
Нейросети в трейдинге: Масштабируемые трансформеры со структурной декомпозицией признаков (FAT)

Введение
Финансовый рынок редко прощает поверхностные решения. Он меняется быстрее, чем успевают обновляться датасеты, и наказывает за избыточную сложность не хуже, чем за чрезмерную простоту. Именно поэтому каждое новое архитектурное решение в области машинного обучения требует не только технической реализации, но и глубокого осмысления его соответствия природе рыночных данных. В предыдущих работах мы последовательно выстраивали инженерную логику построения моделей, анализировали их устойчивость на данных вне обучающей выборки и уделяли особое внимание практической применимости. Теперь логика развития подводит нас к следующему этапу — системному пересмотру механизма внимания в контексте мультимодальных финансовых признаков.
Классический Transformer продемонстрировал впечатляющие результаты в задачах обработки последовательностей. Однако финансовый рынок — это не текст и не речь, здесь нет грамматики в привычном смысле. Рыночные данные представляют собой многослойную структуру признаков, формирующихся одновременно в нескольких смысловых измерениях. Цена, объём, корреляции с индексами, режим волатильности, временные сессии — всё это существует параллельно и взаимодействует по-разному в зависимости от контекста. Когда такие данные подаются в стандартный Self-Attention без структурных ограничений, модель вынуждена самостоятельно выявлять их скрытую организацию. В условиях высокой шумовой компоненты это приводит к росту вариативности оценок и ухудшению обобщающей способности.
Проблема особенно проявляется при масштабировании. Увеличение числа параметров повышает выразительность, но без адекватного индуктивного предположения усиливает переобучение. Финансовые рынки нестационарны: зависимости меняются, корреляции разрушаются, режимы чередуются. Следовательно, архитектура должна учитывать иерархию признаков на уровне своей внутренней структуры.
Именно эта мысль легла в основу работы "From Scaling to Structured Expressivity: Rethinking Transformers for CTR Prediction", в которой была предложена архитектура Field-Aware Transformer (FAT). Авторы фреймворка решали задачу прогнозирования CTR — вероятности клика пользователя на рекламное объявление. На первый взгляд область далека от финансов, однако, при внимательном анализе обнаруживается поразительное сходство постановок. CTR-модель оперирует множеством разнородных признаков: пользователь, товар, контекст показа, история взаимодействий. Эти признаки образуют смысловые поля, взаимодействующие между собой неравномерно. Простое плоское внимание между всеми токенами приводило к слабой масштабируемости и потере структурной выразительности.
Авторы FAT показали, что проблема заключается в отсутствии структурного сдвига между группами признаков. Модель не различала внутренние и межмодальные взаимодействия. В результате рост размера сети не обеспечивал ожидаемого улучшения качества. Решением стала декомпозиция пространства токенов на поля и введение контролируемого механизма внимания внутри и между ними. Такой подход позволил добиться более устойчивого масштабирования и повышения эффективности.
Если перенести эту логику на финансовые рынки, параллели становятся очевидными. Задача прогнозирования клика и задача прогнозирования движения цены формально различны, но по своей вероятностной природе схожи. В обоих случаях речь идёт об оценке вероятности события на основе множества разнородных признаков. И там, и там данные носят табличный характер. И там, и там взаимодействия между группами признаков имеют разную силу и разный экономический смысл. Наконец, и в рекламных системах, и на финансовых рынках наблюдается эффект насыщения: увеличение числа параметров без структурной дисциплины перестаёт приносить прирост качества.
Рыночные признаки естественным образом делятся на поля. Микроструктурные показатели взаимодействуют преимущественно между собой. Динамика цены формирует собственный слой закономерностей. Кросс-активные факторы влияют иначе, чем внутридневные паттерны. Режим волатильности модифицирует интерпретацию сигналов из других групп. Попытка смешать всё в одном однородном пространстве внимания создаёт хаотичную матрицу взаимодействий. Это повышает риск ложных корреляций и снижает устойчивость модели при смене режима.
Именно здесь возникает идея структурной декомпозиции признаков и перехода к Field-Aware Transformer. Предложенный авторами фреймворка подход строится на организации пространства токенов. Каждый признак или группа признаков относится к определённому полю. Внутри поля формируется плотное взаимодействие, позволяющее модели улавливать локальные закономерности. Между полями вводится контролируемый механизм обмена информацией, отражающий экономический смысл их связей и ограничивающий паразитные зависимости. Внимание перестаёт быть плоским и приобретает структурированную форму.
