
Нейросети в трейдинге: Возмущённые модели пространства состояний для анализа рыночной динамики (Основные компоненты)

Введение
Финансовый рынок — это не последовательность ценовых точек и не таблица котировок. Это непрерывный поток изменений, в котором каждое событие оставляет след. Расширение спреда, всплеск объёма, ускорение цены, резкий разворот или затяжная пауза — эти изменения редко бывают симметричными и почти никогда не укладываются в аккуратную сетку временных баров. Именно поэтому рынок так плохо поддаётся анализу классическими методами временных рядов, какими бы современными они ни были.
Большинство моделей по-прежнему смотрит на рынок как на набор наблюдений и пытается угадать следующее значение. Но в реальной торговле решающим фактором является не точка, а состояние рынка. Трендовый ли он, напряжён ли поток ордеров, истощена ли ликвидность, ускоряется ли движение, или рынок собирается перейти в боковую фазу. Эти состояния не наблюдаются напрямую, их приходится восстанавливать и удерживать во времени, фильтруя шум и одновременно сохраняя чувствительность к важным изменениям.
Именно на этой идее построен фреймворк, предложенный в работе "Perturbed State Space Feature Encoders for Optical Flow with Event Cameras". Его архитектура основана на модели пространства состояний. В ней рынок рассматривается как динамическая система, а входной поток данных — последовательность воздействий на неё. Модель не просто реагирует на новые тики или бары, а обновляет скрытое состояние, которое аккумулирует информацию о прошлом движении и текущем режиме рынка. Это приближает алгоритм к тому, как рынок воспринимает опытный трейдер: не через отдельные сделки, а через общее ощущение фазы и направления.
Ключевым элементом архитектуры является механизм возмущений (perturbations). В классических моделях такие отклонения принято считать шумом и устранять фильтрацией. В рассматриваемом подходе всё наоборот — возмущение становится носителем информации. Каждый микросдвиг цены, каждое ускорение или задержка интерпретируются как воздействие на систему, изменяющее её внутреннее состояние. Благодаря этому модель остаётся чувствительной к рыночным импульсам, не теряя при этом устойчивости на спокойных участках.
Обновление состояния происходит рекуррентно и линейно по времени, что принципиально важно для торговли в режиме реального времени. Модель не требует накопления длинных окон истории и не пересчитывает прошлое при каждом новом тике. Она живёт в рынке, обновляя своё представление о нём шаг за шагом. При этом параметры динамики состояния обучаемы и адаптируются к характеру входного потока, что позволяет системе подстраиваться под смену режимов — от тренда к флэту, от спокойствия к высокой волатильности.
Такой подход формирует редкое для нейросетевых моделей сочетание свойств: потоковая работа, устойчивость к шуму, чувствительность к микроимпульсам и долгоживущая память о состоянии рынка. Именно эти качества делают архитектуру особенно ценной для практического трейдинга, где важно не столько предсказать следующий бар, сколько вовремя понять, в каком рынке мы находимся прямо сейчас.
Авторская визуализация фреймворка представлена ниже.


В этой статье мы продолжаем адаптацию фреймворка к условиям финансовых рынков средствами MQL5, сосредоточившись на практических аспектах работы модели. В предыдущих статьях был реализован модуль P-SSE, который фактически заложил фундамент всей архитектуры. Именно на этом этапе модель получила способность формировать устойчивое представление состояния анализируемой среды.
Напомним, что в нашей интерпретации P-SSE возвращает стек из заданного количества эмбеддингов состояния рынка. Каждый такой эмбеддинг отражает локальный контекст и динамику. Авторы оригинального фреймворка предлагают использовать тройки последовательных состояний, это позволяет модели анализировать не только текущее состояние, но и направление его изменения.
Следуя архитектуре, предложенной в оригинальной работе, на основе результатов работы P-SSE формируются корреляционные объёмы и контекстные представления. Далее они, вместе с входным потоком, передаются в модуль GMA-SK Motion Encoder. Стоит отметить, что авторы фреймворка не приводят детального описания его внутренней реализации, ограничиваясь ссылкой на работу "SKFlow: Learning Optical Flow with Super Kernels". Именно подходы, предложенные в этом первоисточнике, мы используем в своей работе при построении GMA-SK Motion Encoder модуля.
Здесь красной линией через всю архитектуру проходит использование Depth-Wise свёрток с остаточными связями. Это решение обеспечивает стабильность обучения, сохранение информации и высокую вычислительную эффективность — качества, критически важные при работе в потоковом режиме. С этого механизма мы и начнём работу.
