
在MQL5中构建自优化智能交易系统(第七部分):同时利用多个时间周期进行交易

技术指标为现代投资者提供了诸多机遇,也带来了同等的挑战。技术指标存在许多众所周知的局限性,例如广为人知的天然滞后性。
在本文中,我们希望聚焦于微观层面上,为技术指标识别正确的应用周期。时间周期是大多数技术指标共有的一个参数,它控制着指标计算时所需要的历史数据量。
一般而言,周期值选择过小,会导致技术指标捕捉到显著的市场噪音;而周期值选择过大,则往往在市场走势已经展开很久之后才产生信号。这两种情况都会导致错失交易机会,并造成绩效水平低下。
我们在本文提出的解决方案,使我们能够消除识别最佳周期的复杂性,转而同时使用所有可用的周期。为实现此目标,我们将向读者介绍一类被称为降维算法的机器学习算法,并重点关注一种相对较新的算法——一致流形逼近与投影(UMAP)。随后,我们将阐明,这类算法允许以一种有意义的表示方式,利用所有描述某个问题的可用数据,这种表示方式比原始数据集能提供更多的信息。
此外,我们还将探讨MQL5中构建实用类所必需的面向对象编程(OOP)原则,有助于我们高效管理命名空间、内存使用以及交易应用程序所需的其他常规操作。在我们将要一起编写的4个类中,我们将构建一个专用类,使我们能够快速开发依赖ONNX模型的应用程序。我们要涵盖的内容很多,让我们开始吧。
在MQL5中构建我们需要的类
在先前探讨自优化智能交易系统的过程中,我们设计了一个RSI类模块,该模块能够以一种逻辑清晰、结构合理的方式,高效获取不同周期下的多组RSI指标数据。不熟悉该文章的读者可以通过此处快速了解。然而,在本次讨论中,我们将不再使用RSI,而是代之的是威廉指标(WPR)。
WPR通常被视为一种动量震荡指标,其可能的总范围从0到-100。读数在0到-20之间通常代表看跌,而读数在-80到-100之间则通常代表看涨。该指标的核心逻辑是将当前价格与指定周期内的最高价进行比较。我们的第一个目标是构建一个名为“SingleBufferIndicator”的新类,它将由我们的RSI类和WPR类共享。通过让RSI类和WPR类继承同一个父类,我们确保了两个指标类功能上的一致性。我们将从定义“SingleBufferIndicator”类并列出其类成员开始。
这种设计方法为我们提供了许多优势,例如,如果我们未来希望所有指标类都拥有某项新功能,我们只需要更新一个类,即父类“SingleBufferIndicator.mqh”,然后我们只需编译子类,并更新即可生效。继承是面向对象编程中不可或缺的特性,因为我们可以通过只修改一个类,来有效地控制许多类。
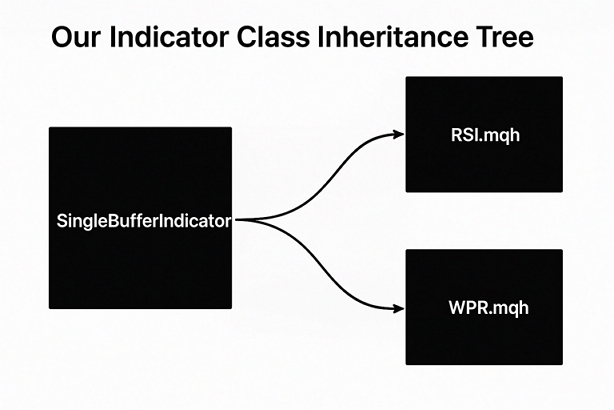
图1:单一缓冲区指标家族的树形继承关系图
为了进一步实现功能,在设计RSI类时,我们将其功能进行通用化设计,使其适用于任何只有1个缓冲区的指标。读者应当注意,MetaTrader 5提供了一整套可供选择的指标。我们正在为只有1个缓冲区的指标构建类,但要提醒读者的是,确实还存在拥有超过1个缓冲区的指标。在设计类时,我们通常希望类具有明确而具体的目的。
试图设计一个能处理所有指标(无论缓冲区数量)的通用类,实现起来可能相当困难。此外,如果设计时不够谨慎,您的代码可能会包含逻辑错误和其他不可预见的隐患。因此,通过限制类的范围,我们奠定了成功基础。
//+------------------------------------------------------------------+ //| SingleBufferIndicator.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" class SingleBufferIndicator { public: //--- Class methods bool SetIndicatorValues(int buffer_size,bool set_as_series); double GetReadingAt(int index); bool SetDifferencedIndicatorValues(int buffer_size,int differencing_period,bool set_as_series); double GetDifferencedReadingAt(int index); double GetCurrentReading(void); //--- Have the indicator values been copied to the buffer? bool indicator_values_initialized; bool indicator_differenced_values_initialized; //--- How far into the future we wish to forecast int forecast_horizon; //--- The buffer for our indicator double indicator_reading[]; vector indicator_differenced_values; //--- The current size of the buffer the user last requested int indicator_buffer_size; int indicator_differenced_buffer_size; //--- The handler for our indicator int indicator_handler; //--- The time frame our indicator should be applied on ENUM_TIMEFRAMES indicator_time_frame; //--- The price should the indicator be applied on ENUM_APPLIED_PRICE indicator_price; //--- Give the user feedback string user_feedback(int flag); //--- The Symbol our indicator should be applied on string indicator_symbol; //--- Our period int indicator_period; //--- Is our indicator valid? bool IsValid(void); //---- Testing the Single Buffer Indicator Class //--- This method should be deleted in production virtual void Test(void); }; //+------------------------------------------------------------------+
现在我们需要一个方法,将指标读数从指标句柄复制到指标缓冲区。该方法有2个参数,一个指定要复制的数据量,另一个指定我们希望如何排列数据。当第二个参数为true时,数据按从过去到现在的顺序排列。
//+------------------------------------------------------------------+ //| Set our indicator values and our buffer size | //+------------------------------------------------------------------+ bool SingleBufferIndicator::SetIndicatorValues(int buffer_size,bool set_as_series) { //--- Buffer size indicator_buffer_size = buffer_size; CopyBuffer(this.indicator_handler,0,0,buffer_size,indicator_reading); //--- Should the array be set as series? if(set_as_series) ArraySetAsSeries(this.indicator_reading,true); indicator_values_initialized = true; //--- Did something go wrong? vector indicator_test; indicator_test.CopyIndicatorBuffer(indicator_handler,0,0,buffer_size); if(indicator_test.Sum() == 0) return(false); //--- Everything went fine. return(true); }
在机器学习中,记录变量的变化可能比仅仅记录原始读数本身信息量更大。因此,我们还要创建一个专用方法,用于计算指标读数的变化,并将其复制到指标缓冲区中。
//+--------------------------------------------------------------+ //| Let's set the conditions for our differenced data | //+--------------------------------------------------------------+ bool SingleBufferIndicator::SetDifferencedIndicatorValues(int buffer_size,int differencing_period,bool set_as_series) { //--- Internal variables indicator_differenced_buffer_size = buffer_size; indicator_differenced_values = vector::Zeros(indicator_differenced_buffer_size); //--- Prepare to record the differences in our RSI readings double temp_buffer[]; int fetch = (indicator_differenced_buffer_size + (2 * differencing_period)); CopyBuffer(indicator_handler,0,0,fetch,temp_buffer); if(set_as_series) ArraySetAsSeries(temp_buffer,true); //--- Fill in our values iteratively for(int i = indicator_differenced_buffer_size;i > 1; i--) { indicator_differenced_values[i-1] = temp_buffer[i-1] - temp_buffer[i-1+differencing_period]; } //--- If the norm of a vector is 0, the vector is empty! if(indicator_differenced_values.Norm(VECTOR_NORM_P) != 0) { Print(user_feedback(2)); indicator_differenced_values_initialized = true; return(true); } indicator_differenced_values_initialized = false; Print(user_feedback(3)); return(false); }
既然我们已经定义了将指标值复制到缓冲区的方法,接下来就需要从这些缓冲区中检索数据的方法。请注意,我们本可以简单地将指标缓冲区声明为类的公共成员,从而快速获取我们想要的值。这种方法的问题在于,它违背了构建类的初衷,即建立一种读写对象的统一方式。
//--- Get a differenced value at a specific index double SingleBufferIndicator::GetDifferencedReadingAt(int index) { //--- Make sure we're not trying to call values beyond our index if(index > indicator_differenced_buffer_size) { Print(user_feedback(4)); return(-1e10); } //--- Make sure our values have been set if(!indicator_differenced_values_initialized) { //--- The user is trying to use values before they were set in memory Print(user_feedback(1)); return(-1e10); } //--- Return the differenced value of our indicator at a specific index if((indicator_differenced_values_initialized) && (index < indicator_differenced_buffer_size)) return(indicator_differenced_values[index]); //--- Something went wrong. return(-1e10); }
