
Redes neuronales: así de sencillo (Parte 59): Dicotomía de control (DoC)

Introducción
La industria de los mercados financieros supone un entorno complejo y multifacético. Cada evento y acción tiene sus raíces en procesos económicos fundamentales. El motivo de determinados acontecimientos se puede encontrar en las noticias: acontecimientos geopolíticos, diversos aspectos técnicos y muchos otros factores, y con frecuencia observamos tales dependencias después del hecho. En el proceso de análisis de la situación del mercado, observamos solo una pequeña parte de estos factores, lo que en general hace que los mercados financieros sean un entorno bastante difícil de analizar. Pero aún así, destacaremos algunas de las herramientas más importantes que, en nuestra opinión, pueden resaltar las principales tendencias. Los otros factores los atribuiremos a la estocasticidad del entorno.
En un entorno tan complejo, el aprendizaje por refuerzo supondrá una poderosa herramienta para desarrollar estrategias en los mercados financieros. No obstante, los métodos existentes, tales como Decision Transformer, podrían no ser lo suficientemente adaptables en entornos altamente estocásticos. Esto es lo que observamos en la parte práctica del artículo anterior.
Permítanme recordarles que, a diferencia de los métodos tradicionales, el Decision Transformer modela secuencias de acciones en el contexto de un modelo autorregresivo de recompensas deseadas. Durante el entrenamiento del modelo, se construye una relación entre la secuencia de estados, acciones y recompensas deseadas y el resultado real obtenido del entorno. No obstante, un gran número de factores aleatorios pueden generar una discrepancia entre la estrategia entrenada y el resultado futuro deseado.
Debemos decir que muchos métodos de aprendizaje por refuerzo y otros se enfrentan a un problema similar. Como una de las opciones para solucionar este problema, el equipo de Google presentó en octubre de 2022 el método Dichotomy of Control.
1. Conceptos básicos del método DoC
La dicotomía del control representa la base lógica del estoicismo, e implica comprender que todo lo que existe a nuestro alrededor se puede dividir en dos partes. La primera está sujeta a nosotros y está completamente bajo nuestro control. No tenemos control sobre la segunda y los acontecimientos sucederán independientemente de nuestras acciones.
Trabajaremos con la primera zona, y daremos por supuesta la segunda.
Los autores del método "Dichotomy of Control" intentaron implementar postulados similares en su algoritmo. DoC permite separar lo que está bajo el control de la estrategia (política de acción) y lo que queda fuera de su control (estocasticidad del entorno).
Pero antes de proceder a estudiar el método, recordemos cómo representamos la trayectoria en DT.
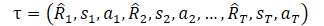
Aquí R1 («Return to go») representa nuestro deseo y no está relacionado con el estado inicial S0. Nuestro modelo entrenado seleccionará la acción que ha producido el resultado deseado en el conjunto de entrenamiento. Sin embargo, la probabilidad de obtener la recompensa deseada del estado actual puede ser tan pequeña que las acciones del Agente estarán lejos de ser óptimas.
Ahora debemos mirar el mundo con los ojos bien abiertos. En este contexto, “Return to go” es una instrucción para que el Agente elija una estrategia de comportamiento. ¿No parece esto similar a la habilidad en los modelos jerárquicos o la orientación en GCRL? Probablemente a los autores del método DoC se les hayan ocurrido pensamientos similares y hayan propuesto utilizar un cierto estado oculto z(τ). Pero, como sabrá, la sustitución de conceptos no cambia la esencia; en este caso, se introducirá un modelo entrenable para representar el estado latente z(τ).
La observación clave de los autores del método es que z no deberá contener información relacionada con la estocasticidad del entorno. No deberá incluir información sobre el futuro Rt y St+1que se desconozca en el momento de la historia anterior. En consecuencia, se añadirá al objetivo una restricción condicional sobre la información mutua entre z y cada par Rty St+1 en el futuro. Para satisfacer esta restricción de información mutua, usaremos métodos de aprendizaje por contraste.
A continuación, introducimos la distribución condicional ω(rt|τ0:t-1,st,at),parametrizada por la función de energía f.
Combinando esto a través de los coeficientes de Lagrange, podremos entrenar π y z(τ) minimizando el objetivo final de DoC:
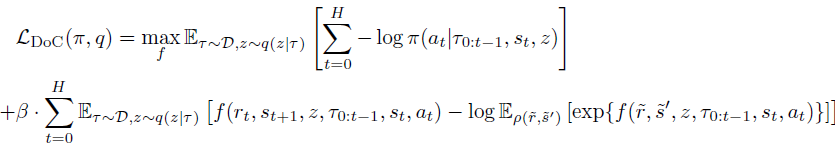
Aplicado al método Decision Transformer, la política entrenada por DoC requiere una condición adecuada z. Para seleccionar la z deseada vinculada con una recompensa esperada alta, los autores del método sugieren:
- Seleccionar una gran cantidad de valores z potenciales;
- Estimar la recompensa esperada para cada uno de estos valores de z;
- Seleccionar z con la recompensa esperada más alta y transmitirla a la política.