Depth-Wise модуль с остаточными связями
Начиная работу над модулем Depth-Wise свёртки с остаточными связями, стоит вспомнить, что при адоптации фреймворка EDCFlow мы уже использовали данный тип свёрток. Однако тогда модуль CNeuronSpikeDepthWiseConv применялся в упрощённом виде — без остаточных связей. Сегодня мы восполним этот пробел. Остаточные связи позволят сохранить информацию о входном представлении, снизить риск деградации признаков и обеспечить стабильную передачу градиентов через глубину модели.
Для потоковых моделей, работающих в реальном времени, это особенно важно: модель должна быть глубокой, но при этом оставаться управляемой и устойчивой.
Класс CNeuronSpikeDepthWiseResidual наследуется от CNeuronSpikeDepthWiseConv, а значит полностью сохраняет поведение базовой Depth-Wise свёртки, дополняя её дополнительным вычислительным путём.
class CNeuronSpikeDepthWiseResidual : public CNeuronSpikeDepthWiseConv { protected: CNeuronSpikeConvBlock cResidual; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikeDepthWiseResidual(void) {}; ~CNeuronSpikeDepthWiseResidual(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint depth_window, uint depth_step, uint units, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeDepthWiseResidual; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; };
В структуре класса объявлен объект cResidual. Это и есть остаточная ветвь, по которой входной сигнал проходит параллельно основной Depth-Wise свёртке. Такая архитектура позволяет модели одновременно анализировать преобразованные признаки и сохранять прямую связь с исходным представлением, что особенно важно при работе с шумными финансовыми потоками, ведь потеря информации на ранних слоях быстро приводит к деградации состояния.
Метод Init обеспечивает полную инициализацию объекта, задавая все параметры для основной Depth-Wise свёртки и остаточной ветви. Он является отправной точкой: без корректной инициализации дальнейшая работа модуля невозможна.
bool CNeuronSpikeDepthWiseResidual::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint depth_window, uint depth_step, uint units, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSpikeDepthWiseConv::Init(numOutputs, myIndex, open_cl, chanels_in, chanels_out, depth_window, depth_step, units, variables, optimization_type, batch)) ReturnFalse;
Вначале вызывается инициализация родительского класса, где происходит настройка основной Depth-Wise свёртки. Если базовый модуль не инициализировался корректно, метод сразу возвращает false, предотвращая дальнейшую работу с некорректным объектом.
Следующий блок отвечает за инициализацию остаточной ветви.
if(!cResidual.Init(0, 0, OpenCL, chanels_in * depth_window, chanels_in * depth_step, chanels_out, units, variables, optimization, iBatch)) ReturnFalse; if(!cResidual.SetGradient(Gradient, true)) ReturnFalse; //--- return true; }
Здесь создаётся параллельная свёртка, которая сохраняет исходный сигнал и обеспечивает устойчивость обучения. Обратите внимание на масштабирование входных каналов: chanels_in * depth_window и chanels_in * depth_step. Это гарантирует, что остаточная ветвь видит тот же контекст, что и основная свёртка. Такой приём критичен для финансовых потоков — даже при резких изменениях рынка информация о предыдущем состоянии не теряется.
Далее устанавливается связь буферов градиентов между основной и остаточной ветвями. Это позволяет корректно распределять ошибки обучения с минимальным количеством операций копирования данных и обеспечивает, чтобы обе ветви адаптировались согласованно. В практическом смысле это снижает риск деградации признаков и стабилизирует обучение на нестабильных финансовых данных.
Если все этапы прошли успешно, метод возвращает true. Это означает, что объект полностью готов к работе.
Метод feedForward отвечает за прямой проход данных через модуль. Он объединяет работу основной Depth-Wise свёртки и остаточной ветви, формируя окончательное представление признаков для последующих этапов модели.
bool CNeuronSpikeDepthWiseResidual::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronSpikeDepthWiseConv::feedForward(NeuronOCL)) ReturnFalse;
Первая строка вызывает прямой проход родительского класса. На этом этапе входной поток обрабатывается основной Depth-Wise свёрткой. Для финансовых данных это значит, что все признаки — движение цены, объём, спред — проходят через фильтры, которые аккумулируют локальные зависимости и создают первичное представление состояния рынка.
