
数据科学和机器学习(第 36 部分):与偏颇的金融市场打交道

内容
概述
不同的外汇市场和金融工具在不同时间展现出不同的行为。虽然一些金融市场如股票和指数在长期运转中常常看涨,而其它如外汇市场则往往显现看跌行为、等等,这种不确定性在利用人工智能(AI)技术和机器学习(ML)预测市场时增加了复杂性。

我们拿几个金融市场(交易代码),及日线时间帧,可视化 1000 根柱线的市场方向。如果一根柱线的收盘价高于开盘价,我们可以将其标记为看涨柱线(1),否则,我们可以将其标记为看跌柱线(0)。
import pandas as pd import numpy as np symbols = [ "EURUSD", "USTEC", "XAUUSD", "USDJPY", "BTCUSD", "CA60", "UK100" ] for symbol in symbols: df = pd.read_csv(fr"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\1640F6577B1C4EC659BF41EA9F6C38ED\MQL5\Files\{symbol}.PERIOD_D1.data.csv") df["Candle type"] = (df["Close"] > df["Open"]).astype(int) print(f"{symbol}(unique):",np.unique(df["Candle type"], return_counts=True))
成果。
EURUSD(unique): (array([0, 1]), array([496, 504])) USTEC(unique): (array([0, 1]), array([472, 528])) XAUUSD(unique): (array([0, 1]), array([472, 528])) USDJPY(unique): (array([0, 1]), array([408, 592])) BTCUSD(unique): (array([0, 1]), array([478, 522])) CA60(unique): (array([0, 1]), array([470, 530])) UK100(unique): (array([0, 1]), array([463, 537]))
能从上面的成果所见,没有一个交易品种完美平衡,在于历史上出现的空头和多头烛条数量不同。
市场偏向某一特定方向本身没问题,但这种历史数据偏颇可能会在训练机器学习模型时引发一些问题,具体如下:
话说我们想基于当前数据集训练一个 USDJPY 模型,数据集中有 1000 根柱线,我们得到 408 根看跌烛条(标记为 0),占所有交易信号的 40.8%;同期我们得到 592 根看涨烛条(标记为 1),占所有交易信号的 59.2%。
存在的看涨信号压过存在的看跌信号,是以机器学习模型更多可能忽视看跌信号,在于模型倾向于偏好盛行类,从而做出有利于更胜类的预测。
鉴于所有模型都旨在达成最低的亏损值,同时完成最大可能的准确率,故模型会有利于看涨类,这在满额 100% 的概率中占据了 59.2% 的时间,如此这般是触及最大准确值的捷径。
这并非高深科学,因为若您忽略所有预测因素和市场中发生的一切,仅凭这些简单信息来预测 USDJPY,您可以说所有柱线在所有时间都看涨,您大约有 59.2% 的概率是正确的,这还不错吧?大错!
因为这样做会让您假设过去发生的事情必然会再次发生,而这在交易世界中是大错特错,简直错得离谱。
正如您所见,机器学习在处理一个问题时,分类数据中目标变量会不平衡,以下是由此带来的一些不足。
机器学习中不平衡目标变量的不足
- 次要类表现不佳
正如我早前所说,模型会朝着主类预测偏颇,因为它优化了整体准确率。例如,在欺诈检测数据中(99% 非欺诈,1% 欺诈),由于大多数人是非欺诈者,故模型或许始终预测非欺诈,且仍会得到 99% 的准确率,但这会令检测欺诈失败。 - 误导性的评估量值
准确率数值变得不可靠,您可能有一个模型的联动准确率为 72%,却未察觉某类预测准确率为 95%,而另一类的预测准确率为 50%。 - 模型过度拟合主类
模型能够记忆来自主类的噪声,从而做出偏颇决策,取代学习预测变量中的普通形态。例如,一份医学诊断数据(95% 健康,5% 患病),模型或许忽略整个患病病例。 - 对于未见(现实世界)数据普适不佳
在真实世界数据中,分布频繁且迅速变化。如果一个模型是据偏颇环境训练的,它很快就会溃败,在于它是据不现实平衡训练而来。
