
Redes neurais de maneira fácil (Parte 59): dicotomia do controle (DoC)

Introdução
Os mercados financeiros são um ambiente complexo e multifacetado. Cada evento e ação têm suas raízes em processos econômicos centrais. A causa de certos eventos pode ser encontrada em notícias, eventos geopolíticos, determinados aspectos técnicos e muitos outros fatores. E, muitas vezes, observamos esse tipo de dependência apenas em retrospecto. Quando analisamos situação de mercado, observamos apenas uma pequena parte desses fatores. O que, em geral, torna os mercados financeiros um ambiente bastante complexo para análise. No entanto, destacamos algumas das ferramentas mais importantes que podem identificar as principais tendências. Atribuímos os demais fatores à estocasticidade do ambiente circundante.
Em um ambiente tão complexo, o aprendizado por reforço se apresenta como uma ferramenta poderosa para desenvolver estratégias nos mercados financeiros. No entanto, os métodos existentes, como o transformador de decisões, podem se mostrar insuficientemente adaptáveis em condições de alta estocasticidade. Foi o que observamos na parte prática do artigo anterior.
Lembro que, ao contrário dos métodos tradicionais, o transformador de decisões modela sequências de ações no contexto de um modelo autorregressivo de recompensas desejadas. Durante o treinamento, estabelece-se uma relação entre a sequência de estados, as ações, a recompensa desejada e o resultado efetivo obtido do ambiente. No entanto, um grande número de fatores aleatórios pode acarretar uma discrepância entre a estratégia treinada e o resultado futuro desejado.
É importante dizer que muitos métodos de aprendizado por reforço e não apenas estes enfrentam esse tipo de problema. Como uma das opções para solucioná-lo, a equipe do Google apresentou em outubro de 2022 o método Dichotomy of Control.
1. Fundamentos do método DoC
A dicotomia do controle é o fundamento lógico por trás do estoicismo. E implica o entendimento de que tudo ao nosso redor pode ser condicionalmente dividido em duas partes. A primeira está sob nosso controle e totalmente sob nossa influência. Sobre a segunda, não temos poder, e os eventos acontecerão independentemente de nossas ações.
Nós nos trabalharemos com primeira parte. E tomaremos a segunda como garantida.
Os autores do método "Dichotomy of Control" tentaram incorporar esses postulados em seu algoritmo. O DoC permite separar o que está sob o controle da estratégia (política de ações) e o que está fora de seu controle (a estocasticidade do ambiente).
Mas antes de passarmos ao estudo do método, sugiro relembrar como representávamos a trajetória no DT.
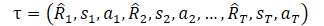
Aqui, R1 ("Return to go") representa nosso desejo e não está relacionado com o estado inicial S0. Nosso modelo treinado escolhe a ação que deu o resultado desejado na amostra de treinamento. Mas a probabilidade de obter a recompensa desejada a partir do estado atual pode ser tão baixa que as ações do Agente serão distantes das ótimas.
E agora, vamos "olhar para o mundo com os olhos bem abertos". Neste contexto, "Return to go" serve como uma indicação ao Agente para escolher uma estratégia de comportamento. Isso não lhe parece semelhante a uma habilidade em modelos hierárquicos ou a uma definição de metas em GCRL? Provavelmente, pensamentos similares ocorreram aos autores do método DoC, e eles sugeriram o uso de um estado oculto z(τ). Mas, como você sabe, trocar conceitos não muda a questão. E introduz-se um modelo treinável para representar o estado latente z(τ).
A observação chave dos autores do método é que z não deve conter informações relacionadas à estocasticidade do ambiente. Ele não deve incluir informações sobre o futuro Rt e St+1, que são desconhecidas no momento do histórico anterior. Por isso, uma restrição condicional sobre as informações mútuas é adicionado ao objetivo entre z e cada par de Rt e St+1 no futuro. Para satisfazer essa restrição de informações mútuas, usaremos métodos de treinamento contrastivo.
Em seguida, introduzimos a distribuição condicional ω(rt|τ0:t-1,st,at), parametrizada por uma função de energia f.
Combinando isso através de coeficientes de Lagrange, podemos treinar π e z(τ) por meio da minimização do objetivo final do DoC:
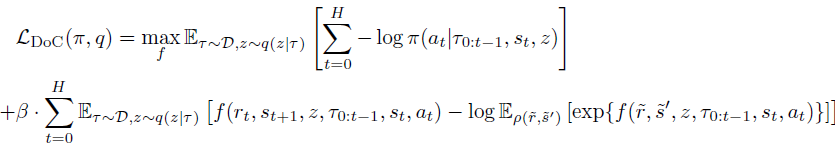
No contexto do transformador de decisões, a política treinada pelo DoC requer uma condição z apropriada. Para escolher um z desejado, associado a uma alta recompensa esperada, os autores do método sugerem:
- Escolher um grande número de valores potenciais de z;
- Estimar a recompensa esperada para cada um desses valores de z;
- Escolher o z com a maior recompensa esperada e passá-lo para a política.