Далее вызывается прямой проход остаточной ветви.
if(!cResidual.FeedForward(NeuronOCL))
ReturnFalse;
Здесь входной сигнал обрабатывается параллельно, сохраняя исходные признаки. Это важно для потоковых данных: резкие импульсы, микро-волатильность и редкие события сохраняются и не теряются при основной свёртке. В финансовом контексте остаточная ветвь работает как память о рынке, позволяя модели видеть не только преобразованные признаки, но и прямой сигнал из исходного потока.
Затем происходит объединение результатов основной и остаточной ветвей с нормализацией.
if(!SumAndNormilize(Output, cResidual.getOutput(), Output, GetFilters(), true, 0, 0, 0, 1)) ReturnFalse; //--- return true; }
Функция SumAndNormalize аккуратно складывает выходы обеих ветвей и нормализует результат. Благодаря этому формируется финальное представление состояния, где каждый признак несёт как информацию о преобразованной динамике, так и исходный контекст. Для рынка это критично: модель остаётся чувствительной к микроимпульсам, сохраняя стабильность при изменении режимов.
И наконец, если все операции прошли успешно, метод возвращает true — прямой проход выполнен корректно, а буфер результатов содержит полное, нормализованное представление состояния рынка, готовое к дальнейшей обработке или передаче следующему модулю фреймворка.
Super-Kernel блок
Следует отметить, что модуль Depth-Wise свёртки с остаточными связями — это лишь один кирпичик в более крупной конструкции. Он формирует фундамент Super Kernel Block, который в свою очередь лежит в основе всех модулей, предложенных в работе "SKFlow: Learning Optical Flow with Super Kernels".
Именно Super Kernel Block обеспечивает устойчивую и эффективную обработку потоковых данных, позволяя сети одновременно сохранять исходное представление и аккумулировать локальные зависимости через свёртки. Для финансовых рынков это особенно важно: даже при резких колебаниях цены, всплесках объёма или внезапных изменениях ликвидности фундаментальный блок сохраняет ключевую информацию, обеспечивая корректное формирование состояния рынка для последующих модулей.
В авторской работе приведено описание трёх типов SK-блоков. Каждый из них имеет свои особенности обработки потока и распределения признаков. Однако на практике, как показали эксперименты авторов, наибольшую эффективность демонстрирует конусноподобная архитектура.
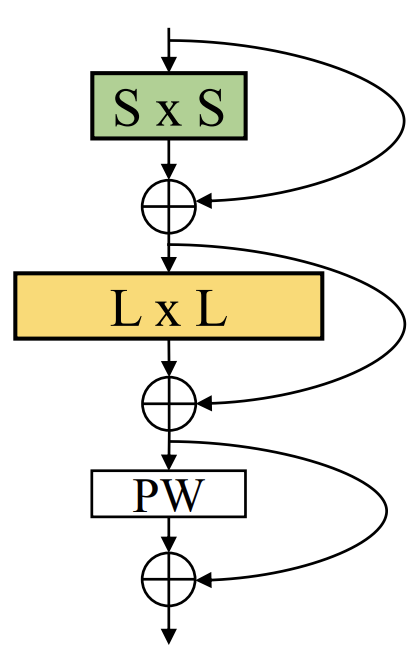
Именно её мы и реализуем в нашем проекте. Ключевая особенность этой архитектуры — узкий вход, который расширяется к более широкой основной свёртке. Такой подход позволяет сначала аккумулировать локальные признаки — микроимпульсы, изменения спреда и объёма, краткосрочные отклонения цены — а затем расширять поле восприятия, захватывая более глобальные зависимости между рыночными сигналами.
Для финансовых потоков это особенно важно. Рынок редко подчиняется линейной структуре. Локальные всплески могут быть связаны с более широкими режимами, а микроимпульсы часто сигнализируют о начале глобальных движений. Конусная форма SK-блока позволяет модели одновременно реагировать на локальные события и удерживать контекст глобального состояния рынка, что делает её устойчивой и адаптивной при потоковой обработке данных.
Класс CNeuronSpikeSuperKernelBlock реализует конусноподобную архитектуру Super Kernel Block.
class CNeuronSpikeSuperKernelBlock : public CNeuronMSRes { protected: CLayer cSKFlow; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikeSuperKernelBlock(void) {}; ~CNeuronSpikeSuperKernelBlock(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint &depth_window[], uint &depth_step[], uint units, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeDepthWiseResidual; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; };
В теле класса объявлен объект cSKFlow. Это центральный компонент блока, содержащий последовательность Depth-Wise свёрток с остаточными связями, организованных в конусную структуру.