处理不平衡数据集问题的技术
现在我们已知晓分类问题中不平衡(偏颇)目标变量所带来的不足之处,我们来讨论解决问题的不同途径。
01:选择正确的评估量值
处理不平衡数据的第一种技术是选择正确的评估量值,正如不足中所说,分类器的准确性(即正确预测的总数,除以预测的总数)在不平衡数据中可能具有误导性。
在不平衡数据问题中,其它量值,譬如衡量分类器预测特定类准确性的精度,以及唤醒率(衡量分类器识别类的能力)比准确率量值更实用。
当处置不平衡数据集时,大多数机器学习专家会用到 f1-分数,在于它更为合适。
它很简单,是精度与唤醒的谐波平均值,由公式表示。

故此,如果分类器预测的是次要类,但预测错误、且假阳增加,精度量值会较低,f1 分数也会降低。
此外,如果分类器识别次要类不佳,那么假阴性会增加,故此唤醒率和 F1 分数都会较低。
仅当分数和整体预测品质提升时,F1 分数才会上升。
为了详细理解这一点,我们先在带有偏颇的 USDJPY 金融工具上训练一个简单的 RandomForest 分类器。
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report # Global variables symbol = "USDJPY" timeframe = "PERIOD_D1" lookahead = 1 common_path = r"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\Common\Files" df = pd.read_csv(f"{common_path}\{symbol}.{timeframe}.data.csv") # Target variable df["future_close"] = df["Close"].shift(-lookahead) # future closing price based on lookahead value df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) print("Signals(unique): ",np.unique(df["Signal"], return_counts=True)) X = df.drop(columns=["Signal", "future_close"]) y = df["Signal"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=False) model = RandomForestClassifier(n_estimators=100, max_depth=5, min_samples_split=3, random_state=42) model.fit(X_train, y_train)
训练完成之后,我们能够将模型保存为 ONNX 格式,以便后续在 MetaTrader 5 中所用。
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType import os def saveModel(model, n_features: int, technique_name: str): initial_type = [("input", FloatTensorType([None, n_features]))] onnx_model = convert_sklearn(model, initial_types=initial_type, target_opset=14) with open(os.path.join(common_path, f"{symbol}.{timeframe}.{technique_name}.onnx"), "wb") as f: f.write(onnx_model.SerializeToString())
saveModel(model=model, n_features=X_train.shape[1], technique_name="no-sampling")
我只得使用分类报告方法来观察 Scikit-Learn 中不同的量值。
Train Classification report precision recall f1-score support 0 0.98 0.41 0.57 158 1 0.68 1.00 0.81 204 accuracy 0.74 362 macro avg 0.83 0.70 0.69 362 weighted avg 0.81 0.74 0.71 362
训练分类报告分析
模型的整体训练准确率为 0.74,初看好似还不错,不过按类仔细观察量值之后,发现模型在两个类之间存在显著不平衡,0 类的精确度极高为 0.98,而唤醒率低至 0.41,导致 F1 分数仅为 0.57。
这意味着虽然模型在预测类 0 时非常有信心,但它会遗漏大量实际的类 0 样本,示意的灵敏度不佳。
另一方面,类 1 所展示的唤醒率为 1.00,F1 分数为 0.81,但精度 0.68 相对较低。
这表明模型过于偏向预测类 1,可能导致大量假阳性。
类 1 的完美唤醒(1.00)是一个红色标志,在于它很可能示意过度拟合、或偏向主类。
模型几乎把所有内容都预测为类 1,并错失许多实际的类 0 样本,这从类 0 的可怜唤醒值 0.41 中可见一斑。
总体上,这些量值不仅展示出不平衡,也引发了对模型普适能力、及其跨类别公平性的担忧。此处有些事情明显不对劲。
我们利用过抽样技术来改进模型,并找到预测平衡。
一款测试智能系统(EA)
机器学习模型分析如上述分类报告的结果,与 MetaTrader 5 的实际交易结果之间始终存在差异。由于我们将把模型保存为 ONNX 格式,以备后续所用,我们能够打造一款简单的交易机器人,按照本文讨论的每种重抽样技术训练模型,并策略测试器上依据训练样本制定交易决策。
所用数据收集在名为 Collectdata.mq5 的文件之内,这是一个脚本,收集的训练数据自 2023 年 01 月 01 日直至 2025 年 01 月 01 日。您能在本文章附件中找到它。
在名为 Test Resampling Techniques.mq5 的智能系统(EA)中,我们初始化 ONNX 格式的模型,然后用它进行预测。
#include <Random Forest.mqh> CRandomForestClassifier random_forest; //A class for loading the RFC in ONNX format #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> CTrade m_trade; CPositionInfo m_position; input string symbol_ = "USDJPY"; input int magic_number= 14042025; input int slippage = 100; input ENUM_TIMEFRAMES timeframe_ = PERIOD_D1; input string technique_name = "randomoversampling"; int lookahead = 1; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!random_forest.Init(StringFormat("%s.%s.%s.onnx", symbol_, EnumToString(timeframe_), technique_name), ONNX_COMMON_FOLDER)) //Initializing the RFC in ONNX format from a commmon folder return INIT_FAILED; //--- Setting up the CTrade module m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(symbol_); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- vector x = { iOpen(symbol_, timeframe_, 1), iHigh(symbol_, timeframe_, 1), iLow(symbol_, timeframe_, 1), iClose(symbol_, timeframe_, 1) }; long signal = random_forest.predict_bin(x); //Predicted class double proba = random_forest.predict_proba(x).Max(); //Maximum predicted probability MqlTick ticks; if (!SymbolInfoTick(symbol_, ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(symbol_, SYMBOL_VOLUME_MIN); if (signal == 1) { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, symbol_, ticks.ask,0,0); } if (signal == 0) { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, symbol_, ticks.bid,0,0); } //--- CloseTradeAfterTime((Timeframe2Minutes(timeframe_)*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool PosExists(ENUM_POSITION_TYPE type) { for (int i=PositionsTotal()-1; i>=0; i--) if (m_position.SelectByIndex(i)) if (m_position.Symbol()==symbol_ && m_position.Magic() == magic_number && m_position.PositionType()==type) return (true); return (false); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool ClosePos(ENUM_POSITION_TYPE type) { for (int i=PositionsTotal()-1; i>=0; i--) if (m_position.SelectByIndex(i)) if (m_position.Symbol() == symbol_ && m_position.Magic() == magic_number && m_position.PositionType()==type) { if (m_trade.PositionClose(m_position.Ticket())) return true; } return (false); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CloseTradeAfterTime(int period_seconds) { for (int i = PositionsTotal() - 1; i >= 0; i--) if (m_position.SelectByIndex(i)) if (m_position.Magic() == magic_number) if (TimeCurrent() - m_position.Time() >= period_seconds) m_trade.PositionClose(m_position.Ticket(), slippage); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int Timeframe2Minutes(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return 1; case PERIOD_M2: return 2; case PERIOD_M3: return 3; case PERIOD_M4: return 4; case PERIOD_M5: return 5; case PERIOD_M6: return 6; case PERIOD_M10: return 10; case PERIOD_M12: return 12; case PERIOD_M15: return 15; case PERIOD_M20: return 20; case PERIOD_M30: return 30; case PERIOD_H1: return 60; case PERIOD_H2: return 120; case PERIOD_H3: return 180; case PERIOD_H4: return 240; case PERIOD_H6: return 360; case PERIOD_H8: return 480; case PERIOD_H12: return 720; case PERIOD_D1: return 1440; // 1 day = 1440 minutes case PERIOD_W1: return 10080; // 1 week = 7 * 1440 minutes case PERIOD_MN1: return 43200; // Approx. 1 month = 30 * 1440 minutes default: PrintFormat("Unknown timeframe: %d", tf); return 0; } }
由于我们所训练模型是基于前瞻值 1,我们须在当前时间帧内经历前瞻数量的栏线之后了结交易,如此行事我们有效确保前瞻值得到了尊重,在于我们根据模型的预测横向范围持仓、及平仓。
在我们考察基于重采样数据训练模型的交易结果之前,我们先来观察一个基于非重采样训练数据(毛料数据)模型的交易结果。
测试器配置。
输入:technique_name = no-sampling。
测试结果。
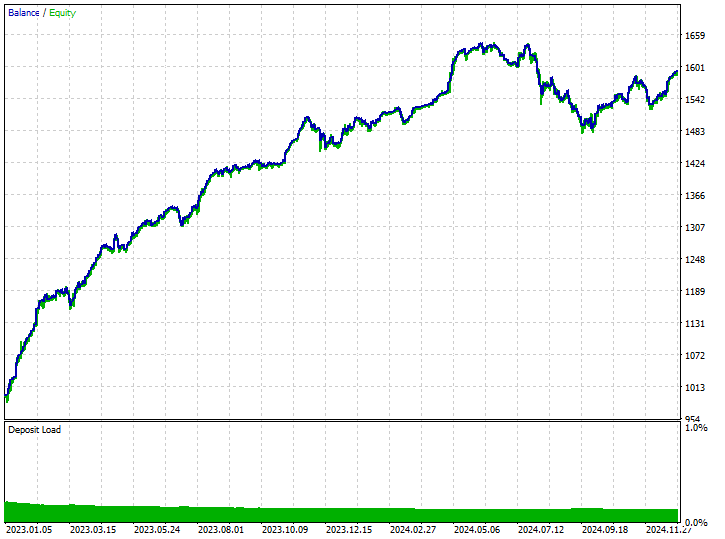
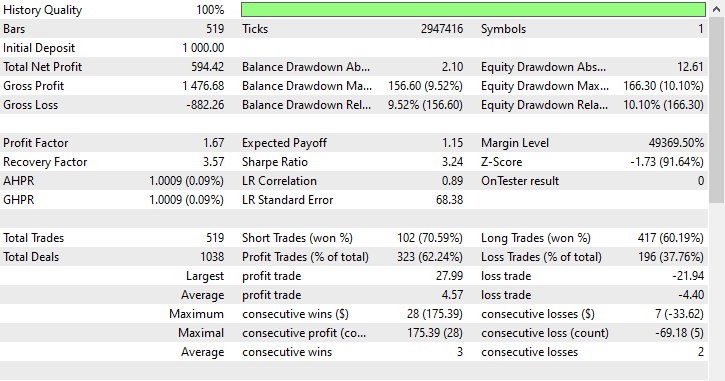
尽管模型能够捕捉到一些良好的信号,并取得了令人印象深刻的交易结果,整体盈利交易占所有交易的 62.24%。如果您考察空头和多头交易的胜局,您会见到空头和多头交易的比率是 1:4。
519 笔交易中有 102 笔做空,导致胜率为 70.59%,而有 417 笔做多,胜率为 60.19%,此处有些事情明显不对劲,因为我们分析的烛条走向是根据前瞻值 1,自 2023 年 1 月 1 日至 2025 年 1 月 1 日。
print("classes in y: ",np.unique(y, return_counts=True))
成果。
classes in y: (array([0, 1]), array([225, 293]))
我们能见到 225 是看跌价格走势,293 是看涨。由于在这两年间(2023 年 1 月 1 日至 2025 年 1 月 1 日),大多数的 USDJPY 烛条走向多头,任何糟糕模型只要看涨都能获利。这并不很难。
现在我们就能理解,模型之所以能获得一定盈利,仅有的原因就是它偏好多头交易多于空头交易 4 倍。
由于当时市场大多看涨,故能够产生一些盈利。
我们继续谈重采样技术,看看如何解决模型中的这种偏颇决策制定。
过抽样技术
随机过抽样
这种技术创建次要类的合成样本,常用来解决数据集中类的不平衡。
它涉及随机选择存在的次要类样本,并复现它们,以便在训练数据中提升它们的代表性,旨在把不平衡数据集中的类分布带至平衡。
这项任务最常用的工具是 imbalanced-learn,下面是一个简单的运用方式。
from imblearn.over_sampling import RandomOverSampler print("b4 Target: ",np.unique(y_train, return_counts=True)) rus = RandomOverSampler(random_state=42) X_resampled, y_resampled = rus.fit_resample(X_train, y_train) print("After Target: ",np.unique(y_resampled, return_counts=True))
输出:
b4 Target: (array([0, 1]), array([304, 395])) After Target: (array([0, 1]), array([395, 395]))
我们能将重抽样数据拟合到之前用过的同一个 RandomForestClassifier,观察成果与无重抽样数据成就的差别。
model.fit(X_resampled, y_resampled)
模型的评估。
y_train_pred = model.predict(X_train) print("Train Classification report\n",classification_report(y_train, y_train_pred))
成果。
Train Classification report precision recall f1-score support 0 0.82 0.85 0.83 158 1 0.88 0.86 0.87 204 accuracy 0.85 362 macro avg 0.85 0.85 0.85 362 weighted avg 0.85 0.85 0.85 362
令人惊讶的是,这些结果示意所有量值都有显著改善。两个类的 F1 分数均为 0.87,表明模型做出了无偏颇、且一致的预测,这点指明模型具有健康的普适能力、及跨目标类的优良分布学习。
尽管过抽样简单有效,但通过创建少数类的复现实例,可能增加过度拟合风险,而这些实例或许无法为模型增添新信息。
使用相同的测试器配置,我们能在策略测试器上测试基于这些数据训练的模型。
输入:technique_name = randomoversampling。
测试结果。
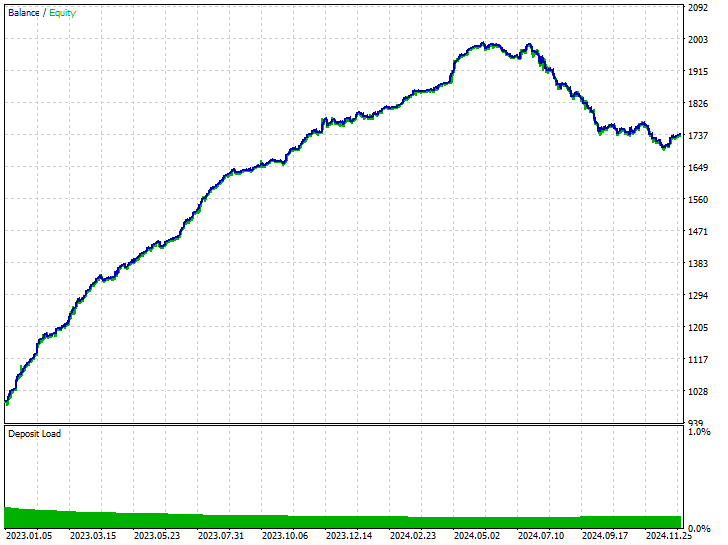
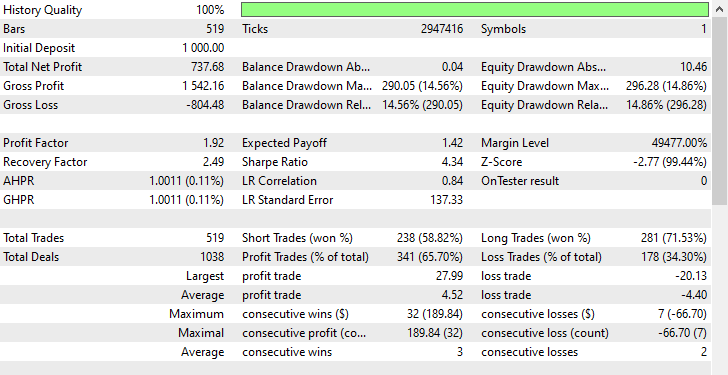
如您所见,我们在所有交易层面都有改进,该模型比用生料数据训练的模型更健壮。现在机器人开立更多空头交易,导致多头交易大幅减少。
再者,在本次训练期间,市场分别展现出 225 笔空头、及 293 笔多头交易,根据我们如何精心制定目标变量,这个基于过抽样数据训练的新模型分别开立了 238 笔空头、和 281 笔多头交易,这是个好迹象,表明模型没有偏见,在于它制定决策时比以往更多基于学到的形态。
欠抽样技术
我们有一对欠抽样技术能在各种 Python 模块中使用。其中一些是:
随机欠抽样
这是一种通过减少主类样本数量,以平衡次要类的技术,常用来解决数据集中的类不平衡。
它涉及随机或策略性地从主类中剔除样本。
类似于我们所应用的过抽样那样,我们能对主类如下欠抽样。
from imblearn.under_sampling import RandomUnderSampler print("b4 Target: ",np.unique(y_train, return_counts=True)) rus = RandomUnderSampler(random_state=42) X_resampled, y_resampled = rus.fit_resample(X_train, y_train) print("After Target: ",np.unique(y_resampled, return_counts=True))
成果。
b4 Target: (array([0, 1]), array([304, 395])) After Target: (array([0, 1]), array([304, 304]))
随机欠抽样和其它欠抽样会通过删除富含信息的主类样本,令模型性能降级,导致训练集的代表性较低。这可能潜在导致模型欠拟合。
该技术令模型在训练数据上的表现,对于两个类都有所提升。
Train Classification report precision recall f1-score support 0 0.76 0.90 0.82 158 1 0.91 0.78 0.84 204 accuracy 0.83 362 macro avg 0.83 0.84 0.83 362 weighted avg 0.84 0.83 0.83 362
使用相同的测试器配置,我们能在策略测试器上测试基于这些数据训练的模型。
输入:technique_name = randomundersampling。
测试结果。
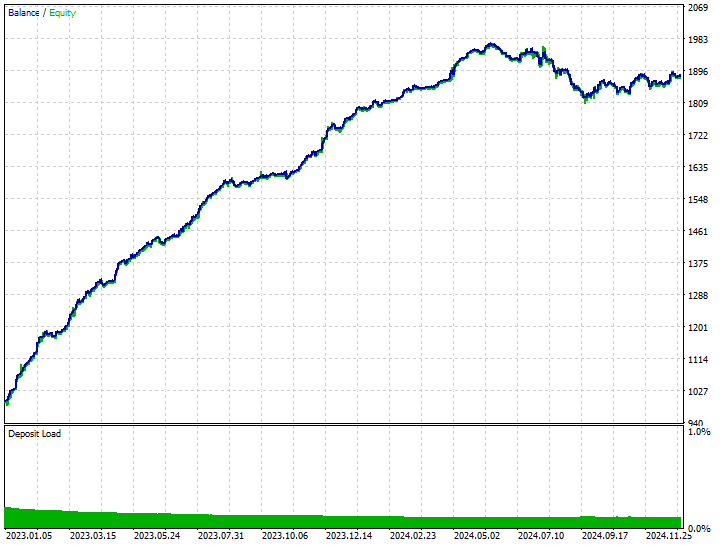
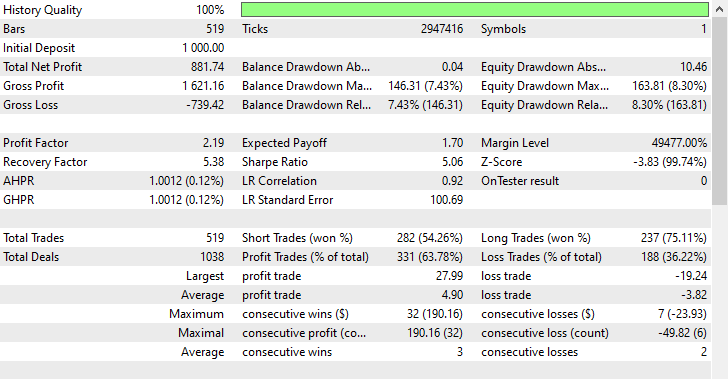
该技术分别产生了 282 笔空头、和 237 笔多头交易,尽管该模型偏向做空,超过做多,而这现象在市场上并未出现,但它仍比依据生料数据训练的偏颇模型、以及偏向看涨走势的过度抽样模型具备赚取更多盈利的能力。
自模型而来这些成果告诉我们,无论历史上发生了什么,我们都能从市场中双向盈利。
托梅克(Tomek)链接
托梅克(Tomek)链接指的是一对来自不同类、且彼此非常接近的实例,往往被视为最近邻。此处是托梅克链接技术如何针对欠抽样机器学习数据进行操作的简单解释。
想象我们有两个点 A 和 B,来自不同的类,A 属于主类,B 属于次要类(或反之亦然)。
如果这两个点(A 和 B)彼此靠近(邻居),那么主类(此处为 A)中的一个观察值将被删除。
该技术有助于清理决策边界,更易区分类,同时仍从主类中删除一些样本。
from imblearn.under_sampling import TomekLinks tl = TomekLinks() X_resampled, y_resampled = tl.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
输出:
Before --> y (unique): (array([0, 1]), array([304, 395])) After --> y (unique): (array([0, 1]), array([304, 283]))
该技术能导致从模型获得令人印象深刻的平衡预测成果,但它限于二元分类,在高度重叠的数据中效果较差,且与其它抽样技术一样,可能导致数据丢失。
该技术在训练数据上的表现更好。
Train Classification report precision recall f1-score support 0 0.69 0.94 0.80 158 1 0.93 0.68 0.78 204 accuracy 0.79 362 macro avg 0.81 0.81 0.79 362 weighted avg 0.83 0.79 0.79 362
在策略测试器上我们采用相同的测试器配置,测试基于这些数据训练出的模型。
输入:technique_name = tomek-links。
测试结果。

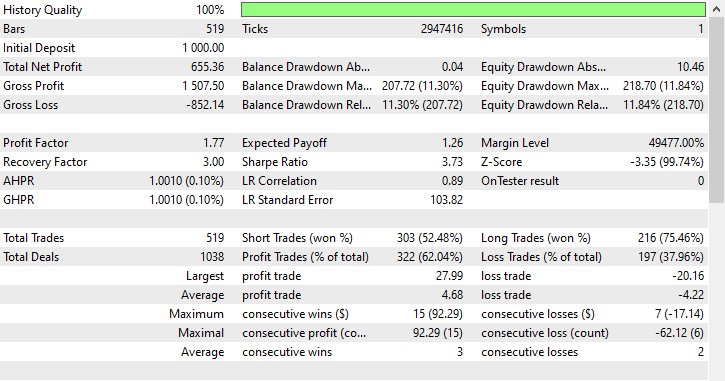
类似于随机欠抽样技术,托梅克链接偏向做空交易,开立 303 笔空头交易,开立 216 笔多头交易,但无论如何仍具备获利能力。
聚簇质心
这是一种欠抽样技术,其中用聚簇质心(通常来自 K-均值聚簇)替换主类样本,降低主类作用。
其工作如下。
- K-均值聚簇应用于主类。
- 选择所需数量的 K-均值样本。
- 该类中大多数样本被 k-聚簇质心所替代。
- 这一成果与次要类结合,造就一个平衡的数据集。
from imblearn.under_sampling import ClusterCentroids cc = ClusterCentroids(random_state=42) X_resampled, y_resampled = cc.fit_resample(X, y) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
输出:
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([225, 225]))
以下是模型运用聚簇质心在欠抽样训练数据上的成果。
Train Classification report precision recall f1-score support 0 0.64 0.86 0.73 158 1 0.85 0.62 0.72 204 accuracy 0.73 362 macro avg 0.75 0.74 0.73 362 weighted avg 0.76 0.73 0.73 362
迄今为止,该技术的准确率值最低,值 0.73 可能示意模型比之前的过度拟合较低,故它或许说是目前最好的模型,我们来观察它在交易环境中的准确性。
输入:technique_name = cluster-centroids。
测试结果。
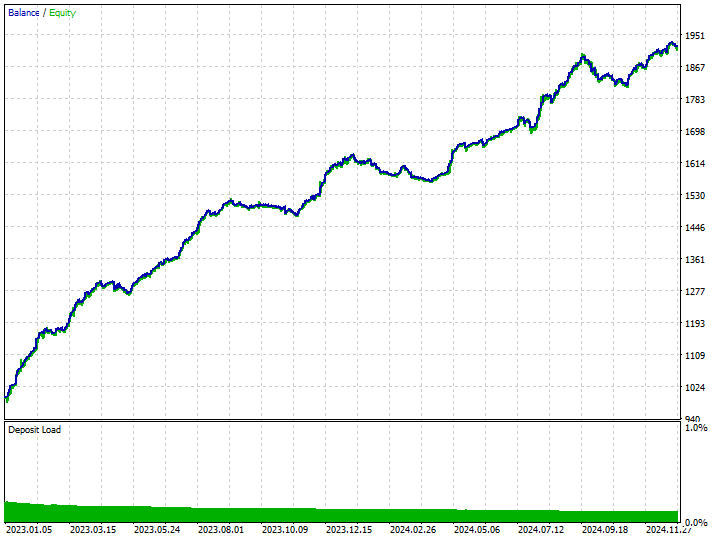
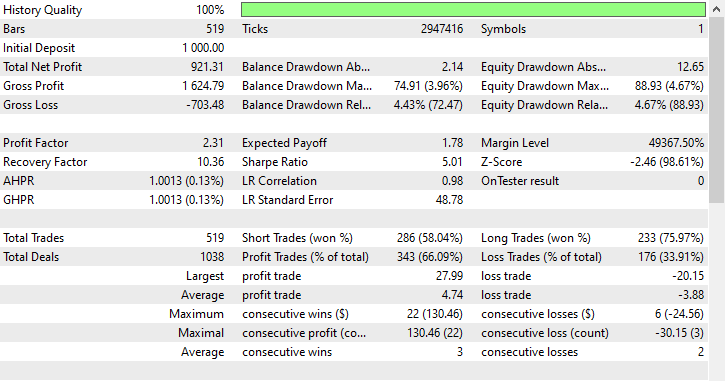
该技术提供了最高的盈利交易数量,在 519 笔交易中有 343 笔盈利交易,准确率达到 66.09%,盈利近乎达到初始本金。尽管模型更偏向做空,但它在预测看涨信号方面非常准确,导致 100% 多头仓位当中有高达 75.97% 的成功率。
混合方法
SMOTE + 托梅克链接
先应用 SMOTE,然后用托梅克链接清理噪声。
from imblearn.combine import SMOTETomek smt = SMOTETomek(random_state=42) X_resampled, y_resampled = smt.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
输出:
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([159, 159]))
以下是模型按照该技术在重抽样数据上训练的成果。