Para garantizar este procedimiento durante la fase operativa, se añadirán 2 componentes adicionales a la formulación del método. Primero, la distribución previa p(z|s0) de la cual se seleccionará una gran cantidad de valores z. En segundo lugar, la función de valor V(z), que clasificará los valores potenciales de z. Estos componentes se entrenarán minimizando el siguiente objetivo:
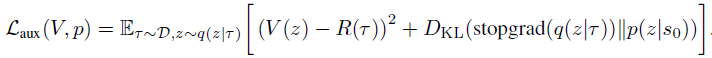
Tenga en cuenta el uso de stop-gradient en q(z|τ) al entrenar p para evitar regularizar q con respecto a la distribución anterior.
En el artículo "Dichotomy of Control: Separating What You Can Control from What You Cannot", hay bastantes ejemplos que demuestran la importante superioridad del método propuesto en diversos entornos estocásticos.
Este es un punto bastante interesante y propongo probar en la práctica la posibilidad de usar este enfoque para resolver nuestros problemas.
2. Implementación usando MQL5
En la parte práctica de este artículo analizaremos la implementación del algoritmo "Dichotomy of Control" utilizando MQL5. Y me gustaría llamar inmediatamente su atención sobre el hecho de que la implementación en cuestión es una interpretación personal del método propuesto, y en algunos momentos estará bastante lejos de la solución original.
En primer lugar, esta implementación será una continuación lógica de los programas del artículo anterior. Implementaremos los mecanismos propuestos en el código DT creado previamente en un intento de optimizar el rendimiento del modelo y aumentar su eficiencia.
Además, intentaremos simplificar un poco el algoritmo DoC manteniendo las ideas fundamentales.
Como hemos mencionado antes, los autores del método introducen un estado latente en lugar de un retorno al inicio. Durante la operación, se mostrará un determinado paquete de dichos estados latentes a partir de la distribución anterior p(z|s0), que posteriormente se estimarán utilizando la función de valor V(z). En la práctica, esto significa que extraeremos los estados más similares del conjunto de entrenamiento y seleccionaremos la representación latente con la recompensa esperada más alta. Y según las ideas de la dicotomía de control, consideraremos no solo el valor absoluto de la recompensa, sino también la probabilidad de recibirla.
Naturalmente, no iteraremos todo el conjunto de entrenamiento cada vez. En su lugar, utilizaremos modelos previamente entrenados que se aproximarán a las características correspondientes del conjunto de entrenamiento. Pero en cualquier caso, muestrear un gran número de representaciones latentes y luego estimarlas es una tarea bastante laboriosa. ¿Podemos simplificar esto de alguna forma?
Veamos la esencia de estas entidades. La representación latente z en el contexto del Decision Transformer será la recompensa esperada. Por tanto, la función de valor V(z) podría ser un reflejo del propio estado latente z. Aquí podría surgir la idea de excluir la función de valor como clase y comparar directamente los estados latentes entre sí, pero no daremos ese paso.
Argumentaremos además que la distribución previa p(z|s0) puede representarse como una distribución de probabilidad del uso de una u otra representación latente en un estado específico del entorno. Pero aquí debemos recordar la función cuantílica totalmente parametrizada (FQF). Esta permite combinar distribuciones de probabilidad y cuantitativas. Y precisamente esto es lo que usaremos en el modelo de generación de representación latente.
Esta solución nos permitirá combinar la distribución previa y la función de coste. Además, de esta forma podremos evitar muestrear un lote de estados latentes y luego estimarlos.
Procederemos de forma similar con la distribución condicional ω(rt|τ0:t-1,st,at),parametrizada por la función de energíaf.
Nótese que en ambos casos estaremos generando una representación latente, y para ahorrar recursos crearemos 2 modelos y usaremos uno en ambos casos. Y aquí deberemos recordar queω(rt|τ0:t-1,st,at) depende de la trayectoria. En consecuencia, a la hora de construir un modelo, deberemos considerar su naturaleza autorregresiva, por analogía con el modelo del Actor DT.