Метод инициализации отвечает за построение внутренней архитектуры Super Kernel Block. Он создаёт последовательность Depth-Wise свёрток с остаточными связями, формируя структуру блока.
bool CNeuronSpikeSuperKernelBlock::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint &depth_window[], uint &depth_step[], uint units, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMSRes::Init(numOutputs, myIndex, open_cl, chanels_out, chanels_out, variables, optimization_type, batch)) ReturnFalse;
Сначала вызывается инициализация родительского класса, что обеспечивает корректное подключение OpenCL-контекста, выделение памяти под унаследованные объекты и настройку параметров обучения. Если базовая инициализация не удалась, метод сразу завершает работу с ошибкой.
Далее определяется количество слоёв внутренней структуры.
uint layers = depth_window.Size(); if(layers == 0 || layers != depth_step.Size()) ReturnFalse;
Проверка гарантирует, что массивы окон глубинной свёртки (depth_window) их шагов (depth_step) совпадают по размеру, а значит каждый слой блока получит корректные параметры.
Следующий блок вычисляет количество элементов последовательности для каждого слоя.
uint units_dw[]; if(ArrayResize(units_dw, layers) < (int)layers) ReturnFalse; units_dw[layers - 1] = units * depth_step[layers - 1]; for(int i = (int)layers - 2; i > 0; i--) units_dw[i] = units_dw[i + 1] * depth_step[i];
Здесь происходит распределение вычислительных ресурсов по слоям. На нижних уровнях конуса количество элементов последовательности увеличивается, чтобы более широкий слой мог аккумулировать больше признаков и захватывать глобальные зависимости. Это соответствует принципу конусной структуры: узкий вход расширяется к широкой основной свёртке, обеспечивая глубокий контекст и устойчивое восприятие рынка.
Далее задаются входные каналы для первого слоя и инициализируется контейнер cSKFlow, который будет хранить все Depth-Wise свёртки с остаточными связями, обеспечивая последовательную обработку потока данных.
uint chanels_dw_in = chanels_in; CNeuronSpikeDepthWiseResidual* conv = NULL; cSKFlow.Clear(); cSKFlow.SetOpenCL(OpenCL); for(uint i = 0; i < layers; i++) { conv = new CNeuronSpikeDepthWiseResidual(); if(!conv || !conv.Init(0, i, OpenCL, chanels_dw_in, chanels_out, depth_window[i], depth_step[i], units_dw[i], variables, optimization, iBatch) || !cSKFlow.Add(conv)) DeleteObjAndFalse(conv); chanels_dw_in = chanels_out; } //--- return true; }
Цикл создаёт слои блока. На каждом шаге:
- создаётся новый объект Depth-Wise свёртки с остаточной ветвью (CNeuronSpikeDepthWiseResidual);
- выполняется инициализация слоя с заданными параметрами окна, шагов и количества элементов в последовательности;
- объект добавляется в контейнер cSKFlow;
- входные каналы для следующего слоя обновляются, чтобы они соответствовали выходным каналам предыдущего.
Таким образом формируется полная цепочка Depth-Wise свёрток, которая сохраняет локальные признаки на нижних уровнях и постепенно расширяет поле восприятия, обеспечивая глобальный контекст. Для финансовых потоков это критично: блок одновременно реагирует на микроимпульсы, аккумулирует глобальные закономерности и поддерживает стабильное состояние модели даже при резких изменениях рынка.
В завершении метод возвращает true, что означает успешное создание всех внутренних объектов и готовность блока к работе.
Метод feedForward отвечает за прямой проход данных через Super Kernel Block, аккумулируя локальные и глобальные признаки рынка на каждом уровне Depth-Wise свёрток.
bool CNeuronSpikeSuperKernelBlock::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; for(int i = 0; i < cSKFlow.Total(); i++) { curr = cSKFlow[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
На старте создаются указатели на текущий и предыдущий слой. Входной поток данных присваивается переменной prev, а curr используется для поочередного обхода слоёв блока.
Цикл по всем слоям cSKFlow последовательно прогоняет поток через каждый слой Depth-Wise свёртки с остаточной ветвью. На каждом этапе текущий слой принимает на вход результаты предыдущего, обрабатывает их через свой прямой проход и передаёт дальше. Таким образом узкий вход постепенно расширяется, формируя конусную структуру обработки. Эта архитектура особенно эффективна для финансовых данных. Локальные микроимпульсы и краткосрочные колебания аккумулируются на нижних уровнях, а по мере прохождения через слои, блок захватывает всё более глобальные зависимости между признаками состояния рынка.