前一个方法返回的是差分后的指标读数,它需要一个对应的方法,返回指标上显示的实际读数。
//+------------------------------------------------------------------+ //| Get a reading at a specific index from our RSI buffer | //+------------------------------------------------------------------+ double SingleBufferIndicator::GetReadingAt(int index) { //--- Is the user trying to call indexes beyond the buffer? if(index > indicator_buffer_size) { Print(user_feedback(4)); return(-1e10); } //--- Get the reading at the specified index if((indicator_values_initialized) && (index < indicator_buffer_size)) return(indicator_reading[index]); //--- User is trying to get values that were not set prior else { Print(user_feedback(1)); return(-1e10); } }
我还认为,设置一个专门用于返回索引0处指标值(即当前指标读数)的函数会很有用。
//+------------------------------------------------------------------+ //| Get our current reading from the RSI indicator | //+------------------------------------------------------------------+ double SingleBufferIndicator::GetCurrentReading(void) { double temp[]; CopyBuffer(this.indicator_handler,0,0,1,temp); return(temp[0]); }
该函数将告知我们的句柄是否已正确加载。这对我们来说是一个有用的安全功能。
//+------------------------------------------------------------------+ //| Check if our indicator handler is valid | //+------------------------------------------------------------------+ bool SingleBufferIndicator::IsValid(void) { return((this.indicator_handler != INVALID_HANDLE)); }
当用户与指标类交互时,我们希望针对他们可能犯的任何错误给出提示,并提供相应的解决方案。
//+------------------------------------------------------------------+ //| Give the user feedback on the actions he is performing | //+------------------------------------------------------------------+ string SingleBufferIndicator::user_feedback(int flag) { string message; //--- Check if the indicator loaded correctly if(flag == 0) { //--- Check the indicator was loaded correctly if(IsValid()) message = "Indicator Class Loaded Correcrtly \nSymbol: " + (string) indicator_symbol + "\nPeriod: " + (string) indicator_period; return(message); //--- Something went wrong message = "Error loading Indicator: [ERROR] " + (string) GetLastError(); return(message); } //--- User tried getting indicator values before setting them if(flag == 1) { message = "Please set the indicator values before trying to fetch them from memory, call SetIndicatorValues()"; return(message); } //--- We sueccessfully set our differenced indicator values if(flag == 2) { message = "Succesfully set differenced indicator values."; return(message); } //--- Failed to set our differenced indicator values if(flag == 3) { message = "Failed to set our differenced indicator values: [ERROR] " + (string) GetLastError(); return(message); } //--- The user is trying to retrieve an index beyond the buffer size and must update the buffer size first if(flag == 4) { message = "The user is attempting to use call an index beyond the buffer size, update the buffer size first"; return(message); } //--- The class has been deactivated by the user if(flag == 5) { message = "Goodbye."; return(message); } //--- No feedback else return(""); }
完成这些后,我们现在可以构建WPR类,它将继承自其父类SingleBufferIndicator。总而言之,如果您打算跟随本文操作,您类的树形依赖关系应该类似于图1。
图2:我们指标类的依赖树
此刻,我们正式开启在 WPR 类中的第一步操作——将 SingleBufferIndicator 类集成至 WPR 类当中。
//+------------------------------------------------------------------+ //| WPR.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| Load the parent class | //+------------------------------------------------------------------+ #include <VolatilityDoctor\Indicators\SingleBuffer\SingleBufferIndicator.mqh>
这一次,在定义WPR类的成员之前,我们将使用冒号“:”语法指定该类继承自SingleBufferIndicator类。这就是我们在MQL5中继承类的方式。对于不熟悉OOP概念的读者来说,继承一个类允许我们从WPR类内部调用在SingleBufferIndicator类中编写的方法。通过让WPR类和RSI类都继承自SingleBufferIndicator类,我们确保了两个类功能接口的一致性。换句话说,我们在SingleBufferIndicator类中构建的所有公共类成员,在任何继承自它的类中都将直接可用。
//+------------------------------------------------------------------+ //| This class will provide us with usefull functionality for the WPR| //+------------------------------------------------------------------+ class WPR : public SingleBufferIndicator { public: WPR(); WPR(string user_symbol,ENUM_TIMEFRAMES user_time_frame,int user_period); ~WPR(); };
WPR和RSI指标都只有1个缓冲区;不过,这些指标需要不同的参数来进行初始化。因此,构造函数针对每个指标实例进行具体化更有意义,因为它们的构造函数签名在不同指标之间可能差异巨大。
//+------------------------------------------------------------------+ //| Our default constructor for our Indicator class | //+------------------------------------------------------------------+ void WPR::WPR() { indicator_values_initialized = false; indicator_symbol = "EURUSD"; indicator_time_frame = PERIOD_D1; indicator_period = 5; indicator_handler = iWPR(indicator_symbol,indicator_time_frame,indicator_period); //--- Give the user feedback on initilization Print(user_feedback(0)); //--- Remind the user they called the default constructor Print("Default Constructor Called: ",__FUNCSIG__," ",&this); }
参数化构造函数允许用户指定WPR指标应使用哪个交易品种、时间框架和周期进行初始化。
//+------------------------------------------------------------------+ //| Our parametric constructor for our Indicator class | //+------------------------------------------------------------------+ void WPR::WPR(string user_symbol,ENUM_TIMEFRAMES user_time_frame,int user_period) { indicator_values_initialized = false; indicator_symbol = user_symbol; indicator_time_frame = user_time_frame; indicator_period = user_period; indicator_handler = iWPR(indicator_symbol,indicator_time_frame,indicator_period); //--- Give the user feedback on initilization Print(user_feedback(0)); }
类的析构函数负责重置关键状态标志并释放指标句柄。及时释放占用的资源,是MQL5编程的良好习惯。通过为此构建一个专用类,可以减轻开发者的负担,因为您不必总是为此操心并重复进行资源清理,取而代之的是让类代替您完成这些工作。
//+------------------------------------------------------------------+ //| Our destructor for our Indicator class | //+------------------------------------------------------------------+ void WPR::~WPR() { //--- Free up resources we don't need and reset our flags if(IndicatorRelease(indicator_handler)) { indicator_differenced_values_initialized = false; indicator_values_initialized = false; Print(user_feedback(5)); } } //+------------------------------------------------------------------+
我们需要的另一个功能是能够识别新K线何时形成。每当出现这种情况时,我们希望执行某些任务。因此,我们将为此专门设计一个类,这对我们至关重要,并且在某些情况下,我们可能希望同时跟踪不同时间周期K线的形成。我们将首先声明Time类所需的类成员。
//+------------------------------------------------------------------+ //| Time.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" class Time { private: datetime time_stamp; datetime current_time; string selected_symbol; ENUM_TIMEFRAMES selected_time_frame; public: Time(string user_symbol,ENUM_TIMEFRAMES user_time_frame); bool NewCandle(void); ~Time(); };
请注意,该类没有默认构造函数,这是刻意为之的。在这种情况下,默认构造函数没有太大意义。
//+------------------------------------------------------------------+ //| Create our time object | //+------------------------------------------------------------------+ Time::Time(string user_symbol,ENUM_TIMEFRAMES user_time_frame) { selected_time_frame = user_time_frame; selected_symbol = user_symbol; current_time = iTime(user_symbol,selected_time_frame,0); time_stamp = iTime(user_symbol,selected_time_frame,0); }
目前,类的析构函数是空的。
//+------------------------------------------------------------------+ //| Our destructor is currently empty | //+------------------------------------------------------------------+ Time::~Time() { } //+------------------------------------------------------------------+
最后,需要一个方法来通知我们新K线是否已形成。如果新K线已形成,该方法将返回true,从而使我们能够定期执行相关程序。
//+------------------------------------------------------------------+ //| Check if a new candle has fully formed | //+------------------------------------------------------------------+ bool Time::NewCandle(void) { current_time = iTime(selected_symbol,selected_time_frame,0); //--- Check if a new candle has formed if(time_stamp != current_time) { time_stamp = current_time; return(true); } //--- No new candle has completely formed return(false); }
接下来,我们还需要一个专用类来处理ONNX对象。随着项目变得越来越大、越来越复杂,我们不希望多次重复某些步骤。最终,为所有接受float数据类型的ONNX模型创建一个ONNXFloat类可能会更好。在撰写本文时,float数据类型被广泛认为是稳定运行ONNX模型的数据类型。让我们从定义ONNX float类的成员开始,介绍ONNX float类。
//+------------------------------------------------------------------+ //| ONNXFloat.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| This class will help us work with ONNX Float models. | //+------------------------------------------------------------------+ class ONNXFloat { private: //--- Our ONNX model handler long onnx_model; int onnx_outputs; public: //--- Is our Model Valid? bool OnnxModelIsValid(void); //--- Define the input shape of our model bool DefineOnnxInputShape(int n_index,int n_stacks,int n_input_params); //--- Define the output shape of our model bool DefineOnnxOutputShape(int n_index,int n_stacks, int n_output_params); vectorf Predict(const vectorf &model_inputs); //--- ONNXFloat class constructor ONNXFloat(const uchar &user_proto[]); //---- ONNXFloat class destructor ~ONNXFloat(); };
ONNXFloat类的构造函数接受一个ONNX模型原型,并从用户传递的缓冲区创建ONNX模型。请注意,ONNX模型缓冲区只能通过引用传递,不能通过值传递。放在ONNX模型缓冲区名称前面的“&”符号“&user_proto”,明确说明此参数是对内存中对象的引用。每当函数有一个通过引用传递的参数时,用户应该理解,在函数内部对该参数所做的任何更改,都会更改函数外部的原始参数。
在我们的情况下,我们不打算编辑ONNX原型;因此,我们将参数修改为“const”,向程序员和编译器表明不应进行任何更改。因此,如果程序员忽略我们的指令,编译器将不会接受。
//+------------------------------------------------------------------+ //| Parametric Constructor For Our ONNXFloat class | //+------------------------------------------------------------------+ ONNXFloat::ONNXFloat(const uchar &user_proto[]) { onnx_model = OnnxCreateFromBuffer(user_proto,ONNX_DATA_TYPE_FLOAT); if(OnnxModelIsValid()) Print("Volatility Doctor ONNXFloat Class Loaded Correctly: ",__FUNCSIG__," ",&this); else Print("Failed To Create The specified ONNX model: ",GetLastError()); }
ONNXFloat类的析构函数会为我们自动释放分配给ONNX模型的内存。
//+------------------------------------------------------------------+ //| Our ONNXFloat class destructor | //+------------------------------------------------------------------+ ONNXFloat::~ONNXFloat() { OnnxRelease(onnx_model); } //+------------------------------------------------------------------+
我们还需要一个专用函数,通过返回一个布尔标志来告知我们ONNX模型是否有效,该标志仅在模型有效时为true。
//+------------------------------------------------------------------+ //| A method that returns true if our ONNXFloat model is valid | //+------------------------------------------------------------------+ bool ONNXFloat::OnnxModelIsValid(void) { //--- Check if the model is valid if(onnx_model != INVALID_HANDLE) return(true); //--- Something went wrong return(false); }
有必要对ONNX模型的输入形状进行设置,我们可能会经常需要这样做。
//+------------------------------------------------------------------+ //| Set the input shape of our ONNXFloat model | //+------------------------------------------------------------------+ bool ONNXFloat::DefineOnnxInputShape(int n_index,int n_stacks,int n_input_params) { const ulong model_input_shape[] = {n_stacks,n_input_params}; if(OnnxSetInputShape(onnx_model,n_index,model_input_shape)) { Print("Succefully specified ONNX model output shape: ",__FUNCTION__," ",&this); return(true); } //--- Something went wrong Print("Failed to set the passed ONNX model output shape: ",GetLastError()); return(false); }
ONNX模型输出形状也是如此。
//+------------------------------------------------------------------+ //| Set the output shape of our model | //+------------------------------------------------------------------+ bool ONNXFloat::DefineOnnxOutputShape(int n_index,int n_stacks,int n_output_params) { const ulong model_output_shape[] = {n_output_params,n_stacks}; onnx_outputs = n_output_params; if(OnnxSetOutputShape(onnx_model,n_index,model_output_shape)) { Print("Succefully specified ONNX model input shape: ",__FUNCSIG__," ",&this); return(true); } //--- Something went wrong Print("Failed to set the passed ONNX model input shape: ",GetLastError()); return(false); }
最后,我们需要一个预测函数。该函数将通过引用接收ONNX模型的输入数据,并且由于我们不打算更改输入数据,我们将该参数修改为常量。这可以防止任何无意的副作用破坏输入数据,最重要的是,它指示我们的编译器防止我们可能犯下的任何更改模型输入的粗心错误。此类安全功能非常宝贵,并且将它们内置到编程语言中,使MQL5成为一流的编程语言。
//+------------------------------------------------------------------+ //| Get a prediction from our model | //+------------------------------------------------------------------+ vectorf ONNXFloat::Predict(const vectorf &model_inputs) { vectorf model_output(onnx_outputs); if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,model_output)) { vectorf res = model_output; return(res); } Comment("Failed to get a prediction from our ONNX model"); Print("ONNX Run Failed: ",GetLastError()); vectorf res = {10e8}; return(res); }
我们需要的最后一个类负责为我们获取有用的交易信息,例如最小交易手数或当前卖出价。
//+------------------------------------------------------------------+ //| TradeInfo.mqh | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" class TradeInfo { private: string user_symbol; ENUM_TIMEFRAMES user_time_frame; double min_volume,max_volume,volume_step; public: TradeInfo(string selected_symbol,ENUM_TIMEFRAMES selected_time_frame); double MinVolume(void); double MaxVolume(void); double VolumeStep(void); double GetAsk(void); double GetBid(void); double GetClose(void); string GetSymbol(void); ~TradeInfo(); };
参数化类构造函数接受2个参数,指定目标品种和时间周期。
//+------------------------------------------------------------------+ //| The constructor will load our symbol information | //+------------------------------------------------------------------+ TradeInfo::TradeInfo(string selected_symbol,ENUM_TIMEFRAMES selected_time_frame) { //--- Which symbol are you interested in? user_symbol = selected_symbol; user_time_frame = selected_time_frame; if(SymbolSelect(user_symbol,true)) { //--- Load symbol details min_volume = SymbolInfoDouble(user_symbol,SYMBOL_VOLUME_MIN); max_volume = SymbolInfoDouble(user_symbol,SYMBOL_VOLUME_MAX); volume_step = SymbolInfoDouble(user_symbol,SYMBOL_VOLUME_STEP); Print("Trade Info Loaded Successfully: ",__FUNCSIG__); } else { Print("Error Symbol Information Could Not Be Found For: ",selected_symbol," ",GetLastError()); } }
我们还将定义方法来获取四个主要价格行情的当前读数,也就是说,这些方法分别返回当前的 开盘价、最高价、最低价和收盘价。
//+------------------------------------------------------------------+ //| Return the close of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetClose(void) { double res = iClose(user_symbol,user_time_frame,0); return(res); } //+------------------------------------------------------------------+ //| Return the open of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetOpen(void) { double res = iOpen(user_symbol,user_time_frame,0); return(res); } //+------------------------------------------------------------------+ //| Return the high of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetHigh(void) { double res = iHigh(user_symbol,user_time_frame,0); return(res); } //+------------------------------------------------------------------+ //| Return the low of the selected symbol | //+------------------------------------------------------------------+ double TradeInfo::GetLow(void) { double res = iLow(user_symbol,user_time_frame,0); return(res); }
处理多个品种时,若有一个提醒可以告诉我们当前类实例已分配给哪个品种,这将会很有用。
//+------------------------------------------------------------------+ //| Return the selected symbol | //+------------------------------------------------------------------+ string TradeInfo::GetSymbol(void) { string res = user_symbol; return(res); }
我们的类还提供了包装器,以便快速获取重要信息,诸如有关当前品种允许的交易手数。
//+------------------------------------------------------------------+ //| Return the volume step allowed | //+------------------------------------------------------------------+ double TradeInfo::VolumeStep(void) { double res = volume_step; return(res); } //+------------------------------------------------------------------+ //| Return the minimum volume allowed | //+------------------------------------------------------------------+ double TradeInfo::MinVolume(void) { double res = min_volume; return(res); } //+------------------------------------------------------------------+ //| Return the maximum volume allowed | //+------------------------------------------------------------------+ double TradeInfo::MaxVolume(void) { double res = max_volume; return(res); }
还需要该类能为我们快速提供当前的买入价和卖出价。
//+------------------------------------------------------------------+ //| Return the current ask | //+------------------------------------------------------------------+ double TradeInfo::GetAsk(void) { return(SymbolInfoDouble(GetSymbol(),SYMBOL_ASK)); } //+------------------------------------------------------------------+ //| Return the current bid | //+------------------------------------------------------------------+ double TradeInfo::GetBid(void) { return(SymbolInfoDouble(GetSymbol(),SYMBOL_BID)); }
目前,我们的Time类析构函数是空的。
//+------------------------------------------------------------------+ //| Destructor is currently empty | //+------------------------------------------------------------------+ TradeInfo::~TradeInfo() { } //+------------------------------------------------------------------+
总而言之,如果您一直跟随我们,那么您的类依赖关系树应该类似于下面的图3。
图3:对于跟随本文的读者,这些类应保存在我们的依赖关系树中
