文章 "算法交易策略:人工智能(AI)铸就的“点金”之路"
读完这篇文章后,我有了一个想法,那就是对聚类过程本身进行改进。
我写了一个变体,在滑动窗口中而不是在整个数据集上执行聚类。考虑到 BP 的时间结构,这可能会改善聚类的划分。
def sliding_window_clustering(dataset, n_clusters: int, window_size=200) -> pd.DataFrame: import numpy as np data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] # 首先,我们创建全球参考中心点 global_kmeans = KMeans(n_clusters=n_clusters).fit(meta_X) global_centroids = global_kmeans.cluster_centers_ clusters = np.zeros(len(data)) # 在滑动窗口中进行聚类 for i in range(0, len(data) - window_size + 1, window_size): window_data = meta_X.iloc[i:i+window_size] # 在当前窗口教授 KMeans local_kmeans = KMeans(n_clusters=n_clusters).fit(window_data) local_centroids = local_kmeans.cluster_centers_ # 将局部中心点与全局中心点相匹配 # 确保群组标签的一致性 centroid_mapping = {} for local_idx in range(n_clusters): # 找到离这个本地中心点最近的全局中心点 distances = np.linalg.norm(local_centroids[local_idx] - global_centroids, axis=1) global_idx = np.argmin(distances) centroid_mapping[local_idx] = global_idx + 1 # +1 从 1 开始编号 # 获取当前窗口的标签 local_labels = local_kmeans.predict(window_data) # 将本地标签转换为一致的全局标签 for j in range(window_size): if i+j < len(clusters): # 检查是否出界 clusters[i+j] = centroid_mapping[local_labels[j]] data['clusters'] = clusters return data
在代码中插入该函数,并用 sliding_window_clustering 代替聚类。
结果似乎有所改善。
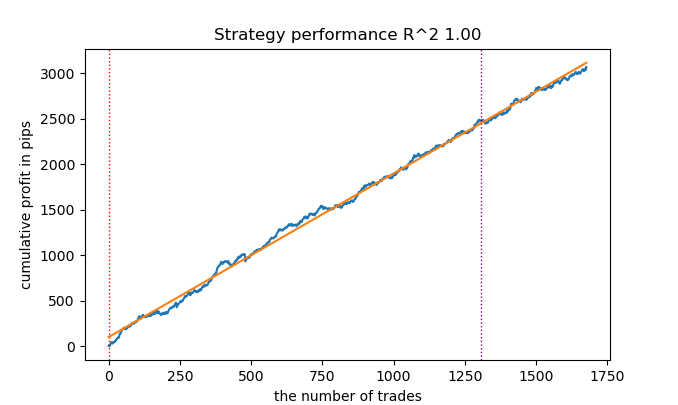
不过,有时候写文章还是很有用的。
感谢 Dmitrievsky 的文章。看起来上传的 EA 和它的包含文件不匹配。
而且 "causal one direction.py "中的 get_features 函数与文章中的不一致。此外,"causal one direction.py "在导出 .onnx 时 生成的 mqh 文件与 MQL5_files.zip 中提供的不一样。
如果您能做出必要的说明,我们将不胜感激。
保罗

我认为我们应该为CatBoost 模型 添加 RandomisedSearchCV 参数枚举,以选择最佳参数。交叉验证也无妨。所有这些都能提高模型的准确性。
sportoman CatBoost 模型 添加 RandomisedSearchCV 参数枚举,以选择最佳参数。交叉验证也无妨。所有这些都能提高模型的准确性。
随机性乘以随机性。这将很难再现,那么你就需要到处固定种子。通常,在一个循环中进行几次再训练就足以对策略进行评估了。
sportoman #:
因此,R2 是一个修正指数,其效率基于点数利润。那么缩水和其他性能指标呢?如果我们的模型在训练中的收益率超过 90%,在测试中的收益率至少达到 85%,那么您的指数就会给出令人印象深刻的数据。无论我在 MT5 上运行测试器多少次,我从未在历史记录上获得过利润。保证金被消耗殆尽。尽管您在 Python 上的测试器给出了 0.97-0.98 的收益,但还是出现了这种情况。
因此,R2 是一个修正指数,其效率基于点数利润。那么缩水和其他性能指标呢?如果我们的模型在训练中的收益率超过 90%,在测试中的收益率至少达到 85%,那么您的指数就会给出令人印象深刻的数据。无论我在 MT5 上运行测试器多少次,我从未在历史记录上获得过利润。保证金被消耗殆尽。尽管您在 Python 上的测试器给出了 0.97-0.98 的收益,但还是出现了这种情况。
我不明白这与 CV 有什么关系。
所有这些策略的证明力都很低,因为它们只是基于非平稳报价的历史。但你可以捕捉趋势。如果趋势发生变化,任何对历史的重复检查都不会增加胜算。也就是说,你不能根据历史来证明未来,你只能估计模型在现有数据基础上的概括能力。这需要一个测试期。
如果已经发明了某种新的有效方法来测试非平稳序列的模型,请告诉我:)。
还有一篇关于均值回归策略的文章。在这篇文章中,我们做了一个更强的假设,即时间序列几乎总是回归均值。这与趋势不同,趋势是会变化的。
新文章 算法交易策略:人工智能(AI)铸就的“点金”之路已发布:
随着对机器学习方法在交易领域应用能力认知的不断深入,各种不同的算法应运而生。这些算法在执行相同任务时表现相似,但内在逻辑却截然不同。本文仍以黄金为例,探讨一种单向趋势交易系统,此次将重点应用聚类算法。
从不同角度对这种重要的时间序列分析与预测方法进行考量,我们能够确定,与仅基于金融时间序列分析与预测来创建交易系统的其他方法相比,该方法具有哪些优势和劣势。在某些情况下,相当有效,在交易系统的创建速度和最终质量方面均超越了传统方法。
在本文中,我们将聚焦于单向交易,即算法仅进行买入或卖出交易操作。我们将采用CatBoost和K-Means算法作为基础算法。CatBoost作为基础模型执行二元分类,用于判定交易方向。而K-Means则用于预处理阶段的市场模式识别。
作者:dmitrievsky