Train Classification report precision recall f1-score support 0 0.74 0.73 0.73 158 1 0.79 0.80 0.80 204 accuracy 0.77 362 macro avg 0.77 0.77 0.77 362 weighted avg 0.77 0.77 0.77 362
以下是交易结果。
输入:technique_name = smote-tomeklinks。
测试结果。
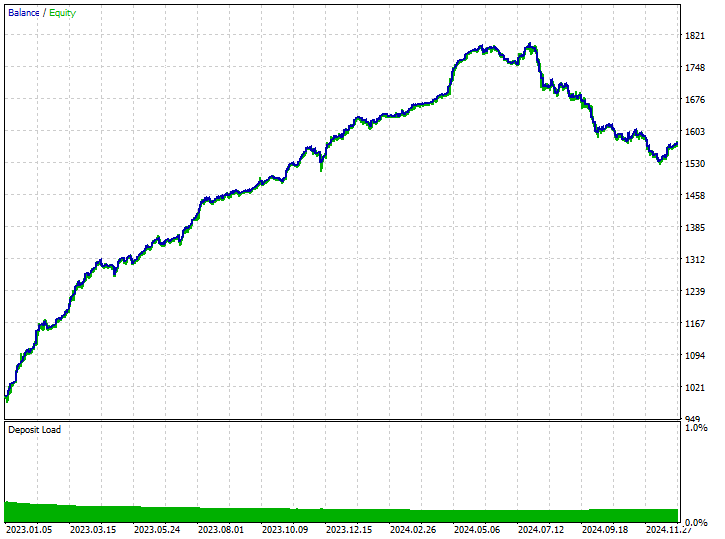
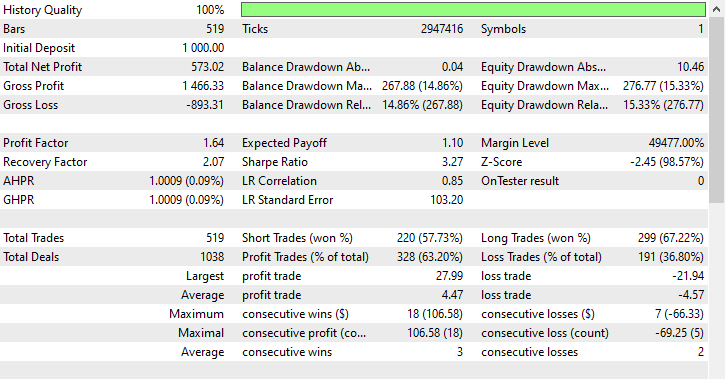
分别是 220 笔空头,和 299 笔多头,还不错。
SMOTE + ENN(编辑最近邻)
SMOTE 生成合成样本,然后 ENN 删除误分类样本。
from imblearn.combine import SMOTEENN sme = SMOTEENN(random_state=42) X_resampled, y_resampled = sme.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
该技术删除了大量数据,训练数据减少到总共 61 个样本。
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([37, 24]))
以下是在训练样本上的分类报告。
Train Classification report precision recall f1-score support 0 0.46 0.76 0.58 158 1 0.63 0.32 0.42 204 accuracy 0.51 362 macro avg 0.55 0.54 0.50 362 weighted avg 0.56 0.51 0.49 362
结果模型如预期般糟糕,在于它只在 61 个样本上训练,数据不足以让任何模型学会有意义的形态。我们来观察交易成果。
输入:technique_name = smote-enn。
测试结果。
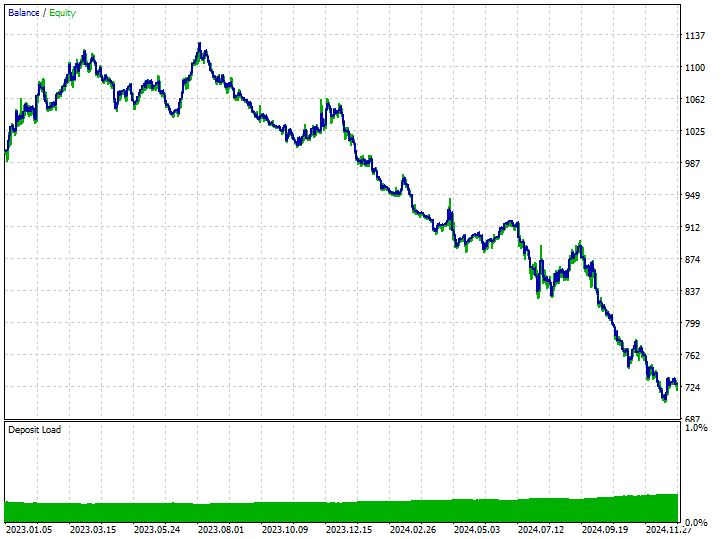
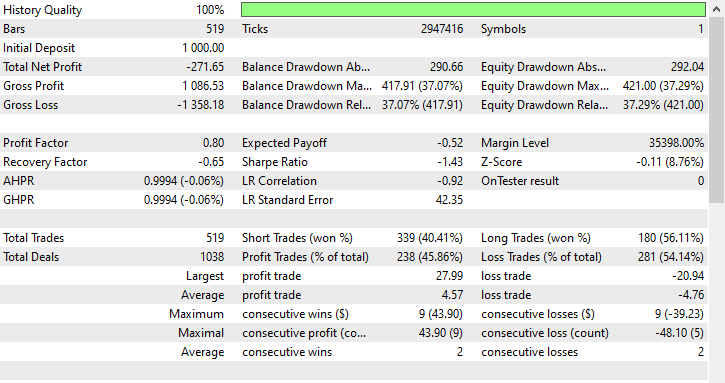
该技术一点帮助都没有,它甚至令情况更糟。它引入了偏颇交易成果,正如机器人开立了 519 笔交易,其中 180 笔买入,339 笔卖出。
这并不意味着该技术糟糕,毕竟它并非这种状况下的最优项。
结束语
我们生活在一个不完美的世界,并非所有发生的现象都有合适的解释或清晰的路径,这在交易世界中也是真理,市场变化迅速且频繁,导致我们的大多数策略即刻被淘汰。
虽然我们无法控制市场发生的事情,我们能做到的最好事情,就是确保至少拥有能够在极端条件下运作的健壮交易系统和策略。
由于历史并不总是重演,确保我们拥有能够在任何市场中运行的无偏颇交易系统是一件好事,认知市场之前出现的形态,但不要过分依赖它们来制定交易决策。这些技术很有帮助,但您必须注意在您的机器学习数据中采用重抽样技术时,随之而来的缺点和权衡。这些缺点包括过抽样导致的过度拟合风险、欠抽样时丢失有价值的信息,以及如果重抽样不当,会引入噪声或偏颇。
找到恰当的平衡是构建能够良好普适未见市场状况的健壮模型的关键。
此致敬意。
附件表
| 文件名 | 说明/用法 |
|---|---|
| Experts\Test Resampling Techniques.mq5 | 一款在 MQL5 中部署 ONNX 文件的智能系统(EA)。 |
| Include\pandas.mqh | 类似 Python 的 Pandas 函数库,用于数据操纵和存储 |
| Scripts\Collectdata.mq5 | 收集训练数据的脚本。 |
| Common\*.onnx | ONNX 格式的机器学习模型 |
| Common\*.csv | 来自不同金融工具的数据,训练机器学习用法 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/17736
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

所需的组件都是笔记本中导入的所有组件的最新版本,您可以进行 pip 安装,而不必担心版本冲突。或者,您也可以通过附件表上的链接进入 Kaggle.com,在那里您可以编辑和修改代码。
未声明标识符,可能意味着变量或对象未定义。请检查您的代码,或通过 DM 将代码截图发给我。