
Нейросети — это просто (Часть 59): Дихотомия контроля (Dichotomy of Control — DoC)

Введение
Индустрия финансовых рынков представляет собой сложную и многогранную среду. Каждое событие и действие имеют свои корни в экономических фундаментальных процессах. Причину тех или иных событий модно найти в новостях, геополитических событиях, различных технических аспектах и многих других факторах. И зачастую, такие зависимости мы наблюдаем постфактум. В процессе же анализа рыночной ситуации мы наблюдаем лишь малую часть этих факторов. Что в целом делает финансовые рынки довольно сложной для анализа средой. Но все же мы выделяем некоторые, наиболее существенные на наш взгляд, инструменты, которые способны выделить основные тенденции. Прочие факторы мы относим на стохастичность окружающей среды.
В такой сложной среде обучение с подкреплением представляет собой мощный инструмент для разработки стратегий на финансовых рынках. Однако существующие методы, такие как Decision Transformer, могут оказаться недостаточно адаптивными в условиях высокой стохастичности. Что мы и наблюдали в практической части предыдущей статьи.
Напомню, что, в отличие от традиционных методов, Decision Transformer моделирует последовательности действий в контексте авторегрессионной модели желаемых вознаграждений. В процессе обучения модели выстраивается взаимосвязь между последовательностью состояний, действий, желаемого вознаграждения и фактическим результатом, получаемым от окружающей среды. Однако большое количество случайных факторы могут привести к несоответствию между обученной стратегией и желаемым будущим результатом.
Надо сказать, что с подобной проблемой сталкиваются многие методы обучения с подкреплением и не только. В качестве одного из вариантов решения данной проблемы команда Google в октябре 2022 года был представлен метод Dichotomy of Control.
1. Основы метода DoC
Дихотомия контроля — это логическая основа стоицизма. И подразумевает понимание того, что все существующее вокруг нас можно условно разделить на две части. Первая подвластна нам и полностью находятся под нашим контролем. Над второй мы не властны и события произойдут независимо от наших действий.
С первой областью мы работаем. А вторую принимаем как должное.
Подобные постулаты авторы метода "Dichotomy of Control" постарались внедрить в свой алгоритм. DoC позволяет разделить то, что подконтрольно стратегии (политике действий), и то, что находится вне ее контроля (стохастичность окружающей среды).
Но прежде, чем перейти к изучению метода я предлагаю вспомнить каким образом мы представляли траекторию в DT.
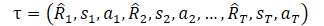
Здесь R1 («Return to go») представляет наше желание и не связано с начальным состояние S0. Наша обученная модель выбирает действие, которое дало желаемый результат на обучающей выборке. Но вероятность получения желаемого вознаграждения из текущего состояния может быть настолько мала, что действия Агента будут далеки от оптимальных.
А теперь давайте посмотрим «на мир широко открытыми глазами». В данном контексте «Return to go» является указанием Агенту к выбору стратегии поведения. Не кажется ли вам это похожим на навык в иерархических моделях или целеуказание в GCRL. Наверное подобные мысли посетили авторов метода DoC, и они предложили использовать некое скрытое состояние z(τ). Но, как вы знаете, подмена понятий не меняет сути. И вводится обучаемая модель для представления латентного состояния z(τ).
Ключевым наблюдением авторов метода является то, что z не должно содержать информации, связанной со стохастичностью окружающей среды. Оно не должно включать информацию о будущем Rt и St+1, которая неизвестна на момент предыдущей истории. Соответственно, в цель добавляется условное ограничение взаимной информации между z и каждой парой Rt и St+1 в будущем. Для удовлетворения данного ограничения взаимной информации мы воспользуемся методами контрастного обучения.
Далее мы вводим условное распределение ω(rt|τ0:t-1,st,at), параметризованное функцией энергии f.