现在让我们定义获取所需的相关市场数据的脚本。我们首先获取四个主要价格行情(OHLC),然后是这四个价格行情的增长情况,最后,我们将写出14个WPR指标的指标数据。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 10 //+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <VolatilityDoctor\Indicators\WPR.mqh> //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ WPR *my_wpr_array[14]; string file_name = Symbol() + " WPR Algorithmic Input Selection.csv"; //+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //--- How much data should we store in our indicator buffer? int fetch = size + (2 * HORIZON); //--- Store pointers to our WPR objects for(int i = 0; i <= 13; i++) { //--- Create an WPR object my_wpr_array[i] = new WPR(Symbol(),PERIOD_CURRENT,((i+1) * 5)); //--- Set the WPR buffers my_wpr_array[i].SetIndicatorValues(fetch,true); my_wpr_array[i].SetDifferencedIndicatorValues(fetch,HORIZON,true); } //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","True Open","True High","True Low","True Close","Open","High","Low","Close","WPR 5","WPR 10","WPR 15","WPR 20","WPR 25","WPR 30","WPR 35","WPR 40","WPR 45","WPR 50","WPR 55","WPR 60","WPR 65","WPR 70","Diff WPR 5","Diff WPR 10","Diff WPR 15","Diff WPR 20","Diff WPR 25","Diff WPR 30","Diff WPR 35","Diff WPR 40","Diff WPR 45","Diff WPR 50","Diff WPR 55","Diff WPR 60","Diff WPR 65","Diff WPR 70"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(Symbol(),PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(Symbol(),PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(Symbol(),PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(Symbol(),PERIOD_CURRENT,i + HORIZON), my_wpr_array[0].GetReadingAt(i), my_wpr_array[1].GetReadingAt(i), my_wpr_array[2].GetReadingAt(i), my_wpr_array[3].GetReadingAt(i), my_wpr_array[4].GetReadingAt(i), my_wpr_array[5].GetReadingAt(i), my_wpr_array[6].GetReadingAt(i), my_wpr_array[7].GetReadingAt(i), my_wpr_array[8].GetReadingAt(i), my_wpr_array[9].GetReadingAt(i), my_wpr_array[10].GetReadingAt(i), my_wpr_array[11].GetReadingAt(i), my_wpr_array[12].GetReadingAt(i), my_wpr_array[13].GetReadingAt(i), my_wpr_array[0].GetDifferencedReadingAt(i), my_wpr_array[1].GetDifferencedReadingAt(i), my_wpr_array[2].GetDifferencedReadingAt(i), my_wpr_array[3].GetDifferencedReadingAt(i), my_wpr_array[4].GetDifferencedReadingAt(i), my_wpr_array[5].GetDifferencedReadingAt(i), my_wpr_array[6].GetDifferencedReadingAt(i), my_wpr_array[7].GetDifferencedReadingAt(i), my_wpr_array[8].GetDifferencedReadingAt(i), my_wpr_array[9].GetDifferencedReadingAt(i), my_wpr_array[10].GetDifferencedReadingAt(i), my_wpr_array[11].GetDifferencedReadingAt(i), my_wpr_array[12].GetDifferencedReadingAt(i), my_wpr_array[13].GetDifferencedReadingAt(i) ); } } //--- Close the file FileClose(file_handle); //--- Delete our WPR object pointers for(int i = 0; i <= 13; i++) { delete my_wpr_array[i]; } } //+------------------------------------------------------------------+ #undef HORIZON
在 Python 中分析我们的数据
完成后,将脚本应用于您选择的市场,以便我们有市场数据可供分析。在本次讨论中,我们将脚本应用于EURGBP货币对,既然数据已准备就绪,让我们加载Python库进行分析。
#Load the libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
读取数据。
#Read in the data data = pd.read_csv("..\EURGBP WPR Algorithmic Input Selection.csv") #Label the data HORIZON = 10 data['Target'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last 10 rows data = data.iloc[:-HORIZON,:]
创建输入输出的备份。
#Define inputs and target X = data.iloc[:,1:-1].copy() y = data.iloc[:,-1].copy()
对数据集中的每个数值列进行缩放和居中处理。
#Store Z-scores Z1 = X.mean() Z2 = X.std() #Scale the data X = ((X - Z1)/ Z2)
加载测试所需的数值库。
from sklearn.model_selection import cross_val_score,TimeSeriesSplit from sklearn.linear_model import Ridge
创建一个时间序列交叉验证对象。
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)sdvdsvds 定义一个始终返回我们交叉验证准确率水平的方法。
#Return our cross validated accuracy def score(f_model,f_X,f_y): return(np.mean(np.abs(cross_val_score(f_model,f_X,f_y,scoring='neg_mean_squared_error',cv=tscv,n_jobs=-1))))
我们还需要一个专用方法来返回一个新模型,这确保我们不会向使用的模型泄漏数据。
def get_model(): return(Ridge())
保留一个完全由零组成的列,让你可以衡量总是预测平均市场回报的准确率。
X['Null'] = 0
记录由总是预测平均市场回报所产生的误差(总平方和/TSS)。既然已经记录了其所定义的误差阈值,我们就可以自信地断言,就本讨论而言,任何产生的误差水平大于0.000324的模型,都无法给我们留下深刻印象。
#This will be the last entry in our list of results #Record our error if we always predict the average market return (total sum of squares/TSS) tss = score(get_model(),X[['Null']],y) tss
0.00032439931180771236
我们现在将创建一个数组来帮助我们跟踪结果。
res = []
我们想要记录的第一个结果,是使用原始形式的OHLC市场数据的误差水平。
#This will be our first entry in our list of results #Record our error using OHLC price data res.append(score(get_model(),X.iloc[:,:8],y))
接下来,我们想知道仅使用我们选择的14个WPR指标周期的误差水平。
#Second #Record our error using just indicators res.append(score(get_model(),X.iloc[:,8:-1],y))
最后,让我们记录使用可用的所有数据的误差水平。
#Third #Record our error using all the data we have res.append(score(get_model(),X.iloc[:,:-1],y))
现在加载UMAP库。原始数据有36列,UMAP库将帮助我们使用大于或等于1且小于原始列数的任意数量的列来表示这些数据。数据的新表示可能比原始形式更具信息量。因此,从这个意义上说,降维算法也可以被认为是一系列方法,使我们能够有效地使用描述问题的所有数据。
import umap
我们希望搜索的嵌入数量最多比原始列数少2。
EPOCHS = X.iloc[:,:-1].shape[1] - 2
使用UMAP迭代地嵌入数据。要生成的嵌入列数量将从1开始,以1步为增量增加,直到我们在上一行代码中设定的上限。
for i in range(EPOCHS): reducer = umap.UMAP(n_components=(i+1),metric='euclidean',random_state=0,transform_seed=0,n_neighbors=30) X_embedded = pd.DataFrame(reducer.fit_transform(X.iloc[:,:-1])) res.append(score(get_model(),X_embedded,y))
连接我们的结果。
res.append(tss)
红色实线是我们的关键误差基准,即总是预测平均市场回报(TSS)所产生的误差。红色虚线是我们能够产生的最低误差水平。这对应于当我们的UMAP算法将原始数据嵌入到2列时所构建的模型。请注意,该误差水平同我们使用原始市场数据所能达到的水平相比,更大幅度地优于TSS。我们基本上同时使用所有WPR周期,其方式比我们原本可能实现的方式更有意义。
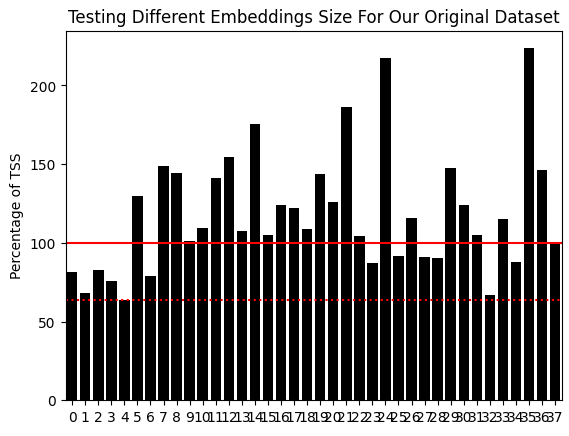
图4:使用2个UMAP嵌入组件,优于使用原始形式所有市场数据的等效模型
使用我们确定的最佳UMAP设置变换数据。
reducer = umap.UMAP(n_components=2,metric='euclidean',random_state=0,transform_seed=0,n_neighbors=30) X_embedded = pd.DataFrame(reducer.fit_transform(X.iloc[:,:-1]))
标记我们的2个类别。这有助于我们后续可视化UMAP对数据的操作。
data['Class'] = 0 data.loc[data['Target'] > 0,'Class'] = 1
准备一个数据集来存储变换后的数据。
umap_data =pd.DataFrame(columns=['UMAP 1','UMAP 2'])
存储内嵌的价格水平。
umap_data['UMAP 1'] = X_embedded.iloc[:,0] umap_data['UMAP 2'] = X_embedded.iloc[:,1]
没有UMAP,由于维度数量众多,我们的数据难以有意义地可视化。事实上,我们能做的最好的事情就是创建成对的散点图;否则,无法一次有效地可视化36个维度。在下面的图5和图6中,红点表示看涨价格行为,黑色代表看跌价格行为。
fig , axs = plt.subplots(2,2) fig.suptitle('Visualizing EURGBP 2002-2025 Daily Price Data') axs[0,0].scatter(data.loc[data['Target']>0 ,'Open'],data.loc[data['Target']>0 ,'Close'],color='red') axs[0,0].scatter(data.loc[data['Target']<0 ,'Open'],data.loc[data['Target']<0 ,'Close'],color='black') axs[0,1].scatter(data.loc[data['Target']>0 ,'True Open'],data.loc[data['Target']>0 ,'True Close'],color='red') axs[0,1].scatter(data.loc[data['Target']<0 ,'True Open'],data.loc[data['Target']<0 ,'True Close'],color='black') axs[1,1].scatter(data.loc[data['Target']>0 ,'WPR 5'],data.loc[data['Target']>0 ,'WPR 50'],color='red') axs[1,1].scatter(data.loc[data['Target']<0 ,'WPR 5'],data.loc[data['Target']<0 ,'WPR 50'],color='black') axs[1,0].scatter(data.loc[data['Target']>0 ,'WPR 15'],data.loc[data['Target']>0 ,'WPR 25'],color='red') axs[1,0].scatter(data.loc[data['Target']<0 ,'WPR 15'],data.loc[data['Target']<0 ,'WPR 25'],color='black')
图5:左侧我们绘制了开盘价变化与收盘价变化的关系。右侧我们绘制了真实的开盘价和收盘价。
图6:左侧散点图表示5周期和50周期WPR之间的关系,右侧是15周期和25周期WPR。
正如我们所见,图5和图6难以进行有意义的解释,数据中没有清晰的规律。此外,为超过两个维度的现象创建二维散点图可能是有害的。这是因为,两个变量之间看似存在的某种关系,可能可以由无法在一张图中包含的其他维度来解释。这可能导致我们错误的发现,或对并不像看起来那样稳定的关系产生不合理的信心。
然而,在应用UMAP之后,我们可以轻松地将所有的数据绘制在仅两个维度上。我们可以看到,第一个嵌入的低值和高值分别对应着看跌和看涨的价格行为。
sns.scatterplot(x=X_embedded.iloc[:,0],y=X_embedded.iloc[:,1],hue=data['Class']) plt.grid() plt.ylabel('Second UMAP Embedding') plt.xlabel('First UMAP Embedding') plt.title('Visualizing The Most Effective Embedding We Found')
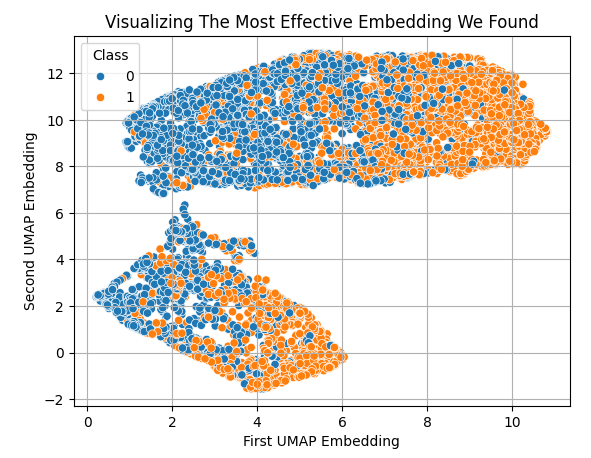
图7:可视化我们原始市场数据的UMAP嵌入
现在让我们为准备模型用于回测。导入所需的库。
from sklearn.model_selection import train_test_split
分割市场数据。我们的训练样本从2002年11月到2018年8月,因此我们的回测期将从2018年9月开始。
train , test = train_test_split(data,test_size=0.3,shuffle=False) train
图8:以原始形式查看我们的市场数据
现在让我们加载统计模型。
from sklearn.neural_network import MLPRegressor
缩放训练数据。
#Sample mean Z1 = train.iloc[:,1:-2].mean() #Sample standard deviation Z2 = train.iloc[:,1:-2].std() train_scaled = train.copy() train_scaled.iloc[:,1:-2] = ((train.iloc[:,1:-2] - Z1) / Z2)
嵌入训练数据。
reducer = umap.UMAP(n_components=2,metric='euclidean',random_state=0,transform_seed=0,n_neighbors=30) X_embedded = pd.DataFrame(reducer.fit_transform(train_scaled.iloc[:,1:-2],columns=['UMAP 1','UMAP 2']))
我们的框架遵循一个两步过程。首先,拟合一个学习近似UMAP算法的模型。这要就无需在MQL5中从头重写UMAP算法。UMAP算法相当复杂,由一个博士后研究团队实现。研究人员编写一个数值稳定的算法实现,这需要相当大的努力。因此,尝试自己实现此类算法一般不是太现实。
#Learn To Estimate UMAP Embeddings From The Data umap_model = MLPRegressor(shuffle=False,hidden_layer_sizes=(train.iloc[:,1:-2].shape[1],10,20,100,20,10,2),random_state=0,solver='lbfgs',activation='relu',learning_rate='constant',learning_rate_init=1e-4,power_t=1e-1) np.mean(np.abs(cross_val_score(umap_model,train.iloc[:,1:-2],X_embedded,scoring='neg_mean_squared_error',n_jobs=-1)))
11.2489992665160363
学习UMAP函数。
umap_model.fit(train.iloc[:,1:-2],X_embedded) predictions = umap_model.predict(train.iloc[:,1:-2])
现在我们需要一个模型,根据市场的UMAP嵌入来预测EURGBP市场回报。在scikit-learn中,我们的神经网络模型有一个名为“random_state”的重要参数。此参数影响神经网络开始的初始权重和偏差。根据手头的问题,使用不同的初始状态多次训练模型,可能会导致性能水平的显著变化,正如我们在下面的图9中所见。
EPOCHS = 100 res = [] for i in range(EPOCHS): #Try different random states model = MLPRegressor(shuffle=False,early_stopping=False,hidden_layer_sizes=(2,1,10,20,1),activation='identity',solver='lbfgs',random_state=i,max_iter=int(2e5)) res.append(score(model,predictions,train['Target']))
可视化我们的结果。
plt.plot(res,color='black') plt.axhline(np.min(res),color='red',linestyle=':') plt.scatter(res.index(np.min(res)),np.min(res),color='red') plt.grid() plt.ylabel('Cross Validated RMSE') plt.xlabel('Neural Network Random State') plt.title('Our Neural Network Performance With Different Initial Conditions')
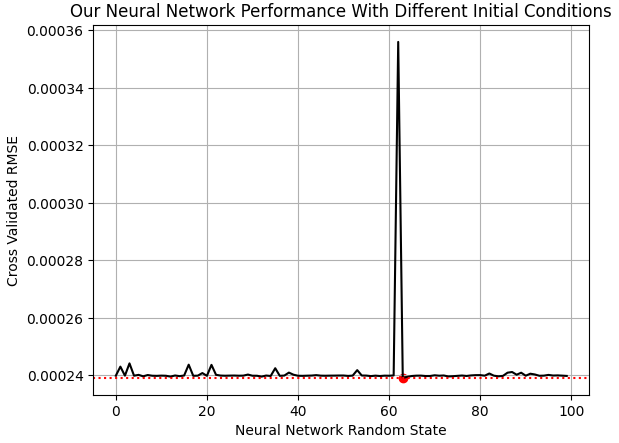
图9:可视化神经网络的最佳初始状态
我们选定的神经网络在预测10天EURGBP市场回报时,误差比总是预测平均市场回报的模型低38%。
tss = score(Ridge(),train[['Close']]*0,train['Target']) 1-(np.min(res)/tss)
0.3822093585025088
使用我们在图9中确定的最佳随机状态拟合模型。
embedded_model = MLPRegressor(shuffle=False,early_stopping=False,hidden_layer_sizes=(2,1,10,20,1),activation='identity',solver='lbfgs',random_state=res.index(np.min(res)),max_iter=int(2e5)) embedded_model.fit(predictions,train['Target'])
加载将模型转换为ONNX格式所需的库。
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
定义我们模型的参数形状。
umap_model_input_shape = [("float_input",FloatTensorType([1,train.iloc[:,1:-2].shape[1]]))] umap_model_output_shape = [("float_output",FloatTensorType([X_embedded.iloc[:,:].shape[1],1]))] embedded_model_input_shape = [("float_input",FloatTensorType([1,X_embedded.iloc[:,:].shape[1]]))] embedded_model_output_shape = [("float_output",FloatTensorType([1,1]))]
将ONNX模型转换为它们原型。
umap_proto = convert_sklearn(umap_model,initial_types=umap_model_input_shape,final_types=umap_model_output_shape,target_opset=12) embeded_proto = convert_sklearn(embedded_model,initial_types=embedded_model_input_shape,final_types=embedded_model_output_shape,target_opset=12)
保存原型。
onnx.save(umap_proto,"EURGBP WPR Ridge UMAP.onnx") onnx.save(embeded_proto,"EURGBP WPR Ridge EMBEDDED.onnx")
在MQL5中构建我们的应用程序
现在让开始构建我们的应用程序。我们首先需要指定在程序中不会改变的系统常量。
//+------------------------------------------------------------------+ //| EURGBP Multiple Periods Analysis.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| REMINDER: | //| These ONNX models were trained with Daily EURGBP data ranging | //| from 24 November 2002 until 12 August 2018. Test the strategy | //| outside of these time periods, on the Daily Time-Frame for | //| reliable results. | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ //--- ONNX Model I/O Parameters #define UMAP_INPUTS 36 #define UMAP_OUTPUTS 2 #define EMBEDDED_INPUTS 2 #define EMBEDDED_OUTPUTS 1 //--- Our forecasting periods #define HORIZON 10 //--- Our desired time frame #define SYSTEM_TIMEFRAME_1 PERIOD_D1
现在加载我们的ONNX模型。
//+------------------------------------------------------------------+ //| Load our ONNX models as resources | //+------------------------------------------------------------------+ //--- ONNX Model Prototypes #resource "\\Files\\EURGBP WPR UMAP.onnx" as const uchar umap_proto[]; #resource "\\Files\\EURGBP WPR EMBEDDED.onnx" as const uchar embedded_proto[];
然后,将加载程序所需的库。
//+------------------------------------------------------------------+ //| Libraries We Need | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Indicators\WPR.mqh> #include <VolatilityDoctor\ONNX\OnnxFloat.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh>
定义整个程序中都会使用到的全局变量。 请注意,我们只需定义少量全局变量,这正是我们在讨论引言中所说的OOP帮助我们控制应用程序命名空间的含义。我们使用的大部分变量和对象都被整齐地封装在我们编写的类中。
//+------------------------------------------------------------------+ //| Global varaibles | //+------------------------------------------------------------------+ CTrade Trade; TradeInfo *TradeInformation; //--- Our time object let's us know when a new candle has fully formed on the specified time-frame Time *eurgbp_daily; //--- All our different William's Percent Range Periods will be kept in a single array WPR *wpr_array[14]; //--- Our ONNX class objects have usefull functions designed for rapid ONNX development ONNXFloat *umap_onnx,*embedded_onnx; //--- Model forecast double expected_return; int position_timer;
我们同时将Python中用于缩放训练数据的Z1和Z2分数复制了过来。
//--- The average column values from the training set double Z1[] = {7.84311120e-01, 7.87104135e-01, 7.81713516e-01, 7.84343731e-01, 5.23887980e-04, 5.26022077e-04, 5.25382257e-04, 5.25688880e-04, -5.08398234e+01, -5.07130228e+01, -5.05834313e+01, -5.04425081e+01, -5.02709031e+01, -5.01349627e+01, -5.00653250e+01, -5.01661938e+01, -5.03082375e+01, -5.04550339e+01, -5.05861939e+01, -5.06434696e+01, -5.07286211e+01, -5.07819768e+01, 1.96979782e-02, 5.29204133e-02, 4.12732506e-02, 3.20037455e-02, 2.61762719e-02, 2.34184127e-02, 2.62342592e-02, 3.32894491e-02, 3.81853070e-02, 3.85464026e-02, 3.85499926e-02, 3.94004124e-02, 4.02388908e-02, 4.02388908e-02 }; //--- The column standard deviation from the training set double Z2[] = {8.29473604e-02, 8.35406090e-02, 8.23981331e-02, 8.28950223e-02, 1.21995172e-02, 1.22880295e-02, 1.20471133e-02, 1.21798952e-02, 3.00742110e+01, 3.05948913e+01, 3.05244154e+01, 3.03776475e+01, 3.02862706e+01, 3.00844693e+01, 2.98788650e+01, 2.97182936e+01, 2.95133008e+01, 2.93983475e+01, 2.92679071e+01, 2.91072869e+01, 2.90154368e+01, 2.89821474e+01, 4.32293242e+01, 4.43537714e+01, 4.02730688e+01, 3.66106699e+01, 3.41930128e+01, 3.21743917e+01, 3.03647897e+01, 2.87462989e+01, 2.73771066e+01, 2.63857585e+01, 2.54625376e+01, 2.43656339e+01, 2.33983568e+01, 2.26334633e+01 };
初始化时,我们会设置好各项指标,并实例化我们的自定义类。如果类加载失败,我们会立即中断初始化流程,并向用户反馈具体出了什么问题。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Do no display the indicators, they will clutter our view TesterHideIndicators(true); //--- Setup our pointers to our WPR objects update_indicators(); //--- Get trade information on the symbol TradeInformation = new TradeInfo(Symbol(),SYSTEM_TIMEFRAME_1); //--- Create our ONNXFloat objects umap_onnx = new ONNXFloat(umap_proto); embedded_onnx = new ONNXFloat(embedded_proto); //--- Create our Time management object eurgbp_daily = new Time(Symbol(),SYSTEM_TIMEFRAME_1); //--- Check if the models are valid if(!umap_onnx.OnnxModelIsValid()) return(INIT_FAILED); if(!embedded_onnx.OnnxModelIsValid()) return(INIT_FAILED); //--- Reset our position timer position_timer = 0; //--- Specify the models I/O shapes if(!umap_onnx.DefineOnnxInputShape(0,1,UMAP_INPUTS)) return(INIT_FAILED); if(!embedded_onnx.DefineOnnxInputShape(0,1,EMBEDDED_INPUTS)) return(INIT_FAILED); if(!umap_onnx.DefineOnnxOutputShape(0,1,UMAP_OUTPUTS)) return(INIT_FAILED); if(!embedded_onnx.DefineOnnxOutputShape(0,1,EMBEDDED_OUTPUTS)) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); }
而在反初始化时,我们会做好清理工作,删除为对象指针。这是MQL5中良好的编程习惯,能有效避免内存泄漏或缓冲区溢出等问题——特别是当我们在一台机器上运行该应用程序的多个实例,而它们又都不自行清理时,这种做法就显得尤为重要。另外需要特别说明的是,有MQL5以外开发经验(尤其是C语言背景)的朋友,可能习惯将指针理解为内存地址。
但这里必须做一个重要区分:MQL5内置的安全特性不允许直接访问内存。MetaQuotes团队的开发者们采用了一种巧妙的变通方案:为每个对象生成一个唯一标识符,然后将该标识符与其对应的对象智能绑定。因此,对于那些在其他地方学过指针概念的读者,请注意MQL5中的“指针”实现并不真的给开发者任何内存地址,因为在MQL5的设计者看来,开放这种权限属于安全漏洞。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Delete the pointers for our custom objects delete umap_onnx; delete embedded_onnx; delete eurgbp_daily; //--- Delete all pointers to our WPR objects for(int i = 0; i <= 13; i++) { delete wpr_array[i]; } }
每当收到价格更新,我们都会调用Time类来检查是否形成了新的日K线。如果是,我们就更新指标读数,随后在没有持仓时寻找交易机会,或者管理已有的持仓。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Do we have a new daily candle? if(eurgbp_daily.NewCandle()) { static int i = 0; Print(i+=1); update_indicators(); if(PositionsTotal() == 0) { position_timer =0; find_setup(); } else if((PositionsTotal() > 0) && (position_timer < HORIZON)) position_timer += 1; else if((PositionsTotal() > 0) && (position_timer >= (HORIZON -1))) Trade.PositionClose(Symbol()); Comment("Position Timer: ",position_timer); } }
寻找交易设置只需获取相关的市场数据,并将其准备为ONNX模型的输入。请注意,在最终将输入数据存入常量vectorf类型之前,我们会先减去每列的均值并除以列标准差。然后,我们将这个常量向量传递给ONNXFloat.Predict()方法,从而从模型中获得预测结果。构建这些类帮助我们大幅减少了需要编写的代码总行数。
//+------------------------------------------------------------------+ //| Find A Trading Setup For Us | //+------------------------------------------------------------------+ void find_setup(void) { //--- Update our indicators update_indicators(); //--- Prepare our input vector vectorf market_state(UMAP_INPUTS); //--- Fill in the Market Data that has to embedded into UMAP form market_state[0] = (float) iOpen(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[1] = (float) iHigh(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[2] = (float) iLow(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[3] = (float) iClose(_Symbol,SYSTEM_TIMEFRAME_1,0); market_state[4] = (float)(iOpen(_Symbol,SYSTEM_TIMEFRAME_1,0) - iOpen(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[5] = (float)(iHigh(_Symbol,SYSTEM_TIMEFRAME_1,0) - iHigh(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[6] = (float)(iLow(_Symbol,SYSTEM_TIMEFRAME_1,0) - iLow(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[7] = (float)(iClose(_Symbol,SYSTEM_TIMEFRAME_1,0) - iClose(Symbol(),SYSTEM_TIMEFRAME_1,HORIZON)); market_state[8] = (float) wpr_array[0].GetReadingAt(0); market_state[9] = (float) wpr_array[1].GetReadingAt(0); market_state[10] = (float) wpr_array[2].GetReadingAt(0); market_state[11] = (float) wpr_array[3].GetReadingAt(0); market_state[12] = (float) wpr_array[4].GetReadingAt(0); market_state[13] = (float) wpr_array[5].GetReadingAt(0); market_state[14] = (float) wpr_array[6].GetReadingAt(0); market_state[15] = (float) wpr_array[7].GetReadingAt(0); market_state[16] = (float) wpr_array[8].GetReadingAt(0); market_state[17] = (float) wpr_array[9].GetReadingAt(0); market_state[18] = (float) wpr_array[10].GetReadingAt(0); market_state[19] = (float) wpr_array[11].GetReadingAt(0); market_state[20] = (float) wpr_array[12].GetReadingAt(0); market_state[21] = (float) wpr_array[13].GetReadingAt(0); market_state[22] = (float) wpr_array[0].GetDifferencedReadingAt(0); market_state[23] = (float) wpr_array[1].GetDifferencedReadingAt(0); market_state[24] = (float) wpr_array[2].GetDifferencedReadingAt(0); market_state[25] = (float) wpr_array[3].GetDifferencedReadingAt(0); market_state[26] = (float) wpr_array[4].GetDifferencedReadingAt(0); market_state[27] = (float) wpr_array[5].GetDifferencedReadingAt(0); market_state[27] = (float) wpr_array[6].GetDifferencedReadingAt(0); market_state[29] = (float) wpr_array[7].GetDifferencedReadingAt(0); market_state[30] = (float) wpr_array[8].GetDifferencedReadingAt(0); market_state[31] = (float) wpr_array[9].GetDifferencedReadingAt(0); market_state[32] = (float) wpr_array[10].GetDifferencedReadingAt(0); market_state[33] = (float) wpr_array[11].GetDifferencedReadingAt(0); market_state[34] = (float) wpr_array[12].GetDifferencedReadingAt(0); market_state[35] = (float) wpr_array[13].GetDifferencedReadingAt(0); //--- Standardize and scale each input for(int i =0; i < UMAP_INPUTS;i++) { market_state[i] = (float)((market_state[i] - Z1[i]) / Z2[i]); }; const vectorf onnx_inputs = market_state; const vectorf umap_predictions = umap_onnx.Predict(onnx_inputs); Print("UMAP Model Returned Embeddings: ",umap_predictions); const vectorf expected_eurgbp_return = embedded_onnx.Predict(umap_predictions); Print("Embeddings Model Expects EURGBP Returns: ",expected_eurgbp_return); expected_return = expected_eurgbp_return[0]; vector o,c; o.CopyRates(Symbol(),SYSTEM_TIMEFRAME_1,COPY_RATES_OPEN,0,HORIZON); c.CopyRates(Symbol(),SYSTEM_TIMEFRAME_1,COPY_RATES_CLOSE,0,HORIZON); bool bullish_reversal = o.Mean() < c.Mean(); bool bearish_reversal = o.Mean() > c.Mean(); if(bearish_reversal) { if(expected_return > 0) { Trade.Buy((TradeInformation.MinVolume()*2),Symbol(),TradeInformation.GetAsk(),0,0,""); return; } Trade.Buy(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetAsk(),0,0,""); return; } else if(bullish_reversal) { if(expected_return < 0) { Trade.Sell((TradeInformation.MinVolume()*2),Symbol(),TradeInformation.GetBid(),0,0,""); } Trade.Sell(TradeInformation.MinVolume(),Symbol(),TradeInformation.GetBid(),0,0,""); return; } }
这就是我们调用的更新技术指标方法的实现。
//+------------------------------------------------------------------+ //| Update our indicator readings | //+------------------------------------------------------------------+ void update_indicators(void) { //--- Store pointers to our WPR objects for(int i = 0; i <= 13; i++) { //--- Create an WPR object wpr_array[i] = new WPR(Symbol(),SYSTEM_TIMEFRAME_1,((i+1) * 5)); //--- Set the WPR buffers wpr_array[i].SetIndicatorValues(60,true); wpr_array[i].SetDifferencedIndicatorValues(60,HORIZON,true); } }
最后,务必记得在程序末尾取消定义你构建的系统常量。
//+------------------------------------------------------------------+ //| Undefine system constants we no longer need | //+------------------------------------------------------------------+ #undef EMBEDDED_INPUTS #undef EMBEDDED_OUTPUTS #undef UMAP_INPUTS #undef UMAP_OUTPUTS #undef HORIZON #undef SYSTEM_TIMEFRAME_1 //+------------------------------------------------------------------+
当你启动应用程序时,它看起来应该像下面的图10那样。这是预期行为,我们只需在初始化过程中再写一行代码,指示终端在测试期间不显示指标即可。
//--- Do no display the indicators, they will clutter our view TesterHideIndicators(true);
图10:由于我们使用了大量指标,视图最初会显得有些杂乱
一旦完成这些,我们就可以开始回测了。回顾一下,我们的训练样本从2002年11月到2018年8月,因此回测期应该从2018年9月开始,直到今天。遗憾的是,我的网络连接不太稳定,无法安全地从经纪商下载历史数据。因此,我不得不改为从2023年初开始测试,直到今天。
图11:回测周期的日期
我们向来更青睐采用基于真实 Tick 数据的全 Tick 模式,如此便能更精准地模拟过去的市场表现。这对你的网络要求可能较高,因为请求的数据量会很大。
图12:用于回测的设置同样重要
我们构建的类会在回测过程中持续给予反馈。可以通过阅读打印出的信息来检查是否有错误。正如图13中所见,我们的类按预期运行,没有记录任何错误信息。
图13:我们构建的类会在回测过程中给予反馈。如果你没有未平仓位,反馈应该是积极的,并且总是以模型预测结束。
我们还可以可视化策略产生的资金曲线。资金曲线呈现出积极的长期上升趋势,这鼓舞我们继续开发该策略,并寻找更多安全特性以尽可能限制损失。
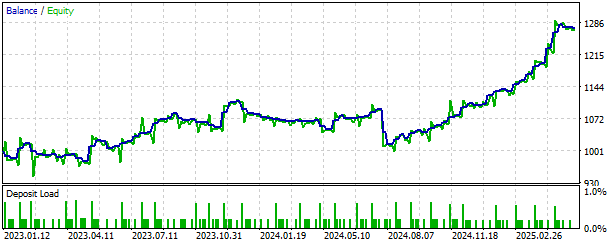
图14:可视化执行交易策略后的资金曲线
最后,还可以对我们交易策略的表现进行详细分析可视化。正如我们所见,在所有交易中,策略的准确率达到58%,夏普比率为0.90。
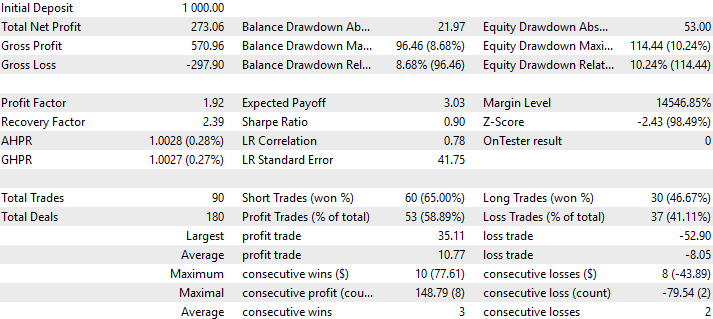
图15:我们的交易策略在未见数据上的表现详细分析
结论
通过本文的论述,读者可以从实际的统计建模中获得宝贵的经验,这超越了常规的价格预测任务所带来的收获。我们向读者展示了:
- 机器学习可用于资金管理:当我们的模型与交易信号一致时,通过增加交易量,我们有效地将交易量控制权交给统计模型,允许我们的计算机在“感到自信”时执行更大的交易量。
- 机器学习还可用于揭示观察数据更有意义的方式:我们可以使用一系列被称为降维方法的机器学习算法来压缩数据,从而让我们能够揭示大型数据集中的重要模式。
这意味着,读者可以用自己偏好的指标组合来替换WPR,并应用本文演示的降维技术。正如我们之前所见,将原本36列的数据通过UMAP压缩为仅2列后,表现反而优于使用全部原始数据;同样地,你也可能通过这种方式为自有策略找到新颖的表示形式,从而提升交易表现。
与PCA(主成分分析)等流行选择相比,读者还能从本文建议的UMAP算法中获得许多益处。我们将强调几个实质性好处:
- UMAP是一种非线性方法:像PCA这样的流行降维技术本质上假设数据中存在线性关系。当这个假设不成立时,算法会失败。而UMAP则明确旨在寻找非线性关系。读者不应说UMAP比PCA更“强大”,而更恰当的说法是UMAP比PCA更“灵活”。
- UMAP是几何的而非欧几里得的:也就是说,UMAP看到的是形状,而不仅仅是直线距离。与用直线切割数据的PCA等方法不同,UMAP会随着你的数据弯曲。它不假设世界是平坦的,而是假设你的数据存在于一个称为黎曼流形的曲面上,这是来自拓扑学数学研究的一个概念,有助于描述复杂的非线性空间。这使UMAP能够保留数据的真实几何结构,不是通过将其扁平化,而是顺应其流动。
最后,读者已从对MQL5中面向对象编程价值的认识中受益。虽然OOP可能被视为一种旧技术,但它仍然具有巨大价值,它允许我们将所有控制和失败处理集成到一个文件中。它节省了重复编写样板代码的时间,使我们能够以可预测的结果快速执行我们的想法。
| 文件名 | 文件描述 |
|---|---|
| Use_All_Data.ipynb | 用于分析市场数据的Jupyter Notebook。 |
| Fetch_Data_Algorithmic_Input_Selection.mq5 | 用于获取所需市场数据的MQL5脚本。 |
| EURGBP_Multiple_Periods_Analysis.mq5 | 同时使用了14个不同的WPR周期构建的EA。 |
| EURGBP_WPR_Algorithmic_Input_Selection.csv | 我们从经纪商获取的历史市场数据。 |
| EURGBP_WPR_EMBEDDED.onnx | 负责将我们的36列数据近似为2个UMAP嵌入的ONNX模型。 |
| EURGBP_WPR_UMAP.onnx | 负责根据2个UMAP嵌入预测EURGBP市场回报的ONNX模型。 |
| EURGBP_Multiple_Periods_Analysis.ex5 | 编译后的EA。 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/18187
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