С точки зрения финансовых рынков, это означает переход от универсального механизма обработки признаков к архитектуре, учитывающей их природу. Мы формируем дисциплинированную матрицу взаимодействий. Такой подход потенциально снижает вариативность результатов на интервалах вне обучающей выборки и повышает устойчивость к смене рыночных режимов. Особенно важно, что структурная организация позволяет масштабировать модель без пропорционального роста хаотичных связей. Это критично для задач, где стабильность важнее краткосрочного максимума метрик.
Финансовый рынок не терпит догматизма. Он требует инженерной аккуратности и стратегического взгляда. Если в рекламных системах структурная декомпозиция позволила добиться предсказуемого роста качества, то в рыночных задачах она может стать инструментом повышения устойчивости и управляемости моделей.
Архитектура Field-Aware Transformer
Переходя к описанию архитектуры, важно сразу зафиксировать принципиальный момент. Мы проектируем систему, в которой структура рыночных данных отражается в структуре вычислений. Архитектура не должна угадывать организацию признаков — она должна её учитывать изначально.
В классическом Transformer каждый признак после эмбеддинга становится токеном в общем пространстве внимания. Модель не различает, относится ли токен к цене, объёму или макроиндикатору. Все взаимодействия потенциально равновероятны. В задачах обработки текста это оправдано: слова действительно образуют последовательность, где любая пара может быть семантически связана. Рынок, напротив, устроен иерархически. Следовательно, и внимание должно быть иерархическим.
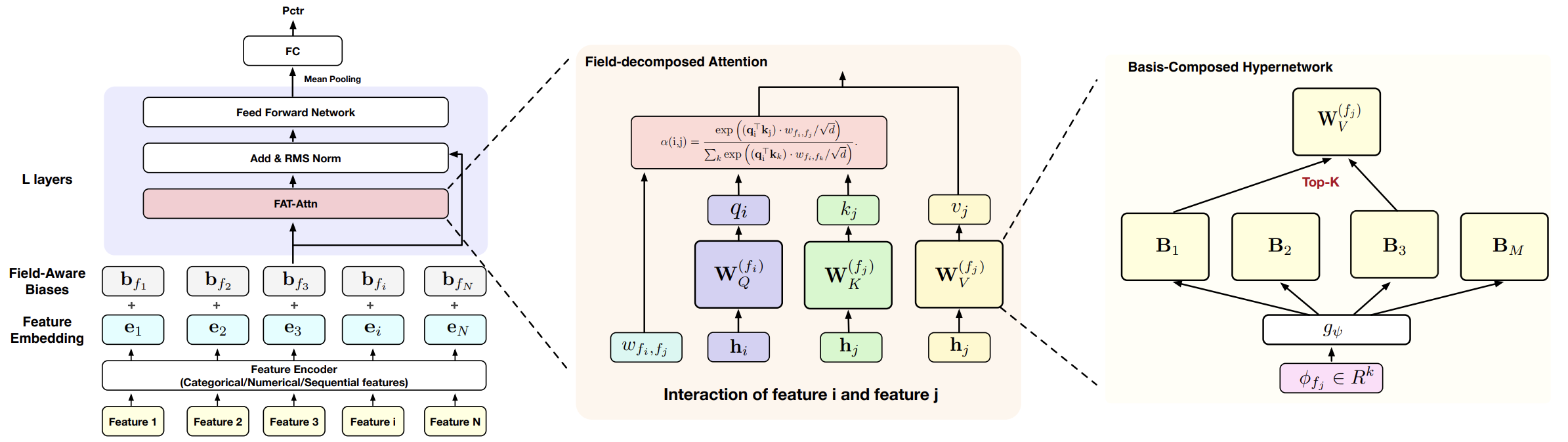
Архитектура Field-Aware Transformer достигает структурной выразительности за счёт декомпозиции механизма внимания вдоль семантических полей. Иначе говоря, внимание организуется учётом принадлежности токенов к различным смысловым группам.
Ключевая идея заключается в том, что проекции Query, Key и Value перестают быть универсальными. Они специализируются для каждой пары полей (fi,fj). Такая специализация реализуется через механизм согласования содержимого между полями и модуль, управляющий интенсивностью их взаимодействия.
Эффективная сложность модели определяется числом семантических групп. В условиях экстремальной разреженности данных — что характерно как для CTR, так и для финансовых рынков — такая структурная априорная организация даёт более жёсткие границы обобщения и повышает устойчивость при масштабировании.
Чтобы дополнительно развязать ёмкость модели и количество полей, в оригинальной работе используется гиперсеть, генерирующая параметры для конкретных полей. Это позволяет отказаться от хранения отдельных матриц для каждой пары и устранить избыточные затраты памяти. При этом на этапе инференса дополнительных вычислительных издержек не возникает. Архитектура остаётся компактной и масштабируемой.
Перейдём к ключевому этапу — структурированной токенизации и обучению представлений с учётом полей. В задаче CTR исходные данные представляют собой неупорядоченный набор гетерогенных признаков: категориальных, числовых и последовательных. Их смысл определяется не позицией в последовательности, а комбинацией взаимодействий между полями — пользователь, товар, контекст. Это важное отличие от языка, где значение формируется за счёт композиции токенов в линейной цепочке.
Финансовые рынки демонстрируют схожую природу. Признаки не образуют синтаксическую последовательность. Они формируют мультимодальную систему: динамика цены, объёмы, микроструктура, кросс-активные индикаторы, режимные характеристики. Их семантика возникает из взаимодействия между группами, а не из порядка следования. Именно поэтому структурированная токенизация становится фундаментальным элементом архитектуры.
Каждый анализируемый признак xi отображается в общее латентное пространство Rd, формируя эмбеддинг ei. Тип преобразования зависит от природы признака. Категориальные переменные кодируются через embedding-таблицы. Числовые признаки могут проходить через монотонные сети или дискретизироваться по квантилям с последующей эмбеддинг-проекцией. Последовательности данных агрегируются специализированными энкодерами и сворачиваются в представление уровня поля.
После этого все эмбеддинги приводятся к общей размерности d, обеспечивая совместимость внутри механизма внимания. Однако ключевое отличие от классического Transformer заключается в отказе от позиционного кодирования, основанного на индексе. В CTR и в финансовых данных порядок признаков произволен. Их смысл определяется принадлежностью к модальности, а не местом в массиве.
Поэтому вместо позиционных векторов вводится модально-специфический сдвиг. Для токена i, принадлежащего полю fi, итоговое представление записывается как
hi = ei + bfi,
где bfi — обучаемый вектор, отражающий семантическую роль поля. Этот сдвиг выполняет две задачи одновременно. Во-первых, он инжектирует структурный приоритет в модель. Во-вторых, обеспечивает корректную обобщающую способность при произвольной перестановке признаков. Модель начинает понимать, к какому уровню рыночной структуры относится каждый токен.
Полученная последовательность H=[h1, ..., hN] представляет собой семантически заземлённый поток токенов с идентификацией полей. Именно на этом фундаменте строится дальнейшее структурированное внимание.
В контексте нашей задачи это означает следующее. Мы переходим от обработки разрозненных признаков к дисциплинированной архитектуре, где каждый элемент рыночной информации изначально помещён в соответствующую смысловую область. Такой подход позволяет модели концентрироваться на экономически оправданных взаимодействиях, а не тратить ресурсы на перебор случайных корреляций.
Иначе говоря, мы формируем архитектуру, в которой масштабирование связано с контролируемым расширением структурной выразительности. Для финансовых рынков, где стабильность и управляемость модели имеют решающее значение, это преимущество становится определяющим.
В классическом Transformer механизм внимания устроен элегантно и строго. Скаляр внимания между токенами i и j вычисляется как нормированное скалярное произведение (hiWQ)(hjWK)T/√d, где матрицы WQ и WK ∈ Rd*d являются глобально общими для всех токенов. Архитектура предполагает универсальность. Любой элемент последовательности обрабатывается по одной и той же схеме, независимо от его происхождения. В текстовых задачах такая однородность допустима. Однако в задачах моделирования сигналов финансовых рынков и высокоразмерных табличных структур — это допущение становится слишком грубым.
Рыночные данные не однородны по природе. Признаки имеют разную семантику, разную динамику и разную роль в принятии решения. Макроэкономический индикатор взаимодействует с процентной ставкой иначе, чем с внутридневной волатильностью. Поток ордеров ведёт себя по-другому в паре с ликвидностью, чем с временной меткой сессии. Эти взаимодействия асимметричны и контекстно-зависимы. Направление имеет значение, и роль поля имеет значение. Игнорировать это — всё равно что оценивать корреляцию между инфляцией и спредами так же, как между двумя соседними лагами одной серии. Формально — корректно, но экономически — наивно.
Именно поэтому естественным шагом становится обобщение идеей Field-aware Factorization Machines, предложенное авторами фреймворка FAT. Вместо использования единой пары матриц проекций они предполагают, что Query, Key и Value зависят от упорядоченной пары полей (fi,fj). Тогда представление токена преобразуется через специализированные матрицы WQ(fi,fj), WK(fi,fj), WV(fi,fj), а скаляр внимания по-прежнему вычисляется как ɑ(i,j)= QiTKj/√d. Механика остаётся прежней, но семантика меняется радикально. Способ, которым признак ликвидности смотрит на спред, может отличаться от того, как он взаимодействует с импульсом цены. Модель начинает учитывать направление связи, а не только её силу.
Для финансовых рынков это принципиально. Большинство сигналов здесь условны. Их значимость зависит от контекста, режима волатильности, временного горизонта. Универсальное внимание сглаживает эти различия. Специализированное внимание к модальности, напротив, отражает комбинаторную природу признаков и их роль в структуре рыночного состояния. Оно позволяет различать структурные взаимодействия и шумовые совпадения. А в условиях рыночного шума это уже стратегическое преимущество.
Однако за концептуальную чистоту приходится платить. Если реализовать полную специализацию для каждой пары полей и каждой головы внимания, параметрическая сложность слоя вырастает как O(HF²d²). В прикладных финансовых задачах число полей легко достигает десятков и сотен, а размерность эмбеддингов остаётся трёхзначной. При таких масштабах даже один слой превращается в конструкцию на миллиарды параметров. Это неприемлемо ни по памяти, ни по вычислительным затратам, ни по латентности инференса. Теория выглядит убедительно, а практика быстро возвращает к реальности.
Чтобы сохранить выразительность моделирования пар полей и при этом обеспечить масштабируемость, авторы фреймворка FAT раскладывают механизм внимания на два уровня. Первый уровень отвечает за содержательное сопоставление признаков — насколько два токена соотносятся с точки зрения их экономического смысла. Второй уровень регулирует силу связи — должен ли вообще поток информации между соответствующими группами признаков быть интенсивным.
Оценка внимания задаётся формулой:
ɑ(i,j) = (QiTKj) • Wfi,fj,
где
Qi = WfiQ hi, Kj = WfjK hj.
Теперь скалярное произведение QiTKj — это сопоставление признаков с учётом их поля происхождения. Каждая модальность обучает собственный способ кодирования. Блок макрофакторов формирует представления иначе, чем блок рыночной микроструктуры. Сигнал ликвидности кодируется иначе, чем временной индикатор или показатель волатильности.
Таким образом, ещё до учёта силы межмодального взаимодействия модель понимает, к какому типу экономической информации относится признак. Это базовый уровень структурной осознанности.
Скаляр Wfi,fj отвечает за направление и интенсивность связи между полями. Он масштабирует влияние одного семантического блока на другой. Причём асимметрия естественна: Wfi,fj ≠ Wfj,fi. В финансовых рынках это принципиально. Влияние процентной ставки на доходность акций не равно обратному эффекту. Передача информации направлена.
Вектор значений формируется аналогично:
Vj = WfjV hj.
Это обеспечивает согласованность выходных представлений с экономической ролью признака.
Важно, что здесь чётко разделены две функции. Скалярное произведение отвечает за смысловую совместимость признаков. Параметр Wfi,fj управляет маршрутизацией информации между блоками. Сначала модель определяет, насколько признаки согласуются экономически. Затем решает, стоит ли усиливать этот канал связи.
Для финансовых рынков такая структура особенно ценна. Рынок — это система неравномерных и режимно-зависимых связей. Одни каналы передачи информации устойчивы, другие активируются лишь в стрессовых условиях. Структурированное внимание позволяет это различать. Оно усиливает значимые межблочные взаимодействия и подавляет случайные.
При этом архитектура остаётся вычислительно дисциплинированной. Полная специализация по парам полей потребовала бы порядка O(F²d²) параметров на одну голову внимания — неприемлемый масштаб при сотнях и тысячах признаков. Факторизация снижает сложность до O(Fd²+F²). Авторы фреймворка FAT сохраняют семантическую точность, но избегают взрывного роста модели. Это более зрелый и стратегически устойчивый подход.
Однако даже в факторизованной версии хранение отдельных матриц WfQ, WfK, WfV для каждого поля остаётся чувствительным к масштабу. В финансовых задачах число семантических полей обычно находится в диапазоне десятков или, в расширенных конфигурациях, порядка сотни. При размерности эмбеддингов d в 64–256 это означает хранение десятков или сотен полноразмерных матриц d×d. Формально это допустимо, но при постоянном добавлении новых факторов, лагов и режимных признаков параметрическая зависимость O(Fd²) начинает постепенно раздувать модель.
Чтобы рост числа полей не тянул за собой линейный рост тяжёлых матриц, вводится базисно-композиционная гиперсеть. Идея инженерно строгая. Вместо хранения полной матрицы для каждого поля авторы фреймворка FAT формируют её как взвешенную комбинацию ограниченного набора общих базисных преобразований.
Задан общий набор матриц B = {B1, …, BM}, Bm ∈ Rd×d. Эти базисы обучаются совместно с моделью и переиспользуются всеми полями. Их можно интерпретировать как универсальные линейные операции — перераспределение координат, масштабирование направлений, структурное смешивание факторов.
Каждому полю f сопоставляется компактный мета-вектор ɸf ∈ Rk. Лёгкая MLP-функция gѱ преобразует его в коэффициенты смешивания:
sf = gѱ(ϕf).
После разреженного отбора Top-K и нормировки через SoftMax, формируется итоговая матрица:
WfQ = ∑m∈ϕf ɑfm Bm.
Аналогично строятся WfK и WfV.
Ключевой эффект — разрыв прямой зависимости между числом полей и количеством полноразмерных параметров. Вместо хранения F матриц размера d², модель использует общий базис порядка O(Md²) и компактные мета-представления порядка O(Fk), где k≪d. Добавление нового поля больше не требует создания новой тяжёлой матрицы — достаточно небольшого мета-вектора.
Для финансовых рынков это означает устойчивую масштабируемость. Мы можем расширять модель, добавляя новые факторные блоки или альтернативные источники данных, не нарушая параметрического баланса. Рост становится управляемым, а не экспоненциальным.
При этом на этапе инференса дополнительных вычислений не возникает. Все матрицы WfQ, WfK, WfV синтезируются и кэшируются после обучения. В продакшене используется стандартный слой внимания с уже готовыми параметрами. Латентность остаётся прежней, что критично для систем оценки рисков и торговых стратегий.
Таким образом, архитектура масштабируется за счёт структурированного переиспользования общего линейного словаря. Это аккуратный, дисциплинированный способ наращивать выразительность модели в условиях постоянно расширяющегося пространства финансовых признаков.
Теоретический результат показывает, что эффективная сложность модели определяется числом семантических полей F и их взаимодействиями, а не общим числом возможных значений признаков. Это принципиально.
В финансовых рынках пространство состояний гигантское. Комбинации лагов, режимов, факторов, производных показателей — практически безграничны. Но число смысловых блоков ограничено: цена, волатильность, ликвидность, макрофакторы, кросс-активные сигналы и так далее. Именно эти блоки определяют структуру задачи.
Модель ограничивает себя структурой полей. Она не может произвольно соединять любые токены, она учится только экономически осмысленным взаимодействиям.
Обычный Self-Attention допускает произвольные токен-уровневые связи. Его эффективная сложность скрыто масштабируется вместе с размером словаря. В шумной среде это повышает риск переобучения. Рынок не прощает такого оптимизма.
FAT действует осторожнее. Он обучает F полевых преобразований и F² направленных связей. Пространство гипотез становится контролируемым. Каждый параметр разделяется большим количеством наблюдений внутри своего семантического блока. Статистическая эффективность растёт.
Отсюда вытекает аккуратный закон масштабирования. Если объём данных m и структура полей F фиксированы, увеличение размерности d расширяет способность модели описывать более тонкие взаимодействия между блоками. Параметры растут пропорционально Fd². Ошибка обучения снижается, потому что модель становится более выразительной. Но благодаря структурным ограничениям рост дисперсии остаётся под контролем. Именно это и даёт плавное, предсказуемое улучшение качества.
Для финансовых рынков это особенно важно. Здесь данные шумные, режимы меняются, а переобучение — частый гость. Архитектура, масштабируемая по структуре, а не по инерции увеличения числа параметров, даёт более устойчивый рост качества. Масштабирование становится управляемым процессом, а не экспериментом на удачу.
Авторская визуализация фреймворка представлена ниже.
Реализация средствами MQL5
Теоретическая часть дала нам главное — понимание, почему архитектура FAT масштабируется предсказуемо, и почему её структурные ограничения работают в нашу пользу. Теперь переходим к практике.
Далее мы рассмотрим один из вариантов реализации предложенного решения средствами MQL5. Перед нами стоит непростая задача. Нам необходимо:
- реализовать эмбеддинги признаков,
- построить механизм внимания с учётом структуры полей,
- организовать хранение и обновление параметров,
- обеспечить вычислительную эффективность,
- сохранить устойчивость к шуму рыночных данных.
Мы не будем пытаться собрать всё сразу. Такой подход в сложных системах почти гарантированно приводит к хаосу. Двигаться будем постепенно — шаг за шагом, блок за блоком. По сути, мы повторим архитектуру FAT, но в строгих условиях прикладной торговой среды. Без лишней абстракции и фокусом на вычислительную дисциплину и контролируемую сложность.
Начинаем с ключевого элемента всей конструкции — генератора модально зависимых параметров. В контексте Field-Aware Transformer это механизм, который позволяет модели подстраивать параметры взаимодействия признака под его семантику. Для финансовых рынков это особенно важно. Цена, объём, волатильность, индикаторы, календарные признаки — всё это разные модальности. И если мы заставим их проходить через одинаковые веса, то получим усреднённую, сглаженную модель. Рынок такого не прощает.
Класс CFieldAwareParams аккуратно встроен в существующую иерархию и наследуется от CNeuronBaseOCL. Это сразу задаёт тон. Мы не изобретаем новую систему обучения, а расширяем уже работающую архитектуру, добавляя в неё структурную выразительность.
class CFieldAwareParams : public CNeuronBaseOCL { protected: CParams cCandidates; CParams cFieldEmbeddings; CLayer cScore; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return FeedForward(); } ///\ingroup neuron_base_opt virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return UpdateInputWeights(); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return true; } public: CFieldAwareParams(void) {}; ~CFieldAwareParams(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint params_to_field, uint fields, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool FeedForward(void); virtual bool UpdateInputWeights(void); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defFieldAwareParams; } virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Внутри класса обращают на себя внимание три объекта: cCandidates, cFieldEmbeddings и cScore.
cFieldEmbeddings — это фундамент. Здесь хранятся эмбеддинги полей. В финансовом контексте под полем можно понимать, например, ценовые признаки, объёмные признаки, осцилляторы, временные характеристики. Каждое поле получает собственное векторное представление фиксированной размерности embed_size. Именно через эти эмбеддинги мы вводим структурный сдвиг между токенами — не через усложнение внимания, а через зависимость параметров от типа источника данных.
cCandidates — это набор параметрических кандидатов. По сути, библиотека возможных проекций или весовых шаблонов, из которых модель будет выбирать подходящие для конкретного поля. В задачах CTR это позволяет учитывать взаимодействие разных категориальных фич. На рынке логика схожа. Взаимодействие цена × объём качественно отличается от волатильность × время суток. Нам нужны разные параметры, но хранить их в полном переборе слишком дорого.
И здесь появляется cScore. Это небольшой MLP, который вычисляет веса для кандидатов. Он получает на вход представление поля и выдаёт распределение, определяющее, какие параметры из библиотеки активировать. В упрощённом виде это мягкий выбор Top-K кандидатов. Мы не создаём уникальный набор весов для каждого поля — мы комбинируем заранее заданные. Это и есть экономия вычислений и памяти.
Метод инициализации задаёт всю геометрию пространства.
bool CFieldAwareParams::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint params_to_field, uint fields, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, params_to_field * fields, optimization_type, batch)) ReturnFalse;
Вызов одноименного метода родительского класса сразу фиксирует размер пространства результатов как params_to_field * fields. Это важный момент. Мы не генерируем параметры в вакууме. Мы заранее знаем, что для каждого поля будет сформирован собственный набор весов размерности params_to_field. Значит итоговый объём генерируемых параметров растёт линейно по числу полей. Линейно — и это уже хорошая новость для масштабируемости.
Далее создаётся cCandidates с размерностью params_to_field * candidates. Это библиотека базовых шаблонов.
uint index = 0; if(!cCandidates.Init(0, index, OpenCL, params_to_field * candidates, optimization, iBatch)) ReturnFalse; cCandidates.SetActivationFunction(None);
Обратите внимание, число кандидатов не умножается на количество полей, они общие. В этом и заключается экономия. Вместо хранения fields×params_to_field независимых матриц мы храним ограниченный пул кандидатов, из которого для каждого поля будет собираться собственная комбинация. Если кандидатов 16 или 32 — это управляемый объём памяти.
Затем инициализируются эмбеддинги полей. Это компактное представление семантики каждого поля.
index++; if(!cFieldEmbeddings.Init(0, index, OpenCL, fields * embed_size, optimization, iBatch)) ReturnFalse; cFieldEmbeddings.SetActivationFunction(SIGMOID); if(fields <= embed_size) if(!cFieldEmbeddings.Identity(fields, embed_size)) ReturnFalse;
В финансовых задачах число полей редко выходит за пределы десятков. Даже если мы разделим признаки на ценовые, объёмные, волатильностные, трендовые, временные и ещё несколько групп, порядок величин остаётся разумным.
Интересный штрих — если параметр fields не превышает embed_size, то вызывается метод Identity. По сути, мы стартуем с ортогонального базиса. Это аккуратная инициализация. Она снижает корреляцию между полями на старте обучения. Для рыночных данных, где признаки и так часто коррелированы, это разумная мера.
Далее формируется блок cScore. Здесь начинается самая динамическая часть архитектуры. Первый сверточный слой расширяет пространство из embed_size до 4*candidates.
index++; cScore.Clear(); cScore.SetOpenCL(OpenCL); CNeuronConvOCL* conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, embed_size, embed_size, 4 * candidates, fields, 1, optimization, iBatch) || !cScore.Add(conv)) DeleteObjAndFalse(conv); conv.SetActivationFunction(SoftPlus);
Мы временно увеличиваем представление, чтобы дать модели больше степеней свободы перед финальным выбором. Затем второй сверточный слой сжимает его до candidates. В итоге для каждого поля формируется вектор оценок длиной candidates.
index++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, 4 * candidates, 4 * candidates, candidates, fields, 1, optimization, iBatch) || !cScore.Add(conv)) DeleteObjAndFalse(conv); conv.SetActivationFunction(SoftPlus);
И вот здесь вступает CNeuronSparseSoftMax с параметром topK. Это ключевой элемент всей конструкции. Мы не используем плотный SoftMax по всем кандидатам, а жёстко ограничиваем число активных шаблонов. Только Top-K из candidates участвуют в формировании итоговых параметров.
index++; CNeuronSparseSoftMax* softmax = new CNeuronSparseSoftMax(); if(!softmax || !softmax.Init(0, index, OpenCL, fields, candidates, topK, optimization, iBatch) || !cScore.Add(softmax)) DeleteObjAndFalse(softmax); //--- return true; }
Именно здесь уменьшается вычислительная сложность. Если бы использовались все кандидаты, то для каждого поля приходилось бы выполнять полную линейную комбинацию из candidates матриц. При topK << candidates фактическое число операций уменьшается пропорционально. Остальные просто не участвуют в вычислениях.
В контексте финансовых рынков это особенно уместно. Рынок редко одновременно находится во всех режимах. Обычно доминируют несколько факторов: тренд, новостной импульс, низкая ликвидность и т.д. Разреженный SoftMax фактически реализует мягкий выбор нескольких активных режимов. Модель не размазывает внимание по всем сценариям сразу.
После инициализации вся конструкция начинает дышать именно в прямом проходе. Здесь теория превращается в механику, а архитектурная идея — в конкретную последовательность вычислений.
bool CFieldAwareParams::FeedForward(void) { if(!bTrain) return true;
Первое, что бросается в глаза, — проверка bTrain. Генерация модально зависимых параметров имеет смысл только в режиме обучения. В боевом режиме модель использует ранее сформированные веса. Это правильная дисциплина. На финансовых рынках лишние вычисления в реальном времени — роскошь. Особенно если стратегия работает на младших таймфреймах.
Далее запускается прямой проход через cCandidates и cFieldEmbeddings.
if(!cCandidates.FeedForward()) ReturnFalse; if(!cFieldEmbeddings.FeedForward()) ReturnFalse;
Кандидаты — это наша библиотека базовых параметров. Эмбеддинги — компактное представление семантики полей. По сути, мы получаем две матрицы: одну с шаблонами весов, вторую — с векторными описаниями источников признаков.
Затем начинается последовательный проход через блок cScore. Эмбеддинги полей по цепочке проходят через два сверточных слоя и завершаются разреженным SoftMax. Это важный момент. В отличие от классического Attention, где веса считаются между всеми токенами, здесь мы вычисляем веса между полем и библиотекой параметров. Это более узкая, но гораздо более контролируемая задача.
CNeuronBaseOCL* prev = cFieldEmbeddings.AsObject(); CNeuronBaseOCL* curr = NULL; for(int i = 0; i < cScore.Total(); i++) { curr = cScore[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
Когда управление доходит до CNeuronSparseSoftMax, мы фактически имеем для каждого поля набор из Top-K активных кандидатов и соответствующие коэффициенты. Остальные кандидаты обнуляются. Это и есть структурная разреженность в действии.
Далее вычисляются ключевые размеры. Это не просто формальность — от корректности этих соотношений зависит геометрия итоговой матрицы весов.
if(prev.Type() != defNeuronSparseSoftMax) ReturnFalse; CNeuronSparseSoftMax* softmax = prev; uint fields = softmax.Heads(); uint topK = softmax.DimensionOut(); uint params_to_field = Neurons() / fields; uint candidates = cCandidates.Neurons() / params_to_field;
Кульминация — вызов SparseMatMul. Вот здесь и происходит генерация модально зависимых параметров. Мы берём индексы выбранных кандидатов, их веса и соответствующие строки из библиотеки cCandidates, после чего формируем итоговый тензор Output.
if(!SparseMatMul(softmax.GetIndexes(), softmax.getOutput(), cCandidates.getOutput(), Output, fields, topK, candidates, params_to_field)) ReturnFalse; dActivation(this); //--- return true; }
Именно разреженная матричная операция позволяет сократить вычислительную нагрузку. Мы работаем только с Top-K элементами на каждое поле. Если представить это интуитивно, то для каждого поля модель выбирает несколько активных режимов и смешивает только их.
Если посмотреть на весь прямой проход целиком, его логика предельно ясна. Сначала мы получаем устойчивые базовые шаблоны, затем на основе семантики полей определяем, какие из них важны. После этого собираем итоговые параметры только из выбранных компонентов. Никакой лишней комбинаторики.
И что особенно важно — вычислительная сложность остаётся линейной по числу полей и пропорциональной Top-K, а не общему числу кандидатов. Для реальных торговых систем это принципиально. Мы можем позволить себе добавить новые поля или расширить библиотеку шаблонов, не опасаясь экспоненциального роста нагрузки.
Таким образом, CFieldAwareParams становится механизмом структурной адаптации. Он позволяет нам управлять выразительностью модели без экспоненциального роста вычислительной сложности. Мы получаем гибкость — но остаёмся в рамках контролируемой инженерной реализации.
Заключение
Предложенный авторами фреймворка FAT подход — это попытка вернуть архитектуре трансформера структурную дисциплину, не жертвуя выразительностью. В условиях финансовых рынков это особенно важно. Здесь избыточная сложность не просто замедляет расчёты — она размывает сигнал. А чрезмерное упрощение, напротив, приводит к потере чувствительности. Field-Aware Transformer позволяет пройти между этими крайностями.
Изначально архитектура была предложена для задач CTR-прогнозирования. Однако сама природа решаемой проблемы — работа с множеством разнородных полей и необходимость моделировать их взаимодействия без экспоненциального роста параметров — удивительно близка к задачам финансовых рынков. В CTR это пользователь, объявление, контекст. В трейдинге — цена, объём, волатильность, время, структура инструмента. Разные домены, но общая архитектурная боль: как учитывать структуру, не разрушая масштабируемость.
Авторский фреймворк FAT предлагает зрелое решение. Он отделяет семантику полей от параметрического пространства. Вводит библиотеку кандидатов вместо полного набора независимых весов. Использует разреженный выбор Top-K вместо плотной агрегации. В результате модель получает возможность адаптировать параметры к структуре исходных данных, оставаясь вычислительно управляемой.
Важно, что структурная декомпозиция признаков снижает риск переобучения. Вместо того чтобы учить гигантскую плотную матрицу взаимодействий, модель работает с компактной библиотекой шаблонов. Это дисциплинирует пространство решений. А на рынке дисциплина — понятие не философское, а практическое.
В следующей статье мы продолжим реализацию подходов, предложенных авторами фреймворка.
Ссылки
- From Scaling to Structured Expressivity: Rethinking Transformers for CTR Prediction
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Создание панели администратора торговли на MQL5 (Часть XI): Современный интерфейс мессенджера в платформе (I)
Создание панели администратора торговли на MQL5 (Часть XI): Современный интерфейс мессенджера в платформе (I)
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования