
机器学习交易系统中的隐马尔可夫模型
目录
- 概述
- hmmlearn 库中的算法
- hmm.GaussianHMM 类
- hmm.GMMHMM 类
- vhmm.VariationalGaussianHMM 类
- 比较模型的性能
- 确定先验矩阵的方法
- 利用 HMM 识别市场状态
- 创建先验矩阵
- 将模型导出到 MetaTrader 5
- 结论
概述
隐马尔可夫模型(HMM)是一类强大的概率模型,旨在分析序列数据,其中观测到的事件取决于构成马尔可夫过程的某些未观测到的(隐藏的)状态序列。HMM 是一种双随机模型(既包含隐藏状态转移的随机性,也包含观测生成的随机性),其特征在于一组有限的隐藏状态和一系列可观测事件,这些事件的概率取决于当前的隐藏状态。 HMM 的主要假设包括隐藏状态的马尔可夫性质,这意味着转移到下一个状态的概率仅取决于当前状态,以及在已知当前隐藏状态的情况下观察结果的独立性。
隐马尔可夫模型已在语音和图像识别、自然语言处理(例如词性标注)、生物信息学(DNA 和蛋白质序列分析)以及时间序列分析(预测、异常检测)等各个领域得到广泛应用。HMM 能够对内部结构无法直接观察但会影响可观察输出的系统进行建模,这一能力使其成为分析复杂时变关系的宝贵工具。此类模型中的观测值只是隐藏过程的间接反映,而理解这些过程可以提供关于系统动力学的重要信息。
hmmlearn 库是一组用于无监督学习(隐马尔可夫模型)的 Python 算法。 它旨在提供简单高效的工具来处理 HMM,遵循 scikit-learn 库 API,便于集成到现有的机器学习项目中,并为熟悉 scikit-learn 的用户简化训练过程。Hmmlearn 构建于 NumPy、SciPy 和 Matplotlib 等基础科学 Python 库之上。
hmmlearn 的主要功能包括实现具有不同观测分布类型的各种 HMM 模型、从观测数据训练模型参数、推断最可能的隐藏状态序列、从训练好的模型生成样本,以及保存和加载训练好的模型。多种已实现的模型使用户能够根据其数据的性质选择最合适的观测分布类型。数据类型(连续型、离散型、计数型)决定了哪种概率分布最能描述每个隐藏状态下观测值的生成过程。
hmmlearn 库中的算法
hmmlearn 库实现了以下主要 HMM 模型:
- hmm.CategoricalHMM - 用于对分类(离散)观测序列进行建模。
- hmm.GaussianHMM - 用于对连续观测序列进行建模,假设每个隐藏状态服从高斯分布。
- hmm.GMMHMM - 用于对连续观测序列进行建模,其中每个隐藏状态的观测由高斯分布的混合来描述。
- hmm.MultinomialHMM - 用于对离散观测序列进行建模,其中每个状态在一组固定的符号上具有概率分布。
- hmm.PoissonHMM - 用于对事件计数数据序列建模,其中每个隐藏状态的观测遵循泊松分布。
- vhmm.VariationalCategoricalHMM - CategoricalHMM 的变分版本,使用变分推理方法进行学习。
- vhmm.VariationalGaussianHMM - GaussianHMM 的变分版本,专为根据多元正态分布的连续观测值而设计,并使用变分推断进行训练。
我们对处理连续数据的算法感兴趣,因此只会考虑这类算法。
hmm.GaussianHMM 类
hmmlearn 库中的 hmm.GaussianHMM 类实现了具有高斯观测的隐马尔可夫模型。当观测变量为连续变量,且假设其在每个隐藏状态中均服从多元正态(高斯)分布时,使用此模型。
高斯隐马尔可夫模型被广泛应用于对各种时间序列进行建模,如金融数据(如股票价格)、各种传感器的读数,以及其他在每个隐藏状态下观测值可用高斯分布描述的连续过程。
hmm.GaussianHMM 类构造函数接受以下参数:
- n_components(int,默认值为 1):定义模型中隐藏状态的数量。每个状态都将与其自身的高斯分布相关联。
- covariance_type ({"spherical", "diag", "full", "tied"}, 默认值为 "diag"): 设置用于每个状态的协方差矩阵类型。协方差类型的选择直接影响模型的复杂度和估计参数的数量。
- spherical - 每个状态对所有特征使用相同的方差。协方差矩阵是单位矩阵的倍数。
- diag - 每个状态使用一个对角协方差矩阵,假设状态内的特征在统计上是独立的,但可能具有不同的方差。
- full - 每个状态使用完全(不受约束的)协方差矩阵,使我们能够对每个状态内的特征之间的相关性进行建模。此选项最为灵活,但需要更多数据来稳定估计参数,且可能易于过拟合。
- tied - 所有隐藏状态共享同一个完整的协方差矩阵。这允许将特征之间的相关性纳入考虑,但前提是这些相关性的结构在所有状态下都是相同的。
- min_covar(float,默认值为 1e-3):设置协方差矩阵对角线元素的最小值,以防止其在训练过程中退化(例如方差为零),并避免过拟合。
- startprob_prior(array,形式为(n_components,),可选):狄利克雷先验参数用于确定初始概率 startprob_,这些参数决定了在每个隐藏状态下开始观测序列的概率。
- transmat_prior(array,形式为(n_components,n_components),可选):transmat_ 转移矩阵中每一行的狄利克雷先验参数,该参数决定了隐藏状态之间的转移概率。
- means_prior(数组,形式为(n_components),可选):每个隐藏状态的均值(means_)的正态先验分布的均值。
- means_weight(数组,形式(n_components),可选):每个隐藏状态的均值(means_)的正态先验分布的权重(或精度,方差的倒数)。
- covars_prior(数组,形式为(n_components),可选):协方差矩阵 covars_ 的先验分布参数。该分布的类型取决于 covariance_type 参数。对于 “spherical” 和 “diag”,这些是逆伽马分布的参数;对于 “full” 和 “tied”,这些是与逆威沙特分布相关的参数。
- covars_weight(数组,形式为(n_components),可选):协方差矩阵 covars_ 的先验分布参数的权重。与 covars_prior 类似,其解释取决于 covariance_type(逆伽马分布或逆威沙特分布的缩放参数)。
- algorithm({"viterbi", "map"},可选):用于解码的算法,即用于找到与观测序列对应的最可能的隐藏状态序列。“viterbi” 实现维特比算法,而 “map”(最大后验概率估计)执行平滑(前向-后向)以找到每个时刻最可能的状态。
- random_state(RandomState 或 int,可选):随机数生成器对象或整数种子,用于随机初始化模型参数,确保结果可重复。
- n_iter(int,可选):训练模型时,期望最大化(EM)算法执行的最大迭代次数。默认值为 10。
- tol(float,可选):EM 算法的收敛阈值。如果连续两次迭代之间的对数似然变化小于此值,则停止训练。0.01 是默认设置。
- verbose(bool,可选):如果设置为 True,则每次迭代都会将收敛数据写入标准误差。也可以通过 monitor_ 属性来监控收敛情况。
- params(string,可选):指定在训练期间将更新哪些模型参数。可能包含以下符号的组合:'s' 表示初始概率 (startprob_),'t' 表示转移概率 (transmat_),'m' 表示均值 (means_),'c' 表示协方差 (covars_)。默认值为 “stmc”(所有参数均已更新)。
- init_params(string,可选):指定在训练开始之前要初始化的模型参数。其符号与 “params” 中的含义相同。默认值为 “stmc”(所有参数均已初始化)。
- implementation(string,可选):定义要使用的前向-后向算法的实现方式:对数(“log”)或使用 “scaling”。默认情况下,为了向后兼容而使用 “log”,但是 “scaling” 实现通常速度更快。
使用 EM 算法训练模型之前,需要初始化 GaussianHMM 参数。初始化参数定义了模型的初始状态。init_params 参数控制哪些参数将被初始化。如果 init_params 中未包含任何参数,则假定其值已手动设置。
参数的初始值可以随机设置,也可以根据提供的数据进行计算。参数的正确初始化会显著影响 EM 算法的收敛速度和最终模型的质量,因为 EM 算法可能会陷入局部最优解。
使用迭代期望最大化(EM)算法进行高斯 HMM 参数优化。该算法包括两个主要步骤,这两个步骤会迭代执行,直至达到收敛:
- E 步(期望步):在这一步中,根据当前模型参数的估计值和观测到的数据序列,计算后验概率(即系统在每个时间点处于某个隐藏状态的概率)。这通常是使用前向-后向算法来实现的。
- M 步(最大化步):在此步骤中,更新模型参数(初始概率、状态之间的转移概率、每个状态的均值和协方差),以最大化观测数据的预期对数似然,受限于 E 步中计算的后验概率。
重复该过程,直至达到收敛状态,这可以通过两种方式判断:一是达到 n_iter 参数设定的最大迭代次数;二是在连续迭代之间,对数似然的变化量小于指定的阈值 tol。EM 算法保证每次迭代都会增加(或保持)对数似然值;但是,它不能保证找到全局最大值,结果可能取决于初始参数设置。
covariance_type 参数的选择直接影响用于对每个隐藏状态下的观测进行建模的协方差矩阵的结构。
- 选择 “spherical” 时,假设协方差是各向同性的,也就是说,给定状态下所有特征的方差相同,协方差矩阵与单位矩阵成比例。
- “diag” 表示使用对角协方差矩阵,这意味着每个状态的特征在统计上是独立的,尽管它们的方差可能不同。
- “full” 允许使用完整的协方差矩阵,考虑每个隐藏状态中不同特征之间的相关性。
- “tied” 表示所有隐藏状态共享同一个完整的协方差矩阵。协方差类型的选择应基于对每个隐藏状态中数据结构的假设。更复杂的协方差类型,如 “full”,可能更适合特征之间具有复杂依赖关系的数据,但需要估计更多参数,当数据不足时,这可能会导致过拟合。
hmm.GaussianHMM 的不同参数所提供的灵活性允许研究人员根据金融时间序列的具体特征来调整模型。具体来说,`covariance_type` 参数允许我们对每个隐藏状态中特征之间的关系做出不同的假设。
在为金融时间序列调整 hmm.GaussianHMM 的参数时,应考虑其特定特征,如波动性、价格冲击以及分布可能偏离正态分布的情况。隐状态的数量(n_components)应根据预期的市场状态数量来选择。这可以根据专家知识或使用模型选择标准(如 AIC 或 BIC)来确定。
建议从少量状态(例如 2 或 3 个)开始,并根据需要增加状态数,同时控制过拟合的风险。对于单变量金融时间序列(例如收益率),“diag” 或 “spherical” 协方差类型可能就足够了。对于多元序列(例如多种资产或特征的回报,如价格和交易量),“full” 允许对相关性进行建模,但会增加模型的复杂性。“tied” 协方差类型假设所有条件下的相关结构相同。
min_covar 参数通过确保方差不会变得太小来防止过拟合。默认值 1e-3 通常是一个不错的起点。设置信息丰富的先验分布(例如使用 startprob_prior 和 transmat_prior 来反映关于初始状态概率和转移趋势的先验想法)可能很有用,尤其是在数据有限的情况下。例如,人们可能会预期市场状态具有稳定性,这种预期可以编码在转移矩阵的先验分布中。
n_iter 和 tol 参数控制 EM 算法的最大迭代次数和收敛阈值。n_iter 值越大,收敛效果可能越好,但训练时间也会增加。tol 值越小,收敛标准就越严格。
金融数据的预处理至关重要。建议使用收益率(百分比变化)而不是价格,并可能包括移动平均线、波动率指标(如 ATR)和成交量指标等技术指标。建议对特征进行归一化或标准化处理。金融时间序列通常是非平稳的。应考虑对数据进行差分处理,或使用滑动窗口进行参数估计,以适应不断变化的市场动态。
为了为特定的金融数据集找到最优的超参数组合,应采用网格搜索或贝叶斯优化(例如,使用 Optuna)等方法。金融时间序列的非平稳性要求认真进行预处理,并可能需采用自适应方法,如滑动窗口学习。超参数调优对于确保 GaussianHMM 模型能够有效捕捉潜在的市场动态,而不会过度拟合历史数据至关重要。
hmm.GMMHMM 类
hmm.GMMHMM 类是为处理连续观测而设计的,连续观测最好用几个高斯分布的混合来表示。这允许对比使用单个高斯分布更复杂的观测模式进行建模,这对于每个隐藏状态内具有明显簇的数据特别有用。
当给定体系内的金融数据分布呈现多模态或显著偏离高斯分布时,hmm.GMMHMM 可能很有用。例如,在高波动性环境下,收益可能根据价格走势方向的不同而呈现出不同的特征。hmm.GMMHMM 通过允许每个隐藏状态与高斯分布的混合相关联,扩展了 hmm.GaussianHMM。这对于金融时间序列尤其有益,因为金融时间序列在不同的市场状态下可能表现出更复杂且非正态分布的行为。
- hmm.GMMHMM 类构造函数包含 hmm.GaussianHMM 类的所有参数,并添加了 n_mix 参数(整数,默认为 1),该参数指定每个状态中的混合成分数量,以及与混合权重相关的先验。
- GMMHMM 中的 covariance_type 参数有一个略有不同的 “tied” 选项:每个状态的所有混合成分共享同一个完整的协方差矩阵。
- params 和 init_params 参数还包含符号 “w”,用于控制 GMM 混合权重。
- 参数的关键区别在于 n_mix 和混合权重的相关先验分布,这使得对每个隐藏状态的观测概率进行更灵活的建模成为可能。GMMHMM 中更微妙的 “tied” 协方差选项也提供了另一种约束模型的方法。
在为金融时间序列设置 hmm.GMMHMM 参数时,选择混合成分的数量 (n_mix) 是一个关键步骤。混合成分的数量应该能够最好地代表每个隐藏状态下金融数据的分布。这可能需要一些实验。建议从少量组件(例如 2 或 3 个)开始,如果模型欠拟合,则增加组件数量,但应避免过拟合。
可以使用 AIC 或 BIC 等信息准则来确定 n_mix 的最佳值。其他参数的配置方式与 hmm.GaussianHMM 参数类似,但需考虑金融数据的具体特征。例如,covariance_type 的选择将影响每个混合分量内部方差建模的方式。选择最佳混合成分数 (n_mix) 是有效使用 hmm.GMMHMM 处理金融时间序列的重要步骤。这涉及到在模型捕捉复杂数据分布的能力与过拟合风险之间取得平衡,并可能需要使用交叉验证或信息准则等方法来获得稳健的估计。
vhmm.VariationalGaussianHMM 类
vhmm.VariationalGaussianHMM 类是一个具有多元高斯观测的隐马尔可夫模型,它使用变分推理进行训练,而不是使用 hmm.GaussianHMM 中使用的期望最大化 (EM) 算法。
变分推理旨在找到最接近潜在变量和模型参数真实后验分布的分布参数。与提供参数点估计的 EM 算法不同,变分推理为模型参数提供了后验分布,这对于估计不确定性非常有用。
vhmm.VariationalGaussianHMM 的主要区别在于使用变分推理进行训练。这种贝叶斯方法比 hmm.GaussianHMM 中的最大似然估计具有优势,尤其是在通过模型参数的后验分布提供不确定性度量方面。
- vhmm.VariationalGaussianHMM 类的构造函数包括 n_components、covariance_type、algorithm、random_state、n_iter、tol、verbose、params、init_params 和实现参数,与 hmm.GaussianHMM 的构造函数类似。
- 与先验分布相关的关键附加参数是 startprob_prior、transmat_prior、means_prior、beta_prior、dof_prior 和 scale_prior。如果将这些参数设置为 None,则使用默认的先验分布。beta_prior 参数与均值正态先验分布的精度有关。dof_prior 和 scale_prior 参数定义了协方差矩阵的先验分布(根据 covariance_type,可能是逆威沙特分布或逆伽马分布)。
- vhmm.VariationalGaussianHMM 的初始化需要指定所有模型参数的先验分布。这些先验分布在训练中起着重要作用,尤其是在数据有限的情况下,它们允许将关于参数的先验知识或信念纳入其中。
在调整用于金融时间序列的 vhmm.VariationalGaussianHMM 的参数时,先验分布的选择非常重要。先验分布起到一种正则化作用,防止模型过度拟合训练数据。它们还可以把已有的参数先验知识纳入模型。
例如,如果可以认为初始状态分布(startprob_)应该相对均匀,则可以使用对称参数接近 1 的狄利克雷先验。类似地,关于转移概率(transmat_)、均值(means_prior)或协方差(scale_prior、dof_prior)的信念可以通过适当选择先验分布进行编码。
先验分布的选择会影响模型参数在数据训练后的后验分布。信息量大的先验分布(例如,在给定值附近具有较低方差)将产生更强的影响,使后验分布向先验分布偏移。无信息或弱先验分布(例如,具有大方差或均匀分布的分布)的影响力较小,从而使数据能够主导后验分布。
比较模型在金融时间序列方面的表现
hmm.GaussianHMM 模型是一个基本模型,它假设每个隐藏状态下的观测金融数据服从高斯分布。其优点在于简单且计算效率高,因此适用于大型数据集以及没有理由认为分布明显偏离正态分布的情况。
然而,其缺点在于假设数据服从正态分布,而许多具有偏度、峰度和重尾特征的金融时间序列可能并不符合这一假设。在每个体系的金融数据相对而言能很好地用正态分布近似的情况下,hmm.GaussianHMM 可以表现良好,例如在对每日或每周数据的主要市场体系进行建模时。在建模高频数据或易受峰值和非正态分布影响的数据时,其表现也可能更差。
hmm.GMMHMM 模型扩展了 hmm.GaussianHMM 的功能,允许使用高斯分布的混合来对每个隐藏状态下的观测进行建模。其优势在于能够模拟更复杂的多模态分布,因此更适合在单一市场体制下可能表现出不同子模式的金融数据。例如,在市场波动剧烈的时期,收益可能会根据市场走向而有所不同。
hmm.GMMHMM 的缺点是参数数量增加,这可能导致过拟合,尤其是在数据有限的情况下。此外,与 hmm.GaussianHMM 相比,训练可能需要更多的计算成本。
hmm.GMMHMM 在数据分布明显偏离正态或呈多峰特征时的金融时间序列进行建模时可能表现更好,例如在分析日内或波动率数据时。在建模近似正态分布的简单模型或数据集非常小的情况下,其表现可能会更差,因为过拟合的风险很高。
vhmm.VariationalGaussianHMM 模型使用变分推理进行学习,这是一种贝叶斯方法。其优势在于能够提供后验参数分布,从而评估模型的不确定性。在数据有限的情况下,贝叶斯方法也能发挥作用,这得益于其使用了先验分布,能够对模型进行正则化并融入先验知识。
vhmm.VariationalGaussianHMM 的一个缺点是难以调整先验分布,这可能会对结果产生重大影响。此外,变分推理是一种近似方法,由此得到的后验分布可能与真实的后验分布存在差异。
vhmm.VariationalGaussianHMM 在对金融时间序列进行建模时表现更佳,因为参数不确定性很重要,或者当可用数据有限且必须使用先验知识时,VariationalGaussianHMM 的表现会更好。如果先验分布选择不当,或者需要非常高的参数估计精度(而最大似然法在数据充足的情况下可以提供这种精度),则其表现可能会更差。
模型的选择受到诸多因素的影响,如可用数据量、市场动态的复杂性以及对模型可解释性的要求。对于大型数据集和相对简单的市场动态,hmm.GaussianHMM 可能足够简单且更受欢迎,因为它简单且计算效率高。对于更复杂的动力学或非正态分布,可能需要 hmm.GMMHMM。如果不确定性评估很重要或者可用数据很少,则应考虑使用 vhmm.VariationalGaussianHMM。
结论和建议
对于金融时间序列,潜在的最佳或最差模型取决于具体问题和数据的特征。
一般来说,如果市场状态下的金融数据可以用高斯分布合理地近似,那么 hmm.GaussianHMM 就是一个简单而有效的选择。如果分布更复杂或具有多峰性,hmm.GMMHMM 可能提供更好的拟合效果,但需要更仔细的调参,并且更容易出现过拟合。vhmm.VariationalGaussianHMM 提供了一种贝叶斯方法,能够估计不确定性,这在某些情况下非常有用,但需要理解并正确选择先验分布。
需要强调的是,模型的选择不能仅凭理论依据。对真实金融数据进行经验估计和回溯测试是确定哪种模型最适合特定问题的必要步骤。应使用各种性能指标(如对数似然、预测准确率和金融特定指标(如 MAPE、R^2))来比较模型的性能,并选择最适合解决特定金融时间序列分析问题的模型。
hmmlearn 库中用于确定时间序列先验协方差矩阵的方法
HMM 的一种常见类型是高斯观测模型,其中假设每个隐藏状态中的观测数据都按照多元正态分布。该分布的参数是均值向量和协方差矩阵,协方差矩阵决定了观测数据各分量之间的形状、方向和依赖程度。
在训练高斯隐马尔可夫模型(Gaussian HMMs)时,尤其是在使用变分推理等贝叶斯方法时,先验协方差矩阵的定义起着重要作用。对时间序列协方差结构的先验知识能显著辅助模型训练,尤其是在数据可用性有限的情况下。先验数据指定错误可能导致结果不佳、学习算法出现收敛问题或模型过拟合。
Python hmmlearn 库提供了 hmm.GaussianHMM(和 hmm.GMMHMM)和 vhmm.VariationalGaussianHMM 类,用于处理具有高斯观测的 HMM。hmm.GaussianHMM 类使用经典的期望最大化 (EM) 算法实现模型训练,而 vhmm.VariationalGaussianHMM 提供了一种基于变分推断的贝叶斯方法。
这两个类都提供了用于影响训练和初始化的参数,包括指定协方差矩阵的先验分布的能力。具体来说,covariance_type 参数允许您选择协方差矩阵类型(spherical、diagonal、full 或 tied),而 hmm.GaussianHMM 中的 covars_prior 和 covars_weight 参数,以及 vhmm.VariationalGaussianHMM 中的 scale_prior 和 dof_prior 参数,允许您指定协方差的先验分布。正确使用这些参数需要了解确定时间序列先验协方差矩阵的各种方法。
确定时间序列先验协方差矩阵的方法
确定时间序列的先验协方差矩阵有几种方法,每种方法都基于对数据和可用先验信息的不同假设。
经验估计。 最直接的方法之一是直接根据之前收集的时间序列数据来估计协方差矩阵。样本协方差矩阵反映了时间序列中不同分量之间的协方差,其中矩阵的每个元素(i,j)表示第 i 个分量和第 j 个分量之间的样本协方差,而对角线元素则表示样本方差。对于长度为 T、维度为 p 的时间序列 X,可以使用标准方程计算样本协方差矩阵 Σ̂。然而,将经验估计应用于时间序列是有局限性的。
首先,假设时间序列是平稳的,即其统计特性(如均值和协方差)不随时间变化。
其次,为了获得可靠的估计,与时间序列的维度相比,需要足够数量的数据。
第三,当样本量相对于维度较小时,可能会出现协方差矩阵的奇异性问题,这使得它不适合用于某些算法。
尽管存在这些局限性,但如果能获得足够的平稳数据,实证估计仍可作为合理的起点。
收缩方法。 在由于数据量有限或维度较高而导致协方差矩阵的经验估计可能不可靠的情况下,可以使用收缩方法。这些方法将样本协方差矩阵与目标矩阵相结合,使用收缩因子来确定每个矩阵的权重。
目标矩阵可以是,例如,单位矩阵(假设各组件独立)、对角矩阵(假设各组件之间无相关性)或方差恒定的矩阵。线性收缩的方程为 Rα = (1 − α)S + αT,其中 S 是样本协方差矩阵,T 是目标矩阵,α∈[0,1] 是收缩系数。
当数据量有限时,收缩方法特别有用,因为它们能减小协方差矩阵的估计误差,提高其稳健性,并防止模型过拟合。选择目标结构需要预先了解数据中依赖关系的性质。
使用信息先验分布。 如果对主题领域或时间序列的协方差结构有先验知识,则可以通过使用信息丰富的先验分布将这些知识正式纳入模型中。
对于协方差矩阵,通常使用逆威沙特分布,该分布是多变量正态分布中协方差矩阵的共轭先验分布。逆威沙特分布的参数是尺度矩阵和自由度。
先验分布参数的选择应反映关于协方差结构的现有先验信念。基于先前的研究、专家知识或对类似时间序列的分析,可以生成信息先验分布。利用此类先验数据可以显著提升模型训练效果,尤其是在有可靠先验知识支持的情况下。
无信息先验分布。 在缺乏关于时间序列协方差结构的强烈先验信念的情况下,可以使用无信息先验分布。这些先验数据的目的是尽量减少它们对后验分布的影响,从而让数据在很大程度上决定训练结果。
协方差矩阵的无信息先验分布的一个例子是杰弗里斯分布。对于相关矩阵,通常使用 LKJ 先验,它确保相关矩阵空间上的分布均匀,或允许相关系数在零附近有不同程度的集中。然而,值得注意的是,定义一个真正无信息的先验分布可能颇具挑战性,即使是信息量较少的先验数据也可能对结果产生影响,尤其是在数据有限的情况下。
关于时间序列的结构性假设。如果时间序列表现出已知的自相关性,那么可以利用这一知识来生成先验协方差矩阵。例如,分析自相关函数 (ACF) 和偏自相关函数 (PACF) 可以帮助确定描述时间序列的自回归 (AR) 或移动平均 (MA) 过程的阶数。
基于这些模型的参数,可以构建一个反映已知时间依赖性的先验协方差矩阵。例如,对于AR(1)过程,协方差矩阵的结构将取决于自相关参数。这种方法假设时间序列可以用某种时间序列模型来充分描述,并且该模型的参数可以根据先前的数据进行估计。
在 hmmlearn 中应用确定先验协方差矩阵的方法
hmmlearn 库提供了使用 hmm.GaussianHMM 和 vhmm.VariationalGaussianHMM 类定义先验协方差矩阵的各种选项。
利用从初步数据获得的协方差矩阵的经验估计值,可以直接初始化 hmm.GaussianHMM 和 vhmm.VariationalGaussianHMM 类中的 covars_ 属性。类似地,将收缩方法应用于经验协方差矩阵的结果可用于初始化 covars_。
为了指定信息丰富的先验分布,hmm.GaussianHMM 类提供了 covars_prior 和 covars_weight 参数。这些参数控制协方差矩阵 covars_ 的先验分布的参数。先验分布的类型取决于 covariance_type 参数的值。如果 covariance_type 设置为 “spherical” 或 “diag”,则使用逆伽马分布。如果 covariance_type 设置为 “full” 或 “tied”,则使用逆威沙特分布。
covars_prior 参数被解释为逆伽马分布的形状参数,并且与逆威沙特分布的自由度有关。covars_weight 参数是逆伽马分布的尺度参数,与逆威沙特分布的尺度矩阵相关。
vhmm.VariationalGaussianHMM 类还允许我们使用 scale_prior 和 dof_prior 参数为协方差矩阵指定信息丰富的先验分布。dof_prior 参数指定威沙特分布(“full” 和 “tied”)或逆伽马分布(“spherical” 和 “diag”)的自由度。scale_prior 参数指定威沙特分布的尺度矩阵(“full” 和 “tied”)或逆伽马分布的尺度参数(“spherical” 和 “diag”)。这些参数决定了在使用变分推理实现的贝叶斯模型中,关于协方差结构的先验信念。
要指定无信息先验分布,可以使用相应的 covars_prior、covars_weight、scale_prior 和 dof_prior 参数,设置它们的值,使先验分布变得弱或扩散。例如,我们可以为与精度或逆比例相关的参数指定非常小的值,或者为与比例相关的参数指定非常大的值。
最后,可以通过基于自相关分析构建适当的协方差矩阵,并使用该矩阵初始化 hmmlearn 中的两个类的 covars_ 属性,从而考虑时间序列的结构假设。
使用 HMM 识别市场状态:深入实践
在阅读本节之前,我建议您先阅读前两篇文章:
这些文章阐述了构建交易系统的基本原理。但我们不会采用因果推断或市场状态聚类的方法,而是会使用隐马尔可夫模型来识别市场状态。这样你就可以测试并比较这些方法,并就它们的效率形成自己的看法。
在开始之前,请确保已安装必要的软件包:
import math import pandas as pd from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from hmmlearn import hmm, vhmm from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import tester_one_direction from bots.botlibs.export_lib import export_model_to_ONNX
该算法将通过训练隐马尔可夫模型来识别市场状态,其原理与市场状态聚类文章中所述的相同。因此,对代码的修改只会影响市场状态的识别。
以下是定义市场状态的函数:
def markov_regime_switching(dataset, n_regimes: int, model_type="GMMHMM") -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() # Extract meta features meta_X = data.loc[:, data.columns.str.contains('meta_feature')] if meta_X.shape[1] > 0: # Format data for HMM (requires 2D array) X = meta_X.values # Features normalization before training from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Create and train the HMM model if model_type == "HMM": model = hmm.GaussianHMM( n_components=n_regimes, covariance_type="spherical", n_iter=10, ) elif model_type == "GMMHMM": model = hmm.GMMHMM( n_components=n_regimes, covariance_type="spherical", n_iter=10, n_mix=3, ) elif model_type == "VARHMM": model = vhmm.VariationalGaussianHMM( n_components=n_regimes, covariance_type="spherical", n_iter=10, ) # Fit the model model.fit(X_scaled) # Predict the hidden states (regimes) hidden_states = model.predict(X_scaled) # Assign states to clusters data['clusters'] = hidden_states return data
该代码展示了理论部分描述的 3 个模型,这些模型具有默认参数。首先,我们需要确保它们都能正常工作,然后再着手设置参数。在调用函数时,您可以选择其中一个模型,并立即测试聚类质量。
除了识别市场状态的功能外,训练周期保持不变:
for i in range(1): data = markov_regime_switching(dataset, n_regimes=hyper_params['n_clusters'], model_type="HMM") sorted_clusters = data['clusters'].unique() sorted_clusters.sort() for clust in sorted_clusters: clustered_data = data[data['clusters'] == clust].copy() if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) continue clustered_data = get_labels_one_direction(clustered_data, markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1) meta_data = data.copy() meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1)))
训练超参数设置如下:
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 5,
} - 隐马尔可夫模型训练所用的特征周期为 5。
- 黄金买入方向。
- 估计状态数量为五个。
所有模型都将以移动窗口(波动率)中的标准差作为特征进行测试:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
使用默认参数的训练结果
- 使用默认参数的 GaussianHMM 算法证明了其能够有效地找到隐藏状态,从而在测试数据上获得了可接受的余额曲线表现。
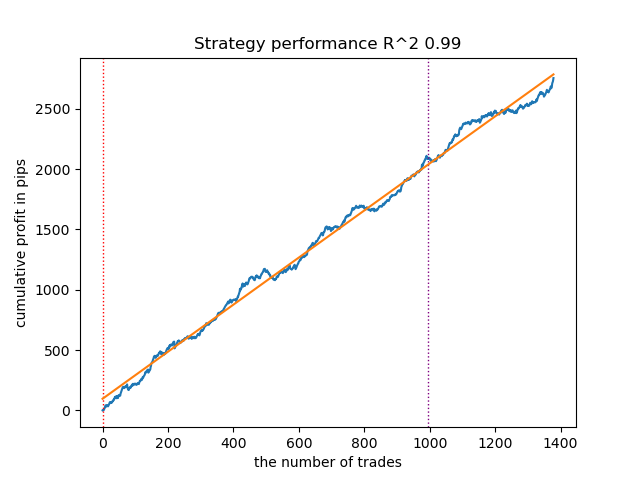
图1.使用默认设置测试 GaussianHMM
- GMMHMM 算法也表现良好,观察到的模型质量没有明显变化。
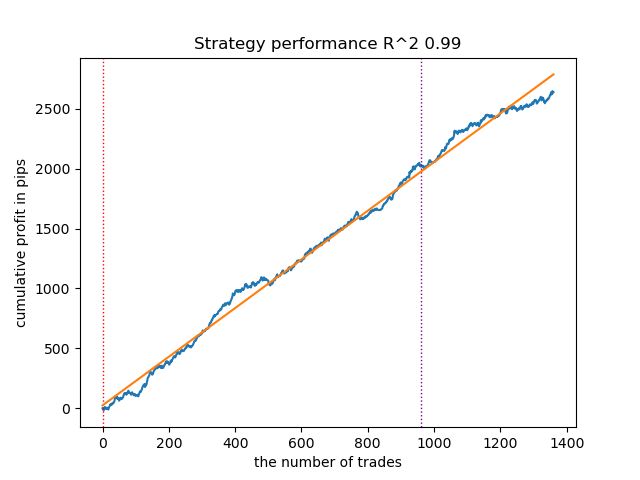
图 2.使用默认设置测试 GMMHMM
- VariationalGaussianHMM 算法可能看起来像个异常值,但经过几次重新训练后,它可以产生更好的曲线。
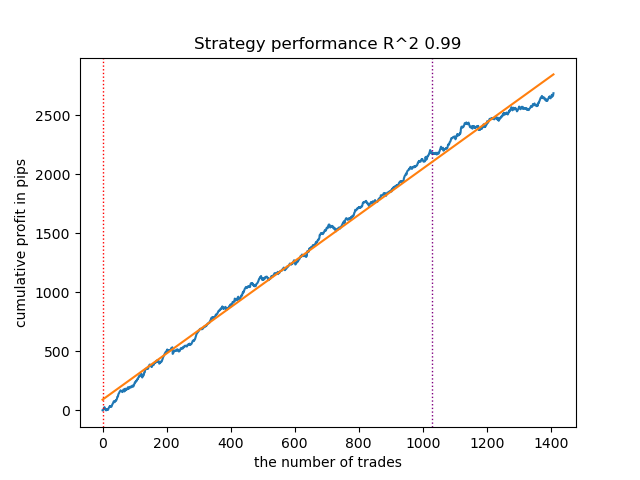
图 3.使用默认设置测试 VariationalGaussianHMM
总体而言,所有算法都已被证明是可行的,这意味着我们可以继续调整它们的参数。
增加训练迭代次数(n_iter = 100)
随着马尔可夫模型训练迭代次数的增加,这几种算法版本在新数据上的结果均有所改善。这显然是因为算法找到了更有利的局部最优解。总体而言,在此阶段,不同算法生成的模型质量并未显示出显著差异。但由于 GaussianHMM 结构简单,其训练速度稍快一些。
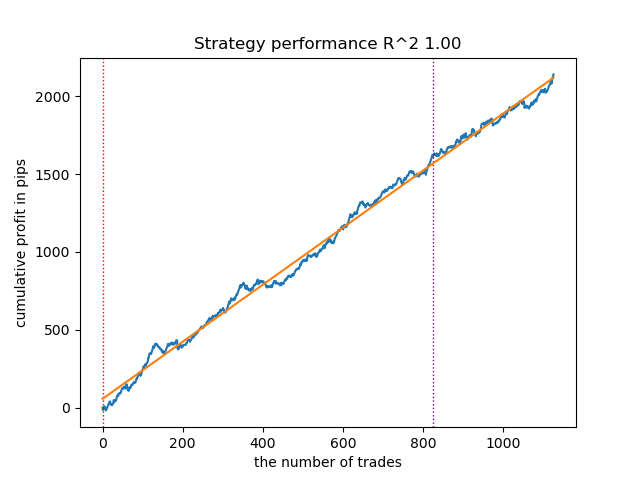
图 4.使用 n_iter = 100 测试 GaussianHMM
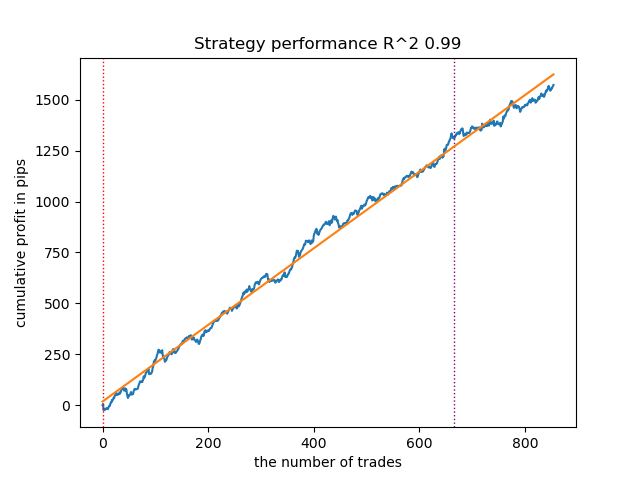
图 5.使用 n_iter = 100 测试 GMMHMM
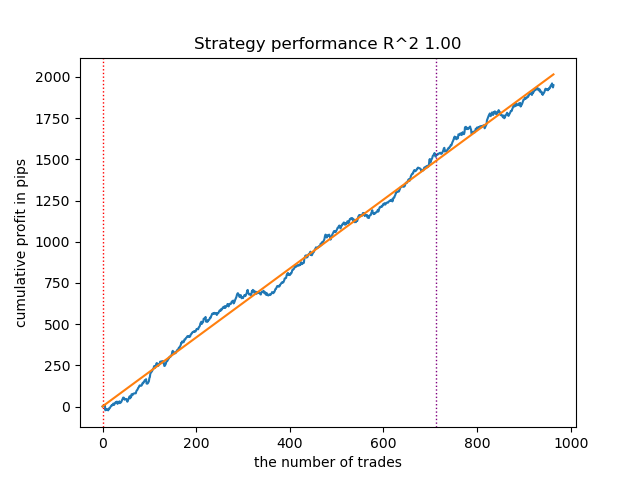
图 6.使用 n_iter = 100 测试 VariationalGaussianHMM
将市场状态的数量减少到三个
迭代次数会影响模型的质量。让我们把这个参数设为 100 次迭代。让我们尝试将状态(模型的隐藏状态)的数量减少到三个,并看看结果。
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 3,
} GaussianHMM、GMMHMM 和 VariationalGaussianHMM 在识别三种市场状态方面表现良好,但最后一个需要多次重新训练。
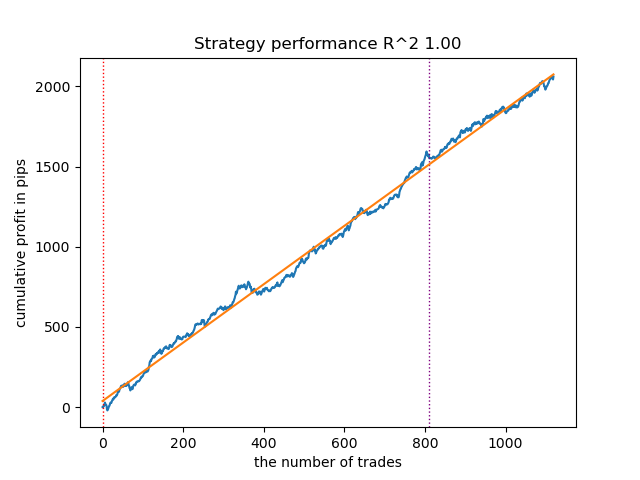
图 7.使用 n_iter = 100 和三种状态测试 GaussianHMM
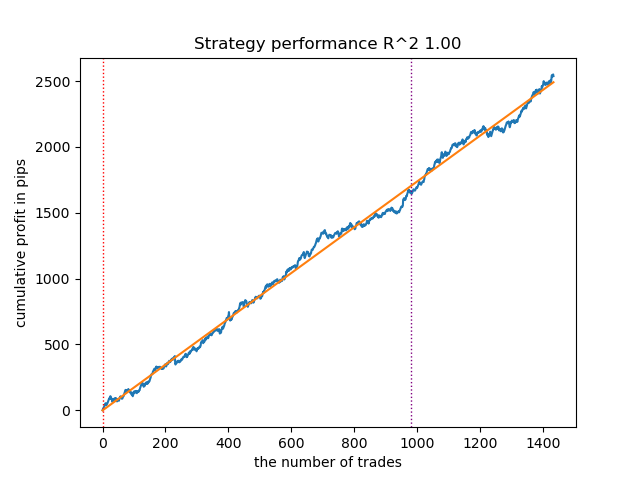
图 8.使用 n_iter = 100 和三种状态测试 GMMHMM
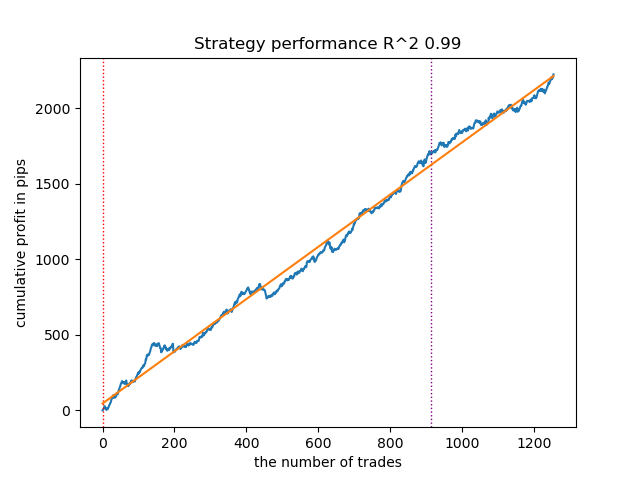
图 9。使用 n_iter = 100 和三种状态测试 VariationalGaussianHMM
为隐马尔可夫模型创建先验协方差矩阵
在本文的理论部分,我们考虑了五种确定时间序列先验协方差矩阵的方法。第一种方法和最后一种方法最适合我们。让我们回顾一下:
- 经验估计。 最直接的方法之一是直接根据之前收集的时间序列数据来估计协方差矩阵。样本协方差矩阵反映了时间序列中不同分量之间的协方差,其中矩阵的每个元素(i,j)表示第 i 个分量和第 j 个分量之间的样本协方差,而对角线元素则表示样本方差。 对于长度为 T、维度为 p 的 X 时间序列,可以使用标准方程计算样本协方差矩阵 Σ̂。然而,将经验估计应用于时间序列是有局限性的。 首先,假设时间序列是平稳的,即其统计特性(如均值和协方差)不随时间变化。 其次,与时间序列的维度相比,获得可靠的估计需要足够数量的数据。 第三,当样本量相对于维度较小时,协方差矩阵可能会出现奇异性,从而使其不适用于某些算法。尽管存在这些局限性,但如果能获得足够的平稳数据,经验估计仍可作为一个合理的起点。
- 关于时间序列的结构性假设。如果时间序列表现出已知的自相关性,那么可以利用这一知识来生成先验协方差矩阵。例如,分析自相关函数 (ACF) 和偏自相关函数 (PACF) 可以帮助确定描述时间序列的自回归 (AR) 或移动平均 (MA) 过程的阶数。 基于这些模型的参数,可以构建一个反映已知时间依赖性的先验协方差矩阵。例如,对于AR(1)过程,协方差矩阵的结构将取决于自相关参数。这种方法假设时间序列可以用某种时间序列模型来充分描述,并且该模型的参数可以根据先前的数据进行估计。
然而,我们无法确定地表示,金融时间序列能够被如此简单的模型充分描述。实验表明,这种先验知识并不总是能改善确定隐马尔可夫状态的结果。此外,我还尝试使用 k-means 进行预聚类,以用获得的值初始化转移矩阵。这导致隐马尔可夫模型产生的结果与前一篇文章中的结果相似,即出现了市场状态聚类,而新数据的余额曲线几乎没有改善或根本没有改善。
基于聚类创建先验分布
训练脚本提供了一个实验函数,该函数使用聚类来预先计算先验概率,然后训练隐马尔可夫模型。
def markov_regime_switching_prior(dataset, n_regimes: int, model_type="HMM", n_iter=100) -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() # Extract meta features meta_X = data.loc[:, data.columns.str.contains('meta_feature')] if meta_X.shape[1] > 0: # Format data for HMM (requires 2D array) X = meta_X.values # Features normalization before training scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Calculate priors from meta_features using k-means clustering from sklearn.cluster import KMeans # Use k-means to cluster the data into n_regimes groups kmeans = KMeans(n_clusters=n_regimes, n_init=10) cluster_labels = kmeans.fit_predict(X_scaled) # Calculate cluster-specific means and covariances to use as priors prior_means = kmeans.cluster_centers_ # Shape: (n_regimes, n_features) # Calculate empirical covariance for each cluster from sklearn.covariance import empirical_covariance prior_covs = [] for i in range(n_regimes): cluster_data = X_scaled[cluster_labels == i] if len(cluster_data) > 1: # Need at least 2 points for covariance cluster_cov = empirical_covariance(cluster_data) prior_covs.append(cluster_cov) else: # Fallback to overall covariance if cluster is too small prior_covs.append(empirical_covariance(X_scaled)) prior_covs = np.array(prior_covs) # Shape: (n_regimes, n_features, n_features) # Calculate initial state distribution from cluster proportions initial_probs = np.bincount(cluster_labels, minlength=n_regimes) / len(cluster_labels) # Calculate transition matrix based on cluster sequences trans_mat = np.zeros((n_regimes, n_regimes)) for t in range(1, len(cluster_labels)): trans_mat[cluster_labels[t-1], cluster_labels[t]] += 1 # Normalize rows to get probabilities row_sums = trans_mat.sum(axis=1, keepdims=True) # Avoid division by zero row_sums[row_sums == 0] = 1 trans_mat = trans_mat / row_sums # Initialize model parameters based on model type if model_type == "HMM": model_params = { 'n_components': n_regimes, 'covariance_type': "full", 'n_iter': n_iter, 'init_params': '' # Don't use default initialization } from hmmlearn import hmm model = hmm.GaussianHMM(**model_params) # Set the model parameters directly with our k-means derived priors model.startprob_ = initial_probs model.transmat_ = trans_mat model.means_ = prior_means model.covars_ = prior_covs # Fit the model model.fit(X_scaled) # Predict the hidden states (regimes) hidden_states = model.predict(X_scaled) # Assign states to clusters data['clusters'] = hidden_states return data return data
以 GaussianHMM 模型为例,先验分布的准备过程如下:
- 数据归一化。使用 StandardScaler 对元特征进行缩放,以消除尺度对聚类结果的影响。
- K-means 聚类。它定义了隐藏状态的初始参数。数据被聚类成 n_regimes 个聚类。获得的聚类标签 cluster_labels 用于计算均值 prior_means(聚类中心)和协方差矩阵 proir_covs - 聚类内的经验协方差,或者如果聚类太小则计算总协方差。
- 计算初始概率。初始分布 initial_probs:每个聚类中的点的比例。例如,如果 30% 的数据属于聚类 0,则 initial_probs[0] = 0.3。
- 转移矩阵。它计算一个聚类在时间上跟随另一个聚类的次数。
- 然后,利用这些先验知识初始化隐马尔可夫模型并进行训练。
其余方法对依赖性的假设更为宽松,因此根本未被考虑。这可能并不是确定先验分布所有可能方法的完整列表。也可以采用其他方法,但应以专家判断为依据。
测试具有先验分布的隐马尔可夫模型
可以发现,结果的分散程度有所降低。模型陷入局部最小值的可能性降低了,但它们的多样性却减少了。此外,使用隐马尔可夫模型识别市场状态通常需要比 k-means 算法更少的状态(聚类)。
下面给出使用给定先验分布测试三个模型的结果:
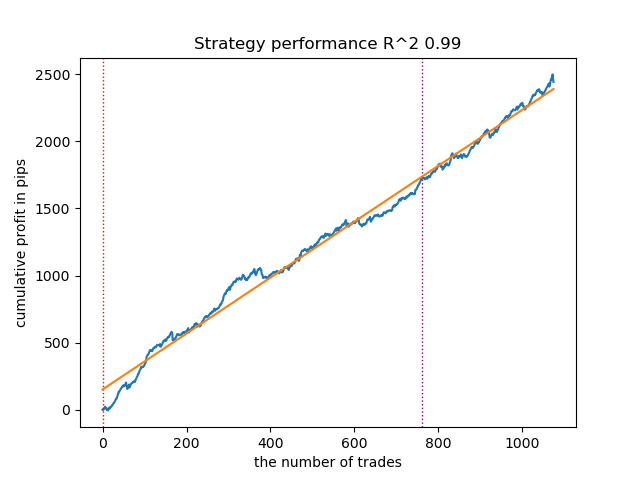
图 10.使用先验分布测试 GaussianHMM
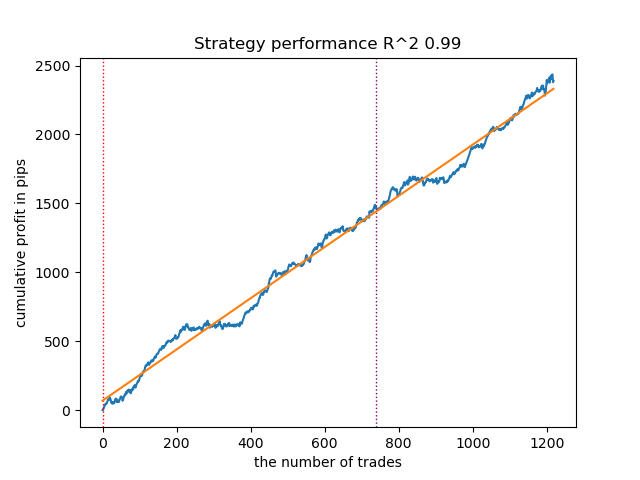
图 11。使用先验分布测试 GMMHMM
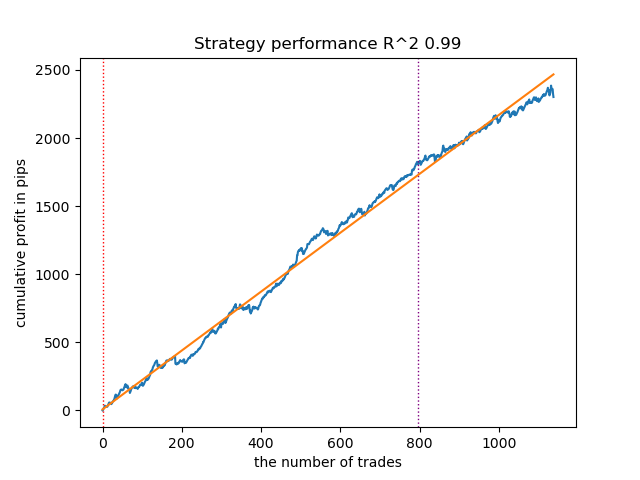
图 12。使用先验分布测试 VariationalGaussianHMM
导出模型并为 MetaTrader 5 编译机器人
导出模型的方式与之前文章中所述完全相同。附带存档中包含带有导出功能的模块。
让我们假设我们已经使用自定义策略测试器选择了一个模型。
# TESTING & EXPORT models.sort(key=lambda x: x[0]) test_model_one_direction(models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=True)
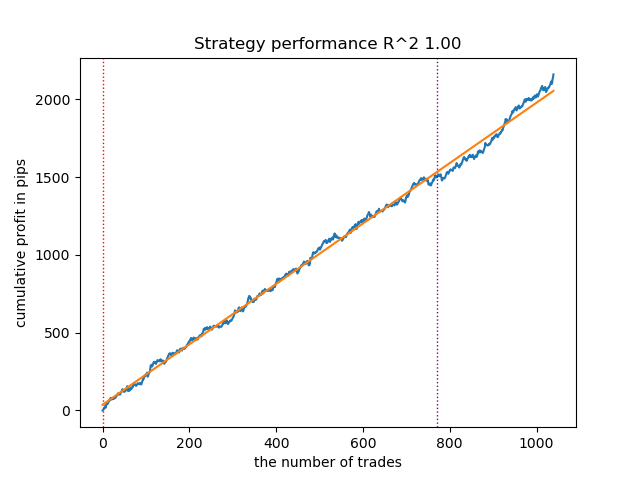
图 13。使用自定义策略测试器测试最佳模型
现在,你需要调用导出函数,该函数会将模型保存到终端文件夹中。
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods_meta'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
然后,我们应该编译附在文章末尾的机器人程序,并在 MetaTrader 5 测试器中进行测试。
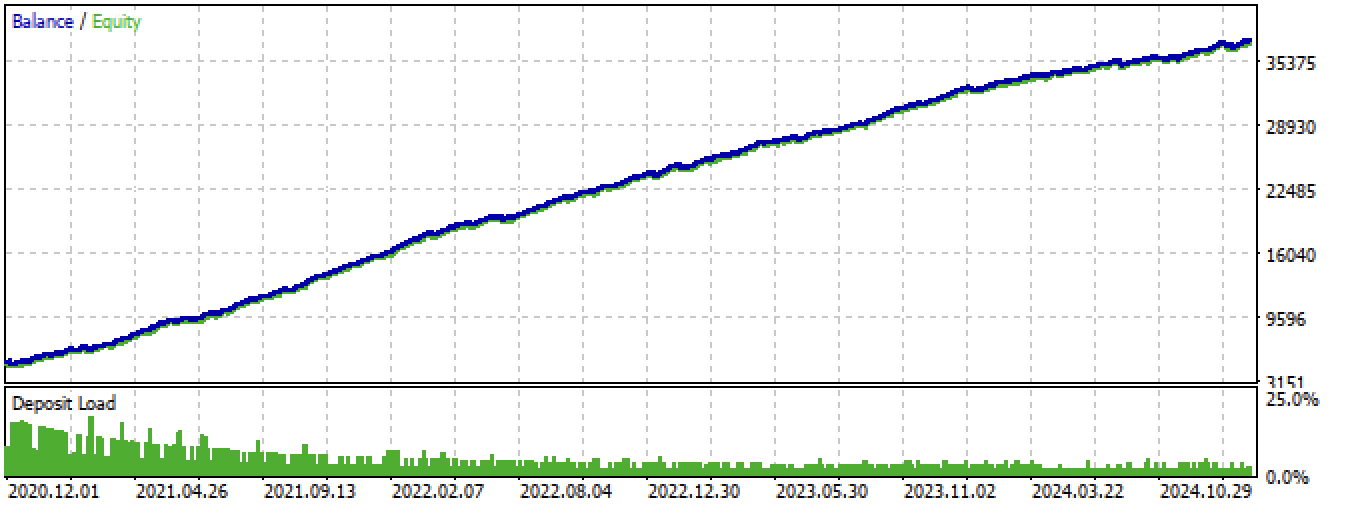
图 14.在整个测试期间,在 MetaTrader 5 终端中测试最佳模型
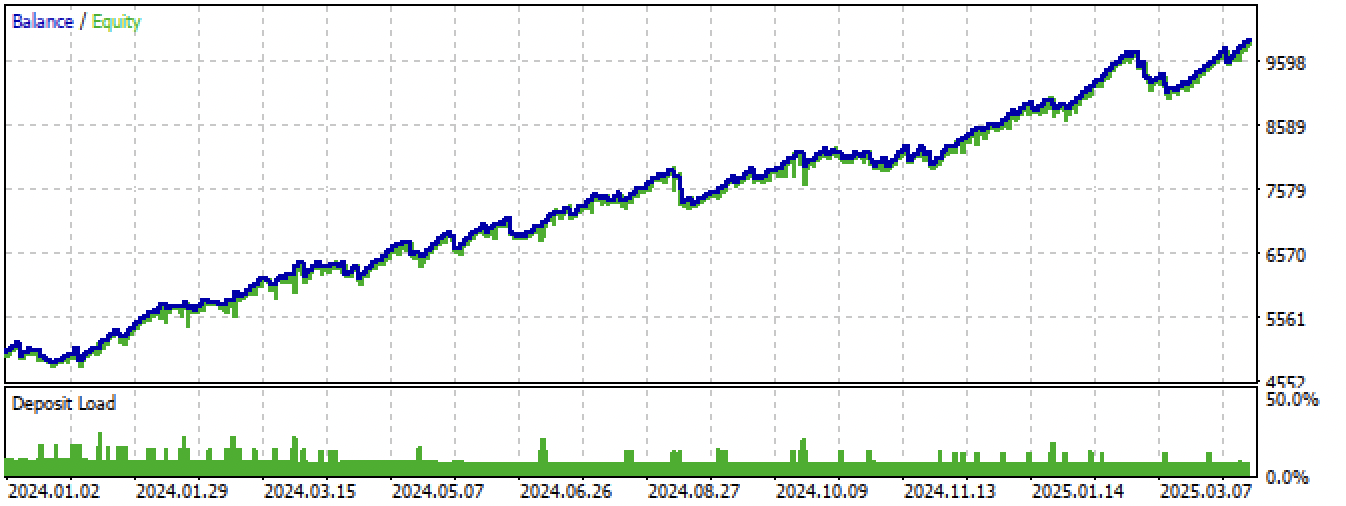
图 15。在 MetaTrader 5 终端中使用新数据测试最佳模型
结论
隐马尔可夫模型是一种识别市场状态的有趣方法。但与所有机器学习模型一样,它们在处理非平稳时间序列时容易出现过拟合现象。
先验矩阵的高质量分配使我们能够找到更稳定的市场状态,这些状态在新数据上仍然有效。通常情况下,它所需的市场状态比集群模式要少。如果第一种情况需要 10 个聚类,那么在第二种情况下,有时只需设置 3-5 个隐藏状态即可。
我发现这三种算法的性能没有太大差异,它们都大致显示出相同的结果。因此,我们可以使用高斯隐马尔可夫模型(GaussianHMM),因为它最简单、速度最快。理论上,GMMHMM 由于混合分布的存在,可以产生更平滑的平衡曲线,这有助于识别每个市场状态中的子模式,但这也可能导致过拟合程度加剧。VariationalGaussianHMM 需要更仔细的先验设置,而其参数更难定义和解释。
另一种有用的方法可能是通过在不同折叠处估计模式分布的参数来进行模型的交叉验证,但本文未考虑此方法。
Python files.zip 压缩包包含以下用于 Python 开发环境的文件:
| 文件名 | 描述 |
|---|---|
| one direction HMM.py | 用于训练模型的主脚本 |
| labeling_lib.py | 更新了包含交易标注模块的模块 |
| tester_lib.py | 基于机器学习的更新版自定义策略测试器 |
| export_lib.py | 用于将模型导出到终端的模块 |
| XAUUSD_H1.csv | 从 MetaTrader 5 终端导出的报价文件。 |
MQL5 files.zip 压缩包包含 MetaTrader 5 终端所需的文件:
| 文件名 | 描述 |
|---|---|
| one direction HMM.ex5 | 文章中编译的机器人 |
| one direction HMM.mq5 | 文章中的机器人源代码 |
| Include/Trend following 文件夹 | ONNX 模型和用于连接机器人的头文件。 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/17917
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
 新手在交易中的10个基本错误
新手在交易中的10个基本错误
Затем, следует скомпилировать приложенного в конце статьи бота и протестировать его в тестере MetaTrader 5.
图14. 在MetaTrader 5交易终端中对最佳模型进行全周期测试
MQL5 files.zip 压缩包包含适用于 MetaTrader 5 交易终端的文件
请将发布文章中包含的回测结果及相应的 tst 文件作为标准做法。谢谢。
请将论文中发布的回测结果及其相应的tst文件作为标准要求。谢谢。