Комбинируя это через коэффициенты Лагранжа, мы можем обучить π и z(τ) путем минимизации конечной цели DoC:
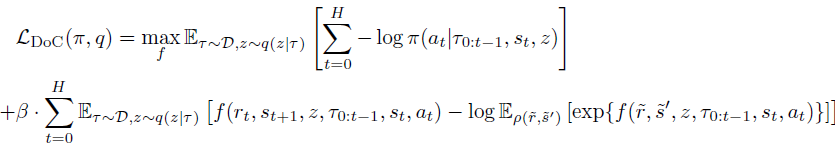
Применительно к методу Decision Transformer, политика, обученная DoC, требует подходящего условия z. Для выбора желаемой z, связанной с высоким ожидаемым вознаграждением, авторы метода предлагают:
- Выбрать большое количество потенциальных значений z;
- Оценить ожидаемое вознаграждение для каждого из этих значений z;
- Выбрать z с наивысшим ожидаемым вознаграждением и передать его в политику.
Чтобы обеспечить такую процедуру на этапе эксплуатации, добавляются 2 дополнительных компонента в формулировку метода. Во-первых, априорное распределение p(z|s0), из которого выбирается большое количество значений z. Во-вторых, функция ценности V(z), с помощью которой ранжируются потенциальные значения z. Эти компоненты обучаются путем минимизации следующей цели:
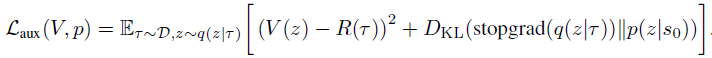
Обратите внимание на использование stop-gradient к q(z|τ) при обучении p, чтобы избежать регуляризации q по отношению к априорному распределению.
В статье "Dichotomy of Control: Separating What You Can Control from What You Cannot" приводится довольно много примеров, демонстрирующих значительное превосходство предложенного метода в различных стохастических средах.
Это довольно интересный момент, и я предлагаю проверить на практике возможность использования данного подхода для решения наших задач.
2. Реализация средствами MQL5
В практической части данной статьи мы разберем вариант реализации алгоритма "Dichotomy of Control" средствами MQL5. И сразу хочу обратить Ваше внимание, что рассматриваемая реализация является личной трактовкой предложенного метода. И в некоторых моментах она будет довольно далека от оригинального решения.
Прежде всего, данная реализация является логическим продолжением программ из предыдущей статьи. Мы внедряем предложенные механизм в созданный ранее код DT в попытках оптимизировать работу модели и повысить её эффективность.
Более того, мы постараемся немного упростить алгоритм DoC с сохранением основополагающих идей.
Как уже было сказано выше, авторы метода вводят некоторое латентное состояние вместо return-to-go. В процессе эксплуатации из априорного распределения p(z|s0) семплируется некоторый пакет таких латентных состояний, которые в последующем оцениваются с помощью функции ценности V(z). Практически это подразумевает, что мы из обучающей выборки извлекаем наиболее похожие состояния и выбираем латентное представление с наибольшим ожидаемым вознаграждением. И в соответствии с идеями дихотомии контроля, мы учитываем не только абсолютное значение вознаграждения, но и вероятность его получения.
Естественно, мы не будем каждый раз перебирать всю обучающую выборку. Вместо этого мы будем использовать предварительно обученные модели, которые аппроксимируют соответствующие функции из обучающей выборки. Но в любом случае семплирование большого числа латентных представлений с последующей их оценкой является довольно трудоемкой задачей. Можем ли мы это как-то упростить?
Давайте посмотрим на суть данных сущностей. Латентное представление z в контексте Decision Transformer является ожидаемым вознаграждением. Таким образом, функция ценности V(z) может быть блика самому латентному состоянию z. Тут может возникнуть идея исключить функцию ценности как класс и напрямую сравнивать латентные состояния между собой, но мы не пойдем на такой шаг.
Рассуждаем далее, априорное распределение p(z|s0) можно представить как вероятностное распределение использования того или иного латентного представления в конкретном состоянии окружающей среды. А вот здесь давайте вспомним про полностью параметризированную квантильную функцию (FQF). Она позволяет объединить вероятностное и количественное распределения. Именно её мы и будем использовать в модели генерации латентного представления.
Такое решение позволяет нам объединить априорное распределение и функцию стоимости. Более того, таким образом мы можем отказаться от семплирования пакете латентных состояний с последующей оценкой.
Аналогично мы поступаем с условным распределением ω(rt|τ0:t-1,st,at), параметризованным функцией энергии f.
Обратите внимание, что в обоих случаях мы генерируем латентное представление. И в целях экономии ресурсов мы будем создавать 2 модели, а воспользуемся одной в обоих случаях. И здесь надо вспомнить, что ω(rt|τ0:t-1,st,at) зависит от траектории. А следовательно, при построении модели мы должны учитывать её авторегрессионный характер, по аналогии с моделью Актера DT.
Архитектура обоих моделей описывается в методе CreateDescriptions. В парметрах метода мы передаем указатели на 2 динамических массива для описания архитектур моделей. Сразу скажу, что отличия в архитектурах моделей будут не значительные. Но все же они будут. Поэтому мы и создаем 2 отдельные архитектуры, а не 1 общую Первой мы создаем архитектуру модели Актера. Слой исходных данных, как и в предыдущей статье, содержит только изменяемые компоненты состояния окружающей среды (данные 1 бара).
bool CreateDescriptions(CArrayObj *agent, CArrayObj *rtg) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (NRewards + BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Далее идет слой пакетной нормализации, в котором осуществляется предварительная обработка сырых исходных данных.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Нормализованные данные проходят через слой эмбединга и добавляются в стек.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NActions,NRewards}; ArrayCopy(descr.windows,temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
В стеке содержатся эмбединги данных за весь анализируемый период. И мы пропускаем их через блок многоголового разреженного внимания.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count*5; descr.window = prev_wout; descr.step = 4; descr.window_out = 32; descr.layers = 8; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
После блока внимания мы снижаем размерность данных при помощи сверточного слоя.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; }
И пропускаем данные через блок принятия решений, который состоит из 3 полносвязных слоев.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
На выходе модели мы используем латентный слой VAE для придания стохастичности политике Агента.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Далее следует описание архитектуры модели латентного представления. Как уже было сказано выше, архитектура модели очень похожа на предыдущую. Но она анализирует меньший объем данных. Как можно заметить из представленных в теоретической части описания, функция условного распределения ω(rt|τ0:t-1,st,at) генерирует латентное представление на основании текущего состояния, действий агента и предшествующей траектории. Полученное латентное состояние мы впоследствии подаем на вход Агента. Именно на размер латентного состояния мы будем подавать меньше данных на вход второй модели.
//--- RTG if(!rtg) { rtg = new CArrayObj(); if(!rtg) return false; } //--- rtg.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Сырые исходные данные так же проходят первичную обработку в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Далее следует эмбединг данных. И тут мы так же наблюдаем изменение структуры исходных данных.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NActions}; ArrayCopy(descr.windows,temp); } prev_wout = descr.window_out = EmbeddingSize; if(!rtg.Add(descr)) { delete descr; return false; }
Ниже мы повторяем структуры блока разреженного внимания. Но обратите внимание, на уменьшения количества анализируемых элементов в последовательности. Если Агент анализировал 5 сущностей на каждом баре, то в данной модели их только 4. Чтобы в этом моменте уйти от ручного управления количеством элементов на каждом баре, мы можем на предыдущем шаге записывать в отдельную переменную размер массива окон исходных данных слоя эмбединга.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count=descr.count = prev_count*4; descr.window = prev_wout; descr.step = 4; descr.window_out = 32; descr.layers = 8; descr.probability = Sparse; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Как и в предыдущей модели, после слоя разреженного внимания мы снижаем размерность анализируемых данный с помощью сверточного слоя. И передаем полученные данные на блок принятия решения.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Только теперь, на выходе блока принятия решения мы используем слой полностью параметризированной квантильной функции. Как и обсуждалось выше.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NRewards; descr.window_out = 32; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- return true; }
После описания архитектуры моделей мы переходим работе над советником взаимодействия с окружающей средой и первичного сбора данных для обучения моделей "\DoC\Research.mq5". Надо сказать, что особенности использования метода дихотомии контроля заметны даже при сборе обучающих данных. Если ранее в аналогичных советниках мы использовали только модель Агента и остальные модели подключались только на стадии обучения, то сейчас мы будем использовать обе модели на всех этапах. Начиная от сбора первичных данных и заканчивая тестированием обученной модели. Ведь, генерируемое второй моделью латентное состояние является частью исходных данных нашего Агента.
В рамках статьи мы не будем подробно рассматривать весь код советника. Большая часть его методов перенесена без изменений из предыдущих статей. Остановимся лишь на методе обработки тиков OnTick, в котором и организован основной процесс сбора данных.
Вначале метода мы, как обычно, проверяем наступление событие открытия нового бара и, при необходимости, обновляем исторические данные ценового движения и показателей анализируемых индикаторов.
Напомню, что все операции нашего советника выполняются лишь на открытии нового бара. Алгоритм наших моделей не контролирует изменение каждого тика. Все обучаемые модели оперируют с историческими данными таймфрейма H1. Однако выбор таймфрейма сугубо субъективное решение и не ограничивается архитектурами моделей. Нужно соблюдать лишь требование, чтобы обучение и эксплуатация моделей осуществлялись на одном таймфрейме и том же инструменте. Перед эксплуатацией моделей, предварительно обученных на другом таймфрейме и/или другом инструменте, необходимо их дообучение на целевых таймфрейме и финансовом инструменте.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Далее мы подготавливаем буфер исходных данных. Вначале мы в него запишем исторические данные движения цены финансового инструмента и показатели анализируемых индикаторов.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Затем добавим информацию о текущем состоянии счета и открытых позициях.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Тут же мы добавляем временную метку.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
И последнее действие Агента, которое нас привело в текущее состояние окружающей среды. При обработке первого бара данный вектор заполнен нулевыми значениями.
//--- Prev action
bState.AddArray(AgentResult);
Далее нам следовало бы добавить целеуказание Агенту в виде "Return-To-Go". Но в рамках алгоритма DoC нам еще предстоит сгенерировать латентное состояние. Однако, собранных данных достаточно для работы модели генерации латентного состояния, и мы осуществляем её прямой проход.
//--- Return to go if(!RTG.feedForward(GetPointer(bState))) return;
После успешного выполнения прямого прохода модели и загружаем полученное латентное представление и добавляем его в буфер исходных данных.
RTG.getResults(Result); bState.AddArray(Result);
На данном этапе мы сформировали полный пакет исходных данных для модели нашего Агента, и мы можем вызвать метод прямого прохода для генерации оптимальных действий в соответствии с ранее выученной политикой. И, как всегда, не забываем контролировать процесс выполнения операций.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
Здесь завершается работа моделей на текущем баре и начинается взаимодействие с окружающей средой. Сначала мы проведем предварительную обработку и дешифровку результатов работы Агента. В предыдущих статьях мы определились с наличием открытых позиций только в одном направлении. Поэтому, первое что мы сделаем, это определим дельту объемов из результатов Агента. И разницу сохраним для направления с максимальным объемом. Во втором направлении обнулим объем операции.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } AgentResult = temp;
Далее мы проверяем необходимость совершения операций на покупку финансового инструмента. Здесь мы проверяем объем и стоп уровни операции, сгенерированной Агентом. Если объем операции меньше минимально возможной позиции или уровни стоп-лосса / тейк-профита не соответствуют минимальным требованиям брокера, то это сигнал к отсутствию открытия длинных позиций. И в этот момент мы должны закрыть все ранее открытые длинные позиции. Конечно если такие существуют.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Если же по решению Агента необходимо наличие длинной позиции, то тут возможны варианты в зависимости от текущего состояния счета:
- Если позиция уже открыта и её объем превышает указанный Агентом, то мы закрываем излишний объем. А для оставшейся позиции, при необходимости, корректируем стоп уровни.
- Уровень открытой позиции равен указанному Агентом — проверяем и, при необходимости, корректируем стоп-уровни.
- Отсутствует открытая позиция или её объем меньше указанного — открываем недостающий объем и корректируем стоп-уровни.
else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Аналогичные операции повторяем для коротких позиций.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
После взаимодействия с окружающей средой нам остается оцифровать результат предыдущих операций и сохранить данные в буфер воспроизведения опыта.
//--- int shift=BarDescr*(NBarInPattern-1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift+1]-1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
На этом мы завершаем работу над советником взаимодействия с окружающей средой и сбора данных обучающей выборки. А с полным кодом советника и всех его функций вы самостоятельно можете ознакомиться во вложении к статье.
А мы переходим к рассмотрению советника обучения моделей "\DoC\Study.mq5". В методе инициализации советника OnInit мы сначала пытаемся загрузить обучающую выборку. Так как мы осуществляем обучение моделей офф-лайн, то эта обучающая выборка для нас является единственном источником данных. Следовательно, при какой-либо ошибке загрузки обучающих данных дальнейшая работа советника не имеет смысла, и мы возвращаем результат ошибки инициализации программы. Предварительно отправим в журнал сообщение с идентификатором возникшей ошибки.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Следующим этапом осуществляется загрузка предварительно обученных моделей. При отсутствии таковых происходит создание и инициализация новых моделей.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTG.Load(FileName + "RTG.nnw", dtStudied, true)) { Print("Init new models"); CArrayObj *agent = new CArrayObj(); CArrayObj *rtg = new CArrayObj(); if(!CreateDescriptions(agent,rtg)) { delete agent; delete rtg; return INIT_FAILED; } if(!Agent.Create(agent) || !RTG.Create(rtg)) { delete agent; delete rtg; return INIT_FAILED; } delete agent; delete rtg; }
Обратите внимание, что при ошибке чтения одной из моделей происходит создание и инициализация обоих моделей. Это сделано с целью сохранения совместимости моделей.
Далее следует блок проверки архитектуры моделей. Здесь мы проверяем соответствие размеров слоев исходных и результатов обоих моделей. Сначала проверяем архитектуру Агента.
//--- Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the agent does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Agent doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; }
А затем повторяем действия для модели латентного представления.
RTG.getResults(Result); if(Result.Total() != NRewards) { PrintFormat("The scope of the RTG does not match the rewards count (%d <> %d)", NRewards, Result.Total()); return INIT_FAILED; } //--- RTG.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of RTG doesn't match state description (%d <> %d)", Result.Total(), (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } RTG.SetUpdateTarget(1000000);
Здесь стоит еще обратить внимание, что в процессе обучения модели латентного представления мы не планируем использовать целевую модель, которая предусмотрена архитектурой FQF. Поэтому мы сразу задаем достаточно большим период обновления целевой модели. Этот прием позволит нам исключить лишние операции в процессе обучения моделей.
После успешного выполнения всех выше указанных операций нам остается лишь сгенерировать событие начала процесса обучения и завершить метод инициализации советника.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
В методе деинициализации советника OnDeinit обязательно добавляем сохранение модели латентного представления. Помните, в отличии от олимпийского "главное участие, а не победа", нам нужен именно результат, а не процесс обучения.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Agent.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); RTG.Save(FileName + "RTG.nnw", TimeCurrent(), true); delete Result; }
И переходим к методу обучения моделей Train. В теле метода мы определяем количеству загруженных траекторий в буфере воспроизведения опыта и сохраняем в локальную переменную текущее состояния счетчика тиков для контроля времени в процессе обучения моделей.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Далее, как и в предыдущей статье мы организовываем систему циклов. Внешний цикл отсчитывает количество пакетов обучения моделей. В его теле мы случайным образом выбираем траекторию из буфера воспроизведения опыта и состояние на этой траектории в качестве начальной точки обучения. Тут же мы очищаем стеки обоих моделей и обнуляем вектор последних действий Агента. Данные операции являются существенными при обучении авторегрессионных моделей и обязательны для выполнения перед каждым переходом к новому отрезку траектории для обучения моделей.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; } Actions = vector<float>::Zeros(NActions); Agent.Clear(); RTG.Clear();
При обучении автореграссионных моделей большую роль играет сохранение последовательности операций в процессе обучения. Именно для выполнения этого требования мы создаем вложенный цикл, в котором мы будем подавать на вход моделей исходные данные в порядке хронологии их совершения при взаимодействии с окружающей средой. Это позволит нам максимально точно воспроизвести поведение Агента и выстроить оптимальный процесс обучения.
for(int state = i; state < MathMin(Buffer[tr].Total - 2,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Для настраивания максимально правильного процесса обучения нам необходимо быть уверенным в полном заполнении буфера стека последовательными данными. Ведь именно так будет происходить при эксплуатации модели на достаточно протяженном временном отрезке. Поэтому вложенный цикл мы настраиваем на число итераций в 3 раза больше длины стека анализируемых данных. Однако, для предотвращения возникновения ошибки выхода за пределы массива сохраненных данных траектории, мы добавляем проверку на завершение траектории.
Далее в теле цикла мы заполняем буфер исходных данных в строгом соответствии с последовательностью записи данных в процессе сбора обучающей выборки. Здесь стоит отметить, что эти процессы должны соответствовать структуре исходных данных, которую мы указали в архитектуре моделей при описании слоя эмбединга.
Первыми в буфер мы добавляем исторические данные о движении цены финансовго инструмента и показатели анализируемых индикаторов. И если в процессе сбора данных мы загружали их из терминала, то теперь мы можем воспользоваться уже готовыми данными их соответствующего массива буфера воспроизведения опыта.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
А вот процесс создания описания состояния счета и временной метки практически полностью повторяет аналогичные процессы в советнике сбора обучающих данных.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
Далее мы добавляем в буфер вектор действий Агента на предыдущем шаге и вызываем метод прямого прохода модели генерации латентного состояния. И обязательно проверяем результат выполнения операций.
//--- Prev action State.AddArray(Actions); //--- Return to go if(!RTG.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
После успешного выполнения метода прямого прохода модели генерации латентного состояния мы можем сразу осуществить обновление её параметров. А обучать модель мы будем на прогнозирование будущего вознаграждения. Такой подход соответствует алгоритму DT и не противоречит алгоритму DoC.
Result.AssignArray(Buffer[tr].States[state+1].rewards); if(!RTG.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Здесь стоит обратить внимание ещё на один момент: на данном этапе мы отказались от использования метода CAGrad для корректировки направления градиента ошибки в векторе результатов. Это связано с тем, что помимо абсолютных значений вознаграждений мы стремимся выучить их вероятностное распределение в недрах слоя FQF. А корректировка целевых значений для оптимизации направления градиента ошибки способно исказить искомое распределение.
После оптимизации параметров модели латентного представления мы переходим к обучению модели политики нашего Агента. Мы добавляем в буфер исходных данных фактически полученное вознаграждение за переход в следующее состояние. Именно так мы поступали при обучении политики Агента Decision Transformer. Более того, в части обучения политики Агента мы полностью повторяем алгоритм Decision Transformer. Ведь нам предстоит обучить Агента сопоставлять совершенные действия из отдельных состояний и ожидаемое вознаграждение. Точно так же, как и в алгоритме Decision Transformer. Основной же вклад алгоритма Dichotomy of Control в создании корректного целеуказания в виде латентного представления, которое формируется второй моделью.
//--- Policy Feed Forward State.AddArray(Buffer[tr].States[state+1].rewards); if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Следующим шагом мы обновляем параметры модели Агента для генерации фактически совершенных действий, которые привели к получению фактического вознаграждения, указанного в исходных данных Агента в качестве целеуказания.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
На это раз мы уже используем метод CAGrad для оптимизации направления вектора градиента ошибки и повышения скорости сходимости модели.
После успешного обновления параметров обоих моделей нам остается проинформировать пользователя о ходе процесса обучения и перейти к следующей итерации обучения.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "RTG", iter * 100.0 / (double)(Iterations), RTG.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
По завершению всех итераций нашей системы циклов мы считаем процесс обучения завершенным. Очищаем поле комментариев на графике. Выводим в журнал результаты процесса обучения и инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "RTG", RTG.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем рассмотрение советника обучения моделей "\DoC\Study.mq5". А с полным его кодом, как и других программ, используемых в статье, вы можете самостоятельно ознакомиться во вложении. Там же вы найдете код советника тестирования обученных моделей "\DoC\Test.mq5". Его код практически полностью повторяет советник взаимодействия с окружающей средой и сбора обучающих данных. Поэтому мы не будем сейчас останавливаться на рассмотрении его методов. А на все возможные ваши вопросы я с удовольствием отвечу в ветке форума, соответствующей данной статье.
3.Тестирование
После завершения работы над созданием советников, в которых мы реализовали наше видение алгоритма Dichotomy of Control мы переходим к этапу тестирования проделанной работы. На этом этапе мы осуществим сбор обучающих данных. Обучим модели. И проверим результаты их работы вне периода обучающей выборки. Использование новых данных для тестирования моделей позволяет максимально нам приблизить тестирование моделей к реальным условиям. Ведь наша цель получить модель, способную генерировать реальную прибыль на финансовых рынках в обозримом будущем.
Как всегда, обучение моделей осуществляется на исторических данных за первые 7 месяцев 2023 года. Для всех тестов мы используем один из наиболее волатильных финансовых инструментов EURUSD, таймфрейм H1. Параметры всех анализируемых индикаторов не меняются от начала нашего цикла статей и используются по умолчанию.
Процесс обучения моделей у нас итерационный и состоит из нескольких последовательных итераций сбора обучающих данных и обучения моделей.
Хочется еще раз акцентировать внимание на необходимости повторений последовательных операций сбора обучающих данных и обучения моделей. Несомненно, вы можете сначала собрать обширную базу обучающих примеров и затем долго обучать на ней модели. Но ресурсы наши не безграничны, и мы физически не можем собрать базу примеров, способную полностью покрыть пространство действий и ответных вознаграждений. Тем более, что мы работаем с непрерывным пространством действий. Добавим к этому большую стохастичность изучаемой среды. А значит в процессе обучения велика вероятность попадания модели в неизученное пространство. И для уточнения наших знаний об окружающей среде нам потребуется дополнительные итерации взаимодействия с ней.
Еще довольно существенный момент, при первичном сборе обучающих данных каждый Агент использует случайную политику. Что позволяет максимально полно изучить окружающую среду. А как вы знаете, одной из основных проблем обучения с подкреплением является поиск баланса между исследованием и эксплуатацией. Очевидно, что здесь мы наблюдаем 100% исследования. При повторном взаимодействии с окружающей средой и сборе обучающих данных Агенты используют уже предварительно обученную политику. И область исследования сужается до размеров стохастичности выученной политики.
Чем чаще мы будем осуществлять итерации взаимодействия со средой, тем более плавно будет осуществляться сужения области стохастичности модели. И вовремя полученная обратная связь может скорректировать направление обучения. Тем самым повышаются наши шансы достичь глобального максимума ожидаемого вознаграждения.
В случае же длительных интервалов офф-лайн обучения мы рискуем сразу максимально снизить стохастичность действий модели, придя к некоторому локальному экстремуму без возможности скорректировать направление обучения модели.
Также следует обратить внимание, что в своих моделях мы использовали блок разреженного внимания, обучение которого вдвойне сложный и длительный процесс. Первое, это все-таки блок Self-Atention, который имеет сложную структуру. А сложная структура требует длительного и тщательного обучения.
Второй момент, это использование разреженного внимания. Следовательно, как и в случае с Dropout, не все нейроны задействованы в полной мере на каждой итерации обучения. Как следствие, в некоторые моменты градиент не проходит до нейронов, и они выпадают из процесса обучения. Выпадение нейронов из процесса обучения происходит довольно стохастично. И для полного обучения модели требуется дополнительное количество итераций.
В то же время использование блоков разреженного внимание сокращает время на одну итерацию обучения и позволяет сделать модель более гибкой.
Но вернемся к результатам обучения и тестирования наших моделей. Для тестирования обученной модели мы использовали исторические данные за август 2023 года. Инструмент EURUSD, таймфрейм H1. Август является месяцем, который непосредственно следует за периодом обучения. Как и было сказано выше, таким образом мы создаем условия для тестирования модели максимально приближенные к промышленной эксплуатации модели. По результатам тестирования модели все же удалось получить прибыль. Хотя и не большую. Напомню, что в предыдущей статье при аналогичных условиях модель, обученная по алгоритму трансформера решений, не смогла получить прибыль. Добавление подходов DoC позволяет поднять практически ту же модель на качественно иной уровень.


Но несмотря на полученную прибыль, результаты работы модели не столь радужные и однозначные. Если мы посмотрим на график баланса в процессе тестирования обученной модели, то можно заметить следующие тенденции:
- В первой декаде месяца мы наблюдаем довольно резкий рост баланса порядка 20%.
- Во второй декаде мы наблюдаем колебания уровня баланса в районе достигнутых результатов. Убыточные периоды сменяются довольно резкими подъемами. Амплитуда колебаний достигает 10% от баланса.
- В третей декаде наблюдается серия убыточных сделок.
В результате за весь период обучения мы имеем порядка 43% прибыльных позиций. При этом максимальная прибыльная сделка более чем в 2 раза превышает максимальный убыток. А средняя прибыльная сделка на 1/3 превышает средний убыток. Как следствие профит-фактор зафиксирован на уровне 1.01, а фактор восстановления 0.03.
Сравнивая результаты тестирования модели с использование принципов DoC и без, можно заметить резкий рост баланса в первой декаде месяца в обоих случаях. Применение подходов DoC позволило сохранить достигнутый результат во второй декаде месяца. В то время как без использования DoC череда убыточных сделок началась сразу.
Из этого складывается мое субъективное мнение, что авторегрессионный подход позволяет достигать довольно хороших результатов. Но, к сожалению только на коротком временном промежутке. В то же время использование DoC демонстрирует, что период полезного эффекта можно увеличить путем некоторых доработок метода. А значит есть потенциал и место для творчества.
Заключение
В данной статье мы познакомились с одним очень интересным алгоритмом с большим потенциалом Дихотомия контроля (Dichotomy of Control — DoC). Данный алгоритм был представлен командой Google в качестве средства повышения эффективности моделей при работе со стохастическими средами. Основной принцип DoC заключается в разделение всех наблюдаемых факторов и результатов на зависящие и независящие от политика Агента. Тем самым в процессе обучения модели мы акцентируем внимание не факторах, зависящих от действий Агента. И выстраиваем политику, направленную на максимизацию результатов с учетом стохастического влияния окружающей среды.
В рамках статьи мы добавили принципы DoC в ранее созданную модель Decision Transformer. И, как следствие, наблюдаем улучшение работы модели на тестовой выборке. Да, достигнутый результат ещё далек от желаемых результатов. Но положительный сдвиг явно заметен. Из этого можно сделать вывод об эффективности внедрения принципов Dichotomy of Control.
Ссылки
- Decision Transformer: Reinforcement Learning via Sequence Modeling
- Dichotomy of Control: Separating What You Can Control from What You Cannot
- Нейросети — это просто (Часть 34): Полностью параметризированная квантильная функция
- Нейросети — это просто (Часть 58): Трансформер решений (Decision Transformer—DT)
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mq5 | Советник | Советник обучения агента |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Запускаем MetaTrader VPS впервые — пошаговая инструкция
Запускаем MetaTrader VPS впервые — пошаговая инструкция
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
think about it...!
how many PHDs are working at goldmansachs? or hfts, or quantfund firms, !
if only it was THIS easy!!!
Хотел сказать спасибо автору за огромное количество идей, это просто Клондайк для экспериментов.
Также я думаю что статьи подходят в качестве примеров возможных методик обучения нейронных сетей, но ни как для практики. Я очень ценю труд вложенный на созданием автором собственной библиотеки для создания и обучения нейронных сетей да еще и с применением видеокарт, но она ни как не может быть использована в практических целях, и тем более конкурировать с tensorflow, keras, pytorch - Собственно все модели обученные с помощью этих библиотек уже можно давно использовать напрямую в mql5, с помощью формата onnx.
Я постепенно буду по возможности применять идеи автора с помощью этих современных библиотек.
Также нужно гораздо точный подбор индикаторов для входных данных обучения нейросетей, у меня самый удачный это bollinger bands, причем я использую сразу 48 таких индикаторов в качестве входных данных с разными настройками для рекуррентных сетей типа LSTM. Но и это не залог успеха, еще я обучаю 28 валютных пар за раз и выбираю лучшие, но и это еще не залог успеха. Далее нужно прогнать хотя бы раз 20 процедуру обучения, меняя количество слоев и их настроек в нейросетях, и на каждом этапе отбирать лучшие получившиеся модели которые себя показали хорошо в тестере стратегий, а худшие убирать, и только тогда можно добиться вменяемых результатов на практике.
В конце просто выбираем например лучшие 9 пар из 28 и торгуем ими на реальном счете, при этом советник должен также иметь у себя в арсенале мани менеджмент, не помешает сетка также, то есть используем нейросети как помощники уже к хорошим идеям советников без нейронных сетей, тем самым делая их умными уже.
Здравствуйте, не могли бы вы дать ссылку на 1 статью, чтобы начать читать/изучать, мне очень интересна эта тема
https://www.mql5.com/ru/articles/7447