После того как поток прошёл через все слои SK-блока, вызывается одноименный метод родительского класса, который объединяет результаты конусной цепочки в итоговое представление состояния блока. Это обеспечивает корректную агрегацию всех признаков и готовность выхода к передаче следующему модулю фреймворка.
if(!CNeuronMSRes::feedForward(prev)) ReturnFalse; //--- return true; }
В завершение, если все операции прошли успешно, метод возвращает true, сигнализируя, что прямой проход блока выполнен корректно. И выходной сигнал содержит полное, нормализованное представление состояния рынка, сочетая локальные детали и глобальный контекст.
Таким образом, CNeuronSpikeSuperKernelBlock является ключевым строительным блоком всей архитектуры, объединяющим Depth-Wise свёртки с остаточными связями в конусной форме. Это обеспечивает одновременное сохранение локальных признаков, расширение поля восприятия и устойчивую работу модели при потоковой обработке рыночных данных.
Модуль GMA
Следующим модулем, на котором мы сосредоточимся, является модуль Глобальной Агрегации Движения (Global Motion Aggregation — GMA). В оригинальной работе авторы предлагают использовать особую вариацию механизма Self-Attention, адаптированного для потоковой обработки признаков. Ключевая особенность этого подхода заключается в том, что запросы и ключи формируются на основе признаков контекста, тогда как агрегируемые значения берутся непосредственно из признаков потока. Такая схема позволяет модели реагировать на локальные изменения и оценивать, как каждый отдельный элемент потока соотносится с общей динамикой среды.
В финансовом контексте это приобретает особое значение. Потоки рыночных данных крайне динамичны: микроимпульсы, изменения объёмов и колебания цен происходят одновременно на разных масштабах. Модуль GMA позволяет связывать эти события между собой, выявляя скрытые зависимости и формируя целостное представление движения рынка. Другими словами, вместо того чтобы обрабатывать каждое событие изолированно, модель оценивает их взаимосвязь и общую направленность, что обеспечивает более точное прогнозирование и устойчивость при потоковой обработке.
Прежде чем приступить к работе над модулем GMA, стоит обратить внимание на одну важную деталь. Для корректной работы этого механизма требуются две группы исходных данных: признаки потока и признаки контекста. На первый взгляд может показаться, что речь идёт о разных источниках. Однако наш опыт показывает, что в реальности они формируются одинаковыми энкодерами из одних и тех же исходных данных. Ранее мы организовывали их параллельное кодирование в рамках единого конкатенированного тензора, что позволяло эффективно объединять локальные и контекстные признаки при минимальной избыточности вычислений.
С учётом такого представления данных мы создаём новый объект — CNeuronSpikeGMA, который реализует модуль глобальной агрегации движения. Класс наследуется от CNeuronBaseOCL, что обеспечивает совместимость с остальными компонентами фреймворка и поддерживает вычисления на GPU через OpenCL.
class CNeuronSpikeGMA : public CNeuronBaseOCL { protected: uint iChanels; uint iUnits; uint iVariables; //--- CLayer cQKV; CNeuronBaseOCL cQ; CNeuronBaseOCL cK; CNeuronTransposeVRCOCL cKT; CNeuronBaseOCL cV; CLayer cScore; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikeGMA(void); ~CNeuronSpikeGMA(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels, uint units, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeGMA; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; };
В теле класса объявлены ключевые параметры: количество каналов, размер последовательности и число переменных, а также блоки для формирования запросов, ключей и значений (cQ, cK, cV) и соответствующий блок для вычисления матрицы коэффициентов зависимости (cScore). Дополнительно используется блок cQKT для параллельного формирования всех трех сущностей из единого тензора конкатенированного представления потока и контекста.
Метод инициализации отвечает за формирование ключевых параметров и архитектуры GMA-блока, определяя, как признаки потока и контекста будут обрабатываться и агрегироваться.
bool CNeuronSpikeGMA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels, uint units, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(chanels < 2) ReturnFalse; if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, chanels * units * variables, optimization_type, batch)) ReturnFalse; activation = None;
Сначала проверяется, что количество каналов достаточно для корректной работы модуля.