Para facilitar tal procedimento na fase de exploração, dois componentes adicionais são acrescentados à formulação do método. Primeiro, a distribuição a priori p(z|s0), da qual um grande número de valores de z é escolhido. Segundo, a função de valor V(z), com a qual os valores potenciais de z são classificados. Esses componentes são treinados minimizando o seguinte objetivo:
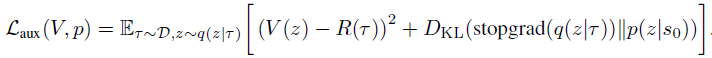
Preste atenção no uso do stop-gradient em q(z|τ) durante o treinamento de p, para evitar a regularização de q em relação à distribuição a priori.
No artigo "Dichotomy of Control: Separating What You Can Control from What You Cannot", são apresentados muitos exemplos que demonstram a superioridade significativa do método proposto em diferentes ambientes estocásticos
Este é um ponto bastante interessante, e sugiro verificar na prática a possibilidade de usar essa abordagem para resolver nossos problemas.
2. Implementação no MQL5
Na parte prática deste artigo, vamos examinar uma maneira de implementar o algoritmo "Dichotomy of Control" usando MQL5. E quero chamar sua atenção imediatamente para o fato de que a implementação em discussão é uma interpretação pessoal do método proposto. E em alguns pontos, ela estará bastante distante da solução original.
Primeiramente, esta implementação é uma continuação lógica dos programas do artigo anterior. Estamos implementando os mecanismos propostos no código DT criado anteriormente em tentativas de otimizar o funcionamento do modelo e aumentar sua eficácia.
Além disso, tentaremos simplificar um pouco o algoritmo DoC enquanto mantemos as ideias fundamentais.
Como já mencionado anteriormente, os autores do método introduzem um estado latente em vez do Return-to-go. Durante a operação, é amostrado um conjunto desses estados latentes a partir da distribuição a priori p(z|s0), que são subsequentemente avaliados usando a função de valor V(z). Na prática, isso implica que extraímos da amostra de treinamento os estados mais semelhantes e selecionamos a representação latente com a maior recompensa esperada. E, de acordo com a dicotomia do controle, consideramos não apenas o valor absoluto da recompensa, mas também a probabilidade de recebê-la.
Naturalmente, não vamos iterar sobre toda a amostra de treinamento a cada vez. Em vez disso, usaremos modelos pré-treinados que aproximam as funções correspondentes da amostra de treinamento. Mas, de qualquer forma, amostrar um grande número de representações latentes seguido por sua avaliação é uma tarefa bastante demorada. Há algo que possamos fazer para simplificar isso?
Vamos olhar para a essência dessas entidades. A representação latente z no contexto do transformador de decisões é a recompensa esperada. Assim, a função de valor V(z) pode estar muito próxima ao próprio estado latente z. Aqui pode surgir a ideia de excluir a função de valor como uma classe e comparar diretamente os estados latentes entre si, mas não tomaremos essa medida.
Continuando, a distribuição a priori p(z|s0) pode ser representada como a distribuição de probabilidade de usar uma ou outra representação latente em um estado específico do ambiente. E aqui vamos nos lembrar da função quantílica totalmente parametrizada (FQF). Ela permite combinar a distribuição probabilística e quantitativa. É ela que usaremos no modelo de geração da representação latente.
Essa solução nos permite combinar a distribuição a priori e a função de custo. Além disso, dessa forma, podemos desistir de amostrar o conjunto de estados latentes seguido pela avaliação.
Da mesma forma, procedemos com a distribuição condicional ω(rt|τ0:t-1,st,at), parametrizada pela função de energia f.
Note que, em ambos os casos, geramos a representação latente. E, para economizar recursos, criaremos 2 modelos, mas usaremos apenas um em ambos os casos. E aqui precisamos lembrar que ω(rt|τ0:t-1,st,at) depende da trajetória. Daí que, ao construir o modelo, devemos levar em conta seu caráter autorregressivo, de forma semelhante ao modelo Ator do DT.
A arquitetura de ambos os modelos é descrita no método CreateDescriptions. Nos parâmetros do método, passamos ponteiros para 2 arrays dinâmicos para descrever as arquiteturas dos modelos. Devo dizer imediatamente que as diferenças nas arquiteturas dos modelos serão insignificantes. Mas ainda assim, elas existirão. Por isso, criamos 2 arquiteturas separadas, não uma única. Primeiro, criamos a arquitetura do modelo do Ator. O camada de dados de entrada, como no artigo anterior, contém apenas os componentes mutáveis do estado do ambiente (dados de 1 barra).
bool CreateDescriptions(CArrayObj *agent, CArrayObj *rtg) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (NRewards + BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
A seguir, temos a camada de normalização em lote, onde ocorre o pré-processamento dos dados brutos de entrada.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Os dados normalizados passam por uma camada de incorporação e são adicionados à pilha.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NActions,NRewards}; ArrayCopy(descr.windows,temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
A pilha contém as incorporações dos dados para todo o período analisado. E passamos por um bloco de atenção multicabeça disperso.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count*5; descr.window = prev_wout; descr.step = 4; descr.window_out = 32; descr.layers = 8; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Após o bloco de atenção, reduzimos a dimensionalidade dos dados usando uma camada convolucional.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; }
E passamos os dados através do bloco de tomada de decisão, que consiste em 3 camadas totalmente conectadas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Na saída do modelo, usamos uma camada latente VAE para adicionar estocasticidade à política do Agente.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Segue-se a descrição da arquitetura do modelo de representação latente. Como já foi dito, a arquitetura do modelo é muito semelhante à anterior. Mas ela analisa um volume menor de dados. Como pode ser observado a partir das descrições apresentadas na parte teórica, a função de distribuição condicional ω(rt|τ0:t-1,st,at) gera uma representação latente com base no estado atual, ações do agente e a trajetória anterior. Em seguida, alimentamos o Agente com o estado latente resultante. Alimentaremos o segundo modelo com menos dados, conforme o tamanho do estado latente.
//--- RTG if(!rtg) { rtg = new CArrayObj(); if(!rtg) return false; } //--- rtg.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Os dados de entrada brutos também passam por um tratamento preliminar na camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
A seguir, ocorre a incorporação de dados. E aqui também observamos uma mudança na estrutura dos dados de entrada.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NActions}; ArrayCopy(descr.windows,temp); } prev_wout = descr.window_out = EmbeddingSize; if(!rtg.Add(descr)) { delete descr; return false; }
Abaixo, repetimos as estruturas do bloco de atenção esparsa. No entanto, note a redução no número de elementos analisados na sequência. Se o Agente analisava 5 entidades em cada barra, nesta modelo há apenas 4. Para evitar o gerenciamento manual do número de elementos em cada a barra neste ponto, podemos registrar, em uma variável separada, o tamanho do array de janelas de dados de entrada da camada de incorporação no passo anterior.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count=descr.count = prev_count*4; descr.window = prev_wout; descr.step = 4; descr.window_out = 32; descr.layers = 8; descr.probability = Sparse; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Assim como no modelo anterior, após a camada de atenção esparsa, reduzimos a dimensionalidade dos dados analisados usando uma camada convolucional. E passamos os dados obtidos para o bloco de tomada de decisão.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Agora, na saída do bloco de tomada de decisão, utilizamos uma camada totalmente parametrizada da função quantílica. Como discutido anteriormente.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NRewards; descr.window_out = 32; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- return true; }
Após descrever a arquitetura dos modelos, passamos a trabalhar no Expert Advisor para interação com o ambiente e coleta inicial de dados para o treinamento dos modelos "\DoC\Research.mq5". É importante notar que as peculiaridades do uso do método de controle de dicotomia são evidentes mesmo quando os dados de treinamento são coletados. Se anteriormente, em Expert Advisors semelhantes, usávamos apenas o modelo do Agente e os outros modelos eram conectados apenas na fase de treinamento, agora usaremos ambos os modelos em todas as etapas. Desde a coleta de dados primários até o teste do modelo treinado. Afinal, o estado latente gerado pelo segundo modelo é parte dos dados de entrada do nosso Agente.
Dentro do escopo deste artigo, não vamos detalhar todo o código do Expert Advisor. A maior parte dos métodos é mantida inalterada em relação aos artigos anteriores. Vamos focar apenas no método de processamento de ticks OnTick, no qual a coleta de dados principal é realizada.
No início do método, como de costume, verificamos a ocorrência do evento de abertura de uma nova a barra e, se necessário, atualizamos os dados históricos do movimento de preços e os indicadores dos indicadores analisados.
Lembro que todas as operações do nosso Expert Advisor são executadas apenas na abertura de uma nova a barra. O algoritmo dos nossos modelos não monitora a mudança de cada tick. Todos os modelos em treinamento operam com dados históricos do timeframe H1. No entanto, a escolha do timeframe é uma decisão subjetiva e não é limitada pelas arquiteturas dos modelos. É necessário apenas garantir que o treinamento e a operação dos modelos sejam realizados no mesmo timeframe e no mesmo instrumento. Antes de operar modelos previamente treinados em outro timeframe e/ou em outro instrumento, é necessário seu re-treinamento no timeframe e instrumento financeiro alvo.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Em seguida, preparamos o buffer de dados de entrada. Inicialmente, registraremos no buffer os dados históricos do movimento de preço do instrumento financeiro e os indicadores dos indicadores analisados.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Em seguida, adicionamos informações sobre o estado atual da conta e posições abertas.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Imediatamente, incluímos um rótulo de tempo.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
E a última ação do Agente, que nos levou ao estado atual do ambiente. Ao processar a primeira a barra, este vetor é preenchido com valores nulos.
//--- Prev action
bState.AddArray(AgentResult);
A seguir, deveríamos adicionar uma diretriz ao Agente na forma de "Return-To-Go". Mas, dentro do algoritmo DoC, ainda precisamos gerar o estado latente. No entanto, os dados coletados são suficientes para operar o modelo de geração do estado latente, e realizamos sua propagação.
//--- Return to go if(!RTG.feedForward(GetPointer(bState))) return;
Após a conclusão bem-sucedida da propagação do modelo, carregamos a representação latente obtida e a adicionamos ao buffer de dados de entrada.
RTG.getResults(Result); bState.AddArray(Result);
Nesta fase, formamos o pacote completo de dados de entrada para o modelo do nosso Agente, e podemos chamar o método de propagação para gerar as ações ótimas de acordo com a política previamente aprendida. E, como sempre, não esquecemos de controlar a execução de operações.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
Aqui termina o trabalho dos modelos na barra atual e começa a interação com o ambiente. Primeiro, realizaremos o pré-processamento e a decodificação dos resultados do trabalho do Agente. Nos artigos anteriores, decidimos ter posições abertas apenas em uma direção. Por isso, a primeira coisa que faremos é determinar o delta dos volumes a partir dos resultados do Agente. E guardaremos a diferença para a direção com o volume máximo. Na segunda direção, zeraremos o volume da operação.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } AgentResult = temp;
Em seguida, verificamos a necessidade de realizar operações de compra do instrumento financeiro. Aqui, verificamos o volume e os níveis de stop da operação gerada pelo Agente. Se o volume da operação for menor que a posição mínima possível ou se os níveis de stop-loss/take-profit não atenderem aos requisitos mínimos da corretora, isso é um sinal da ausência de abertura de posições longas. E neste momento, devemos fechar todas as posições longas previamente abertas. Claro, se existirem tais posições.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Se, por decisão do Agente, for necessária uma posição longa, então as opções dependem do estado atual da conta:
- Se a posição já estiver aberta e seu volume exceder o especificado pelo Agente, então fechamos o volume excedente. E para a posição restante, se necessário, ajustamos os níveis de stop.
- Se o nível da posição aberta for igual ao especificado pelo Agente — verificamos e, se necessário, ajustamos os níveis de stop.
- Se não houver posição aberta ou seu volume for menor do que o especificado, abrimos o volume faltante e ajustamos os níveis de stop.
else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Repetimos operações semelhantes para posições curtas.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Após a interação com o ambiente, resta-nos codificar o resultado das operações anteriores e salvar os dados no buffer de reprodução de experiência.
//--- int shift=BarDescr*(NBarInPattern-1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift+1]-1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Com isso, concluímos o trabalho sobre o EA de interação com o ambiente e coleta de dados da amostra de treinamento. E você pode se familiarizar com o código completo do EA e todas as suas funções no anexo ao artigo.
Agora, passamos a examinar o EA de treinamento de modelos "\DoC\Study.mq5". No método de inicialização do EA OnInit, tentamos primeiro carregar a amostra de treinamento. Como realizamos o treinamento de modelos off-line, essa amostra de treinamento é para nós a única fonte de dados. Consequentemente, em caso de erro no carregamento dos dados de treinamento, não há sentido em continuar o trabalho do Expert Advisor, e retornamos o resultado de um erro de inicialização do programa. Primeiro, enviamos para o log uma mensagem com o identificador do erro que ocorreu.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
A próxima etapa é o carregamento dos modelos previamente treinados. Na ausência desses, procede-se à criação e inicialização de novos modelos.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTG.Load(FileName + "RTG.nnw", dtStudied, true)) { Print("Init new models"); CArrayObj *agent = new CArrayObj(); CArrayObj *rtg = new CArrayObj(); if(!CreateDescriptions(agent,rtg)) { delete agent; delete rtg; return INIT_FAILED; } if(!Agent.Create(agent) || !RTG.Create(rtg)) { delete agent; delete rtg; return INIT_FAILED; } delete agent; delete rtg; }
Note-se que, em caso de erro na leitura de um dos modelos, ambos os modelos são criados e inicializados. Isso é feito com o objetivo de preservar a compatibilidade dos modelos.
Segue-se o bloco de verificação da arquitetura dos modelos. Aqui, verificamos se os tamanhos das camadas dos modelos originais e dos resultados de ambos os modelos correspondem. Primeiro, verificamos a arquitetura do Agente.
//--- Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the agent does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Agent doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; }
E então repetimos as ações para o modelo de representação latente.
RTG.getResults(Result); if(Result.Total() != NRewards) { PrintFormat("The scope of the RTG does not match the rewards count (%d <> %d)", NRewards, Result.Total()); return INIT_FAILED; } //--- RTG.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of RTG doesn't match state description (%d <> %d)", Result.Total(), (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } RTG.SetUpdateTarget(1000000);
Aqui, ainda vale a pena observar que não planejamos usar o modelo de destino, que é fornecido pela arquitetura FQF, no treinamento do modelo de representação latente. Por isso, imediatamente estabelecemos um período de atualização bastante longo para o modelo alvo. Este procedimento nos permitirá excluir operações desnecessárias durante o treinamento dos modelos.
Após a execução bem-sucedida de todas as operações acima mencionadas, resta-nos apenas gerar o evento de início do processo de treinamento e concluir o método de inicialização do EA.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
No método de desinicialização do EA OnDeinit, é essencial adicionar o salvamento do modelo de representação latente. Lembre-se, ao contrário do espírito olimpiano "o importante é competir, não vencer", precisamos do resultado, não do processo de treinamento.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Agent.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); RTG.Save(FileName + "RTG.nnw", TimeCurrent(), true); delete Result; }
E passamos para o método de treinamento dos modelos Train. No corpo do método, determinamos a quantidade de trajetórias carregadas no buffer de reprodução de experiência e salvamos em uma variável local o estado atual do contador de ticks para controlar o tempo no processo de treinamento dos modelos.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Em seguida, como no artigo anterior, fazemos um sistema de laços. O laço externo conta o número de lotes de treinamento dos modelos. Em seu corpo, escolhemos aleatoriamente uma trajetória do buffer de reprodução de experiência e o estado nessa trajetória como o ponto inicial de treinamento. Imediatamente, limpamos as pilhas de ambos os modelos e zeramos o vetor das últimas ações do Agente. Estas operações são essenciais no treinamento de modelos autorregressivos e obrigatórias para serem executadas antes de cada transição para um novo segmento da trajetória durante o treinamento dos modelos.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; } Actions = vector<float>::Zeros(NActions); Agent.Clear(); RTG.Clear();
No treinamento de modelos autorregressivos, a preservação da sequência de operações no processo de treinamento desempenha um papel importante. É para atender a esse requisito que criamos um laço aninhado no qual alimentamos os modelos com dados brutos seguindo a sua ordem cronológica de ocorrência durante a interação com o ambiente. Isso nos permitirá reproduzir o comportamento do Agente com a máxima precisão e construir o processo de treinamento ideal.
for(int state = i; state < MathMin(Buffer[tr].Total - 2,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Para configurar o treinamento o mais corretamente possível, precisamos estar certos de que o buffer da pilha está completamente preenchido com dados sequenciais. Afinal, é assim que acontecerá durante a exploração do modelo por um período de tempo suficientemente longo. Assim sendo, ajustamos o laço aninhado para um número de iterações três vezes maior que o comprimento da pilha de dados analisados. No entanto, para evitar erros de ultrapassagem dos limites do array dos dados da trajetória salvos, adicionamos uma verificação para o término da trajetória.
Em seguida, no corpo do laço, preenchemos o buffer de dados de entrada em estrita conformidade com a sequência de registro de dados durante a coleta da amostra de treinamento. É importante notar que esses processos devem corresponder à estrutura dos dados de entrada que especificamos na arquitetura dos modelos ao descrever a camada de incorporação.
Primeiro, adicionamos ao buffer os dados históricos sobre o movimento do preço do instrumento financeiro e as estimativas dos indicadores analisados. E se no processo de coleta de dados os carregamos do terminal, agora podemos usar os dados já preparados do array correspondente do buffer de reprodução de experiência.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Já o processo de criação da descrição do estado da conta e do registro de tempo repete quase integralmente os processos similares no EA de coleta de dados de treinamento.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
Em seguida, adicionamos ao buffer o vetor de ações do Agente no passo anterior e chamamos o método de propagação do modelo de geração do estado latente. E verificamos obrigatoriamente o resultado da execução das operações.
//--- Prev action State.AddArray(Actions); //--- Return to go if(!RTG.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Após a execução bem-sucedida do método de propagação do modelo de geração de estado latente, podemos imediatamente realizar a atualização de seus parâmetros. E vamos treinar o modelo na previsão de recompensa futura. Esta abordagem é consistente com o algoritmo DT e não contradiz o algoritmo DoC.
Result.AssignArray(Buffer[tr].States[state+1].rewards); if(!RTG.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Aqui vale ressaltar mais um ponto: nesta fase, desistimos do uso do método CAGrad para ajustar a direção do gradiente de erro no vetor de resultados. Isso se deve ao fato de que, além dos valores absolutos das recompensas, estamos tentando aprender sua distribuição de probabilidade dentro da camada FQF. E o ajuste dos valores-alvo para otimizar a direção do gradiente de erro pode distorcer a distribuição desejada.
Após a otimização dos parâmetros do modelo de representação latente, passamos ao treinamento do modelo de política do nosso Agente. Adicionamos ao buffer de dados de entrada a recompensa real recebida pela transição para o próximo estado. É assim que procedemos ao treinar a política do Agente do transformador de decisões. Além disso, na parte de treinamento da política do Agente, nós completamente repetimos o algoritmo transformador de decisões. Afinal, estamos diante da tarefa de treinar o Agente para associar as ações realizadas a partir de estados individuais e a recompensa esperada. Da mesma forma que no algoritmo transformador de decisões. O principal contributo do algoritmo Dichotomy of Control é na criação de uma definição de meta correta na forma de uma representação latente, que é formada pelo segundo modelo.
//--- Policy Feed Forward State.AddArray(Buffer[tr].States[state+1].rewards); if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
O próximo passo é atualizar os parâmetros do modelo do Agente para gerar as ações realmente realizadas, que levaram à obtenção da recompensa real, indicada nos dados de entrada do Agente como definição de meta.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Desta vez, já utilizamos o método CAGrad para otimizar a direção do vetor gradiente de erro e aumentar a velocidade de convergência do modelo.
Após a atualização bem-sucedida dos parâmetros de ambos os modelos, resta-nos informar o usuário sobre o progresso do treinamento e passar para a próxima iteração de treinamento.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "RTG", iter * 100.0 / (double)(Iterations), RTG.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Ao concluir todas as iterações de nosso sistema de ciclos, consideramos o processo de treinamento concluído. Limpamos o campo de comentários no gráfico. Registramos no log os resultados do processo de treinamento e iniciamos a conclusão do trabalho do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "RTG", RTG.getRecentAverageError()); ExpertRemove(); //--- }
Com isso, concluímos a revisão do EA de treinamento de modelos "\DoC\Study.mq5". E você pode se familiarizar com o código completo dele, assim como com os outros programas usados no artigo, por conta própria, no anexo. Lá você também encontrará o código do EA de teste de modelos treinados "\DoC\Test.mq5". Seu código é quase idêntico ao da EA, que interage com o ambiente e coleta dados de treinamento. Assim, não vamos nos deter agora na revisão de seus métodos. Terei prazer em responder a quaisquer perguntas que você possa ter no tópico do fórum correspondente a este artigo.
3. Teste
Após concluir o trabalho de criação dos EAs, nos quais implementamos nossa visão do algoritmo Dichotomy of Control, passamos para a fase de teste do trabalho realizado. Nesta etapa, realizaremos a coleta de dados de treinamento. Treinaremos os modelos. E verificaremos os resultados de seu trabalho fora do período da amostra de treinamento. A utilização de novos dados para testar os modelos nos permite aproximar ao máximo o teste dos modelos às condições reais. Afinal, nosso objetivo é obter um modelo capaz de gerar lucro real nos mercados financeiros no futuro previsível.
Como sempre, o treinamento dos modelos é realizado em dados históricos dos primeiros 7 meses de 2023. Para todos os testes, usamos um dos instrumentos financeiros mais voláteis, o EURUSD, com timeframe H1. Os parâmetros de todos os indicadores analisados permanecem inalterados desde o início de nosso ciclo de artigos e são usados por padrão.
O treinamento dos modelos é iterativo e consiste em várias iterações consecutivas de coleta de dados de treinamento e treinamento dos modelos.
Gostaria de enfatizar novamente a importância da repetição das operações sequenciais de coleta de dados de treinamento e treinamento dos modelos. Certamente, você pode inicialmente coletar uma extensa base de exemplos de treinamento e então passar muito tempo treinando os modelos nela. Mas nossos recursos não são ilimitados, e fisicamente não podemos coletar uma base de exemplos capaz de cobrir completamente o espaço de ações e recompensas correspondentes. Especialmente porque estamos trabalhando com um espaço contínuo de ações. Acrescente a isso a grande estocasticidade do ambiente estudado. Isso significa que, no processo de treinamento, é grande a probabilidade de a modelo entrar em um espaço não explorado. E para refinar nosso conhecimento sobre o ambiente, precisaremos de iterações adicionais de interação com ele.
Outro ponto bastante significativo é que, na coleta inicial de dados de treinamento, cada Agente utiliza uma política aleatória. Isso permite explorar o ambiente o máximo possível. E como você sabe, um dos principais problemas do aprendizado por reforço é encontrar o equilíbrio entre o reconhecimento e a exploração. Claramente, aqui observamos 100% de exploração. Na interação subsequente com o ambiente e na coleta de dados de treinamento, os Agentes usam uma política previamente treinada. E a área de reconhecimento se restringe ao tamanho da estocasticidade da política aprendida.
Quanto mais frequentemente realizarmos iterações de interação com o ambiente, mais suavemente será realizada a restrição da área de estocasticidade do modelo. E o feedback recebido oportuno pode ajustar a direção do treinamento. Isso aumenta nossas chances de atingir o máximo global do prêmio esperado.
No caso de longos intervalos de treinamento offline, corremos o risco de imediatamente reduzir ao máximo a estocasticidade das ações do modelo, chegando a algum extremo local sem a possibilidade de ajustar a direção do treinamento do modelo.
Também vale a pena notar que, em nossos modelos, usamos o bloco de atenção esparsa, cujo treinamento é um processo duplamente complexo e demorado. Primeiro, é o bloco Self-Attention, que tem uma estrutura complexa. E uma estrutura complexa exige treinamento longo e meticuloso.
O segundo ponto é o uso de atenção esparsa. Assim, como no caso do Dropout, nem todos os neurônios são totalmente utilizados em cada iteração de treinamento. Como resultado, em alguns momentos, o gradiente não passa para os neurônios, e eles caem fora do processo de treinamento. A queda dos neurônios do processo de treinamento ocorre de maneira bastante estocástica. E para o treinamento completo do modelo, é necessário um número adicional de iterações.
Ao mesmo tempo, o uso de blocos de atenção esparsa reduz o tempo para uma iteração de treinamento e torna o modelo mais flexível.
Mas vamos voltar aos resultados do treinamento e testes de nossos modelos. Para testar o modelo treinado, usamos dados históricos de agosto de 2023. Instrumento EURUSD, timeframe H1. Agosto é o mês que segue imediatamente após o período de treinamento. Como mencionado anteriormente, assim criamos condições para testar o modelo o mais próximo possível da exploração industrial do modelo. Os resultados do teste do modelo conseguiram obter lucro. Embora não muito grande. Lembro que no artigo anterior, sob condições semelhantes, o modelo treinado pelo algoritmo de transformação de decisões não conseguiu obter lucro. A adição de abordagens DoC permite elevar praticamente o mesmo modelo para um nível qualitativamente diferente.


Mas, apesar do lucro obtido, os resultados do trabalho do modelo não são tão promissores e inequívocos. Se olharmos para o gráfico de saldo durante o teste do modelo treinado, podemos observar as seguintes tendências:
- Na primeira década do mês, observamos um crescimento bastante acentuado do saldo de cerca de 20%.
- Na segunda década, observamos flutuações no nível de saldo em torno dos resultados alcançados. Períodos de perda são substituídos por aumentos bastante abruptos. A amplitude das flutuações atinge 10% do saldo.
- Na terceira década, observa-se uma série de operações perdedoras.
Como resultado, durante todo o período de treinamento, temos cerca de 43% de posições lucrativas. Enquanto isso, a operação mais lucrativa é mais de duas vezes maior que a maior perda. E a operação lucrativa média é um terço maior que a perda média. Como consequência, o fator de lucro foi fixado em 1.01, e o fator de recuperação em 0.03.´
Comparando os resultados do teste do modelo com e sem o uso dos princípios DoC, podemos notar um crescimento acentuado do saldo na primeira década do mês em ambos os casos. A aplicação das abordagens DoC permitiu manter o resultado alcançado na segunda década do mês. Enquanto isso, sem o uso do DoC, uma sequência de operações perdedoras começou imediatamente.
Isso leva à minha opinião subjetiva de que a abordagem autorregressiva permite alcançar resultados bastante bons, mas, infelizmente, apenas em um curto período de tempo. Ao mesmo tempo, o uso do DoC demonstra que é possível estender o período de efeito útil por meio de algumas modificações no método. Portanto, há potencial e espaço para criatividade.
Considerações finais
Neste artigo, nos iniciamos em um algoritmo muito interessante com grande potencial, o dicotomia do controle (Dichotomy of Control, DoC). Este algoritmo foi apresentado pela equipe do Google como uma forma de aumentar a eficácia dos modelos ao trabalhar com ambientes estocásticos. O princípio fundamental do DoC consiste em dividir todos os fatores e resultados observáveis em dependentes e independentes das políticas do Agente. Assim, no processo de treinamento do modelo, focamos nos fatores que dependem das ações do Agente. E construímos uma política direcionada à maximização dos resultados levando em consideração a influência estocástica do ambiente.
Como parte deste artigo, adicionamos os princípios do DoC ao modelo transformador de decisões criado anteriormente. E, como consequência, observamos a melhora do desempenho do modelo na amostra de teste. Sim, o resultado alcançado ainda está longe dos resultados desejados. Mas a mudança positiva é claramente visível. Isso nos permite concluir sobre a eficácia da implementação dos princípios da dicotomia do controle.
Links
- Decision Transformer: Reinforcement Learning via Sequence Modeling
- Dichotomy of Control: Separating What You Can Control from What You Cannot
- Redes neurais de maneira fácil (Parte 34): Função quantil totalmente parametrizada
- Redes neurais de maneira fácil (Parte 58): Transformador de decisões (Decision Transformer—DT)
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor de coleta de exemplos |
| 2 | Study.mq5 | Expert Advisor | Expert Advisor para treinamento do agente |
| 3 | Test.mq5 | Expert Advisor | Expert Advisor para testar o modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código para programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13551
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Pense nisso...!
quantos PHDs estão trabalhando na goldmansachs? ou na hfts, ou em empresas de fundos de investimento?
se ao menos fosse ASSIM tão fácil!!!
Gostaria de agradecer ao autor pela enorme quantidade de ideias, é um Klondike para experimentos.
Também acho que os artigos são adequados como exemplos de métodos possíveis para o treinamento de redes neurais, mas não para a prática. Eu realmente aprecio o trabalho investido na biblioteca do próprio autor para criar e treinar redes neurais, e até mesmo com o uso de placas de vídeo, mas ela não pode ser usada de forma alguma para fins práticos, muito menos competir com tensorflow, keras, pytorch - na verdade, todos os modelos treinados com essas bibliotecas podem ser usados diretamente no mql5, usando o formato onnx.
Vou aplicar gradualmente as ideias do autor com a ajuda dessas bibliotecas modernas.
Também é necessário selecionar indicadores para os dados de entrada para o treinamento de redes neurais. O mais bem-sucedido para mim são as bandas de bollinger, e uso 48 desses indicadores como dados de entrada com diferentes configurações para redes recorrentes como a LSTM. Mas isso não é garantia de sucesso. Também treino 28 pares de moedas de cada vez e escolho os melhores, mas isso não é garantia de sucesso. Então, você precisa executar pelo menos 20 vezes o procedimento de treinamento, alterando o número de camadas e suas configurações nas redes neurais e, em cada estágio, selecionar os melhores modelos que se mostraram bem no testador de estratégias e remover os piores, e só assim poderá obter resultados razoáveis na prática.
Ao final, basta escolher, por exemplo, os 9 melhores pares de um total de 28 e negociá-los em uma conta real. Ao mesmo tempo, o Expert Advisor também deve ter em seu arsenal o gerenciamento de manobras, o que também não prejudicará a grade, ou seja, usamos as redes neurais como assistentes das boas ideias dos consultores sem redes neurais, o que já os torna inteligentes.
Olá, você poderia fornecer um link para o primeiro artigo para começar a ler/aprender, estou muito interessado no assunto
https://www.mql5.com/pt/articles/7447