La arquitectura de ambos modelos se describe en el método CreateDescriptions. En los parámetros del método transmitiremos los punteros a 2 arrays dinámicos para describir las arquitecturas del modelo. Diremos de inmediato que las diferencias en las arquitecturas del modelo no serán significativas, pero aún así lo serán. Por eso crearemos 2 arquitecturas separadas y no una común. Primero, crearemos la arquitectura del modelo del Actor. La capa de datos de origen, como en el artículo anterior, contendrá solo componentes variables del estado del entorno (los datos de 1 barra).
bool CreateDescriptions(CArrayObj *agent, CArrayObj *rtg) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (NRewards + BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Luego vendrá la capa de normalización por lotes, que preprocesará los datos de origen sin procesar.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Los datos normalizados pasarán a través de la capa de incorporación y se añadirán a la pila.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NActions,NRewards}; ArrayCopy(descr.windows,temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
La pila contendrá incorporaciones de datos para todo el periodo analizado. Transmitiremos estos a través de un bloque de atención dispersa multi-cabeza.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count*5; descr.window = prev_wout; descr.step = 4; descr.window_out = 32; descr.layers = 8; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Después del bloque de atención, reduciremos la dimensionalidad de los datos utilizando una capa convolucional.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; }
Y transmitiremos los datos a través de un bloque de toma de decisiones, que constará de 3 capas completamente conectadas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
En la salida del modelo, utilizaremos la capa latente VAE para hacer que la política del Agente sea estocástica.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Lo siguiente será una descripción de la arquitectura del modelo de representación latente. Como hemos mencionado antes, la arquitectura del modelo es muy similar a la anterior, pero analizará una cantidad menor de datos. Como podemos ver por las funciones presentadas en la parte teórica de la descripción, la función de distribución condicional ω(rt|τ0:t-1,st,at) genera una representación latente basada en el estado actual, las acciones del agente y la trayectoria anterior. Posteriormente enviaremos el estado latente resultante a la entrada del Agente. Precisamente al tamaño del estado latente suministraremos menos datos a la entrada del segundo modelo.
//--- RTG if(!rtg) { rtg = new CArrayObj(); if(!rtg) return false; } //--- rtg.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr*NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Los datos de origen sin procesar también se someterán a un procesamiento primario en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Luego vendrá la incorporación de datos. Y aquí también observaremos un cambio en la estructura de los datos originales.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr*NBarInPattern,AccountDescr,TimeDescription,NActions}; ArrayCopy(descr.windows,temp); } prev_wout = descr.window_out = EmbeddingSize; if(!rtg.Add(descr)) { delete descr; return false; }
A continuación repetiremos las estructuras del bloque de atención dispersa, pero preste atención a la reducción del número de elementos analizados en la secuencia. Si el Agente ha analizado 5 entidades en cada barra, entonces en este modelo solo habrá 4 de ellas. Para evitar el control manual del número de elementos en cada barra en este momento, podemos, en el paso anterior, registrar el tamaño del array de ventanas de los datos de origen de la capa de incorporación en una variable aparte.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count=descr.count = prev_count*4; descr.window = prev_wout; descr.step = 4; descr.window_out = 32; descr.layers = 8; descr.probability = Sparse; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Como en el modelo anterior, después de la capa de atención dispersa, reduciremos la dimensionalidad de los datos analizados utilizando una capa convolucional. Y transmitiremos los datos recibidos al bloque de toma de decisiones.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Solo que ahora, en la salida del bloque de toma de decisiones, usaremos una capa de una función cuantil completamente parametrizada, como discutimos anteriormente.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NRewards; descr.window_out = 32; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- return true; }
Tras describir la arquitectura de los modelos, pasaremos a trabajar con el asesor de interacción con el entorno y recopilación primaria de datos para los modelos de entrenamiento “\DoC\Research.mq5”. Debemos decir que las características de uso del método de dicotomía de control se perciben incluso al recopilar los datos de entrenamiento. Si antes en asesores similares usábamos solo el modelo Agente y los otros modelos estaban conectados solo en la etapa de entrenamiento, ahora usaremos ambos modelos en todas las etapas, comenzando por la recopilación de datos primarios y finalizando con la prueba del modelo entrenado. Después de todo, el estado latente generado por el segundo modelo forma parte de los datos iniciales de nuestro Agente.
Dentro del alcance de este artículo, no abarcaremos en detalle todo el código del asesor. La mayoría de sus métodos se conservarán sin cambios respecto a artículos anteriores. Nos detendremos únicamente en el método de procesamiento de ticks OnTick, en el que se organizará el proceso principal de recopilación de datos.
Al inicio del método, como de costumbre, verificaremos la aparición del evento de apertura de una nueva barra y, si fuera necesario, actualizaremos los datos históricos del movimiento de precios y las métricas de los indicadores analizados.
Permítanme recordarles que todas las operaciones de nuestro asesor se realizarán únicamente en la apertura de una nueva barra. El algoritmo de nuestros modelos no controlará el cambio de cada tick. Todos los modelos entrenados trabajarán con los datos históricos del marco temporal H1. Sin embargo, la elección del marco temporal es una decisión puramente subjetiva y no está limitada por las arquitecturas del modelo. Solo debemos cumplir con el requisito de que el entrenamiento y la explotación de los modelos se realice en el mismo marco temporal y en el mismo instrumento. Antes de usar los modelos previamente entrenados en otro marco temporal y/u otro instrumento, se deberán entrenar adicionalmente en el marco temporal e instrumento financiero objetivo.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
A continuación, prepararemos el búfer de datos de origen. Primero, registraremos los datos históricos sobre el movimiento del precio del instrumento financiero y las métricas de los indicadores analizados.
//--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Luego añadiremos la información sobre el estado actual de la cuenta y las posiciones abiertas.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Aquí añadiremos una marca temporal,
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
así como la última acción del Agente que nos ha llevado al estado actual del entorno. Al procesar la primera barra, este vector se rellenará con valores cero.
//--- Prev action
bState.AddArray(AgentResult);
A continuación, deberemos añadir la designación objetivo al Agente como "Return-To-Go", pero dentro del algoritmo DoC, todavía tenemos que generar el estado latente. No obstante, los datos recopilados serán suficientes para que funcione el modelo de generación del estado latente y realicemos su pasada directa.
//--- Return to go if(!RTG.feedForward(GetPointer(bState))) return;
Tras realizar con éxito la pasada directa a través del modelo, cargaremos la representación latente resultante y la añadiremos al búfer de datos de origen.
RTG.getResults(Result); bState.AddArray(Result);
En este punto, hemos generado un paquete completo de datos de entrada para nuestro modelo de Agente, así que podremos llamar al método de pasada directa para generar acciones óptimas según la política aprendida previamente. Y, como siempre, no nos olvidaremos de controlar el proceso de las operaciones.
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat*)NULL)) return;
Aquí termina el trabajo de los modelos en la barra actual y comenzará la interacción con el entorno. Primero, realizaremos el preprocesamiento y descifraremos los resultados del trabajo del Agente. En artículos anteriores, ya aclaramos la presencia de posiciones abiertas en una sola dirección. Por tanto, lo primero que haremos será determinar el delta de volumen partiendo de los resultados del Agente, y guardar la diferencia para la dirección con el volumen máximo. En la segunda dirección, restableceremos el volumen de la operación.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } AgentResult = temp;
A continuación, comprobaremos la necesidad de realizar transacciones para comprar un instrumento financiero. Aquí comprobaremos el volumen y los niveles stop de la operación generada por el Agente. Si el volumen de transacciones es inferior a la posición mínima posible o los niveles de stop loss/take profit no cumplen con los requisitos mínimos del bróker, entonces esto será una señal para no abrir posiciones largas. Y en este momento deberemos cerrar todas las posiciones largas abiertas anteriormente. Por supuesto, si estas existen.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Si, por decisión del Agente, debemos tener una posición larga, entonces tendremos algunas opciones posibles dependiendo del estado actual de la cuenta:
- Si una posición ya está abierta y su volumen supera el volumen especificado por el Agente, cerraremos el exceso de volumen. Y para la posición restante, si es necesario, ajustaremos los niveles stop.
- El nivel de la posición abierta es igual al especificado por el Agente; comprobaremos todo y, de ser necesario, ajustaremos los niveles de parada.
- No hay ninguna posición abierta o su volumen es inferior al especificado: abriremos el volumen faltante y ajustaremos los niveles stop.
else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Repetiremos operaciones similares para las posiciones cortas.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Tras interactuar con el entorno, todo lo que deberemos hacer es digitalizar el resultado de las operaciones anteriores y almacenar los datos en el búfer de reproducción de experiencias.
//--- int shift=BarDescr*(NBarInPattern-1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift+1]-1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Con esto concluirá nuestro trabajo sobre el asesor para interactuar con el entorno y recopilar los datos de la muestra de entrenamiento. Podrá leer el código completo del asesor y todas sus funciones en el archivo adjunto al artículo.
Ahora analizaremos el modelo de asesor de entrenamiento "\DoC\Study.mq5". En el método de inicialización del asesor OnInit EA, primero intentaremos cargar la muestra de entrenamiento. Como estamos entrenando modelos offline, este conjunto de entrenamiento será nuestra única fuente de datos. Por lo tanto, si hay algún error al cargar los datos de entrenamiento, el trabajo adicional del asesor no tendrá sentido y retornaremos el resultado del error de inicialización del programa. Primero, enviaremos un mensaje al registro con el identificador del error ocurrido.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
El siguiente paso será cargar los modelos previamente entrenados. En ausencia de estos, se crearán e inicializarán nuevos modelos.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !RTG.Load(FileName + "RTG.nnw", dtStudied, true)) { Print("Init new models"); CArrayObj *agent = new CArrayObj(); CArrayObj *rtg = new CArrayObj(); if(!CreateDescriptions(agent,rtg)) { delete agent; delete rtg; return INIT_FAILED; } if(!Agent.Create(agent) || !RTG.Create(rtg)) { delete agent; delete rtg; return INIT_FAILED; } delete agent; delete rtg; }
Tenga en cuenta que si hay un error al leer uno de los modelos, ambos modelos se crearán e inicializarán. Esto se hace para mantener la compatibilidad del modelo.