Далее вызывается инициализация родительского класса, которая выделяет память под унаследованные интерфейсы и настраивает параметры оптимизации. На этом этапе блок получает базовую структуру, позволяющую работать с OpenCL для ускоренных вычислений.
После этого сохраняются внутренние параметры: количество каналов, единиц и переменных, которые определяют размерность потоковых признаков и контекста.
iChanels = chanels; iUnits = units; iVariables = variables;
Контейнер cQKV очищается и подключается к OpenCL, после чего формируется последовательность слоёв для кодирования запросов, ключей и значений.
cQKV.Clear(); cQKV.SetOpenCL(OpenCL); CNeuronSpikeActivation* act = NULL; CNeuronMultiWindowsConvOCL* conv = NULL; CNeuronBatchNormOCL* norm = NULL; uint index = 0;
На первом шаге создаётся слой спайковой активации, который обрабатывает конкатенированные признаки потока и контекста, обеспечивая нелинейное преобразование.
act = new CNeuronSpikeActivation(); if(!act || !act.Init(0, index, OpenCL, 2 * chanels * units * variables, optimization, iBatch) || !cQKV.Add(act)) DeleteObjAndFalse(act);
Затем формируется многооконный свёрточный слой, способный параллельно работать с разными окнами. Это позволяет независимо формировать запросы и ключи из контекста, а значения — из признаков потока.
index++; uint windows[] = {chanels, chanels}; conv = new CNeuronMultiWindowsConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, windows, chanels, units, variables, optimization, iBatch) || !cQKV.Add(conv)) DeleteObjAndFalse(conv); conv.SetActivationFunction(None);
После свёртки применяется слой пакетной нормализации, который стабилизирует распределение признаков и облегчает последующее обучение.
index++; norm = CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, conv.Neurons(), iBatch, optimization) || !cQKV.Add(norm)) DeleteObjAndFalse(norm); norm.SetActivationFunction(None);
Следующий этап — инициализация отдельных компонентов механизма внимания. cQ и cK получают запросы и ключи на основе контекстных признаков, а cKT обеспечивает транспонирование ключей для удобного вычисления матрицы внимания.
index++; if(!cQ.Init(0, index, OpenCL, (chanels + 1) / 2 * units * variables, optimization, iBatch)) ReturnFalse; cQ.SetActivationFunction(None); cQ.Clear(); index++; if(!cK.Init(0, index, OpenCL, (chanels + 1) / 2 * units * variables, optimization, iBatch)) ReturnFalse; cK.SetActivationFunction(None); index++; if(!cKT.Init(0, index, OpenCL, variables, units, (chanels + 1) / 2, optimization, iBatch)) ReturnFalse; cKT.SetActivationFunction(None); index++; if(!cV.Init(0, index, OpenCL, chanels * units * variables, optimization, iBatch)) ReturnFalse; cV.SetActivationFunction(None);
cV агрегирует значения из признаков потока, обеспечивая интеграцию локальной информации в глобальный контекст.
Наконец, формируется контейнер cScore, который вычисляет скоры внимания и нормализует их с помощью CNeuronSoftMaxOCL.
cScore.Clear(); cScore.SetOpenCL(OpenCL); CNeuronBaseOCL* neuron = NULL; CNeuronSoftMaxOCL* softmax = NULL; //--- index++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, units * units * variables, optimization, iBatch) || !cScore.Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None); index++; softmax = new CNeuronSoftMaxOCL(); if(!softmax || !softmax.Init(0, index, OpenCL, neuron.Neurons(), optimization, iBatch) || !cScore.Add(softmax)) DeleteObjAndFalse(softmax); softmax.SetHeads(units * variables); //--- return true; }
В результате каждый элемент потока получает корректно взвешенные значения, отражающие как локальные изменения, так и глобальное движение рынка.
Всё это вместе обеспечивает GMA-блоку способность связывать признаки потока и контекста, выявлять скрытые зависимости и формировать единое, согласованное представление движения рынка.
Метод feedForward реализует прямой проход данных через GMA-блок, обеспечивая согласованную интеграцию признаков потока и контекста.
bool CNeuronSpikeGMA::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; for(int i = 0; i < cQKV.Total(); i++) { curr = cQKV[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
На старте поток данных передаётся в локальную переменную prev, а curr используется для последовательного обхода всех слоёв блока cQKV. Каждый слой обрабатывает входной сигнал предыдущего слоя, выполняя активацию, свёртку и нормализацию. После чего передаёт результаты дальше. Таким образом формируется первичная обработка признаков, вычисление запросов, ключей и значений. При этом сохраняются локальные микроимпульсы и глобальные зависимости между признаками рынка.
