
希尔伯特-施密特独立性判据(HSIC)

概述
交易者在处理金融工具报价时的主要任务是构建一个具有正数学期望值的交易系统(EA)。在设计此类系统时,通常假设用于训练和后续交易的数据中存在隐藏的依赖关系。然而,通常不会考虑对该假设进行统计检验的问题。人们认为可以通过对样本外数据进行测试来获得间接答案。
同时,对于特征与目标变量之间是否存在关系这一问题,一个具有统计意义的答案至关重要。肯定的答案支持使用预测模型,而否定的答案则让人不禁要问:算法到底想预测什么?
在数理统计中,随机变量之间是否存在概率依赖关系的问题是通过独立性检验来回答的。其中一项标准是 HSIC 统计检验,这是一种强大的非参数方法,由统计学家 Arthur Gretton 于 2005 年开发。
与仅能识别线性关系的相关系数不同,HSIC 能够同时检测线性和非线性关系。正因如此,它在机器学习中被广泛用于特征选择、因果分析和其他任务。在本文中,我们将分析 HSIC 的工作原理,并在 MQL5 环境中实现它。
HSIC 是什么?
HSIC 是基于核方法衡量两个随机变量 X 和 Y 之间依赖性的指标。该方法利用核函数(例如高斯核函数(图 1))的数学“魔力”,将数据转换为特殊的 RKHS(再生核希尔伯特空间)空间,从而更容易检测到依赖关系。
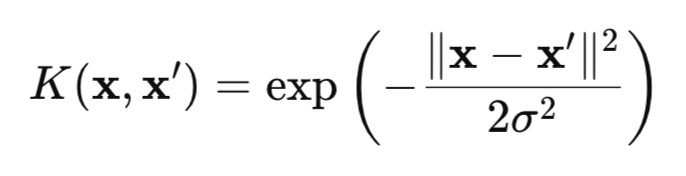
图 1.高斯核(RBF 核)
其中:
- x,x' — 观测值的向量(点),
- || || 2 — 欧几里得范数的平方,
- σ — 核宽度。
有许多核函数可用于 HSIC 测试,例如用于分类数据的核函数或拉普拉斯核函数。然而,在本文中,我们将重点关注高斯核函数,因为高斯核具有通用性,并且是具有特征性的核。因此能够识别数据数据中的任何依赖关系,从而使高斯核函数特别高效。
经典 HSIC 检验两个随机变量 X 和 Y 是否独立,方法是检查条件 P(X,Y) = P(X)P(Y) 是否满足。为此,HSIC 使用核矩阵(一个矩阵,其中每个元素都反映了数据点对之间的相似性,该相似性是通过核函数计算得出的)来分析联合分布与边缘分布乘积的偏差。
HSIC 的一个重要优势是它能够处理任何维度的数据:标量、向量或两者的组合。在由于数据维度较高而难以明确构建多元联合分布 P(X,Y) 的问题中,这一点尤其有价值。
从数学角度来看,HSIC 判据定义为 RKHS 中交叉协方差算子的希尔伯特-施密特范数的平方:
![]()
其中:
- K(X,X') – 随机变量 X 的核函数,
- L(Y,Y') – 随机变量 Y 的核函数,
- || || HS -希尔伯特-施密特范数。
这里有必要将 HSIC 与通常的协方差进行比较。经典协方差度量的是原始空间中变量X和Y之间的线性关系,而 HSIC 则是将 X 和 Y 映射到再生核希尔伯特空间(RKHS),即一个函数空间,从而允许对数据进行转换以揭示复杂的非线性依赖关系。
实际上,并不需要直接计算希尔伯特-施密特范数。相反,HSIC 是通过依赖于为数据样本构建的核矩阵的经验统计方法进行估计的:
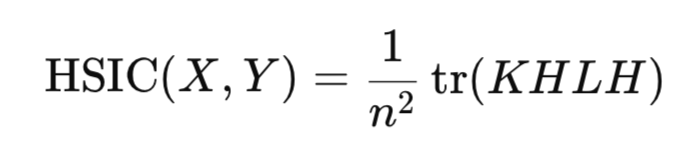
其中:
- K,L – n*n 核矩阵,
- H – n*n 居中矩阵 ( I - 1/n 11 ^T ),
- tr() – 矩阵迹,
- n – 观测次数。
与相关系数类似,HSIC 利用样本统计量来估计随机变量 X 和 Y 之间是否存在关系,而无需显式构造这些变量的分布形式。
HSIC 统计量始终为非负值:
- HSIC > 0 表示存在依赖性,
- 而 HSIC = 0 表示数据相互独立。
HSIC 显著性检验
然而,仅计算统计量还不足以得出可靠的结论。应确认其统计显著性,以排除随机结果的可能性。对于 HSIC 统计量,在零假设下没有分布的精确解析形式。也就是说,我们不能简单地使用(例如)正态分布,然后而无需付出显著的计算代价就能快速轻松地获得临界值或 p 值。解决这个问题主要有两种方法:
- 置换检验,
- 伽马近似。
置换检验是估计 H0 下 HSIC 分布的基本和最准确的方法。它的目标是通过随机置换其中一个变量的索引或打乱该变量的核矩阵来打破 X 和 Y 之间的任何依赖性。为了获得准确的结果,应进行相当多的此类置换(大约 1000 次)。因此,置换检验成本相当高,因为它需要计算每个置换的 HSIC。
置换检验的主要优点是它不需要对数据分布的形状做任何假设。相反,它依赖于通过置换得到的统计量的经验分布。然后利用经验 HSIC 分布来获得 p 值估计。
伽马近似法用于加快统计计算速度。在这种方法中,HSIC 统计量按样本大小进行缩放 (n*HSIC),伽马分布参数由 HSIC 样本矩(均值和方差)估计得出。该方法比置换检验速度快得多,但对于小样本,其准确性可能会降低。在独立性零假设下估计 HSIC 分布还有其他方法,但这些方法实施起来很复杂,在实践中也很少使用,因此本文不予讨论。
在 MQL5 中实现 HSIC 置换
置换检验在 hsic_test 函数中实现。