Luego vendrá el bloque para verificar la arquitectura del modelo. Aquí comprobaremos la coherencia de los tamaños de capa del original y los resultados de ambos modelos. Primero verificaremos la arquitectura del Agente.
//--- Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the agent does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Agent doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; }
Y luego repetiremos los pasos para el modelo de representación latente.
RTG.getResults(Result); if(Result.Total() != NRewards) { PrintFormat("The scope of the RTG does not match the rewards count (%d <> %d)", NRewards, Result.Total()); return INIT_FAILED; } //--- RTG.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of RTG doesn't match state description (%d <> %d)", Result.Total(), (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } RTG.SetUpdateTarget(1000000);
Aquí también vale la pena señalar que en el proceso de entrenamiento del modelo de representación latente, no planeamos utilizar el modelo objetivo ofrecido por la arquitectura de FQF. Por lo tanto, inmediatamente estableceremos que el periodo de actualización del modelo objetivo sea bastante largo. Esta técnica nos permitirá eliminar operaciones innecesarias en el proceso de entrenamiento de modelos.
Después de completar con éxito todas las operaciones anteriores, todo lo que tendremos que hacer es generar el evento de inicio del proceso de entrenamiento y completar el método de inicialización del asesor.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
En el método de desinicialización del asesor OnDeinit deberemos añadir el almacenamiento del modelo de representación latente. Recuerde que, a diferencia de los Juegos Olímpicos, "lo importante es participar, no ganar": lo que necesitamos es exactamente el resultado y no el proceso de entrenamiento.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Agent.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); RTG.Save(FileName + "RTG.nnw", TimeCurrent(), true); delete Result; }
Ahora pasaremos al método de entrenamiento del modelo Train. En el cuerpo del método, determinaremos la cantidad de trayectorias cargadas en el búfer de reproducción de experiencias y guardaremos el estado actual del contador de ticks en una variable local para controlar el tiempo durante el proceso de entrenamiento del modelo.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
A continuación, como en el artículo anterior, organizaremos un sistema de ciclos. El ciclo exterior contará el número de lotes de entrenamiento de los modelos. En su cuerpo, seleccionaremos aleatoriamente una trayectoria del búfer de repetición de experiencias y un estado en esta trayectoria como punto de partida para el entrenamiento. Inmediatamente limpiaremos las pilas de ambos modelos y reiniciaremos el vector de las últimas acciones del Agente. Estas operaciones resultan esenciales al entrenar modelos autorregresivos y deberán realizarse antes de cada transición a un nuevo segmento de la trayectoria para entrenar modelos.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; } Actions = vector<float>::Zeros(NActions); Agent.Clear(); RTG.Clear();
Al entrenar modelos autorregresivos, el mantenimiento de la secuencia de operaciones durante el proceso de entrenamiento juega un papel importante. Para cumplir con este requisito, crearemos un ciclo anidado en el que ofreceremos los datos de origen a la entrada de los modelos en el orden cronológico de su aparición al interactuar con el entorno. Esto nos permitirá reproducir el comportamiento del Agente con la mayor precisión posible y construir un proceso de entrenamiento óptimo.
for(int state = i; state < MathMin(Buffer[tr].Total - 2,i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
Para configurar el proceso de entrenamiento más correcto, deberemos asegurarnos de que el búfer de pila esté completamente lleno con los datos secuencialmente. Después de todo, esto será exactamente lo que sucederá cuando el modelo se utilice durante un segmento temporal bastante largo. Por lo tanto, configuraremos el ciclo anidado para una cantidad de iteraciones que será 3 veces la longitud de la pila de datos analizados. No obstante, para evitar que ocurra un error fuera de los límites en el array de datos de la trayectoria guardada, añadiremos una verificación sobre la finalización de la trayectoria.
A continuación, en el cuerpo del ciclo, rellenaremos el búfer de datos de origen en riguroso acuerdo con la secuencia de registro de los datos durante el proceso de recopilación de la muestra de entrenamiento. Aquí vale la pena señalar que estos procesos deberán corresponderse con la estructura de los datos de origen que especificamos en la arquitectura del modelo al describir la capa de incorporación.
Lo primero que añadiremos al búfer serán los datos históricos sobre el movimiento de precios del instrumento financiero y las métricas de los indicadores analizados. Y si durante el proceso de recopilación de datos los hemos descargado del terminal, ahora podremos usar los datos ya preparados del array correspondiente del búfer de reproducción de experiencias.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Pero el proceso de creación de una descripción del estado de la cuenta y la marca temporal repetirá casi por completo los procesos similares en el asesor de recopilación de datos de entrenamiento.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
A continuación, añadiremos al búfer el vector de acción del Agente en el paso anterior y llamaremos al método de pasada directa del modelo de generación del estado latente. Y nos aseguraremos de comprobar los resultados de las operaciones.
//--- Prev action State.AddArray(Actions); //--- Return to go if(!RTG.feedForward(GetPointer(State))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Después de ejecutar con éxito el método de pasada directa del modelo de generación del estado latente, podremos actualizar inmediatamente sus parámetros, y entrenar ya el modelo para predecir recompensas futuras. Este enfoque es consistente con el algoritmo DT y no contradice el algoritmo DoC.
Result.AssignArray(Buffer[tr].States[state+1].rewards); if(!RTG.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Merece la pena prestar atención a un punto más aquí: en esta etapa, hemos abandonado el uso del método CAGrad para ajustar la dirección del gradiente de error en el vector de resultados. Esto se debe al hecho de que, además de los valores absolutos de las recompensas, nos esforzaremos por conocer su distribución probabilística en las profundidades de la capa FQF, mientras que el ajuste de los valores objetivo para optimizar la dirección del gradiente de error puede distorsionar la distribución deseada.
Después de optimizar los parámetros del modelo de representación latente, comenzaremos a entrenar el modelo de política de nuestro Agente. Luego añadiremos la recompensa real recibida por pasar al siguiente estado al búfer de datos inicial. Esto es exactamente lo que hemos hecho al entrenar la política del Agente del Decision Transformer. Además, en términos de entrenamiento de la política del Agente, hemos repetido completamente el algoritmo del Decision Transformer. Después de todo, tendremos que entrenar al Agente para que compare las acciones completadas de los estados individuales y la recompensa esperada. Exactamente lo mismo que en el algoritmo del Decision Transformer. La principal contribución del algoritmo Dichotomy of Control consiste en la creación de una designación objetivo correcta en forma de representación latente formada por el segundo modelo.
//--- Policy Feed Forward State.AddArray(Buffer[tr].States[state+1].rewards); if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
El siguiente paso será actualizar los parámetros del modelo del Agente para generar las acciones reales que han dado como resultado la recompensa real especificada en los datos de entrada del Agente como objetivo.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Esta vez ya estaremos utilizando el métodoCAGrad para optimizar la dirección del vector de gradiente de error y aumentar la velocidad de convergencia del modelo.
Tras actualizar con éxito los parámetros de ambos modelos, todo lo que tendremos que hacer es informar al usuario sobre el progreso del proceso de entrenamiento y pasar a la siguiente iteración de entrenamiento.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "RTG", iter * 100.0 / (double)(Iterations), RTG.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Una vez se completen todas las iteraciones de nuestro sistema de ciclos, consideraremos que el proceso de entrenamiento está completo. Ahora limpiaremos el campo de comentarios en el gráfico. Y enviaremos los resultados del proceso de entrenamiento en el registro e iniciaremos el proceso de finalización del trabajo del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "RTG", RTG.getRecentAverageError()); ExpertRemove(); //--- }
Con esto concluirá nuestra revisión del asesor de entrenamiento de modelos "\DoC\Study.mq5". Podrá leer el código completo del mismo, así como de otros programas utilizados en el artículo, en el archivo adjunto. Allí también encontrará el código del asesor para probar los modelos entrenados "\DoC\Test.mq5". Su código replica casi por completo al asesor para interactuar con el entorno y recopilar datos de entrenamiento. Por lo tanto, no nos detendremos ahora en considerar sus métodos. Estaré encantado de responder a todas sus dudas en el hilo del foro correspondiente a este artículo.
3.Pruebas
Tras finalizar el trabajo de creación de los asesores en los que hemos implementado nuestra visión del algoritmoDichotomy of Control, pasaremos a la etapa de prueba del trabajo realizado. En esta etapa recopilaremos los datos de entrenamiento. Entrenaremos los modelos. Y comprobaremos los resultados de su trabajo fuera del periodo de la muestra de entrenamiento. El uso de nuevos datos para probar modelos nos permitirá acercar las pruebas de modelos lo más posible a las condiciones reales. Después de todo, nuestro objetivo será obtener un modelo capaz de generar beneficios reales en los mercados financieros en un futuro previsible.
Como siempre, los modelos se entrenarán con los datos históricos de los primeros 7 meses de 2023. Para todas las pruebas utilizaremos uno de los instrumentos financieros más volátiles, el EURUSD, así como el marco temporal H1. Los parámetros de todos los indicadores analizados no han cambiado desde el comienzo de nuestra serie de artículos y se utilizarán de forma predeterminada.
Nuestro proceso de entrenamiento de modelos será iterativo y constará de varias iteraciones sucesivas de recopilación de datos de entrenamiento y modelos de entrenamiento.
Querríamos enfatizar una vez más la necesidad de repetir las operaciones sucesivas de recopilación de los datos y modelos de entrenamiento. Por supuesto, primero puede recopilar una base de datos extensa de ejemplos de entrenamiento y luego entrenar modelos en ella durante mucho tiempo. Pero nuestros recursos no son ilimitados y físicamente no podremos recopilar una base de datos de ejemplos capaces de abarcar completamente el espacio de acciones y las recompensas recíprocas. Además, trabajaremos con un espacio continuo de acciones. Sumemos a esto la gran estocasticidad del entorno estudiado, y esto implica que durante el proceso de entrenamiento existirá una alta probabilidad de que el modelo acabe en un espacio inexplorado. Y para perfeccionar nuestro conocimiento del entorno, necesitaremos iteraciones adicionales de interacción con él.
Otro punto bastante importante es que durante la recopilación inicial de datos de entrenamiento, cada Agente utilizará una política aleatoria. Esto le permitirá explorar el entorno lo más a fondo posible. Y como ya sabe, uno de los principales desafíos del aprendizaje por refuerzo es encontrar el equilibrio entre la exploración y la explotación. Obviamente, aquí estamos viendo un 100% de la exploración. Al volver a interactuar con el entorno y recopilar los datos de entrenamiento, los agentes utilizarán una política ya entrenada previamente. Y el alcance de la investigación se reducirá en la medida de la estocasticidad de la política aprendida.
Cuanto más a menudo realicemos iteraciones de interacción con el entorno, más suave será el estrechamiento de la región de estocasticidad del modelo. Y una retroalimentación recibida oportunamente podrá ajustar la dirección del aprendizaje. Esto aumentará nuestras posibilidades de lograr la recompensa máxima esperada global.
Si se dan intervalos de entrenamiento largos offline, corremos el riesgo de reducir inmediatamente la estocasticidad de las acciones del modelo tanto como sea posible, llegando a algún extremo local sin la capacidad de ajustar la dirección del entrenamiento del modelo.
También cabe señalar que en nuestros modelos utilizaremos un bloque de atención dispersa, cuyo entrenamiento es un proceso doblemente complejo y largo. En primer lugar, sigue siendo un bloque de Autoatención, que tiene una estructura compleja. Una estructura compleja requiere un entrenamiento largo y cuidadoso.
El segundo punto será el uso de la atención dispersa. Por lo tanto, al igual que con el Dropout, no todas las neuronas se implican por completo en cada iteración del entrenamiento. Como resultado, en algunos momentos el gradiente no llegará a las neuronas y estas abandonarán el proceso de entrenamiento. La pérdida de neuronas durante el proceso de entrenamiento se producirá de forma bastante estocástica. Y para entrenar completamente el modelo, se requerirá una cantidad adicional de iteraciones.
Al mismo tiempo, el uso de bloques de atención dispersa reducirá el tiempo por iteración de entrenamiento y hará que el modelo sea más flexible.
Pero volvamos a los resultados del entrenamiento y la prueba de nuestros modelos. Para probar el modelo entrenado, utilizaremos los datos históricos de agosto de 2023. Instrumento EURUSD, marco temporal H1. Agosto es el mes que sigue inmediatamente al periodo de entrenamiento. Como hemos mencionado antes, de esta manera hemos creado un conjunto de condiciones para probar el modelo lo más semejante posible a la explotación industrial del modelo. Según los resultados de las pruebas del modelo, aun así hemos logrado obtener ganancias, aunque no significativas. Permítanme recordarles que en el artículo anterior, en condiciones similares, el modelo entrenado con el algoritmo del transformador de decisión no pudo generar ganancias. La adición de enfoques DoC permite elevar casi el mismo modelo a un nivel cualitativamente diferente.


Pero a pesar de los beneficios obtenidos, los resultados del modelo no son tan halagüeños e inequívocos. Si observamos el gráfico de balance durante la prueba del modelo entrenado, podemos notar las siguientes tendencias:
- En los primeros diez días del mes observamos un aumento bastante pronunciado del balance, de alrededor del 20%.
- En la segunda década observamos fluctuaciones en el nivel de balance en el ámbito de los resultados obtenidos. A los periodos no rentables les siguen aumentos bastante pronunciados. La amplitud de las fluctuaciones alcanza el 10% del balance.
- En la tercera década se produce una serie de transacciones no rentables.
Como resultado, durante todo el periodo de entrenamiento tenemos alrededor del 43% de posiciones rentables. En este caso, la transacción rentable máxima es más de 2 veces superior a la pérdida máxima, mientras que la operación rentable promedio es 1/3 mayor que la pérdida promedio. Como resultado, el factor de beneficio se fija en 1,01, y el factor de recuperación en 0,03.
Al comparar los resultados de las pruebas del modelo con y sin el uso de los principios de DoC, podemos notar un fuerte aumento en el balance en los primeros diez días del mes en ambos casos. El uso de enfoques DoC ha permitido mantener los resultados obtenidos en los segundos diez días del mes. Sin el uso de DoC, inmediatamente ha comenzado una serie de transacciones no rentables.
De ahí mi opinión, siempre subjetiva: el enfoque autorregresivo permite lograr resultados bastante buenos, pero, lamentablemente, solo por un corto periodo de tiempo. Al mismo tiempo, el uso de DoC demuestra que el periodo de efecto beneficioso puede aumentar usando algunas modificaciones del método. Esto significa que existe potencial y espacio para la creatividad.
Conclusión
En este artículo, nos hemos familiarizado con un algoritmo muy interesante y con gran potencial: la dicotomía de control (DoC). Este algoritmo fue introducido por el equipo de Google como un medio para mejorar la eficiencia de los modelos al trabajar con entornos estocásticos. El principio fundamental de DoC consiste en dividir todos los factores y resultados observables en aquellos que dependen y que no dependen de la política del Agente. Por lo tanto, en el proceso de entrenamiento del modelo, no centraremos la atención en factores que dependan de las acciones del Agente, construyendo en cambio una política encaminada a maximizar los resultados, teniendo en cuenta la influencia estocástica del entorno.
Como parte del artículo, hemos añadido principios de DoC al modelo de Transformador de Decisión creado anteriormente. Y, como resultado, hemos observado una mejora en el rendimiento del modelo en la muestra de prueba. Sí, el resultado alcanzado aún está lejos de los resultados deseados, pero se percibe claramente un cambio positivo. De esto podemos concluir que la implementación de los principios de la Dicotomía de Control resulta efectiva.
Enlaces
- Decision Transformer: Reinforcement Learning via Sequence Modeling
- Dichotomy of Control: Separating What You Can Control from What You Cannot
- Redes neuronales: así de sencillo (Parte 34): Función cuantílica totalmente parametrizada
- Redes neuronales: así de sencillo (Parte 58): Transformador de decisión (Decision Transformer—DT)
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13551
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
piensa en ello...
¡¿cuantos PHD trabajan en goldmansachs? o en hfts, o en empresas de quantfund, !
¡¡¡si fuera asi de facil !!!
Quería dar las gracias al autor por la enorme cantidad de ideas, es un Klondike para la experimentación.
También creo que los artículos son adecuados como ejemplos de posibles métodos para entrenar redes neuronales, pero no para la práctica. Aprecio mucho el trabajo invertido en la librería propia del autor para la creación y entrenamiento de redes neuronales, e incluso con el uso de tarjetas de video, pero no se puede utilizar de ninguna manera con fines prácticos, y mucho menos competir con tensorflow, keras, pytorch - En realidad, todos los modelos entrenados con estas bibliotecas se pueden utilizar directamente en mql5, utilizando el formato onnx.
Poco a poco voy a aplicar las ideas del autor con la ayuda de estas bibliotecas modernas.
También es necesario seleccionar indicadores para los datos de entrada para la formación de redes neuronales, tengo el más exitoso es bandas de bollinger, y yo uso 48 de estos indicadores como datos de entrada con diferentes configuraciones para redes recurrentes como LSTM. Pero esto no es una garantía de éxito, también entreno 28 pares de divisas a la vez y elijo los mejores, pero esto no es una garantía de éxito. Entonces usted necesita para ejecutar al menos 20 veces el procedimiento de formación, cambiando el número de capas y sus ajustes en las redes neuronales, y en cada etapa de seleccionar los mejores modelos que se han mostrado bien en el probador de estrategia, y eliminar el peor, y sólo entonces se puede lograr resultados razonables en la práctica.
Al final solo elegimos por ejemplo los mejores 9 pares de 28 y los operamos en una cuenta real, al mismo tiempo el Asesor Experto también debe tener en su arsenal mani-gestión, no perjudicará a la red también, es decir, utilizamos las redes neuronales como asistentes a las buenas ideas de los asesores sin redes neuronales, haciéndolos así inteligentes ya.
Hola, podrías facilitar un enlace al 1er artículo para empezar a leer/aprender, estoy muy interesado en el tema
https://www.mql5.com/es/articles/7447