После прохождения всех слоёв выполняется разделение конкатенированного тензора с помощью функции DeConcat. Поток признаков разбивается на три компонента: значения V для агрегации, ключи K и запросы Q.
if(!DeConcat(cV.getOutput(), cQ.getOutput(), cK.getOutput(), prev.getOutput(), iChanels, iChanels / 2, iChanels / 2, iUnits * iVariables)) ReturnFalse;
Затем ключи транспонируются через cKT, чтобы корректно вычислить матрицу внимания.
if(!cKT.FeedForward(cK.AsObject())) ReturnFalse; prev = cScore[0]; if(!MatMul(cQ.getOutput(), cKT.getOutput(), prev.getOutput(), iUnits, iChanels / 2, iUnits, iVariables, true)) ReturnFalse;
На следующем этапе осуществляется матричное умножение MatMul между запросами и транспонированными ключами, создавая скоры внимания, которые отражают, насколько каждый элемент потока соотносится с контекстом рынка. Эти скоры последовательно проходят через слои cScore, где они нормализуются и преобразуются в окончательные веса внимания.
for(int i = 1; i < cScore.Total(); i++) { curr = cScore[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
После того как внимание рассчитано и значения агрегированы, стоит подчеркнуть, что на входе мы имеем конкатенированный тензор признаков движения и контекста. А на выходе нам нужны только уточнённые признаки движения. Чтобы корректно обработать данные, сначала выполняется деконкатенация, которая выделяет из исходного тензора признаки движения, сохраняя их соответствие по каналам и элементам последовательности.
if(!DeConcat(PrevOutput, Output, NeuronOCL.getOutput(), iChanels, iChanels, iUnits * iVariables))
ReturnFalse;
Затем вычисляются уточнённые значения на основе матрицы внимания и тензора значений V, формируя взвешенные признаки движения, которые учитывают глобальные зависимости и локальные импульсы рынка.
if(!MatMul(prev.getOutput(), cV.getOutput(), Output, iUnits, iUnits, iChanels, iVariables, true)) ReturnFalse;
На финальном этапе новые уточнённые признаки суммируются с исходными значениями потока и проходят нормализацию.
if(!SumAndNormilize(PrevOutput, Output, Output, iChanels, true, 0, 0, 0, 1)) ReturnFalse; //--- return true; }
Этот шаг обеспечивает плавное уточнение информации, интегрируя свежие вычисленные зависимости с уже существующими признаками движения. Благодаря такой процедуре модель получает устойчивое и согласованное представление динамики рынка, способное одновременно фиксировать микроимпульсы и глобальные тенденции.
Разветвленнвя структура потока данных внутри GMA-модуля требует особого подхода к распространению градиентов в рамках обратного прохода. Этот алгоритм мы встраиваем в метод calcInputGradients. В отличие от линейных блоков, здесь необходимо учитывать, что поток данных многократно разветвляется на запросы, ключи и значения, а затем агрегируется в матрицу внимания, поэтому градиенты тоже должны аккуратно распределяться по всем ветвям.
bool CNeuronSpikeGMA::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) ReturnFalse; //--- CNeuronBaseOCL* next = cScore[-1]; CNeuronBaseOCL* curr = NULL; if(!next || !MatMulGrad(next.getOutput(), next.getGradient(), cV.getOutput(), cV.getGradient(), Gradient, iUnits, iUnits, iChanels, iVariables, true)) ReturnFalse;
Обратный поток градиентов начинается с последних слоёв вычисления скоринговой матрицы cScore. Итоговые градиенты проходят через матричное умножение, чтобы скорректировать веса значений V в соответствии с влиянием на конечный результат.
