich.
Gleichzeitig reduziert die Verwendung von spärlichen Aufmerksamkeitsblöcken die Zeit pro Trainingsiteration und macht das Modell flexibler.
Aber kommen wir zurück zu den Ergebnissen des Trainings und der Tests unserer Modelle. Um das trainierte Modell zu testen, haben wir historische Daten vom August 2023 verwendet. EURUSD H1. Der August ist der Monat, der unmittelbar auf die Ausbildungszeit folgt. Wie bereits erwähnt, schaffen wir auf diese Weise Bedingungen für die Erprobung des Modells, die so nah wie möglich am Alltagsbetrieb des Modells liegen. Ausgehend von den Ergebnissen der Tests des Modells konnten wir dennoch einen gewissen Gewinn erzielen. Wie Sie sich vielleicht erinnern, konnte ein mit dem Entscheidungstransformator-Algorithmus trainiertes Modell im vorigen Artikel unter ähnlichen Bedingungen keinen Gewinn erzielen. Durch die Hinzufügung von DoC-Ansätzen können wir fast das gleiche Modell auf eine qualitativ andere Ebene heben.


Doch trotz des Gewinns sind die Ergebnisse des Modells nicht perfekt. Wenn wir uns die Saldenkurve beim Testen des trainierten Modells ansehen, können wir die folgenden Trends feststellen:
- In den ersten zehn Tagen des Monats ist ein recht starker Anstieg des Saldos um etwa 20 % zu beobachten.
- Im zweiten Jahrzehnt beobachten wir Schwankungen im Saldo der erzielten Ergebnisse. Auf unrentable Perioden folgen relativ starke Anstiege. Die Amplitude der Schwankungen erreicht 10 % des Saldos.
- Im dritten Jahrzehnt gibt es eine Reihe von unrentablen Handelsgeschäften.
Das Ergebnis ist, dass wir während des gesamten Trainingszeitraums etwa 43 % profitable Positionen haben. In diesem Fall ist die maximal gewinnbringende Transaktion mehr als 2-mal größer als der maximale Verlust. Der durchschnittliche Gewinn ist um 1/3 höher als der durchschnittliche Verlust. Infolgedessen bleibt der Gewinnfaktor bei 1,01 mit einem Erholungsfaktor von 0,03.
Vergleicht man die Ergebnisse der Tests des Modells mit und ohne Anwendung der DoC-Prinzipien, so ist in beiden Fällen ein starker Anstieg des Saldos in den ersten zehn Tagen des Monats zu erkennen. Durch den Einsatz von DoC-Ansätzen konnten die erzielten Ergebnisse in den zweiten zehn Tagen des Monats beibehalten werden. Ohne den Einsatz von DoC begann sofort eine Reihe von unrentablen Handelsgeschäften.
Dies führt zu meiner subjektiven Meinung, dass man mit dem autoregressiven Ansatz recht gute Ergebnisse erzielen kann, wenn auch nur für einen kurzen Zeitraum. Gleichzeitig zeigt die Anwendung von DoC, dass die Dauer der positiven Wirkung durch einige Änderungen der Methode verlängert werden kann. Das bedeutet, dass es Potenzial und Raum für Kreativität gibt.
Schlussfolgerung
In diesem Artikel haben wir einen sehr interessanten Algorithmus mit großem Potenzial kennengelernt - Dichotomy of Control (DoC). Dieser Algorithmus wurde vom Google-Team als Mittel zur Verbesserung der Effizienz von Modellen bei der Arbeit mit stochastischen Umgebungen eingeführt. Das Hauptprinzip der DoC besteht darin, alle beobachtbaren Faktoren und Ergebnisse in solche zu unterteilen, die von der Politik des Agenten abhängig und unabhängig sind. Daher konzentrieren wir uns beim Training des Modells nicht auf Faktoren, die von den Handlungen des Agenten abhängen, sondern entwickeln eine Politik, die auf die Maximierung der Ergebnisse abzielt und dabei den stochastischen Einfluss der Umwelt berücksichtigt.
Im Rahmen des Artikels haben wir dem zuvor erstellten Decision Transformer-Modell DoC-Prinzipien hinzugefügt. Infolgedessen ist eine Verbesserung der Leistung des Modells in der Teststichprobe zu beobachten. Das erzielte Ergebnis ist noch lange nicht perfekt. Aber die positive Veränderung ist deutlich sichtbar, und wir können die Effizienz der Umsetzung der Grundsätze der Dichotomie der Kontrolle feststellen.
Links
- Decision Transformer: Reinforcement Learning via Sequence Modeling
- Dichotomy of Control: Separating What You Can Control from What You Cannot
- Neuronale Netze leicht gemacht (Teil 34): Vollständig parametrisierte Quantilsfunktion
- Neuronale Netze leicht gemacht (Teil 58): Entscheidungstransformator (DT)
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mq5 | Expert Advisor | Trainings-EA des Agenten |
| 3 | Test.mq5 | Expert Advisor | Test-EA des Modells |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 6 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13551
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Überlegen Sie mal...!
wie viele PHDs arbeiten bei goldmansachs? oder hfts, oder quantfund firms, !
wenn es doch nur SO einfach wäre !!!
Ich wollte dem Autor für die große Menge an Ideen danken, es ist ein Klondike zum Experimentieren.
Ich denke auch, dass die Artikel als Beispiele für mögliche Methoden zum Training neuronaler Netze geeignet sind, aber nicht für die Praxis. Ich schätze wirklich die Arbeit, die der Autor in seine eigene Bibliothek zum Erstellen und Trainieren neuronaler Netze investiert hat, und sogar mit dem Einsatz von Videokarten, aber sie kann in keiner Weise für praktische Zwecke verwendet werden, geschweige denn mit Tensorflow, Keras, Pytorch konkurrieren - Eigentlich können alle Modelle, die mit diesen Bibliotheken trainiert wurden, direkt in mql5 verwendet werden, unter Verwendung des onnx-Formats.
Ich werde nach und nach die Ideen des Autors mit Hilfe dieser modernen Bibliotheken anwenden.
Auch ist es notwendig, Indikatoren für die Eingabedaten für das Training neuronaler Netze zu wählen, ich habe die erfolgreichste ist bollinger bands, und ich benutze 48 solcher Indikatoren als Eingabedaten mit verschiedenen Einstellungen für rekurrente Netzwerke wie LSTM. Aber das ist keine Erfolgsgarantie. Ich trainiere auch 28 Währungspaare auf einmal und wähle die besten aus, aber auch das ist keine Erfolgsgarantie. Dann müssen Sie das Trainingsverfahren mindestens 20 Mal durchführen, wobei Sie die Anzahl der Schichten und ihre Einstellungen in den neuronalen Netzen ändern, und in jeder Phase die besten Modelle auswählen, die sich im Strategietester gut bewährt haben, und die schlechtesten entfernen, und erst dann können Sie in der Praxis vernünftige Ergebnisse erzielen.
Am Ende wählen wir einfach zum Beispiel die besten 9 Paare aus 28 und handeln sie auf einem realen Konto, gleichzeitig sollte der Expert Advisor auch in seinem Arsenal Mani-Management haben, wird es nicht schaden, das Netz auch, das heißt, wir verwenden neuronale Netze als Assistenten für gute Ideen von Beratern ohne neuronale Netze, so dass sie bereits smart.
Hallo, würden Sie mir einen Link zum 1. Artikel geben, um mit dem Lesen/Lernen zu beginnen, ich bin sehr an dem Thema interessiert
https://www.mql5.com/de/articles/7447