//+------------------------------------------------------------------+ //| Permutation test function | //+------------------------------------------------------------------+ vector hsic_test(matrix &X,matrix &Y,const double alpha,bool Bootstrap = false,int n_permutations=1000) { vector ret = vector::Zeros(3); int n = (int)X.Rows(); matrix K = RBF_kernel(X); // kernel matrix for X matrix L = RBF_kernel(Y); // kernel matrix for Y matrix H = matrix::Eye(n, n) - matrix::Ones(n, n)/n; // Centering matrix //-------------------------------------- // Kc centered kernel matrix К matrix Kc(n, n); if(!Kc.GeMM(H, K, 1.0, 0.0)) { Print("Error: Failed to calculate Kc = H * K"); return ret; } if(!Kc.GeMM(Kc, H, 1.0, 0.0)) { Print("Error: Failed to calculate temp = Kc * H"); return ret; } Kc = Kc.Transpose(); double coef = 1/pow(n,2); // Calculate the observed value of the HSIC statistic double hsic_obs = compute_hsic(L,Kc,coef); ret[0]= hsic_obs; //------------ Permutation test ---------------------------------------- if (Bootstrap == true){ vector hsic_perms = vector::Zeros(n_permutations); for ( int i = 0; i<n_permutations; i++) { ShuffleMatrix(L); // Shuffle the matrix hsic_perms[i] = compute_hsic(L,Kc,coef); } int count = 0; for(int i = 0; i < n_permutations; i++) { if(hsic_perms[i] >= hsic_obs) count++; } // Calculate the p-value double p_value = (n_permutations > 0) ? (double)count / n_permutations : 0.0; ret[1] = p_value; // Calculate the critical value double hsic_sort[]; VectortoArray(hsic_perms,hsic_sort); ArraySort(hsic_sort); double CV = hsic_sort[(int)round((1-alpha)*n_permutations)]; ret[2] = CV; } //---------------------------------------------------------------------------------- return ret; }
该函数接受两个数据集 X 和 Y(这些是大小为 n*d 的矩阵,其中 n 是观测值的数量,d 是数据的维度),
“alpha” 参数设定显著性水平(这是第一类错误,即当原假设实际上为真时拒绝原假设的概率)。
Bootstrap 参数(如果为 “true”,则执行置换检验以获得 p 值;否则,仅计算统计量),
n_permutations – 随机置换的数量,
该函数返回一个向量,其中包含观察到的 HSIC 值、p 值和所选 “alpha” 水平的临界值。
高斯核矩阵的计算在 RBF_kernel 函数中执行。
//+------------------------------------------------------------------+ //| Gaussian kernel | //+------------------------------------------------------------------+ matrix RBF_kernel(const matrix &X) { int n = (int)X.Rows(); // Calculate the distance matrix using the scalar product matrix XX(n, n); if(!XX.GeMM(X, X.Transpose(), 1.0, 0.0)) { Print("Error: Failed to calculate XX = X * X^T"); } matrix diag(n,1); diag.Col(XX.Diag(),0); // vector of diagonal elements // squares of distances matrix D_sq = matrix::Ones(n, 1).MatMul(diag.Transpose()) + diag.MatMul(matrix::Ones(1, n)) - 2*XX; // Calculate sigma on the first n_sigma rows int n_sigma = MathMin(n, 100); int num_elements = (n_sigma * (n_sigma - 1)) / 2; vector upper_tri(num_elements); int idx = 0; for(int i = 0; i < n_sigma; i++) { for(int j = i + 1; j < n_sigma; j++) { upper_tri[idx] = D_sq[i, j]; idx++; } } double sigma = MathSqrt(0.5 * upper_tri.Median()); return MathExp((-1* D_sq) / (2 * sigma*sigma)); }
该函数计算数据点之间距离的平方、核宽度的 sigma,并返回所需的 n*n 核矩阵。
为了高效地计算平方距离,使用矩阵形式而不是常规循环:
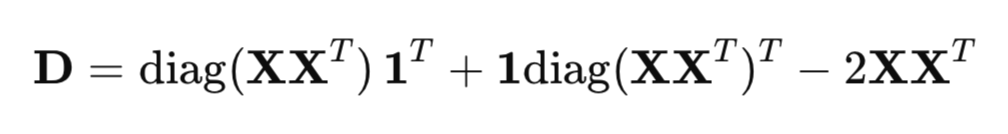
其中:
- XX^T - 格拉姆矩阵(内积矩阵),
- diag(XX^T) - 对角元素向量,
- 1 - 全为 1 的向量。
高斯核中的 sigma 参数决定了核的宽度,并显著影响 HSIC 检测数据中依赖性的灵敏度。sigma 参数决定相似性的尺度:较大的 sigma 值使核更宽(相距较远的点仍然被认为是相似的),而较小的值使核更窄(只有非常接近的点才被认为是相似的)。
选择 sigma 的一种常用方法是使用以下中位数启发式方法:

取系数 0.5 是为了确保 RBF 核的分母等于数据点之间欧几里得距离平方的中位数,从而确保自适应估计能够考虑到数据的规模。
n_sigma = MathMin (n, 100) 变量将用于计算 sigma 的数据量限制为 100。这样做是为了在保持 σ 估计值代表性的同时,降低大样本的计算成本。将平方欧几里得距离复制到 upper_tri 向量中,仅使用距离矩阵的上三角部分(不包括对角线,即 i=j 的情况),以避免重复和零距离。
用于计算 HSIC 统计数据的函数 compute_hsic。
//+------------------------------------------------------------------+ //| Function to calculate HSIC | //+------------------------------------------------------------------+ double compute_hsic(const matrix &L, const matrix& Kc, const double coef){ matrix KcL= Kc*L; return coef*KcL.Sum(); }
计算出观察到的 HSIC 统计量后,进行置换检验以检验其统计显著性。ShuffleMatrix(matrix &m) 函数实现了与 Y 变量对应的 L 核矩阵的这种置换。从统计学角度来看,L 或 K 的打乱顺序并无区别,因为 HSIC 关于 X 和 Y 是对称的,在 HSIC 的置换检验中会给出等效的结果。对 Y 变量本身进行打乱,然后为每种置换重新计算 L 矩阵,这种做法效率低下。
//+------------------------------------------------------------------+ //| Function for shuffling matrix data | //+------------------------------------------------------------------+ void ShuffleMatrix(matrix &m) { int rows = (int)m.Rows(); int cols = (int)m.Cols(); if (rows != cols) { Print("Error: Matrix should be square"); } int perm[]; GeneratePermutation(rows, perm); // Generate a random permutation of indices matrix temp = m; // Rearrange rows and columns for(int i = 0; i < rows; i++) { for(int j = 0; j < cols; j++) { m[i,j] = temp[perm[i], perm[j]]; } } }
使用 GeneratePermutation 函数生成随机索引。
//+------------------------------------------------------------------+ //| Function to create a random permutation of indices | //+------------------------------------------------------------------+ void GeneratePermutation(int size, int &perm[]) { MathSequence(0,size,1,perm); // Fisher-Yates algorithm for permutation for(int i = size - 1; i > 0; i--) { // Generate a random index from 0 to i int j = (int)(MathRand() / 32768.0 * (i + 1)); int temp = perm[i]; perm[i] = perm[j]; perm[j] = temp; } }
对 L 核矩阵进行多次置换后,利用 ShuffleMatrix 函数形成在独立性零假设下 HSIC 统计量的经验分布。p 值定义为 HSIC 置换值大于或等于观测统计量的比例。如果 p 值小于 “alpha” 显著性水平,则拒绝独立性的零假设。
临界值被选为经验分布在 1−alpha 水平的分位数,即高于 alpha⋅100% 的 HSIC 置换计算值的值。
实现 HSIC Gamma
hsic_Gamma_test 函数负责计算 Gamma 近似值。
//+------------------------------------------------------------------+ //| HSIC Gamma approximation function | //+------------------------------------------------------------------+ double hsic_Gamma_test(matrix &X, matrix &Y, double &CV, double & pvalue) { int n = (int)X.Rows(); matrix K = RBF_kernel(X); // kernel matrix for X matrix L = RBF_kernel(Y); // kernel matrix for Y matrix H = matrix::Eye(n, n) - matrix::Ones(n, n)/n; // Centering matrix matrix Kc(n, n); // Calculate the centered X kernel matrix if(!Kc.GeMM(H, K, 1.0, 0.0)) { Print("Error: Failed to calculate Kc = H * K"); return 0; } if(!Kc.GeMM(Kc, H, 1.0, 0.0)) { Print("Error: Failed to calculate temp = Kc * H"); return 0; } matrix KcT = Kc.Transpose(); matrix Lc(n, n); // Calculate the centered Y kernel matrix if(!Lc.GeMM(H, L, 1.0, 0.0)) { Print("Error: Failed to calculate Lc = H * L"); return 0; } if(!Lc.GeMM(Lc, H, 1.0, 0.0)) { Print("Error: Failed to calculate temp = Lc * H"); return 0; } double m = (double)n; double coef = 1/m; // Calculate the observed HSIC value matrix KcLc; double hsic_obs = compute_hsic_Gamma(Lc,KcT,coef,KcLc); // n*HSIC matrix varHSIC_m = KcLc*KcLc; varHSIC_m = (1.0/36.0)*varHSIC_m; double varHSIC = 1/(m)/(m-1) * (varHSIC_m.Sum() - varHSIC_m.Trace() ); varHSIC = 72*(m-4)*(m-5)/m/(m-1)/(m-2)/(m-3) * varHSIC; // HSIC variance matrix KD; KD.Diag(K.Diag(),0); matrix LD; LD.Diag(L.Diag(),0); K = K-KD; L = L-LD; matrix one = matrix::Ones(n,1); matrix a = 1/m/(m-1)*one.Transpose(); matrix muX; muX.GeMM(a,K.MatMul(one),1,0); matrix muY; muY.GeMM(a,L.MatMul(one),1,0); double mHSIC = 1/m * ( 1 +muX[0,0]*muY[0,0] - muX[0,0] - muY[0,0] ) ; // HSIC mathematical expectation //Gamma distribution parameters double alphaG = mHSIC*mHSIC / varHSIC; double beta = varHSIC*m / mHSIC; int err; CV = MathQuantileGamma(1-alpha_,alphaG,beta,err); // Critical value pvalue = 1 - MathCumulativeDistributionGamma(hsic_obs,alphaG,beta,err); // p-value //---------------------------------------------------------------------------------- return hsic_obs; }
这里我们计算按样本大小 n 缩放的 HSIC 统计量 (n*HSIC),它由具有形状 (alpha) 和尺度 (beta) 参数的伽马分布近似表示。这些参数是基于 HSIC 统计量的数学期望和方差来确定的。
在合成数据上进行测试
为了评估 HSIC 检测非线性依赖性的能力,我们模拟了一个典型的交易问题实验。让我们考虑两个特征 X={X 1 ,X 2 },它们与标量目标变量 Y 非线性相关,但与 Y 没有线性相关性(图 2)。这种情况反映了交易者在现实世界中面临的一个挑战:在将所选特征用于交易系统之前,要测试它们是否对预测变量有影响。
让我们按如下方式生成数据:
Y = X1^2 * cos(pi * X2) + Noise
其中:
- X1 和 X2 是独立同分布的均匀变量,其取值范围为 [-5,5],
- Noise — 高斯噪声
- Y - 目标变量,与 X1 和 X2 呈非线性关系。

图 2. Y 目标变量和 X 特征的散点图
该实验的目的是检验以下形式的独立性假设:
P(X1,X2,Y) = P(X1,X2)P(Y),
也就是说,确定这两个特征是否共同影响目标变量,或者它们之间是否存在任何关系。
在现实世界中,特征数量可能很大,HSIC 允许灵活地测试依赖关系:既可以针对单个特征(例如,X1 或 X2 与 Y),也可以针对任意数据子组。这使得该方法在筛选有效特征方面非常有用,例如,可以通过根据p值对特征进行排序,从而选择出最重要的特征来构建交易系统。
图 3 显示了使用 Gamma 近似的 HSIC 测试结果。所得的 HSIC 值以及相应的 p 值和临界值证实了 X 和 Y 之间存在具有统计显著性的非线性关系。这表明 HSIC 能够有效地识别数据中的复杂关系,这对于股票市场分析尤为重要,因为在股票市场分析中,特征通常对预测变量产生非线性影响。相比之下,计算得到的 X1、X2 和 Y 的相关系数接近于零,表明它们之间没有线性关系。

图 3. HSIC 测试结果,伽马近似
在相同样本量下,精确的 HSIC 置换检验在作者那台以当今标准来看配置较为普通的电脑(一台 4 核 Ryzen 3)上耗时 8.5 秒。然而,伽马近似的计算时间要快得多,因此,在计算速度至关重要的任务中,如实时分析大量金融数据时,它是首选。尽管小样本可能存在不准确性,但伽马近似法在速度和准确性之间取得了平衡,使其成为在 MQL5 交易算法中实现 HSIC 的宝贵工具。
结论
在本文中,我们讨论了 HSIC(希尔伯特-施密特独立性判据),这是一种强大的非参数方法,用于评估随机变量之间的关系。HSIC 采用核方法,使其能够在无需显式建模联合分布的情况下,识别复杂的非线性关系。
HSIC 的主要优势:
- 适用于任何维度的标量数据和向量数据,
- 捕捉复杂的非线性依赖关系,
- 相对容易实现。
然而,这种方法也有其局限性:
- 对核宽度 σ 参数的选择的敏感性,
- 样本量依赖性:在小样本情况下,置换检验的效力可能较低;在大样本情况下,计算 K 和 L 核矩阵非常耗时。
- 与相关系数不同,HSIC 仅表明存在某种关系,但并不表征其强度。
在本文中,我们展示了 HSIC 在具有非线性依赖性的合成数据中的应用,证实了其能够检测出传统方法(如皮尔逊相关系数)无法发现的关系。MQL5 中 HSIC 的实现证明了其在交易系统开发中选择有信息量的特征方面的实际应用性。
我们已经研究了使用高斯核的基本方法,但 HSIC 具有更高级的功能,包括处理分类数据和测试条件独立性。这些方向为该方法在交易、机器学习和数据分析问题中的进一步研究与应用提供了广阔前景。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/18099
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。


 新手在交易中的10个基本错误
新手在交易中的10个基本错误
作为独立同分布(iid)变量之和而得到的序列不会变得相关,但它会失去平稳性,因此无法使用统计检验标准。
我怀疑对于计算量极其庞大的检验标准,是否应该采纳这一观点。
在不存在信息丢失的情况下,变换不应影响相关性评估的结果。
关于交易、自动交易系统及交易策略测试的论坛
关于文章《希尔伯特-施密特独立性检验(HSIC)》的讨论
fxsaber, 2025年5月13日 05:46
命题。
如果对序列进行变换后(不丢失信息——可以恢复到初始状态)得到独立性,则原始序列是独立的。
我怀疑这是否适用于计算量极其巨大的标准。
在不丢失信息的情况下,转换操作不应影响依赖性评估的结果。
遗憾的是,这适用于大多数统计方法,无论复杂还是简单。 更不用说,95%的计量经济学方法都是建立在iid假设之上的(例外包括ARIMA、动态神经网络、隐马尔可夫模型等)。必须牢记这一点,否则得出的结果将毫无意义。
95%的机器学习方法基于iid假设
想必有人曾尝试通过机器学习构建依赖性准则——采用的是同样的方法,只是该准则本身位于ONNX文件中。
可能有人试图通过MO来建立依赖关系标准——这是一种类似的方法,只是该标准本身位于ONNX文件中。
机器学习模型会学习进行预测,如果该预测优于“朴素”预测,那么我们就推断数据中存在关联。也就是说,这是对关联的间接检测,并未验证其统计显著性。 而独立性检验标准则不进行任何预测,但能为发现的关联性提供统计学上的验证。这可以说是一枚硬币的两面。 R包中实现了更通用的dHSIC检验。它包含我之前提到的成对独立性实现,并进一步将检验范围扩展到了联合独立性。