Далее выполняется последовательная обработка всех слоёв cScore в обратном порядке, что позволяет корректно учесть вклад каждого слоя в формирование внимания и уточнённых признаков движения.
for(int i = cScore.Total() - 2; i >= 0; i--) { curr = cScore[i]; if(!curr || !curr.CalcHiddenGradients(next)) ReturnFalse; next = curr; }
После этого градиенты распространяются на запросы и ключи. Вычисляется влияние матрицы внимания на Q и транспонированные K, при этом корректируется поток сигналов через транспонированные ключи.
if(!MatMulGrad(cQ.getOutput(), cQ.getGradient(), cKT.getOutput(), cKT.getGradient(), next.getGradient(), iUnits, iChanels / 2, iUnits, iVariables, true)) ReturnFalse; if(!cK.CalcHiddenGradients(cKT.AsObject())) ReturnFalse;
Затем возвращаемся к ветви cQKV, где градиенты конкатенируются из трёх составляющих (V, Q и K) и передаются обратно по последовательным слоям энкодеров.
next = cQKV[-1]; if(!next || !Concat(cV.getGradient(), cQ.getGradient(), cK.getGradient(), next.getGradient(), iChanels, iChanels / 2, iChanels / 2, iUnits * iVariables)) ReturnFalse; for(int i = cQKV.Total() - 1; i >= 0; i--) { curr = cQKV[i]; if(!curr || !curr.CalcHiddenGradients(next)) ReturnFalse; next = curr; }
Каждый слой получает свой вклад, корректирует скрытые градиенты и передаёт их дальше, обеспечивая аккуратное распространение сигналов через весь конкатенированный тензор.
На заключительном этапе градиенты передаются на уровень исходных данных.
if(!NeuronOCL.CalcHiddenGradients(next))
ReturnFalse;
Далее следует обратить внимание, что алгоритм выше передал лишь градиенты ошибки по основной магистрали. И теперь нам необходимо учесть влияние остаточных связей. Но здесь у нас проблема, ведь в остаточных связях участвуют только признаки потока, а исходные данные содержат еще и контекст. Мы не можем суммировать матрицы разного размера. Нам нужно привести их в соответствие, заполнив недостающие элементы нулевыми значениями. Для этого мы создаем вначале тензор нулевых градиентов для признаков контекста.
if(!PrevOutput.Fill(0) || !Concat(PrevOutput, Gradient, next.getPrevOutput(), iChanels, iChanels, iUnits * iVariables)) ReturnFalse;
После чего конкатенируем его с градиентами остаточных связей. При необходимости корректируем полученный тензор на производную функции активации слоя исходных данных.
if(NeuronOCL.Activation() != None) if(!DeActivation(NeuronOCL.getOutput(), next.getPrevOutput(), next.getPrevOutput(), NeuronOCL.Activation())) ReturnFalse;
И теперь, когда мы подготовили тензор соответствующего размера, осуществляем суммирование данных двух информационных потоков.
if(!SumAndNormilize(next.getPrevOutput(), NeuronOCL.getGradient(), NeuronOCL.getGradient(), iChanels, false, 0, 0, 0, 1)) ReturnFalse; //--- return true; }
Таким образом, calcInputGradients обеспечивает точное и согласованное распространение градиентов по сложной архитектуре GMA, позволяя модели одновременно учитывать локальные микроимпульсы рынка и глобальные зависимости, что критично для качественной обработки финансовых потоков. А CNeuronSpikeGMA становится логическим продолжением информационного потока фреймворка, аккумулируя и согласовывая признаки потока и контекста, чтобы модель могла формировать целостное представление движения рынка, выявляя скрытые зависимости и глобальные тенденции.
Заключение
В этой статье мы продолжили адаптацию фреймворка, предложенного в работе "Perturbed State Space Feature Encoders for Optical Flow with Event Cameras", к специфике финансовых потоков, сосредоточившись на реализации ключевых компонентов средствами MQL5. Начав с углублённого рассмотрения Depth-Wise свёрток с остаточными связями, мы показали, как конструкторские решения позволяют аккумулировать локальные признаки и одновременно удерживать глобальный контекст, формируя устойчивое и информативное представление состояния рынка.
Далее мы подробно рассмотрели Super Kernel Block, демонстрируя, как последовательное расширение поля восприятия позволяет модели фиксировать микроимпульсы, объёмы и краткосрочные отклонения, а затем интегрировать их в более широкие зависимости рыночного потока.
Модуль Global Motion Aggregation (GMA) был представлен как логическое продолжение архитектуры.
В совокупности все рассмотренные решения образуют единый поток обработки, где локальные микроимпульсы, глобальные рыночные зависимости и контекстные признаки интегрируются в согласованное и адаптивное представление рынка. Такая архитектура позволяет модели реагировать на краткосрочные события и удерживать долгосрочную устойчивость, что существенно повышает качество прогнозирования и эффективность торговых стратегий.
Ссылки
- Perturbed State Space Feature Encoders for Optical Flow with Event Cameras
- SKFlow: Learning Optical Flow with Super Kernels
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования